

本篇文章将解读腾讯多媒体实验室“腾讯天籁”团队在 Interspeech2020 上同佐治亚理工学院和中国科学技术大学等单位联合发表的 3 篇论文。Interspeech 是语音技术领域的国际顶级会议,今年于 10 月 25 至 29 日在线上举行,根据主办方发布的数据,Interspeech2020 共接收到有效论文投稿 2140 篇,其中 1022 篇被接收。
▌01


在本篇论文中,探索了语音增强领域的深度张量-向量回归模型(deep tensor-to-vector regression models)中,不同模型参数量和增强后语音质量的关系。提出了一种结合深度卷积神经网络(convolutional neural network,CNNs)和张量训练(tensor-train,TT)输出的混合结构的模型 CNN-TT,该网络结构在保证语音质量的同时,达到了降低了模型参数量的目的。同时,在本篇论文中,我们首先推导出了基于卷积神经网络的向量-向量回归模型的泛化上界。而且,该模型不仅适用于单通道降噪模型,对于多通道也表现良好。
论文地址为:
https://isca-speech.org/archive/Interspeech_2020/pdfs/1900.pdf
背景
语音增强的目的在于提高带噪语音的质量和可懂度。近些年来,随着深度神经网络的引入,语音增强领域有了很大的提升。主流的方法是,通过深度网络将带噪语音的频谱向量映射到干净语音频谱向量,该方法对单通道和多通道语音增强都有着令人惊艳的效果。深度卷积神经网络(CNNs)和循环神经网络(recurrentneural networks,RNNs)更进一步的提升了语音增强的性能。但是,深度神经网络通常意味着较大的计算量,对于一些性能受限的硬件设备,往往不能实用。因此,对不同参数量对应的模型性能进行研究是非常有意义的。深度卷积神经网络(CNNs)对于时域空间信息的学习以及提取更结构化的特征信息有着更强大的建模能力,而张量训练深度神经网络(tensor-traindeep neural networks,TT-DNN)能够在保证语音质量不下降的情况下,降低网络参数量,因此我们的 CNN-TT 网络结合了两个网络的优点。本文中,我们将对 DNN、CNN、TT-DNN、CNN-TT 的模型参数量以及模型效果在单通道和多通道语音降噪两个领域进行比较。我们的 CNN-TT 在参数量是 CNN 模型的 32%时,降噪后的语音质量略超过原始的 CNN 模型,当参数量是原始模型的 44%时,该性能得到进一步提升。
模型
张量训练深度神经网络(TT-DNN)的本质是将网络的输入、输出、权重、偏置均改为张量的形式进行训练,反向传播仍然采用链式传导法则。原理上,对于一个节点数为 256 的全连接层,如果输入是 160*120*3,那么权重的参数量为 14745600。而张量训练,是将向量变换为张量的形式,比如输入变换为 8*20*20*18,输出变换为 4*4*4*4,张量训练的秩为 1*4*4*4*1,则只需要 2976 个参数,参数量的压缩率为 2e-4。所以张量训练可以极大的压缩模型的参数量。
如下图所示,本文提出的模型是 CNN-TT 如(d)所示,前三个图是我们用于对比的模型,分别是原始的 DNN 模型、原始的 CNN 模型、张量训练 DNN 模型(TT-DNN)。该模型的一个重要优势在于通过将输出全连接层替换为张量训练层,模型计算量得到极大的减小。并且结合 CNN 和 TT 的性能上界推断出 CNN-TT 的上界为:
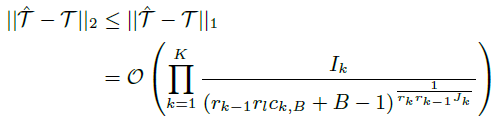

实验
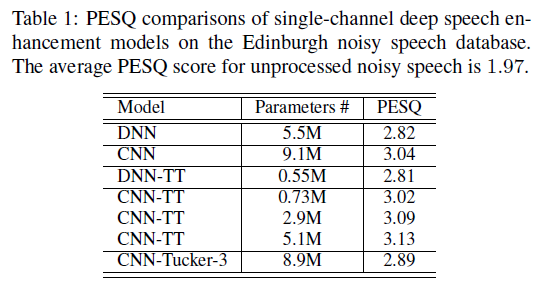
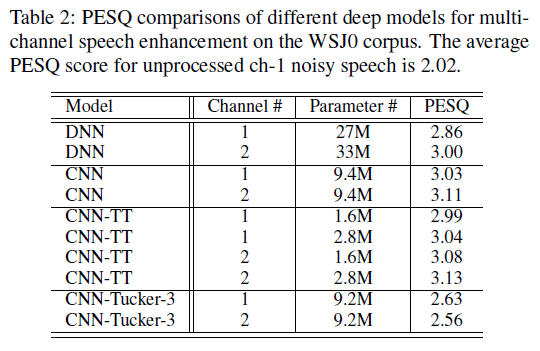
本文所提出来的方法分别在 Edinburgh 和 WSJ0 数据集上进行单通道降噪和多通道降噪效果的评估,结果分如表 1 和表 2 所示。表 1 中,张量训练的 DNN-TT 模型和原始的 DNN 模型相比,参数量从 5.5M 下降到 0.55M,pesq 基本持平。原始的 CNN 和 DNN 相比,pesq 提升了 0.22 个点。本文提出的 CNN-TT 模型参数量从 9.1M 下降到 0.73M 时,性能略有下降,下降到 2.9M 时,性能略有提升。同样的,在表 2 的多通道语音增强中,CNN-TT 在保持 pesq 不下降的情况下,降低参数量。两个表格中的,Tucker-3 是一种在正交空间中计算不同张量模式的高阶扩展奇异值分解方法,在这里作为 CNN-TT 的对比,可以看到,该方法参数量下降有限,并且语音质量有所下降。
结论
本文提出了一种结合深度卷积神经网络和张量训练输出的混合结构的模型 CNN-TT,该网络结构在保证语音质量的同时,达到了降低了模型参数量的目的。并将该结构和其他几种张量到向量的回归网络进行了对比,在单通道降噪和多通道降噪上均给出了实验对比。
▌02
接下来,我们将介绍论文《Relational Teacher Student Learning with Neural Label Embedding forDevice Adaptation in Acoustic Scene Classification》。

在这篇论文中,提出了基于域自适应的框架来处理声学场景识别中设备不匹配的问题,这种框架是基于神经标注提取(Neural Label Embedding, NLE) 和关系性的老师-学生学习(Relational teacher student learning, RTSL)。通过综合考滤到不同声学场景之间的结构性关系,提出的方法可以实现设备非相关的系统。训练阶段,可转移知识在 NLE 模块被提取出来,在自适应阶段,全新提出的 RTSL 策略被使用来学习目标声学模型,学习过程中没有使用配对好的源-目标数据,而这些源-目标数据在传统老师学生模型中是必须的。在 DCASE 2018 Task 1b 的数据集上验证, 单独的 NLE 方法可以达到传统设备自适应和老师学生技术。NLE 和 RTSL 相结合后,可以更进一步提高系统的识别性能。
论文地址为:
https://isca-speech.org/archive/Interspeech_2020/pdfs/2038.pdf
背景
近些年来,声学场景识别性能有了很大的提升,在学术与工业界越来越多的队伍进行做此类研究,例如像国际顶尖级别的声学场景识别比赛(DCASE challenge)。性能最好的系统采用了深度学习网络(DNNs)来处理声学场景识别。深度卷积神经网络(CNNs)更进一步的提升了声学场景识别的性能。后来,基于对抗神经网络(GAN)与可变自回归网络(VAE)被用来扩充传统的数据扩充方法,如 Mix-up,加减速等。尽管如此,这些声学场景识别系统还是不能处理不匹配的信道问题,比如声音由不同的设备采集,而不同设备采集是声学信号采集不可避免的一部分。所以在 DCASE2018 Task1b 中就新增加了关于不同设备采集声学场景识别的任务。这个任务就是使场景识别的系统可以识别不同设备采集的信号,保证尽可能的准确,同时训练的语料也相对较少。基于老师-学生(TS)的方法,也被称为知识蒸馏,在声学场景里面被证明了有效性。关键思想就是最小化老师模型与学生模型分布之间的距离。NLE 是最近几年被提出来解决不同域之间的蒸馏操作。这篇文章通过使用不同声学场景之间的关系来扩展了 NLE 的机制,提出了 RTSL 的方法来解决不同设备不匹配的问题。
模型
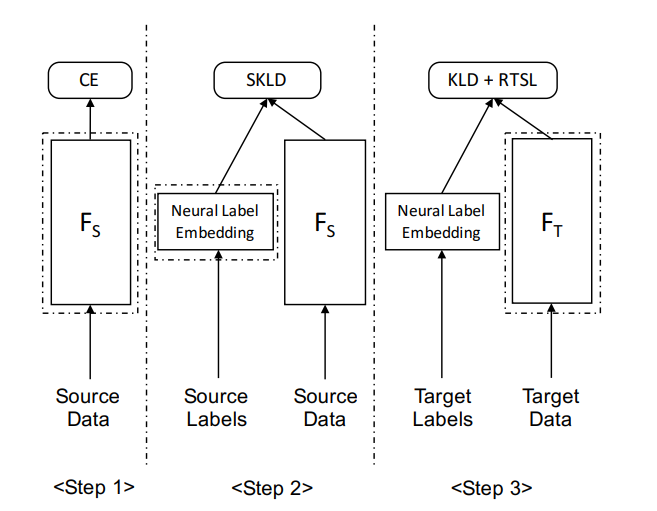
如下图所示,本文提出来的模型有三个方面,第一个是源模型训练(SourceModel Training),第二个 NLE 标签生成(NLELable Generatation),第三个是不同设备域的 NLE 自适应过程(NLEfor Device Domain Adaptation)。在源模型训练阶段,NLE 为声学场景识别系统独立构建一个单独的深度学习网络模型。在 NLE 标签生成阶段,NLE 生成的 Label 可以替代源数据中的 one-hot 向量。在不同设备域的 NLE 自适应过程就是获取自适应后的目标模型。
实验
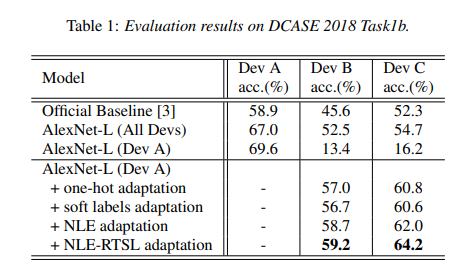
本文所提出来的方法在 DCASE 2018 Task1b 开发集上进行评估。DCASE 2018 Task1b 提供了 28 个小时的声学场景录制数据,使用了三种不同的设备设备 A 有 24 个小时,设备 B 和 C 各自有 2 个小时,录制的音频每 10 秒一个片断。
上述表格给出了在 DCASE 2018 Task1b 上的一些实验结果,最上面一行可以看到不同的设备采集的声音信号在同样的识别系统上的确有不同的识别性能。Official Baseline,AlexNet-L(All Devs)使用了所有设备录制的数据,AlexNet-L(Dev A) 仅使用了设备 A 录制的数据,所以在设备 B 和 C 上的识别性能很低。本文中采用的方法最终在设备 B 和设备 C 上采集的信号得到了最好的性能效果。
结论
本文提出了一个老师学生方案的神经网络表征技术来解决设备不匹配的问题。本文做了一个不同声学场景间的一些共性与不同。这些结构性的关系在网络中被学习到后被编码进入 NLE 中,然后把源设备域自适应到目标设备域。所提出来方法与技术方案在 DCASE 2018 Task1b 上被验证取得了有效的性能提升。
▌03
最后,我们来介绍论文《An Acoustic Segment Model Based Segment UnitSelection Approach to Acoustic Scene Classification with Partial Utterances》。

在这篇论文中, 我们主要探究通过声学单元选择的方式提升声学场景分类任务的准确性。首先通过声学分段模型(ASMs)对声学单元建模,然后检测停止声学分段模型(stop ASMs)来屏蔽相关声学段。在 DCASE2018 任务上,我们提出的方法在没有进行数据扩增的情况下将场景分类准确率由 68%提升到了 72.1%,并取得了和 AlexNet-L 模型可比的效果,
论文地址为:
https://isca-speech.org/archive/Interspeech_2020/pdfs/2044.pdf
背景
声学场景分类主要是对实际生活中的声音片段进行分类,判断其属于何种环境类型,比如地铁站,街道,公园等。目前现在的声学场景分类方法中效果最好的主要是基于深度神经网络,尤其是 CNN 网络,而引入注意力机制和基于深度神经网络的数据扩增等方法进一步提升了其效果。
系统介绍
本文使用的基于 ASMs 指导的声学单元选择方案,过滤去除和声学场景相关性较小的单元,只利用信息量较大的相关单元,其系统框图如下图:
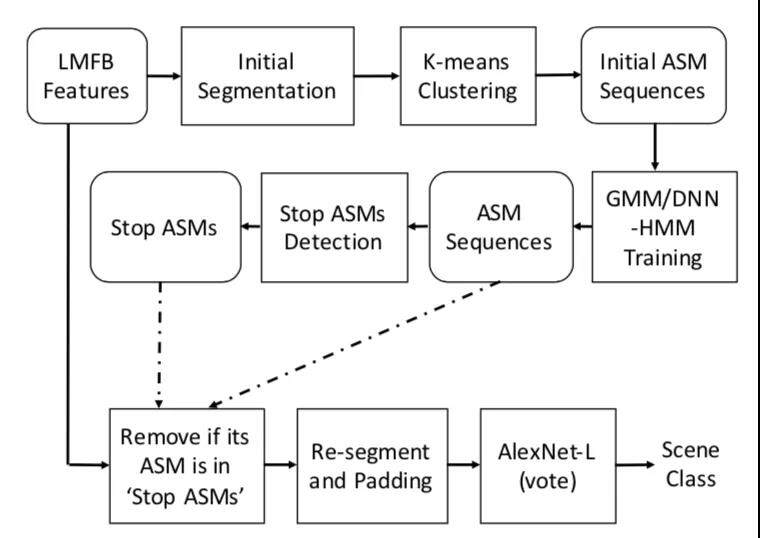
具体的 ASM 序列可由两个步骤获得:
1. 通过无监督方式初始化 ASM,使其每个声学单元的长度相同
2. 在初始 ASM 上建立 GMM-HMM 或者 DNN-HMM 系统来生成 ASM 序列
而 stop ASMs 通过 Mean Probability(MP)、Inverse Document Frequency(IDF)、Variance of Probability(VP)、 StatisticalValues(SATs)等 4 种方法获得最高概率的单元。
实验结果
本文的实验建立在 DCASE2018 比赛数据上,共用 48kH 采样率的数据 24 小时,分为 10 个场景,并分别分为 6122 句的训练集和 2518 句的测试集, 我们的基线系统采用压缩后的 AlexNet-L 模型,实验结果如下表:
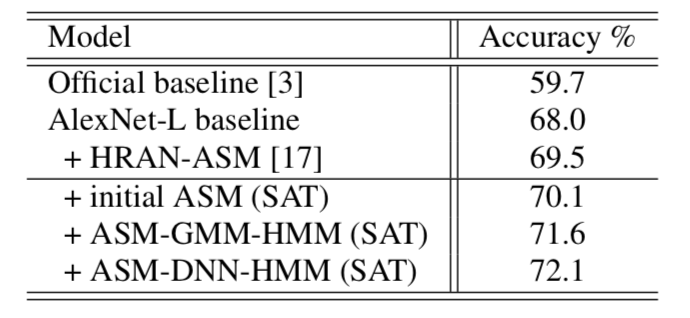
我们可以发现, 引入 ASM 后可以将 AlexNet-L 基线系统性能提升到 70.1%,而通过 GMM-HMM 和 DNN-HMM 方式进一步优化 ASM 后,其性能可进一步提升到 72.1%。
结论
综上所述,实验结果表明,通过引入基于 ASM 的前端声学单元选择方式,只利用部分信号的有用信息,在通过声学分段建模选择和基于 CNN 的模型分类两个步骤,实现了无数据扩增情况下的单系统最好的可比效果。
头图:Unsplash
作者:腾讯多媒体实验室
来源:腾讯多媒体实验室 - 微信公众号 [ID:TencentAVLab]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论