

机器学习无疑是一个时髦的话题,它在一定程度上已经改变了商业运作的方式以及我们每一个人的生活。事实上,机器学习并没有什么神秘之处,它就是一套用于识别不同数据模式的方法,随着科技的发展,它正作为一种工具供人类数据工程师使用。
为了增强企业竞争力,越来越多的人试图在其产品中加入机器学习。但是,真的有必要在所有的产品中都加入机器学习吗?如果没有必要的话,产品经理又应该在什么时候对机器学习说 “No” 呢?
包括我自己在内的产品经理,越来越多地面临这样的压力:将机器学习整合到产品中。而这种压力来自多方面:工程师和数据科学家因前沿算法而感到非常兴奋;销售和市场利益相关者希望能够更快、更便宜地解决问题;而我们自己的愿望却是能够更好地为用户服务。
作为一个领域,使用机器学习为面向用户的关键应用提供动力,这样的产品还处于早期的阶段。在研究了房地产、招聘和基因组学领域的机器学习应用之后,我发现,在考虑机器学习对面向用户产品的影响时,以下内容非常有用:
区分机器学习模型和基于规则的模型。
认识到基于规则的模型识别比机器学习模型更占优势。
在构建机器学习模型之前需回答三个关键问题。
最后,我针对这三个问题评估了各种实际用例,从而确定了使用机器学习的好处和坏处。
并非所有好的模型都是机器学习模型
从较高的层次上来讲,模型可以分为 “学习” (或机器学习)和 “基于规则” 的模型。对于学习模型,开发人员为模型提供数据,而模型则学习输入和输出之间的关联(associations)。这些学习到的关联可能并不符合人们的期望。对于基于规则的模型,开发人员只需编写显式规则(且没有 Bug)的程序即可,而且模型的输出还符合人们的期望。
认为学习模型要比基于规则的模型更复杂,其实这是一种误解。学习模型在数学上,可以是复杂的(如深度神经网络),也可以是相对简单的(如线性回归)。类似地,基于规则的模型可以是复杂的(如需要超级计算机运行的物理模拟),也可以是简单的(如一两个 if 语句)。
另一个关键点是,回测(backtesting,严格统计的主要组成部分)也适用于基于规则的模型,而不仅仅是学习模型。回测意味着使用一个模型对具有已知结果的过去实例进行预测,并将预测结果与已知结果进行比较。这可以通过基于规则的模型来实现,并且可以为基于规则的模型计算用于学习模型(AUC、F1、R2、MSE……)的所有相同正确率的度量。基于规则的模型不仅可以进行回测,而且也应该进行回测以防出现过拟合。
基于规则的模型比机器学习模型更具优势
基于规则的模型需要领域知识。为了确定规则应该是什么,产品团队必须对问题空间有所了解,并具备一些相关知识。这是一个有用的约束条件。它促进了产品团队对模型用例和用户更深入的理解,并鼓励产品团队不断提高他们的的理解。将学习模型简单地应用到行业数据集中,对用户将会有很大的帮助,而且这样做很少会出现问题。但不幸的是,这种容易实现的目标,已经在大多数行业中实现了。
基于规则的模型通常只需较少的数据。基于规则的模型不需要经过训练!这对于新应用或初创企业尤为有用,因为他们可能有很深的领域知识,但拥有的数据却很少。
基于规则的模型通常更容易调试。与学习模型相比,它们更容易推理,因为基于规则的模型只反映了人们编码到其中的关联。此外,这些关联是直接在代码中表示的。相反,在学习系统中,关联并不是用代码来表示的,而是用可能难以发现、难以理解且时间不稳定的系数来表示的。当生产模型在凌晨 3 点开始出现问题,产品团队被叫醒去修复时,搜索一个在人类可读代码中肯定存在的错误是最好的选择。
何时应该使用机器学习模型?
尽管基于规则的模型有很多优点,但你如果要访问 TechCrunch 网站,就不能不了解学习模型是如何推动从无人驾驶汽车到语言翻译取得惊人进展的。而且,如果你对过去十年的人工智能研究有所了解,你就会知道,现在的天平已经明显倾向于学习模型,而不是基于规则的模型。那么,产品经理何时应该支持面向用户产品的学习模型呢?当你对以下三个问题给出的答案是 “Yes” 的时候,你就可以支持学习模型了。
1. 一种概率的,或不透明的基本原理是否可以接受?
这是一个关于模型用例的问题,而非模型本身的问题。这是一个关于价值观的问题。请扪心自问,如果你应用这个模型的话,你是否会接受它可能返回的任何决定?
当 Netflix 为我推荐一个糟糕且不直观的推荐时,我并不会觉得我的价值观受到了侵犯。风险很低,而且没有类似 “社会契约” 之类的东西让我必须理解给我的电影推荐。人们很容易就能推断出,我们应该只在低风险的情况下使用概率理论。然而不幸的是,事情没有那么简单。以医学为例,人们普遍认为,统计(概率)结果是作出生死攸关的决定的最佳方法,比如批准新药。概率理论是否可以接受,这是一个价值观的问题,而不是一个关乎规模或严重性的问题。
下面是另一个医学上的例子,阐明了相反的观点。想象一下,当你看完医生后,向你的健康保险公司提出了索赔,但被拒绝了,因为保险公司认为,你的索赔不符合他们承保规则的可能性过高。我和医生都会被激怒的。我只是想要一个可以理解的、确定的答案,它究竟违反了什么规则?尽管如此,保险公司还是在使用不透明的学习模型来裁定索赔,因为他们在自身支付规则累积的复杂性下苦苦挣扎,难以自拔。
类似地,让我们来看看批准假释的程序。鉴于美国存在偏见性假释决定的历史,这些判决应该遵循高度可解释的理由,以防止偏见的永久化。但这并不意味着模型不能使用,而是社会至少应该能够理解模型的逻辑。尽管如此,今天的许多假释决定都是用黑盒学习算法作出的。(很多人已经对此进行了抨击,因此我就不再赘述,但要了解黑盒解释算法的话,这里有个很好的摘录,你可以看看。)
人的价值观各不相同,所以总是会存在很大的灰色区域,但我们应该从 “概率决策是否与我们的价值观一致” 这一问题开始机器学习的探索过程。
2. 数据是否真实地代表了现实世界?
模型需要两种类型的数据:标签(又名基准真相(ground truth)、结果、因变量)和特征(又名输入、自变量)。
首先,我们需要代表现实的标签。在现实和数据标签之间可能有很多关联。以犯罪相关的数据集为例。由于罪犯希望避免受到惩罚,因此,他们会努力防止自己的罪行出现在定罪数据集中! “真实” 的标签只是实际犯罪的一部分,但不幸的是,由于无辜的人被定罪,因此它们也包括假正类(译注: 假正类,False Positive,FP。被模型预测为正的负样本)。用这样的训练数据标签去构建无偏模型无疑是非常困难的。
降低标签质量的常见问题之一是审查,或者当数据生成过程还阻止标记某些实例时。让我们设想一个预测求职者表现的模型。绩效考核适用于被录用的求职者,但是根据定义,它并不适用于被拒绝的求职者。审查的有害影响有时候可以通过巧妙的统计数据来减少,但如果你的用例涉及到审查数据,那么这就是一个很大的危险信号。
其次,我们需要能够代表我们的先验信念(prior beliefs)的特征,这些特征事关什么输入很重要,以及为什么重要。换句话说,我们需要有一个因果心智模型(causal mental model)(见脚注 1),并警惕那些不符合因果模型的特征。这些特征可以提高回测的正确率,同时降低现实世界的正确率。下面是一个这样的例子,学习模型被用来从切片图像中识别皮肤癌变:
当皮肤科医生在检查他们认为可能是肿瘤的病变时,会拿出一把尺子(你可能在小学时使用的那种尺子)来精确测量病灶的大小。皮肤科医生倾向于只对病灶引起关注时才会这么做。因此,在这组切片图像中,如果图像中有尺子,算法更有可能将其判断为恶性肿瘤,因为尺子的存在增加了病灶是癌变的可能性。(来源)
在这种情况下,研究人员能够克服 “尺子表明癌症” 的这一错误关联,因为(a)他们的模型有足够的解释性,可以突出所学到的关联;(b)他们的领域知识提醒他们,这种关联是不合逻辑的。
3. 静默失败是可以容忍的吗?
在我们的公司 Opendoor,我们遇到了一个可怕的情况。我们构建了一个新的房产估价模型,提高了我们在回测和 A/B 测试中的正确率。我们将其大规模部署,这意味着我们开始使用这个模型预测的价格去购买房产,承担了巨大的资产负债表的风险。然后,模型就悄无声息地失败了。
我所说的 “静默失败” ,是指该模型在回测中仍然是正确的,但它在现实世界中的正确率已经降低了。模型出现静默失败有很多原因,因此,将希望寄托在良好的工程设计来防止所有这些失败的发生是不现实的。一种突出的静默失败模式是训练服务数据不匹配。继续使用我们的 OpenDoor 的例子,当我们更新网站表单上的提示时,可能会发生这种情况,因此,我们从卖房者那里收集的数据的性质在服务时间内会发生变化,但在我们的训练数据中并没有出现相应的变化。
由于静默失败无法完全避免,关键问题是:静默失败造成的损失在多大程度上可以容忍?静默失败所造成的损害与故障持续时间成正比,而持续时间与现实世界中可以观察到的结果恶化的速度成正比。如果你要预测未来的一天,你就必须等待一天。如果你要预测未来的某一年,你就必须等待一年。
考虑内容推荐算法,其中,现实世界的正确率通常是通过点击率来评估的。由于点击通常发生在推荐出现后的几秒钟内(至少对于搜索应用程序是这样),反馈循环非常短。静默失败可以被快速识别出来。
相反,再来考虑一种对贷款申请进行评分的算法。贷方可能要花费数月或数年的时间才能看到高于预期的违约率,并认识到违约是由于静默失败造成的。至此,贷方可能已经为不良贷款投入了巨额资金,而且很可能在法律上无法解决这些不良贷款问题。
实际用例
为了将所有这些结合起来,下面是我前面提到的用例(以及其他一些用例)是如何解决这三个问题的。下面这张表只是一个粗略的指南,而非严格的评估,我预计会有一些领域专家不会同意我的观点。
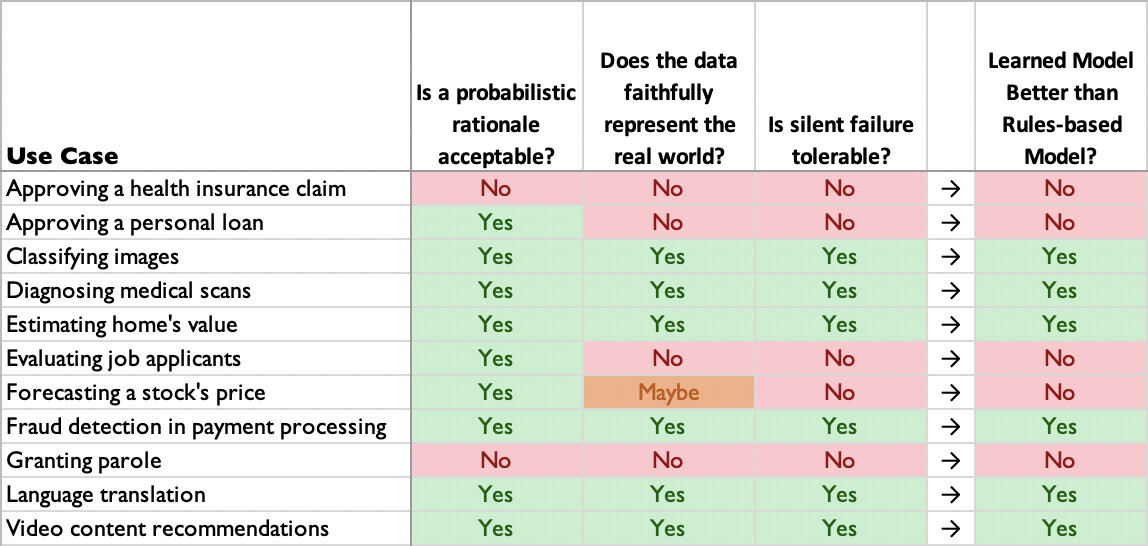
我很看好这一点:机器学习将会显著而积极地改变社会。基于这一信念,我作出了自己的职业决定。但,机器学习并不是包治百病的万灵药。与所有的软件项目一样,机器学习模型开发也会有很大的失败风险。我不希望机器学习重蹈协和飞机停飞的命运,协和飞机由于一些糟糕的早期设计决策永久停飞了。我希望本文提到的这些原则能够减少这种情况发生的可能性。
脚注 1: 在构建机器学习模型之前,需要一个因果心智模型的含义是很重要的。可自然引出的结论是,当人类专家拥有比随机更好的正确率和可解释的基本原理(explainable rationale)时,你应该构建一个学习模型。
含义 A:如果你要构建一个比专家更快、更一致和 / 或更便宜的模型,那么低风险建模选项是将专家可解释的基本原理编码到基于规则的模型中!只有在需要比专家正确率更高的情况下,才能去探索构建学习模型。
含义 B:如果专家很少,或者比随机好不了多少时,那么构建学习模型很有可能是徒劳的。如果专家不正确,他们甚至可能没有使用正确的因果输入。而且,如果你的特征集中没有正确的因果输入,即使是最复杂的学习模型,也注定将会失败。像这样的情况包括预测股价和地缘政治事件:必要的因果输入是什么,就连专家也没有达成一致的意见。
作者介绍:
Sam Stone,Ansaro 博客和 Semi-Random Thoughts 的编辑。
原文链接:

前InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论