

背景
随着整个中国互联网下半场的到来,用户红利所剩无几,原来粗放式的发展模式已经行不通,企业的发展越来越趋向于精耕细作。美团的价值观提倡以客户为中心,面对海量的用户行为数据,如何利用好这些数据,并通过技术手段发挥出数据的价值,提高用户的使用体验,是我们技术团队未来工作的重点。
大众点评在精细化运营层面进行了很多深度的思考,我们根据用户在 App 内的操作行为的频次和周期等数据,给用户划分了不同的生命周期,并且针对用户所处生命周期,制定了不同的运营策略,比如针对成长期的用户,主要运营方向是让其了解平台的核心功能,提高认知,比如写点评、分享、收藏等。同时,我们还需要为新激活用户提供即时激励,这对时效性的要求很高,从用户的行为发生到激励的下发,需要在毫秒级别完成,才能有效提升新用户的留存率。
所以,针对这些精细化的运营场景,我们需要能够实时感知用户的行为,构建用户的实时画像。此外,面对大众点评超大数据流量的冲击,我们还要保证时效性和稳定性,这对系统也提出了非常高的要求。在这样的背景下,我们搭建了一套用户行为系统(User Action System,以下简称 UAS)。
面临的问题
如何实时加工处理海量的用户行为数据,我们面临以下几个问题:
上报不规范 :点评平台业务繁多,用户在业务上产生的行为分散在四处,格式不统一,有些行为消息是基于自研消息中间件 Mafka/Swallow,有些行为消息是基于流量打点的 Kafka 消息,还有一些行为没有对应的业务消息,收集处理工作是一个难点。
上报时效性差 :目前大部分行为,我们通过后台业务消息方式进行收集,但是部分行为我们通过公司统一的流量打点体系进行收集,但是流量打点收集在一些场景下,无法满足我们的时效性要求,如何保证收集处理的时效性,我们需要格外关注。
查询多样化 :收集好行为数据之后,各个业务对用户行为的查询存在差异化,比如对行为次数的统计,不同业务有自己的统计逻辑。无法满足现有业务系统的查询需求,如何让系统既统一又灵活?这对我们的业务架构能力提出了新要求。
针对问题模型,方案思考
格式统一
面对繁杂的格式,我们如何进行统一?在这里我们参考了 5W1H 模型,将用户的行为抽象为以下几大要素:
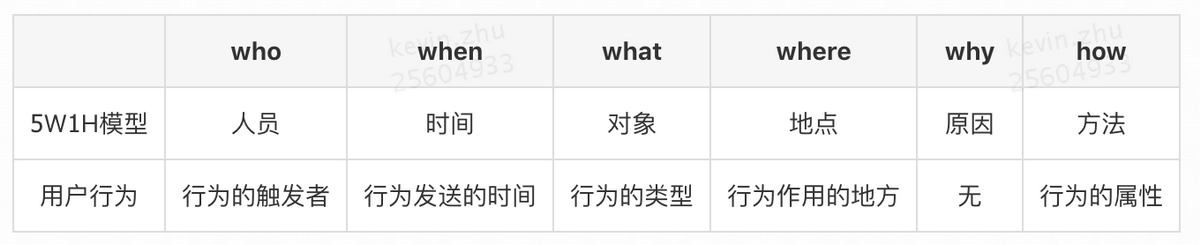
其中行为作用的地方,这里一般都是作用对象的 ID,比如商户 ID,评论 ID 等等。
行为的属性,代表的是行为发生的一些额外属性,比如浏览商户的商户品类、签到商家的城市等。
上报统一
对于用户行为的上报,之前的状态基本只有基于流量打点的上报,虽然上报的格式较为标准化,但是存在上报延时,数据丢失的情况,不能作为主要的上报渠道,因此我们自建了其他的上报渠道,通过维护一个通用的 MAPI 上报通道,直接从客户端通过专有的长连接通道进行上报,保证数据的时效性,上报后的数据处理之后,进行了标准化,再以消息的形式传播出去,并且按照一定的维度,进行了 TOPIC 的拆分。目前我们是两个上报通道在不同场景使用,对外是无感知的。
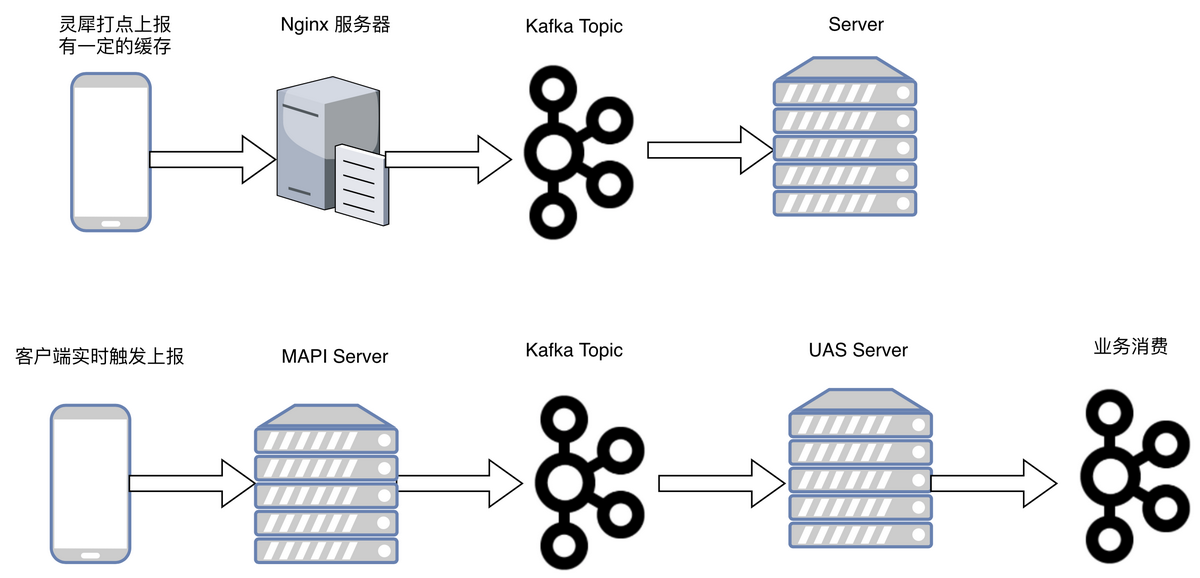
服务统一
不同场景下,对用户行为处理的数据规模要求,时效性要求也是不一样的,比如有些场景需要在用户行为上报之后,立刻做相关的查询,因此写入和查询的性能要求很高,有些场景下,只需要进行行为的写入,就可以采取异步的方式写入,针对这样不同的场景,我们有不同的解决方案,但是我们统一对外提供的还是 UAS 服务。
架构统一
从数据的收集上报,到处理分发,到业务加工,到持久化,UAS 系统架构需要做到有机的统一,既要能满足日益增长的数据需求,同时也要能够给业务充分的灵活性,起到数据中台的作用,方便各个业务基于现有的架构上,进行快速灵活的开发,满足高速发展的业务。
系统整体架构
针对这样一些想法,开始搭建我们的 UAS 系统,下图是 UAS 系统目前的整体架构:
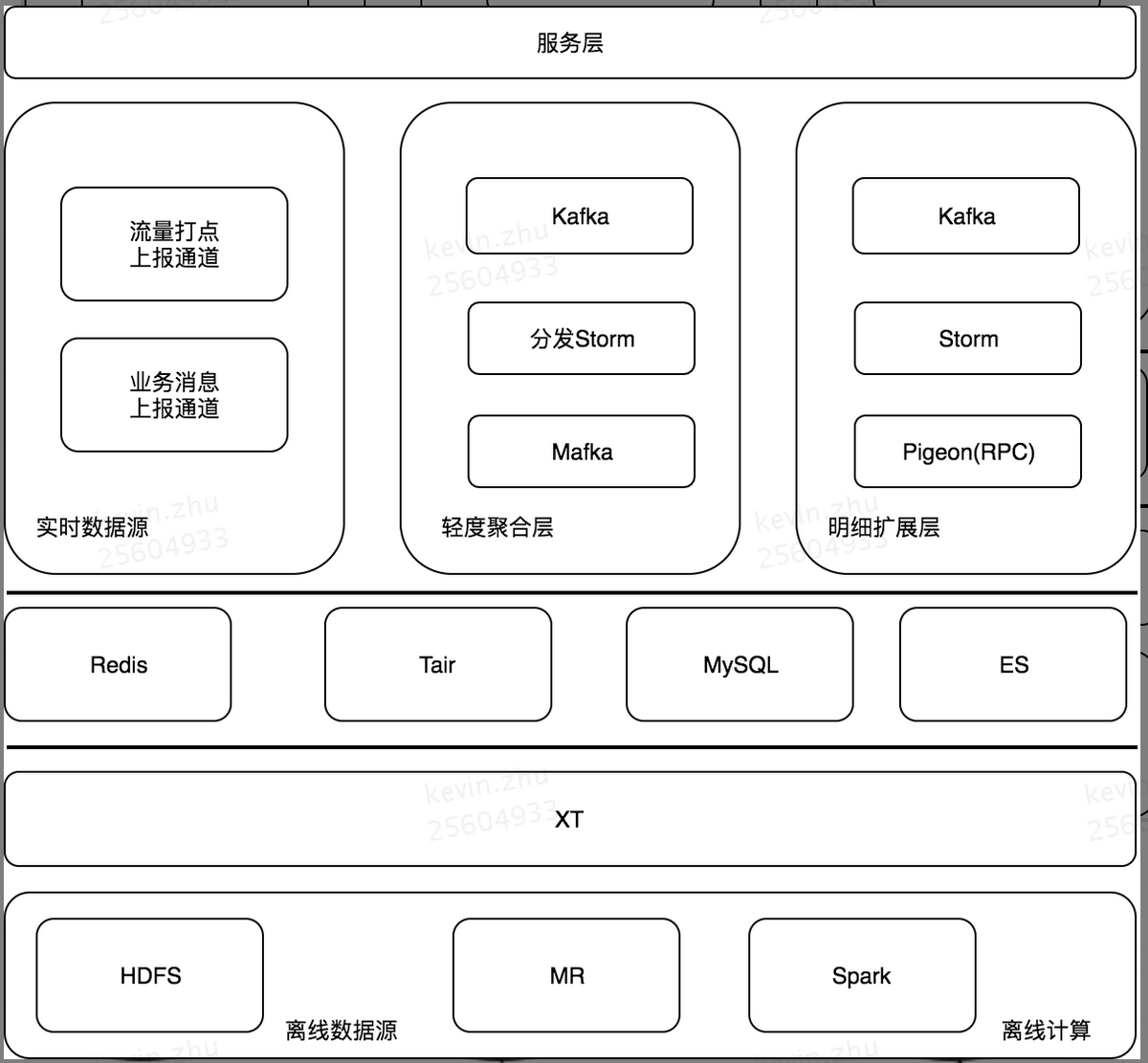
数据源简介
我们处理的数据源分为实时数据源和离线数据源:
实时数据源主要分两块,一块是基于客户端打点上报,另外一块是我们的后台消息,这两部分是基于公司的消息中间件 Mafka 和开源消息中间件 Kafka,以消息的形式上报上来,方便我们后续的处理,MQ 的方式能够让系统更好的解耦,并且具备更高的吞吐量,还可以指定消费的起始时间点,做到消息的回溯。历史数据的来源主要是我们的 Hive 和 HDFS,可以方便的做到大数据量的存储和并行计算。
离线计算简介
在离线处理这块,主要包含了 MR 模块和 Spark 模块,我们的一些 ETL 操作,就是基于 MR 模块的,一些用户行为数据的深度分析,会基于 Spark 去做,其中我们还有一个 XT 平台,是美团点评内部基于 Hive 搭建的 ETL 平台,它主要用来开发数据处理任务和数据传输任务,并且可以配置相关的任务调度信息。
实时计算简介
对于用户行为的实时数据处理,我们使用的是 Storm 实时大数据处理框架,Storm 中的 Spout 可以方便的对接我们的实时消息队列,在 Bolt 中处理我们的业务逻辑,通过流的形式,可以方便的做到业务数据的分流、处理、汇聚,并且保持它的时效性。而且 Storm 也有比较好的心跳检测机制,在 Worker 挂了之后,可以做到自动重启,保证任务不挂,同时 Storm 的 Acker 机制,可以保持我们实时处理的可靠性。
接下来,我们按照用户行为数据的处理和存储来详细介绍我们的系统。
数据的处理
离线处理
离线数据的处理,主要依赖的是我们的数据开发同学,在构建用户行为的数据仓库时,我们会遵循一套美团点评的数据仓库分层体系。
同时我们会出一些比较通用的数据,方便线上用户使用,比如我们会根据用户的行为,发放勋章奖励,其中一个勋章的发放条件是用户过去 30 天的浏览商户数量,我们不会直接出一个 30 天的聚合数据,而是以天为周期,做一次聚合,然后再把 30 天的数据聚合,这样比较通用灵活一些,上层应用可以按照自己的业务需求,进行一些其他时间段的聚合。
在数据的导入中,我们也有不同的策略:
比如用户的行为路径分析中,我们在 Hive 中计算好的结果,数据量是非常庞大的,但是 Hive 本身的设计无法满足我们的查询时效性要求,为了后台系统有比较好的体验,我们会把数据导入到 ES 中,这里我们无需全量导入,只要抽样导入即可,这样在满足我们的查询要求的同时也能提高我们的查询效率。
在导入到一些其他存储介质中,传输的效率有时候会成为我们的瓶颈,比如我们导入到 Cellar 中,数据量大,写入效率也不高,针对这种情况,我们会采用增量导入的方式,每次导入的数据都是有发生变化的,这样我们的导入数据量会减少,从而减小我们的传输耗时。
实时处理
实时处理这块,我们构建了基于点评全网的流量网关,所有用户产生的行为数据,都会通过实时上报通道进行上报,并且会在我们的网关中流转,我们在这里对行为数据,做一些加工。
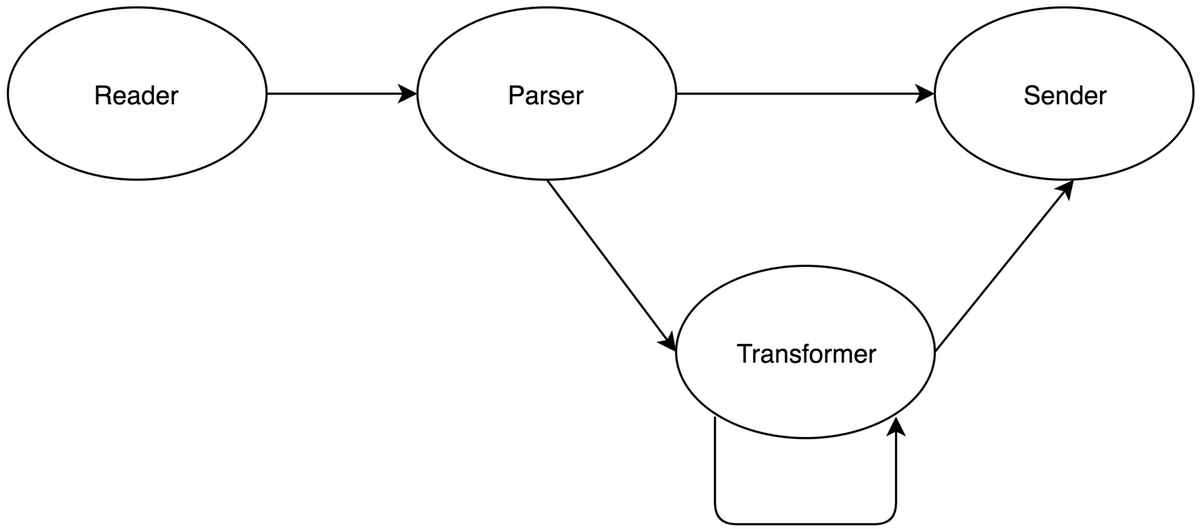
实时处理
Reader
我们目前使用的是 Storm 的 Spout 组件对接我们的实时消息,基于抽象的接口,未来可以扩展更多的数据来源,比如数据库、文件系统等。
Parser
Parser 是我们的解析模块,主要具备以下功能:
我们会对字段做一些兼容,不同版本的打点数据可能会有差异。
JSON 串的处理,对于多层的 JSON 串进行处理,使得后续可以正常解析。
时间解析,对于不同格式的的上报时间进行兼容统一。
Transformer
Transformer 是我们的转换模块,它是一种更加高级的处理过程,能够提供给业务进行灵活的行为属性扩展:
比如需要根据商户 ID 转换出商户的星级、品类等其他信息,我们可以在我们的明细扩展层配置一个 Transformer。
或者业务有自己的转换规则,比如他需要把一些字段进行合并、拆分、转换,都可以通过一个 Transformer 模块,解决这个问题。
Sender
Sender 是我们的发送模块,将处理好的数据,按照不同的业务数据流,进行转发,一般我们是发送到消息队列中,Sender 模块,可以指定发送的格式、字段名称等。
目前我们的实时处理,基本上已经做到可视化的配置,之前需要几人日才能做到的用户行为数据分发和处理,现在从配置到验证上线只需要几分钟左右。
近实时处理
在近线计算中,我们会把经过流量网关的数据,通过 Kafka2Hive 的流程,写入到我们的 Hive 中,整个过程的时延不超过 15 分钟,我们的算法同学,可以利用这样一些近实时的数据,再结合其他的海量数据,进行整体的加工、存储,主要针对的是一些时效性要求不高的场景。
通过上面三套处理方法,离线、实时、近实时,我们可以很好的满足业务不同的时效性需求。
数据的存储
经过实时处理之后,基本上已经是我们认为的标准化数据,我们会对这些数据进行明细存储和聚合存储。
明细存储
明细的存储,是为了保证我们的数据存储,能够满足业务的查询需求,这些明细数据,主要是用户的一些核心操作行为,比如分享、浏览、点击、签到等,这些数据我们会按照一定的粒度拆分,存储在不同的搜索集群中,并且有一定的过期机制。
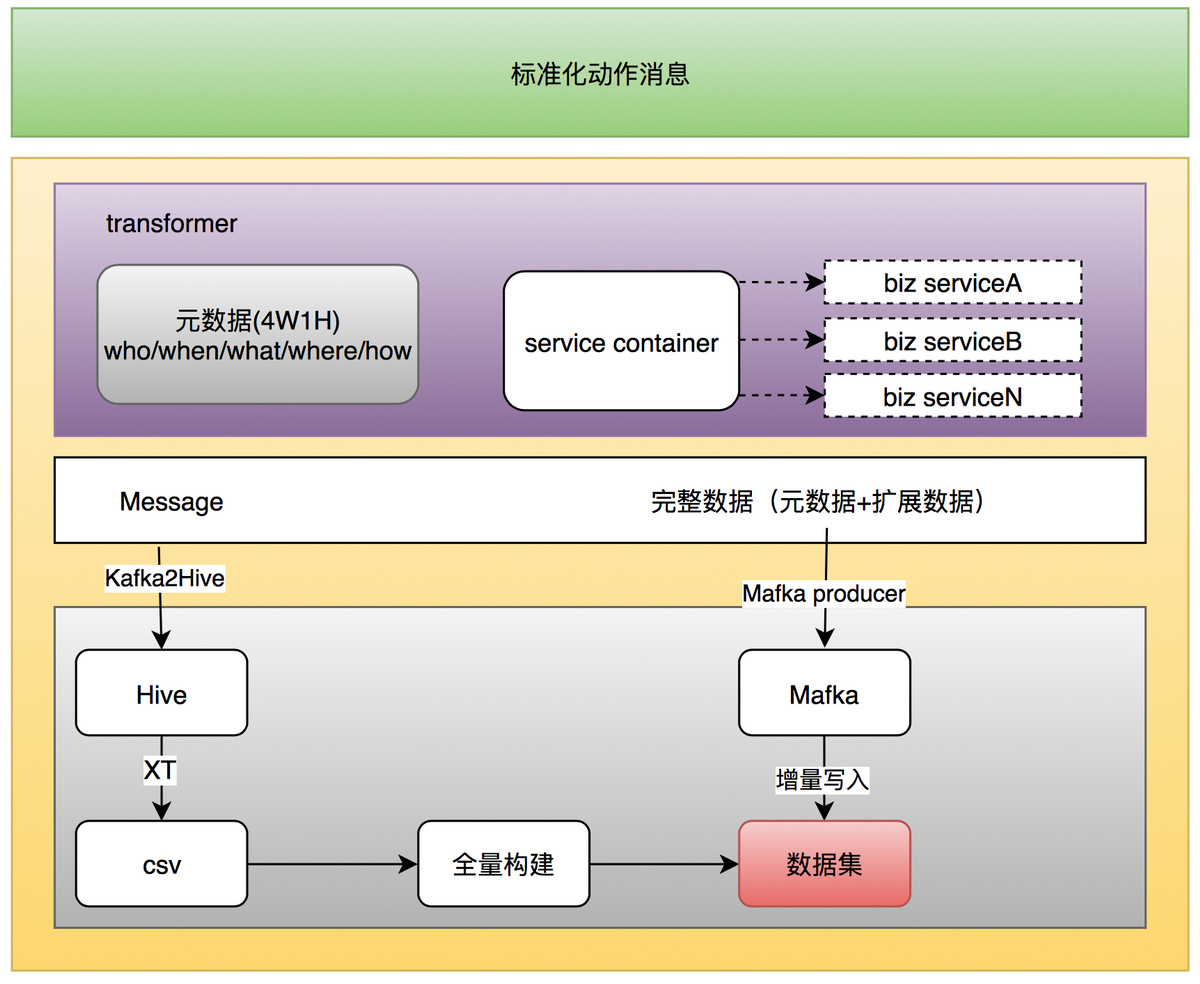
搜索
上图是我们的处理方式:
通过 Transformer,业务方可以通过自己的服务,对数据的维度进行扩展,从而 Sender 发出的 Message 就是满足业务需求的数据。
然后在 Kafka2Hive 这一步,会去更新对应的 Hive 表结构,支持新的扩展数据字段,同时在 XT 作业中,可以通过表的关联,把新扩展的字段进行补齐。
重跑我们的历史之后,我们的全量数据就是已经扩展好的字段。同时,我们的实时数据的写入,也是扩展之后的字段,至此完成了字段的扩展。
NoSQL 存储
通过明细数据的存储,我们可以解决大部分问题。虽然搜索支持的查询方式比较灵活,但是某些情况下,查询效率会较慢,平均响应时间在 20ms 左右,对一些高性能的场景,或者一些基础的用户行为画像,这个响应时间显然是偏高的。因此我们引入了 NoSQL 的存储,使用公司的存储中间件 Squirrel 和 Cellar,其中 Cellar 是基于淘宝开源的 Tair 进行开发的,而 Squirrel 是基于 Redis-cluster 进行开发的,两者的差异就不在此赘述,简单讲一下我们的使用场景:
对于冷热比较分明,单个数据不是很大(小于 20KB,过大会影响查询效率),并且 value 不是复杂的,我们会使用 Cellar,比如一些低频次的用户行为数据。
在大并发下,对于延迟要求极为敏感,我们会使用 Redis。
对于一些复杂的数据结构,我们会使用到 Redis,比如会用到 Redis 封装好的 HyperLogLog 算法,进行数据的统计处理。
系统特性
灵活性
构建系统的灵活性,可以从以下几个方面入手:
对用户的行为数据,可以通过 Transformer 组件进行数据扩展,从而满足业务的需求,业务只需要开发一个扩展接口即可。
第二个方面就是查询,我们支持业务方以服务注册的方式,去编写自己的查询逻辑,或者以插件的形式,托管在 UAS 平台,去实现自己负责的业务逻辑,比如同样一个浏览商户行为,有些业务的逻辑是需要看某批用户最近 7 天看了多少家 3 星商户,并且按照 shopID 去重,有些业务逻辑可能是需要看某批用户最近 7 天浏览了多少个品类的商户。因此这些业务复杂的逻辑可以直接托管在我们这里,对外的接口吐出基本是一致的,做到服务的统一。
我们系统目前从实时分发/计算/统计/存储/服务提供,是一套比较完备的系统,在不同的处理阶段,都可以有不同的组件/技术选型,根据业务的需求,我们可以做到灵活的组合、搭配。
低延时
对于一些跨周期非常长,存储非常大的数据,我们采用了 Lambda 架构,既保证了数据的完备性又做到了数据的时效性。其中 Batch Layer 为批处理层,会有固定的计算视图,对历史数据进行预计算,生成离线结果;Speed Layer 为实时计算层,对实时数据进行计算,生成增量的结果,最终 Server Layer 合并两个视图的数据集,从而来提供服务。
可用性
数据可用性
前面提到了我们采用 Lambda 架构处理一些数据,但是离线数据有时候会因为上游的一些原因,处理不稳定,导致产出延迟,这个时候为了保证数据的准确性,我们在 Speed Layer 会多保留两天的数据 ,保证覆盖到全量数据。如图所示:
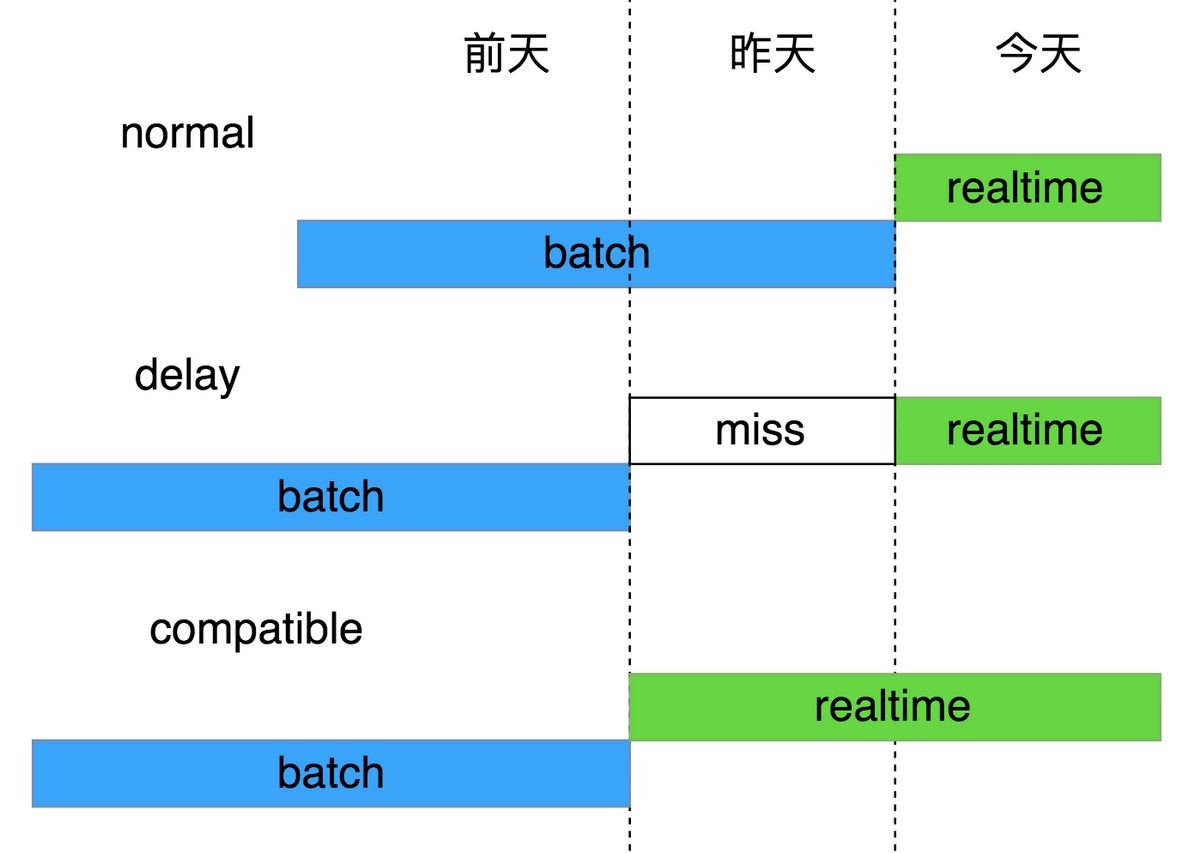
服务的可用性
在服务的可用性方面,我们对接入的服务进行了鉴权,保证服务的安全可靠,部分核心行为,我们做了物理上的隔离,保证行为数据之间不会相互影响,同时接入了公司内部基于 Docker 的容器管理和可伸缩平台 HULK,能做到自动扩容。对于数据使用有严格权限审计,并且做了相关数据脱敏工作。
监控
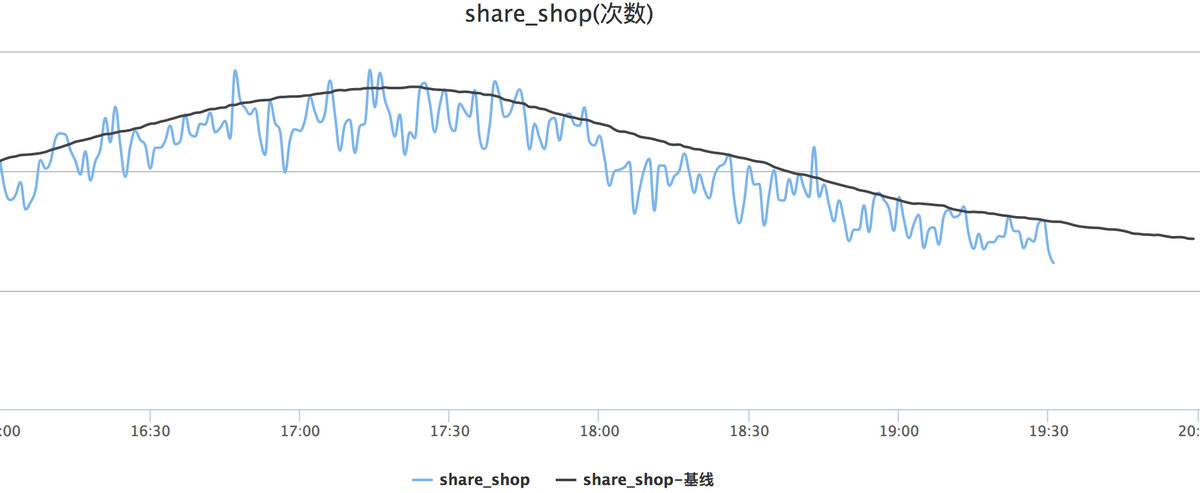
从用户行为数据的产生,到收集分发,到最后的处理,我们都做到了相关的监控,比如因为我们的代码改动,发生处理时长变长,我们可以立马收到相关的报警,检查是不是代码出问题了。或者监控到的行为产生次数和历史基线比,发生较大变化,我们也会去追踪定位问题,甚至可以早于业务先发现相关问题。下图是分享商户行为的一个监控:
结语
用户行为系统搭建之后,目前:
处理的上报数据量日均在 45+亿。
核心行为的上报延迟从秒级降低到毫秒级。
收录用户行为数十项,提供用户行为实时流。
提供多维度下的实时服务,日均调用量在 15 亿左右,平均响应时间在 3ms,99 线在 10ms。
目前系统承载的业务还在不断增长中,相比以前的 T+1 服务延时,大大提升了用户体验。我们希望构建用户行为的中台系统,通过我们已经抽象出的基础能力,解决业务 80%的问题,业务可以通过插件或者接口的形式,在我们的中台上解决自己个性化的问题。
未来展望
目前我们的实时计算视图,比较简单,做的是相对比较通用的聚合计算,但是业务的聚合规则可能是比较复杂且多变的,不一定是直接累加,未来我们希望在聚合计算这块,也能直接通过配置的方式,得到业务自定义的聚合数据,快速满足线上业务需求。
同时,用户的实时行为会流经我们的网关,我们对用户行为进行一些特征处理之后,结合用户过去的一些画像数据,进行用户意图的猜测,这种猜测是可以更加贴近业务的。
作者简介
朱凯,资深工程师,2014 年加入大众点评,先后从事过账号端/商家端的开发,有着丰富的后台开发架构经验,同时对实时数据处理领域方法有较深入的理解,目前在点评平台负责运营业务相关的研发工作,构建精细化运营的底层数据驱动能力,着力提升用户运营效率。重点打造点评平台数据中台产品——灯塔。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论