
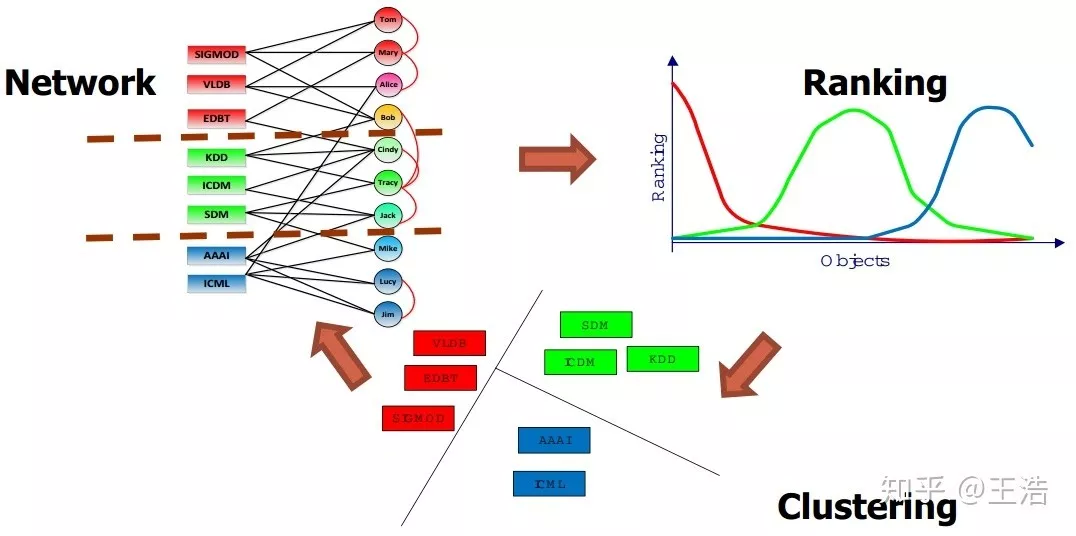
导读:网络图模型综述,网络图模型知识点,看这一篇就够啦~主要结合韩家炜及崔鹏的相关工作以及我个人理解阐述网络图模型的各方向知识点,用通俗的话把每个知识点的关键写出来,帮大家高效理解这个领域。另附个人 Blog:
https://chmx0929.gitbook.io/machine-learning/
主要内容包括:
概述
Classic Graph Algorithm
Network Embedding
业界应用
1. 概述
1.1 网络图相关概念
这里介绍了 13 组相关基础概念,非常繁杂劝退,建议大家先跳到后面看 Classic Graph Algorithm,对基础概念不清晰并不影响看算法~
Network/Graph:G=(V,E),其中 V:vertices/nodes;E:edges/links。
图 ( Graph ) vs. 网络 ( Network ):Graph 是数学领域的表示,是一种数据结构。Network 是现实生活中的表示,是指的数据。
度矩阵 ( Degree matrix ) & 邻接矩阵 ( Adjacency matrix ) & 拉普拉斯矩阵 ( Laplacian matrix ):
度矩阵即节点度 ( 边 ) 的数量,邻接矩阵即节点和哪些节点相连,拉普拉斯即度矩阵-邻接矩阵。

无向图/网络 vs 有向图/网络 以及他们的度:
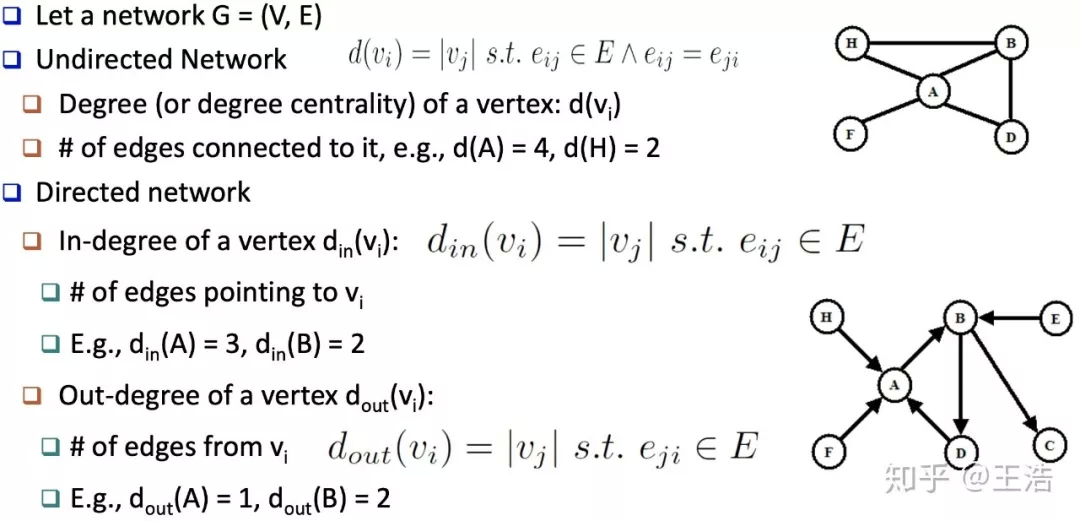
不同类型网络及他们的度:
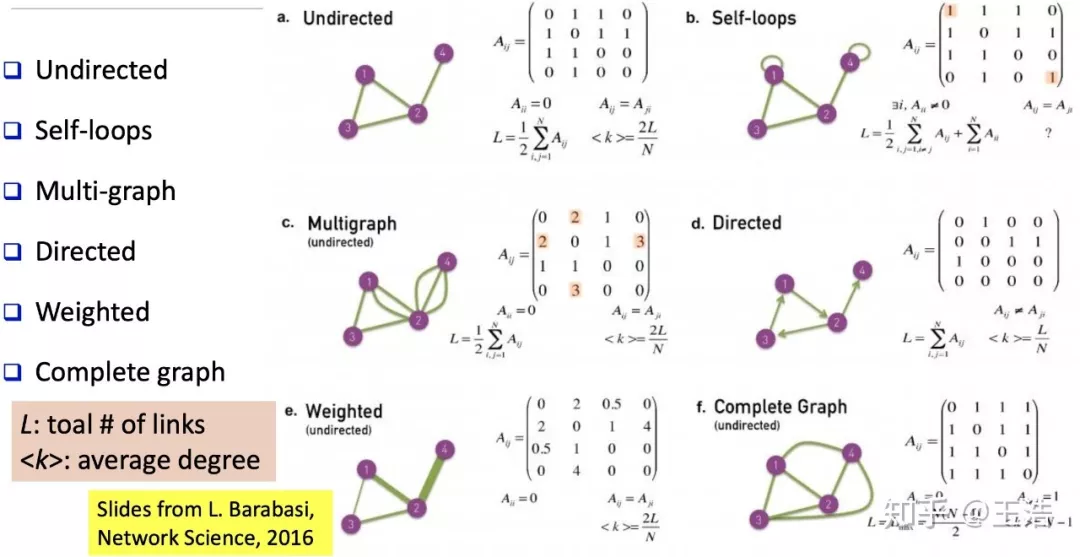
基础网络结构及其性质:
度 ( Degree ) 的分布及路径 ( Path ):

路径 ( Path ):

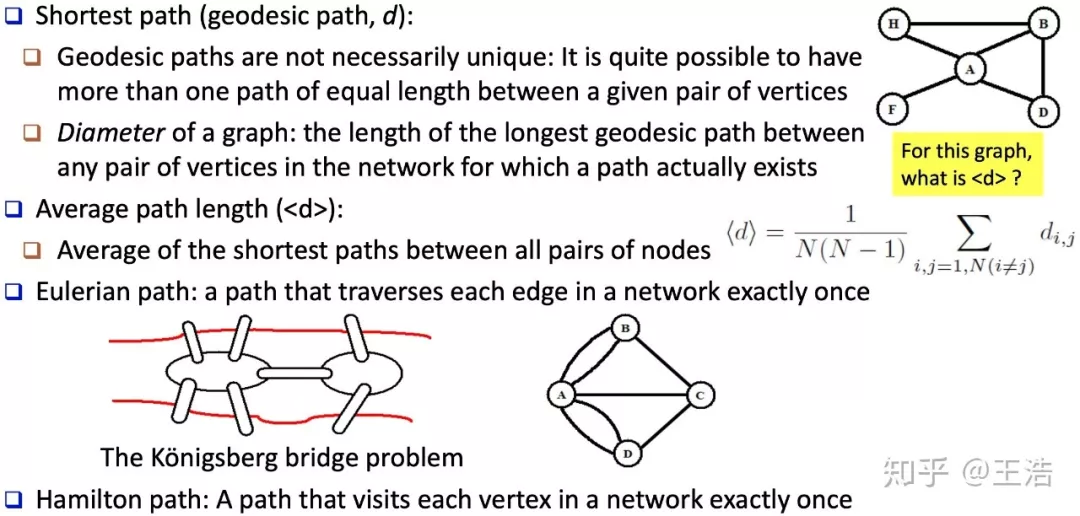
网络的半径 ( Radius ) 与直径 ( Diameter ):

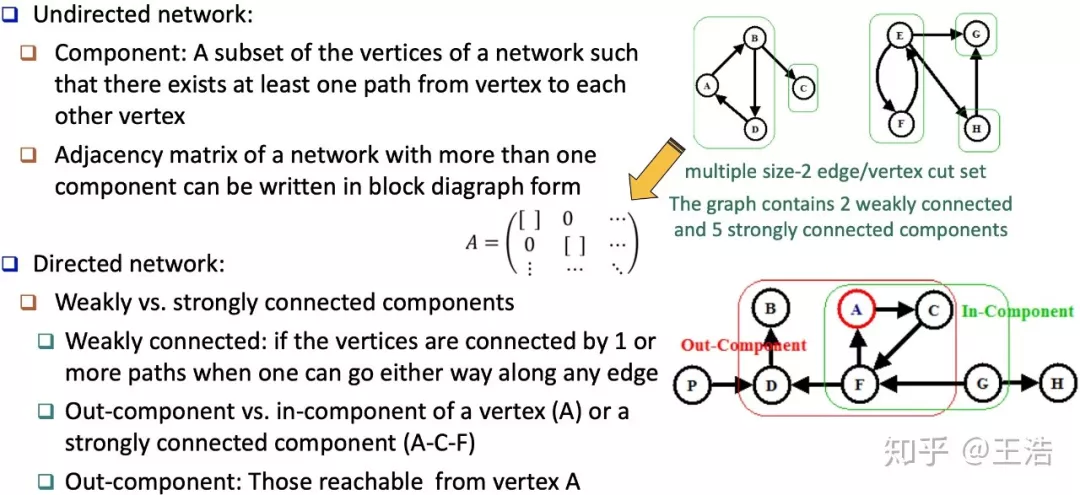
无向网络 ( Undirected Network ) 与有向网络 ( Directed Network ) 中的元素:
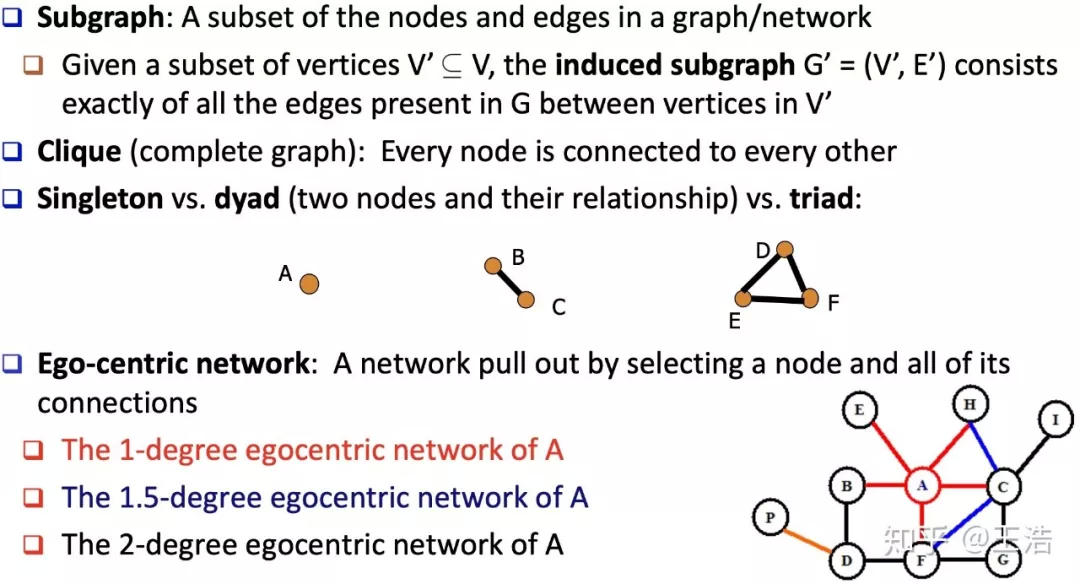
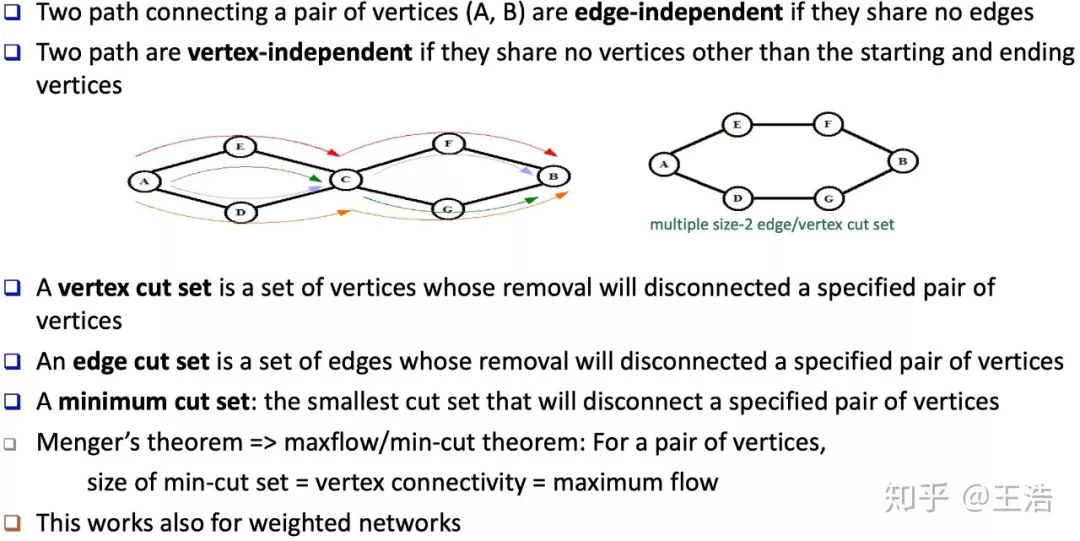
独立路径 ( Independent Path ) & 连通性 ( Connectivity ) & 切割集 ( Cut Set )
聚类系数 ( Clustering Coefficient ):

同质网络 ( Homogeneous Network ) vs 异构网络 ( Heterogeneous Network ):


1.2 网络图模型应用
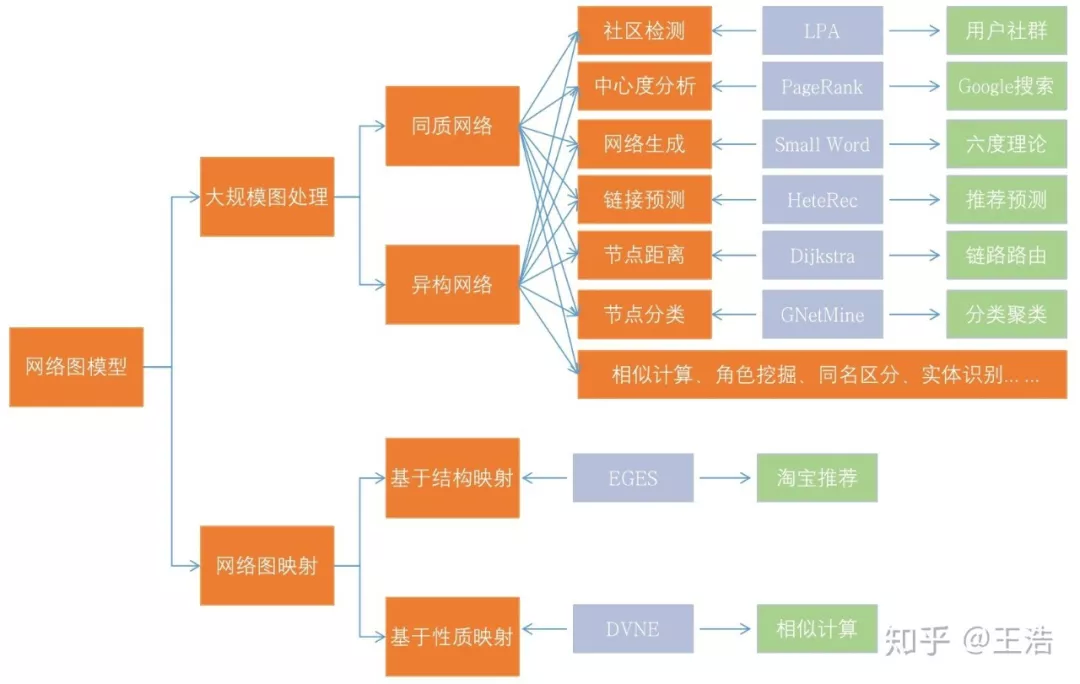
网络图模型有很多应用场景,所以是工业界和学术界的重要研究方向之一。因为网络图模型契合现实生活,技术成熟后效果肯定会好。比如 Dijkstra 最短路径算法,就是路由器和各种地图导航等的基础性算法;再比如 PageRank 作为前期 Google 网页搜索推荐的核心,是 Google 庞大公司的基石;像这样的成功的例子有很多,当然还有不少正在探究的方向,比如链接预测就是天然贴合互联网搜素推荐场景的方向;现实生活中有一万个叫张伟的,到底哪个才是我们熟知的张益达、snake…,这就是网络图中的同名区分;当然还有多个方向可以解决相同现实问题的,比如军事网络中通过角色挖掘,找到谁才是将军,和用中心度分析找到网络中最重要成员…现实生活中有各式各样的应用场景,只有你想不到,没有做不到。
2. Classic Graph Algorithm
恭喜你看完了乏味的基础知识部分,下面我们来看一些经典图算法,这里分为路径与关联、社区检测、中心度分析、网络生成、最短路径、聚类与排序、分类与预测这几个主题介绍。后续我再想到相关主题会继续补充。
2.1 路径与关联
SimRank:如果两个节点被相似或相同的节点关联,则认为这两个主体相似:
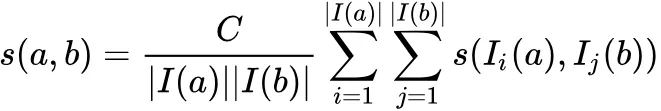
Personalized PageRank ( P-Pagerank ):P-Pagerank 的分数 x 被定义为:x=αPx+(1-α)b,其中 P 为网络 G 的转移矩阵,b 是一个称为 Personalized vector 随机向量, 是隐形传输常数。
Random Walk:通过元路径 ( Meta-path ) P 从节点 x 随机游走到达 y 的概率:

Pairwise Random Walk:根据元路径 ( Meta-path ) (p1,p2),从 (x,y) 两点随机游走,到达共同节点 z 的概率:
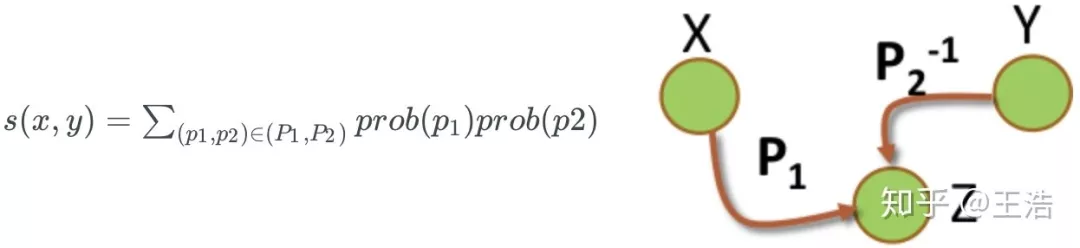
PathSim:简单回顾一下 Meta-path,两个主体在 Meta-level 的路径,描述两主体的关系比如作者-论文-作者 ( 两个人共写一篇论文,这是网络中两作者间一种联系 ),当然一个网络中有多种 Meta-path,比如作者-论文-会议-论文-作者…
PathSim 的计算公式:
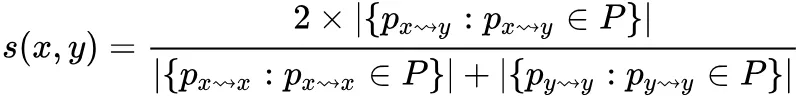
比如下图例子:
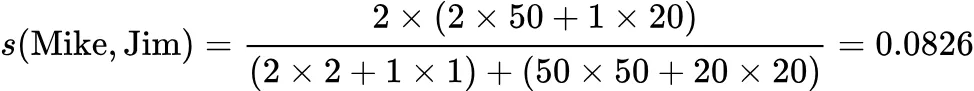
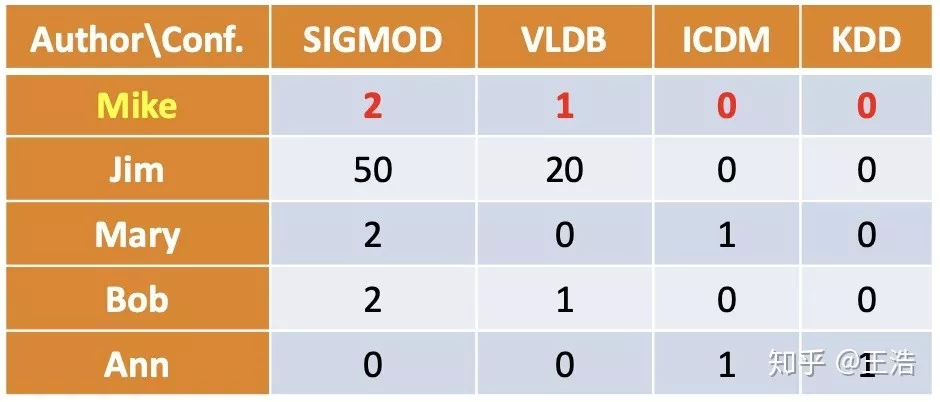
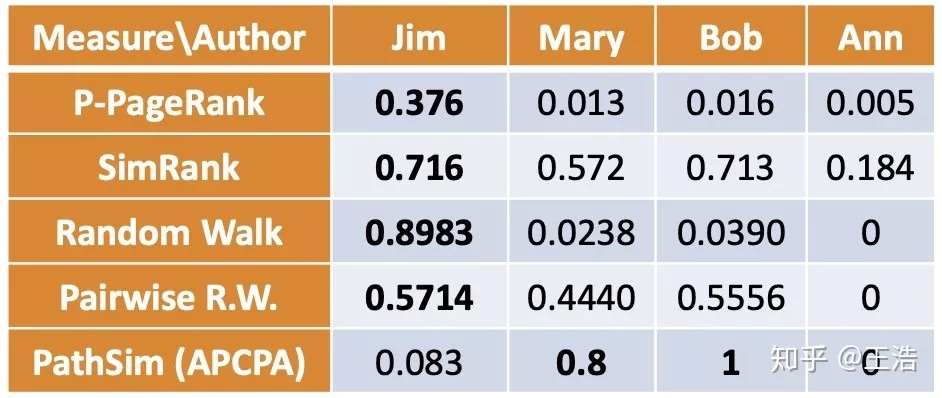
2.2 社区检测
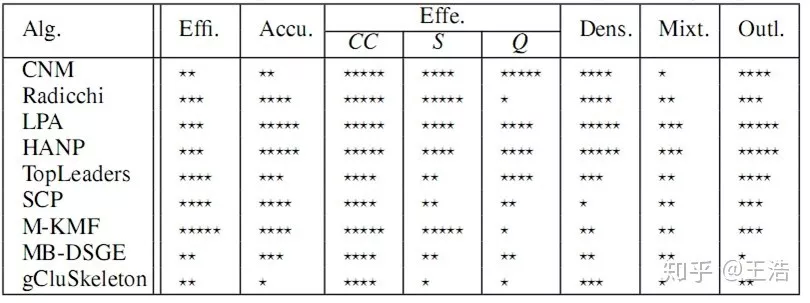
社区检测与搜索是图算法重要的一个课题,下图为几个评价指标,从左至右依次为:1. 计算时间复杂度;2. 精确度 ( 与实际标签比较、计算标准化互信息 );3. 有效性 ( 聚类系数、模块度、强度 );4. 密度敏感性;5. 混合社区敏感点;6. 离群点检测。可以看到 LPA ( 标签传播 ) 和 HANP ( 改进后标签传播 ) 效果较好。
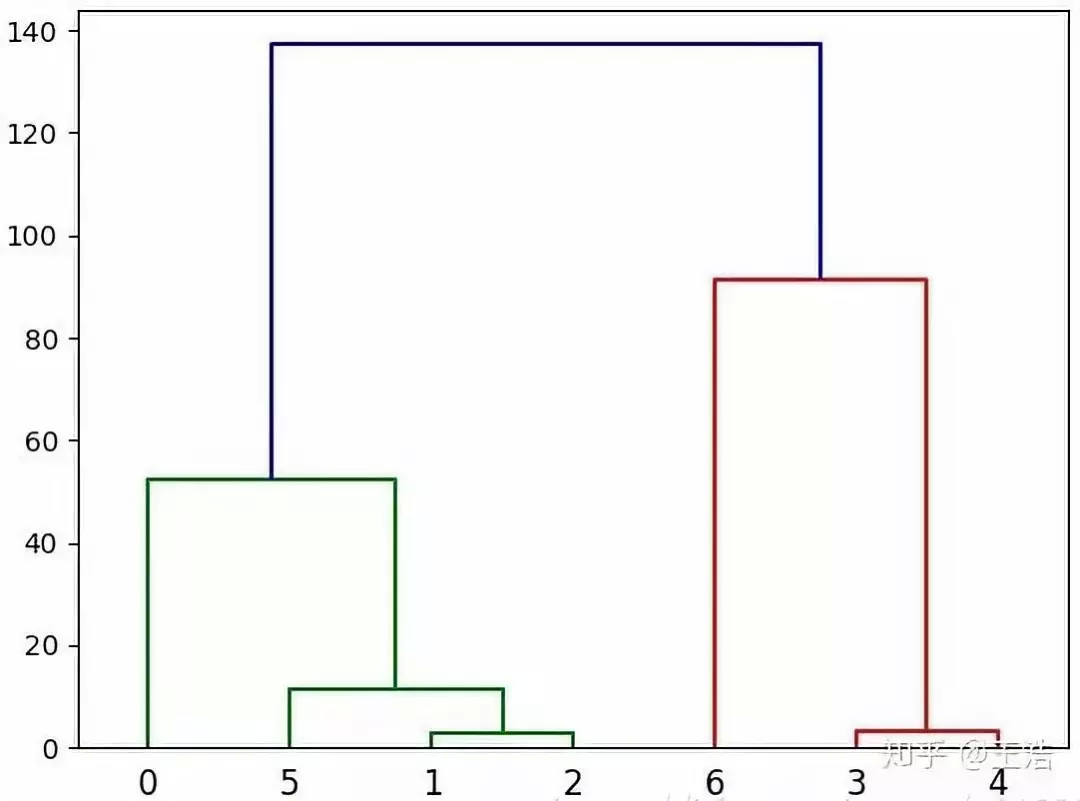
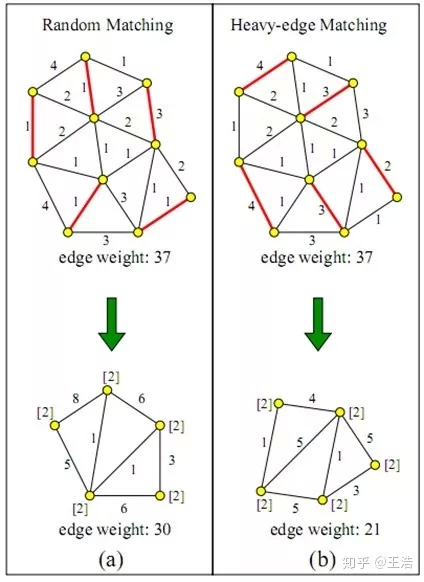
层次化聚类:给以网络 ( 邻接矩阵 ),根据距离进行切分,步骤如下:
① 由网络结构计算距离矩阵
② 距离确定节点相似度 ( 相邻即 1,隔最少 n 个相连即 n+1 )
③ 根据相似度从强到弱递归合并节点
④ 根据实际需求横切树状图 ( 如下图要分 3 类,可在 80 切一刀 )
谱聚类:将图切分成相互没有连接的 k 个子图:,要求 且 ,则优化目标:
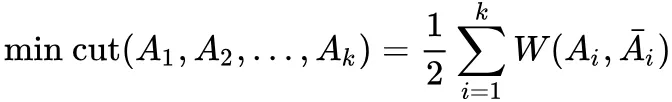
即将划分问题转化为求解拉普拉斯矩阵的 k 个最小特征值问题。步骤如下:
① 构建拉普拉斯矩阵:L=D-W ( D:度矩阵,W:邻接矩阵 )
② 标准化:
③ 求最小的 n 个特征值对应的特征向量 ( 降维 )
④ 标准化后再用常规方法 ( k-means 等)聚为 k 个类
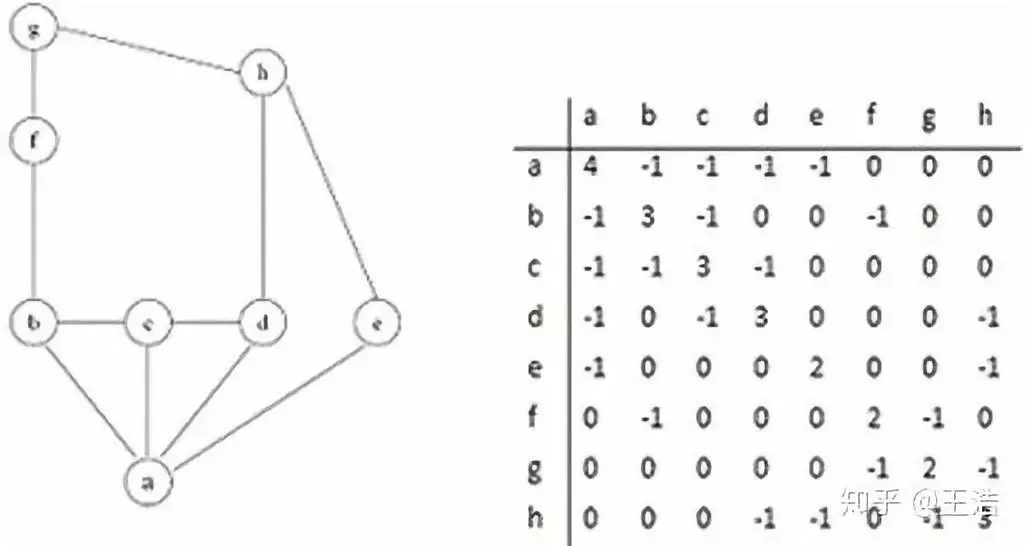
图划分:划分为近似相等的分区,同时边切边最小。( 明尼苏达大学的 METIS 是最权威的图划分工具 )
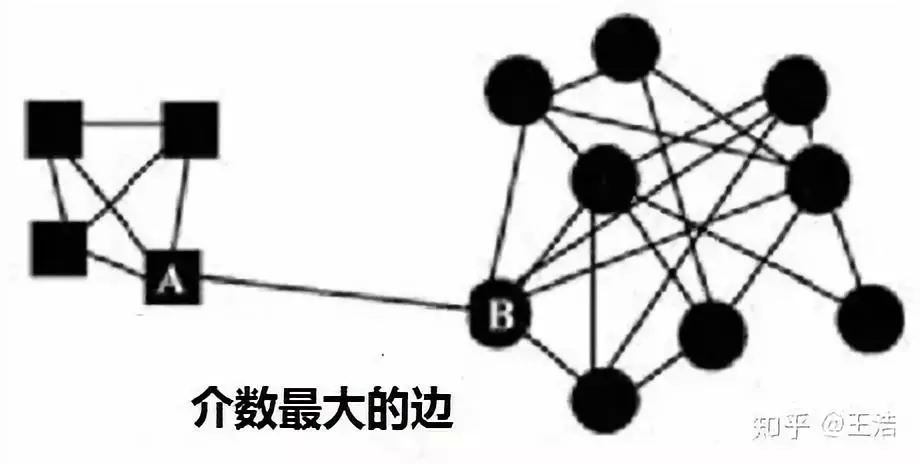
GN 算法,思想是:1. 定义边介数 ( betweenness ) 指标:衡量的是网络里一个边占据其它节点间捷径的程度;2. 具有高边介数的边代表了社区的边界。
边介数最常见的定义:图中通过该边的所有最短路径数量。如下图 A 和 B 之间的边即当前最可能切除的。步骤如下:
① 找到网络中具有最大边介数的边
② 删除该边
③ 重复 ① 和 ②,直到所有边被移除或数量已满足要求 k 类
模块度优化算法,思想是:1. 定义模块度 ( Modularity ) 指标:衡量一个社区的划分好坏;2. 以模块度为目标进行优化;例如在层次化聚类中使用贪婪算法。一种模块度的定义:社区内的边占比 - 社区的边占比平方。假设网络分为 k 个社区,那么定义一个 k x k 的对称矩阵 e,它的元素 eij 表示社区 i 和社区 j 之间的边的数量占比,ai 表示连接社区 i 的边的总数占比:
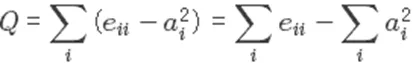

标签传播算法,思想是:一个节点应该与多数邻居在同一社区内。特点:适合半监督和无监督、效率很高适合大规模、存在震荡->采取异步更新、结果可能不稳定。步骤如下:
① 给每个节点初始化一个标签
② 在网络中传播标签
③ 选择邻居的标签中数量最多的进行更新 ( 若有相同数量标签时,选择具有最高 ID 的标签 )
④ 重复步骤 ② 和 ③,直到收敛或满足迭代次数
随机游走,思想是:1. 从节点出发随机游走,停留在社区内的概率高于到达社区外的。2. 重复随机游走,强化并逐渐显现社区结构。步骤如下:
① 建立邻接矩阵 ( 含自环 )
② 标准化转移概率矩阵
③ Expansion 操作,对矩阵计算 e 次幂方
④ Inflation 操作,对矩阵元素计算 r 次幂方并标准化 ( 这一步将强化紧密的点,弱化松散的点 )
⑤ 重复 ③ 和 ④ 直到稳定
⑥ 对结果矩阵进行常规聚类

K-Truss:给以图 G,K-Truss 定义为 : 每个在最大的子图 H 中的边至少在 ( k-2 ) 个存在于 H 三角形中,如下:
K-Truss 检索社区步骤如下:
① 给定 k,找到至少对应 ( k-2 )个三角形的边
② 三角形们共享的公共边构成社区边链接
③ 最大化经过前两步找到的子图
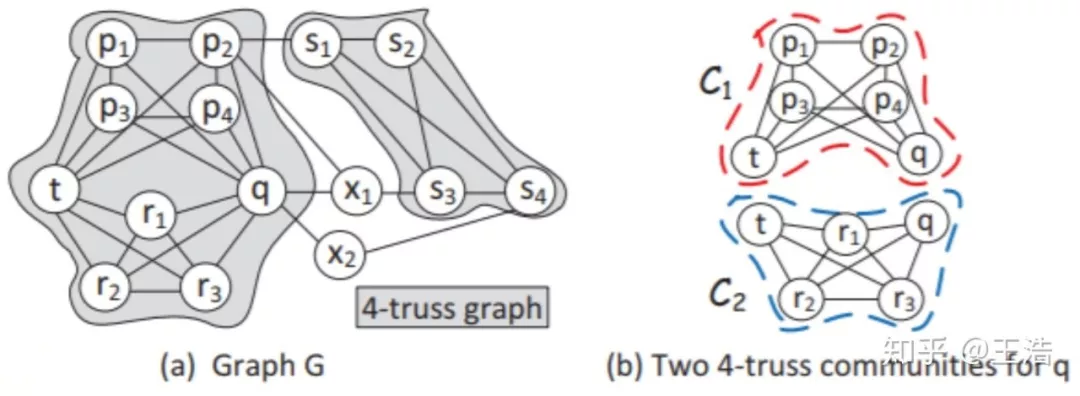
其他:
派系过滤算法 ( clique percolation algorithm ) - 社区的网络
领导力扩张 ( Leadership expansion ) - 类似于 kmeans
基于聚类系数的方法 ( Maximal K-Mutual friends ) - 目标函数优化
HANP ( Hop attenuation & node preference ) - LPA 增加节点传播能力
SLPA ( Speak-Listen Propagation Algorithm ) - 记录历史标签序列
Matrix blocking – 根据邻接矩阵列向量的相似性排序
Skeleton clustering – 映射网络到核心连接树后进行检测
2.3 中心度分析
PageRank:让链接来“投票”。一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的 PageRank 是由所有链向它的页面的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入,那么它没有等级 ( 后来做平滑,从高等级页面中取出一部分声望匀给这些,保证平滑 )。
例子:假设有 A、B、C 和 D 四个节点。
若所有页面都只链向 A,那么 A 的 PR ( PageRank ) 值将是 B、C 和 D 的 PageRank 总和:
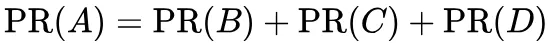
现假设 B 除了链向 A 也链向 C;D 链接到 A、B 和 C 三个页面;一个页面不能投票 2 次,所以 B 给每个页面半票,D 给每个页面三分之一票:
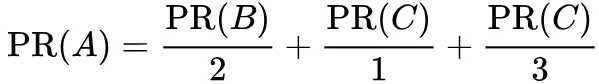
即
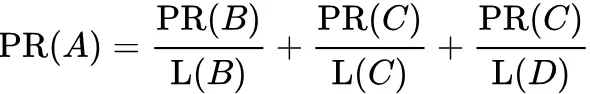
又做了平滑,即拿出一部分声望 来匀给从未出现过的页面:
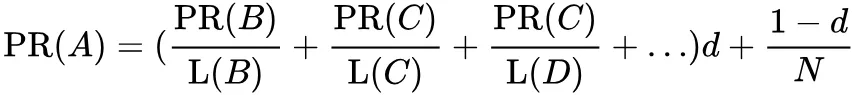
如果给每个页面一个随机 PageRank 值 ( 非 0 ),然后不断地迭代计算直至收敛。
HITS:按照 HITS 算法,用户输入关键词后,算法对返回的匹配页面计算两种值,一种是枢纽值 ( Hub Scores ),另一种是权威值 ( Authority Scores ),这两种值是互相依存、互相影响的。所谓枢纽值,指的是页面上所有导出链接指向页面的权威值之和。权威值是指所有导入链接所在的页面中枢纽值之和。
2.4 网络生成
小品中说不想知道怎么来的,就想知道怎么没的,但网络图的研究需要弄清网络怎么来的。若我们依照某些原则构造网络图,可以达到和现实中的网络一样,那这些原则即我们挖掘出来的现实中网络图的重要性质,现在研究得出的比较重要也比较知名的性质或因素有 3 个:
Small Word 性质:平均路径长度 μL 大小和 n ( 网络中节点数 ) 对数比例相关: 这也就是著名的 6 度理论 ( 世界中任何两个人都可以通过不超过 6 个人关系网而联系起来 )。
Scale-free 性质 ( 幂定律分布 ):绝大多数节点有很少量的度 ( 边 ),而小部分节点有很大的度 ( 边 )。一个节点有 k 度的概率:。log-log 图上为一条直线:
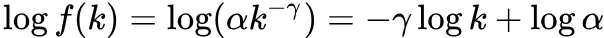
Clustering effect:如果两个节点有相同邻居,那么这两个节点链接的概率高。
Erdös-Rényi Random Graph Model:G(N,p) 一个网络有 N 个节点,每两个节点连接的概率为 p。很明显,如果网络比较小 ( N 比较小 ),则服从二项分布;若网络较大 ( N 较大,p 相对小 ) 则泊松分布。但是实际中网络并非泊松分布的,起码有一些中心点,节点的度更广,下图为 ER model 的网络与实际对比。
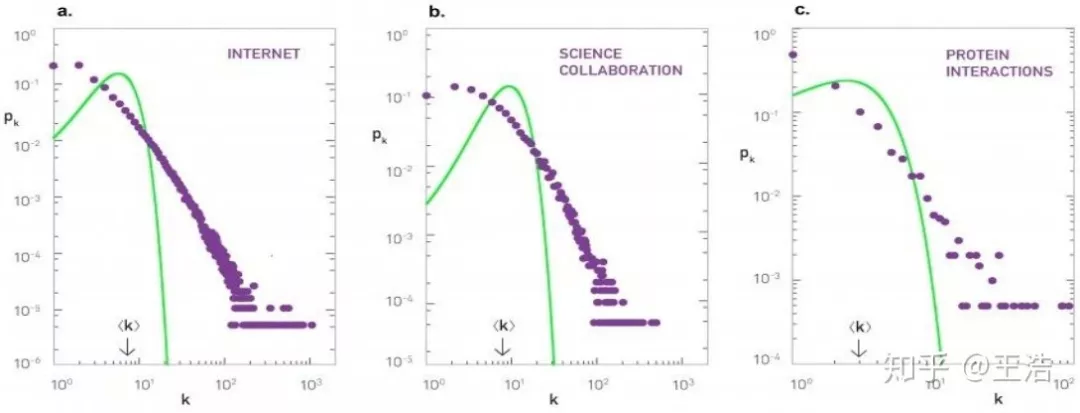
Watts-Strogatz Small World Graph Model:这个模型相较上面 Random Graph Model 加入了 small world 特征 ( 6 度理论 ),平均路径长度比随机网络短。所以这个模型网络中大部分的节点彼此并不相连,但绝大部分节点之间经过少数几步就可到达。
引入了集聚系数 ( Cluster coefficient ),描述图或网络中的顶点 ( 节点 ) 之间结集成团的程度的系数。具体来说,是一个点的邻接点之间相互连接的程度。例如在社交网络中,你的朋友之间相互认识的程度。一个节点 si 的集聚系数 C(i) 等于所有与它相连的顶点相互之间所连的边的数量,除以这些顶点之间可以连出的最大边数。显然 C(i) 是一个介于 0 与 1 之间的数。C(i) 越接近 1,表示这个节点附近的点越有“抱团”的趋势。
构建思路:
规则的网络开始。这个网络中的 N 个节点排成正多边形,每个节点都与离它最近的 2K 个节点相连。其中 K 是一个远小于 N 的正整数。
选择网络中的一个节点,从它开始 ( 它自己是 1 号节点 ) 将所有节点顺时针编号,再将每个节点连出的连接也按顺时针排序。然后,1 号节点的第 1 条连接会有 0<P<1 的概率被重连。重连方式如下:保持 1 号节点这一端不变,将连接的另一端随机换成网络里的另一个节点,但不能使得两个节点之间有多于 1 个连接。
重连之后,对 2 号、3 号节点也做同样的事 ( 如果这其中有连接已经有过重连的机会,就不再重复 ),直到绕完一圈为止。再次从 1 号节点的第 2 条连接开始,重复第 2 个步骤和第 3 个步骤,直到绕完一圈为止。再次从 1 号节点开始,重复第 4 个步骤,直到所有的连接都被执行过第 2 个步骤 ( 重连的步骤 )。
由于 NK 个连接里每个连接都恰好有一次重连的机会,所以这个过程最后总会结束。最后得到的网络称为 WS 模型网络。WS 集聚系数表达式:
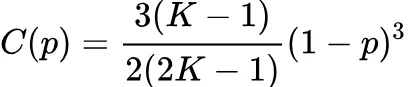
Barabási-Albert Scale-free Model:构造方法如下
初始化:由含 m0 个节点的初始网络开始
一次加一个节点,新节点链接到 m≤m0 个已存在节点,其概率与现有节点已有的链路数成比例。新节点链接已存节点 i 的概率为:
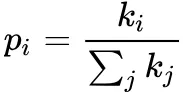
kj 为节点 i 的度,并且在所有预先存在的节点 j 上进行求和 ( 比如分母是网络中当前边缘数的两倍 )。重度链接的节点 ( hubs ) 倾向于快速累积更多链路,而仅具有少量链路的节点不太可能被选择作为新链路的目的地。新节点具有将其自身附加到已经高度链接的节点的“偏好”。
2.5 最短路径
最短路径是最早一批被关注的问题之一,DFS、BFS 和 Dijkstra 都是解决最短路径的经典方法,也都非常基础,在这里我就不做过多展开。
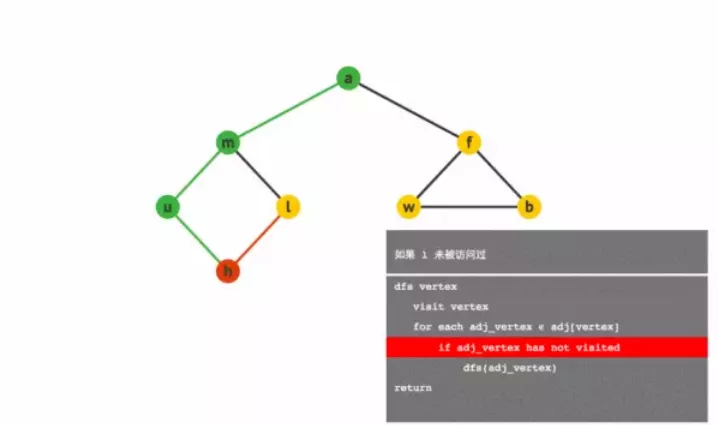
DFS:深度优先搜索算法 ( Depth-First-Search,DFS ) 是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点 v 的所在边都己被探寻过,搜索将回溯到发现节点 v 的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。属于盲目搜索。
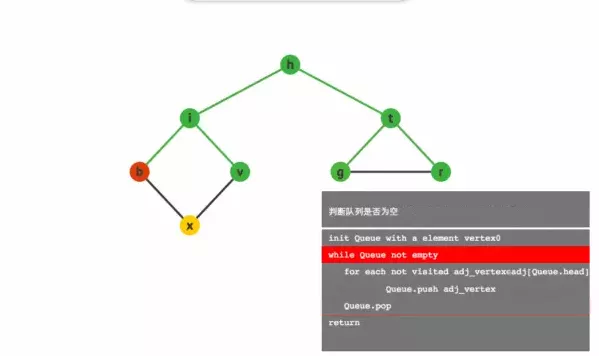
BFS:宽度优先搜索算法 ( Breadth-First-Search,DFS ) 以一种系统的方式探寻图的边,从而“发现” s 所能到达的所有顶点,并计算 s 到所有这些顶点的距离 ( 最少边数 ),该算法同时能生成一棵根为 s 且包括所有可达顶点的宽度优先树。所有因为展开节点而得到的子节点都会被加进一个先进先出的队列中。其邻居节点尚未被检验过的节点会被放置在一个被称为 open 的容器中,而被检验过的节点则被放置在被称为 closed 的容器中。
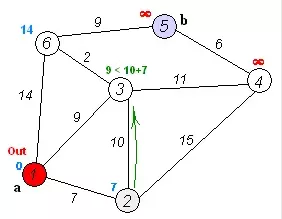
Dijkstra:Dijkstra 算法通过为每个顶点 v 保留当前为止所找到从 s 到 v 的最短路径来工作的。
2.6 聚类与排序
RankClus:排序与聚类相互加强:更好聚类可从排序中获得,排序范围又从聚类习得。思想
高排名的作者发布高排名论文在排名较高的会议或期刊:
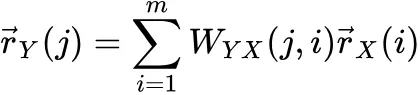
顶级会议或期刊吸引高排名作者发高排名论文:
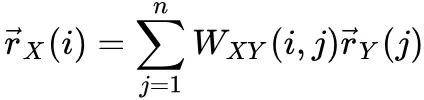
作者的排名受与他合作的作者的论文排名影响:
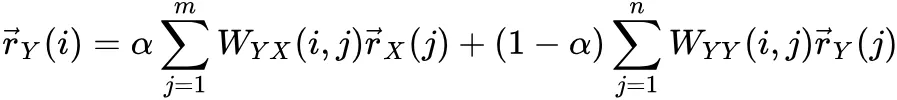
所分析网络领域的其他特性 ( 由于例子基于 DBLP,就先用上 3 个 )
NetClus:把一个网络分割成一个个子网络,还是以 DBLP 举例,权重 为两节点链接:
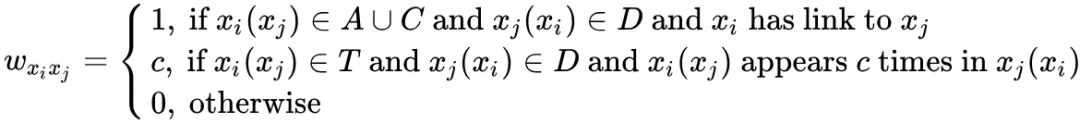
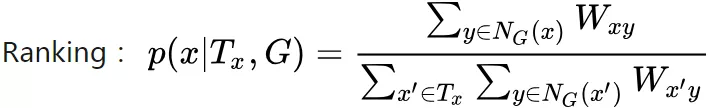
针对 DBLP 数据集来说:
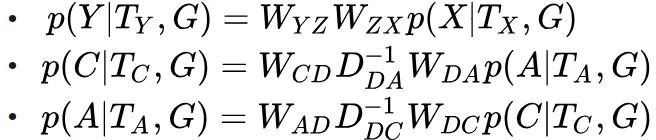
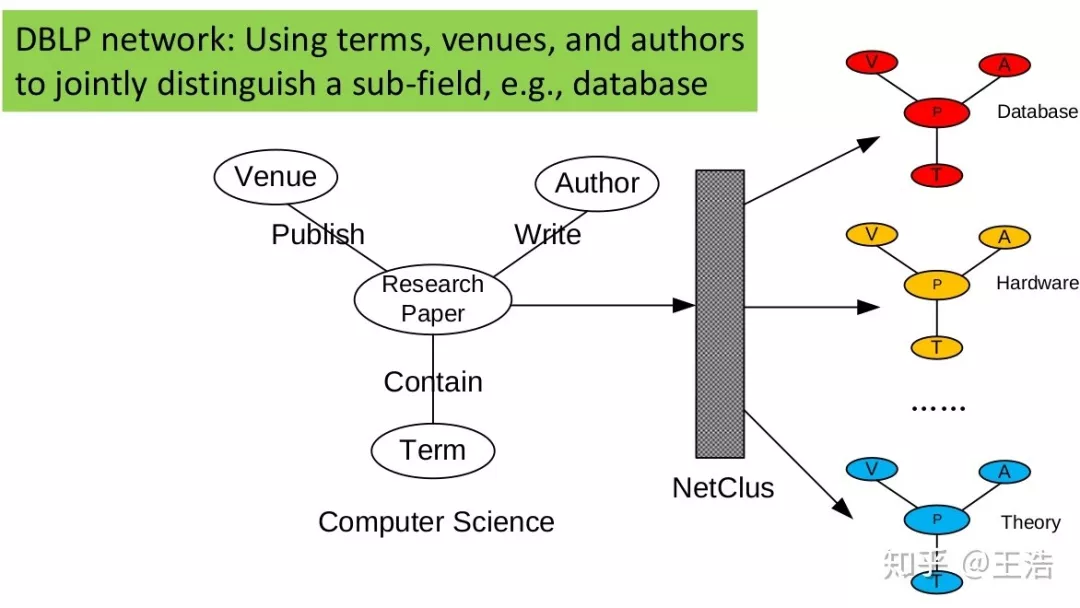
NetClus: Ranking-Based Clustering of Heterogeneous Information Networks with Star Network Schema. KDD 2009
2.7 分类与预测
GNetMine:这里再介绍一篇孙怡舟的工作,为啥老介绍她的论文,没办法,毕竟是异父异母同门的亲学姐,还和她合著的书,课上 1/5 都有她的贡献。嗯…借机膜一下。GNetMine 利用异构网络信息传递性,基于以下两启发式:
两个主体预测结果同属于类别的话,他们应当相似
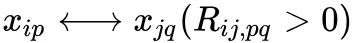
已知类别的数据我们模型的预测结果应该与事实一致或相似
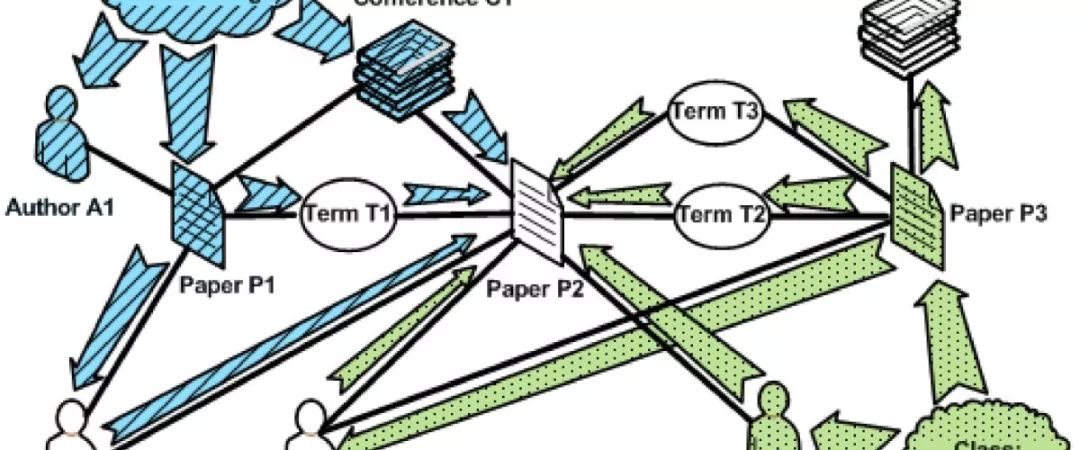
GNetMine: Graph Regularized Transductive Classification on Heterogeneous Information Networks. KDD 2011
算法步骤如下:
① 建立 m ( 节点类型 ) 个 i x K 矩阵,比如上图,i 为每个类型的元素数,10 个作者、50 篇论文等,K 为我们要分的类别,Data Ming、Database 两类则 K=2,m=4 ( 作者、论文、会议、名词 )。训练样本在概率矩阵中对应的位置的值为 1,剩余样本全部为 0,即:
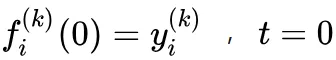
② 基于 计算:
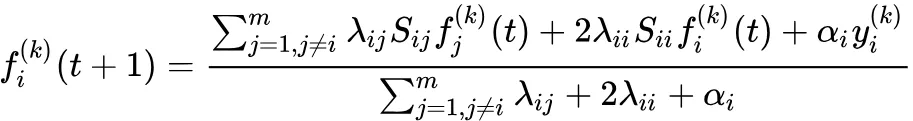
$f^{(k)}i(t)S{ij}=D^{-1/2}{ij}R{ij}D^{-1/2}_{ji}$,一个作者可以写多篇论文,一篇论文可以由多个作者合著,这里 Rij 是关系图比如作者-论文各为行列,对应即 1 不对应即 0,矩阵 S 就是标准化后的矩阵,同理可得 Sii,我就不展开了;参数方面,λij 调节不同主体比如论文-作者链接信息传递,λii 代表是作者之间、论文之间链接信息传递, αi 调节 Ground Truth。
③ 重复第 ② 步直到收敛后,各节点对应的向量中值最高维度对应的类别即预测类别。
RankClass:上面提到的 GNetMine 将每个节点看作相同影响力,RankClass 加了 Rank 部分,调节每个节点的影响力,比如和数据挖掘领域大佬相连,传递过去的属于数据挖掘这个类别的信息,要比像我这样数据挖掘领域小白相连传递过去的类别信息要高得多。
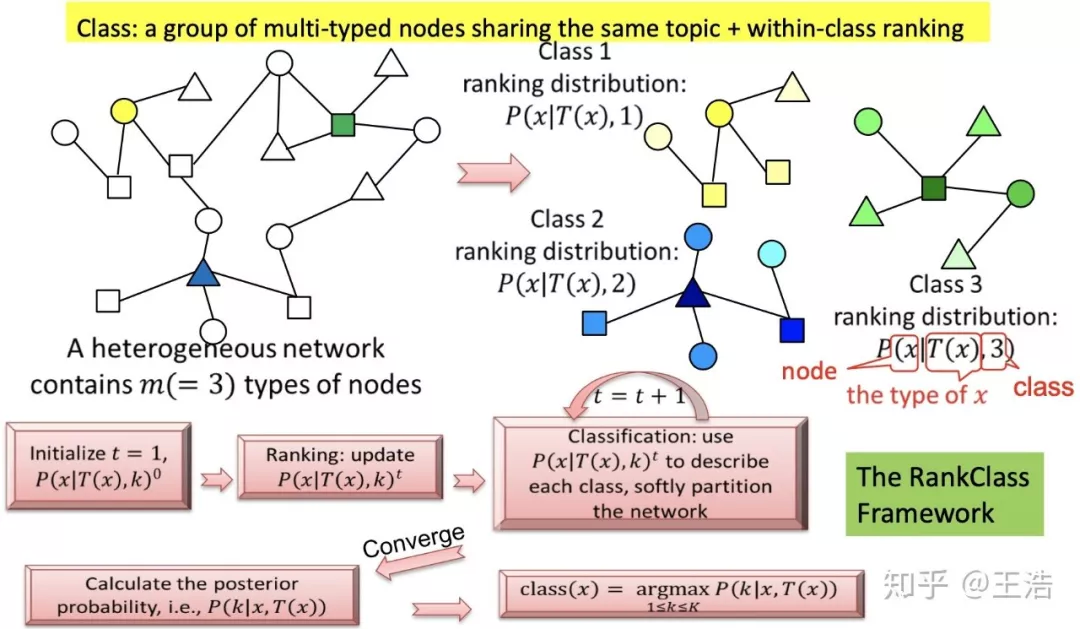
PathPredict:这个算法是做链接预测,比如两个人近五年内会不会合著论文,通过异构网络中不同的 Meta-path,基于逻辑回归进行预测。这篇文章预测的 A-P-A 路径链接预测,即两个人会不会合著论文,当然也可以进行其他 Meta-path 的链接预测。

PathPredict: Co-Author Relationship Prediction in Heterogeneous Bibliographic Networks. ASONAM 2011
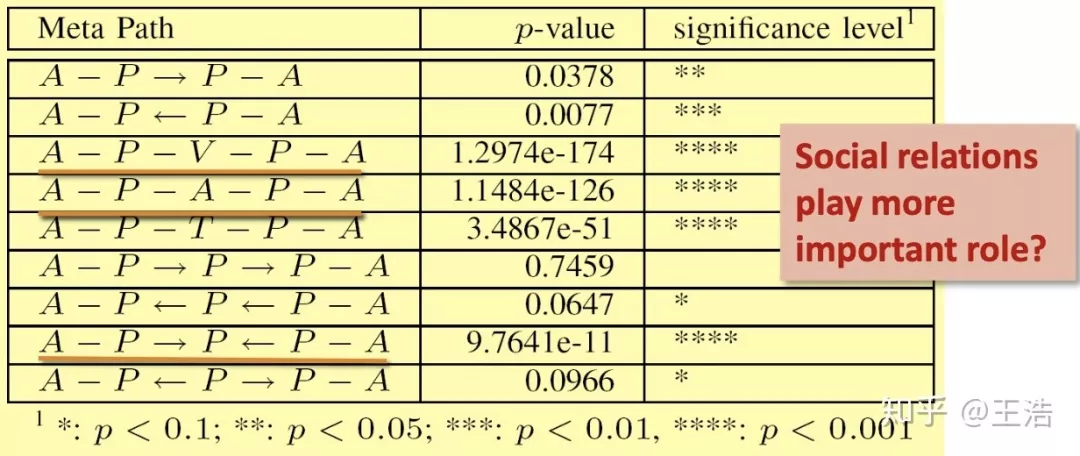
这篇论文还有一大探索就是基于不同问题的路径影响重要程度的研究,发现学术领域中社交因素相关的路径重要度更高。算法模型从 4809 个候选人中准确找到了 42 个裴健教授在 03-09 年有首次合作的人,可谓十分优秀。
PathPredict_When:上一篇链接预测判断两个人会不会合作,这一篇是判断什么时候合作。
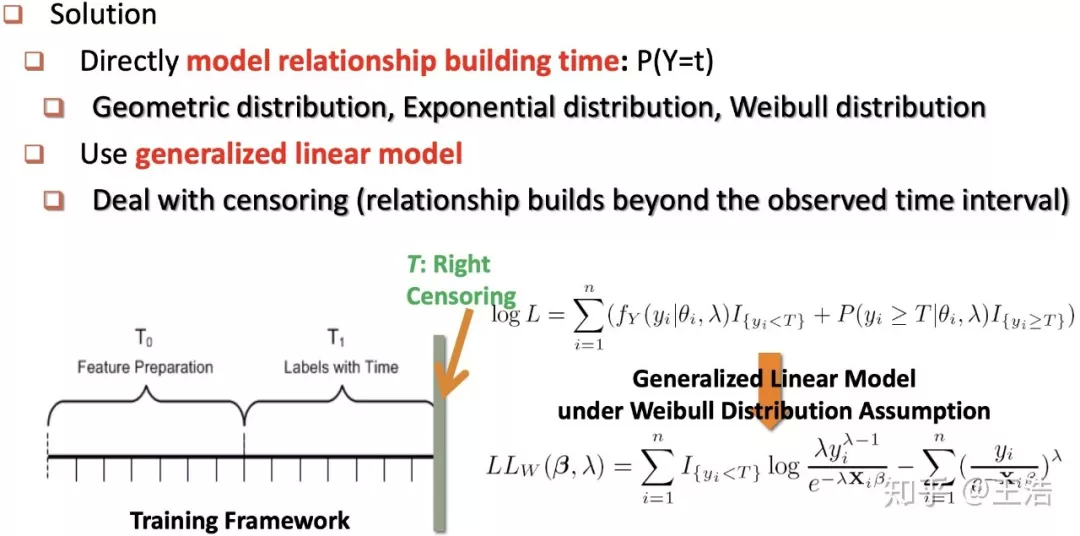
PathPredict_When: When Will It Happen? — Relationship Prediction inHeterogeneous Information Networks. WSDM 2012
3. Network Embedding
Classic Graph Algorithm 算法这么强了,为啥搞 Network Embedding?主要以下 3 点原因:
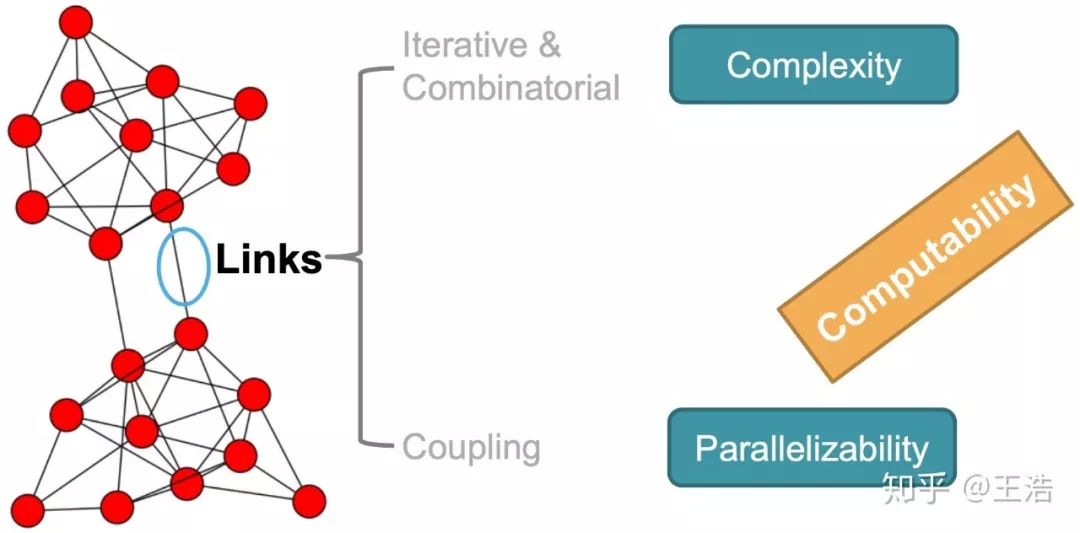
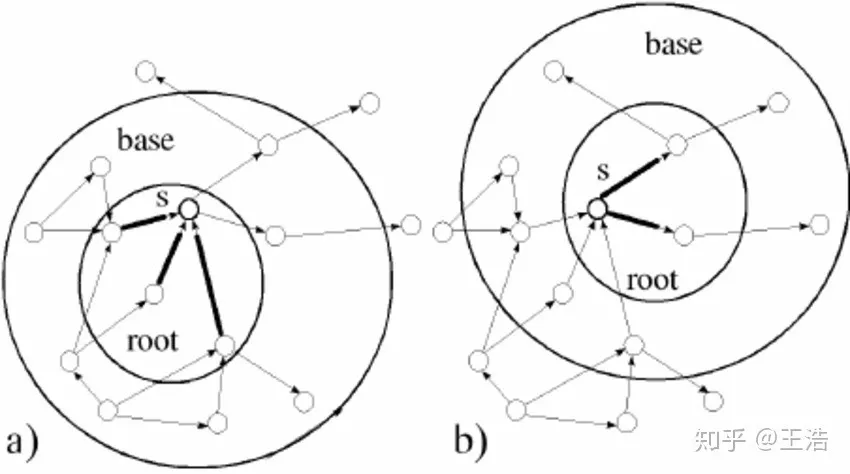
① 首先因为 Network 的计算复杂性。这是由网络结构导致的,计算两个节点相似度,肯定得去看他们相邻的节点情况,而相邻的节点情况,又得看其相邻的节点情况,然后在看相邻相邻…不限制计算的话遍历整个网络。
② 其次 Network 不宜并行计算。现在大数据这么火,有很大原因计算速度能上去了,其中并行计算是关键。但对于网络图结构来讲,把每个节点扔去一台机器 Map 计算再 Reduce?节点是相连的,相互通信成本巨大。把边或社区搞并行?通信成本都很高。
③ 最关键的 Classic Graph Algorithm 只能对问题做针对性算法,因问题制宜,无法采用机器学习、深度学习、强化学习… ( 各种学习 ) 的模型算法。而将 Network 转成 Vector,那就非常爽了!啥深度学习、机器学习模型都能往上怼!
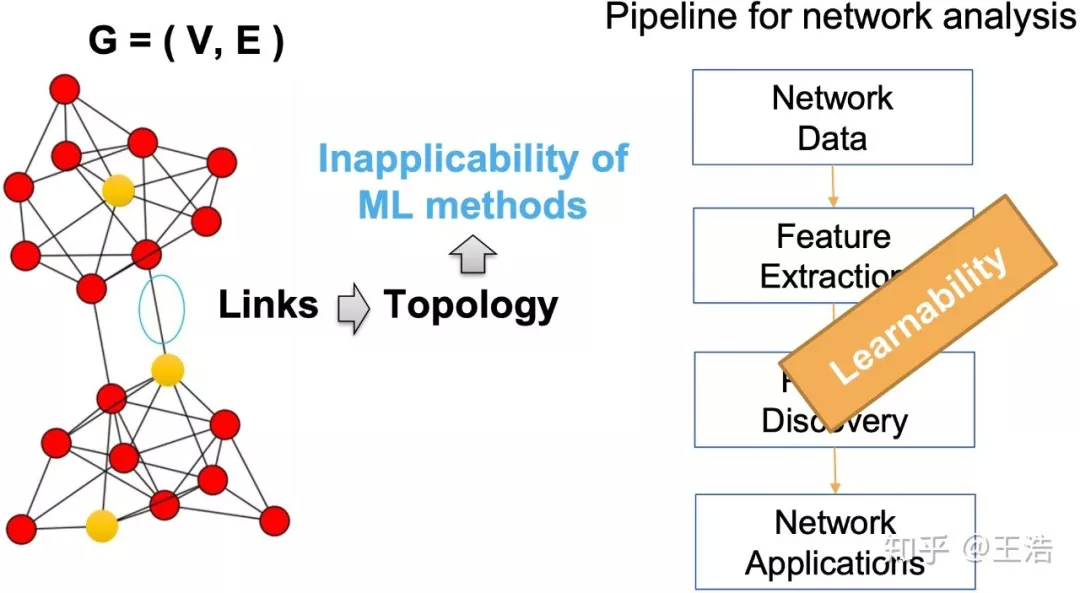
还在收集 Network Data,进行 Feature Extraction、Discovery 最后在 Network Applications 吗?现在不需要了!不要 998!甚至不要 98!只需进行 Network Embedding,然后想怼啥模型怼啥模型,岂不嗨的一批!Network Embedding 这么优秀,为啥现在各公司没有都入坑?因为 Embedding 也是有难度的。
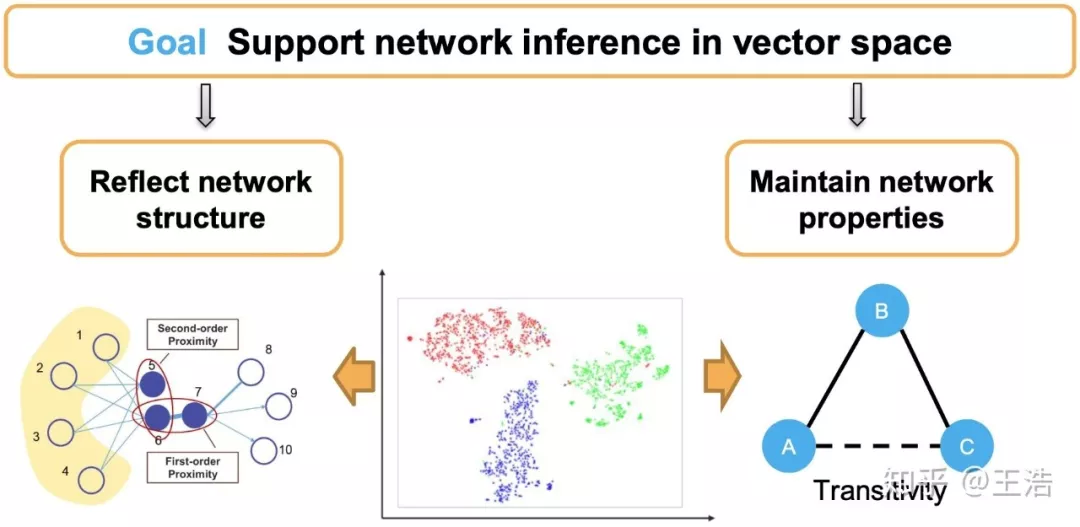
我们 Network Embedding 的目标是 Embedding 后的 vector space 支持网络推断。这就要求 vector space 起码得具有重构性,即可从 vector 再转回网络图结构,保持网络结构信息不丢失。那我们直接用邻接矩阵不就可以了吗,保持了网络结构信息,并非如此。Embedding 后的 vector space 还需要保持网络的一些性质。所以研究大都基于网络结构或网络性质进行 Embedding,下面的讲解也是从这两大方向阐述一些方法。
3.1 基于网络结构的 Embedding
什么是基于网络结构的 Embedding?就是我们希望 Embedding 之后 Vector 们依旧保留网络结构信息。网络结构有这几个研究方向:Nodes&Links、Pair-wise Proximity、Community Structures、Hyper Edges 和 Global Structures。Embedding 工作主要基于 Nodes&Links、Pair-wise Proximity 和 Global Structures 这仨方向。Nodes&Links 是最直接原始的方法;Pair-wise Proximity 更关注节点周围信息,即目标节点周边关系要保留;Global Structures 更关注全局信息,比如两节点不直接相连,但都是公司中层,管十几个人,在社会网络中结构相似。
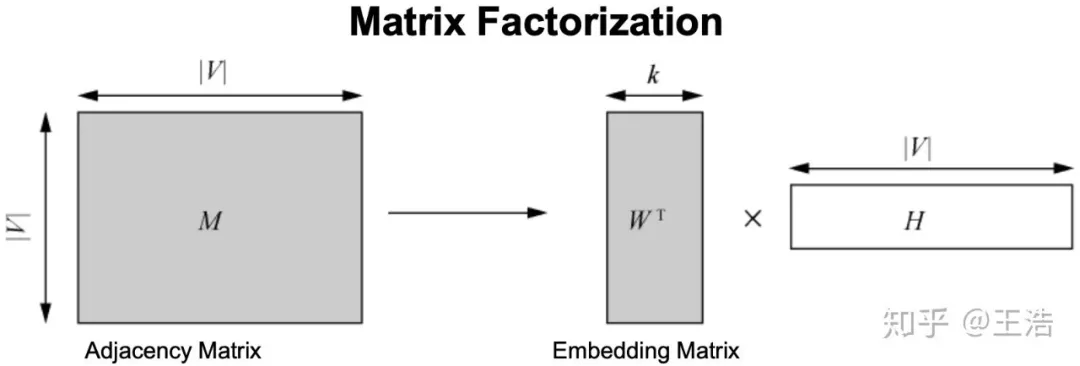
基于 Nodes&Links 的 Embedding
基于 Node&Links 的方法比如矩阵分解,也可以从降为的角度去理解,将大的邻接矩阵进行矩阵分解,得到 k 维的 Embedding Matrix。
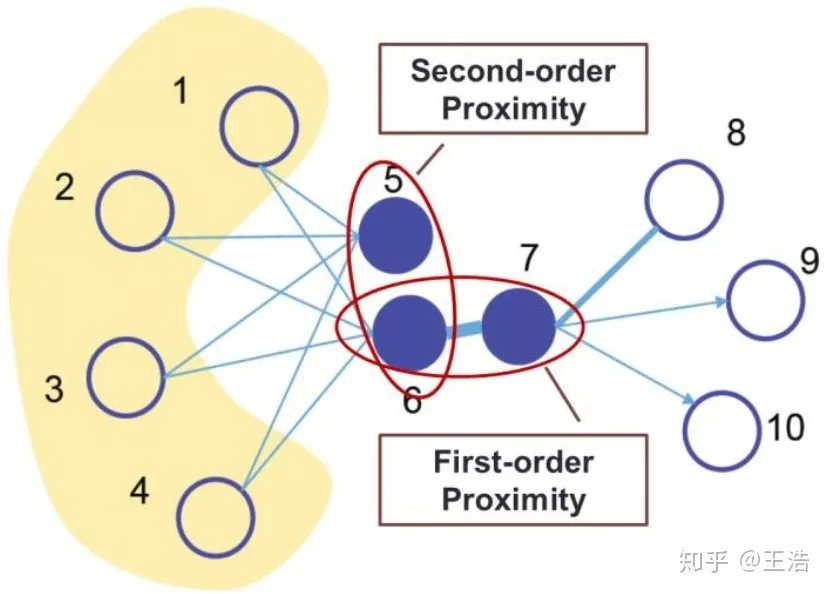
基于 Pair-wise Proximity 的 Embedding
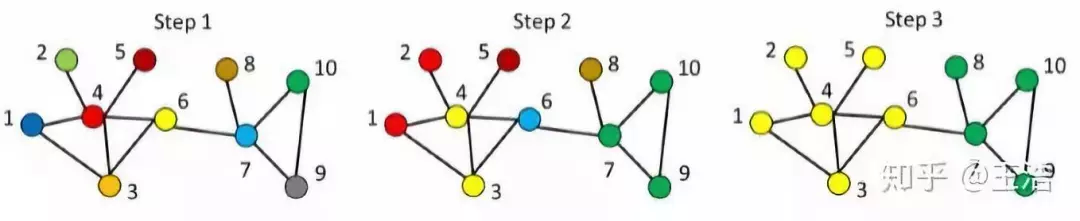
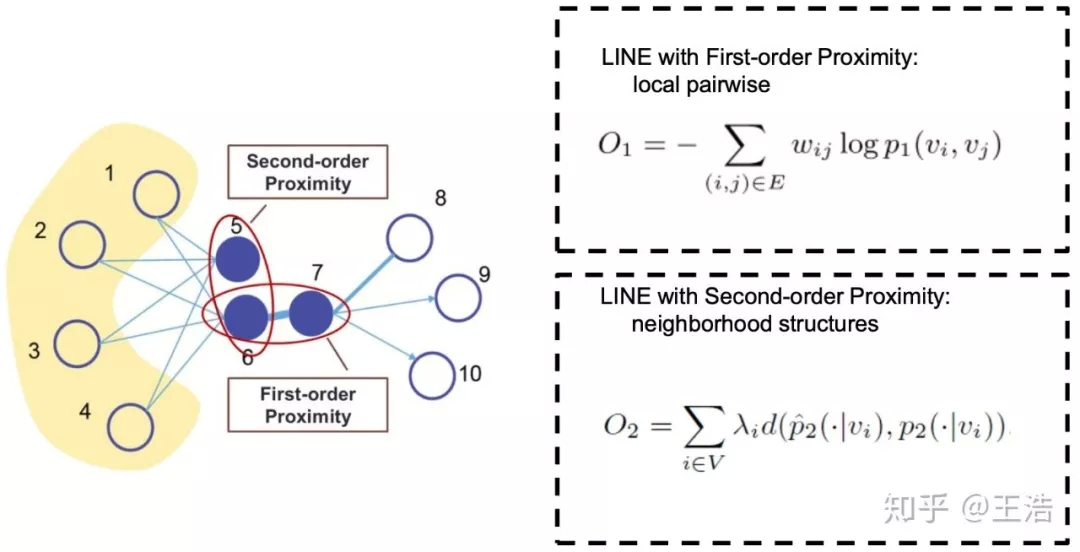
因为我们关注点与点之间的信息,所以现大多方法都是基于 Pair-wise Proximity 的 Embedding。这里先解释以下 Graph 中的 Proximity,像下图节点 6 和 7 直接相连,他们的 Proximity 就是 First-order Proximity;5 和 6 不直接相连,但经过一个节点后他们是相连的,是 Second-order Proximity;当然还有更高 order 的 Proximity,比如 5 和 7,5-1-6-7,中间经过两个节点,Third-order Proximity…
Deep Walk:Deep Walk 用一句话来讲就是固定长度的 Random Walk,如下图右上通过 Random Walk 将网络变成固定长度的序列。这些序列可以看作我们自然语言中一个个句子,所以再应用一些 word2vector 的方法就可以转成 vector 啦 ( Random Walk 忘了的同学,就是一句话,节点 X 到节点 Y 的概率 )。
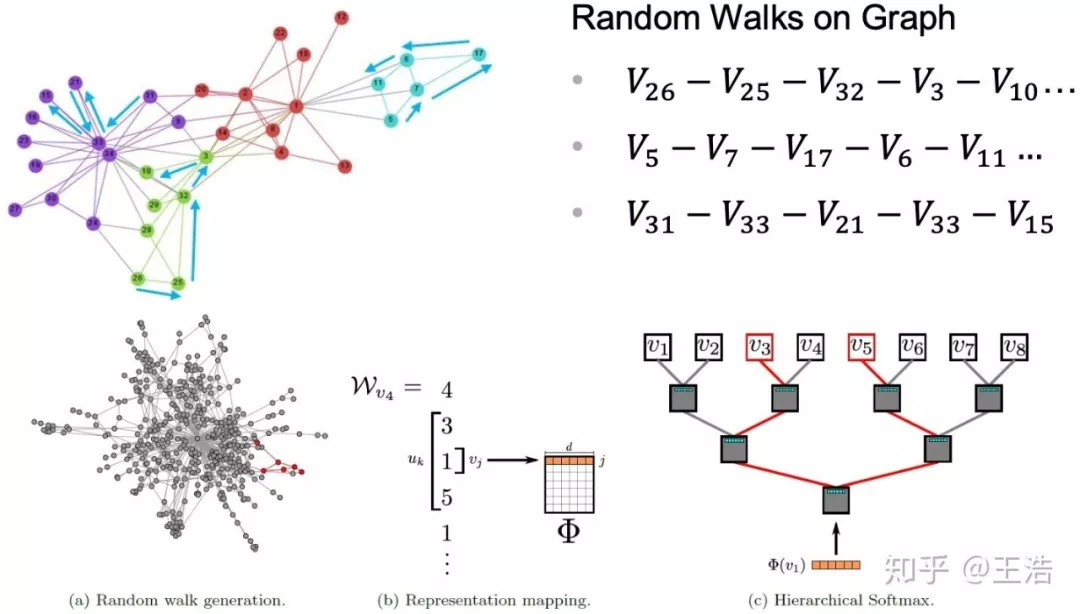
LINE:相比 DeepWalk 纯粹随机游走的序列生成方式,LINE 可以应用于有向图、无向图以及边有权重的网络,并通过将一阶、二阶的邻近关系引入目标函数,能够使最终学出的 node embedding 的分布更为均衡平滑,避免 DeepWalk 容易使 node embedding 聚集的情况发生。
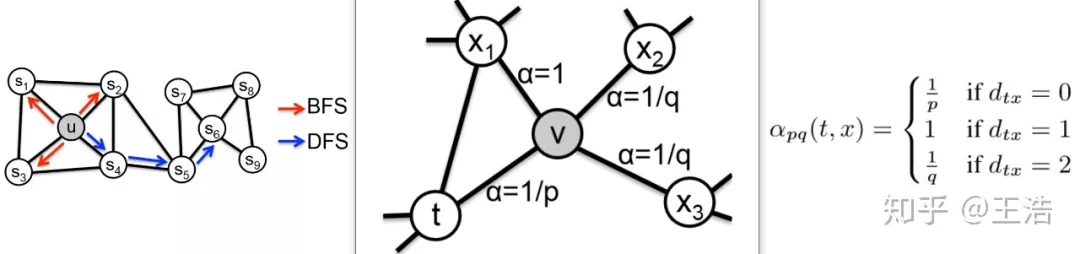
Node2Vec:斯坦福大学在 DeepWalk 的基础上更进一步,通过调整随机游走权重的方法使 Graph Embedding 的结果在网络的同质性 ( homophily ) 和结构性 ( structural equivalence ) 中进行权衡权衡。具体来讲:
“同质性”指的是距离相近节点的 embedding 应该尽量近似。为了使 Graph Embedding 的结果能够表达网络的同质性,在随机游走的过程中,需要让游走的过程更倾向于宽度优先搜索 ( BFS ),因为 BFS 更喜欢游走到跟当前节点有直接连接的节点上,因此就会有更多同质性信息包含到生成的样本序列中,从而被 embedding 表达。
“结构性”指的是结构上相似的节点的 embedding 应该尽量接近。为了抓住网络的结构性,就需要随机游走更倾向于深度优先搜索 ( DFS ),因为 DFS 会更倾向于通过多次跳转,游走到远方节点上,使得生成的样本序列包含更多网络的整体结构信息。
返回概率参数 ( Return parameter ) p,对应 BFS,控制回到原来节点的概率,如图中从 t 跳到 v 以后,有 1/p 的概率在节点 v 处再跳回到 t。离开概率参数 ( In outparameter ) q,对应 DFS,控制跳到其他节点的概率。拿下图举例,从 edge (t,v) 到节点 v 上,下一步要决定往那边走。其中 dtx 表示节点 t 到节点 x 之间的最短路径即 dtx=1 则表示 t 和 x 直接相连…参数 p 和 q 共同控制着随机游走的倾向性。
node2vec: Scalable Feature Learning for Networks. KDD 2016
SDNE:SDNE 是一种半监督深度模型,包含有监督和无监督两部分。有监督部分由 Laplacian 矩阵建模一阶相似性,无监督部分由深度自编码机对二阶相似性建模。
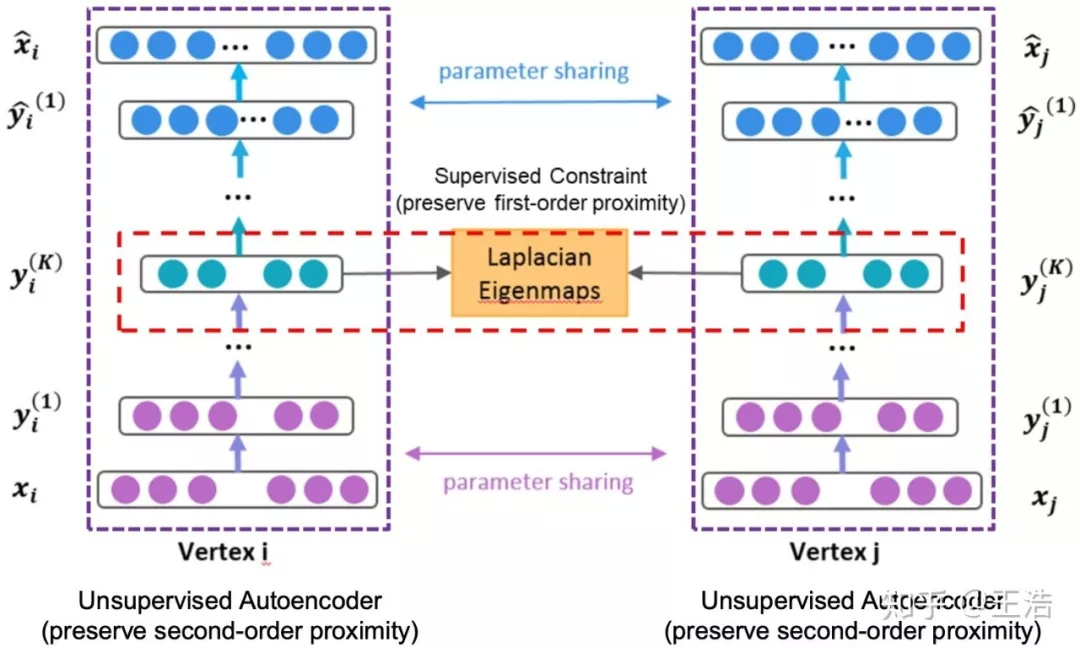
SDNE: Structural Deep Network Embedding. KDD 2016
AROPE:不同的任务需要考虑不同 order 的 proximity,那我们怎么蕴含任意 order 的 proximity 信息呢?邻接矩阵其实可以由一个多项式表示,就像泰勒展开一样,q 是 order,A 是其他变量比如拉普拉斯矩阵之类,我们就可得:
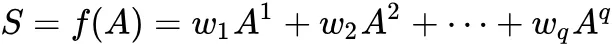
所以目标函数可写为 $\min_{U^,V^}|S-U^V^{T}|^2_FU^=U\sqrt{\sum},V^=V\sqrt{\sum}$。
AROPE: Arbitrary-Order Proximity Preserved Network Embedding. KDD 2018
基于 Global Structures 的 Embedding
除了局部关系 ( 不同 order 的 proximity ),还有全局关系,如果两个节点全局关系相似,那他们的 Embedding 也应该相似,比如工作社交网络中两个节点,都是中层领导,领导 10 几个人小组,向上面汇报。虽然两人不认识,但在社会工作网中扮演的角色相似,全局关系近,所以他们的 Embedding Vector 也应当相近。
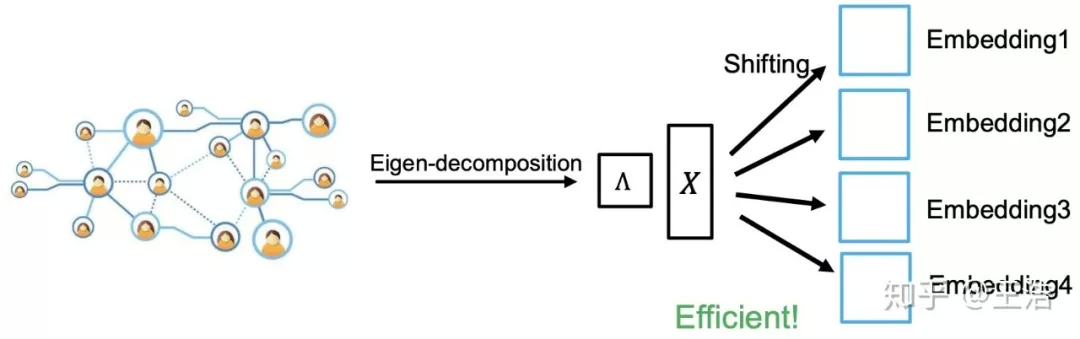
GraRep:如下图,拿取 k 步的信息,如果全局中虽不相连但第 k 步信息相似的结构,那他们的 Embedding 向量应当相近。模型里不对 1 阶 2 阶的信息进行相似查找,为什么这么做很好理解,这种低阶关系太多了意义不大还耗费计算量。
GraRep: Learning Graph Representations with Global Structural Information. CIKM 2015
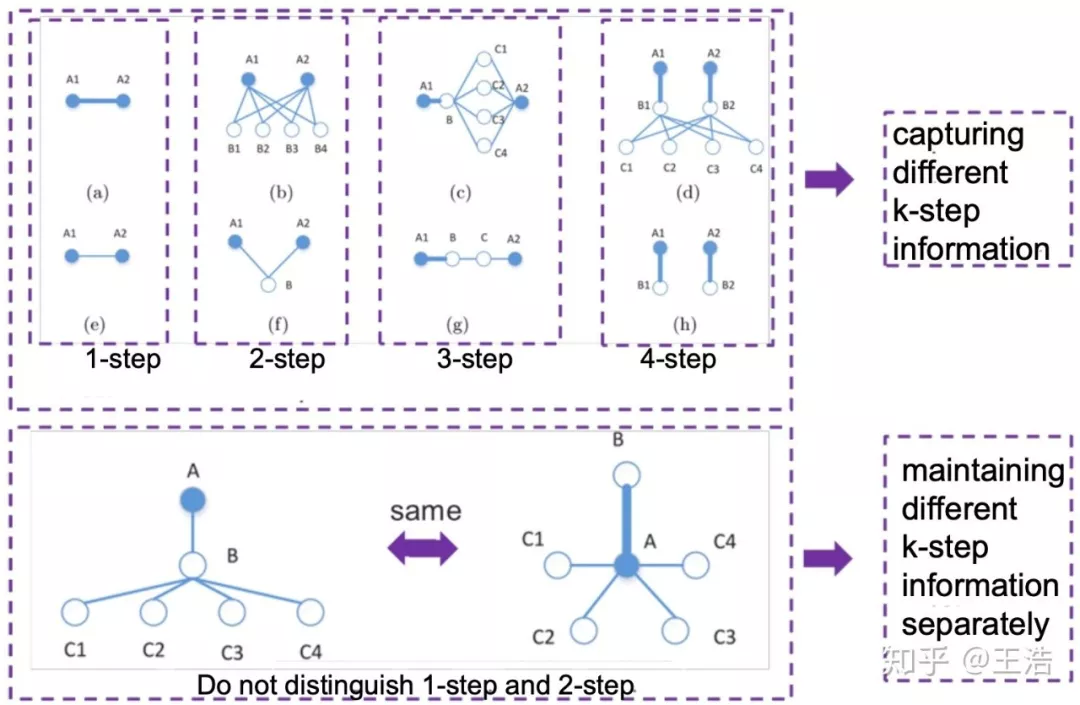
DRNE:DRNE 步骤如下图
① 采样目标节点的邻居们
② 根据邻居们的度进行排序
③ 聚合目标节点的邻居们
④ 对目标节点的训练进行弱正则化
DRNE: Deep Recursive Network Embedding with Regular Equivalence. KDD 2018
3.2 基于网络性质的 Embedding
网络性质主要有:传递性、非传递性、非对称传递性以及不确定性。
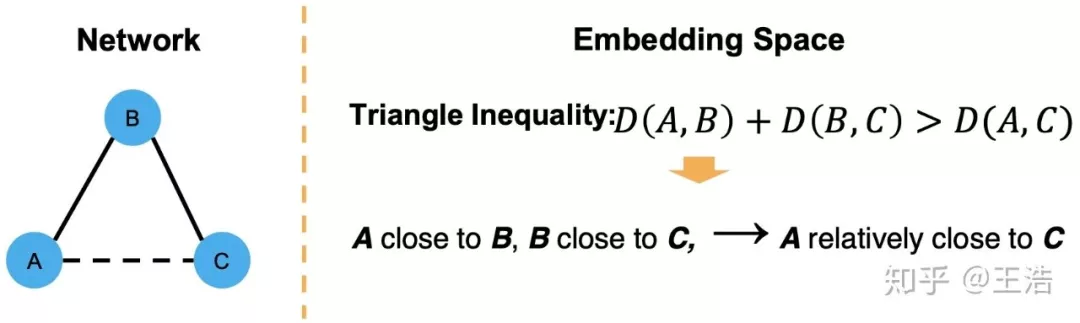
传递性 ( Transitivity ):传递性很容易理解,前面提到经典的 Deep Walk 等其实都是依赖传递性。比如我 close to 霍建华,霍建华 close to 胡歌,我很大概率也 close to 胡歌,毕竟都帅。
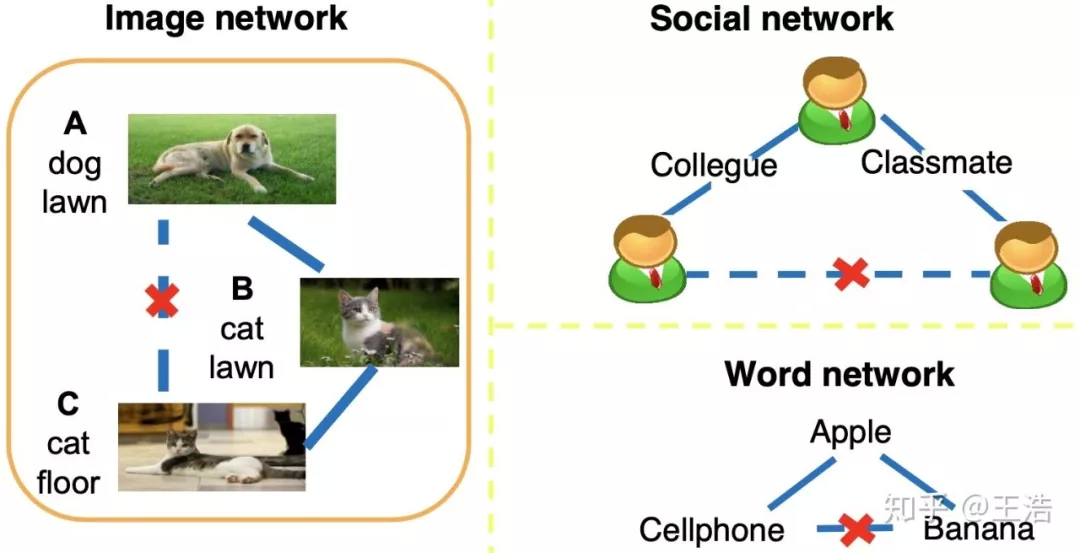
非传递性 ( Non-transitivity ):传递性好理解,又有非传递性,这和传递性不冲突吗?其实并不冲突,两个性质在现实网络中共存,毕竟现实中网络是有向图,如下图,大家有不少同事,也有很多同学,但社交网络里,他们基本是都不认识的。当然,你要是同学同事都是一批人,那我服,你去看 Cell Phone-Apple-Banana 的例子。
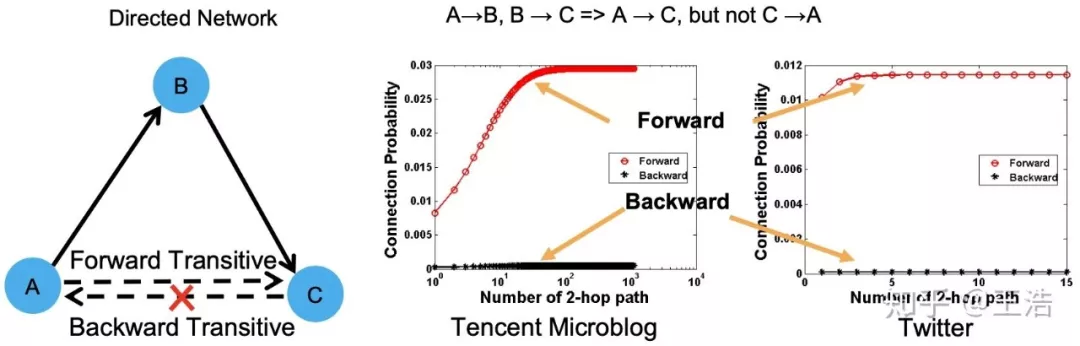
非对称传递性 ( Asymmetric Transitivity ):非对称传递性又是个啥?很简单,我微博 follow 了高圆圆,高圆圆 follow 了刘亦菲,但是刘亦菲并不会 follow 我,而我怎么也得 follow 一下自己老婆,这就是下图中 A ( 我 )、B ( 高圆圆 )、C ( 刘亦菲 ) 之间的非对称传递性。
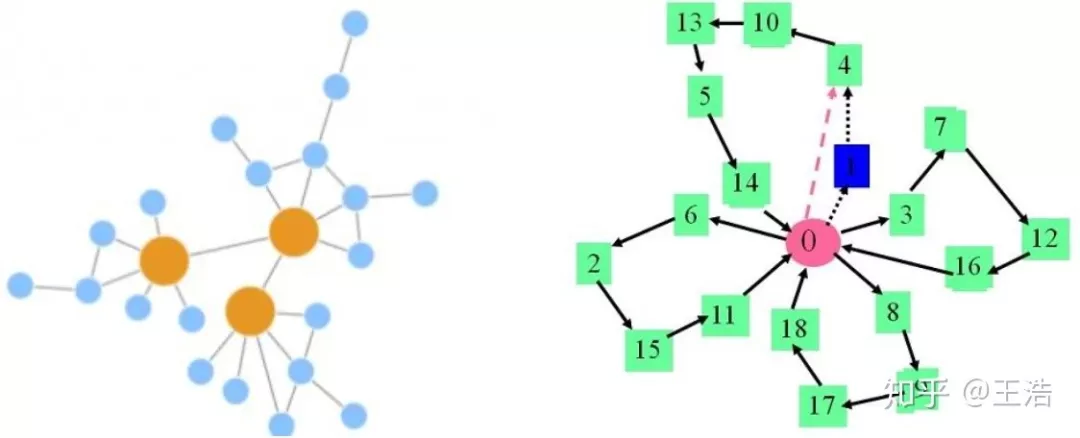
不确定性 ( Uncertainty ):不确定性主要是指现实网络中根据节点蕴含的信息,有大量不确定性。比如下图左,只有很少边的节点,信息较少,我们 Embedding 出来后的 Vector 相较其他边多一些的节点更不确定;边非常多就确定了吗?也不尽然,如果边链接多个社区,那这个节点包含的信息会很杂,也会造成不确定性,如下图右。
DVNE:DVNE 加入了 Ranking Loss,这里很好理解,高圆圆和刘亦菲的 Rank 都高,我的 Rank 不高,我链接她们两个的可能高,她们链接我的可能小,我的 Embedding 向量当然距离也会远一些。
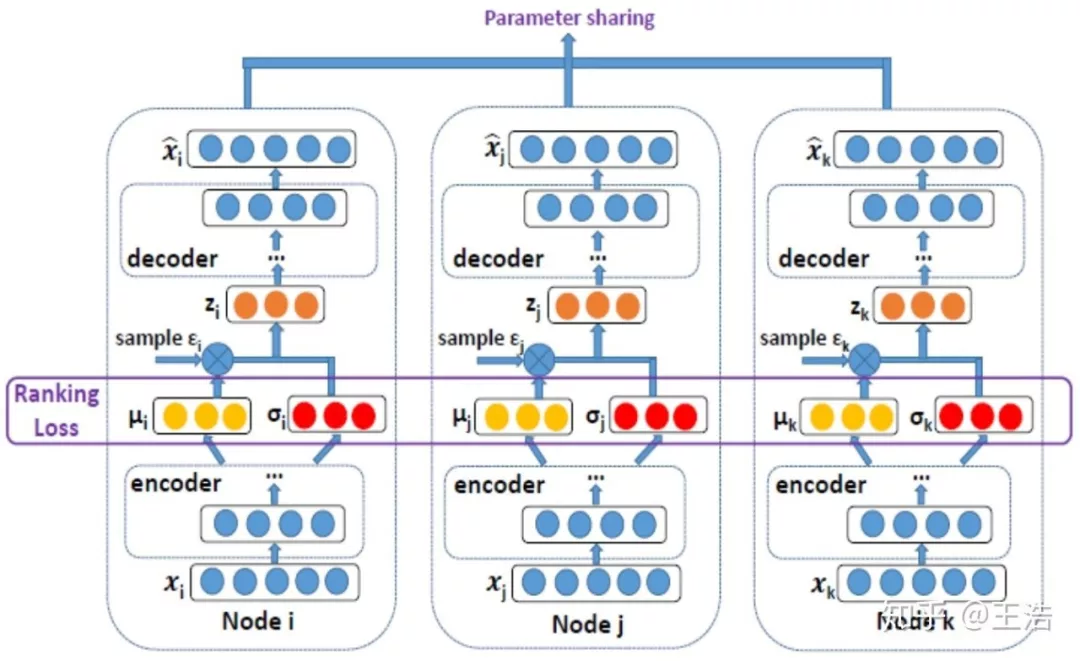
DVNE: Deep Variational Network Embedding in Wasserstein Space. KDD 2018
3.3 动态网络 Embedding
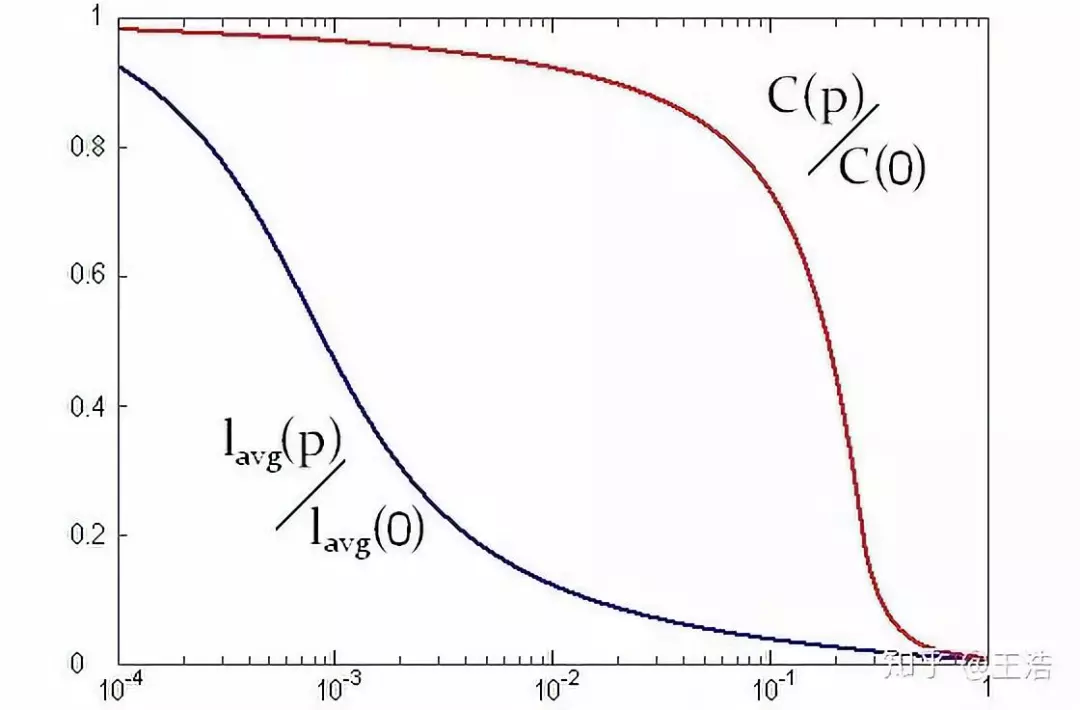
工业界应用 Graph Embedding 有一个很关键的问题,网络很大,而且是动态的,难道微博每注册一个新用户,一个用户关注了另一个就要重新训练我们的 Embedding Vectors 吗?动态网络 Embedding 就可以解决这个问题。总的来说动态网络有下列四大关键问题
样本外节点 ( Out-of-sample Nodes )
新增链接 ( Incremental Edges )
聚合误差 ( Aggregated error )
可扩展优化 ( Scalable optimization )
4. 业界应用
现在业界最成熟的应用是多轮对话 ( 微软小冰、阿里小蜜… ),因为这个场景落地好,技术也比较成熟;当然网络图的性质结构天然适用于搜索推荐,现在也有很多在这个领域的尝试;除此之外还有很多业界落地的应用或正在尝试的方向。在业界应用这里我并不能涵盖全,但已知的有些非常有借鉴意义,我会将值得借鉴的亮点进行总结表述,由于并不了解完全细节,有不对的地方欢迎交流批评指正。
4.1 概念化节点
大部分公司都选择构建了一些概念化节点 ( 非实体节点 )。
微软已有的 Concept Graph,比如 Microsoft ( 实体 )-公司 ( 非实体 )-操作系统供应公司 ( 非实体 ),这样从抽象范概念到细概念的图关系结构,虽然不是典型的图谱,但是作为层次化图利用发现效果也很好。
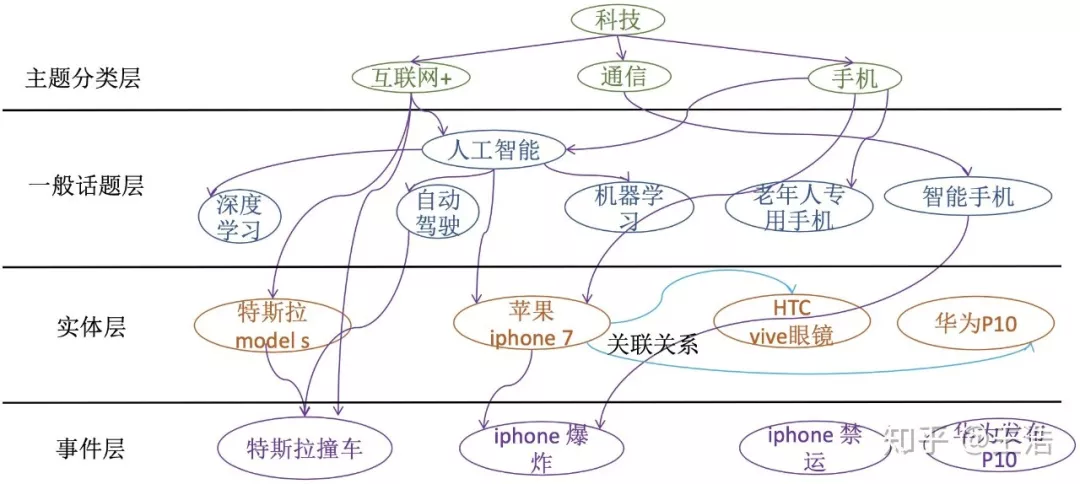
腾讯,比如王宝强离婚,特斯拉撞车等事件层。针对广告场景,广告主又针对到不同的主题,甚者细粒度的一般话题。如下图的四层提供了一个很好的业务逻辑及图谱思路。有了好的图谱构建,后续的内容理解比如概念挖掘、热门挖掘、关联关系、文本分类、关键词提取、语义匹配等等任务都可以迎刃而解。
阿里小蜜也同样设置了概念化节点,比如促销活动 ( 非实体 )-双 11 ( 实体 ),促销活动 ( 非实体 )-双 12 ( 实体 );美团,咖啡 ( 非实体 )-星巴克 ( 实体 ),咖啡 ( 非实体 ) - 冰美式咖啡 ( 实体 )…
4.2 Embedding
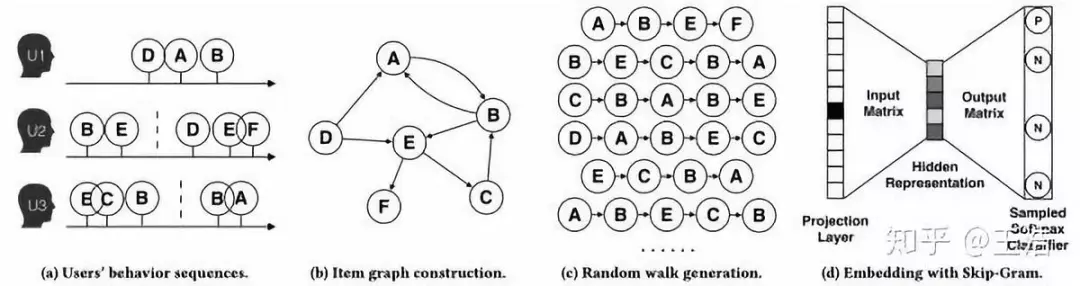
阿里的 EGES,用户购物的 Item 序列构建成 Graph,利用 Random walk 进行 Embedding。网上有很多解读,我就不展开详谈了,据了解效果很不错。
滴滴提出的 AHINE 方法将地点等也转化成 vector,下图是与北京南站最近的 vector,可以看到基本都是火车站和飞机场,效果也不错。
既然在知乎发文章,怎么能不提一下知乎。知乎作为问答社区,包含了三大块子网络:一块是人和人之间的连接,一块是人与内容之间的连接,还有一块是内容自身的连接 ( 比如收藏夹 )。主要应用场景也是用户表示,具体业务比如相似用户 ( 给以种子用户,找到相似用户,即 Lookalike ):用户关注推荐、Live 课推荐;人群划分 ( 将人群进行分类 ):广告定向人群投放;显示推荐 ( 聚类协同过滤等 ):群体高互动内容作为 feed 候选。知乎采用的 GraphSAGE 框架,好处很明显,在知乎的动态网络中,有新用户或用户有新的链接,不需要高频重新训练 Embedding 向量。下图是其训练出 vector 后做用户聚类的结果,可以看到大佬们在哪个平台都是大佬。

5. 参考资料:
Jiawei Han 个人主页:
Peng CUI 个人主页:
http://pengcui.thumedialab.com
RankClus: Integrating Clustering with Ranking for Heterogeneous Information Network Analysis
http://zuse9-2.se.cuhk.edu.hk/~hcheng/paper/edbt09_ysun.pdf
Ranking-Based Clustering of Heterogeneous Information Networks with Star Network Schema
http://www.ccs.neu.edu/home/yzsun/papers/kdd09_netclus.pdf
Graph Regularized Transductive Classification on Heterogeneous Information Networks⋆
http://marinadanilevsky.com/wp-content/uploads/2013/05/PKDD10_paper_Ming.pdf
Yizhou Sun 个人主页
http://web.cs.ucla.edu/~yzsun/
Ranking-Based Classification of HeterogeneousInformation Networks
http://marinadanilevsky.com/wp-content/uploads/2013/05/Ming-Ji-RankClass-KDD11-final-version.pdf
Co-Author Relationship Prediction in Heterogeneous Bibliographic Networks*
http://www.ccs.neu.edu/home/yzsun/papers/asonam11_pathpredict.pdf<>
When will It Happen? — Relationship Predictionin Heterogeneous Information Networks
https://www3.nd.edu/~nchawla/papers/WSDM12.pdf
Deep Walk:
https://github.com/phanein/deepwalk
LINE :
https://github.com/tangjianpku/LINE
Node2Vec:
http://snap.stanford.edu/node2vec/
SDNE:
https://github.com/suanrong/SDNE
AROPE:
https://github.com/ZW-ZHANG/AROPE
GraRep:
https://dl.acm.org/citation.cfm?id=2806512
Deep Recursive Network Embedding with Regular Equivalence
http://pengcui.thumedialab.com/papers/NE-RegularEquivalence.pdf
Deep Variational Network Embedding in Wasserstein Space
http://pengcui.thumedialab.com/papers/NE-DeepVariational.pdf
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
https://arxiv.org/pdf/1803.02349.pdf
AHINE: Adaptive Heterogeneous Information Network Embedding
https://arxiv.org/pdf/1909.01087.pdf
作者介绍:
王浩
微博 | 算法工程师
本文来自 DataFun 社区
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论