

我知道许多数据科学家,包括我自己,都通过 Jupyter Notebooks 或某些 Python IDE 在支持 GPU 的计算机上,包括本地或在云中完成大部分工作。近两年来,作为 AI/ML 软件工程师,我正在做的事情是——在一台没有 GPU 的机器上准备数据,然后在云中使用 GPU 虚拟机做训练。
另一方面,您可能已经听说过Azure 机器学习——一个特殊的用于机器学习的平台服务。但是,如果您开始寻找一些入门教程,您将意识到,使用 Azure 的 ML 会创建很多不必要的开销,并且这个过程不是很理想。例如,在前面提到的例子中训练脚本是作为一个 Jupyter Cell 的文本文件创建的,没有代码补全,也没有任何方便地在本地执行或调试的方式。这些额外的开销也是我们并没有在我们的项目中尽可能多的使用它的原因。
不过,最近我发现有一个Visual Studio Code Extension for Azure ML。有了这个扩展,您可以在 VS Code 中直接开发您的的训练代码,并在本地运行,然后将相同的代码提交到集群上进行训练,只需点击几下按钮。这样的方式有几个重要的优势:
您可以将大部分的时间花在本地机器上,并 仅为训练使用强大的 GPU 资源。训练集群可以根据需求自动调整大小,通过将机器的最小量设置为 0,可以根据需要调整 VM。
您 将训练的所有结果 维护在一个中心位置,包括指标和创建模型——没有必要为手工为每个实验保留精确度记录。
如果 几个人在同一项目上工作——他们可以使用同一个集群(所有实验将进行排队),并且可以查看彼此的实验结果。例如,您可以使用 教室环境中的 Azure ML,创建一个集群供所有人使用,而不是给每个学生创建一个单独的 GPU 机器,并促进学生之间为模型精确度进行竞争。
如果您需要进行大量训练,例如用于 超参数优化 ——所有这些可以通过几个命令来完成,无需手动运行一系列的实验。
我希望已经说服您来尝试一下 Azure ML!下面是如何开始使用的最佳方式:
安装Visual Studio Code, Azure Sign In 和 Azure ML 扩展
克隆库 https://github.com/CloudAdvocacy/AzureMLStarter ——它包含了一些示例代码来训练识别 MNIST 数字模型。然后,您可以在 VS Code 中打开该克隆库。
继续阅读!
Azure ML 的工作区和门户
Azure ML 中的一切都围绕着一个 工作区 进行组织。这是您提交实验、存储数据和结果模型的中心位置。还有一个特殊的Azure ML Portal,为您的工作区提供 Web 界面,从这里您可以执行很多操作,如监视您的实验和指标等等。
您可以通过 Azure Portal 的 Web 界面创建一个工作区(可参考步骤说明),或使用 Azure CLI(介绍)。
工作区包含了一些 计算 资源。一旦您有了一个训练脚本,可以 提交实验 到工作区,并指定 计算目标 ——这将确保实验在指定的位置运行,并将实验的所有结果存储在工作区,以供将来参考。
MNIST 训练脚本
在我们的示例中,我们将展示如何使用 MNIST 数据集来解决非常传统的手写数字识别问题。以同样的方式,您将能够运行其他任何训练脚本。
我们的样本库包含简单的 MNIST 训练脚本 train_local.py。这个脚本从 OpenML 下载 MNIST 数据集,然后使用 SKLearn 逻辑回归 训练模型并打印结果精确度:
当然,我们使用逻辑回归仅是为了作为示例,并不意味着这是解决这个问题的最好方式……
在 Azure ML 中运行脚本
您可以在本地运行此脚本并查看结果。然而,如果我们选择使用 Azure ML,会给我们带来两大好处:
在集中式计算资源上调度和运行训练,其性能通常比本地计算机更强大。Azure ML 会使用合适的配置将脚本打包到 Docker 容器中。
将训练结果记录到 Azure ML 工作区内的集中位置。要做到这一点,我们需要将下面的代码添加到脚本中,用来记录指标:
此脚本修改后的版本被称为train_universal.py(它比上面呈现的代码更复杂一些),它既可以在本地运行(不使用 Azure ML),也可以运行在远程计算资源上。
为了从 VS Code 中将其运行在 Azure ML 上,请遵循这些步骤:
确保您的 Azure 扩展连接到您的云帐户。选择左侧菜单的 Azure 图标。如果您没有连接,您会看到在右下角显示一个通知以便您连接(见图)。点击它,并通过浏览器登录。您也可以按下 Ctrl-Shift-P,将弹出命令面板,输入 Azure Sign In 进行登录。
然后,您应该能够在 Azure 栏部分的 MACHINE LEARNING 中看见您的工作区:
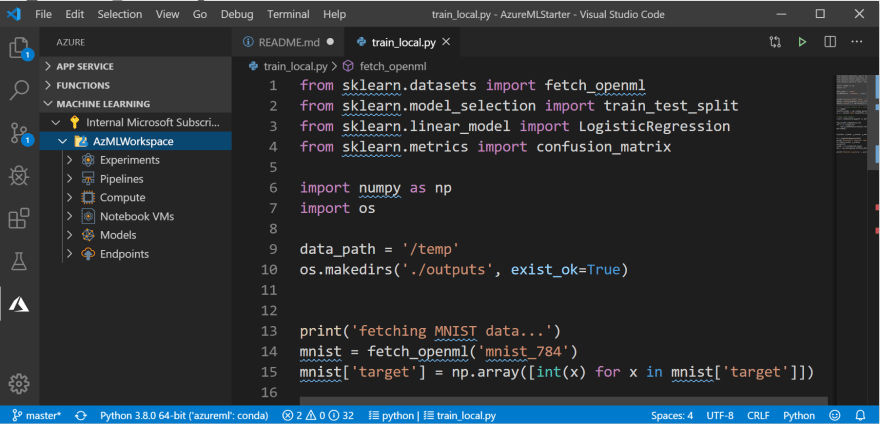
在这里,您会看到工作区中的不同对象:计算资源,实验等。
回到文件列表,并用鼠标右键点击
train_universal.py并选择 Azure ML: Run as experiment in Azure。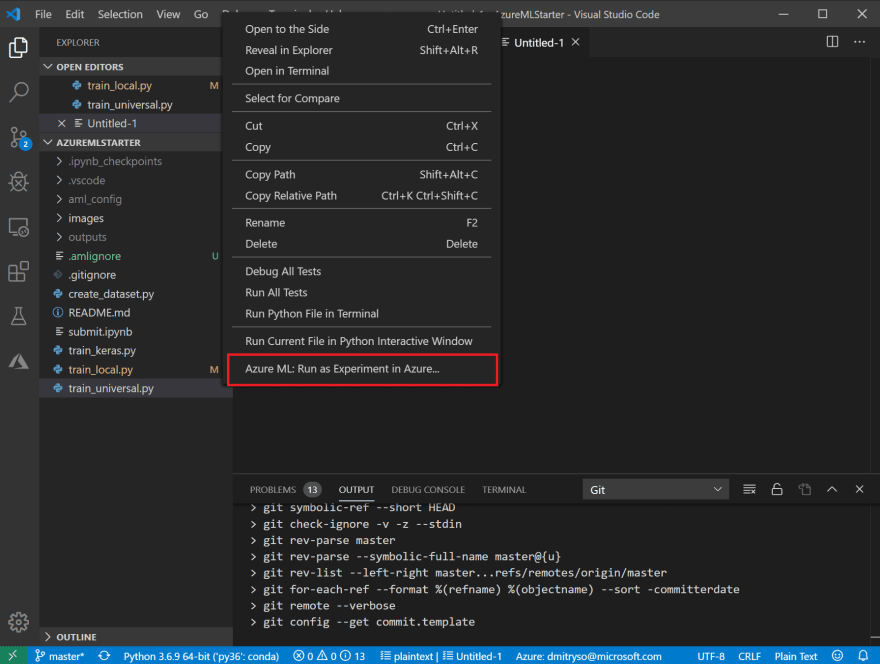
确认您的 Azure 订阅和您的工作区,然后选择创建新实验:



创建新的 Compute 和 compute configuration:
Compute 定义了用于训练/推理的计算资源。您可以使用本地计算机或任何云资源。在我们的示例中,我们将使用 AmlCompute 集群。请建立 STANDARD_DS3_v2 机器的可扩展群集,节点配置为 min=0 和 max=4。您可以从 VS Code 中,或从ML 门户中进行配置。

Compute Configuration 定义远程资源上创建的用于执行训练的容器选项。特别是,它指定所有要安装的库。在我们的例子中,选择 SkLearn,并确认库列表。VS Code 中的 Azure ML 工作区

然后您会看到一个窗口,显示下一个实验的 JSON 描述。您可以在其中编辑信息,例如改变实验或集群名称,并调整一些参数。当您准备好后,点击 Submit Experiment:
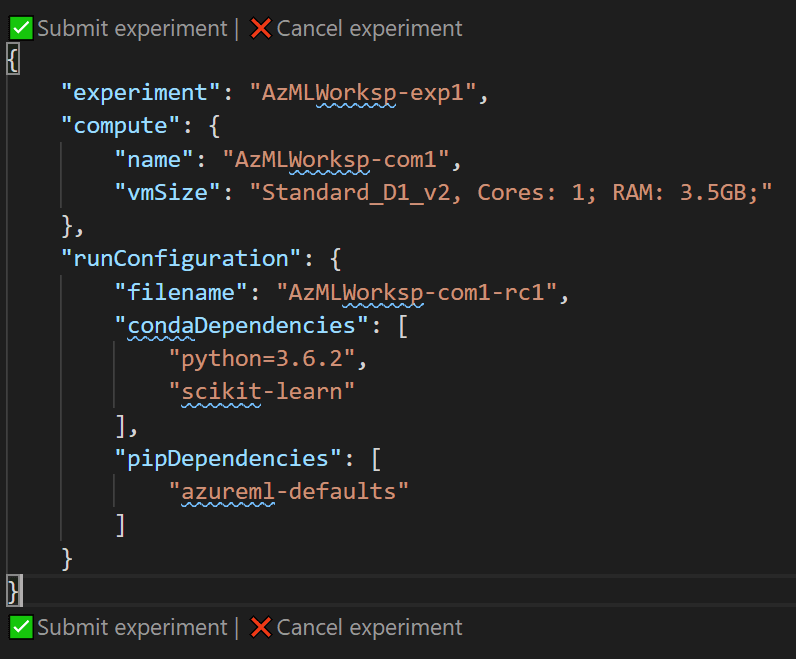
在 VS Code 中成功提交实验后,您会得到一个链接,指向Azure ML 门户中的实验进度和结果。
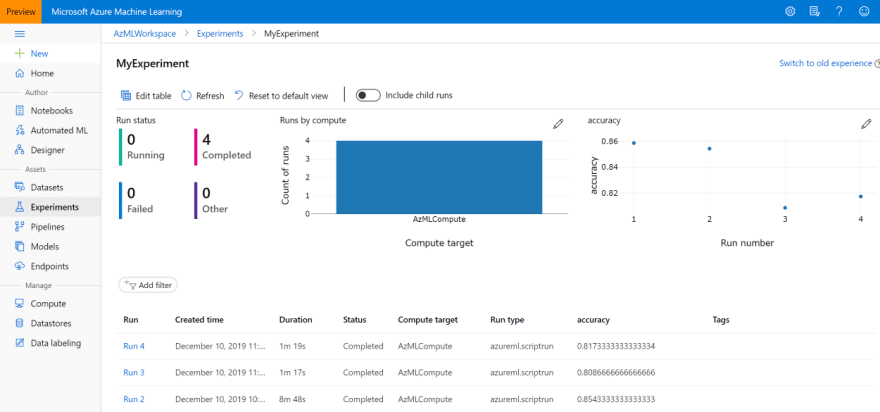
您还可以从 Azure ML 门户 中的 Experiments 选项卡,或 VS Code 中的 Azure Machine Learning 栏找到您的实验:
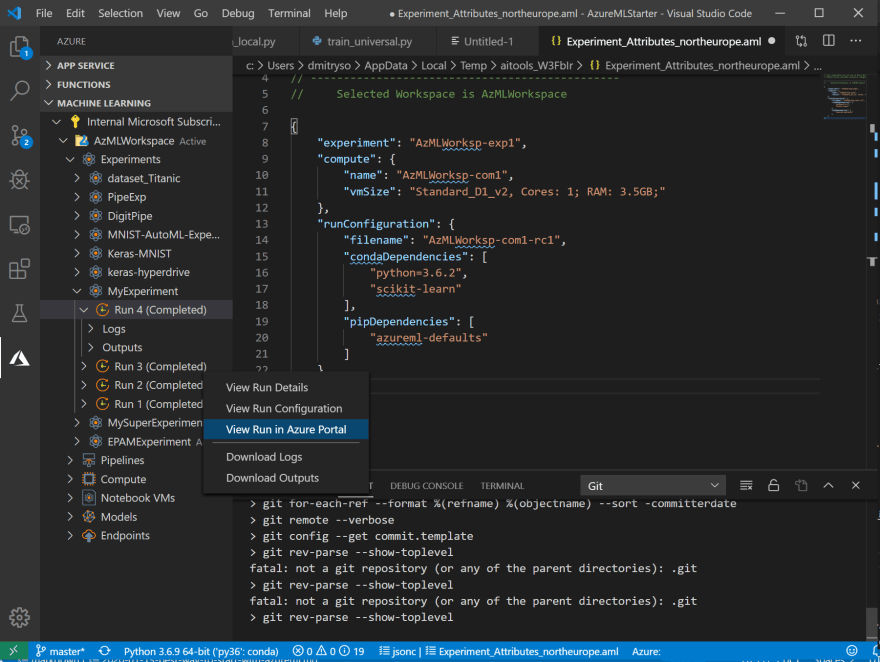
在您的代码调整一些参数后,如果要再次运行实验,这个过程会更快、更容易。用鼠标右键单击您的训练文件,您会看到一个新的菜单选项 Repeat last run ——只需选择它,实验将立即被提交。
然后,您将在 Azure ML 门户中看到所有运行的指标结果,如上面的截图所示。
现在您已了解,将运行提交到 Azure ML 并不复杂,而且一些功能(如从您的运行、模型等存储所有的统计数据)是免费的。
您可能已经注意到,对我们的示例来说,在集群上运行脚本所花费的时间比本地运行要长——它甚至可能需要几分钟。当然,还有一些开销,如将脚本和所有环境打包到容器中,并将其发送到云端。如果群集被设置为自动缩放到 0 节点——可能还会有一些额外的开销,如虚拟机的启动,并且当这个示例脚本小到仅需要几秒钟来执行的时候,这些开销都是显而易见的。然而,在现实的场景中,当训练需要几十分钟,有时甚至更多的时候——这种开销变得几乎不再重要,尤其是对从集群中获得的速度提升来说。
下一步是什么?
现在您已经了解了如何将脚本提交到远程群集上来执行,可以开始在您的日常工作中使用 Azure ML 了。您可以在普通 PC 上开发脚本,然后在 GPU 虚拟机或集群上自动计划执行,并在一个地方保存所有的结果。
不过,使用 Azure ML 不仅仅只有这两个优势。Azure ML 也可用于数据存储和数据集处理——使用不同的训练脚本来访问相同的数据会更加方便。另外,您还可以通过 API 自动提交实验、改变参数——从而进行一些超参数优化。此外,Azure ML 中内置的称为Hyperdrive的特定技术,能够进行更聪明的超参数搜索。我将在下一篇文章中讨论这些功能和技术。
原文链接:

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论