

导读:短视频已经成为信息流行业的风口,成为拉动规模增长的主要驱动力。短视频天然具有信息能量高、用户粘性大、内容丰富等优点,也有视频帧内容难以分析提取、结构化的缺点。如何提高短视频的分发效率和推荐精准度,做到千人千面的个性化推荐,是一个推荐系统的核心能力。基于深度学习的推荐模型,是业界前沿的研究课题;在短视频推荐的业务中,如何利用深度学习算法有效的提升消费点击和消费时长,是推荐模型的核心命题。此次演讲主要讲解视频推荐模型在多目标和模型优化方面的进展。包括以下几个模块:
业务和系统
基于 Graph Embedding 的多目标
基于 WnD 的 Boosting 算法
未来规划
业务和系统
短视频业务背景、系统结构

我们的业务主要是做视频推荐,嵌入到 UC 浏览器中做国内信息流:
UC 从工具型产品转型至内容分发平台,信息流业务成为 UC 的第二大引擎;
短视频已经成为信息流行业的风口,成为拉动规模增长的主要驱动力;
短视频播放时长已经超过图文,极大的增强了信息流的用户粘性;
算法的持续优化与迭代提高了短视频流量分发的效率和准确度。
右图是视频推荐的界面,其背后的视频推荐系统分为三个结构,第一个是召回模块,第二个是粗排的模型,第三个是精排的模型。从召回 -> 粗排 -> 精排,Item 的数目从多到少,推荐的准确性从低到高。
技术演进史
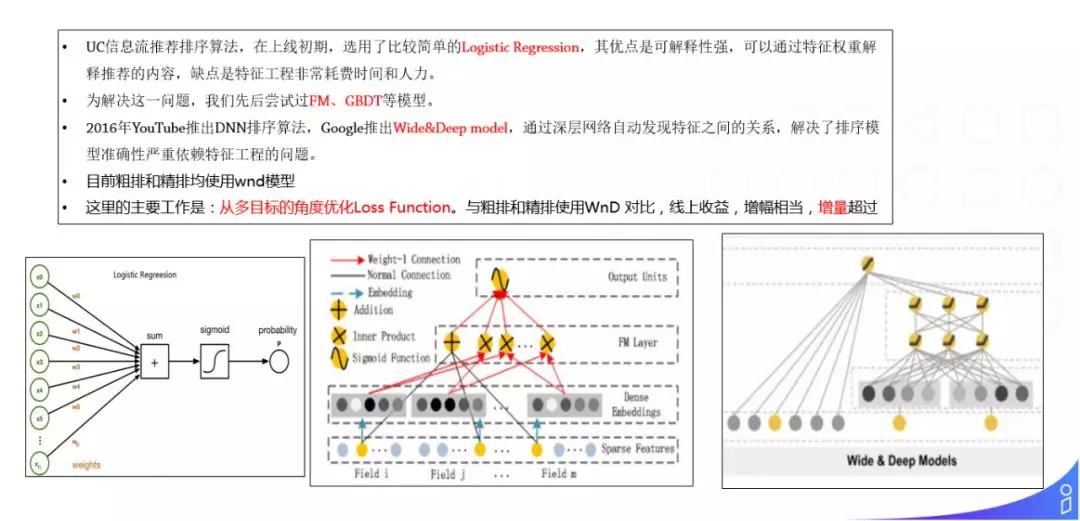
我们在视频推荐上,尝试过多个推荐方案:
最早用的是 LR ( 如图,左下角 ),LR 的缺点主要是在特征工程上会耗费很大的人力;
后来我们又尝试了 GBDT 和 FM ( 如图,中间部分 ),但是这些模型在泛化性上相对较弱;
最后我们采用了 Wide & Deep model ( 如图,右下角 )。
这里主要介绍的工作是:从多目标的角度优化 Loss Function。与粗排和精排使用的 WnD 对比,线上收益增幅相当,增量超过。
多目标在视频推荐模型中的应用
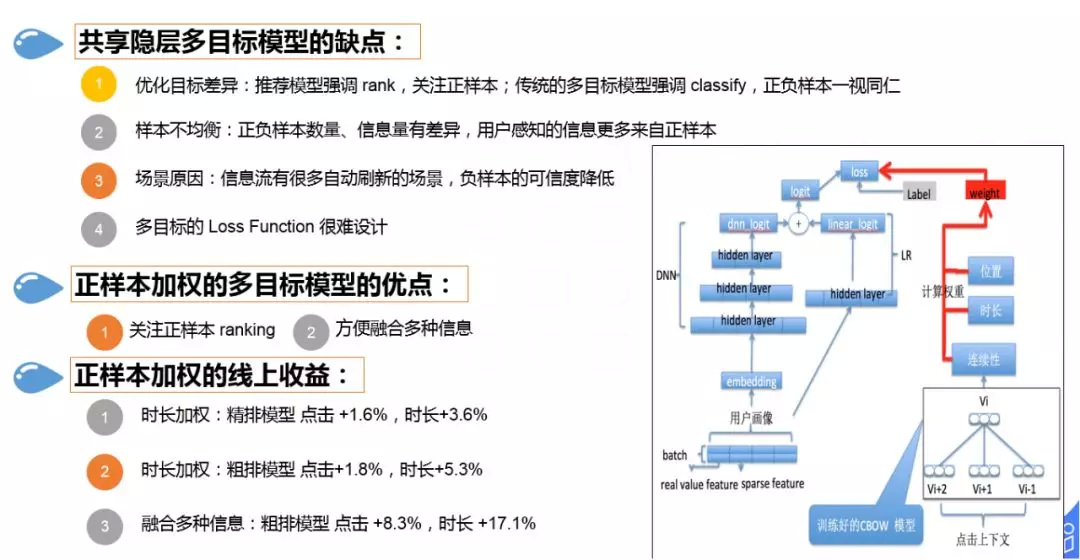
常规的多目标是共享隐层的 soft 多目标模型,我们使用的是基于正样本加权的模型。
共享隐层多目标模型的缺点:
① 优化目标差异:推荐模型强调 rank,关注正样本排序;传统的多目标模型强调 classify 分类,正负样本一视同仁;
② 样本不均衡:在信息流中正负样本数量、信息量存在差异,用户感知的信息更多来自正样本;
③ 场景原因:信息流有很多自动刷新的场景,负样本的可信度降低
④ 多目标的 Loss Function 很难设计,市面上的多目标方案大多是一个主目标和一个辅助的目标
我们使用的正样本加权的多目标模型的优点:
① 关注正样本 ranking
② 方便融合多种信息
我们的方案最终在线上取得了不错的效果。
基于 Graph Embedding 多目标融合的 WnD 模型优化
优化 WnD 模型 logit 配比
信号正向传播
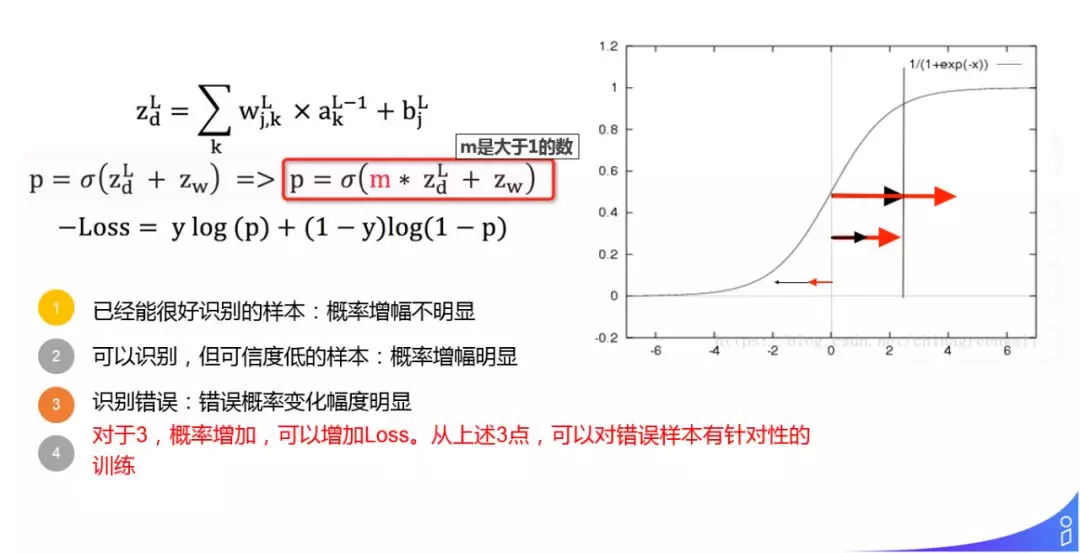
首先是 WnD 模型的一个小的优化,我们知道 WnD 分为 LR 侧和 DNN 侧,LR 侧使用的优化器是 FTRL,它的优化速度非常快,在数千万 DAU 的场景下,只需采用一次流式训练,在这样的场景下 DNN 对样本的训练很难迭代多次,这时 WnD 模型更倾向于使用 LR 侧的 logit。基于这样的原因,我们想能不能增加 DNN 侧的 logit,提高系统的准确度,大体就是这样的 motivation。
具体实施的时候,见图中红框部分,d 指 DNN,w 指 LR,zd 指 DNN 最后一个隐层的输入,zw 指 LR 最后一个隐层的输入,我们在 DNN 侧乘以了一个系数 m,这就是大体的一个优化方向:
① 对于已经能很好识别的样本:概率增幅不明显(如右图最上部分的箭头,已经进入饱和区,所以增加不明显)
② 对于可以识别,但可信度低的样本:概率增幅明显(如右图中间部分的箭头)
③ 识别错误:错误概率变化幅度明显(如右图最下部分的箭头)
④ 对于 ③,概率增加,可以增加 Loss,从上述 3 点,可以对错误样本有针对性的训练
梯度反向传播、Adagrad 优化器

这是一个反向传播公式的推导,上面讲过增加 DNN 侧的 logit 会增加 Loss,图中标红的表示 Loss 会增大,同时,m 可以提出来作用到 Adagrad 优化器时:
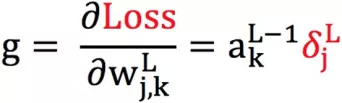
也是相应增加的。
基于时长加权的多目标融合的 WnD 模型优化

这部分的 motivation 是我们在做模型训练时,做的还是二分类的一个分类模型,这时点击观看的时长没有用到。因此,我们利用用户观看时长,来提升推荐效果。
这里设计了一个 weigh 计算方式:对于某个视频用 u_play_len 这个视频的历史观看总时长 / avg_item_history_view_len 这个视频历史的平均观看时长,用 max 做了一个规范化,求得 weigh,且 weigh>1。图中统计了右边视频随着时长增加,用户观看数量的一个变化情况。有了 weigh 我们可以对 WnD loss function reweight:
① 如果某用户观看 Item 时长低于历史平均时长,权重为 1,那么原来的既得收益 ( ctr ) 不会变化。
② 如果某用户观看 Item 时长高于历史平均时长,权重为 1.x,那么此类视频加权充分训练,会被 Ranking 比较高的分数,增加时长收益。
基于 Graph Embedding 多目标融合的 WnD 模型优化
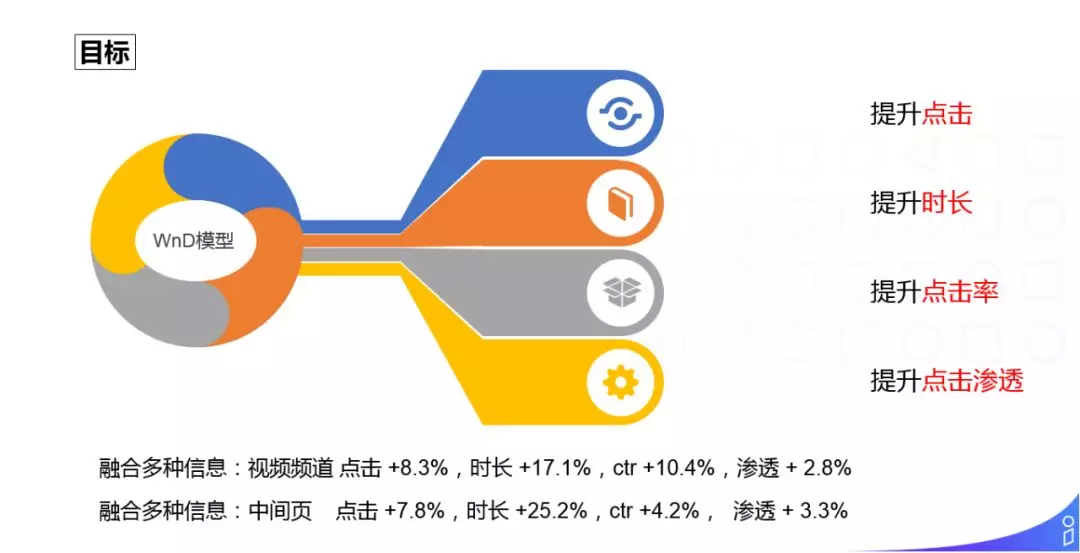
基于 Graph Embedding 多目标融合的方案中,多目标包括:提升点击、提升时长、提升点击率、提升点击渗透。
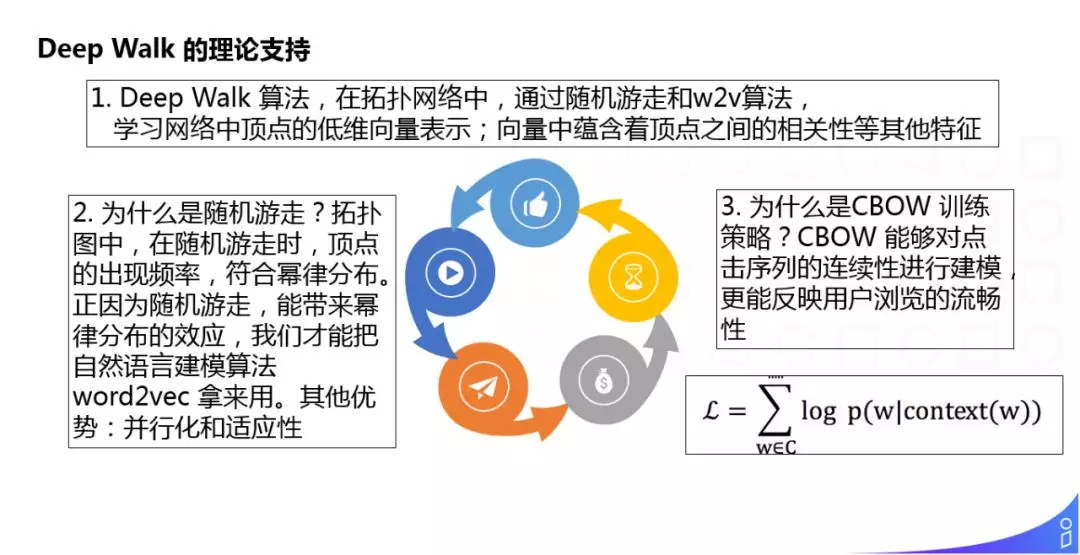
首先如何取到一个 Item Embedding?我们采用的是 Deep Walk 算法,在拓扑网络中,通过随机游走和 w2v 算法,学习网络中顶点的低维向量表示,向量中蕴含着顶点之间的相关性等其他特征。真正训练的时候采用的是 CBOW 训练策略,其 Loss Function 如下:
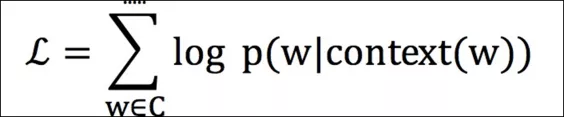
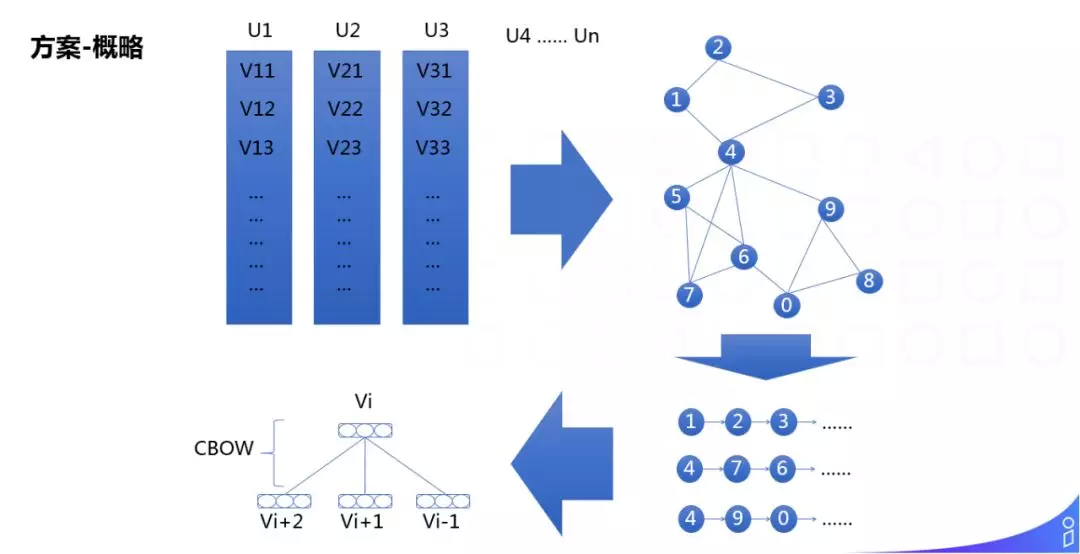
我们的方案是,从用户日志中挖掘出每个 User 的点击序列,根据点击序列建立无向图,然后在每个节点随机游走形成句子,最后经过 w2v 的训练策略,得到每个 Item 的 Embedding 表示。
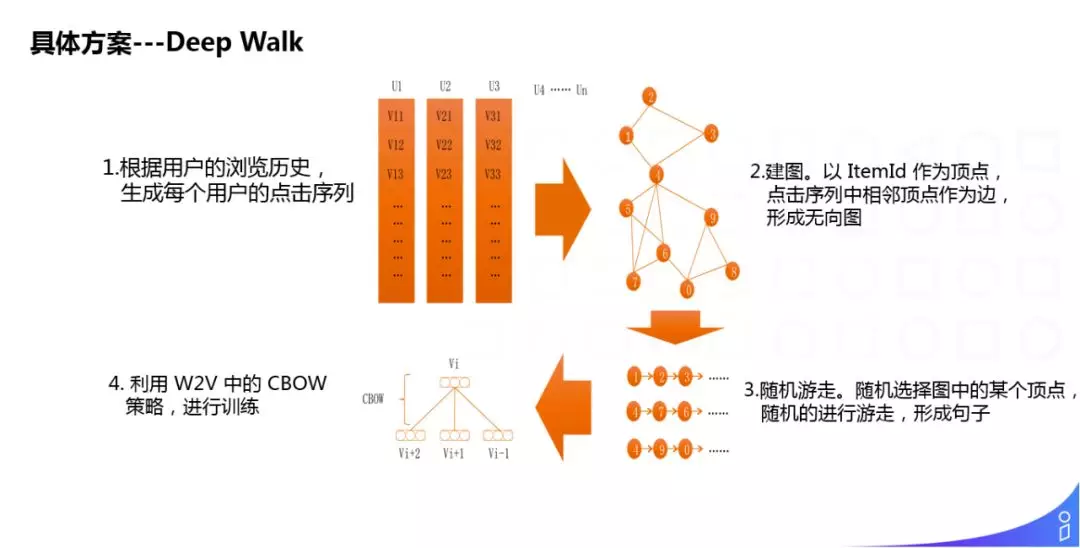
具体方案:
① 根据用户浏览历史,生成每个用户的点击序列;
② 建图,以 ItemId 作为顶点,点击序列中相邻顶点作为边,形成无向图;
③ 随机游走,随机选择图中的某个顶点,随机的进行游走,形成句子;
④ 利用 w2v 中的 CBOW 策略,进行训练。
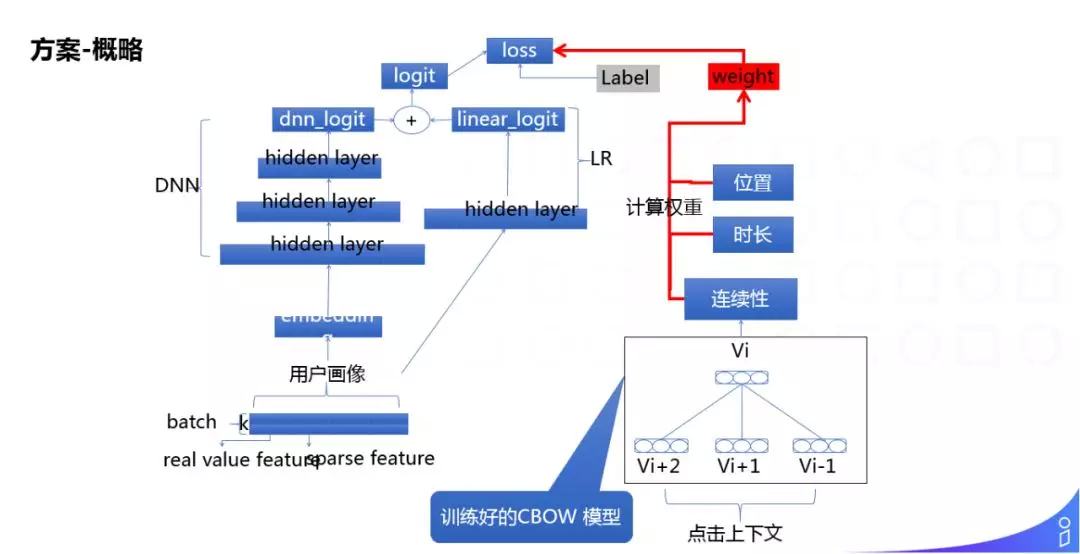
有了 Item Embedding 之后,做 Loss Function 的 reweight,reweight 时加入了位置、时长、连续性 ( 通过 Graph Embedding 计算得出 ) 等信息。

Loss Function reweight 方式是在正样本前面乘一个系数 di,j,然后负样本保持不变,如果拿掉系数,是一个标准的交叉熵公式,di,j 考虑了观看时长、观看连续性、Item 的位置等综合信息来得到的,它们之间用的是 α、β、γ 线性加权得到的:
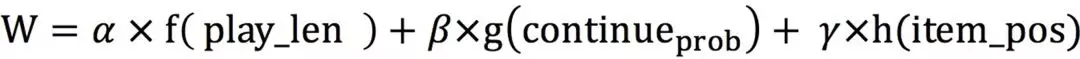
f(play_len)是关于时长的函数,由播放时长的分布估计得出:
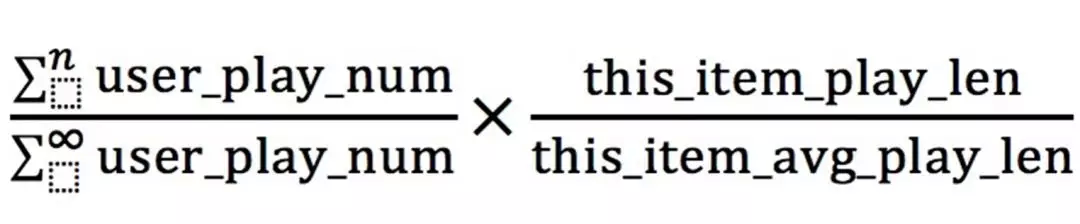
左下角为用户播放数的累加,它的上面是观看到某一时长 n 的用户播放数的累加,右边侧延续了时长加权公式的模板。
连续性
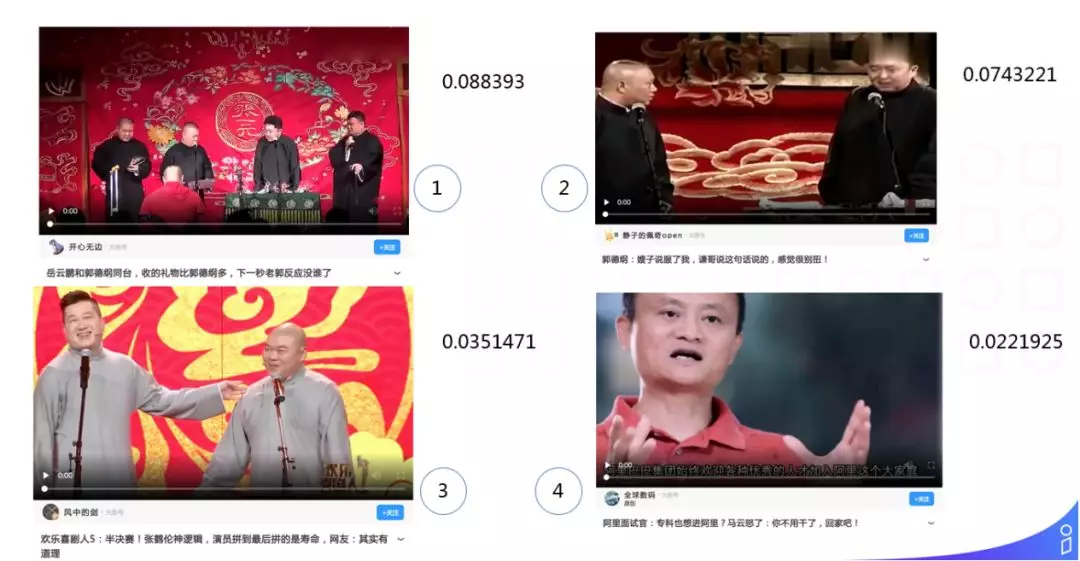

接下来讲一个连续性的实际案例:
①②③④⑤⑥⑦⑧这是用户的点击顺序,对应的分数是基于连续性 w2v 算法计算出来的分数,我们认为分数较高的视频很容易带领用户继续看下去,把它称作一个连续性的信息,我们对此类信息进行加权,希望能够带动用户整体的消费。
基于 WnD 的 Boosting 算法
模型
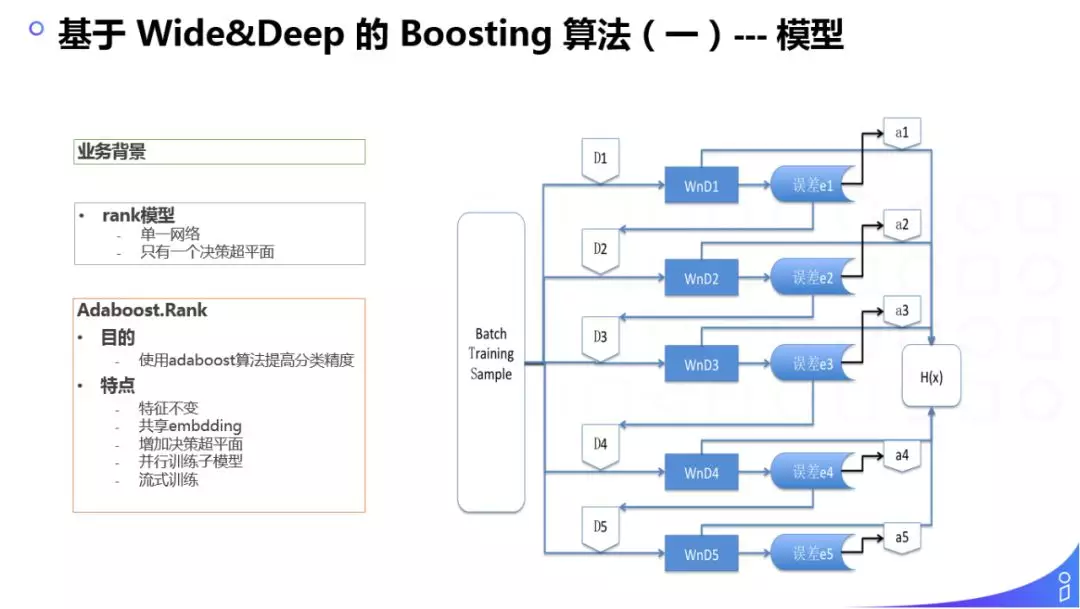
由于 Wide&Deep 建模方案是一个二分类,理论上只有一个分类超平面,很容造成样本错分。我们理想的方案是,虽然是二分类,但是我们可以有多个决策超平面,所以我们用了 Boosting 算法,综合 5 个 Wide&Deep,进行二分类。其应用场景是训练的实时流,每次训练都是一个 Batch ( 相当于在线训练 ),中间融合了 5 个 Wide&Deep 模型 ( 5 个模型的特征是不变的,共享 Embedding 隐层,采用的是并行计算 ),最终生成一个强分类器。
Adaboost:

这是 Adaboost 算法的标准模式:
① 初始化训练数据的权值分布
② 使用权值分布 Dm 的训练数据集学习,得到子分类器 Gm(x)
③ 计算 Gm(x) 在训练数据集上的分类误差率
④ 利用分类误差率计算基本分类器在最终分类器中所占的权重
⑤ 更新每个样本的权重,继续训练下一个模型,如果有 5 个子模型就训练 5 个子模型
⑥ 最终综合每个子模型的权重和预测值,得到一个强分类器
算法

具体的算法有几个不同点:
第一个是误差项的计算方式,原先标准 Adaboost 算法误差项计算用的是加权指标函数:
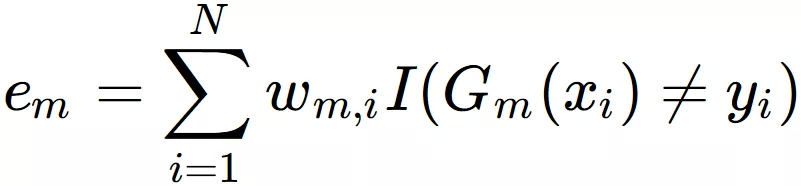
我们的方案采用的是 AUC 加权的误差项:
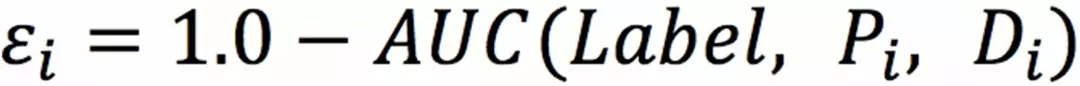
每个子模型的权重,由于是在线训练,所以采用的是迭代的方式:
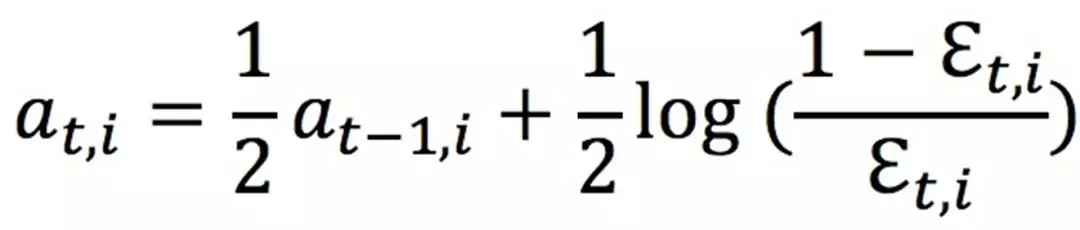
每次用上一个 Batch 1/2 权重加上此次误差项的计算。
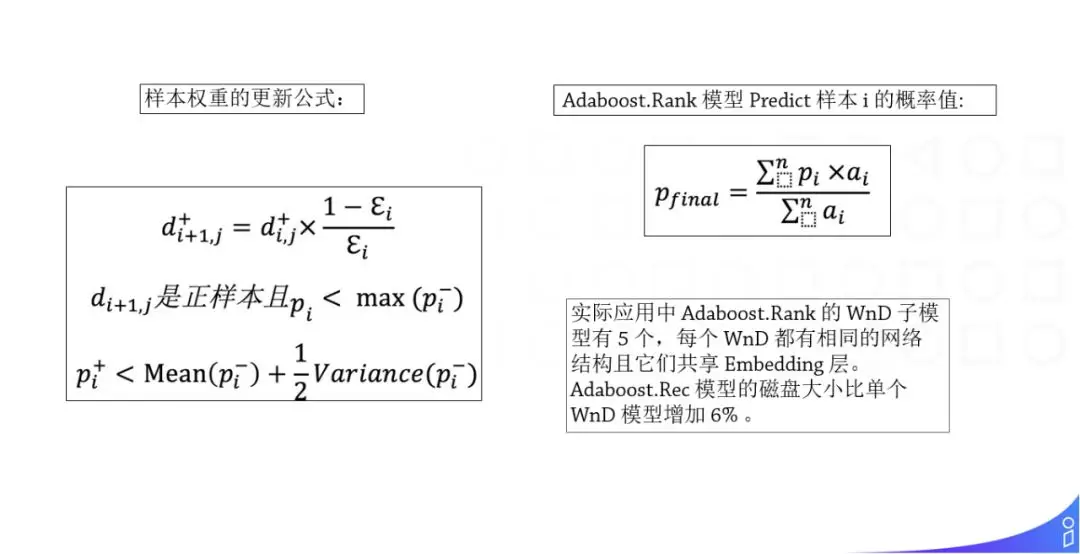
第二个是样本权重的更新,样本权重更新时只对正样本进行更新,而标准的 Adaboost 是对正负样本都进行更新的:
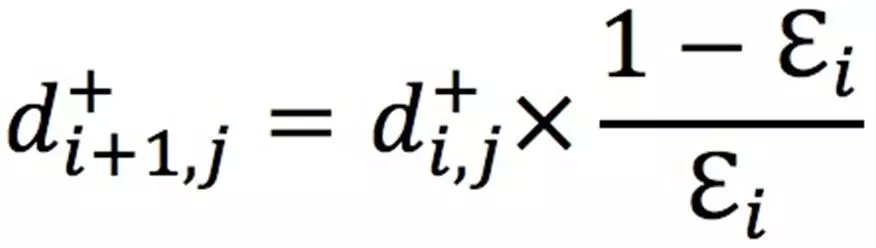
di,j+ 指的是这个样本上一个子模型的权重,εi 是误差项。
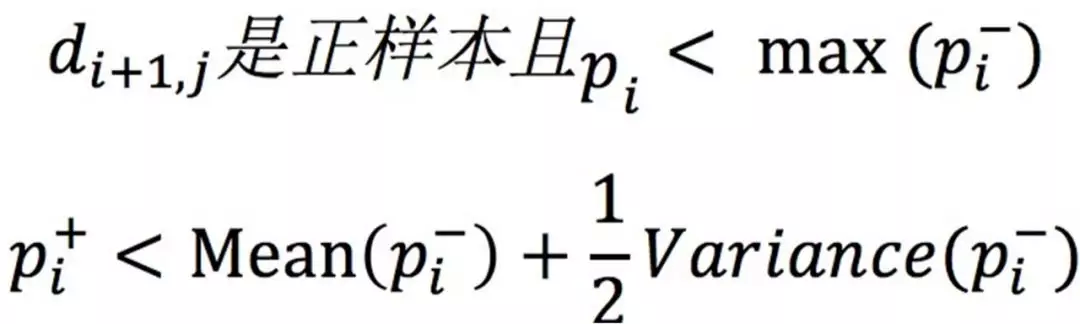
这是样本的更新方式。
最终强分类器的预测和 Adaboost 标准模型差不多:
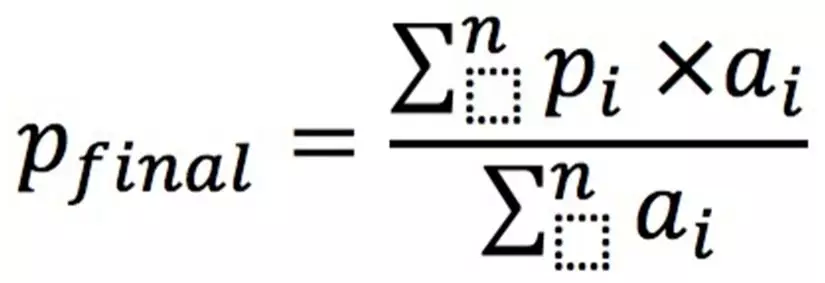
也是线性加权然后除以总的权重。
实际应用中 Adaboost.Rank 的 WnD 子模型有 5 个,每个 WnD 都有相同的网络结构且它们共享 Embedding 层,Adaboost.Rec 模型的磁盘大小只比单个 WnD 模型增加了 6%。
在短视频推荐中的应用
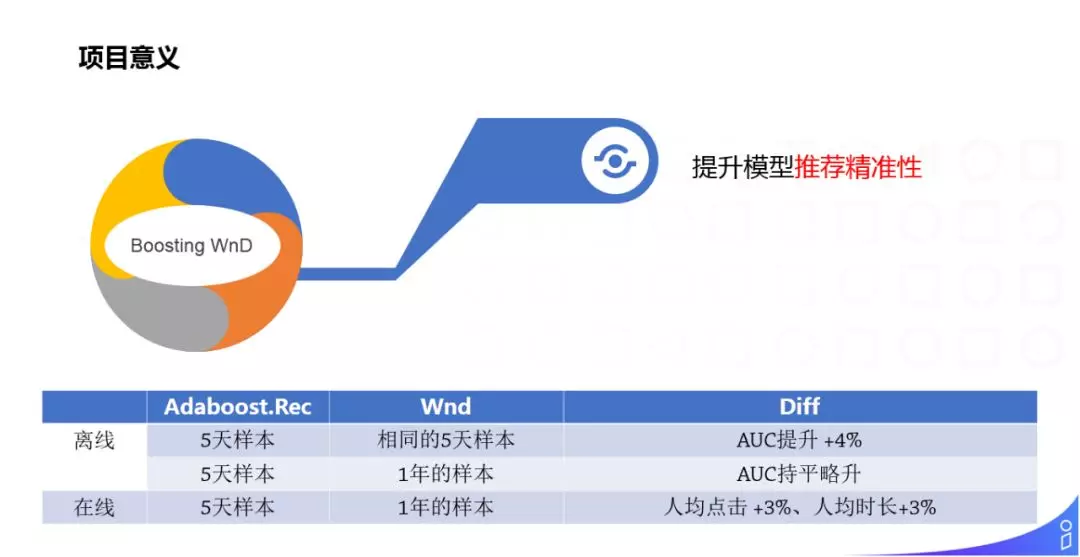
方案的实验效果和 WnD 模型对比如上,提升了模型推荐的精准性。
未来规划
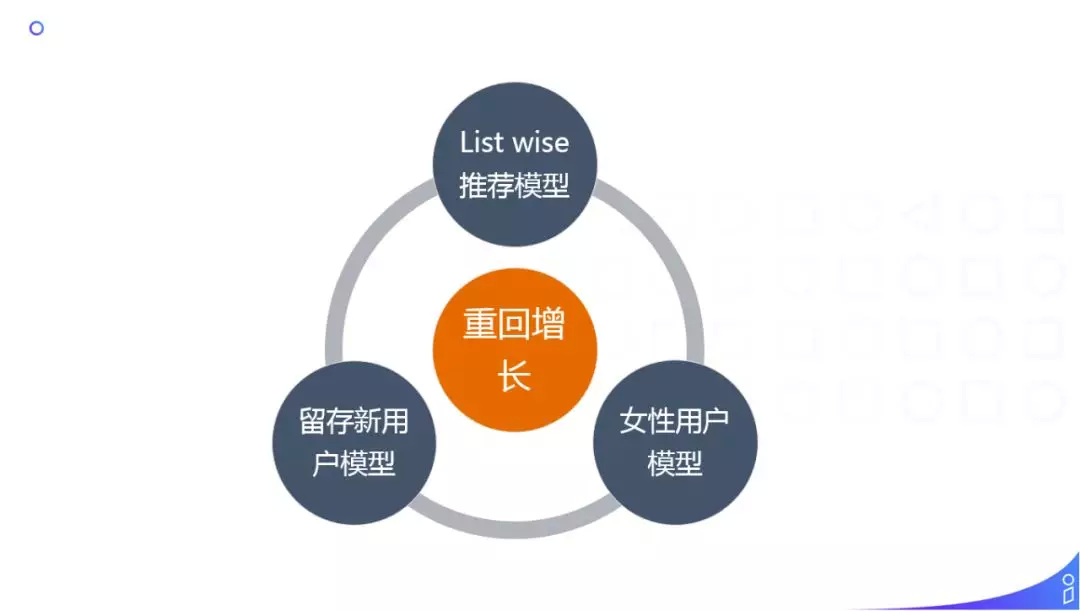
未来的规划:
现在的推荐都是基于 point wise 的推荐模型,每次都是预测单个 Item 的分数,未来希望可以一次给用户推荐一刷的结果。
因为每天都有新用户进来,所以我们希望建立一个留存新用户模型,来留住新用户。
UC 信息流目前的主要消费群体为男性用户,在推荐的偏好上模型和策略都偏向男性用户,我们希望可以留住更多的女性用户。
作者介绍:
语露
阿里巴巴 | 高级算法工程师
本文来自 DataFun 社区
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论