
Spanner 支持事务的四个特性 ACID,2012 年的《Spanner: Google’s Globally-Distributed Database》论文,并没有明确描述 ACID 分别是怎么实现的,只是描述了 C 特性实现的一些内容,而 D 特性简单通过描述而被提及 。 在支持事务的特性上,论文特别提及了:
外部一致性事务(externally consistent transactions):外部一致性,是分布式的经典问题,如下将详述。2. 无锁的只读事务(lockfree read-only transactions):凭借 MVCC 的快照技术,Spanner 实现了无锁的只读事务。3. 对过去数据的无阻塞读(non-blocking reads in the past):类似无锁的只读事务,只是快照点的建立所依赖的时间点不同。 从并发访问控制策略上看,Spanner 采取了悲观策略,对于写操作,采用了基于封锁的并发访问控制技术,而对于读类型的操作,采取了 MVCC 技术,即图 1 中的“lock-free”所标识的内容。下文将对以上内容做详细介绍。
一、读操作的分类和意义
对于读类型的操作,有三种,除此之外的事务,都归属于“Read-Write Transaction”。
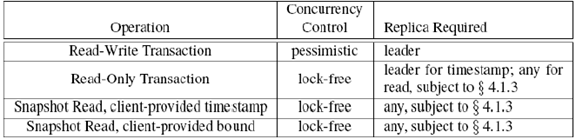
图 1 Spanner 读写操作使用的并发访问控制技术图
Read-Only Transaction:预先声明事务是只读的,Spanner 会利用 MVCC 技术为本事务生成一个快照(snapshot,快照点是 Spanner 系统自动提供的),快照标识了本事务开始时刻、所有活动的事务,从而能够帮助本事务识别自己应该能读取那些数据(”Read-Write Transaction“会生成新版本,只有本事务之前已经提交的事务生成的数据才可以被本事务读取到)。只读事务有机会从 follower 的副本(数据上的时间戳值相对快照的快照点而言、足够新的副本)中读取数据从而减少了 leader 的压力。
Snapshot Read:快照读,但快照点不是 Spanner 系统自动提供的,而是由用户指定的,细分为如下两种:
a: Snapshot Read, client-provided timestamp:由客户端提供快照点的值
b: Snapshot Read, client-provided bound:由客户端提供快照点的范围。
Read-Only Transaction 和 Snapshot Read 对数据库的数据只读取不写所以数据的状态不会受到影响,因此即使在某台机器上读了一部分的数据,之后机器失效,仍然可以换机器用一样的时间戳重试,结果不会有变化,这点可以保证做到 2017 年论文中描述的“瞬态故障情况下查询重新执行(query restarts upon transient failures)”。
有了这三种读操作类型,可以方便地利用 follower 中的副本对外提供查询功能,从而减少对“participant leader”节点的读请求压力。
另外,三种读操作基于使用快照实现的 MVCC 技术,数据项上保存有全局提交时间戳,从数据项的角度确保了全局一致性读。
二、外部一致性实现原理
Spanner 还支持外部一致性(external consistency,即 linearizability),这和全局一致性读密切相关,但也和 Truetime 机制以及 Spanner 的提交、读取机制相关。
举一个分布式系统中一致性的例子:
假设数据项 X 要从 Node1 被复制到 Node2。
客户端 A 事务 T1 写节点 Node1 上的数据项 X。
一段时间后,客户端 B 事务 T2 从 Node2 上读取数据项 X(这是朝从副本读取数据)。
那么客户端 B 是否应该读取到客户端 A 写到 Node1 上的数据项 X 的值呢?
Spanner 保证外部一致性约束(external consistency invariant):
如果 T2 开始前 T1 已经提交,则 T1 的提交时间戳小于 T2 的提交时间戳,这意味着事务 T2 一定能够读到事务 T1 提交过的数据,这是典型的读已提交问题(看似关联的问题包括:ANSI SQL 标准定义的读已提交隔离级别;可恢复性 Recoverability 所要求读已提交这样的行为不会引发级联回滚)。
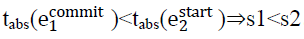
图 2 事务间时间戳
因事务启动时间的先后使得不同事务读写这个事情,在单机数据库系统中,不是什么问题,但是到了分布式系统中,因为读取数据有了多种选择,比如从“participant leader”的主副本上读或者从其他的从副本上读,是有差异的(其他从副本的数据因写多数派协议影响,有可能还没有被及时更新,造成主副本和其他从副本在某时刻数据不一致)。
那么,Spanner 是如何保证图 7 在分布式环境中因读从副本而做到“读已提交”的外部一致性的呢?外部一致性还需要两条规则来确保:Start 规则和 Commit Wait 规则。
首先,对于一个写操作 Ti 而言,担任协调者的领导者(coordinator leader)发出提交请求的事件。
其次,满足 Start 规则:coordinator leader 给写事务 Ti 指定的提交时间戳 Si 满足如下条件:Si ≥ TT.now().latest
其中 TT.now 在请求之后调用,这样使得事务 Ti 的提交时间一定比提交请求晚一个时间段。
再次,满足 Commit Wait 规则:这个规则是说,提交的真实时间戳要大于/晚于提交事件的时间,也即 TT.after(Si)为真,这样把提交操作再次推迟了一个时间段。即有如下条件成立:
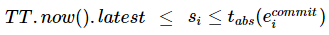
图 3 外部一致性保证的条件图
这两个规则保证了外部一致性,可以从如下推导看到逻辑过程,如下图所示,最终 s2 晚于 s1 则 s2 能看到 s1 提交的数据:

图 4 外部一致性规则推导图(使得并发操作全序化,非偏序)
另外,确保读事务 ACID 中的“C”一致性和外部一致性,还依赖于稳定精准的 Truetime 给定的事务的单调递增时间戳规则。如原论文 4.1.3、4.1.4 节所述及图 5 所示。该规则和图表明了读操作相对于以 Poxos 组为写单位的写操作的时间戳提交点(注意,影响着外部一致性的是以 Poxos 组为写单位),确保读一定发生在一个可用的写事务提交之后(这是假如当时有并发的写事务存在。如果没有并发写事务,都是并发的只读事务则更不会有不一致问题所以不必对此种情况进行讨论)。本质上是 Spanner 利用 Truetime 在为所有并发事务线性排了队,即在分布式、多副本的前提条件下,使得所有事务满足了“可串行化”理论,因而得以保证事务 ACID 中的“C”一致性和外部一致性。
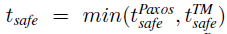
图 5 在某个时间戳下的读操作“安全时间戳”图
另外,外部一致性是允许向从副本读取数据时,从副本上有足够信息能够帮助判断主副本的数据相关的事务状态信息,这点细节参见 4.1.3 节。
基于以上分析,作者认为,外部一致性,其实是读操作是否满足全局一致,因此可以称其为“读外部一致性”,以明确区别于写事务操作。
另外,有的分布式数据库系统,象 Spanner 一样提供了 Paxos 组(主副本、多个从副本),但只允许在主副本上读写数据,这样就会避免这里谈到的问题,但是,也限制了并发使得效率降低。因此可以看出 Spanner 这样的设计的妙处所在。
三、写操作一致性的实现原理
Spanner 的写事务的分布式实现,依据的是什么机制?这个问题,其实是一个难题。
在 Spanner 的论文里,如图 6 所示,“Read-Write Transaction”的并发访问控制技术使用的是悲观机制,并且论文里说“Reads within read-write transactions use wound-wait to avoid deadlocks”,这两个明确在说,Spanner 是采用基于封锁并发访问控制机制来实现事务的一致性所以才需要使用“伤停等待”算法来解决死锁问题。这就会让我们联想到 2PL,联想到单机数据库如 Informix、Oracle、MySQL/InnoDB 都使用了 2PL 的 SS2PL 算法来解决事务的一致性问题。那么,Spanner 是否也使用了 SS2PL 算法呢?
在 Spanner 的论文里,还有如下表述:
Like Bigtable, writes that occur in a transaction are buffered at the client until commit. As a result, reads in a transaction do not see the effects of the transaction’s writes. This design works well in Spanner because a read returns the timestamps of any data read, and uncommitted writes have not yet been assigned timestamps.
这段话,看起来又是别有洞天:写操作缓冲在客户端,直到提交。这样的方式,是乐观机制的行为,偏偏 Spanner 的论文把自己描述为悲观机制,这是一个值得注意的地方。之后,又有下文:
When a client has completed all reads and buffered all writes, it begins two-phase commit. The client chooses a coordinator group and sends a commit message to each participant’s leader with the identity of the coordinator and any buffered writes.
这段话,表明 Spanner 事务提交,跨节点使用了 2PC,提交信息发给所有参与本事务的节点中的 leader 角色,并指明哪个 leader 是协调者。
之后,参与者获取写锁,如果获取到写锁,则选择一个“单调递增”的、比历史给出的时间戳更大的时间戳值赋值作为两阶段提交的第一阶段的时间戳值。如下:
A non-coordinator-participant leader first acquires write locks. It then chooses a prepare timestamp that must be larger than any timestamps it has assigned to previous transactions (to preserve monotonicity), and logs a prepare record through Paxos.
再之后,协调者开始获取写锁,记录提交日志,同步到自己的 Paxos 组内,并作提交等待,目的是让提交时间度过一个网络延迟的事务提交安全期,以获得一个安全的事务提交的时间戳值:
The coordinator leader also first acquires write locks, but skips the prepare phase. ……Before allowing any coordinator replica to apply the commit record, the coordinator leader waits until TT.after(s)…
而安全的提交时间戳值,Spanner 是由主副本(leader replica)简单地按照递增的顺序指定的。当然,这之外还需要一个约束:在切换主副本(leader replica)所在的 leader 时,保证跨主备切换下的时间戳也是递增的。此约束在论文中表述为“单调不变性(monotonicity invariant)”。这是确保时间戳单调递增。
当获得安全的提交时间戳值后,协调着开始两阶断提交的第二阶段,通知参与者发起提交,参与者提交并记录提交日志并复制日志给同组的副本,最后通知客户端事务成功与否。
再之后,才进行锁的释放工作。这意味着并发访问控制机制是 SS2PL。
All participants apply at the same timestamp and then release locks.
对于“Read-Write Transaction”事务中的读操作,论文描述:
The client issues reads to the leader replica of the appropriate group, which acquires read locks and then reads the most recent data.
客户端对于一个 Paxos 组,向该组内领导者副本即主副本发起读操作,获取读锁。这点很重要,一是在“Read-Write Transaction”事务中的读操作,与基于快照的读操作和只读操作读取的副本主体是不同的,二是读操作也加锁。这也是分布式系统中全局一致性的一个体现,读写事务只能在主副本发起才能保证一致性。
总结 Spanner 的读写事务处理机制,我们可以看到:
第一,在读写事务中,Spanner 混用了乐观和悲观机制,把两者结合起来:
读在提交点之前:自由读取,不存在读写冲突。
读在提交点之后:如是并发写事务的提交点,存在读写冲突,提交点推迟,线性把事务排了队,解决了读写冲突。
a. 先是乐观策略,但乐观阶段中夹杂了读锁而悲观了。
b. 提交阶段采取悲观策略,时间戳是提交时间戳而不是事务启动时间戳,这使得并发的读操作只需要和读写事务的提交点比较即可:
提交时刻,写操作加锁,使得并发事务排序,实现了序列化保证了 ACID 中的 C。
第二,在悲观机制中,使用了 SS2PL,统一释放乐观策略阶段施加的读锁,释放 SS2PL 过程中施加的写锁。
第三,Spanner 采取两阶段提交解决了跨节点的数据一致性问题,此两阶段融合在了悲观机制中的 SS2PL 算法过程中。
第四,提交阶段,给写事务赋予一个时间点,是通过图 4 的方式保证,这样 TrueTime 发生作用,致使外部一致性得到保证。
四、Truetime 事务处理机制的缺点
Spanner 的处理机制,是否存在弱点呢?
如前三节所述,Spanner 事务处理的本质,是线性排序。
这意味着,在一个时间轴上,充满了事务提交点。而 Truetime 的计算特性,把一个事务的生命周期划分为“一个线段”,即使提交阶段才算做是生命起始期有效缩短了事务在时间轴上的线段长度,但是,这个线段长度最小也得是“2ε”;而且并发事务在时间轴上占据的时间段不重叠。所以可以算出,每秒事务的吞吐量=1/(2ε),而ε平均值是 4ms(如果使用 NTP,时间的延迟误差在 100ms 到 250ms 之间,远大于一个ε),所以:
每秒事务的吞吐量 = 1/2ε = 1/0.008 = 125 个事务/秒
如果ε有希望减小,如缩小 200 倍,则一个 Spanner 集群的一个 Paxos 组也就是每秒两万五千个事务。这个值,其实不高。
另外,如果一个长事务总不提交,则后面的事务不能得到提交,解决办法是不支持过长事务,或者作为一个缺陷告诉用户只能使用短事务哦,否则发生问题概不负责之类的云云。
最后,我们要表明的是,如果不是写同一个数据项的并发事务(注意是并发不是并行哦),则吞吐量,是不应当这么计算的,不要因此处的讨论而引发不必要的争议。
作者介绍:
李海翔,网名“那海蓝蓝”,腾讯金融云数据库技术专家。中国人民大学信息学院工程硕士企业导师。著有《数据库事务处理的艺术:事务管理和并发访问控制》、《数据库查询优化器的艺术:原理解析与 SQL 性能优化》、《大数据管理》,广受好评。
本文转载自腾讯云数据库。
原文链接:
https://cloud.tencent.com/developer/article/1442909

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论