几乎所有现代应用程序都要通过数据库实现数据持久化。数据库访问层经常要对严重的性能问题负责。一旦遇到数据库的问题,大多数人开始研究数据库本身。正确的索引和数据库结构对提高性能非常关键。然而,很多时候糟糕的性能或可伸缩性问题的罪魁祸首却是应用程序层,而不是数据库。
应用程序层控制并驱动数据库的访问。这一层的问题不能从数据库上得到补偿。所以要想得到高性能和扩展性,数据访问逻辑的设计非常关键。虽然数据库驱动的应用程序中使用情况各不相同,但所有问题能够归结到几个反模式上。分析你的应用程序中是否使用了下列的反模式,并且解决他们,能够以最小的代价简单让你的软件更快、 更稳定。
对象 / 关系映射的误用
对象 / 关系映射已经成为现代数据库应用程序的中心部分。对象 / 关系映射让人从面向对象软件中翻译和访问关系型数据的重担中解脱出来。它们向应用程序人员隐藏了数据访问大部分的复杂逻辑。由于开发人员更专注于实际的业务逻辑,而不是基础架构细节,会使得生产效率更高。对象关系层不需要看到细节就可以轻松操作复杂的对象图。这经常让人产生错误的印象,认为这些框架让人从设计数据访问逻辑的重担中解脱了出来。
开发人员经常认为数据访问框架很容易就把一切搞定了;然而,不理解内部工作机制就使用对象 / 关系映射框架,很多时候会导致程序性能低下。主要有两个误解引起了这些问题──加载的行为和加载的时间。
对象 / 关系映射基于每个对象加载数据。这意味着只有当一个对象被请求或者访问时,需要的 SQL 语句才会被创建并执行。这个原则非常普遍,乍一看多数情况下没问题。但同时它也常常是性能和扩展性问题的原因所在。
让我们看一个简单的例子。在一个存储地址信息的数据库中,我们有一张表存储人和一张表存储地址。如果我们想得到每个人的名字及其居住的城市,我们不得不遍历人那张表,然后访问地址信息。下图显示了使用直接(out-of-the box)查询机制的结果。可以看出,这个简单的例子就导致了大量的数据库查询。
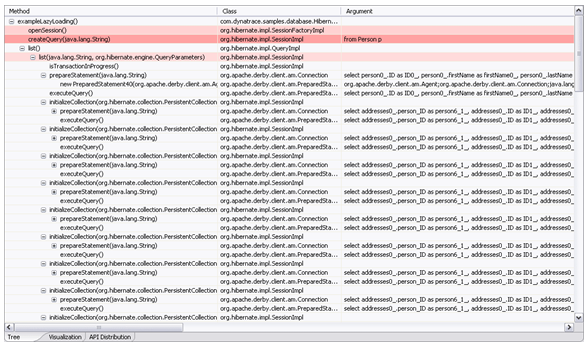
这直接引起了对象 / 关系映射中第二个重要的细节──加载时间。对象 / 关系映射 - 如果没有事先告知 - 会尽量晚地加载数据。这一行为就是延迟加载。延迟加载保证了数据尽可能晚地加载,目的是执行尽量少的数据库查询,同时避免创建不必要的对象。虽然这个方法通常情况下是可行的,但当它访问那些没有加载的数据,而数据连接已经不存在时,就可能导致严重的性能问题,以及所谓的 LazyLoadingExceptions。
在如上所述的情况下,使用专门的数据查询能够显著提高性能。
因此,虽然对象 / 关系映射在数据访问的开发方面作用很大,设计合适的数据访问逻辑的重担仍然需要我们挑起。像 dynaTrace 这样带有工具的动态架构验证,能够帮助有效地识别程序中性能的弱点,并能主动解决。
加载了太多数据,实际不需要这么多
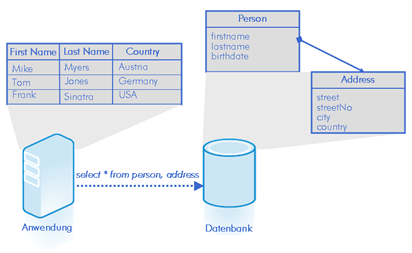
数据库访问中经常出现的另外一个反模式是加载了太多的数据,而实际上不需要这么多。导致这样的原因很多。快速应用程序开发工具提供了简单的方式,能把数据结构和用户接口控制连接起来。由于数据层由领域对象构成,通常它们包含的数据要比实际显示的多得多。再次使用地址薄作为例子。这一次需要显示人的名字及其居住城市。两个对象──地址和人──都被加载了,而不是只加载这 3 个字段。这导致了数据库、网络和应用程序层的大量开销。使用专门的查询能够大大减少查询的数据量。然而这种性能的提升需要额外的工作去维护。表中新增一列可能需要对数据访问层修改多处。
设计的服务接口不合理也经常引起这种反模式。服务接口通常要设计的很通用,以支持大量的用例。其好处是各种各样的用例中都可以使用服务。另外,用例要比后台服务实现变化的快得多。这会导致服务接口在某些场景下不适合。开发人员然后不得不使用一些补救方法,这可能导致数据访问逻辑效率低下。这个问题在数据驱动的 Web Services 上经常出现。
为了克服这些问题,开发过程中需要不断地分析数据访问模式。如果是敏捷开发方法,每个用户故事完成后都应该检查数据访问逻辑。除此之外,应该跨应用程序用例分析数据访问模式,以理解数据访问逻辑,这样能够在开发中相应地优化数据访问逻辑。
未充分利用资源
数据库是应用程序中资源的瓶颈,所以使用越少越好。通常情况下大家对数据库连接的使用关注甚少。像任何共享的资源一样,数据库连接会严重影响整个系统的性能。尤其是 web 应用和使用对象 / 关系映射框架并用了延迟初始化的程序,会让数据库保持连接的时间比需要的更长。处理开始时获得连接,直到页面生成完成或者再也没有数据访问了才断开。在使用对象 / 关系映射的应用程序中,连接经常保持着以避免可恶的延迟初始化的问题。通过重新设计数据访问逻辑,把它从后处理(比如页面生成)中分离出来,应用程序的性能和扩展性能得到极大的提高。
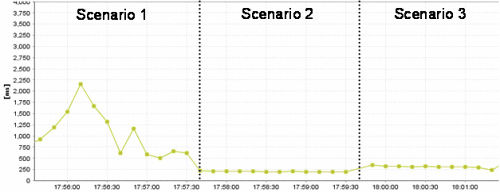
下图展示了 10 个并发数据处理线程的反应时间。第一个使用了 1 个数据库连接,第二个使用了 2 个连接,第三个使用了 2 个连接,但是有 2/3 的处理是在释放连接之后执行的。第三个场景数据访问经过更好的设计,仅用了 1/10 的资源就获得了几乎同样高的性能。
一刀切
一刀切是一种反模式,开发过程中经常见到,敏捷团队中则更多。这种反模式的特征是开发了主要功能之后,所有的数据访问就同样对待,好像它们没有任何区别。然而,区别对待不同类型的数据和查询可以显著提高应用程序的性能和扩展性。
应该对数据进行分析,考虑其生命周期的特性。它是否经常变化,它是可修改的还是只读的呢?数据的访问频率和访问模式,就隐含了一些潜在的代码,比如可以做缓存。访问频率也暗含了一些线索,比如在哪里做优化更有意义。这可以避免过早进行优化以及不必要的优化,保证了性能调优效果最好。
对数据的使用模式进行分析也有助于调整数据访问层。理解真正使用了哪些数据有助于优化加载策略。比如,理解用户怎样浏览搜索结果对优化 fetch size 很有用。知道了用户是否查看订单详细信息可以给订单选择延迟还是立即加载。
除数据之外,查询也应该被分析并分类。重要的因素包括查询时间、执行频率、是否用于交互用户的上下文或者批量处理的场景中。事务特性有助于更好地调整查询的隔离级别。
比如,在同一个连接中运行用户短暂的交互查询和时间很长的报表查询,很容易导致终端用户的体验很糟糕。报表查询花费的时间很长,会占用大量的数据库连接,让终端用户的查询无法拿到连接。通过给不同的查询类型使用不同的数据库连接池,会使终端用户的性能更可预测。降低数据库查询中不需要的隔离级别,也能引起性能和扩展性的显著提高。
糟糕的测试
最后,缺少测试或者测试不正确是数据库访问应用程序性能和稳定性问题的一个主要原因。最近我曾就这一主题作了一个演讲,并询问听众是否把数据库访问看作应用程序中一个性能问题。虽然他们都赞成,但没人有这样的测试流程,来测试数据访问的性能。所以虽然这个话题看上去是很重要,大家似乎都没有花时间去做。然而,即使有测试流程,这也不一定说明测试就是正确的。虽然代码完成后能够立刻发现数据访问逻辑中的很多问题,但通常很晚之后才执行测试,比如负载测试的时候。由于在生命周期的晚期才改动,可能需要修改架构,从而引起额外的开发和测试工作,这带来了很高的不必要的代价。
而且,必须设计一些测试用例,来测试真实世界的数据访问场景。测试数据访问必须在并发模式下进行,并且使用不同的访问类型。只有结合使用读 / 写访问才可能识别死锁和并发的问题。除此之外,输入的数据应该多种多样,以避免数据库访问时经常命中缓存,这是不切合实际的。
很多时候人们对预期的负载知之甚少,也不知道去测试哪些负载。很不幸的是,根据我的经验这种情况比比皆是。然而,不能把这当作借口,不定义负载和性能标准。要知道,定义一些标准比一点也不定义要好得多。
如果你对性能数据真的毫无头绪,最好是使用负载渐增测试法,逐步增加负载,直到达到了应用程序的最大值。这样你就知道了应用程序的负载峰值。如果负载峰值既合理又现实,那就说明你做的不错。否则你得知道在哪方面提高性能。大多数情况下初始的测试表明,应用程序能够处理的负载要比期望的少得多。
结论
数据库访问是影响现代应用程序性能和可伸缩性的一个关键点。虽然框架支持构建数据访问逻辑,仍然需要对数据访问逻辑投入相当的精力,以避免种种陷阱和问题。问题之关键是要理解应用程序数据访问层的动态和特性的一切细节。
作者简介
Alois Reitbauer 是 dynaTrace 软件公司的一名高级性能架构师。在研发部门任职期间,他参与制定了 dynaTrace 的产品策略,并与大客户紧密合作,为应用程序的整个生命周期实现了性能管理解决方案。Alois Reitbauer 在 Java 和.NET 领域有 10 年的开发和架构经验。
译者注
本文“未充分利用资源”一节中举了这样一个例子:第一个场景使用了 1 个数据库连接,第二个场景使用了 2 个,第三个场景使用了 2 个,但是后处理(比如页面生成)是在释放数据库连接之后进行。从图表看出,第一个场景的反应时间最长,第三个场景的反应时间与第二个差不多,但是只用了 1/10 的资源。
根据上下文,实际上应该是这样的:第一个场景使用了 1 个连接,第二个使用了 10 个,第三个使用了 1 个,但是后处理(比如页面生成)是在释放数据库连接之后进行。只有这样,文中的结论才合理。
事实上,InfoQ 总站该文后面 Ray Davis 有一个跟帖,就该问题提出了疑问,认为第二个场景的 2 个连接应该为 10 个。除了 Ray Davis 的疑问,译者认为,第三个场景的 2 个连接应该是 1 个,这样上下文不矛盾了。
阅读英文原文: Performance Anti-Patterns in Database-Driven Applications 。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




