

本文主要讲述 Beat 公司的 ElastiCache 迁移故事。
Beat 的系统是由一个比较大但规模不断缩小的单体系统,和不断增加的微服务组成的。为了支撑持久化服务,ElastiCache 使用了多种数据库来存储其状态,同时选择 Redis 作为前面的第二层存储。到目前为止,Beat 一直在禁用集群模式下使用 AWS ElastiCache 托管服务,在一段时间内容,ElastiCache 为 Beat 提供了很好的服务,但是最近它带来了一些麻烦,甚至导致无法再进行扩展。
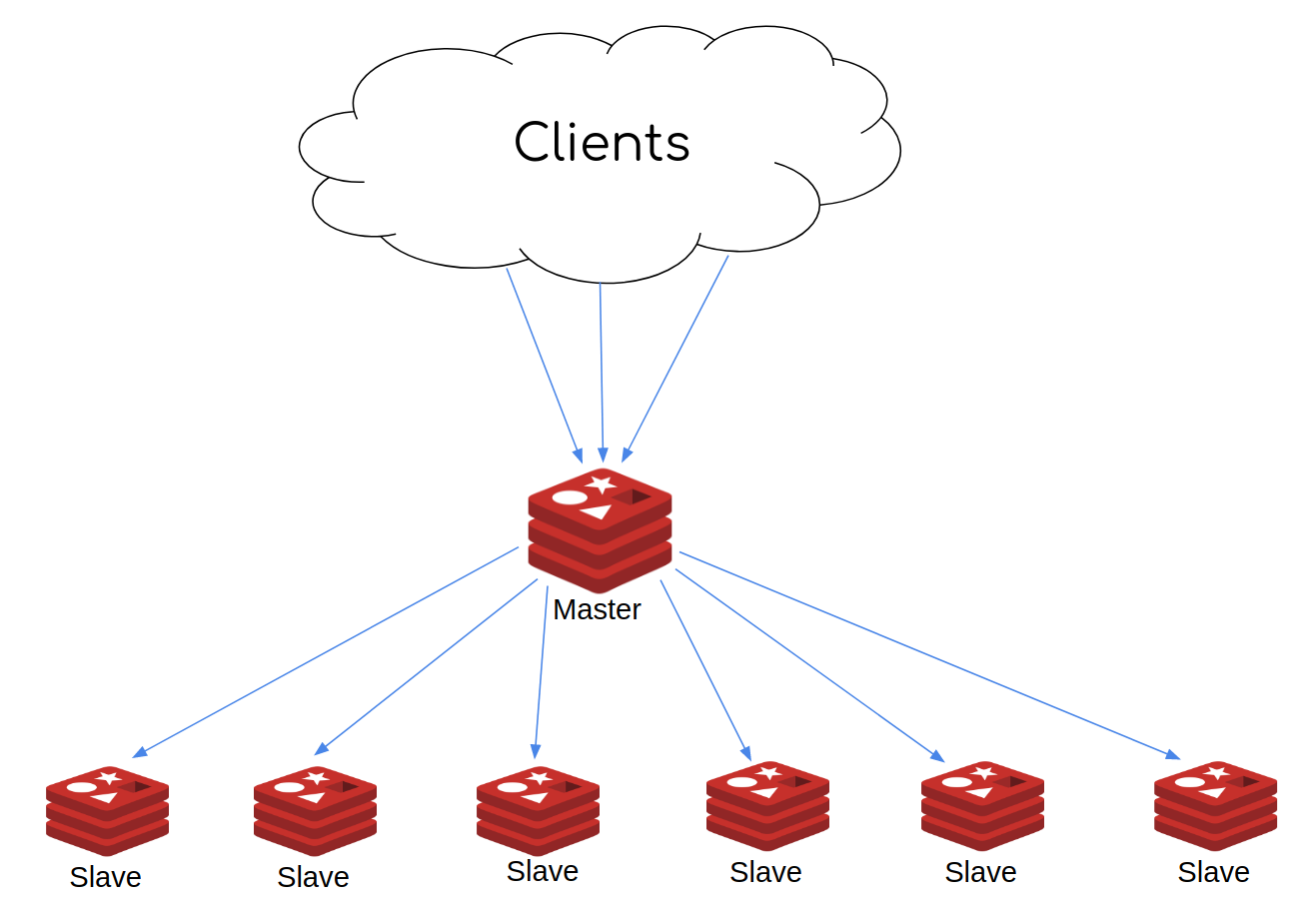
禁用集群的 AWS ElastiCache 架构
从上图很容易看出,主节点是瓶颈,目前唯一的扩展方法是垂直扩展。我们尝试了几次垂直扩展,但是扩展过程很痛苦,而且会导致停机。此外,垂直扩展使得我们的成本上升了很多,无法充分利用实例的能力,即使是在集群中添加一个节点也非常耗时,有时还会导致小停机甚至大停机。
我们的单体服务倾向于创建热键,特定事件会导致负载峰值。这样设计是不合理的,我们也有计划去重构,但这都需要时间。在没重构之前,我们希望有一个可以更好地扩展的系统。
为了解决这个问题,并防止将来出现更大停机时间的情况,我们决定组建一个由后端、QA 和基础设施工程师组成的子团队,并提出可伸缩的替代解决方案。经过与 AWS 技术客户经理和支持工程师的几轮讨论之后,我们决定采用启用集群模式的架构。从理论上讲,这将让我们可以扩展重负荷的主节点并平衡其流量。
新的架构如下图所示:
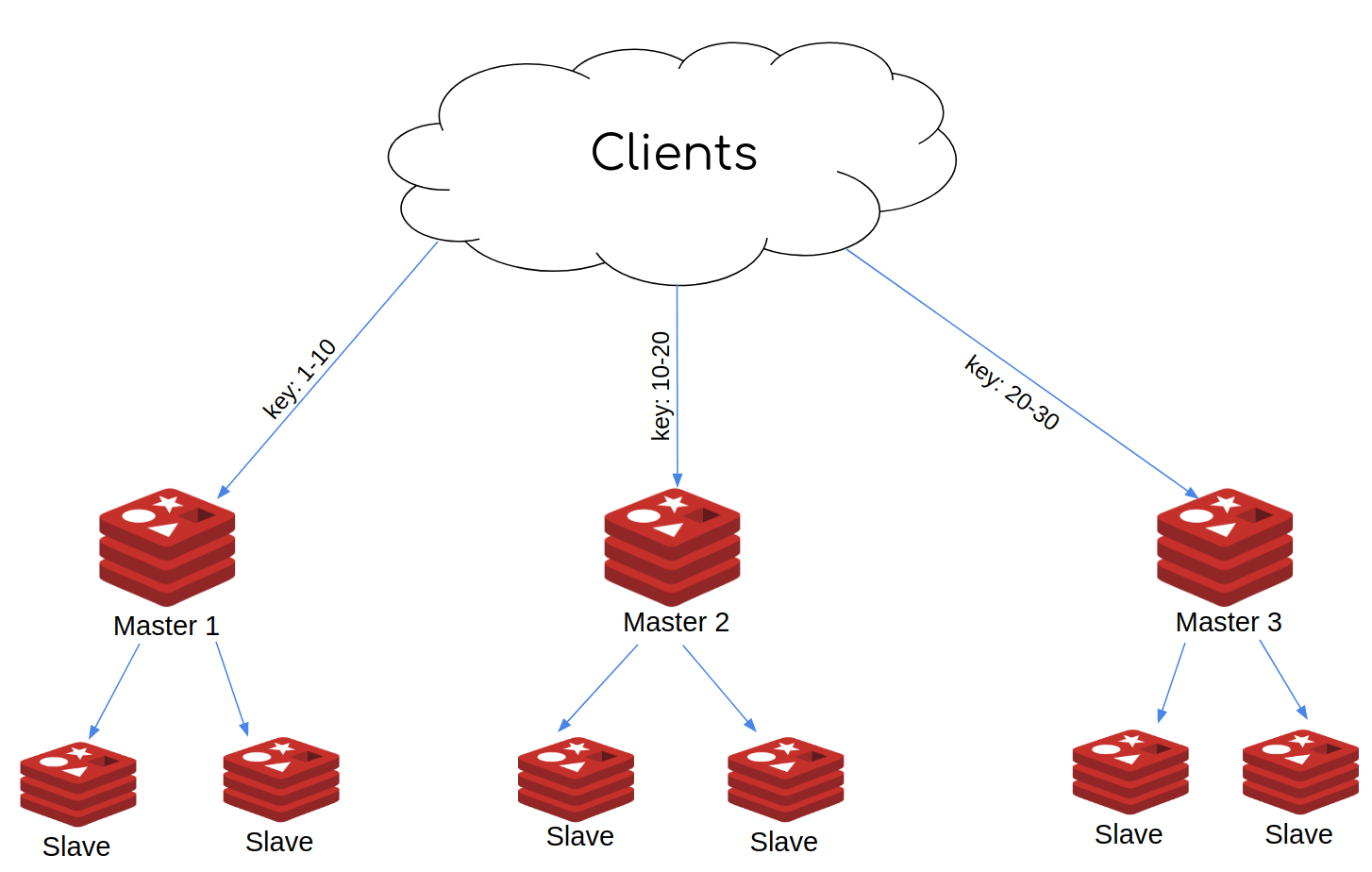
启用集群的 AWS ElastiCache 架构
压力测试
在真正投入到新架构之前,我们要先来测试一下它是否能够满足我们的期望和增长需求。
我们的需求包括:
如果一个特定的 shard 节点过载,我们应该能够添加副本节点,而不会对现有集群产生任何影响。
如果某个特定 shard 节点的负载比其他 shard 节点大很多,我们应该能够创建一个新的 shard 并重新平衡集群,而不需要停机或对客户端造成任何影响。
如果我们想要垂直地扩展集群并更改实例类型,那么应该不需要停机。
对于每一项测试,我们都创建了一个测试集群,加载了一些虚拟数据,并开始从多个客户端进行查询。
我们使用了像 memtier 和 redis-benchmark 这样的工具,以及一些自己开发的脚本,这些脚本能够使测试平台尽可能接近产品,并且允许测试我们的用例。
测试通过之后,我们就可以进入到新集群能力规划的阶段。
能力规划
在压力测试阶段,我们检查了当前的系统,并计算了当时服务于当前负载所需的资源。我们的目标是使新设置的初始版本能够支撑两倍的负载。毕竟,扩展需求随时都可能出现。
事实上,Redis 服务器是单线程的,这使得我们可以关注整个集群的内存、网络带宽和连接数量等指标。
出于某些原因,我们打算保守地规划能力,并且使得以后可以轻松添加更多的 shard 和副本节点,而不需要停机。同时,我们在管道中进行了一些改进,这将有助于减少集群负载。
迁移阶段
当准备好了新的集群和支持它的代码库,我们就开始执行一个由多个阶段组成的发布计划,尽可能在每个阶段都更少的引入更改。
“试水”阶段
在这一阶段,除了应该支持 Redis 集群模式之外,我们并没有对后端进行任何大幅的更改,只针对一小部分用户(最初是在希腊市场)启用了集群。在质量保证工程师的支持下,我们做了切换。然而,结果并没有让人眼前一亮。
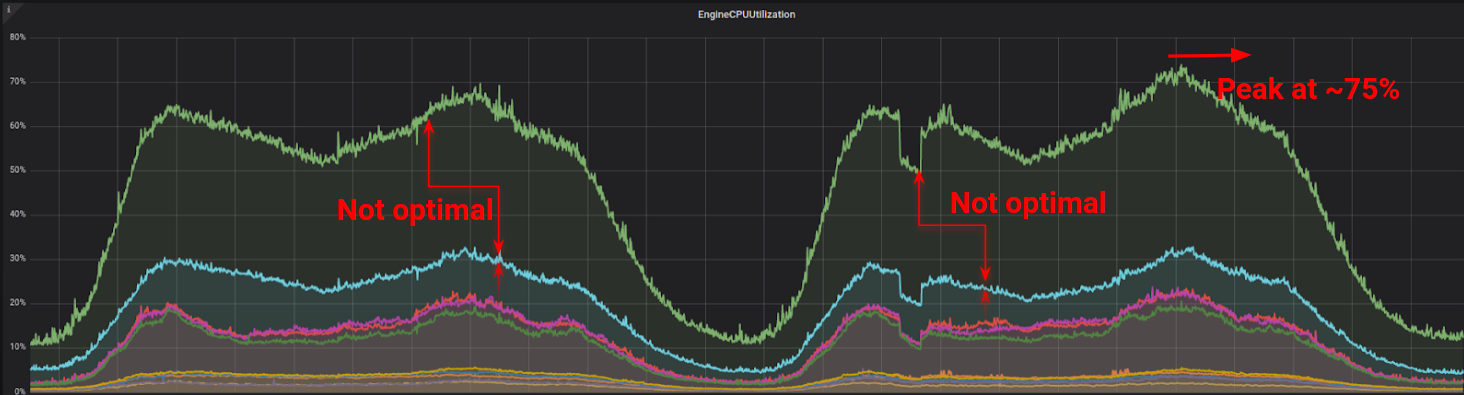
启用集群后的集群 CPU 使用情况
上图展示了我们的新集群以某种方式更好地平衡了流量,并且负载在多个主机之间进行了分配。然而,流量分布并没有达到预期,因此,我们需要继续深入研究,使流量更好地分布在节点上。
“热身”阶段
我们确实有一张隐藏的王牌,我们怀疑新客户端没有使用持久连接。使用来自 bcc 工具 的 tcpconnect 脚本,我们观察到有大量的新连接连接到 Redis 集群的 TCP 端口。
对于每个 Redis 命令,我们都在创建到服务器的新连接。对于系统级的 ElastiCache 节点来说,这样做成本非常高,因为它会导致 Linux 内核在打开和关闭这些新连接时做大量的工作。在使用新的持久连接标识部署代码之后,我们很高兴地看到了以下效果。
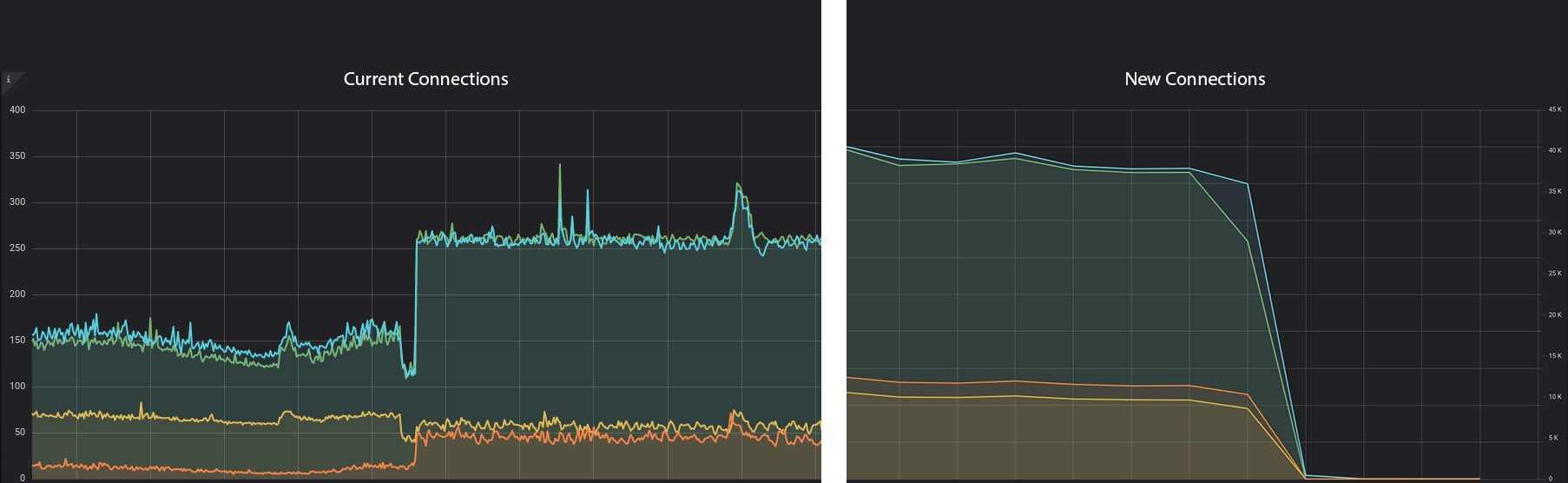
左侧:集群当前的连接——右侧:集群新的连接
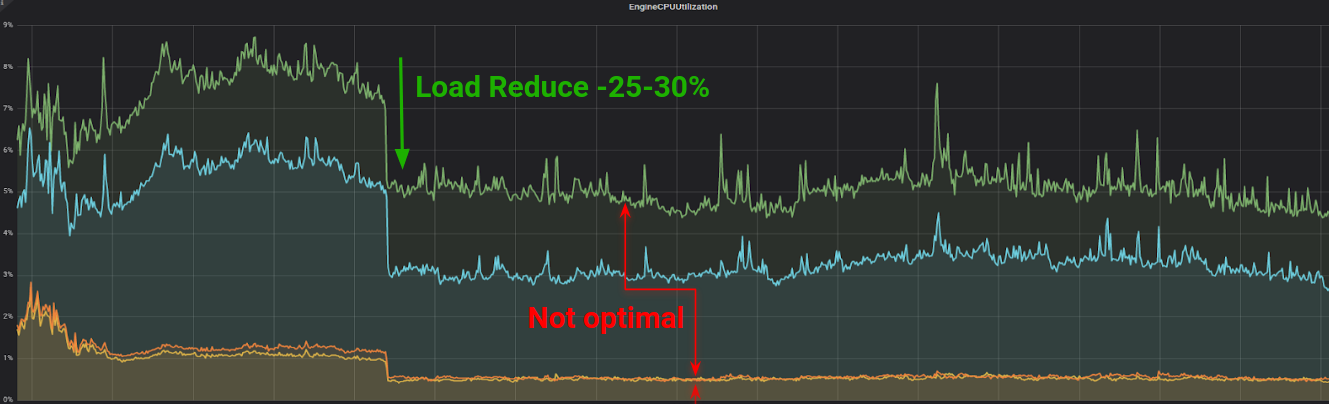
启用持久连接后的集群 CPU 使用情况
如你所见,CPU 大幅下降,当前连接增加,因为它们是长时间存在的,而新连接几乎减少到 0。同时,重新运行 tcpconnect 工具,我们看到,实例中新连接的比例显著降低。
“大海捞针”阶段
然而,我们仍然没有解决特定 shard 主节点不能平衡负载的问题。我们知道,Redis 流量模式是写 / 读命令 1:7,这意味着,如果在主节点和副本节点之间分配流量,主节点的负载就不应该那么重。现在是进行网络检查的时候了,看看我们与不同的 Redis 集群节点交换的是什么类型的流量。在我们的一个正在运行集群客户端的实例中触发 tcpdump 之后,我们注意到一件有趣的事情:
我们的客户端实例是 IP 为 10.3.2.202 的机器,Redis 副本节点 IP 是 10.3.2.246。
我们从集群分片映射中得知,特定的 Redis 副本是分片的一部分,负责请求的密钥。我们得到的响应是一个 MOVED 响应,它将我们重定向到另一个 IP 为 10.3.2.35 的实例,这个实例恰好是这个分片的主节点。经过研究之后,我们发现,为了使副本响应 READONLY 命令,我们必须在命令前面加上一个 READONLY 前缀。我们的后端工程师在代码库中做了更改,一旦部署了新的更改,我们就看到了以下内容:
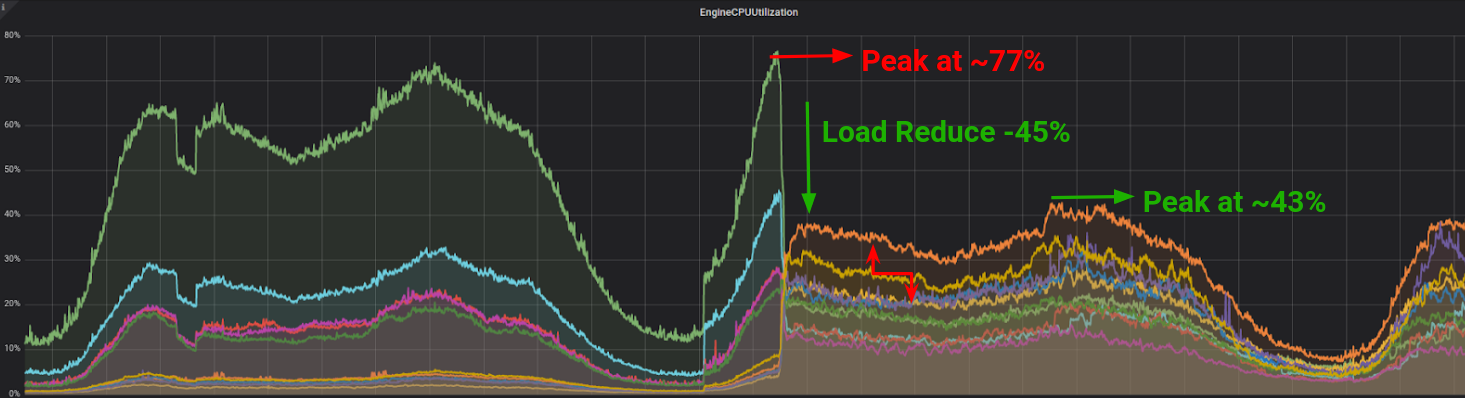
集群 CPU 使用情况变化
这样就完成了任务,主节点和副本节点之间的差距明显缩小了。
“收尾”阶段
如果你仔细查看上面的图表,就会发现我们的主节点获得的流量低于预期。我们把流量从主节点转移到了副本,导致了一个非同质的流量模式。通过与后端工程师交谈,这被证明是我们内部库的一个特性,它是作为我们之前设置的一部分开发的。因为现在不再需要它了,所以我们禁用了它,并允许主节点也获得只读查询的一部分。在完成这最后一项工作之后,我们得到了以下令人满意的结果。

READONLY 变更后的 CPU 使用情况
作者介绍:
Andreas Strikos 是一名高级 DevOps 工程师,是 Beat DevOps 小组的成员。他不断尝试在编写代码和构建健壮的系统之间找到平衡。他热衷于网络和复杂的系统架构。
原文链接:
https://build.thebeat.co/an-elasticache-migration-story-9090a524b3f8

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论