

谷歌大脑的新论文《The Evolved Transformer》提出了首个用于改进 Transformer 的神经网络架构搜索算法(NAS)。Transformer 是许多自然语言处理任务的最流行的网络架构之一。该论文使用基于锦标赛选择的进化算法,通过网络搜索算法得到进化版 Transformer。新的网络结构比原来的 Transformer 取得了更好的表现,并且减少了所需要的训练时间。本文是 AI 前线第 72 篇论文导读,带你一起探究进化版 Transformer 背后的秘密。
神经网络架构搜索(Neural architecture search,NAS)是通过算法搜索来实现神经网络新架构的方法。虽然多年来研究人员已经手动开发出了各种各样复杂的网络架构,但是找到最有效的网络结构的能力依然有限,然而最近由 NAS 模型的表现性能已经达到优于人类所设计模型的水平。
谷歌大脑在新论文《The Evolved Transformer》中提出了首个用于改进 Transformer 的 NAS。Transformer 是许多自然语言处理任务的最流行的网络架构之一。该论文使用基于进化的算法,用一种新的方法来加速搜索过程,让 Transformer 的结构产生改变,以得到一个更好的版本——进化版 Transformer(Evolved Transformer,ET)。新的网络结构比原来的 Transformer 取得了更好的表现,尤其是与比较小的适合移动端的模型相比,并且减少了所需要的训练时间。论文中提出的“使用 NAS 来进化人类设计的模型”这一概念,能够帮助许多其他领域的研究人员改进他们的网络结构。
背景
Transformer网络于 2017 年首次提出,该网络引入了一种注意力机制,能够同时处理整个文本输入,以学习单词之间的上下文关系。一个 Transformer 网络包括两个部分——编码器,读取文本输入并生成它的横向表示(例如每个词用一个矢量表示),以及解码器,从该表示中生成翻译的文本。实验证明该网络设计是非常有效的,许多目前最先进的模型(例如 BERT、GPT-2)都是基于 Transformer 的网络结构而设计的。(Transformer 的深度介绍:Transformer 综述)
虽然 Transformer 的结构是由研究人员手动设计的,但也有另一种选择,就是使用搜索算法来获得网络结构。他们的目标是在给定的搜索空间中找到最好的网络结构,搜索空间定义了模型的约束参数,如层数、参数数量等。一个已知的搜索算法是基于进化算法的锦标赛选择(Tournament Selection)算法,该算法让最合适的网络结构可以生存下来并产生突变,而最弱的结构则被淘汰。该算法的优点在于它既简单又有效。这篇论文采用的是Real等人提出的版本。(见附录 A 中的伪代码):
通过在搜索空间随机采样或使用已知模型作为种子来初始化第一代模型。
用给定的任务训练这些模型,并随机采样创建子种群。
对表现最好的模型进行突变,随机改变它们结构的一小部分,例如替换一个层或者改变两个层之间的连接。
将突变模型(子模型)添加到种群中,而子种群中最弱的模型则被从整个种群中移除。
定义搜索空间是解决搜索问题的另一个挑战。如果搜索空间太宽或不够明确,算法可能无法收敛,或者无法在合理的时间内找到一个更好的模型。另一方面,如果搜索空间过于狭窄,则降低了找到一个比人为设计的模型表现更好的新模型的可能性。NASNet搜索结构通过定义“可堆叠单元”来应对这一挑战。一个单元可以从一个预定义的词汇表中选择一组作用在输入上的操作(例如卷积),然后通过多次堆叠相同的单元结构来建立模型。这样一来,搜索算法仅需要找到单元的最佳结构。
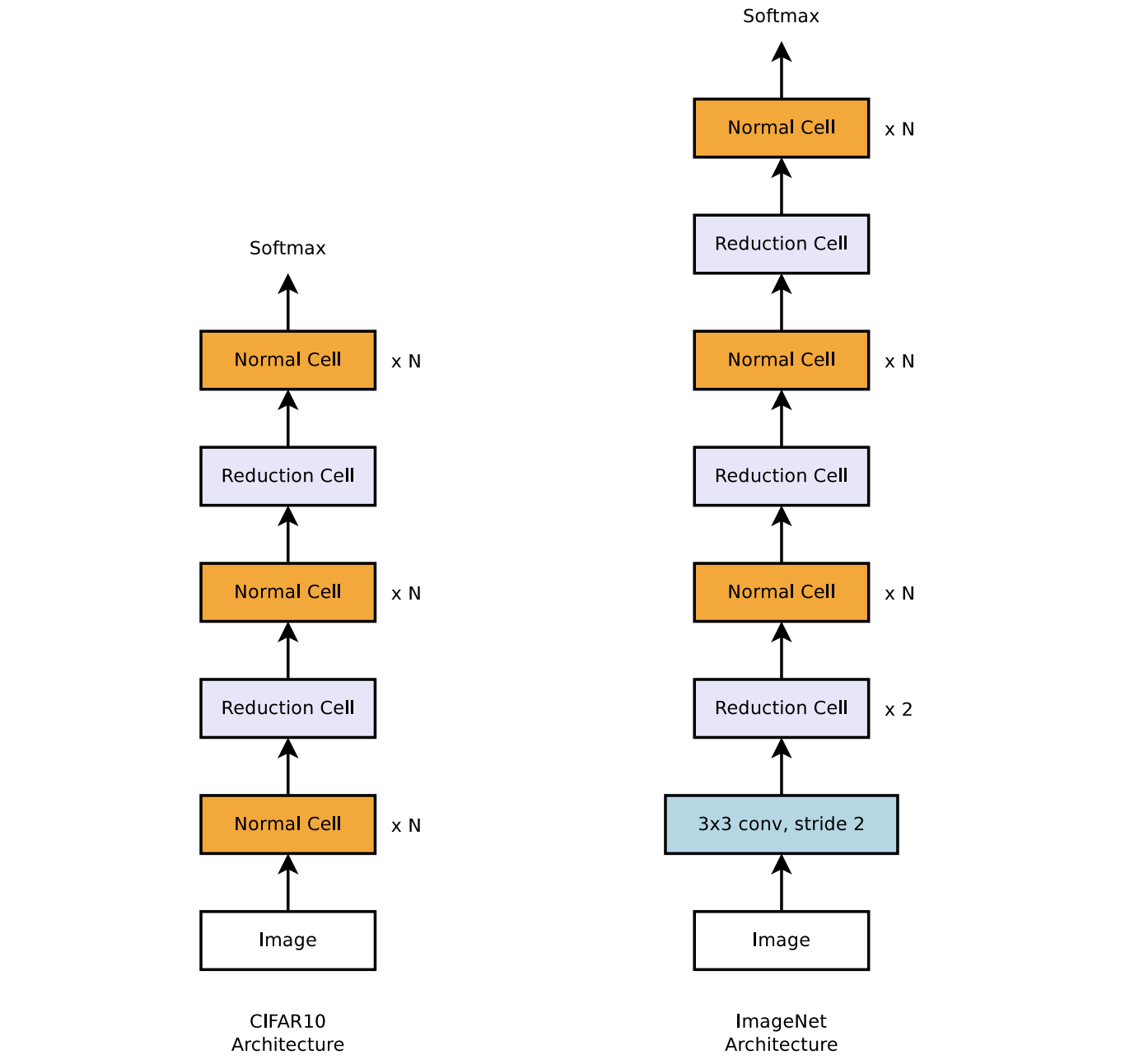
包含两种可堆叠单元(正常和缩减单元)的用于图像分类任务的 NASNet 网络搜索结构示意
进化 Transformer
由于 Transformer 网络结构已经经过了无数次证明,作者的目标是使用搜索算法让其进化成更好的模型。因此,模型框架和搜索空间的设计要适合原始的 Transformer 网络结构:
该算法搜索两种类型的单元——一种复制 6 次(块),用于编码器,另一种复制 8 次,用于解码器。
每个块包括两个操作分支,如下图所示。例如,输入是上一层(块)的任意两个输出,一个层可以是标准卷积操作、注意力头(attention head)等,并且激活函数可以是 ReLU 和 Leaky ReLU。某些元素也可以是同样的操作或终端。
每个单元可以重复多达六次。
总的来说,搜索空间可以增加到 7.3×10^115 个可选模型。论文的附录给出了搜索空间的详细介绍。
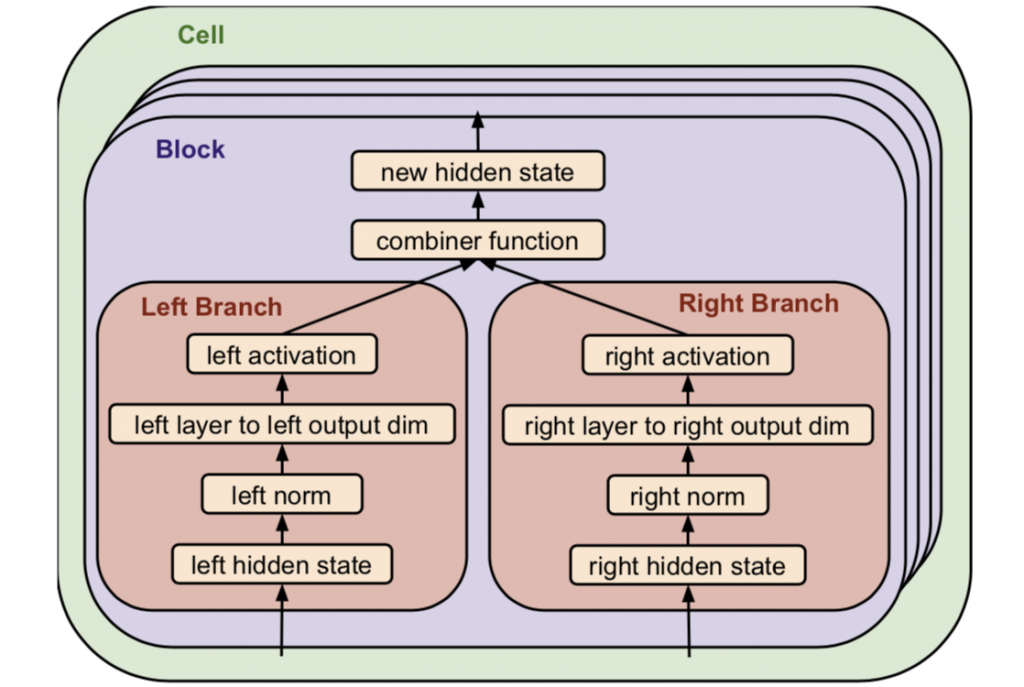
ET 可堆叠单元格式
递进动态跨栏(PDH)
如果每个模型的训练和评估时间被延长,那么搜索整个空间需要的时间可能过长。在图像分类领域,可以通过在代理任务上执行搜索来克服这个问题,例如在较大的数据集(如 ImageNet)上测试之前先在较小的数据集(例如 CIFAR-10)上训练。然而,对于翻译模型。作者无法找到等价的解决方案,因此作者引入了锦标赛选择算法的一个升级版本。
作者没有在整个数据集上训练模型池中的每个模型,该过程在单个 TPU 上都需要花费大约 10 个小时。训练是逐渐完成的,并且只对模型池中的最佳模型进行训练。池中的模型在一定数量的样本上进行训练,并且根据原始锦标赛选择算法创建更多模型。一旦池中有了足够的模型,就计算一个“适应度”阈值,只有取得了更好的结果(适应度)的模型才能继续下一步。这些模型将在另一批样本上进行训练,并且下一代模型将基于它们创建和突变。因此,PDH 显著减少了在失败模型上浪费的训练时间,并提高了搜索效率。缺点是“慢热”,那些需要更多的样本才能获得好的结果的模型可能会被忽略。
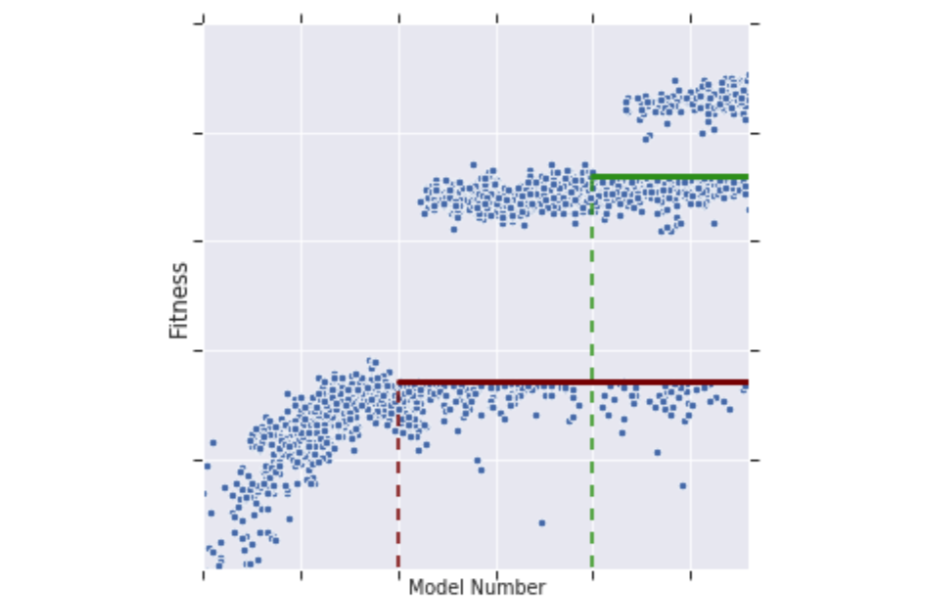
锦标赛选择算法训练过程示意图。适应度阈值之上的模型在更多的样本上训练,从而达到更好的适应度。当创建新模型时,相应增加适应度阈值。
为了“帮助”搜索取到高质量的结果,作者用 Transformer 模型而不是完全随机模型对搜索进行初始化。由于计算资源的限制,该步骤是必要的。下表比较了不同搜索技术得到的最佳模型的性能(使用困惑度(perplexity)评价标准,数值越低越好):Transformer 初始化 vs.随机初始化,以及 PDH 算法与常规锦标赛选择算法(每个模型的训练步数一定)。
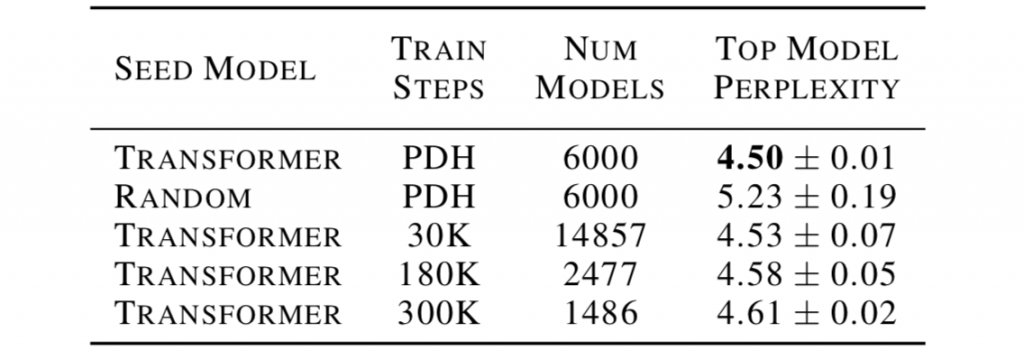
不同搜索方法对比
作者固定了的每种方案的总训练时间,因此模型的数目有所不同:每个模型的训练步骤越多,可以搜索的模型总数就越少,反之亦然。PDH 方法获得了评价最好的结果,同时也更稳定(低方差)。当减少训练步数的数量时(30K),常规方法的平均表现几乎和 PDH 的一样好。然而,它的方差更高,因为它更容易在搜索过程中出错。
结果
该论文使用所介绍的搜索空间和 PDH 来搜索在已知数据集(如WMT’18)上表现良好的翻译模型。搜索算法搜索了 15000 个模型,使用 270 个 TPU,总共进行大约 10 亿步训练。如果没有 PDH,所需的总步数将是 36 亿个。作者将发现的最好的模型命名为进化 Transformer(ET),和原始的 Transformer 网络相比取得了更好的结果(困惑度 3.95 vs 4.05),并且所需要的训练时间也更少。下图给出了它的编码器和解码器块结构(与原始的结构图相对比)。
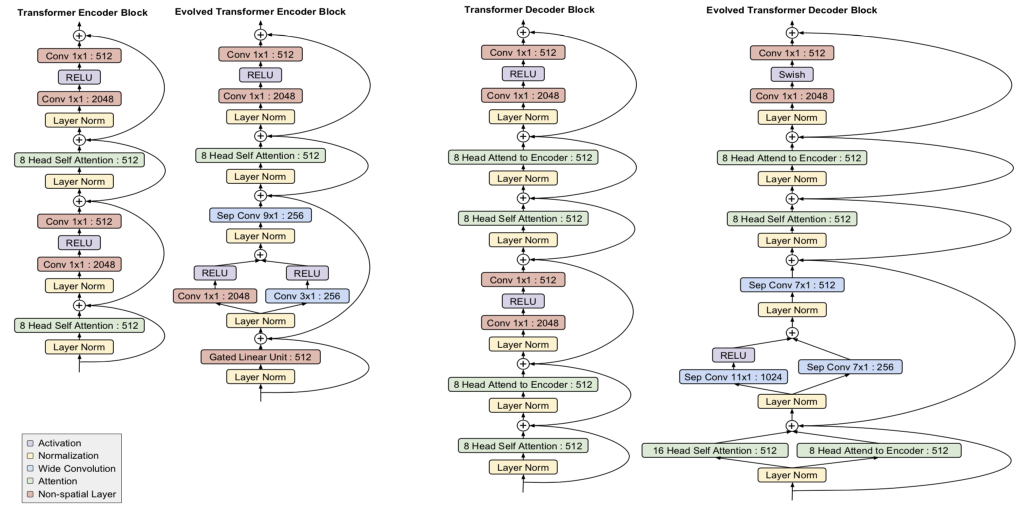
Transformer 和 ET 网络编码器解码器结构对比。
虽然 ET 网络中的一些结构与原始的相似,但其他一些则不太传统,例如深度可分离卷积,它比常规卷积的参数效率更高,但计算能力较低。另一个有趣的例子是在解码器和编码器中使用并行分支(例如,用于相同输入的两个卷积和 ReLU 层)。在消融研究中,作者还发现 ET 能取得如此优异的表现不能只归因于 ET 和 Transformer 之间的任何单一突变。
ET 和 Transformer 都是具有超过 2 亿个参数的重量级模型。可以通过改变输入内嵌表示(词向量)的大小,并对应的改变网络的其余部分来减小它们的参数量。有趣的是,模型越小,ET 对 Transformer 的优势就越大。例如,对于只有 700 万个参数的最小模型,ET 的困惑度超过 Transformer 1 个点(7.62 vs 8.62)。
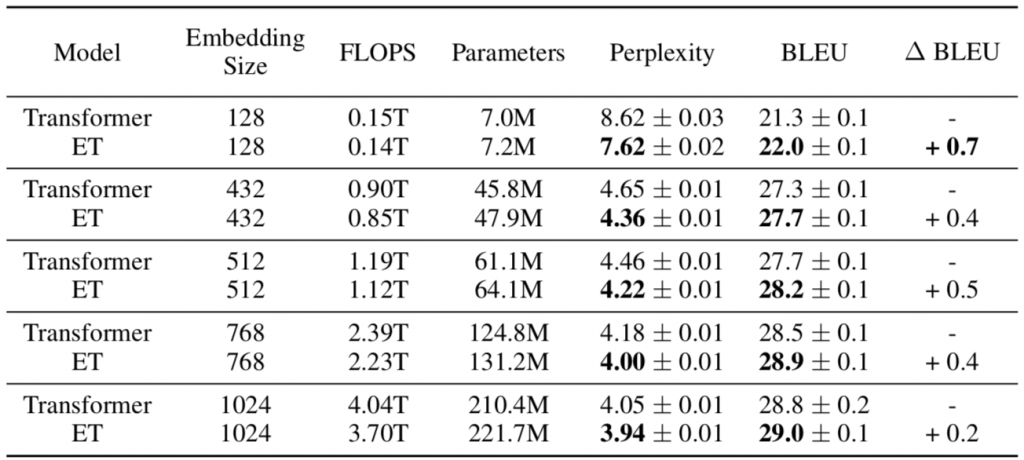
Transformer 和 ET 的不同尺寸模型(根据内嵌表示尺寸)的比较。FLOPS 代表模型的训练持续时间。
实现细节
如上所述,搜索算法需要超过 200 个谷歌的 TPU,才能在合理的时间内训练数以千计的模型。最后得到的 ET 模型自身的训练时间比原始 Transformer 更短,但仍然需要在单个 TPU 上运行几个小时才能完成在 WTM’14 En-De 数据集上的训练。
代码采用 Tensorflow 实现,已开源:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/evolved_transformer.py
总结
进化 Transformer 展示了将手工设计与神经网络结构搜索算法相结合来创造更好、训练更快的新网络的潜力。由于计算资源仍然有限(即使是对于谷歌来说),研究人员仍然需要仔细设计搜索空间并改进搜索算法以获得超越人类设计的模型。然而随着时间的推移,这种趋势毫无疑问会越来越强。
附录 A——锦标赛选择算法
这篇论文采用Real等人提出的锦标赛选择算法,但是没有使用老化过程,即从种群中丢弃最古老的模型:

查看英文原文:The Evolved Transformer – Enhancing Transformer with Neural Architecture Search
论文原文链接:https://arxiv.org/abs/1901.11117v2
更多内容,请关注 AI 前线


暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论