

过去,为了从“内部”(通常都是位于同一地点)的硬件中获得最大的性能和最低的延迟,这些有低延迟需求的公司都是在裸机服务器上部署的,放弃了虚拟化和容器化的便利性和可编程性。
近来,这些公司日益转向公共和私有“云”环境,或为其所调整的低延迟/高容量(LL/HV)系统提供卫星服务,或在一些场合下用于 LL/HV 工作负载本身。
这个演示是在一个典型的云原生环境中实现了 Chronicle Queue 的复制。该解决方案实现了主动/被动冗余和由 Consul 服务注册表健康检查驱动的自动故障切换。使用 Prometheus 和 Grafana 仪表盘来显示实时指标。
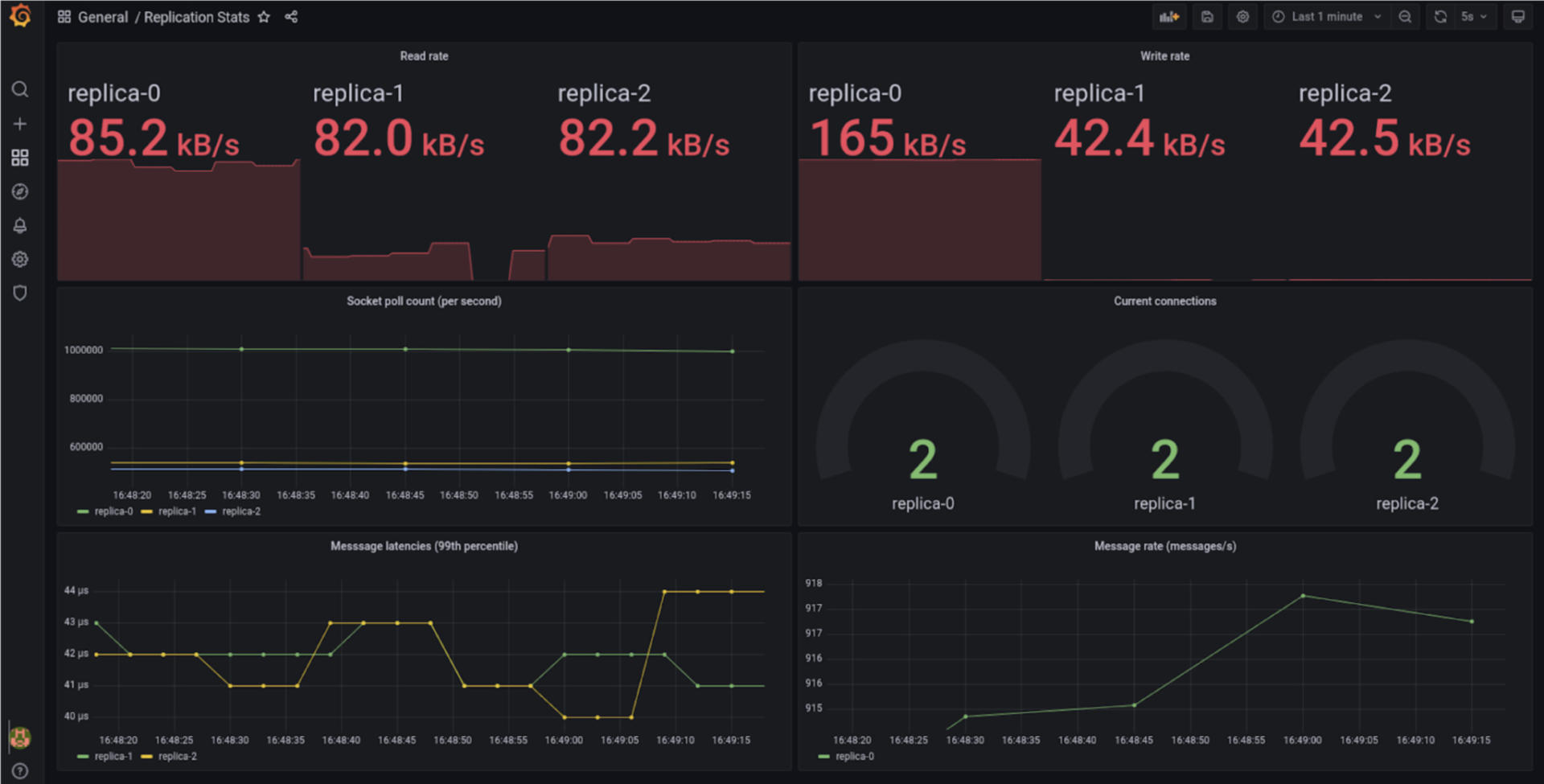
图 1:指标面板:在测试设备上(一台配备 NVME SSD 的 i9 笔记本,使用 Minikube 和 Docker 驱动),我们看到第 99 个百分点的写到读的延迟在 40us 左右(从领导者到追随者的测量)。这个性能可以得到很大的改善,但是由于性能调整不在本文的讨论范围内,所以没有试图对部署和示例代码进行调整。
优势与挑战
云原生环境为简化复杂应用架构的定义和部署提供了一个通用平台和接口。这种基础设施使人们能够使用成熟的现成组件来解决常见的问题,诸如领导者选举、服务发现、可观察性、健康检查、自我修复、扩展和配置管理。
典型的模式是在这些环境中的虚拟机上运行容器。但是,如今各大云提供商(如云提供商亚马逊云科技、Microsoft Azure、Google Cloud等)都提供了裸机(或接近裸机)解决方案,因此即使是对延迟敏感的工作负载也可以在云中托管。
这是对 Chronicle 产品如何在这些架构中使用的第一次迭代演示,包括对我们的客户在云和其他环境中遇到的一些挑战的解决方案。通过利用常见的基础设施解决方案,我们可以将 Chronicle 产品的优势与现代生产环境的便利性结合起来,提供简单的低延迟、运行稳定的系统。
解决方案
该演示由一组可配置(和动态)规模的集群中的节点组成。我们选择 Kubernetes 进行演示,因为它是云原生基础设施的事实标准;然而,大多数协调平台实现了类似的功能。
集群中的每个节点都包含一些玩具业务逻辑,这些逻辑在复制的 Chronicle Queue 中存储其状态。
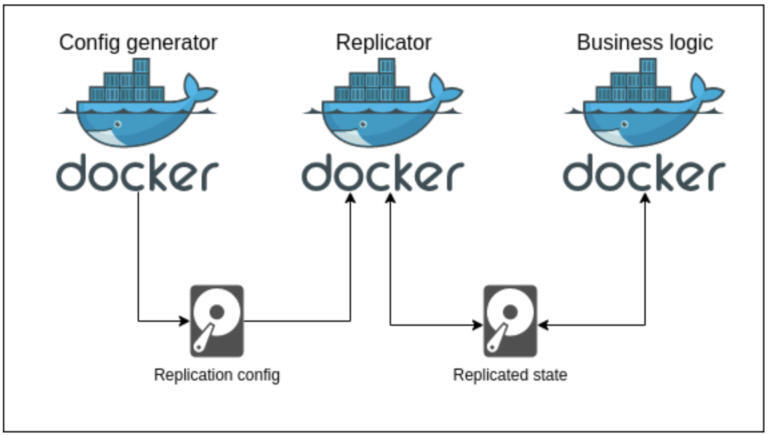
图 2:单个 Pod 的示意图,显示了重要的容器和卷。
集群中的节点各自维护一个 Chronicle Queue 的副本,这些副本通过 Chronicle Queue Enterprise 复制保持同步。在任何时候,其中一个节点被设置为 "领导者 "节点;领导者负责根据一些业务流程填充队列。当当前的领导者节点失败或从集群中移除时,其中一个 "跟随者 "节点将被提升为领导者。这是一个用于实现高可用性的常见模式。
集群节点在 Consul 服务云提供商注册表注册自己,并配置一个简单的健康检查,通过 HTTP 轮询其指标端点来监控节点的健康状况。在生产部署中,这种健康检查可能更复杂。
每个节点都是 StatefulSet 中的一个 Kubernetes Pod。每个 Pod 都包含以下容器:
业务逻辑
这个容器运行玩具“业务逻辑”,它可以填充或从队列中读取(取决于其角色)。就本演示而言,业务逻辑层只是在领导者时向队列写入一串数值,并作为跟随者将这些序列号输出。在真实的部署中,这将是一个真正的应用程序——例如,在 HA(高可用性)模式下的 Chronicle FIX、Chronicle Matching Engine,或一个自定义的应用程序。
集群必须提名一个领导者 Pod,负责填充队列,所以业务逻辑层参与 Consul 领导者的选举。业务逻辑层的伪代码如下:
业务逻辑容器从/到“复制状态”卷的读/写队列。
replicator
这个容器运行 Chronicle Enterprise Queue 的复制过程。它监控“replication config”卷中复制配置文件的更新,当检测到更新时,它用新的配置重新启动复制。如果复制配置不存在或无效,它不会启动复制。
当集群发生变化时,重启复制是我们推荐的一种常见模式,重启本身发生在几毫秒内,这意味着复制的中断是最小的。
config-generator
因为我们有 Consul 作为服务注册表,而且我们的领导者选举是通过 Consul 键值存储进行的,所以我们可以仅从 Consul 的状态中得出我们的复制配置。
这个容器使用 Consul 模板来监控 Consul 在集群中的变化(例如,增加或移除节点)或当前领导者的变化。当任何这些变化发生时,复制配置会重新生成到“复制配置”卷中。
exporter-merger
这个容器运行一个进程,将来自复制器和业务逻辑容器的普罗米修斯指标组合起来。
监控
Consul 使用云提供商可配置的检查来监控容器的健康状况。如果健康检查发现一个节点失败了,它就会放弃领导权(如果持有的话)并从集群中移除。Kubernetes 也监控每个 Pod 的健康状况,当一个 Pod 出现故障时,它将被关闭,并创建另一个 Pod 来代替它。
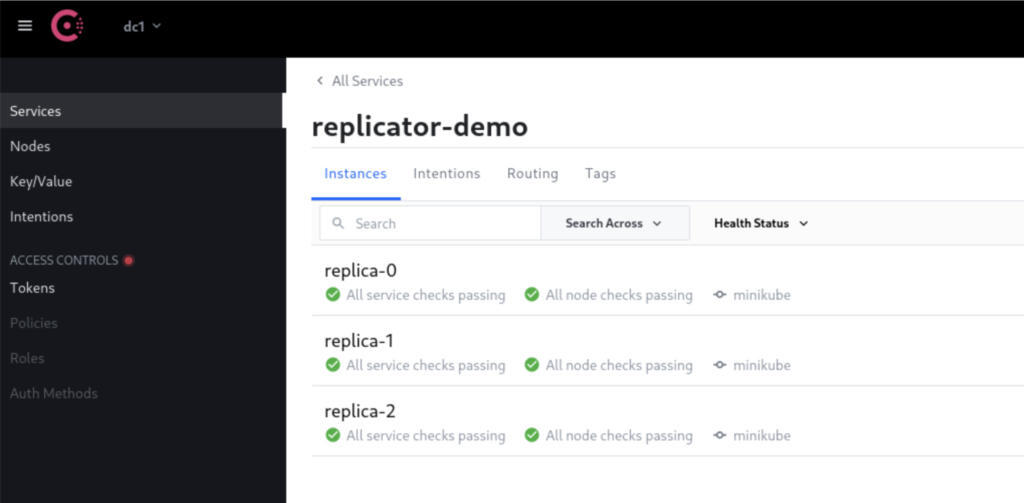
图 3:Consul 服务注册表 UI 显示健康的复制集群
业务逻辑和复制容器都通过 Prometheus 发布指标,公开集群的状态。通过 Prometheus 发布的指标会被 Grafana 渲染成一个仪表盘。
图 1 显示了指标仪表板。你可以看到在这个快照中,replica-0 是领导者,其他副本是跟随者。由于其他复制体的回执,复制体-0 的读取率非常高。
总结
Consul 维护一个集群成员的注册表,我们的应用程序注册健康检查,以删除任何不健康的节点。Consul 还促进了领导者的选举,确定哪个节点应该是领导者,哪个节点应该是追随者。然后,Chronicle Queue 复制配置是由 Consul 中的集群状态衍生出来的。
该演示有以下属性:
当领导者节点失败时,一个追随者节点会自动晋升为新的领导者节点。
如果使用 Kubernetes 的“scale”命令来改变集群的大小,节点的配置将自动调整。这种扩展也可以根据负载情况自动进行。
新的节点由 Prometheus 发现,其指标会自动包含在仪表盘中。
故障转移大约发生在(检测故障所需时间,即健康检查超时)+(传播 Consul 状态的时间)+(到 Consul 服务器的 TCP 往返),在演示环境中,健康检查超时占主导地位。对于更多地理分布的部署,传播 Consul 状态的时间将变得更加重要。
这些功能大部分是通过配置而不是代码实现的。有一些插入标准 Chronicle 接口的瘦身适配器可以实现这种行为。
结论
本文展示了将一个动态的、低延迟的、基于 Chronicle 队列的应用程序部署到 Kubernetes 集群的一种方法。
Kubernetes(StatefulSets、动态配置)和 Consul(服务注册表、领导者选举、配置模板)中的一些结构与 Chronicle Queue Enterprise 中的概念非常匹配,大大简化了操作层面。
标准的 Chronicle 接口允许发布关键指标,以提供部署应用程序状态的实时视图。
作者介绍:
Peter Lawrey,开发者。
Nick Tindall,Chronicle Chronicle 顾问。
原文链接:
https://dzone.com/articles/deployment-of-low-latency-solutions-in-the-cloud

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论