

运维行业流传着一句话:“无监控,不运维”,监控的重要程度可见一斑。
随着互联网行业的不断发展,各种监控工具多得不可胜数,如何利用这些工具构建一个完整好用的监控平台呢?在近期召开的QCon上海2019大会现场,InfoQ 记者采访了饿了么框架工具部、监控平台负责人黄杰,他和我们分享了随着业务和系统越来越复杂,饿了么的监控平台是如何不断演进的。
饿了么的监控痛点与架构设计
与其它行业相比,外卖行业最显著的特点就是它的高峰和低谷是非常明显的,一般集中在中午的 10 点到 12 点和晚上的 5 点到 8 点,这样的瞬时高峰对于整个系统的压力会非常大,监控系统也不例外。
据黄杰介绍整个饿了么的业务发展是超高速的:“我加入饿了么的第一年,当时每天采集的原始数据差不多是 10 个 T,第二年就增长到了 80 个 T,第三年变成了 200T,而现在每天采集的原始数据可以达到 800T。”
在技术层面,监控系统不仅要支撑这样快速发展的业务,同时还要兼顾稳定性。在稳定性方面,饿了么 CTO 雪峰对监控系统的要求是比饿了么整个系统可用性高一个 9,因为监控是整个系统的眼睛,如果眼睛出了问题,会影响很多判断。
而在用户层面,饿了么监控系统要解决两类人的问题,第一类是 GOC 的问题,当系统出来问题的时候,怎么快速发现并恢复问题;第二类是开发人员,需要做到的是快速定位问题。
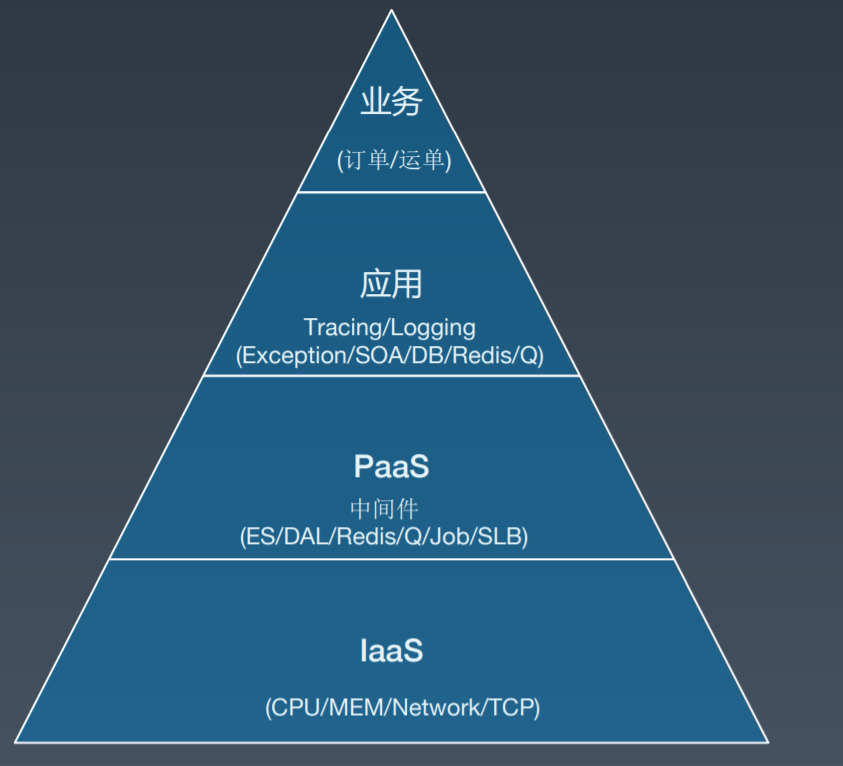
目前饿了么的监控系统覆盖了所有应用及服务器,包括业务监控、全链路监控、PaaS、IaaS 等。如果分层来看的话,最上层是业务,理论上可以做到端到端,针对某些特定业务的监控,运维团队会与业务团队一起协作;第二层是应用,云数据中心和本地数据中心的应用都可以监控到;第三层是 PaaS,例如 MySQL、Redis;最底层是 IaaS,主要是关注应用跑在哪些机器上,容器、物理机还是虚拟机,服务器之间的机架、交换机,机房之间的专线等等。
整个监控平台每天的增量数据大约有 800TB,高峰计算事件 7000W/s,1W 多个报警规则。
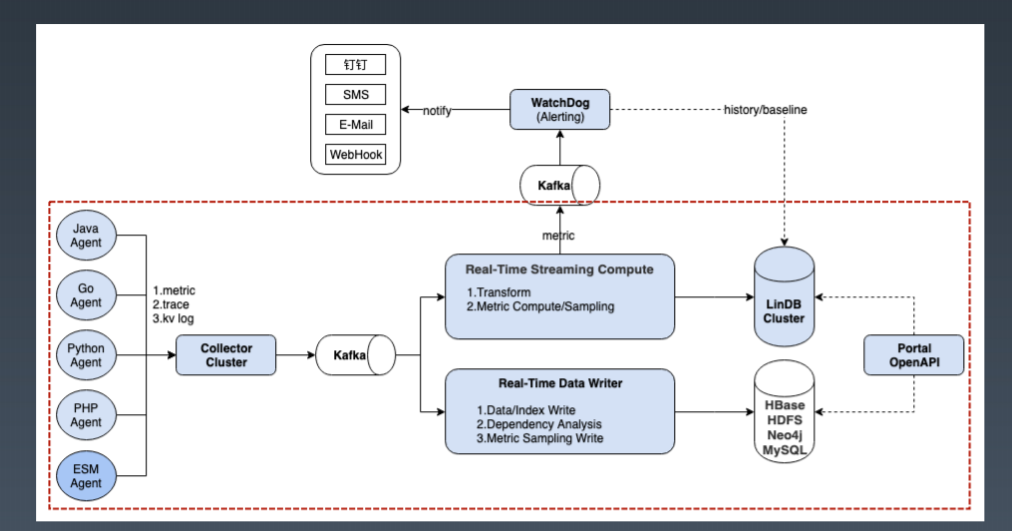
最早,饿了么监控平台的架构类似于 Pipeline 的架构,消息采集之后放到队列里,然后去处理,处理之后再进行存储。这种架构的缺点是如果一个环节出现问题,那么整个平台都可能出现问题。除了稳定性,Pipeline 架构整体的开发效率也是一个问题,由于很多监控的逻辑需要去了解业务,再通过代码来实现,所以实现一个监控项的整个周期会比较长。
因此,饿了么团队把一些实时计算的逻辑抽象出来,放到自研的一个类 SQL 的实时计算平台上,把收集到的无结构化的日志转换成结构化的数据之后(例如把一条普通的日志转换成一条 SOA 调用的日志),再通过 SQL 的方式计算出 Metrics,整个架构也慢慢的从 Pipeline 变成类似于 Lambda 架构,然后计算出来的 Metric 再回溯到 Kafka 中,这些 Metric 又可以被别的系统使用,如流式报警等。
根据重要程度,饿了么团队又把集群分为关键和非关键集群,在非关键集群上做灰度上线,以保证整个升级过程对用户无感,如果有问题,可以在非关键集群上提早暴露。
另外,在 Collector 这层还做了数据的动态 Load Balance,即根据用户发送的数据类型提前 Sharding 到 Kafka 不同的 Partition 中,这样的好处是 Kafka 后面的 Consumer 只需要处理一小部分数据即可,理论上来说随着数据量的增加只需要水平增加机器就可以解决容量上的问题。
饿了么监控平台的演进历程
开始的时候,饿了么的监控是由不同团队负责的,直到 2017 年底,把原来 3 个团队负责的监控系统整合成一个团队来负责。“统一的好处还是很显示的”,黄杰表示:“之前几套监控系统还是比较割裂的,相互之间关联性比较低,用户需要在不同的监控系统中看不同维度的监控,有些新同学刚加入的时候,都不知道去哪里查看,而现在有故障出现,普通的开发人员就可以直接查看监控,定位到问题出现在哪里,相比之前,效率的提升还是很明显的。”
最早,饿了么一共维护了三套监控系统,去年把三套系统合并成了一套。为什么要这么做呢?黄杰表示主要原因是三套系统来回切换在定位问题时是很浪费时间的。但是合并之后,推行新系统也遇到了一些难题,一是团队内部的矛盾,因为之前三套系统采集的数据和后台处理都是类似的,如何来统一呢?二是推行时遇到的外部矛盾,大家已经习惯了通过 Grafana 来查看业务大屏,如何让用户切换到新的平台上是一个比较大的阻力,后来,饿了么团队启动了一个公司级项目来推进这个事情,花了半年左右的时间,把所有的监控都统一到了现在的平台上。
从技术角度来看,饿了么监控平台从单 IDC 到异地多活共经历了三个阶段。当开发和业务初具规模时,当时主要是使用 ETrace 来做全链路监控,使用 Statsd+Graphite+Grafana 做业务层监控,使用 Zabbix 来做运营团队的业务监控;第二阶段标志性的就是做了异地多活,引入 ELK 做日志检索,使用自研的 ESM 系统替换掉 Zabbix,同时引入了自研的时序数据库 LinDB;第三阶段就是集成,把三个系统整合成到 EMonitor 系统,日志系统使用了阿里云的 SLS 产品,所有的时序数据存储统一走 LinDB,目前 LinDB 也在做开源版本。
在黄杰看来,整个监控平台在饿了么的发展和推行可以分为 3 个阶段:
第一阶段主要是在卖产品,在接近一年的时间中,让内部的员工接受并使用该平台;
第二阶段主要是查漏补缺,所有的监控不可能一蹴而就,肯定是有个过程的,所以这个阶段就是不断完善之前缺少的监控部分;
第三阶段是建立信任,通过前两阶段,内部员工渐渐享受到了监控平台带来的好处,这时要做的就是提升监控准确率,加深他们对平台的信任感。
目前饿了么监控平台采取的是自研+开源的开发模式,其中自研占据了 70%,分阶段性只做 2-3 件很重要的事情,不断打基础的同时服务好用户。
饿了么监控平台的报警策略
报警策略是很多企业都会面临的挑战,报警太少,可能会遗漏重大的错误,而报警太多,则会浪费时间和经历。黄杰表示:“我们没有使用目前比较流行的机器学习或者人工智能,而是使用的比较传统的报警策略,针对不同的数据类型提供不同的报警策略给用户使用。”
饿了么的报警策略有以下三种:
趋势型报警策略,主要的应用场景是业务大盘的(黄金指标)监控报警,因为外卖行业的数据特性还是非常强的,对于这类数据,饿了么团队会依据历史数据计算出一个基线数据,在计算基线数据的同时会去掉一些压测或者异常的数据,因为这些数据是噪音数据,再结合当前数据的趋势来预测将来的趋势应该是怎么样的,如果有偏离就会报警;
缺失报警策略,上面也讲了整个报警是流式事件驱动性的,如果数据没有了,整个报警就会失效,所以针对这种场景增加了缺失,以应对流量突然掉底的场景;
阈值报警策略,最基础的阈值报警,用户输入一个条件,高于或者低于就会报警。但建议用户把一些个数可以转换成比率,例如失败率>10%,比错误数>1000,更容易让人理解。
采访嘉宾介绍:
黄杰,饿了么框架工具部,监控平台负责人。2015 年加入饿了么,负责整个监控平台的构建及周边工具链的建设。整个监控也经历了饿了么异地多活地洗礼。之前曾在携程、eBao 等多家公司工作,在监控、消息系统及大数据等领域积累了丰富经验。
更多国内外一线技术大咖分享请持续关注 QCon 全球软件开发大会,访问官网与技术大咖面对面交流实践心得。

暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论