

诞生伊始,计算机处理能力就处于高速发展中。及至最近十年,随着大数据、区块链、AI 等新技术的持续火爆,人们为提升计算处理速度更是发展了多种不同的技术思路。大数据受惠于分布式集群技术,区块链带来了专用处理器(Application-Specific IC, ASIC)的春天,AI 则让大众听到了“异构计算”这个计算机界的学术名词。
“异构计算”(Heterogeneous computing),是指在系统中使用不同体系结构的处理器的联合计算方式。在 AI 领域,常见的处理器包括:CPU(X86,Arm,RISC-V 等),GPU,FPGA 和 ASIC。(按照通用性从高到低排序)
AI 是一门较为复杂、综合的学科。在只有 CPU 平台的情况下,AI 开发者要学习的算法、模型、框架、编程语言已经不少。如果再考虑多个不同处理器平台,情况会变得更为复杂。在展开讨论不同的应用场景之前,我们先了解一下什么是“异构计算”。
异构计算
首先需要明确的是,计算机体系结构≠硬件架构。体系结构不单包括硬件层面的实现,也包括软件层面的考量。当 IBM 在 S/360 服务器中提出体系结构这个概念之前,每一代 IBM 服务器的硬件实现都会有所不同(其实今日的处理器硬件亦是如此)。由此带来了各不相同的指令,以至于开发者编写的软件无法在不同的 IBM 服务器上运行。
因此,经典的体系结构概念与软硬件的界面——指令集有比较大的关系。通常来讲,如果两个处理器都能支持同一套指令集,那么可以认为它们有相同的体系结构。好比 AMD 的 CPU 和 Intel 的 CPU 都属于 X86 CPU。
虽然异构计算能带来潜在的算力提升,但也会造成额外的开发成本。在进行异构计算开发之前,开发者需要进行几个方面的评估。
第一,权衡代码通用性与代码性能。
今天的 AI 开发者恐怕只在较少的情况下可能会直接使用指令集进行编程(例如,X86 CPU 的 AVX2 指令等),绝大多数情况下,我们用到的主要是些程序库。然而程序库在不同平台上的实现依旧需要调用底层的指令集。在 AI 这样需要高性能编程的领域,常用的 BLAS (Basic Linear Algebra Subprograms)程序库就有多种选择:
即便只使用 CPU 进行计算,依然会面临诸如 OpenBLAS 和 Intel MKL 之间的选择。开发者需要根据具体需求谨慎评估通用性与性能之间的优先级。AI 这些年虽然很火,但是 AI 应用收益与开发成本的矛盾也一直较为突出。
第二,考虑开发环境的成熟度。
虽然 AI 开发者可用的计算硬件有 CPU,GPU,FPGA,ASIC 等,目前开发环境比较成熟的是 CPU,GPU 和 FPGA。ASIC 在开发成熟度上目前较为尴尬,因为应用专有芯片的开发依赖于所瞄准的应用是否已经达到了一个比较成熟的阶段。而 AI 领域中,即便是最成熟的机器视觉(CV)也依然还在持续发展中。因此,ASIC 厂商要打造一个较为稳定的开发环境面临一定的挑战。
这也无怪乎年初知名的“矿业”公司爆出了 AI 芯片团队大规模裁员的消息。
第三,考虑技术普及程度。
越普及的技术硬件成本越低,人才储备也更为充足。这一点上, FPGA 就比较占劣势,毕竟一般人很少机会接触 FPGA 硬件。
因此,目前异构计算开发仍然以 CPU 结合 GPU 为主。
寻找异构计算场景
要真正发挥异构计算的优势,必须得寻找合适的场景。否则 GPU 等协处理器并不总是能带来性能的提升。我们先来回想一下 GPU 最典型、最擅长的应用场景——大型 3D 游戏是怎么样的:
把游戏数据载入显存
在用户游戏的过程中,显卡始终在进行高速运算
以上看起来好像是一段废话,但要理解 GPU 等协处理器的特点,这段废话值得反复回味。GPU 的优势场景在于:
一定量的数据。如果数据量太小,那么 GPU 可能会比 CPU 慢。如何判断这个临界点也很简单,可以利用 Python 的 Pandas dataframe 和 RAPIDS 的 cuDF 进行一个对比测试。
数据量不能太大,显存一定要装得下。一旦发生显存对外的 I/O(哪怕是内存和显存之间的),处理速度依然会受到很大影响。
需要有持续的工作流发送给 GPU 处理。计算核心更多的 GPU 启动代价比 CPU 高得多。
看似矛盾的第一点和第二点说明,要找到异构计算的优势场景并不容易。事实上,一个计算任务的处理时间包括计算与 I/O(CPU 访问内存也算在内)两部分。高算力的 AI 处理器可以帮你加速计算的部分,但碍于服务器架构,异构计算也会带来一些额外的 I/O 开销。因此,问题的关键在于一个程序的处理时间究竟是花在计算上更多,还是花在 I/O 上更多。
在 Linux 系统下,我们可以通过 perf 工具(Linux kernel profiling)来了解一个处理任务执行时的 CPU 计算繁忙程度。

(引用自: https://perf.wiki.kernel.org/index.php/Tutorial )
在上面的示例中,IPC(Instructions Per Second)仅为 0.679,要知道现代的 CPU 单核 IPC 理论峰值可以达到 10。一般认为,运行时 IPC 如果低于 1,说明正在运行的工作流在 I/O(CPU 读取内存)上花的时间更多。在这种情况下,异构计算带来的提升就不太可能像硬件厂商宣传的那样达到 10 倍,甚至 100 倍。
前面提到“异构计算也会带来一些额外的 I/O 开销”。这主要受限于以 CPU 为核心的系统架构,其他协处理器只能通过 PCI/E 连接到系统。当需要把数据从硬盘载入到显存的时候:(假设使用 PCI/E 硬盘)
数据从硬盘经过 PCI/E 复制到内存
数据从内存经过 PCI/E 复制到显存
在这种情况下,数据从硬盘载入显存的速度只有 PCI/E 传输速度的一半。为了解决这个问题,GPU 厂商开发了 GPUDirect Storage 技术,这样可以直接把数据从硬盘加载到显存。
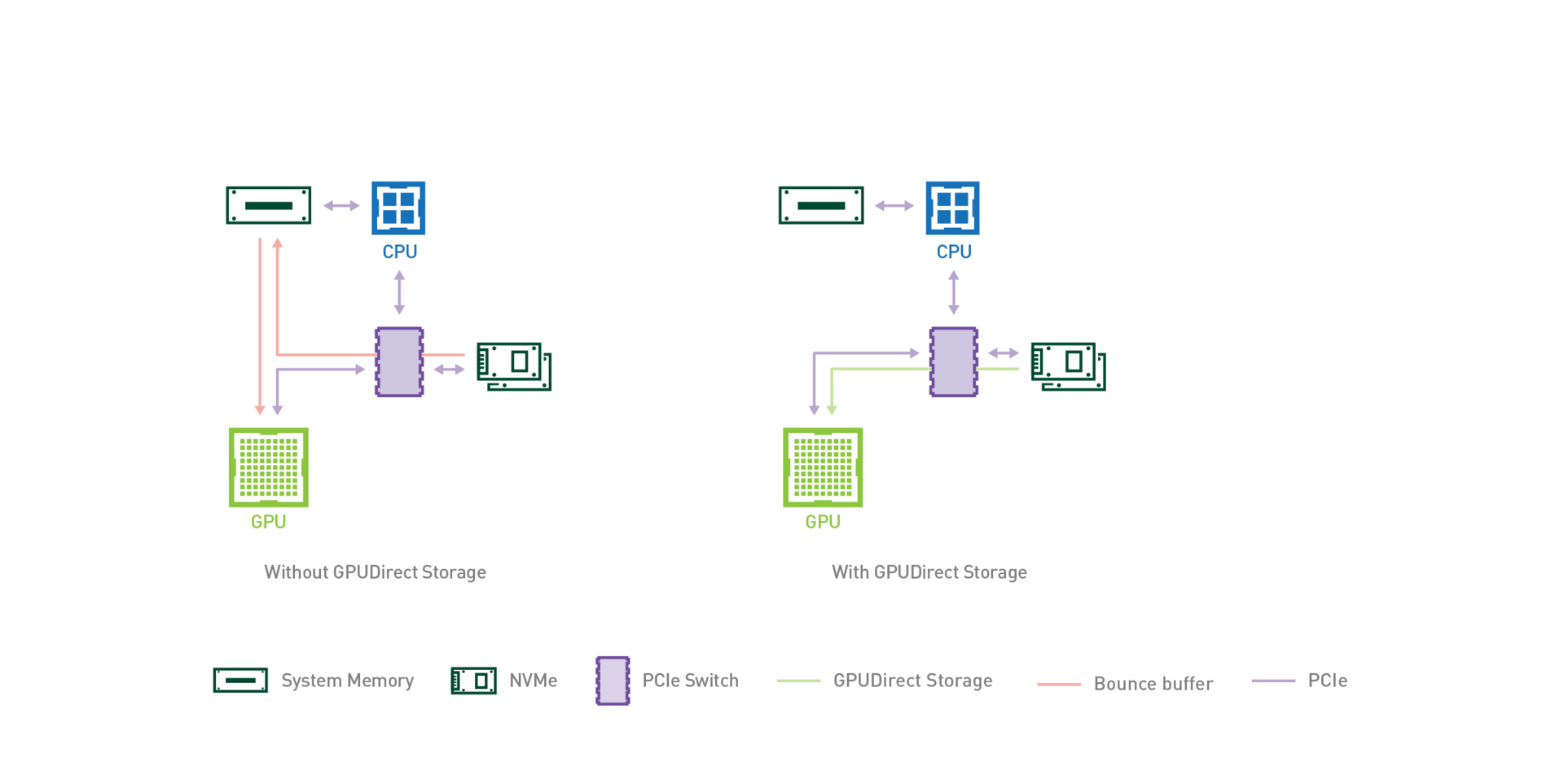
(引用自: https://devblogs.nvidia.com/gpudirect-storage/ )
一般企业级计算显卡的显存大小为 16GB 或 32GB,而一般企业级 CPU 的内存上限可以达到 768GB 或 1TB。在海量数据的场景下,如何利用异构算力需要仔细的设计,不然异构计算产生的 I/O 开销可能会适得其反。
异构计算在 AI 中的应用
异构计算的优势与局限都非常突出。在 AI 的全流程中,开发者逐渐在以下阶段中找到了异构计算的场景。
数据准备阶段
不同于传统大数据应用,AI 应用的数据不但包括一般的结构化数据,也包含了大量非结构化数据(如图片、视频、声音、文本等)。针对海量结构化数据的处理,因为通常 I/O 占比远高于计算占比,因此这部分数据的处理依旧以 CPU 为主。不过,今天的 CPU 也提供了 AVX2 向量指令集进行 SIMD 计算(单指令多数据)。
但在非结构数据,尤其是图片、视频等的转解码处理上,异构芯片的优势还是比较明显。
模型训练、调优阶段
目前的深度学习模型主要是基于张量(tensor based)模型,很多 AI 处理器会着重加强自己的乘累加(MACC,基础的矩阵计算操作)处理能力。模型训练是整个 AI 流程中异构计算最为有优势的部分。GPU,TPU 和其他一些 ASIC 都能在这里发挥作用。
回想一下前文中讨论过的游戏场景,模型训练是不是和它很像呢?
运行时阶段
运行时的任务主要包括模型推理,向量相似度搜索等。
模型推理本身并不需要像模型训练那样进行大规模计算,但模型推理往往涉及多种不同类型的硬件部署平台。因此,模型推理中的异构计算首要任务不是融合算力,而是考虑代码的跨平台通用性以降低开发成本。业界已经有一些开源模型推理框架来解决代码的跨平台通用性问题,比如 Linux 基金会旗下的 Adlik 和 微软的 ONNX RT。
向量相似度搜索,是图片、视频搜索、推荐系统、问答系统中的常用技术。由于要搜索的特征向量规模往往会达到上亿甚至十亿级,搜索时的 I/O 比重很高,异构计算在搜索时的帮助会比较有限。但是在建立向量相似度索引时却是一个典型的计算密集型任务,异构计算能大幅提升索引创建速度。供开发者参考的开源项目有 Facebook Faiss、Spotify Annoy、NMSLIB 以及 Linux 基金会旗下的 Milvus 等。
总结
作为异构计算专题的开篇,本文整体性的介绍了异构计算的定义,场景与局限性。在后续的专题文章中,我们将深入不同的 AI 应用场景进一步解释异构计算的优势。
作者简介:
顾钧,毕业于北京大学,在数据库相关领域有 15 年经验。目前任职于 ZILLIZ,负责 Milvus 开源向量搜索引擎的社区建设与推广。

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论