

有没有想过自己对某个好玩的历史数据集进行分析呢?比如,历届春晚的历史数据集,看看谁上春晚次数多,谁人气最高等等,可是分析的思路又该是什么样的呢?InfoQ 带来了 Sadrach Pierr 博士的文章,虽然不是对春晚的历史数据集分析,但思路是类似的,话不多说,让我们看看他是怎么对超级碗历史数据集进行分析的,相信对你一定有所裨益!
超级碗(Superbowl)是美国一年一度的比赛,决定着美国国家橄榄球联盟(National Football League,NFL)的冠军。这是世界上收视率最高的年度体育赛事之一,在美国,拥有大量的国内观众,平均每年有超过 1 亿人收看超级碗。
在本文中,我们将分析超级碗历史数据集(1967-2020 年)。我们将生成汇总统计和数据可视化信息,如获胜球队、大球场、获胜得分和最有价值球员。我们将要使用的数据可以在这里找到。
言归正题。
首先,让我们用 pandas 导入数据:
接下来,我们可以打印列的列表:

如你所见,有 10 列。让我们打印前五行。
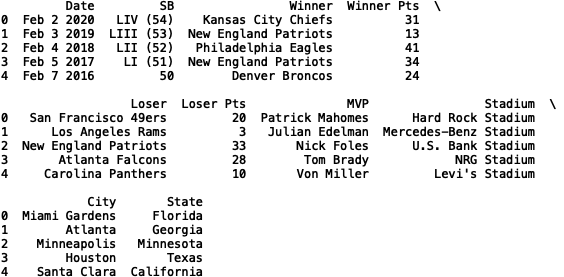
我们可以看到有几个分类列。让我们定义一个函数,该函数接受数据框、列名和限制作为输入。调用时,它将打印分类值字典及其出现的频率:
让我们将函数应用到最有价值球员(Most Valuable Player,MVP)列,并将结果限制在以下五个最常见的值:
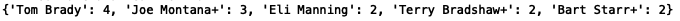
我们将会看到,Tom Brady 拥有最多的 MVP 记录,其次是 Joe Montana。

让我们将函数应用到“Stadium”(大球场)一栏:
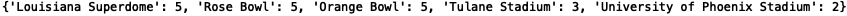
Louisiana Superdome、Rose Bowl、Orange 在数据集中出现了 5 次。
让我们试试看“Winner”(获胜者)列,它对应于获胜球队。

New England Partriots 和 Pittsburg Steelers 以六场胜利并列。
我鼓励你将此函数应用于其余的分类列,如“State”(州)、“City”(城市)和“Loser”(失败者)等。
正如你所见到的,这是一个非常有用的快速测试,可以查看数据中是否存在任何明显的不平衡,这通常是在构建模型时需要处理的一个关键问题。
接下来,从数字列生成汇总统计数据将会很有用,如“Winner Pts”,这是获胜球队的得分。让我们定义一个函数,该函数接受一个数据框、一个分类列和一个数字列。每个类别的数字列的平均值和标准差存储在一个数据框中,数据框按照平均值降序排序。如果要快速查看特定数字列的某些类别的平均值和 / 或标准差值是否更高还是更低,这将非常有用。
我们可以查看“Winner”和“Winner Pts”的汇总统计数据:
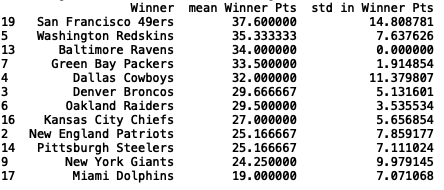
旧金山 49 人队的“Winner Pts”平均得分和“Winner Pts”的标准准差都是最高的。
接下来,我们将使用箱型图根据最小值、最大值、中值、第一个四分位数和第三个四分位数的数值分布进行可视化。如果你对它们不熟悉,可以看看这篇文章《理解箱型图》(Understanding Boxplots)
与汇总统计函数类似,该函数接受一个数据框、分类列和数字列,并根据限制显示最常见列表的箱型图:
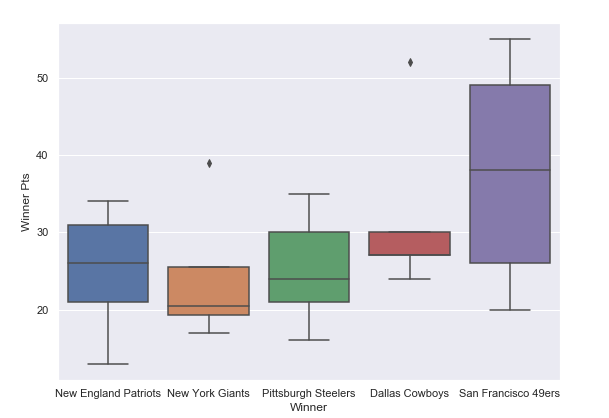
让我们为 5 个最常见的获胜球队中的“Winner Pts”生成箱型图:
我们还可以定义一个函数,来显示得分的时间序列图。首先,让我们将“Date”转换为“date-time”对象。
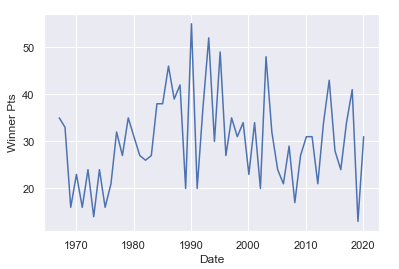
接下来,让我们定义一个函数,该函数以数字框和数字列作为输入,并显示“Winner Pts”的时间序列图:
让我们用数据框和“Winner Pts”来调用这个函数:
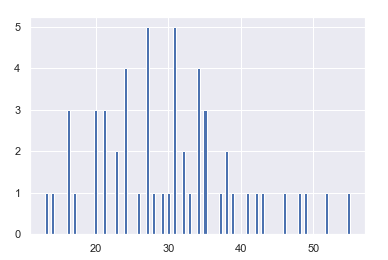
最后,让我们定义一个函数,该函数将数据框和数字列作为输入,并显示一个直方图:
让我们用数据框调用函数,并生成得分的直方图:
我就讲到这里,但你可以随意使用数据并自己编写代码。
概括地说,我在本文中,研究了分析超级碗历史数据集的几种方法。这包括定义用于生成汇总统计数据的函数,如平均值、标准差和分类值计数等。我们还定义了用箱型图、直方图和时间序列图对数据进行可视化的函数。这篇文章的代码可以在 GitHub 上找到。
作者介绍:
Sadrach Pierre 博士,热情的数据科学家,对自然语言处理、机器学习、数学、物理和化学感兴趣。
原文链接:
https://towardsdatascience.com/analyzing-the-superbowl-history-dataset-1967-2020-fdee01a760c9
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论