

Kylin 在贝壳的使用情况介绍
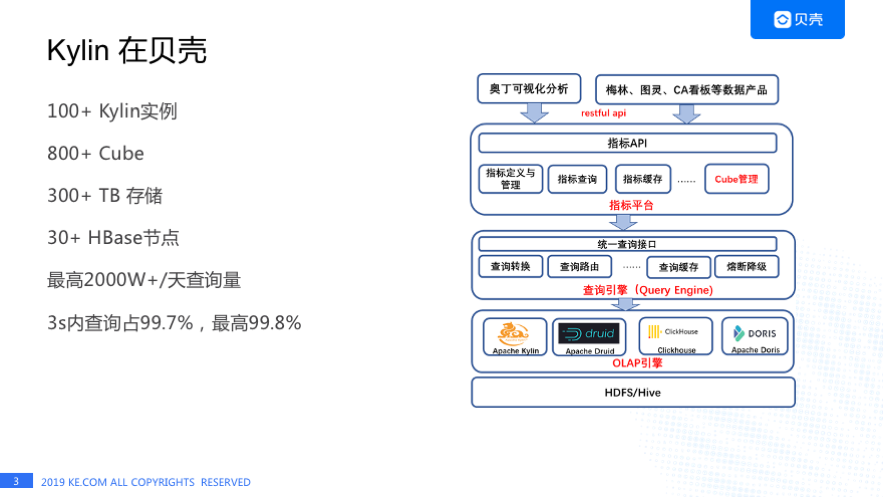
Kylin 从 2017 年开始作为贝壳公司级 OLAP 引擎对外提供服务, 目前有 100 多台 Kylin 实例;有 800 多个 Cube;有 300 多 T 的单副本存储;在贝壳 Kylin 有两套 HBase 集群,30 多个节点,Kylin 每天的查询量最高 2000+万 。
我们负责 Kylin 同事张如松在 2018 年 Kylin Meetup 上分享过Kylin在贝壳的实践,当时每天最高请求量是 100 多万,两年的时间里请求量增加了 19 倍;我们对用户的查询响应时间承诺是 3 秒内的查询占比要达到 99.7%,我们最高是达到了 99.8%。在每天 2000+W 查询量的情况下,Kylin 遇到很多的挑战,接下来我将为大家介绍一下我们遇到的一些问题,希望能给社区的朋友提供一些参考。
Kylin HBase 优化
表/Region 不可访问
1)现象:

凌晨构建 Cube 期间,会出现重要表的某个 region 不可访问导致构建失败的情况,右上角的图是 HBase 的 meta 表不可访问的日志;白天查询时也有部分查询因为数据表某个 Region 不可访问导致查询超时的情况,右下角的图是查询数据表 Region 超时的日志;另外一个现象是老的 Kylin 集群 Region 数量达到 16W+,平均每台机器上 1W+个 Region,这导致 Kylin HBase 集群建表和删表都非常慢,凌晨构建会出现建表卡住的现象,同时清理程序删除一张表需要三四分钟的时间,面对这样的情况,我们做了一些改进。
2)解决方案:

删除无用表减少 Region。 通过刚才的介绍 HBase 集群平均每台机器上 1W+个 Region,这对于 HBase 来说是不太合理的,另外由于删除一张表需要三四分钟的时间,清理程序也执行的异常缓慢,最后我们不得不使用了一些非常规手段删除了 10W+个 Region。
缩短清理周期, 从之前的一周清理一次 HBase 表到每天清理一次,除此之外 Kylin 会每周合并一次 Cube 来减少 HBase 表数量从而减少 Region 数量,最终 16W+的 Region 删到了不到 6 万,至此我们解决了一部分问题,还会存在构建时重点表的 Region 不可访问的情况。
将 HBase 从 1.2.6 升到 1.4.9, 主要是想要利用 RSGroup 的能力来做重点表和数据表的计算隔离;
关闭 HBase 自动 Balance 的功能, 仅在夜间业务低峰期开启几个小时;
使用 HBase 自带的 Canary 定期的检测 Region 的可能性, 如果发现某些 Region 不可用马上发送告警
使用 RSGroup 单独隔离重点表来屏蔽了计算带来干扰, 这些重点表包括 HBase Meta 表、Acl 表、Namespace 表、Kylin_metadata 表。
经过了这一系列的改进之后表/Region 不可访问的问题基本上解决了,现在基本上没有再出现 Region 不可访问的情况。解决这个问题我们花费了很长时间,经历了升级重启和删了大量的表后,我们遇到了另外一个问题。
RS 数据本地性提升
1)现象

Kylin HBase 集群的 RegionServer 数据本地性非常低,只有 20%不能很好的利用 HDFS 短路读,这样对查询响应时间产生了一定影响 ,我们三秒内的查询占比出现了下降。了解 HBase 的朋友都知道如果 RS 的数据本地性较低,有一种解决方案就是做 Compact 把数据拉到 RegionServer 对应的 Datanode 上,考虑到大规模的做 Compact 会对查询造成很大影响,我们没有这么做,跟 Kylin 的同学沟通后发现绝大多数的 Cube 每天会使用最新构建的表,查旧表的可能系不是特别大,所以提升每天新建表的数据本地性就可以了, 具体我们是这样做的。
2)解决方案

我们发现 Kylin 用到的是 HFileOutputFormat3 跟 HBase 的 HFileOutputFormat2 是有一些差别的,我们在 HFileOutputFormat3 里面加入了 HBASE—12596 的特性,这个特性主要是生成 HFile 的时候会写一份数据的副本到 Region 所在的 RegionServer 对应的 Datanode 上。下面是一些代码细节,程序会先取到这个 Region 所在的机器,然后再获取 Writer 时,把这台节点的信息传递过去,最后写数据的时候会写一个副本到这个 Region 对应的 Datanode 上, 这样逐渐我们的数据稳定性就提上来了,现在看了一下基本上在 80%多左右。
RegionServer IO 瓶颈
1)现象
我们发现在构建早高峰时,HBase 响应时间的 P99 会随之升高的,通过监控发现是由于 RegionServer 机器的 IO Wait 偏高导致的。
还有一种场景是用户构建时间范围选择过大,导致网卡被打满,之前有个用户构建了一年的数据,还有构建三四个月数据,这两种情况都会造成 RegionServer 机器 IO 出现瓶颈导致 Kylin 查询超时。
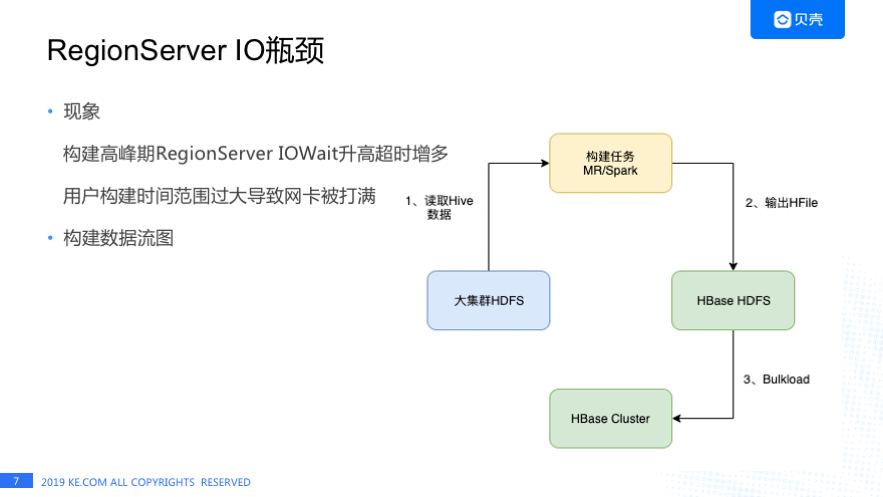
上图是 Cube 数据构建流程,首先 HBase 集群和公司大的 Hadoop 集群是独立的两套 HDFS 集群,每天构建是从大集群的 HDFS 去读取 Hive 的数据,构建任务直接输出 HFile 到 HBase 的 HDFS 集群,最后执行 Bulkload 操作。由于 HBase HDFS 集群机器较少,构建任务写数据过快导致 DataNode/RegionServer 机器 IO Wait 升高,怎么解决这个问题呢?
2)解决方案
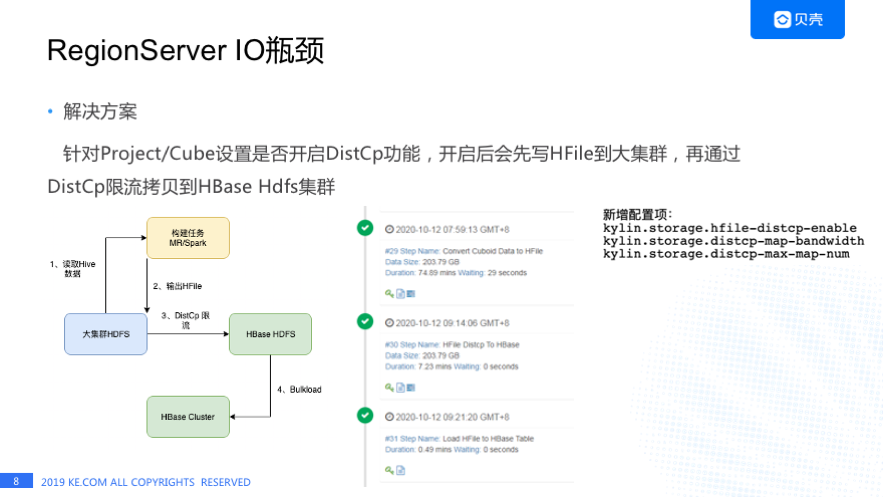
我们想用 HBase 比较常用的方式就是 DistCp 来解决这个问题,左下角这张图是我们的改进方案,就是我们设置构建任务的输出路径到 Hadoop 的大集群,而不是到 HBase 的 HDFSB 及群,再通过 DistCp 限流的拷贝 HFile 到 HBase 的 HDFS 集群,最后做 Bulkload 操作。之前提到我们有 800 多个 Cube,并不是所有的 Cube 都需要走这套流程, 因为限流拷贝的话肯定会影响数据的产出时间,我们设计了针对 Project 或者是 Cube 设置开启这个功能, 我们通常会对数据量比较大的 Cube 开启 DistCp 限流拷贝,其他 Cube 还是使用之前的数据流程。
中间这个图是一个构建任务的截图,第一步是生成 HFile,第二步是 DistCp,最后再 Bulkload,这个功能我们新增了一些配置项,比如说第一个是否开启 DictCp,第二个是每个 Map 带宽是多少,再有就是最大有多少 Map。通过这个功能我们基本上解决了构建高峰 IOWait 会变高的情况。
慢查询治理–超时定位链路优化
1)现象
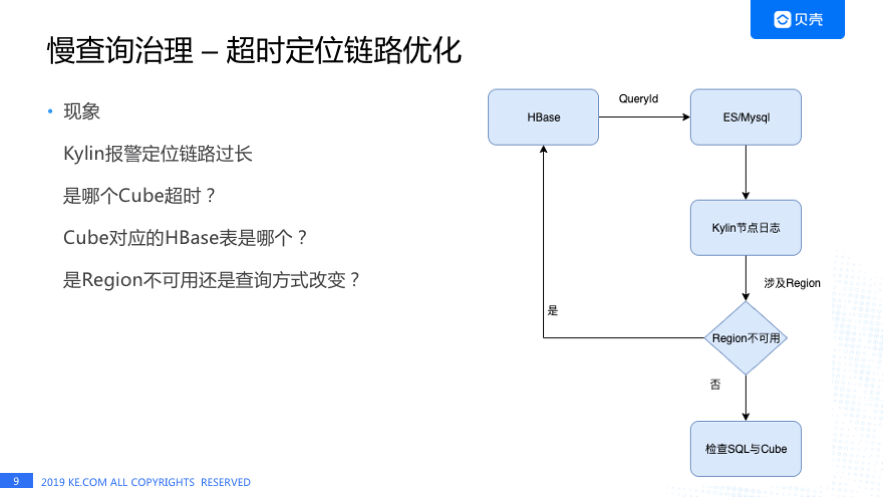
慢查询治理遇到的第一个问题就是超时定位链路特别长。我们收到 Kylin 报警时首先会想知道:
是哪个 Cube 超时了?
Cube 对应的 HBase 表是哪个?
是 Region 不可用还是查询方式变了?
之前提到有一段时间经常出现 Region 不可用的情况,一旦出现超时我们查询链路是什么样的呢? 可能我们先去看 HBase 日志里看有没有 Deadline has passed 的警告日志,有这种报警的话我们会拿到它的 QueryID,然后去 ES 或者是 Mysql 里面去查询这个 QureyID 对应的 Cube 信息和 SQL,知道这些信息之后,还需要去到超时的 Kylin 节点上去查询日志,从日志里面才能找到是查询哪个 HBase 表的哪个 Region 超时,然后再去判断是不是 Region 不可用了,或者是查询方式改变。 这个链路非常长,每次都需要 HBase 和 Kylin 的同学一块儿来查。
2)解决方案
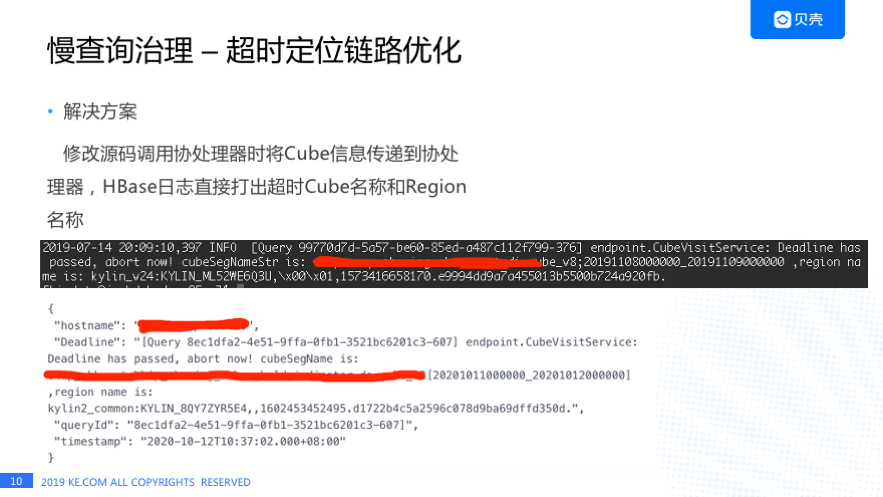
针对这个痛点给我们做了如下改进:我们直接把 Cube 信息和 Region 的信息打在 HBase 的日志里。 中间这个黑色的部分就是 HBase 的日志,我们可以看到这个查询已经终止了,Cube 的名字是什么,Region 的名字是什么,下面的白色部分是通过天眼系统配置的报警信息,这个报警是直接报到企业微信的,我们能马上知道这个 Deadline 涉及的 Cube 和 Region,能马上做一个检测是这个表不可用了还是查询方式改变了,大大节省了定位问题的时间。
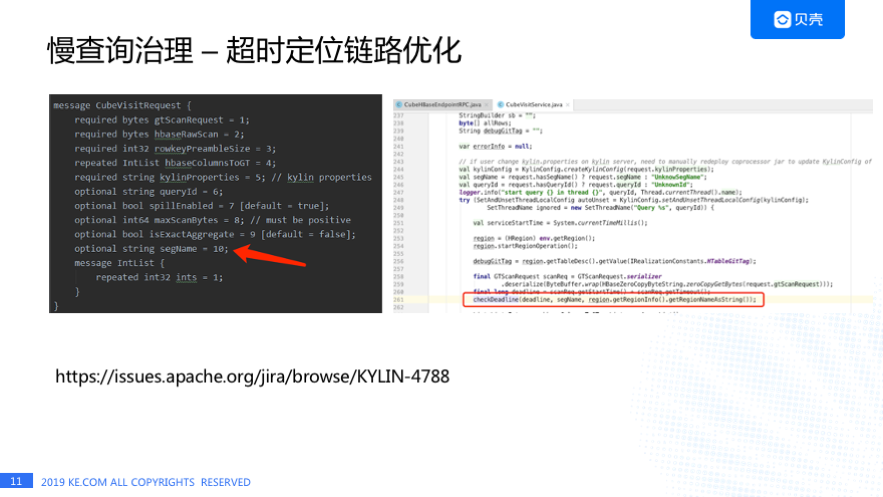
这个是为了解决超时链路过长我们对 Kylin 做的一些代码改动,首先我们在 Protobuf 文件中加了一个 segmentName 字段,然后在协处理器类中获取了 Region 名字,在协处理器调用 checkDeadLine 方法检查时传入 segmentName 和 regionName,最后日志会打印出来 segment 名称和 Region 的信息。 这个功能已经反馈给社区了,见:https://issues.apache.org/jira/browse/KYLIN-4788
慢查询治理-队列堆积定位
1)现象

有一天我们发现 Kylin HBase RegionServer 队列堆积非常严重,RegionServer 的 P99 的响应时间已经达到了 10 多分钟的级别,大家看右上角是 HBase 关于队列的监控情况,一些机器的堆积已将近 3W。我们当时非常疑惑,因为 Kylin 和 HBase 之间 RPC 的超时时间是 10 秒,在 10 秒之后 Kylin 和 HBase 的连接都已经断开了,HBase 到底处理什么查询,右下角是 HBase RegionServer UI 页面的截图,在这个截图里我们发现一些查询其实已经执行了快半个小时了,这半个小时是在执行什么呢?
2)解决方案

我们当时的解决方案是去任务堆积的有队列推积的 RegionServer 上去看日志,通过查询开始时间结束时间做差值,找出查询时间最长的 Top10 的查询,通过 QureyID 匹配出 Cube 和具体的 SQL,最终我们发现一般这种查询时间特别长都是因为查询方式的变化与原来 Cube 设置的 Rowkey 不相符导致了全表扫描。最终的方案其实查出来之后 Kylin 的同学会去调整 Cube 的 Rowkey 设置,然后重新构建。
这种离线的定位的方式其实不是特别好,一开始我们想基于日志做实时报警,这样能帮助我们更快的发现和定位问题,但是后来想想这也是比较被动的一种方式,这只是发现问题,不能彻底解决这个问题。
我们后来想的一个方案是 SQL 作执行之前可以为 SQL 打分,评分过低的就拒绝执行,这个功能还没有实现。有这个想法是因为当我们找到 SQL 信息后, Kylin 的同学是可以看出来查询是不是不合理,是不是跟 Rowkey 设置不符,我们想以后做这样一个功能,把人为判断的经验程序化,在 SQL 没有执行之前就把潜在的风险化解掉。
慢查询治理 – 主动防御
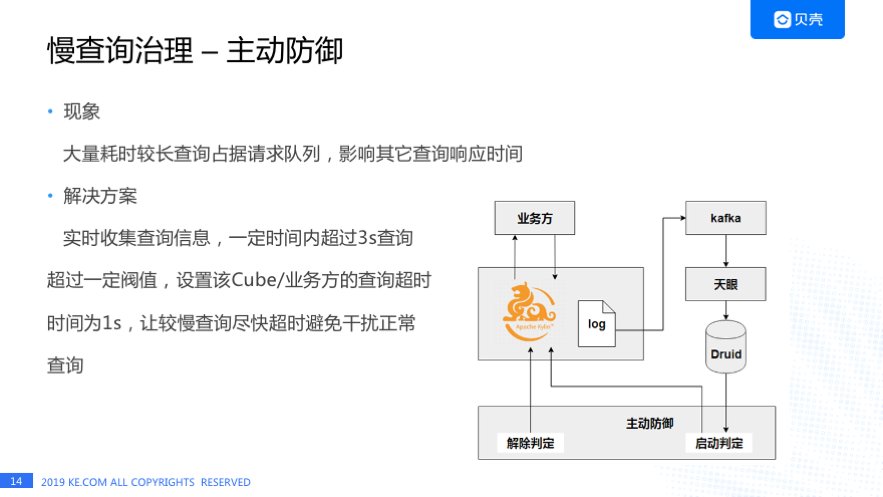
慢查询治理还有一个举措是 Kylin 的主动防御。我们发现有大量的耗时较长的查询会占据请求队列,影响其他查询的响应时间。
解决方案是通过 Kafka 收集 Kylin 的日志,经过天眼系统实时清洗后写入 Druid,通过 Druid 做统计分析,如果某个业务方/Cube 在一定时间内超过 3 秒的查询到达一定的阀值,主动防御系统会把这个业务方/Cube 的查询超时时间设置为 1s,让较慢的查询尽快超时,避免对正常查询的干扰。右边就是我们整个流程的一个架构图,主动防御对慢查询治理有一定的作用,但全表扫描的情况还是没有办法完全避免。
重点指标查询性能保障
1)现象

另外一个举措是对重点指标的查询性能保障。早期 HBase 集群只有 HDD 一种存储介质,重点指标和普通指标都存储在 HDD 上,非常容易受到其他查询和 HDD 性能的影响,重点指标响应时间无法保障。
2)解决方案
我们的解决方案是利用了 HDFS 的异构存储,给一部分 DataNode 插上 SSD,将重点 Cube 的数据存储在 SSD 上,提升吞吐的同时与普通指标数据做存储隔离,这样就既避免了受到其他查询的影响,也可以通过 SSD 的性能来提升吞吐。引入 SSD 只是做了存储的隔离,还可以通过 RSGroup 做计算隔离,但由于重点指标的请求量占到了集群总请求量的 90%以上,单独隔离出几台机器是不足以支撑这么大请求量的,所以最终我们并没有这么做。
最后是我们得出的一些经验, SSD 对十万以上扫描量查询性能提升 40%左右,对百万以上扫描量性能提升 20%左右。
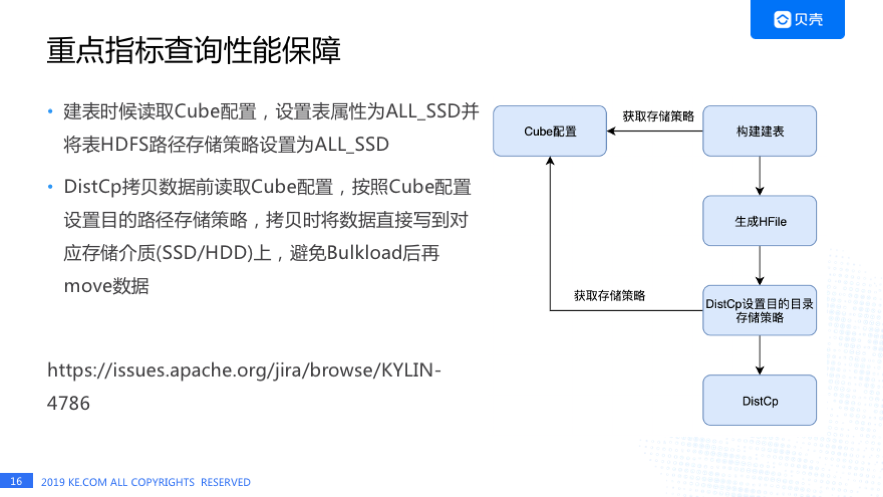
这是我们用 SSD 做的一些改动,数据存储在 SSD 是可针对 Cube 设置的。我们可以指定哪些 Cube 存在 SSD 上,构建任务建表时会读取 Cube 的配置,按照 Cube 配置来设置 HBase 表的属性和该表的 HDFS 路径存储策略。在 DistCp 拷贝之前也要先读取 Cube 的配置,如果 Cube 的配置是 ALL_SSD,程序需要设置 DistCp 的目的路径存储策略为 ALL_SSD,设置完成后再进行数据拷贝。
这样做的目的是为了避免 Bulkload 后数据还需要从 HDD 移动到 SSD,移动数据会带来什么影响呢? 我们发现如果不先设置 DistCp 目的路径存储策略的话,数据会被先写到 HDD 上,Bulkload 后由于表的 HDFS 存储路径存储策略是 ALL_SSD,Hadoop 的 Mover 程序会把数据从 HDD 移动到 SSD,当一个数据块的三个副本都移动到 SSD 机器上后,RegionServer 不能从其缓存该数据块的三台 DataNode 上读取到数据,这时 RegionServer 会随机等待几秒钟后去向 NameNode 获取该数据块最新的 DataNode 信息,这会导致查询响应时间变长,所以需要在 DistCp 拷贝数据之前先设置目的路径的存储策略。
JVM GC 瓶颈
1)现象
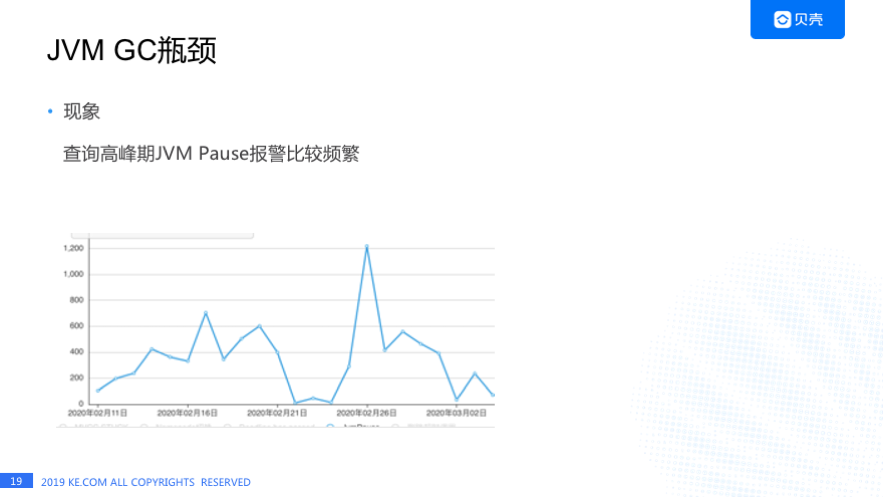
我们遇到的下一个问题就是 RegionServer 的 JVM GC 瓶颈。在查询高峰期 Kylin HBase JVM Pause 报警特别频繁,从这张图里面可以看到有一天已经超过 1200 个。Kylin 对用户的承诺是三秒内查询占比在 99.7%,当时已经达到了 99.8%,于是我们就想还需要优化哪一块能让 3 秒内查询占比达到 99.9%,这个 JVM Pause 明显成为我们需要改进的一个点,大家做 JAVA 基本都知道 JVM 怎么去优化呢?
2)解决方案
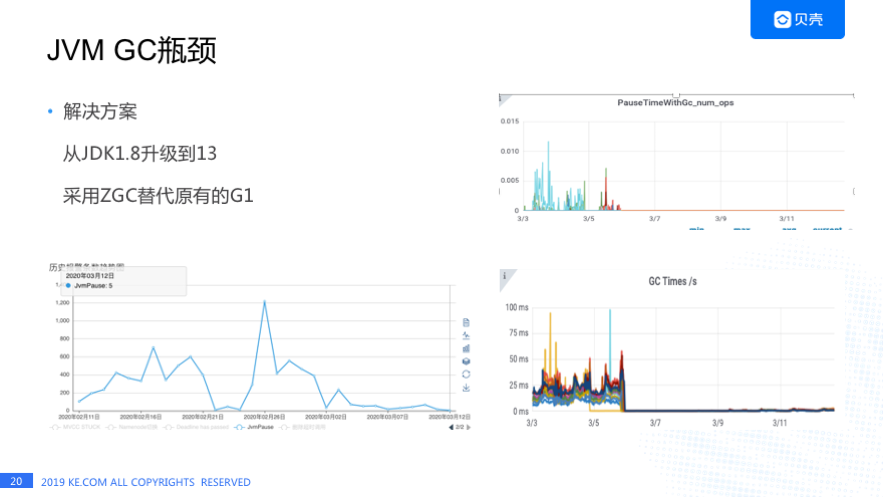
首先可能会想到调整参数,其次就是换一种 GC 算法,我们采用了后者。 之前我们用的是 JDK1.8,GC 算法是 G1,后来我们了解到 JDK11 推出了一个新的算法叫 ZGC。最终,我们把 JDK 从 1.8 升级到 JDK13,采用 ZGC 替代了原有的 G1。右上角的图是 ZGC 上线后,这套集群 RegionServer 的 JVM Pause 的次数几乎为 0,右下角的 GC 时间也是相比之前降低特别多。ZGC 有一个设计目标是 Max JVM Pause 的时间在几毫秒,这个效果当时看着是比较明显的,左边的图是天眼系统的报警的趋势图,ZGC 上线后 JVM Pause 报警数量明显降低。关于 ZGC 我本月会发一篇文章介绍 ZGC 算法和我们做了哪些改动来适配 JDK13,这里就不详细介绍了。
作者介绍:
冯亮,贝壳找房高级研发工程师。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论