
人工智能模型正在加速发展,但基础设施却未能跟上。随着大语言模型从客户支持到企业搜索全面赋能,传统单体式服务器架构正在成为巨大的瓶颈,而解耦(disaggregation )或许是突破之道。
大语言模型简介
大语言模型已经从研究项目转变为关键的商业基础设施,从客户服务聊天机器人到内容创作平台全面赋能。像GPT-4、Claude和Llama这样的模型拥有数十亿个参数,需要有复杂的计算基础设施才能高效地提供预测。
一个基本的挑战在于图 1 所示的 LLM 推理的双重性:一个初始的“预填充”阶段,同步处理输入上下文,然后是一个迭代的“解码”阶段,逐个生成输出令牌。这些阶段的计算特性完全不同,带来了传统服务架构无法有效解决的优化挑战。
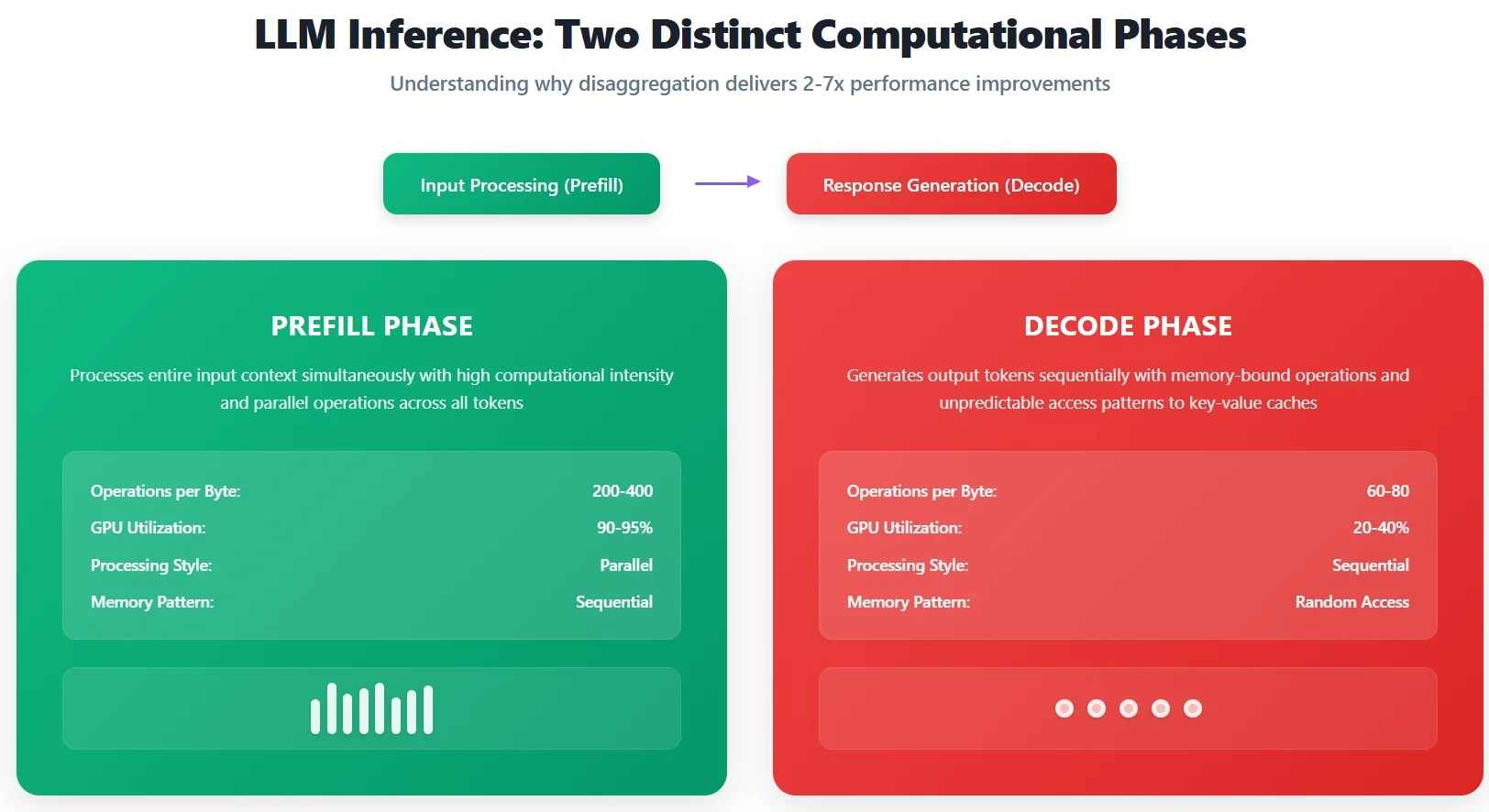
图 1:预填充和解码阶段的特性
理解预填充和解码阶段
预填充阶段计算强度高,每字节内存访问有 200-400 个操作,在现代加速器上实现了 90-95%的 GPU 利用率。多个请求可以高效地批量处理,使其非常适合计算密集型硬件。
相比之下,解码阶段每字节只有 60-80 个操作,由于内存带宽限制,仅实现了 20-40%的 GPU 利用率。每个令牌的生成都需要访问模式不可预测的大型键值缓存,使得高效批量处理变得困难。
这两个阶段之间的计算特性差了 5-10 倍。不同的应用场景加剧了这一挑战:摘要任务需处理大量预填充内容(占计算时间的 80-90%),输入庞大而输出精炼;交互式聊天机器人则要求响应时间低于 200 毫秒,且输入长度不固定。而Agentic AI系统需管理 8K 至 32K+令牌的复杂上下文,并集成内存密集型工具,这就需要采用截然不同的优化策略。
为什么单个加速器无法优化两个阶段
像NVIDIA H100和A100 GPU 这样的现代 AI 加速器是为特定的计算模式而设计的,这些模式能很好地匹配预填充或解码,但无法同时兼顾两者。H100 3.35 TB/s 的内存带宽和比 A100 高出 3 倍的计算能力使其非常适合预填充阶段这样的计算密集型操作。然而,由于内存架构的不同,A100 在解码阶段更高效。
这种优化困境源于基本的硬件权衡。预填充阶段受益于高计算密度和大芯片内存,而解码阶段需要高内存带宽和低延迟访问模式。对一个阶段有益的内存层次结构优化往往会对另一个阶段有害,而且,由于使用模式不同,能效差异显著。
在 LLM 推理期间,预填充阶段有效地利用了张量核心,通常能接近最大硬件容量。相比之下,解码阶段利用率往往低很多,报告的值通常是预填充的三分之一或更少。此外,预填充阶段的能效显著更高;研究表明,相对于解码阶段,其单个操作的效率提高了 3-4 倍。这些硬件性能和能耗的差异凸显了单体推理的限制。
LLM 推理服务解耦的兴起
与普遍认知相反,vLLM框架早在 2023 年 6 月推出时,就率先实现了专为服务场景设计的解耦式大语言模型服务方案。尽管DeepSpeed早在 2022 年就实现了异构推理能力,但其核心关注点在于模型并行化,而非通过预填充-解码解耦技术优化服务性能。
vLLM的突破性进展在于采用了PagedAttention机制实现了高效的键值缓存管理,以及通过连续批处理技术提升了吞吐量。如图 2 所示,0.6.0 版本使 Llama 8B 模型的吞吐量提升了 2.7 倍,每输出令牌耗时缩短至原先的 1/5,为该技术在行业内的广泛应用奠定了基础。
SGLang随后推出,借助RadixAttention和结构化生成能力,实现了比基线实现高 6.4 倍的吞吐量,并且在 Llama-70B 模型上始终比竞争对手高出 3.1 倍。学术界通过DistServe(OSDI 2024)巩固了理论基础。该方案相较于同地部署的系统实现了 4.48 倍的吞吐量提升,并使不同阶段间的延迟波动降低了 20 倍。
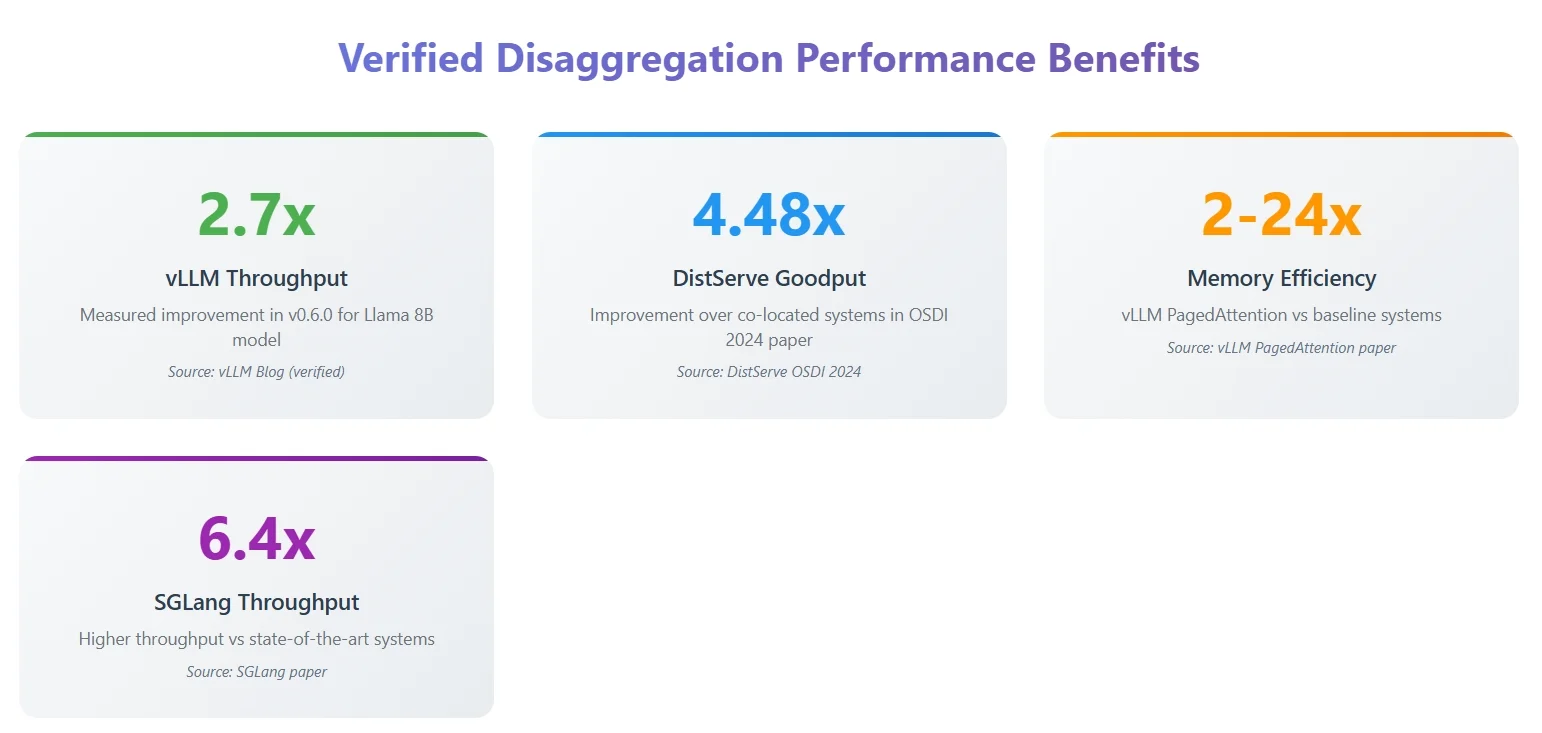
图 2:解耦的好处
经济影响和商业案例
传统单体 LLM 服务存在明显的低效问题:针对解码阶段过度配置高端 GPU,导致预填充密集型工作负载情况下资源利用率严重不足。这导致未充分利用的加速器空耗能源,同时复杂的部署又增加了管理开销。
解耦架构通过优化硬件分配来应对这些挑战,在不同工作负载阶段可实现总基础设施成本降低15%到40%,GPU利用率提升40%到60%。能效提升有一部分是通过压缩模型和优化配置实现的,这些举措将功耗降低了 50%,部分部署方案在服务器配置方面成本削减高达 4 倍。
这在调整每个用例的计算需求中也发挥了关键作用,即使在同一组织内的不同应用程序之间也是如此,如图 3 所示:

图 3:LLM 工作负载模式
实施策略:从规划到生产
要成功实现 LLM 服务解耦,需要对基础设施、系统规划和动态工作负载管理相关的技术有一个清晰的了解。本节为旨在优化 LLM 推理效率、最大化成本节约和资源利用的组织提供一个蓝图。
架构蓝图:解耦服务管道
解耦服务架构是在物理和逻辑上将 LLM 推理的两个不同的计算阶段分离:
预填充集群:专门用于最初的上下文处理。通常使用做过计算优化的高性能 GPU,如 NVIDIA H100,它们擅长张量操作和批量处理大型提示,可以实现吞吐量最大化。
解码集群:通过迭代生成令牌。这个阶段是内存密集型的,通常使用具有高内存带宽和低延迟缓存访问的 GPU(如 NVIDIA A100),或者是新兴的具有先进内存层次结构的加速器。
专用硬件集群通过低延迟、高带宽网络(如 InfiniBand、NVLink)相互连接,在预填充和解码阶段之间高效地传递键/值缓存数据。中央工作负载编排器或 GPU 感知调度器(如具有自定义调度逻辑的 Kubernetes 或 Ray)根据大小、类型和延迟要求动态路由请求。
实施的技术步骤
1、工作负载分析
首先严格分析现有的 LLM 部署,以区分预填充和解码密集型应用。摘要和文档处理工作负载往往是预填充为主的,而对话代理和代理系统则主要是解码密集型、内存密集型操作。
2、资源分割与映射
将计算密集型任务(大上下文、批量生成)分配给具有最大 FLOP 和高效批处理支持的集群。
将逐个生成令牌的内存密集型工作负载分配给在带宽、缓存局部性和低延迟响应方面做过优化的集群(通常有更多节点,实现了分布式并行解码)。
3、框架选择
vLLM:提供广泛的模型支持,非常适合通用部署,支持连续批量处理和 PagedAttention 缓存管理。
SGLang:通过 RadicAttention 提供高吞吐量服务,非常适合结构化生成和多模态工作负载。
TensorRT-LLM:适用于大型企业,提供强大的集成能力、供应商支持和对底层 GPU 资源利用率的精细控制。
4、部署策略
并行部署:同时运行传统架构和解耦架构。使用负载均衡器将选定的流量导向新设置,以便进行 A/B 测试、基准测试和阶段性生产迁移。
逐步迁移:从非关键工作流程开始,验证关键指标(延迟、吞吐量、GPU 利用率),然后在可靠性得到充分验证后再逐步过渡到关键任务应用程序。
5、状态管理和可扩展性
使用分布式缓存系统(如 Redis、Memcached)在集群之间同步上下文和令牌状态。尽可能采用无状态微服务,简化故障转移、自动扩展、组件重启等操作。
真实世界的 GPU 使用模式
1、Splitwise(微软研究院)
这篇论文使用生产追踪对 NVIDIA A100 和 H100 GPU 的特征进行了广泛描述。Splitwise 将吞吐量提升了 1.4 倍,同时成本降低了 20%,而在成本和功耗预算相同的情况下,吞吐量增加了 2.35 倍。
硬件结果:
在微软 Azure 的 DGX-A100 和 DGX-H100 虚拟机(有 InfiniBand 连接)上实现
在令牌阶段,A100 相较于 H100 可实现更高的成本效益和能效
A100 和 H100 设置的 KV 缓存传输延迟分别约为 8ms 和 5ms
2、SGLang与 DeepSeek 实现
一个在 Atlas Cloud 上运行的真实的大规模部署,包含 12 个节点,每个节点配备 8 个 H100 GPU,对于 2000-token 输入序列,可实现每秒 52.3k 个输入令牌和每秒 22.3k 个输出令牌的处理能力。
硬件性能:这是第一个在规模比较大的情况下几乎可以与 DeepSeek 官方博客报告的吞吐量相媲美的开源实现,与官方 DeepSeek Chat API 相比,其成本为每 1M 输出令牌 0.20 美元。优化策略使输出吞吐量较基础向量并行方案提高了高达 5 倍。
3、DistServe(OSDI 2024)
这篇论文提出了“DistServe”,它将预填充和解码计算拆分到了不同的 GPU 上。该系统的性能有显著的提升:与当前最先进的系统相比,它可以处理 7.4 倍的请求量,或者是在 90%以上的请求满足延迟约束的情况下,实现更严格的服务水平目标(SLO)——提升 12.6 倍。
硬件实现:该系统的评估是在 A100-80GB GPU 上进行的,使用了合成工作负载,输入长度为 512,输出长度为 64。这篇论文表明,借助 NVLink 和 PCIe 5.0 等高速网络,通过合理布局可以降低 KV 缓存传输开销,使其低于解码步骤所需的时间。
生产环境最佳实践
实现可靠的监控:跟踪集群层面的 GPU 利用率、功耗、并发性、令牌延迟和缓存命中率/未命中率,以便可以动态地扩展集群。
保证组件隔离和冗余:解耦后的微服务减少了整个系统发生故障的风险,并且组件可以快速重启或水平扩展。
保证组件间通道安全:在网络传输过程中,使用服务网格框架和集群间端到端加密来保护敏感用户数据和模型数据。
分布式架构中的安全性和可靠性
因为攻击面增加和网络通信需求,解耦架构引入了一些新的安全考量,但也通过组件隔离和改进故障检测带来了好处。组织必须为组件间通信提供端到端加密,使用服务网格架构实现安全的服务间通信,并建立全面的访问控制。
组件隔离提高了可靠性,减少了级联故障风险,并且可以利用组件级的重启能力实现更快的恢复。高可用性策略涵盖预填充集群与解码集群的冗余部署、健康组件间的负载均衡,以及用于防止级联故障的断路器机制。状态管理需采用具备一致性保障的分布式缓存策略,并尽可能地采用无状态架构以简化恢复流程。
未来展望:硬件和软件的演变
硬件领域正朝着针对分离工作负载进行优化的专用芯片的方向发展。它们通过内存与计算的协同设计提升效率,并采用专用的互连技术实现分布式推理。基于小芯片的设计将实现灵活的资源分配,而近内存计算则能减少数据移动开销。
软件框架继续发展,支持视觉-语言应用的多模态模型、特定于模型的解耦策略,以及基于实时工作负载分析的动态资源分配。行业标准化工作主要聚焦为解耦服务框架构建通用 API,制定标准化指标与基准测试方法,以及优化适用于解耦部署的可移植模型格式。
生态系统开发包括供应商中立的编排平台、集成开发和部署工具,以及社区驱动的优化库(可加速各种规模的组织采用)。
小结
解耦服务意味着 LLM 基础设施设计的根本转变,通过分别优化预填充阶段和解码阶段来解决单体架构固有的低效问题。事实证明,这可以在性能、成本和运营指标方面带来好处。该技术已从学术研究阶段发展成熟,被各大机构采用并投入生产级应用。
随着硬件和软件继续向着支持解耦工作负载的方向发展,这种方法将成为大规模 LLM 部署的标准,使组织能够比以往任何时候都更高效、更经济地提供 AI 服务。
原文链接:
https://www.infoq.com/articles/llms-evolution-ai-infrastructure/




