

一、前言
伴随着 AIGC 浪潮的涌起,Embedding 技术作为助推 AIGC 的关键因素逐渐为更多人所熟知。随着该技术的应用日益广泛,使用 Embedding 的人群也与日俱增。关于 Embedding 的最早提法可追溯至 2012 年 Google 的 Word2vec 论文。时至今日,Embedding 经历了超过十年的发展历程,从最初的 Word Embedding,发展到 Sentence/Paragraph Embedding,并扩展至结构化数据、图像处理、语音识别以及多模态等多个方向,以至于有“万物皆可 Embedding”的说法。模型的训练框架也由最初的浅层网络逐步发展为以 Transformer 为核心的深度学习网络。
数据科学应用中心很早便开始广泛使用 Embedding 技术,在众多项目中都可见其身影。本文将首先介绍数科 Embedding 技术的应用案例,展示了如何通过将 Embedding 技术与其他算法相融合,以提升排序效果。紧接着,详细介绍了模型效果的评价方法。最后,展示了与 OpenAI 的 Embedding 模型、开源 Embedding 模型 S-Bert 的效果对比。在众安 FAQ 数据集和中文通用 FAQ 数据集上,众安 Embedding 模型各项指标都处于领先位置。
二、案例介绍
Embedding 技术可以用来进行相似度计算,如:文本、图像、语音等的相似度。因此,它在搜索业务中得到广泛应用,可以直接用于搜索,也可以作为整个搜索链路中的一部分。同时,还可以作为特征用于提升推荐、聚类、分类排序等各类算法的应用效果。
2.1 概述
目前,Embedding 被应用到智能客服、金融风控、企微赋能等多个项目中,为业务突破提供助力。
在智能客服场景中,FAQ 检索是非常重要的模块。用户的问题会被拿到知识库中检索,找到与之匹配的标准问题,然后将标准问题对应的答案返回给用户。在知识库检索中,我们用到了基于向量的检索(Embedding Based Retrieval, EBR),用户问题 Embedding 后,通过 EBR 召回部分问题。EBR 作为召回层的其中一路(图 1),用于提升整个流程的召回准确率。在客服 FAQ 数据集上,Top1 标准问题召回率 97.6%, Top5 标准问题召回率 99.7%。
在金融风控场景中,团伙报案连续性强、数量多、危害大,业务日均审批单流量非常大,人工方式从海量的历史图片中挖掘出数百张相似图片,难度非常大。数科算法部图像组应用基于向量的检索方法后,线上相似场景识别率接近 100%,在仅有 CPU 资源的条件下,实现了数百毫秒的服务耗时。
在企微赋能场景中,坐席通常需要同时服务非常多的用户,选出高意向度用户精准服务就非常的关键。通过 Embedding + Attention (注意力机制),用户的属性信息及多个时间段会话文本被精准的融合在一起计算用户的投保意向度。相关模型上线后,7 日内转化率提升 80%, 人均保费提升 10%。
2.2 案例详解
我们挑选了 FAQ 检索的案例给大家做更为详细的介绍,描述如何将 Embedding 技术与其他算法结合提升 FAQ 的排序效果。但在这之前,需要先明确算法里面速度和准确率的权衡和基于向量的检索相关知识,这对不熟悉的同学理解我们的架构非常重要。

图 1. FAQ 检索算法架构
2.2.1 速度和准确性的权衡
机器学习算法领域,在其他条件一致的情况下,准确性高的模型通常计算复杂度也会更高。很多时候,因为生产环境的硬件水平限制(无 GPU 或者应用在边缘设备上),通常会选择准确性略低但速度满足应用场景的模型。一般在谈论算法准确性的时候,需要考虑到计算复杂度。(注:前提是同一测试数据集,同一模型在不同数据集上表现差异很大,主要原因就是不同数据集数据分布和难度不同,脱离数据集谈准确性毫无意义)
比如,在实时语音通话过程中用户的意图计算,需要先将语音通过 ASR 算法转化为文本,再通过意图识别模型完成预测,整个流程需要在非常短的时间内完成。应用大模型确实可以将模型准确率推高一点(如:准确率 Accuracy-93.6% vs 95.3%),提高得很少,但是秒级以上的推理时间会严重影响用户体验,而数科算法团队研发的模型在 CPU 环境中仅需几十毫秒、几毫秒甚至更少的时间,就可以取得 93.6% 的准确率。
特别说明,这里的大模型并非 ChatGPT 这样的大语言模型,在意图识别场景,ChatGPT 模型要做意图识别,通常的做法是给出意图定义及示范例,通过上下文学习(In-Context Learning)的方式进行预测,这种方法不仅准确率相对参数量少很多的监督学习的模型低(相关评价指标 Accuracy、F-score),而且推理速度也要慢很多。如果对大语言模型参数设置不熟悉,使用默认的参数配制,还容易出现多次预测结果不一致的情况。
下面要介绍的 FAQ 检索中,直接将复杂度更高精排模型应用于用户问题和所有知识库问题相似度计算中会提升 FAQ 匹配的相关指标,但是需要大量的计算资源和高企的推理时间为代价,尤其在 QPS 大的时候。因此,通常的做法就是召回+排序的策略, 召回层通过快速的相似度计算方法,召回有限数量的样本, 然后用精度高排序算法排序,通常各个网站和应用的搜索引擎也遵循这样的策略。
2.2.2 基于向量的检索 EBR
基于向量的检索 EBR 其实就是通过算法模型 Encoder 将 Query 转化成向量,然后计算 Query 向量与知识库中预先计算好的文本、图片等对应向量之间的距离。最后,根据距离排序,检索出相应的结果。距离计算可以是余弦相似度,向量内积、欧几里得距离等,具体选择哪一种距离取决于模型 Encoder 的训练策略。
需要注意的是,在计算 Query 向量和知识库向量距离的时候,如果知识库内容数量特别大,推荐选择近似近邻(Approximate Nearest Neighbor, ANN)方法而不是 K 近邻(K-Nearest Neighbor, KNN),其主要原因也是速度和准确率的权衡,KNN 的计算量过大。并且通过调整 ANN 方法特定参数可以使得相关指标非常接近 KNN, 比如其中的 HNSW 算法,可以通过调整 nlist、nprobe 等参数来提升检索的准确率。
2.2.3 FAQ 检索
图 1 展示了 FAQ 检索的架构图,基于向量的检索 EBR 是被用作召回层的一路来提升整体的召回效果(评价指标 recall@k,后面我们会详细讲解该指标),因为仅用 Embedding 并不能满足 FAQ 排序指标的要求。具体算法流程如下:
1.用户问题理解
主要包括:问题 Embedding、意图识别、问题纠错和关键词识别等。其中 Embedding 模型是针对众安 FAQ 检索场景开发的专有模型,具有非常好的召回和排序效果。
2. 知识库问题召回
算法模型一般具有偏向性,多路召回有助于提升召回样本的多样性,改进最终的排序效果,该案例采用了两路召回的策略:
向量检索 EBR:使用了 FAISS 工具,同时预先将知识库 FAQ 转化成向量。在调用时,根据当前用户 Embedding 与知识库向量之间的欧几里得距离进行排序。本案例会根据不同的知识库问题数量采用不同的检索策略。当知识库问题数量很大时,用 HNSW 算法进行近邻检索,相对于其他的 ANN 方法,该算法在保障召回率的同时,计算速度上有一定优势,通常的向量检索工具中都有该算法。当知识库数据量较小时,则会采用 KNN。
关键词加权的召回:ElasticSearch 基于词的检索使用的是 tf-idf、BM25 等算法,这些算法在关键词的权重的计算方面并不准确,依赖知识库中的数据分布。因此,本案例采用 DeepCT+BM25 的方法,用 DeepCT 算法来精确计算词的权重,然后根据权重调整 BM25 中 query 的输入形式,提升了召回率。简单来说,就是利用 DeepCT 算法提升了 ElasticSearch 的搜索效果。
3. 排序
如果直接对召回的知识库问题进行精排,计算量会非常大,因此采用粗排+精排的策略:
粗排:采用相对召回层略复杂准确率更高的 Poly-Bert 算法,从召回的结果中选出 Top20 的知识库问题。
精排:计算文本相似度方面,Google 在相关论文中从理论上证明了相对于 Embedding 距离计算方法,交互式文本相似度计算具有更高的准确性,当然也具有更高的算法复杂度。不同于 Embedding 方法,在分别计算两个问题的向量后再通过两个向量的距离比较相似度,交互式相似度计算从算法模型最底层就开始层层相互比较,因此选择了基于文本对交互计算的模型 Keywords-Bert。这个模型不仅从 transformer 框架的最底层开始交互比较,而且还在最后一层还加入了两个问题关键词之间的比较,通过各种细节的比较提升相似度计算的准确性。最终,该算法挑出 Top5 问题。
4. 策略层
这一层主要是通过规则及语言模型(Language Model,LM)来判断用户问题和答案之间的关联性,从而选出最合适的答案来回答用户问题。
在 FAQ 检索中,Embedding 被用作召回功能,通过快速的 Embedding 模型召回及排序模型的精准选择,实现速度和精度的平衡。虽然在这里 Embedding 模型只负责召回,但是召回 k 个知识库问题中包含的相关问题数量同样影响到最终的排序效果。如果 Embedding 模型召回精度不高,那么为了保障最终的排序效果就需要增加 k 的数量,这会带来后续计算耗时的提升,因此需要训练高质量的 Embedding 模型来保证召回效果。
三、Embedding 模型检索效果
Embedding 模型的效果如何,不同的场景有不同的指标,相同的模型在不同的场景也会有不同的表现。由于目前更多的是用在检索场景,因此这里仅分析模型在检索场景下的表现。
3.1 评估指标
在比较 Embedding 模型的效果之前,需要先了解检索效果的评估方法,检索效果评估主要指标有:召回率(Recall) 、精确度(Precision)、MAP(Mean Average Precision)、MRR(Mean Reciprocal Rank) 、nDCG(Normalized Discounted Cumulative Gain)等,这里主要讲 Recall 和 MRR 这两个指标。
召回率(Recall) 是基于向量的检索模型召回效果的常用评估指标,它表示在检索到 top-k 问题中相关问题的数量与所有相关问题数量的比值。
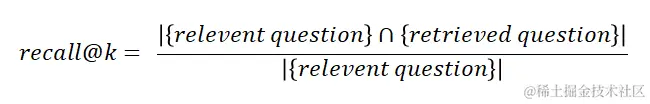
其中,k 表示召回问题的数量,k 越大对应的召回率越高,当 k 等于知识库问题量的时候,recall 必然等于 100%。因此,只有在 k 值有限且相同的情况下,recall 比较才有意义,k 越小 recall@k 值越高模型效果越好。
表 1. Recall 计算示例

表 1 中,检索显示 top3 的结果,因此 k=3,可以计算得出该测试集 recall@3 = (1/2 + 1/1) / 2 = 3/4 = 0.75
然而 recall@k 这个指标中并没有考虑排序因素,比如: 表 1 中“枸杞,菊花,红枣一起泡茶喝有什么好处”,无论其排在第 1 还是第 3 都不会影响其 recall@k 的值,而排第 1 的排序效果明显要好于排第 3 的,所以在一些关注 top-k 顺序的场景,recall@k 就不适用了。
MRR(Mean Reciprocal Rank) 就是考虑了 top-k 顺序的指标,RR(Reciprocal Rank)是请求 Q 检索响应的前 k 个结果中第一个正确响应的排序位置的倒数,如果第一个正确相应排序位置是 1,那么 RR=1/1; 如果排序位置是 2,则 RR=1/2; 如果是 3,则 RR=1/3,以此类推。如果前 k 个结果中没有正确相应,则 RR=0,排名越靠前 RR 就越大。MRR 是所有请求测试样本的 RR 平均值。

表 2. MRR 计算示例

在表 2 中,检索显示 top 3 的结果,因此 k=3,可以计算出 MRR@3 = (1/2 + 1/3)/2 = 5/12 ≈ 0.417
3.2 模型效果
这里主要展示了数科自研 Embedding 模型(众安 Embedding)、OpenAI Embedding 模型和 SentenceBert(S-Bert) 中文 Embedding 模型在众安及通用中文 FAQ 上的效果比较(表 3), 三个模型的详情如下:
众安 Embedding 模型 - 参数量: 0.2 亿,输出向量长度: 128/256
OpenAI Embedding 模型 – 参数量: 6 亿,输出向量长度: 1536
SentenceBert 中文模型 - 参数量:4.8 亿, 输出向量长度:768
在这三个模型中 OpenAI Embedding 的参数量和输出向量长度最大的,其次是 SentenceBert, 众安 Embedding 模型最小。因此,众安 Embedding 模型在将 query 转化成向量时是最快的,同时由于输出向量长度仅 128 或 256,在应用 ANN 或者 KNN 方法进行检索时的耗时也最短。
表 3. 测试数据集
表 4. Embedding 模型 Recall 指标比较

注:1-recall@k 的 1 表示所有的相关问题数量是 1
表 5. Embedding 模型 MRR 指标比较

注:当 k=1 的时候,因为不存在排序问题,1-Recall@1 和 MRR@1 相等
表 4 和表 5 展示了三个模型的召回排序性能比较结果。在众安 FAQ 数据集上,众安 Embedding 模型不论是 Recall 还是 MRR 指标均明显优其他两个模型,其中 1-Recall@1 为 0.976 比 OpenAI 的 0.828 高 0.148,MRR@10 为 0.983 比 OpenAI 的 0.887 高 0.096,无论是召回能力还是排序性都有很大优势。这表明特定领域的专有模型表现要明显好于通用模型,即使专有模型的参数量要小很多。而在中文通用 FAQ 数据集上,众安 Embedding 模型依然表现最好,但优势已没有那么大。一方面因为 OpenAI 和 S-Bert 在中文通用 FAQ 数据集上表现都不错,1-Recall@1 达到 0.92+,可提升空间相对较小;另外一方面是众安 Embedding 模型参数量仅 0.2 亿,远小于其他两个模型,如果采用差不多参数量的模型,其效果还会有所提升。
四、总结
本文展示了 Embedding 应用的案例、模型评估方法及众安 Embedding 模型的效果。Embedding 既可以直接用来检索,也可以与其他的模型相结合做出更高精度的模型。在实践中应用高质量的 Embedding 是一项复杂且具有挑战的工作,涉及到数据、深度学习建模、生产系统构建、端到端优化等多方面,每个方面都有大量细致性的工作,我们会持续提升 Embedding 系统,为业务加增量提供助力。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论