

1 背景介绍
AntMonitor:蚂蚁集团研发的一款面向云原生时代的全功能智能运维产品,包含业务监控、应用监控、基础设施监控、云原生可观测、一站式多维分析等功能。其中,智能化的单指标异常检测是该产品最基础、最重要的组成部分。
针对时序异常检测,目前蚂蚁集团内部基本都在按照以下几个思路进行研发:
通过时序预测的方法,典型算法为 ARIMA、LSTM 等,将历史数据训练的模型预测当前时刻的幅值,通过与真实值的差异来判断此刻的异常程度。在多次尝试此类模型后发现,其不但算法复杂度较高,还存有隐藏风险,此类模型训练遵循的是全局最优化策略,因此在预测当前值时无法保证当前值是单点最优(运气不好的情况下,当前点预测值误差较大)。一种解决的思路是结合其他算法进行集成学习,将误差概率尽可能的降低;
采用深度学习的方法,通过大量采集正负样本,采用一维 CNN、甚至二维 CNN (将时序数据视为图像)的方法训练模型。在尝试该类方法后发现,虽然其能够解决一些无法用规则描述的异常场景,但要搭建一个合适的针对时序数据的网络模型难度较大,此外在当前异常标准没有完全统一的情况下,模型移植性存在着很大的问题,当不同的 SRE 对业务容忍阈值不一致时,意味着要针对性地重新训练模型,这个工作量是十分巨大的;
通过集成学习的方法,有项目组是将多个弱分类赋予权重后投票来解决异常识别问题,当前的效果是在部分场景中可以达到很高的准招率。但与传统 Ensemble Learning 不同的是,其各个弱分类器的权重调整并不是一个自优化过程,而是需要通过人工调整获得,这在检测指标数量不大的时候可以采用,但是针对 AntMonitor 动辄几十万个目标指标的场景就无解了;
通过统计规则与机器学习相结合的方法,需要尽可能地将异常场景进行分类剥离(或者对数据进行分类,即算法路由),再针对各个场景进行求解。其中机器学习或深度学习可以用于描述一些难于公式化的场景,如描述波形相似。此类方法还可以将模型内部的各个参数进行透传,可以兼顾计算效率和模型移植性;
上述几种思路无所谓优劣,不同的方法都有其优势及不足,都有其契合及尴尬的场景,合适的方法才是最好的方法。针对 AntMonitor 实际面对的运维场景,统计规则和机器学习相结合的方法被选为最终解决方案。本文将分享研发 AntMonitor 智能检测算法时的一些想法和思路,欢迎各位交流学习。
2 异常分类
在做智能异常检测的过程中,其中最棘手的问题是获得一个明确的异常判断标准。比较遗憾的是,针对不同的业务、不同的指标甚至不同的使用方都会有不同的判断标准。因此,本文从另一个角度出发,先挖掘认可度高的基础异常波形,再以点到面逐步地解决异常判断问题。以耗时值上升异常检测为例,下图给出了 AntMonitor 常见异常波形 A-D(各种异常波形都可认为是以下几种波形的变种或组合),根据各自不同的特性将其归纳为 3 种不同的类型,分别为冲高异常、趋势抬升异常和频率变化异常。其中 A、B 归为冲击异常,从图中可以看到其都有一个显著的幅值突变;C 归为缓变抬升异常,相较与冲击异常,其幅值抬升过程相对较为平缓;D 归为频率变化异常,主要特征为波动频率出现巨大的变化。下面分别对不同类型异常进行求解。
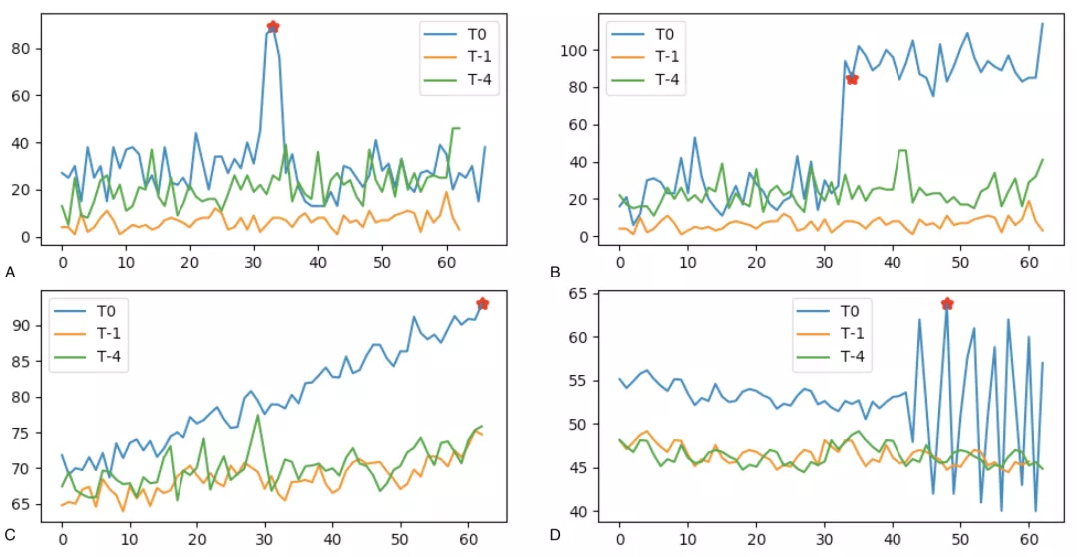
图 1 常见异常波形
3 算法整体架构
图 2 为整体算法架构,其主要由 preFilter、coreUp 和 adapter 三部分组成。preFilter 为前置过滤器,能够在较少数据输入的情况下过滤绝大部分正常信号,极大地降低资源消耗,这是算法能够大规模覆盖的基础;coreUp 为核心检测层,通过算法路由将不同类型数据映射到对应到合适的算法参数或模块,主要对冲击、趋势和频率三种异常类型进行检测;adapter 为适配层,其主要作用是能够允许不同对象创建适合自身的异常检测模型,其中可通过透出的算法进行人工配置,也可以通过样本打标来自动训练最优模型参数。下一章节主要对 coreUp 层几个核心模块的具体实现做详细介绍。
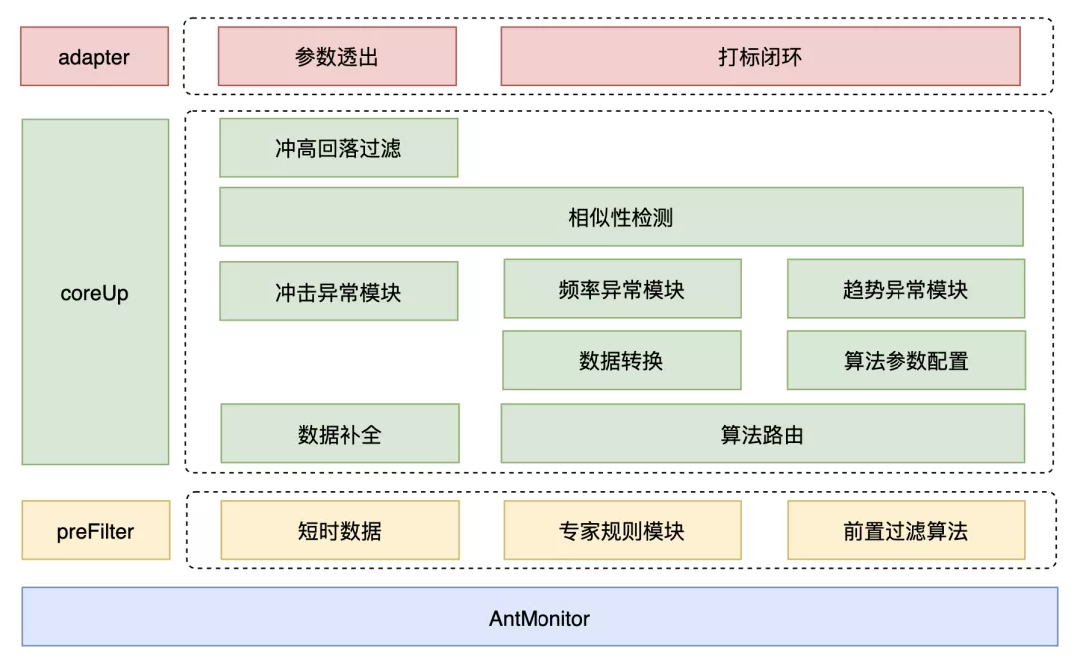
图 2 算法整体构架
4 核心模块介绍
冲击异常模块
冲击异常在波形上表现为某时刻突然出现的一个尖峰,往往是局部的幅值极大值。然而直接从幅值触发判断当前点是否异常,往往会出现漏报。如图 3 所示,由于原始波形存在着趋势项,冲击波形虽然是局部及极大值但往往不是全局视野内的最大值,因此会有被过滤的可能。观察冲击异常波形,发现其往往都是瞬时“变化”最大的时刻,其显著特征是当前值远大于前一时刻的值或持续大于前值。因此,本节从寻找瞬时波动幅值突变点的角度出发,开发基于一阶差分的异常检测算法。
当间距相等时,用下一个值减去上一个值定义为“一阶差分”。如图 3 所示,当带有趋势项的时间序列经过一次差分后可以有效地去除趋势项,同时冲击异常点也从局部极大值转变为了全局最大值。针对长度为 的时间序列 ,其对应差分序列可以表示为 , 其中 。若当天时间序列与历史事件序列分别用 和 表示,分别计算各自差分序列得到 和 , 同时获得当前时刻差值 。若 在集合 和 同时被判定为异常,则意味着当前时刻存在着冲击异常可能。考虑到存在着连续上升的情况,在实际应用中对差分计算稍作修改使其更为精确,例如当满足 时,令 。
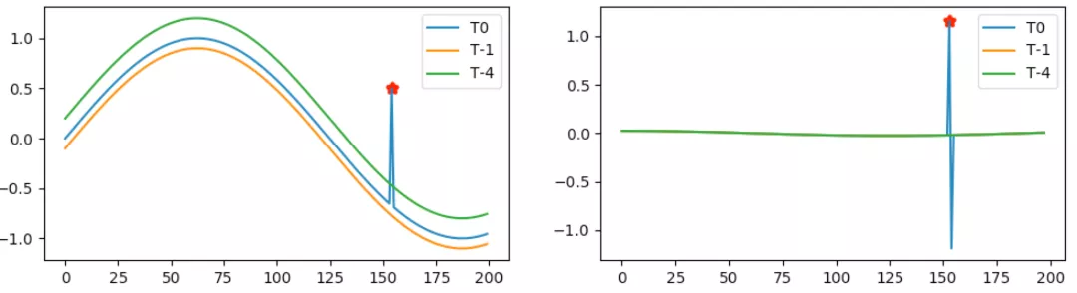
图 3 时序趋势的影响
常用的异常检测方法可参考异常检测算法综述类论文。此处采用 Tukey 箱型图作为异常检测算法。选择箱线图算法的原因主要有三点:1)计算简单;2)可适用于非正态分布数据;3)可调整判断阈值。
Tukey 箱型图
此处对 Tukey 箱型图分析做一下简单介绍。众所周知,基于正态分布的 3σ 法则或 Z 分数方法的异常检测是以假定数据服从正态分布为前提的,但实际数据往往并不严格服从正态分布。应用这种方法于非正态分布数据中判断异常值,其有效性是有限的。Tukey 箱型图是一种用于反映原始数据分布的特征常用方法,也可用于异常点识别。在识别异常点时其主要依靠实际数据,因此有其自身的优越性。箱型图的绘制方法是:
先找出一组数据的最大值、最小值、中位数和两个四分位数;
然后,连接两个四分位数画出箱子;
再将最大值和最小值与箱子相连接,中位数在箱子中间;
箱型图为我们提供了识别异常值的一个标准:异常值被定义为小于 Q1-1.5IQR 或大于 Q+1.5IQR 的值。虽然这种标准有点任意性,但它来源于经验判断,经验表明它在处理需要特别注意的数据方面表现不错。
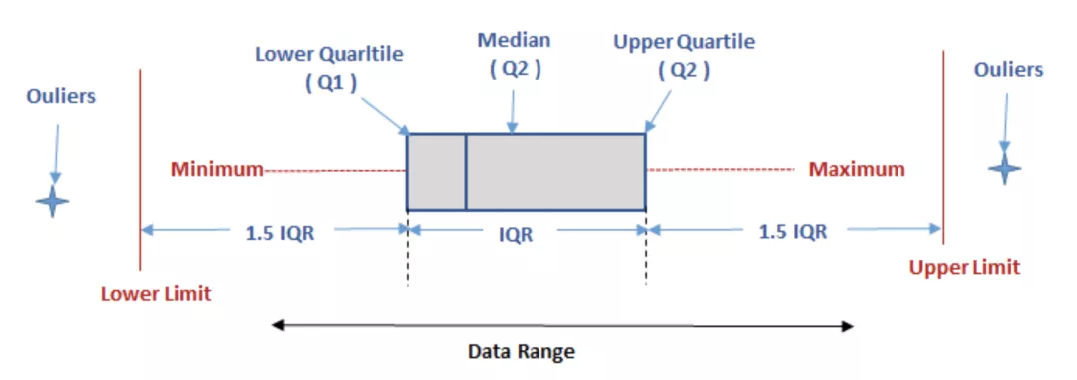
图 4 箱型图示意图
冲击检测流程
冲击异常检测的简要流程如下:
当日序列 和历史序列 ,获得差分序列 和 ,已经当前差分值 ;
采用 Turkey 箱线图获得集合 的上限,判断 是否超限,若否返回“正常”,若是进入下一步;
判断异常时刻是否超过预设异常持续时长 ,若否返回“正常”,若是进入下一步;
在 中截取以当前时刻为中心且长度为 的子集合,采用 Turkey 箱线图获得其上限,判断 是否超限,若否返回“正常”,若是进入下一步;
判断在当日前序时间序列中是否也存在冲高异常点,若不存在返回“异常”结果;若存在进入下一步;
判断 是否大于 ,若是返回“异常”结果,若否则返回“正常”结果;
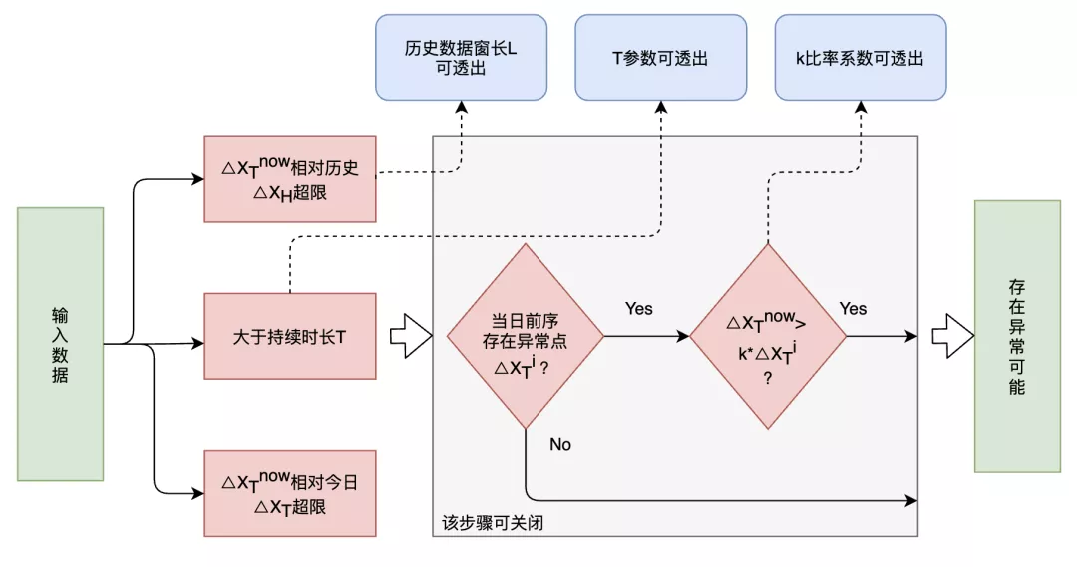
图 5 冲击检测流程
存在的问题
采用上述方法存在两个问题,第一个如下左图所示,若出现大幅度下跌回升(相当于下跌检测中的冲高回落)的情况,当前点的差分值必然会超限告警,这种误报当前通过类似“冲高回落”的方法进行过滤,本文不再具体介绍;第二种,在整体波动幅度较大的情况下,出现这种小幅缓变抬升的小凸起,采用冲击异常检测是无能为力的。针对这种异常类型,本文通过趋势异常模块来进行解决。
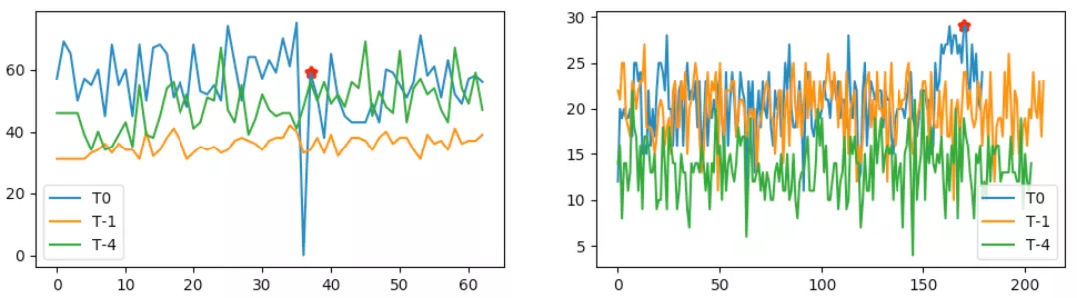
图 6 存在的漏报场景
趋势异常模块
当波形缓慢上升时,由于差值大小是基本稳态的,上述冲击异常模块是无法有效识别的。因此,必须要有方法支持此类缓慢变化异常识别。在尝试各种算法模型后,本文最终选择 AugmentedDickey–FullerTest 和 Mann-Kendall Test 相结合的方式来求解此类问题。
ADF Test
Augmented Dickey–Fuller test 又称为扩展迪基-福勒检验,其可以用来检测当前序列是否平稳。ADF 检验的原假设是存在单位根,因为存在单位根就是非平稳时间序列了,只要这个统计值是小于 1% 水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF 值一般是负的,也有正的,但是它只有小于 1% 水平下的才能认为是及其显著的拒绝原假设。
Mann-Kendall Test
Mann-Kendall 非参数秩次检验原理如下,对长度为 的时间序列 , 统计假设 :未经调整修正的数据系列 是一个由 个元素组成的独立的具有相同分布的随机变量。备择假设 是双边检测:对所有的 ,当 时和 时 和 的分布不相同。计算时,对每一个 ,与其后的 进行比较,记录 出现的次数。定义 Mann-Kendall 统计量 :
其中, 为符号函数。当 小于、等于或者大于零时, 分别为-1、0 或者 1;对于假设统计 ,当 时, 的分布为正态分布, 的均值为 ,方差为 。当 时,即可应用近似正态分布进行检验分析。
标准整体统计变量 可以用下式计算:
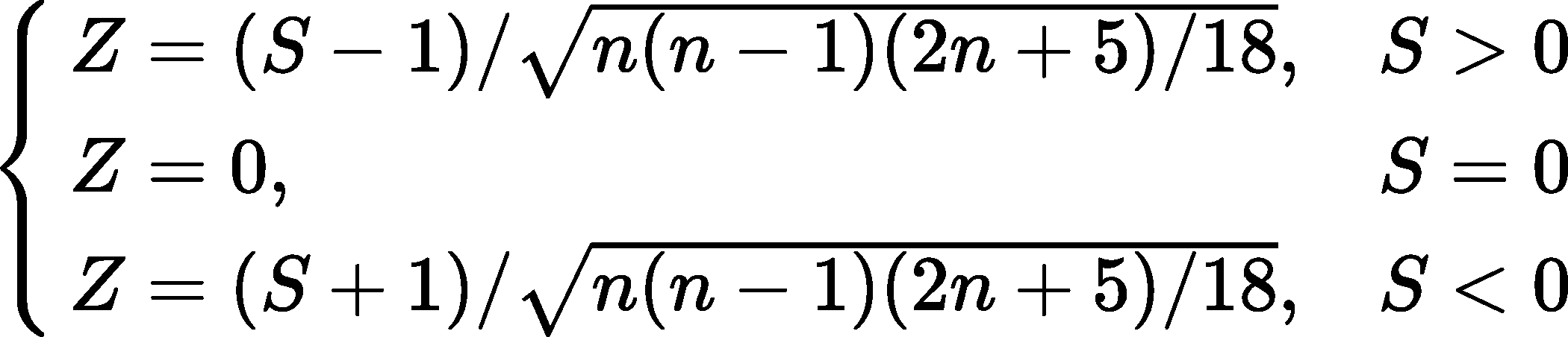
这样,在双边的趋势检验中,在给定的 置信水平上,如果 则原假设是不可接受的。 为正值表示增加趋势,负值表示减少趋势。 的绝对值在大于等于 1.28、1.64、2.32 时表示分别通过了信度为 90%、95%、99%的显著性检验。
Mann-Kendall 非参数秩次检验在数据趋势检测中极为有用,其特点表现为:
无需对数据系列进行特定的分布检验,对于极端值也可参与趋势检验;
允许系列有缺失值;
主要分析相对数量级而不是数字本身,这使得微量值或低于检测范围的值也可以参与分析;
在时间序列分析中,无需指定是否是线性趋势;
趋势检测流程
趋势检测并不是直接检测当日数据是否存在上涨趋势,理论上若历史数据与当天数据同步上涨,那么该波形趋势不应该识别为异常。换句话说,需要去除当日数据相对于历史的趋势。此处采用相对差值的方式来实现该目的。假设当日数据为 ,某天历史数据为 ,那么两者之间的差值序列可以表示为 ,在此基础上再进行趋势分析。
详细流程如下:
计算当日数据 与某历史数据 的相对差值序列 ;
采用 Mann-Kendall 检验判断 是否存在上涨趋势,若无上涨趋势返回“正常”结果,反之进入下一步;
计算趋势上涨的起始点 ,采用最小二乘法拟合上涨段波形,获得上涨绝对幅值 , 计算当日数据 中 点对应的基础值 ,计算实际上涨比率 ;
判断 是否大于设定涨幅比率阈值 ,若不大于设定阈值则返回“正常”结果,反之则进入下一步;
采用 T 检验判断前序数据是否存在类似的上涨波形,若存在则返回“正常”结果,若不存在则返回“异常”结果;
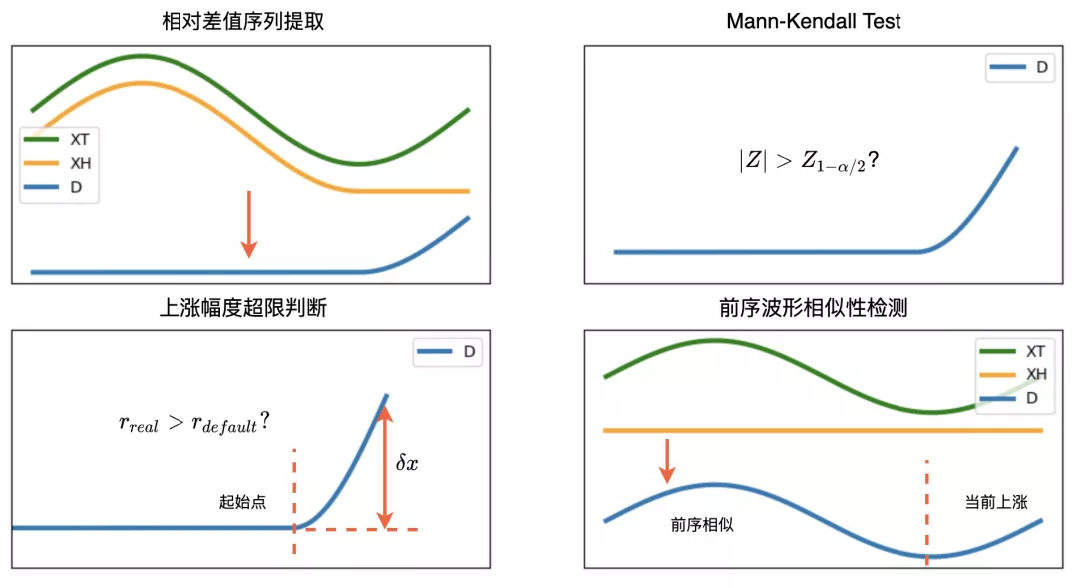
图 7 单次趋势检测流程
实际应用中流程会稍复杂一点,并且做了部分假设:1)若当天相对于昨日不存在上涨趋势,即可认为不存在缓变上涨异常;2)若当天相对于昨日存在上涨趋势,那么需考察当天相对与剩余历史是否也存在上涨趋势,此处设定若有大于 天不存在相对趋势,即认为不存在缓变趋势。考虑到算法需要获得准确的告警时间点,并用来计算精确的涨幅比率,此处对 按不同长度先后进行趋势判断。大致的判断流程如图 13 所示,此处不再展开。
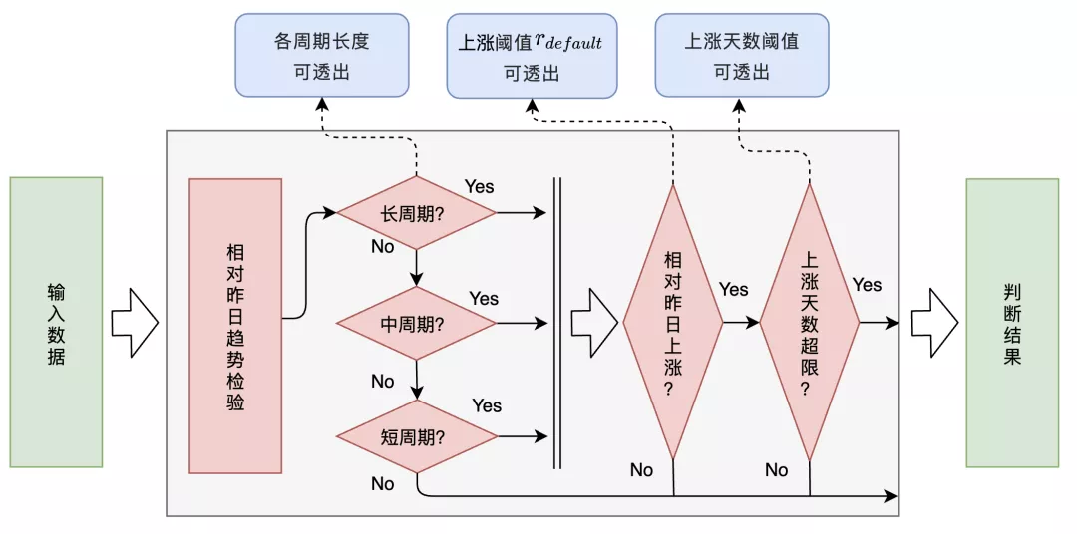
图 8 趋势上涨异常检测整体流程
频率异常模块
频率异常在实际场景中并不多见,但是作为一类异常类型,此处也对其进行了覆盖。针对频率异常数据类型,本文采用分位数聚合特征来进行求解,主要步骤如下:
DoulbeRollingAggregate
分位数定义:对一个有着连续分布函数的样本集 ,分位数是将一个概率分布切分为有着相同概率的连续区间的切分点。用数学公式表达的话: ,则称 为随机变量 的 分位数。
分位数聚合特征$$F$$计算流程如下:
长度为 的时间序列 ,分别扩展得到 的时间序列 和 ,具体为:
对时间序列 进行滑窗截取操作,窗口长度为 ,获得长度为 的子序列集合 ,其中 ;同样的,获得时间序列 对应的子序列 ;
计算 集合中各个子序列的 个分位数,用 表示子序列 的 分位数;同样的,计算 集合中各个子序列的对应的分位数,用 表示;
通过 和 获得当前时刻的分位数聚合特征,具体公式如下:
分位数聚合特征计算示意图如下所示:
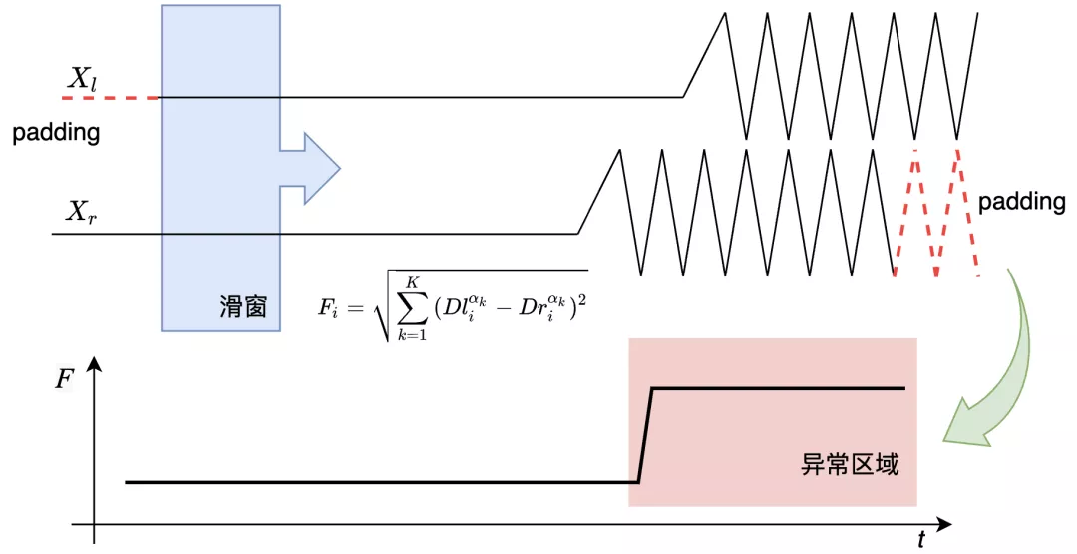
图 9 分位数聚合特征计算示意图
实际检测效果
在频率异常检测的应用中,需要对数据类型进行区分。针对稀疏类型数据直接进行“分位数聚合”算法计算,而对于存在趋势项的非稀疏数据,必须先对其进行一阶差分操作后才可以使用当前算法。图 10 给出了两者不同类型的频率异常检测模型,分别给出了“分位数聚合”特征曲线,从图中可以看到可以准确地识别此类异常波形。在实际使用中还需要根据具体场景添加一些规则限制,此处不再具体展开。
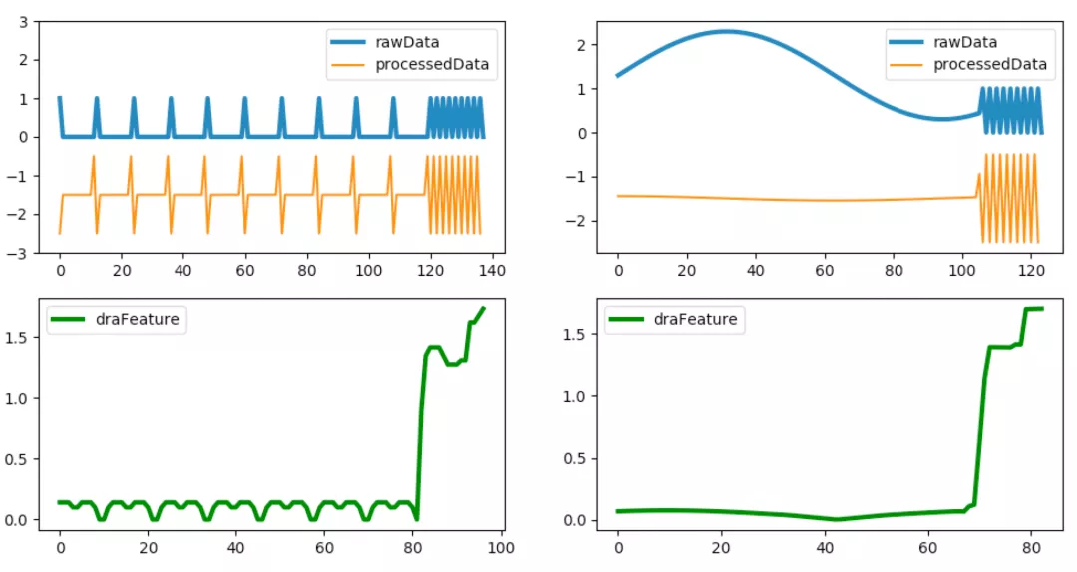
图 10 不同类型异常数据检测效果
相似性检测模块
相似性误报在时序异常检测中占有不小的比例。如下图时序在检测时刻出现异常冲高时,若不考虑历史同期波形,往往会出现相似性误报现象。实际在波形进行相似性检测时,往往需要考虑时序长短不一致和波形偏移的问题。一般来讲,时序长短不一致和波形偏移主要表现为:
如下图所示,当日波形 与历史波形的冲高部分出现一段前后偏移;
为提高实时检测的时效性,一般参考将历史参考波形相对于当前检测时刻延后几分钟;
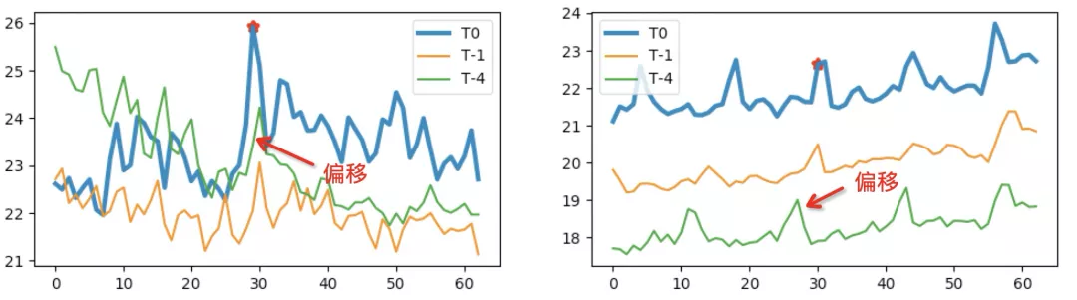
图 11 相似性误报
由于时序长短不一致和波形偏移的情况,皮尔逊相关系数、余弦相似度、欧式距离等相似性评价指标就不再适用。动态时间规整(DTW)是一种常用的模板匹配算法,其可以有效的解决对比长度不一致的时间序列相似性问题,图 12 给出了 DTW 算法与传统欧式距离评价的差异,此处不再展开描述。但实际应用中,DTW 算法更多的是一种搜索匹配算法,即其返回结果是目标库中的最优匹配对象,而在时间序列实时监测过程中,需要的是能给出一个可量化的相似度参考值做为判断依据,因此 DTW 也不能直接使用。本文给出了一种基于动态时间规整(DTW)及 T 检验的时序波形相似性评估方法,不但能够有效评估长度不同、发生偏移序列的相似度,还可以返回可量化的相似性度量值,能够应用于时间序列实时异常检测。
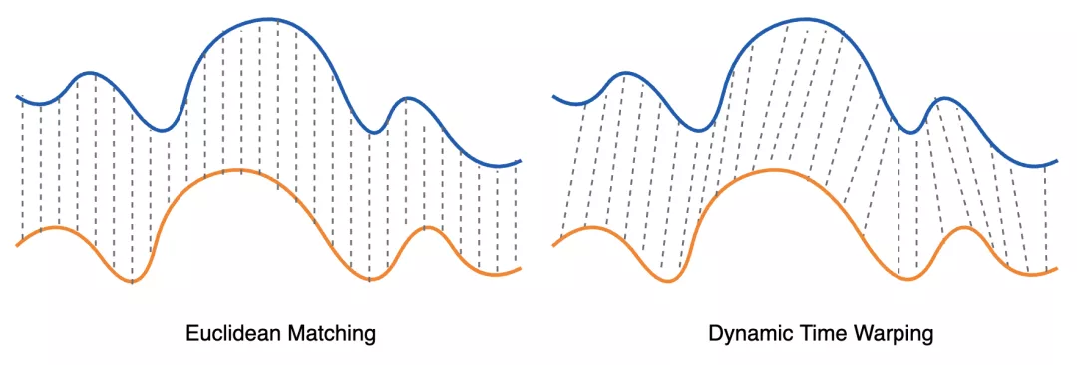
图 12 DTW 算法与欧式距离对比
相似性检测流程
截取当日数据,记时间序列为 , 表示当前时刻的实时数据;
截取历史同时刻对比数据,记为 , 为了刻画数据偏移特性,历史对比数据比当天数据往后多取 个数据点;
为消除时序常数项对 距离度量的影响,对时序做“拉平”预处理,即将各个时间序列减去其自身中位数,获得新的序列分别记为 和 ;
定义时序 到时序 的 距离定义为 ,分别计算当日 与各个历史 的 距离,获得距离集合 ,此处 和 的长度分别为 和 ;
分别计算 内两两时序的 距离,获得距离集合 ,为与上一步骤保持一致,此处 中波形 取数据前 个点, 取 个点;
采用 STest 算法判断集合 和 中的距离均值 和 是否存在显著性差异,设原假设 ,备择假设 ,检验水准 ;
计算获得 pValue,若 pValue> ,不拒绝原假设 ,表明当日波形与历史波形相似; 反之,当日波形与历史波形不相似;
实际检测效果
下图给出了“相似性检测模块”的实际检测效果,图 13 中的 4 例告警都为未配置“相似性检测”模块前的上升告警样例,采用上述算法回跑后都可以有效地识别为相似性误报。从实际使用情况来看,该模块评估为误报的案例基本都是相似的,反之存在着一定的偏差,但对于一个后置过滤模块来讲是完全可接受的。总体来讲,对较为规整的波形判断效果不错,当历史数据本身趋势不相关、波形太过杂乱,上述算法效果一般。
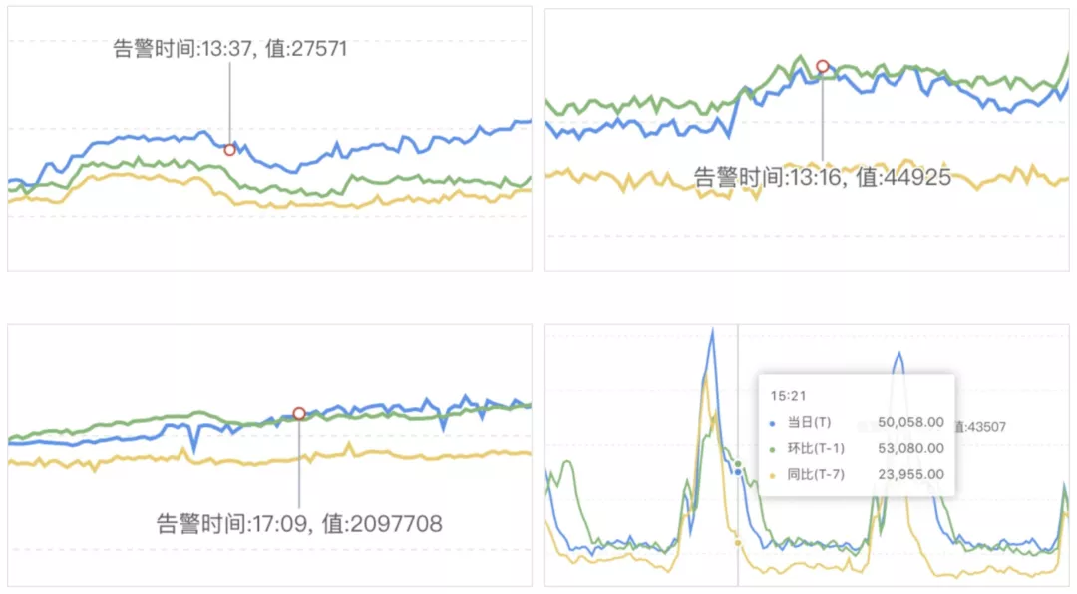
图 13 相似性检测效果
五 算法过滤场景
通过上述整体算法判断后,下图中的潜在异常场景,如单点冲高、冲高前序相似、冲高历史相似、抬升历史相似等都可以被有效过滤。在实际应用中,此类过滤项都配置有相应的开关,由业务人员来确认是否开启。
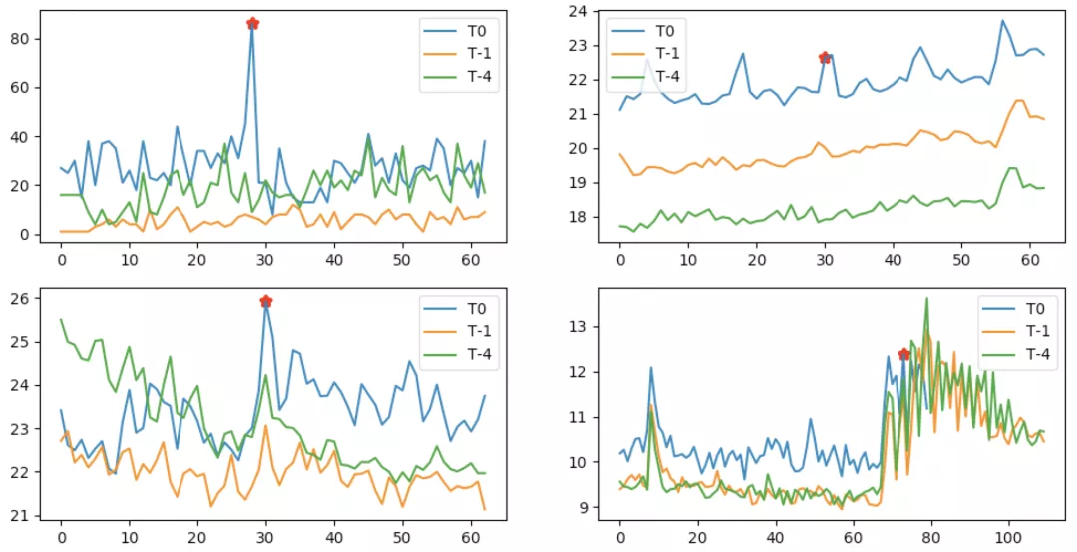
图 14 典型过滤场景
六 总结与展望
本文算法总体思路是对单指标波形异常检测问题进行拆解,将其归纳为冲高异常、趋势上涨异常和频率变化异常三个模式。在此基础上,辅以一些过滤模块来减少特定误报的产生,如利用基于 DTW 的算法来求解诸如"波形相似性"的误报场景。此外,本文中的异常判断标准相对统一,都以箱线图分析为标准,各个超参数都可以进行透传,后期针对不同的应用场景不同的阈值都可以快速调整。当前根据以上思路设计的模型主要应用在 JVM&System 指标监测上,约 5w 条 key 总体异常告警量小于 5 条/分钟。
基本上,上述算法可以覆盖绝大部分的场景,但往往会有各种意想不到的误报漏报情况出现,后期的一部分工作要重点解决此类问题;另一方面,针对一些偏明确的场景,在后期可以用机器学习或者深度学习模型来进行代替,如“波形相似性”问题,在积累足够样本量后可尝试通过深度学习模型进行覆盖。同时,也可以尝试集成算法,以往从事机器学习的项目经验表明,往往集成后会有意想不到的精度提升。
作者介绍:
徐剑,花名辂远,蚂蚁集团高级开发工程师,工学博士,长期从事智能运维、机器学习和信号处理等领域的研究及开发工作,当前为 AntMonitor 算法开发人员。
本文转载自公众号金融级分布式架构(ID:Antfin_SOFA)。
原文链接:

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论