

了解自然语言处理的同学,应该没有不知道 BERT 的;甚至连很多自然语言处理圈外的开发的同学,都知道这个模型的厉害。不得不佩服谷歌的影响力和营销水平,当然,也确实是它的效果有这么棒。
这里就不再说 BERT 当年是怎么样横扫各大 NLP 任务榜单的故事了。毕竟现在出了个 XLnet,各方面都比他强了一点点;而且,也开始有一些论文开始接 BERT 的短了。
BERT 是什么?
那我们言归正传,现在来看看 BERT 究竟是什么,有什么样的结构,如何进行预训练等。
BERT,全称是 Pre-training of Deep Bidirectional Transformers for Language Understanding。注意其中的每一个词都说明了 BERT 的一个特征。
Pre-training 说明 BERT 是一个预训练模型,通过前期的大量语料的无监督训练,为下游任务学习大量的先验的语言、句法、词义等信息。
Bidirectional 说明 BERT 采用的是双向语言模型的方式,能够更好的融合前后文的知识。
Transformers 说明 BERT 采用 Transformers 作为特征抽取器。
Deep 说明模型很深,base 版本有 12 层,large 版本有 24 层。
总的来说,BERT 是一个用 Transformers 作为特征抽取器的深度双向预训练语言理解模型。
BERT 的结构

上图是 BERT 的模型结构,它由多层的双向 Transformer 连接而成,有 12 层和 24 层两个版本。BERT 中 Transformer 的实现与上一期讲的 Transformer 实现别无二致。
要理解 BERT,最主要在于它预训练时采取的方法,下面我们做一个详细的讲解。
BERT 预训练模式
(1) Input Representation
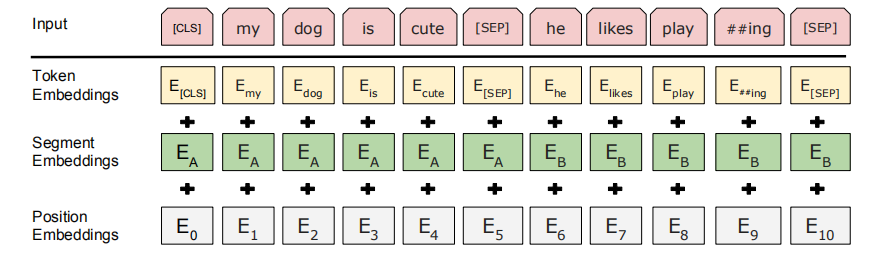
我们先看看,BERT 网络接受的输入是什么,如上图所示,BERT 接受的输入包括三个部分:
词嵌入后的 Token Embedding,每次输入总以符号[CLS]的 embedding 开始,如果是两个句子,则句之间用[SEP]隔开。
句子类别的符号
Position Embedding,这个与 Transformer 中的一致。
上述三个向量相加,组成 BERT 的输入。
(2) Masked Language Model
那么,BERT 是通过什么样的任务进行训练呢?其中一个是 Masked Language Model。BERT 会在训练时遮住训练语料中 15%的词(实际的 MASK 机制还有一些调整),用符号[MASK]代替,通过预测这部分被遮住的内容,来让网络学习通用的词义、句法和语义信息。
那么,该怎么理解 Masked Language Model 呢?我们不妨回想一下高中阶段都做过的英语完形填空,我们在做完形填空题目的时候,为了填上空格中的词,常常需要不断的看空格词的上下文,甚至要了解整个段落的信息。有时候,有些空甚至要通过一些英语常识才能得到答案。通过做完形填空,我们能够学习到英语中很多的词义、句法和语义信息。BERT 的训练过程也类似,Masked Language Model 通过预测[MASK]代替的词,不断的“对比”上下文的语义,句法和词义信息,从而学到了大量相关的知识。
哈哈,不知道 BERT 的提出者们是不是受中国英语试卷里完形填空题目的启发呢?
(3) Next Sentence Prediction
BERT 的预训练过程,还有一个预测下一句的任务。就是输入两个句子,判断第二个句子是不是第一个句子的下一句的任务。这个任务是为像 QA 和 NLI 这样需要考虑句子间关系的下游任务准备的。
通过这个任务,BERT 获得了句子级表征的能力。通常,BERT 的第一个输出,即[CLS]对应的输出,就可以用来当作输入句子的句向量来使用。
4 BERT 到底学到了什么?
(1) 在 BERT 在预训练过程中,学习到了丰富的语言学方面的信息。
短语句法的信息在低层网络结构中学习到;BERT 的中层网络就学习到了丰富的语言学特征;BERT 的高层网络则学习到了丰富的语义信息特征。
上述观点来自如下的论文,该团队用一系列的探针实验,佐证了上述的观点,对我们进一步了解 BERT 和更有效的使用 BERT 有一定的指导意义。
Ganesh Jawahar Benoˆıt Sagot Djam´e Seddah (2019). What does BERT learn about the structure of language?.
(2) BERT 其实并没有学习到深层的语义信息,只是学习到了一些浅层语义和语言概率的线索?
最近有一篇论文"Probing Neural Network Comprehension of Natural Language Arguments",讨论 BERT 在 Argument Reasoning Comprehension Task(ARCT)任务中是不是其实只是学习到了数据集中一些虚假的统计线索,并没有真正理解语言中的推理和常识。
事情大概是这样子,论文作者为了杀杀 BERT 的威风,挑了自然语言处理中比较难的任务 ARCT,并且在测试数据中做了一些“手脚”,想试一试 BERT 的身手。所谓的 ARCT,是一个推理理解的任务。如下图所示,展示了一个 ARCT 数据集中的例子。ARCT 数据中有一个结论 Claim,一个原因 Reason,一个论据 Warrant,还有一个错误论据 Alternative。

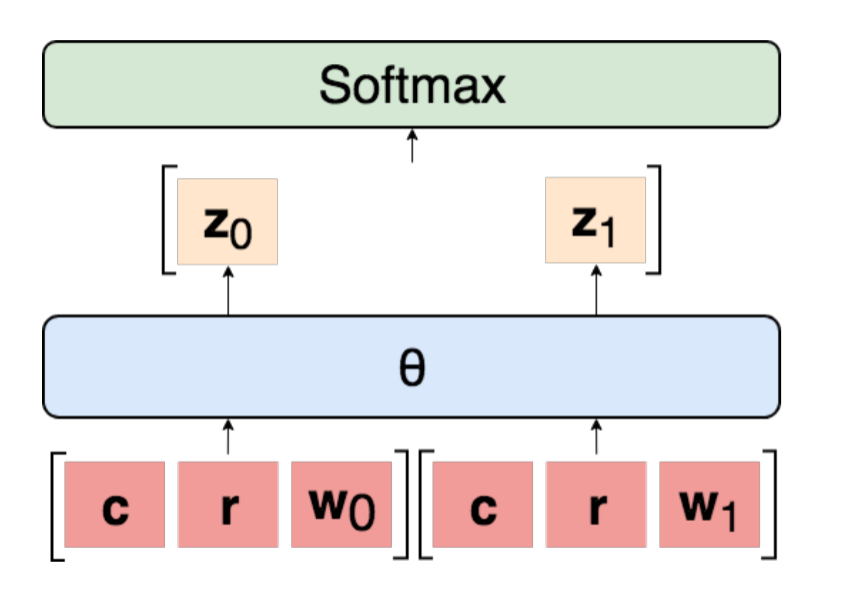
如上图所示,是 ARCT 任务的通用模型结构,就是同时输入,Claim,Reason 和两个 Warrant,预测哪个 Warrant 是正确的。
论文作者首先在 ARCT 原始数据集上用 BERT 进行 ARCT 任务的预测,发现 BERT 的效果确实很好,达到 71.6±0.04,跟没有接受过训练的人员成绩接近。
然后,研究人员研究测试数据集发现数据集里面其实隐藏了一些统计线索。简单的说就是,数据集里正确的 Warrant 里包含某些词的概率比错误的 Warrant 要高。例如,只要看到 Warrant 中包含 not 就预测其为正确的 Warrant 就能够达到 60 的正确率。
同时,研究人员还做了只把 warrant 和 claim、warrant 和 reason 作为输入来训练模型的实验。实验发现,BERT 的效果也能达到 70+。这就好像老师题目都还没有说完,学生就把答案写出来,这显然不太合理的,要么是学生作弊,要么是学生提前把答案背下来了。
最后,研究人员来了一招狠的,就是将数据集中的数据进行反转和一些词概率上的平均处理,如下所示:

实验结果令人惊讶,BERT 最好的效果只有 53%,只比瞎猜好一点点。
所以,BERT 的预训练过程到底学到了什么呢?
要准确回答这个问题并不容易。但通过上述两篇论文在两个维度上对 BERT 的解析,我们心里应该能够给 BERT 一个清晰的定位。BERT 是一个强大的预训练,因其超大的参数量和较强的特征提取能力,能够从海量的语料中学习到一些语言学和一定程度的语义信息。但是,笔者认为,跟此前的所有 NLP 模型一样,它还远没有学习到语言中蕴含的大量的常识和推理。例如,利用 BERT 或许能够从"天下雨了",推断出“要带伞”。但是更深层次的,“要带伞是因为怕淋湿,淋湿了会感冒”这些 BERT 是很难学到的。
NLP 的难处就在于,语言是高度精炼和情境化的。一句简单的话,可能需要丰富的知识才能理解。现在来看,预训练模型是一条有希望但漫长的道路。
总结
BERT 是目前最火爆的 NLP 预训练模型,其基于 MLM 和双向语言模型和以 Transformer 作为特征抽取器,是其成功最主要的两个原因。
原文链接:
https://mp.weixin.qq.com/s/9eAJMbdep0s1I4upxGzw1Q

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论