
编者按:UCloud 最新发布了名为“Sixshot”的可用区特性,用 UCloud VP 陈晓建的话说,“可用区就好比云计算的太祖长拳,看似平平淡淡,但要打得好着实不易。”太祖长拳属于南拳流派,共有四套拳路,讲求一胆、二力、三功、四气、五巧、六变、七奸、八狠。有鉴于此,解密「云计算的太祖长拳」系列将在接下来的三篇内容里,详细介绍 UCloud 可用区项目的“一胆、二力、三功”。
本文是解密「云计算的太祖长拳」系列的第三篇(关注“细说云计算(CloudNote)”并回复“太祖长拳”可查阅该系列全部内容),我们会和大家一起探讨一下我们对网络业务的后台服务(包括管理面程序 management plane 和控制面程序 control plane)所做的重构工作。这里最重要的是如何对后端各个模块做正确的解耦从而使得我们可以做用户级别的灰度来可控地发布可用区这样一个涉及全局各个业务的特性,并且将亿万条用户数据从老的非可用区架构平滑迁移到新的可用区架构上。云计算十年,架构师的地位越来越重要说明了什么?架构设计和数据迁移方见真功夫,因此本篇选太祖长拳之“三功”为题。
这是一个看似平淡沉闷但实则步步惊心的指尖之舞——如何尽最大可能保证用户的现网业务在切换过程中不受影响是我们最高优先级的任务。诚然,在整个可用区灰度上线的过程中,我们还是遭遇了很多事先没有预料到的故障和挑战,这一程也远不是一马平川过来的。因此我们也在不断地总结和打磨我们的支撑系统和方法论,但长期以来,以下的一些基本思想一直是整个研发和运维团队所秉承的底线:
- 持续改进的能力高于一步到位的完美;
- 早于客户探知和快速回滚的能力高于万无一失的程序逻辑;
- 主动重构的团队意识高于一劳永逸的个人英雄主义。
千里之任:后台管理程序的分拆
UCloud 的 SDN 网络服务的整个后台逻辑事实上是一个由 20 多个服务组成的大型的分布式系统。这些服务负责了 SDN 业务逻辑的方方面面,其中包括(只列举了主要的):
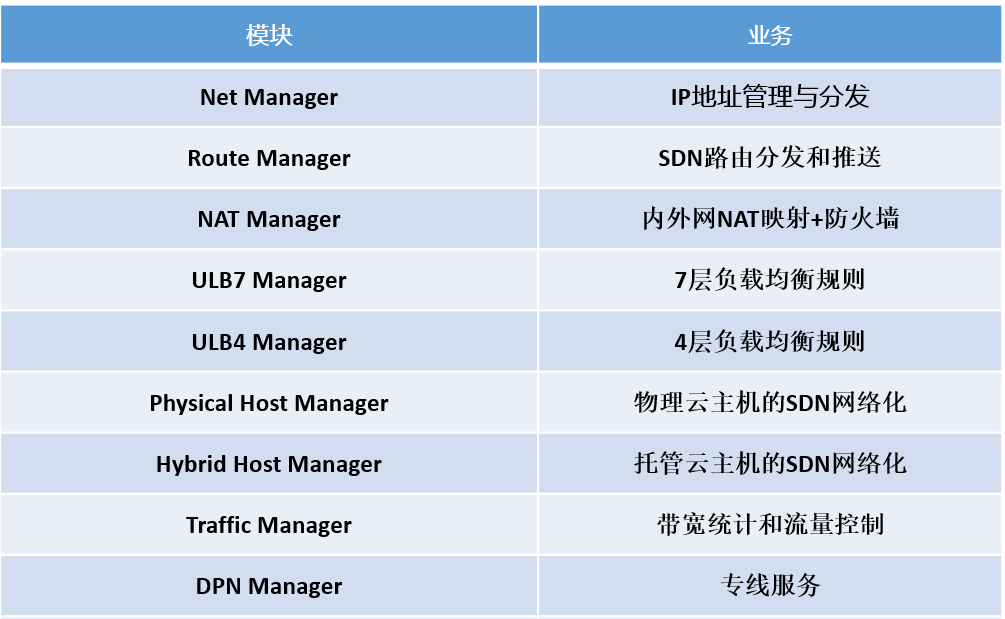
我们在可用区项目进行的过程中,遇到的第一个大型的全局性问题就是我们发现由于之前广泛遵循的模式(design pattern),所有的 manager 的前端(Frontend)和后端(Backend)的逻辑都是在一个模块里实现的(当然部署的时候也是这一个模块同时覆盖了 Frontend 和 Backend 的功能),如下图:
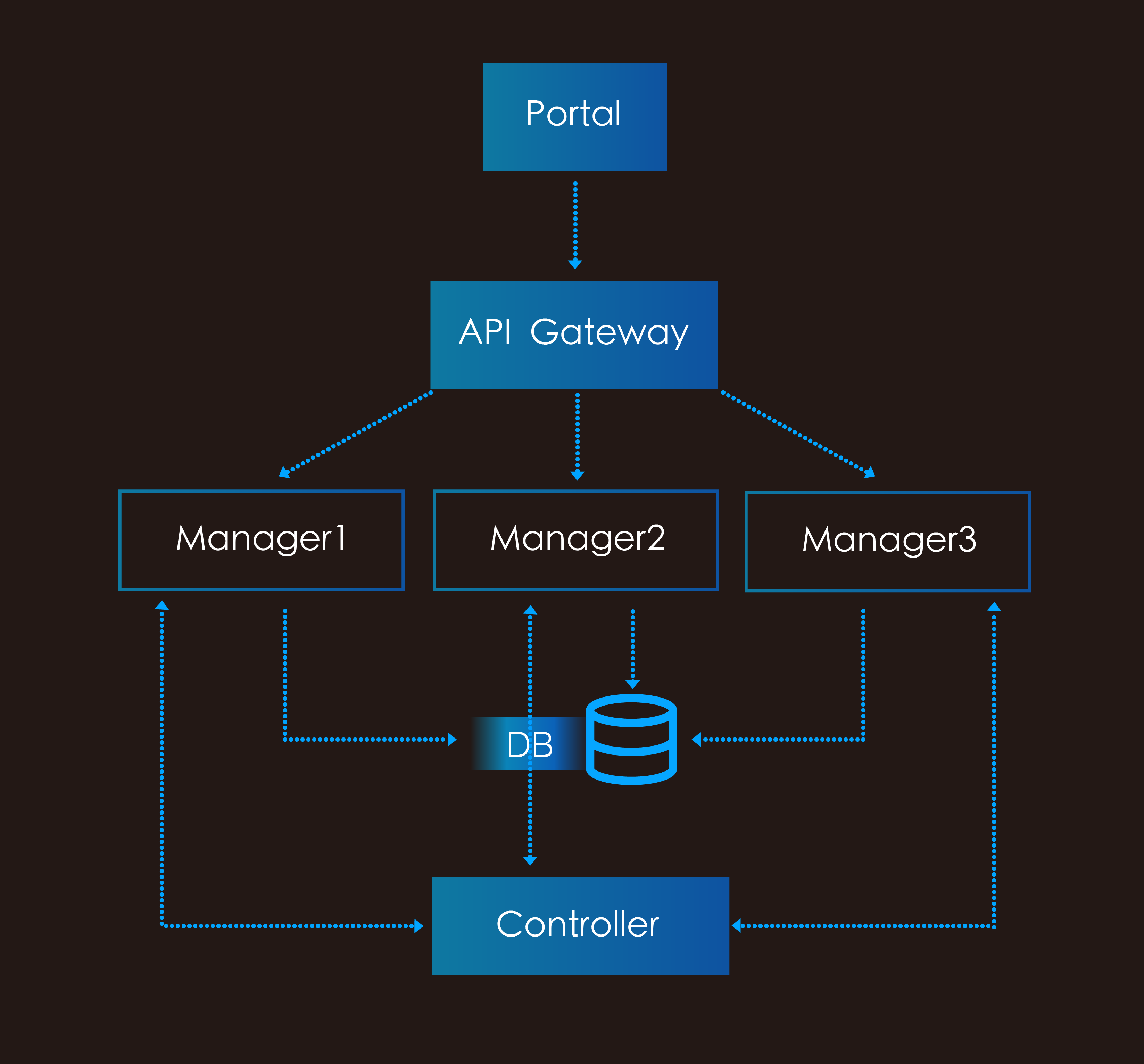
这个架构的主要问题在于服务的前后端功能是耦合的。在服务程序逻辑相对简单,升级变更还相对轻量级的情况下,这里的矛盾还不是特别突出,我们通过严密的监控、主动的运营(扩容或重启服务等)、及快速的回滚(升级验证失败的时候)等手段基本还是能控制整个系统的运行状态。但其实之前我们已经逐渐发现这个不同关键路径程序逻辑间的耦合带来的问题了:一个十分典型的事例就是曾经发生过的一个现网事故——当时有用户反馈说从某个时间开始,控制台上的一些网络服务的页面经常有间歇性超时从而无法显示数据的情况。
如上图所示,我们的官网控制台是通过 API Gateway 来调用 Manager 上的接口的,因此我们的研发工程师自然而然地去排查了所有 Frontend 的运行日志,却发现在出现 CPU 飙高的时间点,Frontend 的日志里没有显示任何异常的行为。然后我们逐个排查了整条控制台到 Manager 调用路径上所有服务(API Gateway,Access 层,包括控制台本身),都没有发现任何的问题。正当我们一筹莫展的时候,一个偶然的机会,另一位负责 Manager 中 Backend 功能的同学提到,由于 Backend 每秒收到的请求(query per second)较高,所产生的日志也通常比较大,容易占用过多的磁盘空间。因此他提交了一个优化的逻辑,会随机地将一些旧的日志打包并送到远端的一个存储空间里保存起来。而进一步分析 Backend 的运行日志后,我们发现所有控制台发生超时情况的时间点都是和 Backend 上这个日志打包逻辑的运行时间是吻合的。这个变更对 Backend 的影响姑且不论,这里最大的问题在于:一个看似旁路的后端逻辑却直接影响了直接有损用户体验的前端服务,这是十分不应该的。
笔者之前在 Amazon 工作的时候,曾经听过一次内训的讲座,是当时 Amazon 的 Global Payments 部门的高级研发经理 Thomas Vaughan 所做的”Greatest Disaster in Amazon’s History”的演讲(这个是 Amazon 内训讲座中排名前三的一个演讲,可惜由于是内部资料,非 Amazon 的员工无法听讲)。Thomas 在讲座中总结了 Amazon 历史上最有教育意义的 6 次重大现网事故并从中总结了一系列大型分布式系统开发的原则和规范,其中第二条就是:
Partition your critical use cases.
也就是说:要注意解耦关键路径上程序逻辑。很难想象这样一个简单的原则却一直在不断地被违反(我们可以指出很多的原因,客观的,主观的),但事实就是如此。
在可用区项目中,我们面临着一个相关的但更大的挑战,即:由于整个业务逻辑的复杂性,将一个用户从非可用区切换至可用区,整个操作流程需要经过许多个业务组的配合联动,若强行要求前后端的业务同时操作不发生同步上的问题,那是代价巨大且不现实的,因此我们最终的灰度方案是后端控制面和管理面的逻辑先进行切换,然后前端再将用户切换至新的可用区界面上(这样前后端的业务组不必一定要同时操作)。但如此我们必定要对 Manager 中耦合在一起的 Frontend 和 Backend 的逻辑进行拆分才行:
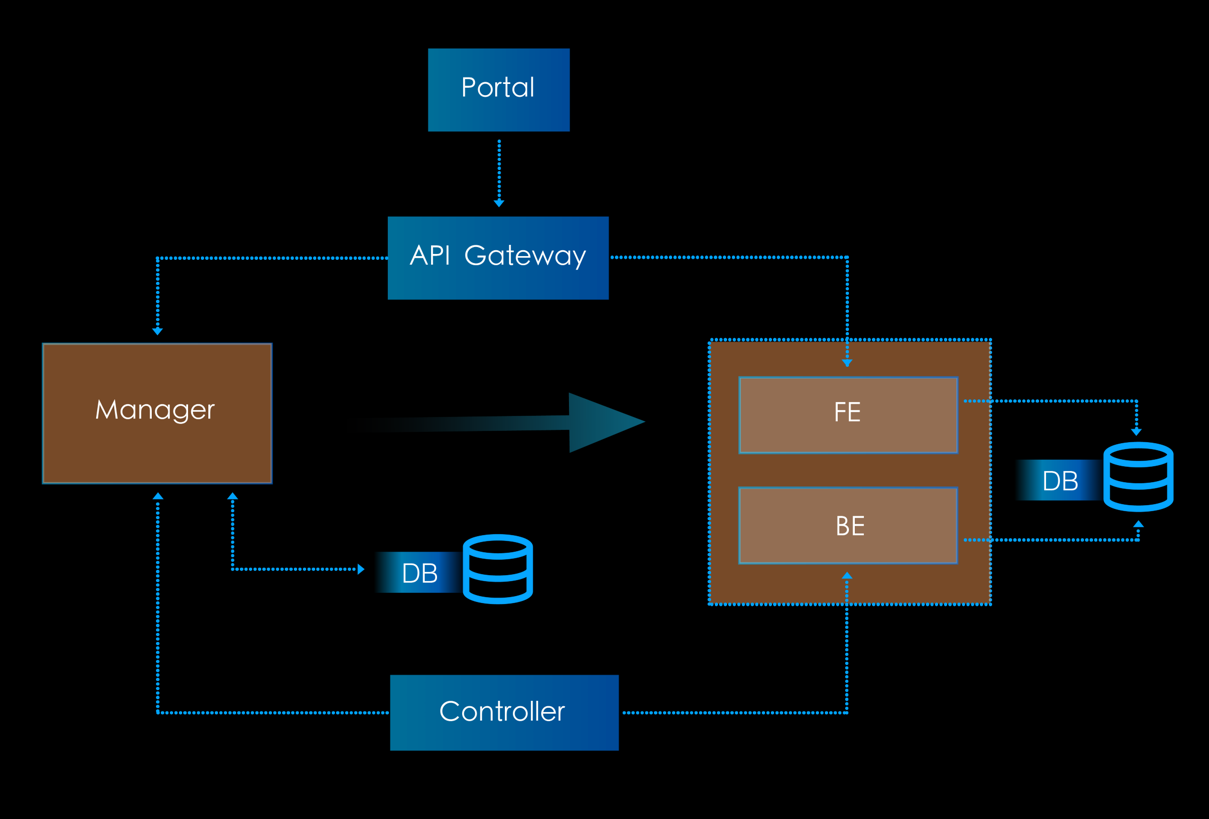
我们对大部分的后台 Manager 做了这样的重构。这样做也为我们今后打算进行的持续优化做了必要的铺垫。比如,之前整个 Manager 是用 C++ 编写的,但拆分后,我们就可以为 Frontend 和 Backend 各自选择更适合它们特性的编程语言和框架 - 当前我们正在将整个 Frontend 用 Go 语言进行重构,对于编写一个基于 REST 风格的 HTTP web service 来说,用 Go 语言做开发,所能获得的工作效率上的提升是十分显著的(Go 对 RESTful 风格的支持,对异步请求的处理等等,都要明显优于 C++)。
分寸之间:控制面程序的灰度
做完了 Manager 的 Frontend 和 Backend 的拆分后,我们分别对 Frontend 和 Backend 的代码做了大量的修改以支持可用区相关的特性。其中,Frontend 部分主要负责的是和前端控制台以及 API 交互的逻辑,也就是所谓管理面 management plane 的逻辑,这部分逻辑一般是用户直接可见或可操作的。Frontend 模块的灰度能力是由上图中的 API Gateway 来提供,可以支持按用户 / 按 API/ 按控制台版本等各个维度的转发调度。
另一方面,Backend 模块主要负责的是与 controller 交互下发规则的逻辑,也就是所谓控制面 control plane 的逻辑(或者说 Backend 模块 + controller 共同组成了 control plane,直接决定了整个底层 SDN 网络在数据转发面的行为逻辑)。此时对于 Backend 模块,我们还是缺乏一个灵活的灰度能力。在此之前,Manager 的发布流程是这样灰度的:
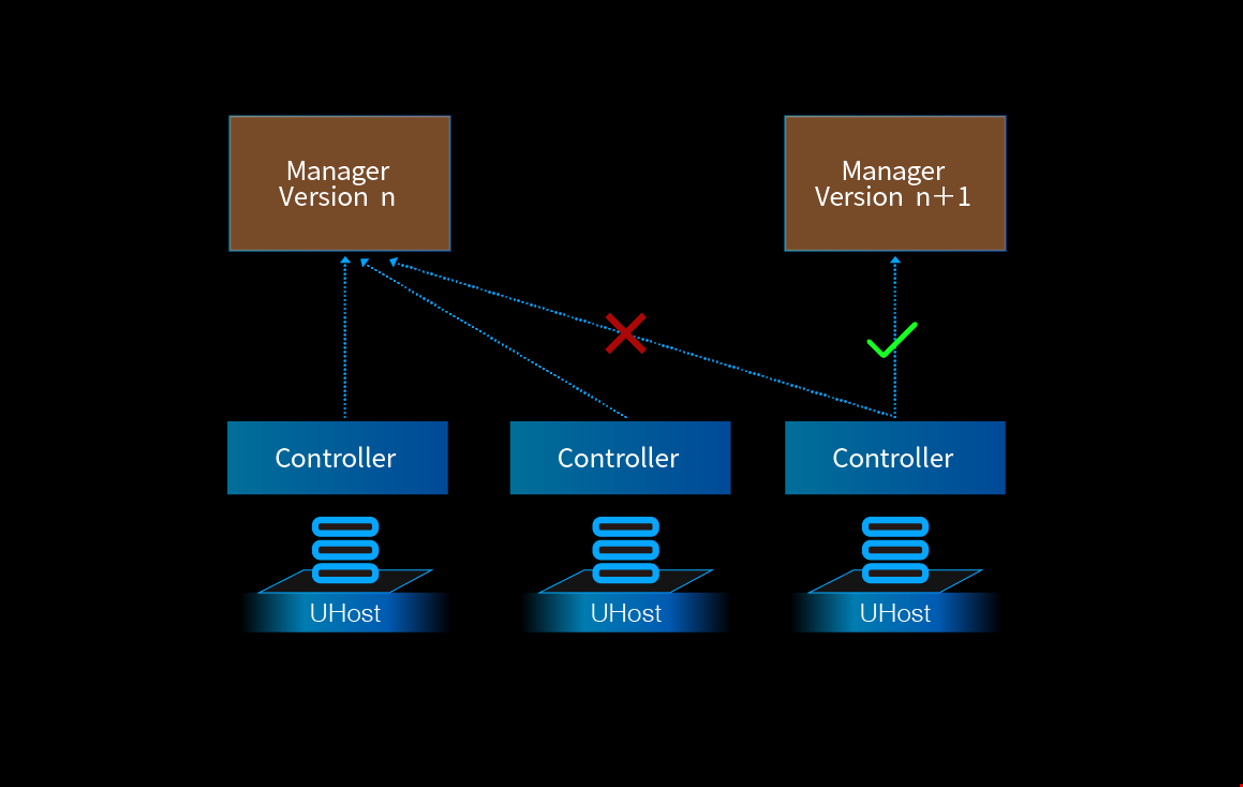
也就是说,对于后端控制面,我们是按照宿主机的维度来灰度的:通过修改一台宿主机上 controller 的指向来决定它所运行的控制面逻辑。这个方式也许在之前的场景下都还可以接受,但在面对可用区这样深入彻底的全局特性变更的时候,一台宿主机粒度的灰度能力还是不够精细。这是因为对于基于虚拟化的云计算平台而言,一台宿主机上一般都是多租户(multi-tenant)的(除非是像主机私有专区之类的特殊主机产品),我们要求的灰度能力是可以按用户的维度,一个用户一个用户地将他们切换到可用区的服务上。
正如 David Wheeler 所言:
All problems in computer science can be solved by another level of indirection.
我们也为 controller 和各个 Manager 的 Backend 之间添加了一层转发代理(这里以 Route Manager 为例):
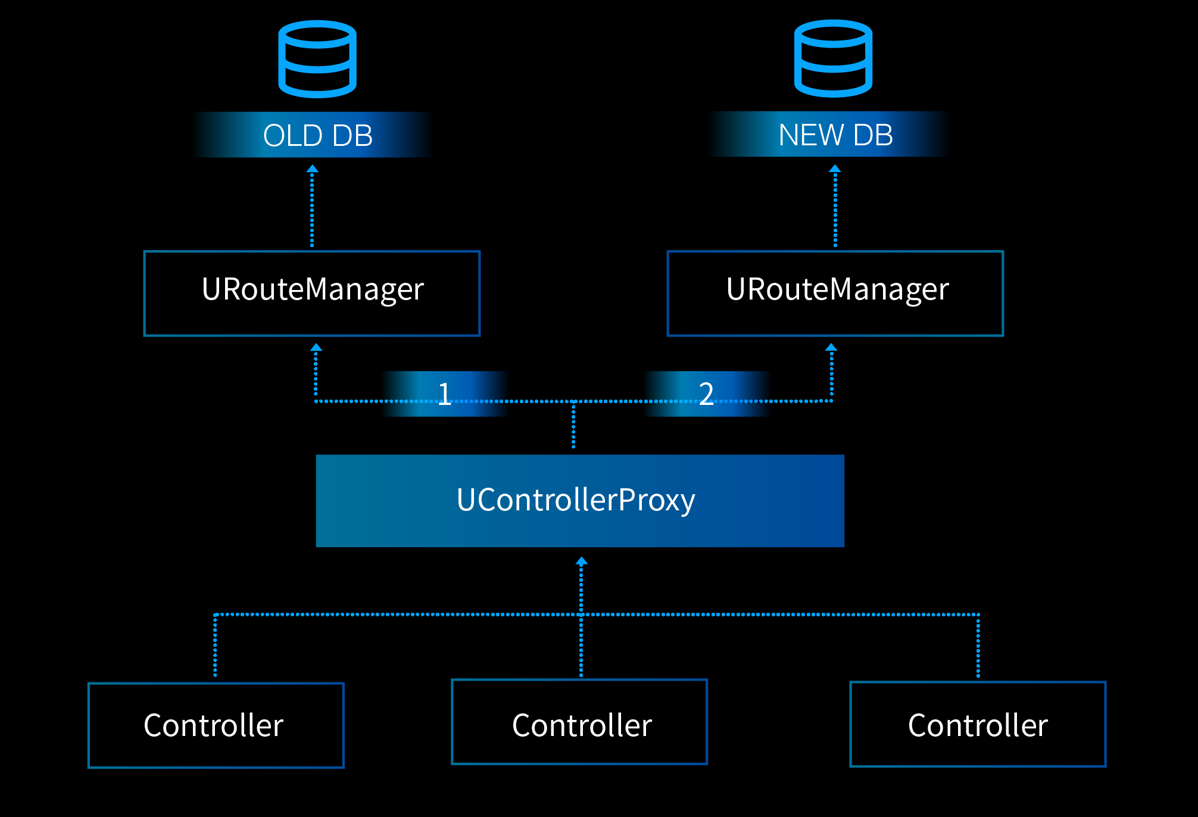
在 Controller Proxy 里我们实现了如下能力:
- SDN 层面的 ID 到用户账户 ID 之间的映射(因为数据转发面上的 overlay 协议是不关心用户的账户信息的,因此也不可见);
- 高并发的处理能力(因为数据转发面和控制面之间的交互通信是海量的);
- 快速水平扩容的能力(其实就是通过 ZooKeeper 来添加节点)。
如此,我们对整个后台服务灰度能力的改造就基本完成了。最后,我们还是想提一句,对于模块间耦合的重构一定要持续主动地进行。这次在可用区项目的过程中对如此大量的服务程序做一次性的重构(可以说是“被迫的”),代价是很大的,整个研发团队顶着巨大的压力加班加点;从项目管理的角度来看,这不是一个很理想的状态。而且在时间期限的压力下,很可能还会做出妥协而非最合理的架构决定,要知道,对于 David Wheeler 上面那句著名的引语,Kevlin Henney 还给出了一句著名的推论:
All problems in computer science can be solved by another level of indirection, except for the problem of too many layers of indirection.
在下一节中,我们就来讨论一下,既然我们做了如此之多的变更和重构,我们又是如何保证这些新的逻辑既能实现新的功能,又不会破坏向前兼容性的?靠巨细靡遗的测试来保障吗?
移山之术:管理面程序的灰度和亿万用户数据迁移
UCloud 的整个后台服务程序在升级到可用区逻辑的过程中经历了大量的改造,尤其是在 SDN 网络服务的部分,大量的 overlay 互联互通(内网虚拟 IP 之间的,外网 EIP 和内网 UHost 之间的)的逻辑都发生了改变。更为重要的是,为了支持可用区的逻辑,后台业务信息数据库表的 Schema 都要经过改造,我们面临的挑战是将海量的用户数据平行迁移到新的 Schema 下与新的后台程序的读写逻辑兼容并在这期间不中断客户的现网业务。
首先,我们清醒地认识到:即使我们设计再复杂的测试用例,也无法真正覆盖到生产环境中错综复杂的用户场景;并且,如果我们单纯地依赖自身的测试,整个项目的实施时间也会变得无法忍受之长。在飞速奔驰的生产环境的跑车上换引擎的问题我们已经在前面讨论过了,但在换之前,如何保证这个引擎和车的其他部分是兼容的而不会一换上就将整辆车 crash 掉,这个是我们要解决的问题。
我们必须在行进中的跑车上加一组轮胎让新的引擎去驱动,然后看看那组轮胎是不是运行正常,新的引擎和轮胎会接受同样的驾驶指令——方向盘、油门、排挡等等——并做出它们的响应,但不会直接影响原车的行驶,我们只需观察它们响应驾驶指令时的行为是否与平行的原车的行为是一致的,如果有问题,我们可以做停机修正然后再启动。
这个思路的灵感是来自于一篇 Twitch.tv 工程师分享的技术文章《 How we migrated over half a billion records without downtime 》(注:Twitch.tv 是北美第一大的游戏直播门户,2014 年 Amazon 耗资 10 亿美元收购了它),我们首先来看一下总体的迁移思路:
- 对当前的数据库做一次全量的 dump;
- 开启“双读双写”模式将全量的用户读写操作导到新的可用区程序逻辑上执行一遍;
- 将原数据库的全量 dump 导入新的数据库内;
- 将第 1 步和第 2 步之间“遗漏”的所有操作重新写入(replay)新的数据库中;
- 开始验证新的逻辑和新数据库里的信息适合和原数据库保持一致;
- 对于任何产生不一致的情况排查并修复根因;
- 当数据一致性达到 100% 并保持一定时间的时候,确信新的 pipeline 可以投入使用了;
- 按用户维度将流量切换到新的 pipeline 上。
下图完整地呈现了我们整体思路的架构:
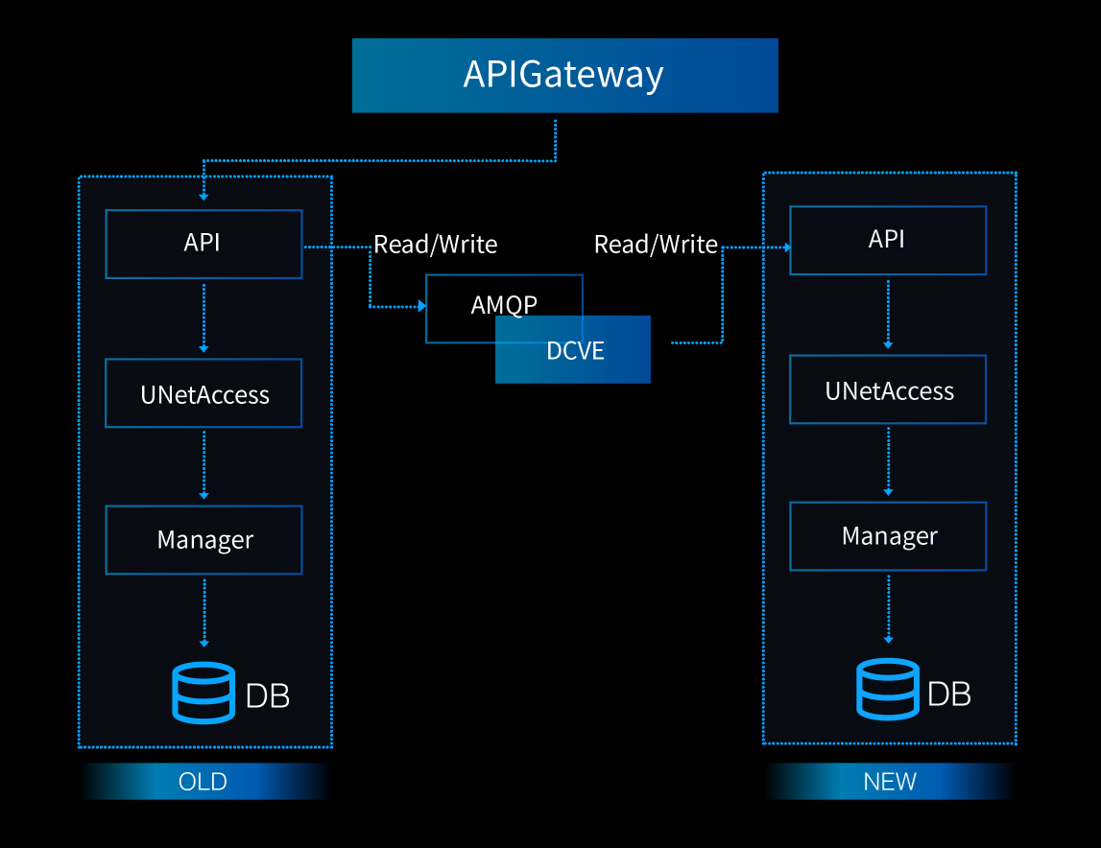
当非可用区的 API 接到一个请求时,它会首先执行该请求,然后将一个 message 添加到我们后台的消息队列(AMQP 协议)中去,这个 message 会包含下列信息:
Message: [TimeStamp] [API Operation] [Input Parameter] [Result of the API Operation]
其中“时间戳”的信息是必要的,因为我们在新的逻辑中执行这些操作的时候必须保证其时序是不变的。另外对于“读”操作,我们会在 message 中带入原操作的结果,这样在新的逻辑上执行了同一操作后,我们可以实时地在线校验两个操作的返回结果是否一致。如果不一致的话,DCVE 会立刻抛出一个异常告警,然后研发团队就会介入排查原因了。对于“写”操作,由于一般不会直接返回操作后的新数据内容(有些 API 可能会),所以我们更多的是依赖离线对账,但原理也是一样的。
图中的 DCVE 是 Data Consistency Validation Engine 的缩写,它主要的任务就是从消息队列中读取包含 API 操作信息的消息,然后通过一张 API 映射表将同样的操作在新的可用区逻辑上执行一遍并比对执行的结果。新的操作在执行后,我们通过在线校验或者离线对账的手段来验证两边的数据是否在语义上保持一致的,如果不是就会抛出异常告警。这样的机制使我们能实时利用现网真实的用户操作来验证我们新编写的程序代码,不但省去了我们自己穷举测试用例的时间,也利用了“众包”的手段更好地复现了用户真实的操作行为,帮助我们更快地定位到那些真正会对用户使用造成影响的程序 bug:
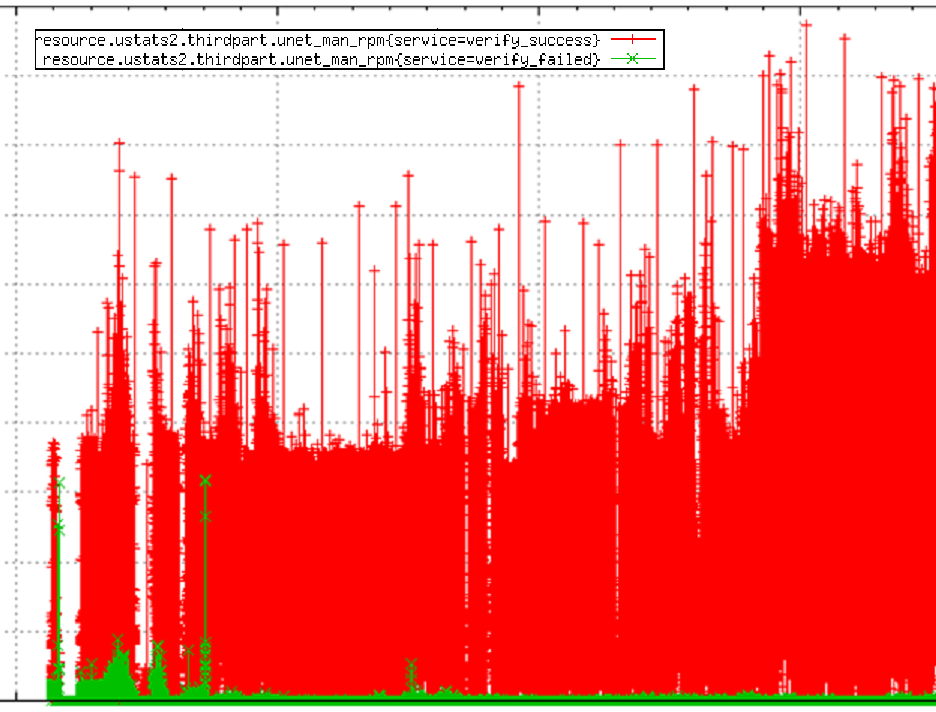
这样截图中显示了我们对其中一个 Manager 上两边的读写操作所做的校验结果。绿色的是不一致的结果,红色的是一致的结果。可以看到,前期还是有一定量不一致的结果的,一般都会对应一个或数个程序逻辑里的 bug。在经过一段时间的修复后,我们基本能达到一个稳定的状态了。我们发现的 bug 里比较有代表性的包括:
- 异步操作执行顺序不一致导致数据不一致;
- 批量返回数据的时候由于数据是不排序的导致不一致;
- 操作失败后的重试逻辑在新的服务里没有正确实现导致的不一致。
下图是我们对每一个用户灰度过程中会遵循的一个标准化流程:
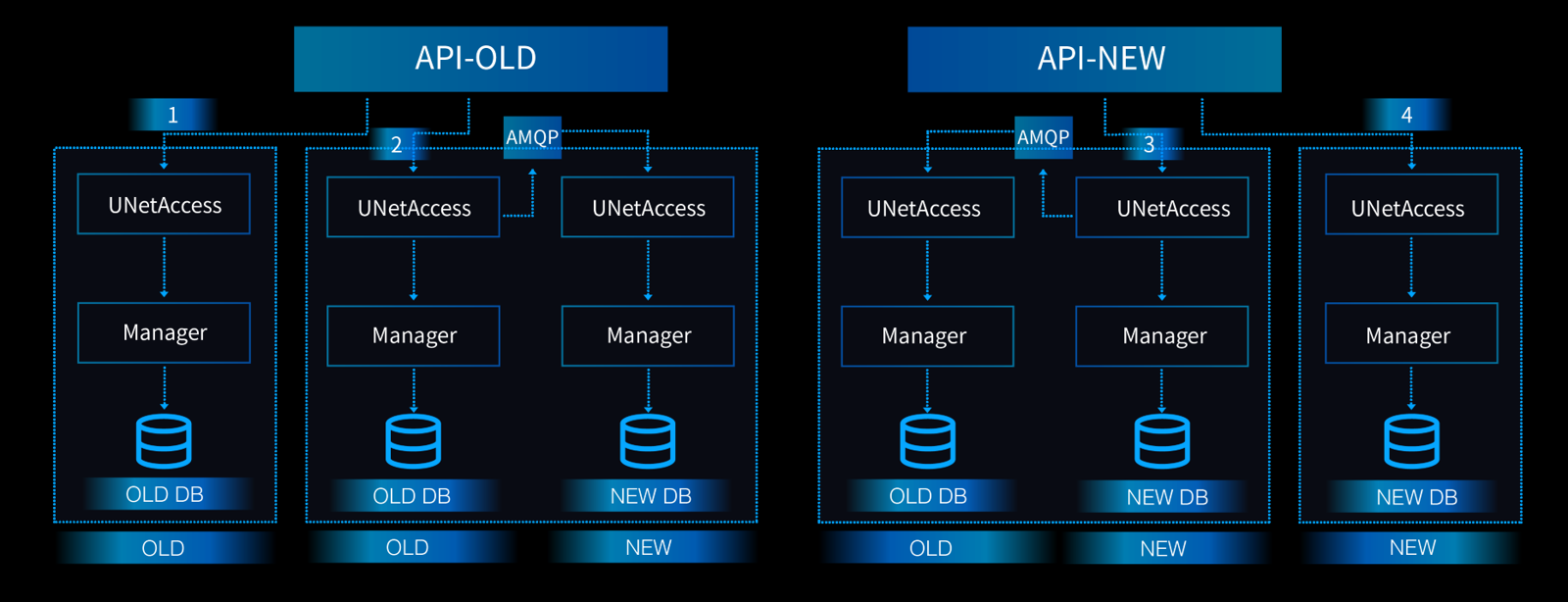
简单解释一下每一个阶段我们后台逻辑工作的模式:

大家可能注意到,在 Stage 3 中,我们还是将切换后的用户在新可用区下所做的操作同样“双写”回了老的非可用区的数据库里(通过调用非可用区对应的 API)。这样做的原因在于如果我们一旦发现可用区的逻辑有重大缺陷的时候,老的数据库中的信息还是和新的数据库保持了一致的,如此我们如果需要做紧急回退的话,也能够有条件完成。
结语
在本篇技术分享中,我们详细介绍了我们是如何验证并灰度发布可用区这个全局性的产品的。实现一个生产环境下的大型分布式系统,如果面对的问题数量级很小,通常很多矛盾都不会暴露出来。
如果所有的新功能都能重起炉灶,也只是在规模达到一定量级前一个美好的理想状态。真正的困难往往就是在运营海量数据和保证现网服务不回归这两个前提下才会集中爆发出来,而在这两个前提条件下稳定地迭代新的特性和功能,就犹如是给高速飞驰中的跑车更换引擎,是对一个系统和它背后的研发运营团队的真正挑战。仅仅有用户至上的情怀恐怕还是不够的,要能拿出切实可行的技术方案和运营手段来。而这里的方法论、支撑系统、团队协同都需要经过大量的实战考验才能形成。
UCloud 的团队在运营一个超大型的 IaaS 公有云平台上已经探索了 4 年时间,我们还是在不断地发现可以改进的地方,也在不断地总结和推广经验和方法论,同时希望在这方面有实践的朋友们一起来讨论和切磋。感谢大家对这个“可用去特性技术内幕全面解析”系列的关注,期待听到您的批评和指正。
答疑环节
问:可用区对物理范围的限制有多大?AWS 的划分比较大,比如亚太是一个区。但是大陆互联网链路复杂,互联互通一直是个问题,可用区的架构能多大程度上消弭这个障碍。
俞圆圆:一个可用区理论上一般是一个物理的机房,当然也可以由多个物理数据中心组成,然后一个区域(Region)是由多个可用区组成的,因此这位先生可能问的是一个 Region 内的不同可用区之间的物理范围有何限制。
一般来说,可用区之间除了要保障带宽,供电,防火,防水,防震等等方面的完全独立之外,其他最重要的限制就是可用区之间的网络延迟。因为客户很可能是要基于可用区来搭建同城异地容灾的应用架构,所以网络延迟太高是无法接受的。因此也决定了可用区之间的物理距离一般不会太远,而且和连接可用区的网络链路的建设和质量有关,在 50-80 公里左右是一个正常范围。
大陆地区的互联网链路情况确实很复杂,UCloud 的可用区之间是通过由双星型 POP 点来连接的。这个在我们这个系列的第一篇技术文章里有详细的介绍,大家可以在 InfoQ 官网找到。POP 点是运营商中立的属性,这样就较好地规避了不同数据中心间由于归属不同运营商造成网络链路建设很困难的情况,这里的困难不是说技术上的,而是说商务或政策上的,具体我就不展开说了,相信大家如果使用过电信 / 移动 / 联通 / 世纪互联 / 首都在线等等 IDC 运营商的服务,应该都会有些体会。不同运营商的情况不同,无法一概而论,要慢慢积累经验和商务关系。
问:想请教一下可用区对 CDN 的依赖如何?现在很多视频直播应用其实几乎全靠 CDN 在扛。
俞圆圆:CDN 是不依赖于可用区的,CDN 的节点一般来说都会比云服务商的数据中心要多的多。UCloud 现在有 10+ 个数据中心(海内外),但 CDN 节点已经有 500 多个了(还在不断建设中)。
问:很多私有云 / 混合云用户选择用 OpenStack 部署,想问下 UCloud 可用区技术研发过程中开源项目的占比有多大,自研占比有多大?以及为什么是这样的占比?
俞圆圆:这个其实不同的业务的情况不同,就我所负责的业务来说,开源与自研大致是 3:7 的比例。我们不想重新发明轮子,但有很多定制化的需求(比如像 ovs 内核模块的调优,SDN 业务逻辑的实现),还有许多相对前沿的项目(比如 NFV 的实现),还是没有太多成熟的现成开源方案的。我们研发团队的心态比较开放,也很乐意参加各类社区的讨论和活动,并和很多企业和团体有合作。
问:实际线上实施的时候,有过切换到非可用区接口的情况吗?切换的时候用户数据平面的网络会受影响吗?
俞圆圆:确实发生过切换后测试外网 IP ping 不通的情况,或者服务告警的情况,遇到这些我们检验或者监控到的异常情况,我们都会尽可能选择第一时间先回退变更。
问:多可用区方案中广播域是覆盖所有 AZ 吗?AWS 和阿里云都是把子网限制在一个 AZ 里。
俞圆圆:广播域的定义 follow 经典网络的行为(这是 SDN 的一般原则吧,在虚拟网络中尽量不改变经典网络的协议行为)也就是说广播域就是主机所处的子网,当前子网是不能跨 AZ 的,因此广播域也不跨 AZ。后续,我们会支持子网跨 AZ,也就是子网变成 Region 级别的属性。
问:我想问一个问题,就是刚才有几张图都反复提到了 API 网关,这个和 SDN 里常讲到的虚拟路由下的虚拟网关有什么关联度?还是二者是同一个?
俞圆圆:哦,API 网关是为跨 region API 做转发调度的,也提供了比较完整的灰度能力,和 SDN 的虚拟网关没什么关系。SDN 网络中的虚拟网关是一个逻辑概念,它可能对应了一个服务集群或实例,也可能对应是一组路由调度规则。我觉得后者更符合”虚拟网关“的实现,就是说,和”物理网关“不同,”虚拟网关“主要是 SDN 网络中的一个调度逻辑。
作者简介
Y3(俞圆圆),UCloud 基础云计算研发中心总监,负责超大规模的虚拟网络及下一代 NFV 产品的架构设计和研发。在大规模、企业级分布式系统、面向服务架构、TCP/IP 协议栈、数据中心网络、云计算平台的研发方面积累了大量的实战经验。曾经分别供职于 Microsoft Windows Azure 和 Amazon AWS EC2,历任研发工程师,高级研发主管,首席软件开发经理,组建和带领过实战能力极强的研发团队。
感谢魏星对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论