

PointRend 是何恺明团队对图像分割领域的又一最新探索,该项工作创新地采用计算机图形学的渲染思路来解决计算机视觉领域的图像分割问题。算法不仅提升了分割过程中的平滑性,实现了对图像细节的准确分割,也大大节省了资源消耗,算力需求仅为 Mask R-CNN 的 2.6%。此外,PointRend 可以作为神经网络模块,与其他图像分割元网络,例如 Mask R-CNN 和 DeepLabV3 结合使用,能够显著提升分割网络的性能。目前,PointRend 已在 GitHub 上开源,本文为 AI 前线第 104 篇论文导读,我们将对这篇论文的具体方法和效果进行解读。
在论文《PointRend: Image Segmentation as Rendering》中,研究人员提出了一种有效的高质量图像分割新方法:将计算机图形学经典方法中的高效渲染与像素标记任务中的过采样(oversampling)和欠采样(undersampling)挑战类比,提出了将图像分割作为渲染问题的独特视角。从这个角度出发,作者提出了 PointRend(Point-based Rendering)神经网络模块:该模块基于迭代细分算法,在自适应选择的位置执行基于点的分割预测。PointRend 可以与现有的最新模型结合,灵活地应用于实例和语义分割任务。定性实验表明,对于先前的方法过度平滑的区域,PointRend 可以输出清晰的对象边界。定量实验表明,PointRend 在 COCO 和 Cityscapes 数据集上的实例分割和语义分割任务的表现都有显著提高。在同样的内存和算力情况下,PointRend 与现有方法相比能输出更高的分辨率。
1 介绍
图像分割任务需要将从规则网格中采样的像素映射为同一网格上的一个或一组标签图(label map)。对于语义分割任务来说,标签图表示了每个像素的预测类别。而在实例分割任务中,需要为每个被检测的对象预测二值的前景 vs 背景图。这些任务所使用的方法目前基本上都是基于卷积神经网络(CNN)构建的。
用于图像分割任务的卷积神经网络通常在规则网格(regular grid)上操作:输入的是图像像素的规则网格,隐藏表征是规则网格上的特征向量,而输出则是基于规则网格的标签图。规则网格虽然方便,但在对图像分割而言,在计算方面未必理想。图像分割网络预测的标签图应当是基本平滑的,即邻近的像素一般使用同一个标签,因为图像的高频区域往往被限制在不同对象之间的稀疏边界。规则网格会对平滑区域过采样,而同时对对象边界欠采样。这样会导致在平滑区域进行过度计算,使得预测结果的轮廓变得模糊(如图 1 左上)。图像分割方法通常基于低分辨率规则网格来预测标签,如在语义分割任务中输入 1/8 分辨率的图像,或实例分割中输入大小为 28×28 的图像,以此作为欠采样和过采样之间的折衷。

图 1:使用 PointRend(右)进行实例分割与传统方法(左)的对比。PointRend 的细节效果更好,并且分辨率高,甚至五指的轮廓都可以分割出来。
数十年来,计算机图形学领域研究了很多类似的采样问题。例如,渲染器将模型(如 3D 网格)映射为点阵图像,即规则网格像素。尽管输出是基于规则网格的,但计算并不按照网格来均匀分配。常用的图形学策略是,对图像平面中被自适应选择点的不规则子集计算出像素值。例如典型的细分(subdivision)技术,例如类四叉树采样,常用于高效渲染出平滑的高分辨率图像。
这篇论文的核心思想是将图像分割视为渲染问题,并利用计算机图形学中的经典思想来高效地“渲染”高质量标签图。作者将这一思想实现为一个新型神经网络模块——PointRend,该模块使用细分策略来自适应地选择一组非均匀点,进而计算标签。PointRend 可以整合到常用的实例分割元架构(如 Mask R-CNN)和语义分割元架构(如 FCN)中。PointRend 的细分策略所需的浮点数运算相比于直接密集计算减少了一个数量级,能高效地计算高分辨率分割图。
PointRend 是一种通用思路,允许多种具体实现,但是作者表示,简单的设计已经取得良好的效果。抽象来看,PointRend 模块输入一或多个典型 CNN 特征图 f(xi, yi)(基于规则网格定义),输出基于更细粒度网格的高分辨率预测结果 p(x’i , y’i )。PointRend 不对输出网格上的所有点执行过度预测,仅对精心选择的点执行预测。PointRend 通过对特征图 f 执行内插,提取所选点的逐点特征表示,并使用一个小型 point head 子网络基于这些逐点特征预测输出标签。
作者在 COCO 和 Cityscapes 基准数据集上评估了 PointRend 在实例分割和语义分割任务上的性能。定性结果显示,PointRend 能够高效计算不同对象之间的清晰边界,如图 2 和图 8 所示。作者也观察到了评价指标上的性能提升,尽管这些任务所采用的评价指标(mask AP 和 mIoU)基于标准 IoU 度量,会偏向于对象内部像素的准确性,而对边界改进相对不那么敏感。定量实验结果显示,PointRend 显著提升了 Mask R-CNN 和 DeepLabV3 的性能。

图 2:Mask RCNN 使用标准掩码头的结果(左)与 Mask RCNN 使用 PointRend 的结果(右)示例。PointRend 的预测结果在对象边界具有更好的细节效果。
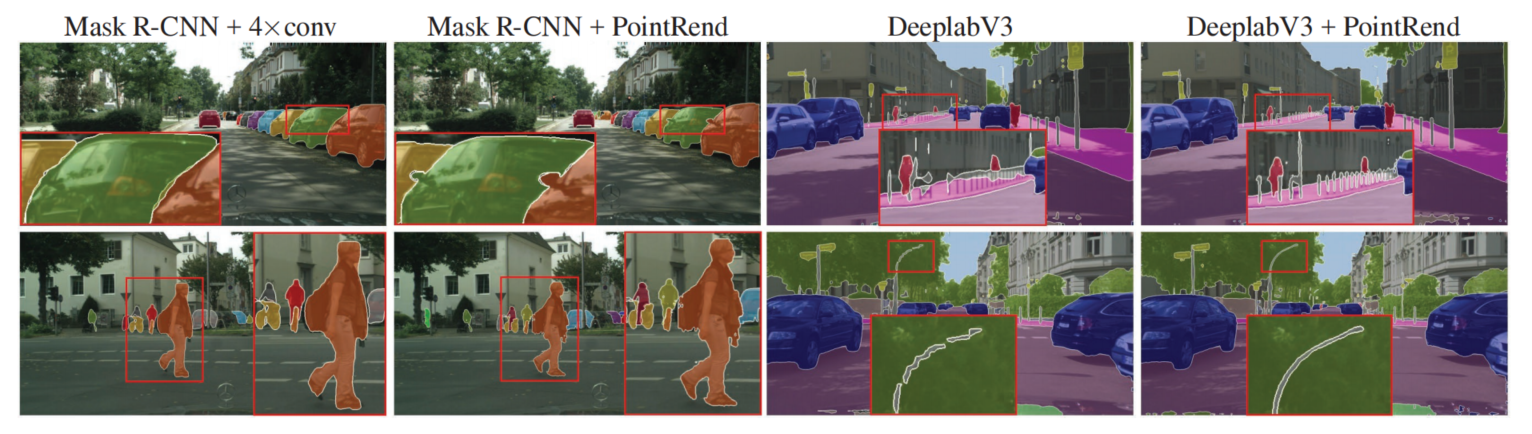
图 8:模型在 Cityscapes 数据集上的实例分割和语义分割结果。
2 方法
作者将计算机视觉中的图像分割问题类比为计算机图形学中的图像渲染问题。渲染是指将模型(如 3D 网格)显示为规则网格像素,即图像。尽管输出表示为规则网格,但其底层物理实体(3D 模型)是连续的,使用物理和几何推理(如光线追踪)可在图像平面的任意真值点查询其物理占用(physical occupancy)等属性。
类似地,在计算机视觉中,我们可以将图像分割看作底层连续实体的占用图,然后从中“渲染”得到预测标签的规则网格。该实体被编码为网络特征图,可以通过内插访问任意点。如果训练一个参数化函数,能够基于这些内插点的特征表示进行预测占用图。这个参数化函数即对应于计算机图形学中的物理和几何推理。
基于这种类比,作者提出 PointRend(Pointbased Rendering,基于点的渲染),用点的特征表示来解决图像分割问题。PointRend 模块输入一个或多个包含 C 个通道的典型 CNN 特征图 f∈R^(C×H×W),每一个特征图都基于规则网格定义的,并基于不同分辨率的规则网格输出预测结果,共有 K 个类别标签 p∈R^(K×H’×W’)。
PointRend 架构可应用于实例分割(如 Mask R-CNN)和语义分割(如 FCN)任务。在实例分割任务中,PointRend 应用于每个区域,通过对一组选中点执行预测,以从粗到细的方式计算 mask(如图 3)。在语义分割任务中,则将整张图像看作一个区域。因此在不损失通用性的情况下,作者在实例分割背景中介绍 PointRend。
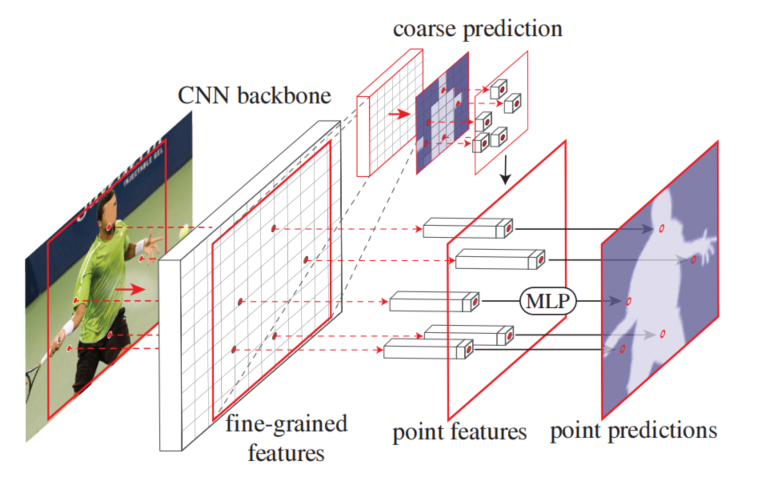
图 3 PointRend 应用于实例分割任务。
图像分割步骤:
一个标准的分割网络(实心红色箭头)输入一张图像,使用轻量级的分割头,对每个检测到的对象(红色框)进行粗略的 mask 预测(例如 7×7)。
PointRend 选择一组点(红色点),并用一个小规模的多层感知器(MLP)为每个点进行独立预测。MLP 使用在这些点处计算的插值特征(红色虚线箭头)进行预测。该特征包含细粒度特征和粗略预测特征。
迭代执行细分 mask 渲染算法,来细化预测 mask 的不确定区域。
PointRend 模块包括三个主要组件:
Point Selection(点选择):选择少量真值点执行预测,避免对高分辨率输出网格中的所有像素进行过度计算。
逐点(point-wise)表示:使用每个选中点在 f 规则网格上的 4 个最近邻点,对 f 进行双线性内插,计算真值点的特征。
point head:一个小型神经网络,基于逐点特征表示预测标签。
下面介绍 PointRend 三个主要组件的细节。
2.1 Point Selection(点选择)
PointRend 的核心思想是在图像平面中灵活和自适应地选择预测分割标签的点。理论上来说,这些点的位置应该在邻近高频区域分布较为稠密,如对象边界,类似于光线追踪中的抗锯齿问题。
推断:作者提出的用于推断的点选择策略受到计算机图形学中自适应细分(adaptive subdivision)这一经典技术的启发。该技术仅在与近邻值显著不同的位置上进行计算,来高效渲染高分辨率图像;其他位置的值则通过内插已经计算好的输出值来获得。
对于每一个区域,作者以一种从粗到细的方式迭代“渲染”输出的 mask。首先对规则网格上的点进行最粗级别的预测(例如使用标准的粗分割预测头)。在每次迭代中,PointRend 使用双线性插值对其先前预测的分割进行上采样,然后在这个更密集的网格上选择 N 个最不确定的点(例如,对于二进制 mask,概率接近 0.5 的点)。PointRend 然后计算这 N 个点的逐点特征表示,并预测它们的标签。一直重复该过程,直到分割上采样到目标分辨率。
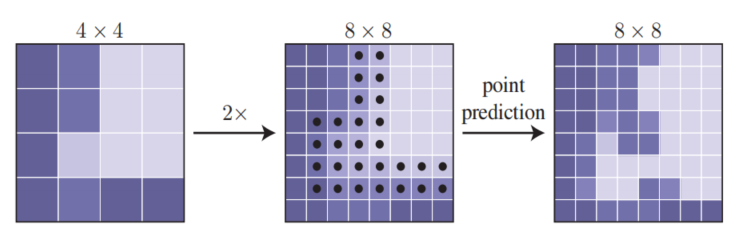
图 4:自适应细分步骤示例。在 4×4 网格上的预测经过 2 倍上采样为 8×8。然后 PointRend 对 N 个最不确定的点(图中黑色点)进行预测,在这一更细的网格上恢复细节。一直重复这一过程,直到达到期望的网格分辨率。
训练:在训练过程中,PointRend 还需要选择点来构建训练 point head 所需的逐点特征。原则上,点选择策略类似于推断过程中使用的细分策略。但是,细分策略使用的顺序步骤对于利用反向传播训练神经网络不那么友好。因此,训练过程使用基于随机采样的非迭代策略。
采样策略选择特征图上的 N 个点进行训练。它的目的是偏向不确定区域的选择,同时保持一定程度的均匀覆盖。基于以下三个原则:
(i)Over generation(过度生成):通过从均匀分布中随机抽样 kN 个点(k>1)来过度生成候选点。
(ii)Importance sampling(重要性抽样):通过在所有 kN 个点对粗略预测插值,并计算特定任务的不确定性估计来关注具有不确定粗略预测的点。从 kN 个候选点中选出最不确定的βN 个点(β∈[0,1])。
(iii)Coverage(覆盖范围):其余(1-β)N 个点从均匀分布中采样得到。
如图 5 所示,作者用不同的设置来说明这个过程,并将其与常规的网格选择进行对比。

图 5:训练中的点采样。图中展示了使用不同策略对同一底层粗糙预测进行点采样的结果。
2.2 逐点表示
PointRend 通过组合细粒度特征(fine-grained features)和粗略预测特征(coarse prediction features),来构建所选点的逐点特征表示。
在细粒度特征方面,为了让 PointRend 渲染出精细的分割细节,作者从 CNN 特征图中对每个采样点提取了特征向量。由于一个点是真值 2D 坐标,作者通过在特征图上进行双线性插值来计算特征向量。
细粒度特征虽然可以解析细节,但是也存在两方面的不足:
它们不包含区域特定的信息,因此被不同边界框覆盖的同一点具有相同的细粒度特征。而对于实例分割任务,同一点有可能预测不同的标签,因此需要额外的区域信息。
细粒度特征的提取取决于所用的 CNN 网络特征图,有可能只含有相对较低级别的信息。
因此,需要第二种特征类型——网络输出的粗略分割预测对细粒度特征进行补充,提供更多全局信息。以实例分割为例,粗略预测可以是 Mask R-CNN 中 7×7 的轻量级 mask head 的输出。以语义分割为例,它可以是步长为 16 的特征图。
2.3 Point head
对于每个选定点的逐点特征表示,PointRend 使用简单的多层感知器(MLP)进行逐点分割预测。该多层感知器在所有点(和所有区域)上共享权重。由于 MLP 预测的是每个点的分割标签,因此它可以通过标准的任务特定的分割损失进行训练。
3 实验:实例分割
3.1 实验设置
作者采用两个标准的实例分割数据集 COCO 和 Cityscapes,以及标准 mask AP 评价指标。实验使用以 ResNet-50+FPN 为主干的 Mask R-CNN 作为实例分割网络。Mask R-CNN 中的默认 mask head 是一个基于区域的 FCN,用“4×conv”来表示。作者用它作为对比的基线。
3.2 主要实验结果
表 1 对比了 PointRend 和 Mask R-CNN 中采用默认 4×卷积 head 的性能。PointRend 在 COCO 和 Cityscapes 数据集上的性能均超过 Mask R-CNN。
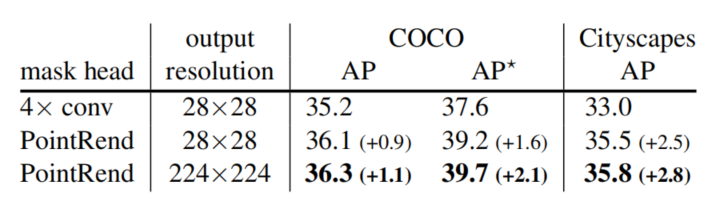
表 1:PointRend vs Mask R-CNN 默认 4×卷积掩码 head 的性能对比。
对于 PointRend 来说,28×28 和 224×224 之间的差距相对较小,因为评价指标 AP 基于标准 IoU 度量,会偏向于对象内部像素的准确性,而对边界改进相对不那么敏感。但视觉对比中,可以看出边界质量的提升十分明显,如图 6。

图 6:PointRend 不同输出分辨率的推断结果。高分辨率 mask 中对象边界更加贴合。
细分推断策略(Subdivision inference)让 PointRend 能够获得高分辨率预测结果(224×224),而使用的浮点数运算和内存仅为默认 4×卷积 head 的 1/30,见下表 2。PointRend 忽略对象中粗粒度预测就已足够的区域,从而在计算量大幅减少的情况下输出与 Mask R-CNN 框架一样的高分辨率结果。
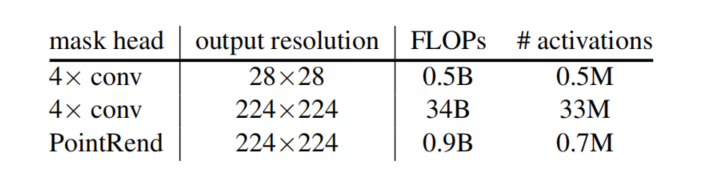
表 2:输出 224×224 分辨率 mask 的浮点数(乘加)和激活计数。
表 3 展示了在不同输出分辨率和每个细分步骤不同选择点数量的情况下,PointRend 的细分推断性能。
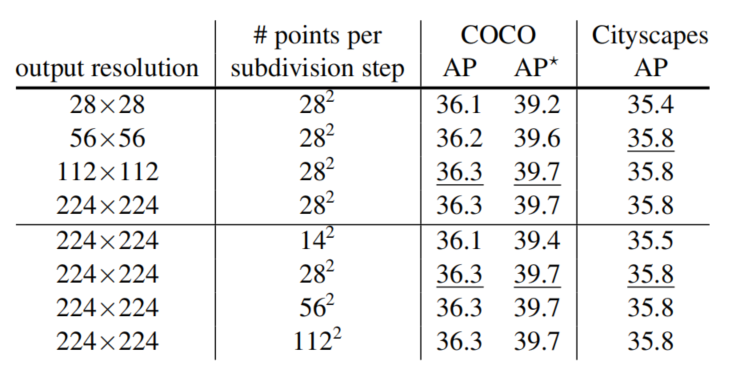
表 3:细分推断参数。
更高的输出分辨率能提升 AP 指标。AP 指标接近饱和时,输出分辨率从低到高(比如从 56×56 到 224×224)的视觉效果提升仍然很明显,如图 7。

图 7:PointRend 抗锯齿效果。
随着每个细分步骤中的采样点数增加,AP 指标也会饱和,因为首先在最模糊的区域中选择点。在粗略预测已经足够的区域对其他点进行预测。但是,对于具有复杂边界的对象,使用更多的点可能是有益的。
3.3 消融研究
表 4 展示了 PointRend 在训练过程中使用不同点选择策略时的性能。可以看出规则网格选择与均匀采样的结果相似。而偏向模糊区域的采样提升了 AP 值。然而,过于偏向粗预测的边界(k>10 且β接近 1.0)的策略会降低 AP 的值。作者发现参数 2<k<5 和 0.75<β<1.0 的范围内呈现相似的结果。
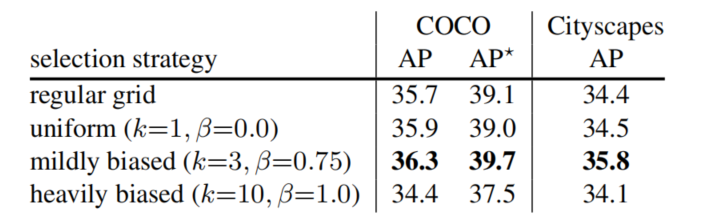
表 4:训练时不同点选择策略的性能。
表 5 展示了 PointRend 和基线的对比情况,PointRend 性能超过基线模型,且基线模型的训练时间比 PointRend 长,模型规模也比 PointRend 大,且其训练时间是 PointRend 的 3 倍。
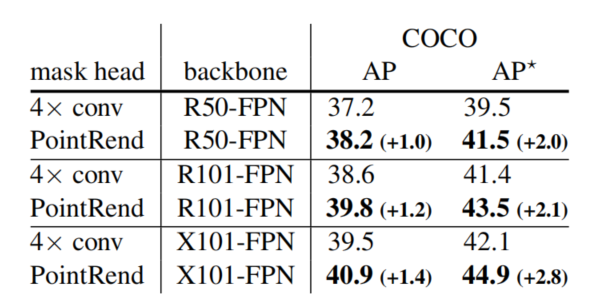
表 5:基线模型和 PointRend 性能对比。
4 实验:语义分割
4.1 实验设置
作者采用 Cityscapes 语义分割数据集,采用 mIoU 评价指标。作者采用 DeeplabV3 和 SemanticFPN 作为语义分割网络。PointRend 中的粗略预测特征来自语义分割网络的输出,细粒度特征分别从 DeeplabV3 的 res2 层以及 SemanticFPN 的 P2 层插值得到。
4.2 实验结果
表 6 展示了 DeepLabV3 和 DeeplabV3 + PointRend 的对比情况。
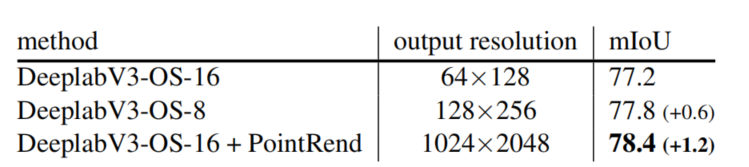
表 6:DeeplabV3 + PointRend 在 Cityscapes 语义分割任务上的性能超过基线 DeepLabV3。
使用空洞卷积可以将推断时 DeepLabV3 的输出分辨率提升二倍,但是需要大量算力和内存。与之对比,PointRend 具备更高的 mIoU。定性提升也非常明显,如图 8。
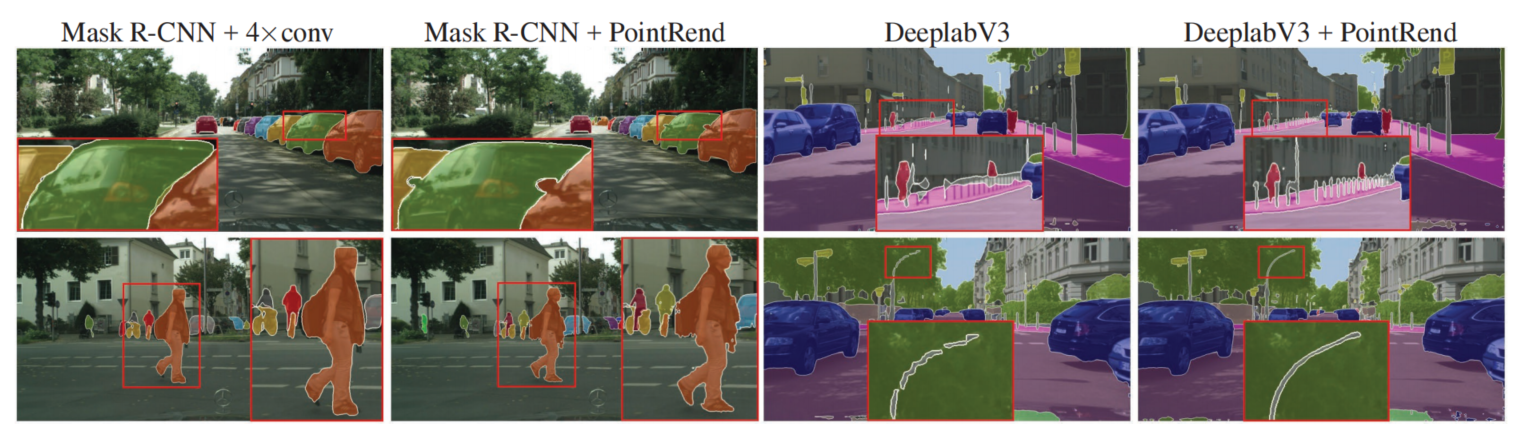
图 8:模型在 Cityscapes 样本上的实例分割和语义分割结果。
通过自适应地采样点,PointRend 对 32k 个点执行预测,可以达到了 1024×2048 的分辨率,如图 9。
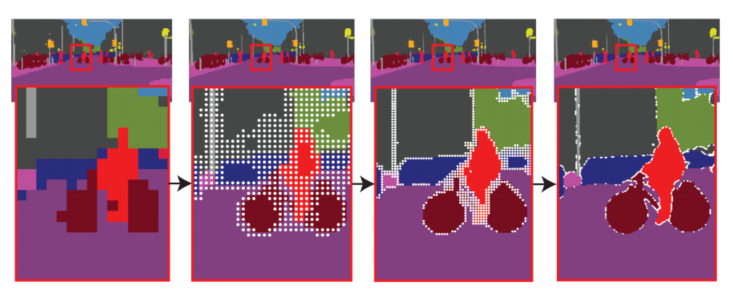
图 9:PointRend 在语义分割任务中的推断。
表 7 展示了,在 8 倍和 4 倍输出步长变化的情况下,SemanticFPN+PointRend 的性能较 SemanticFPN 有所提升。
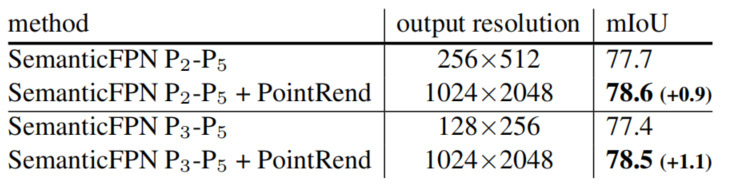
表 7:在 Cityscapes 语义分割任务中,SemanticFPN+PointRend 的性能超过基线 SemanticFPN。
论文原文链接:
PointRend: Image Segmentation as Rendering

InfoQ 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论