
概述
监控系统是整个 IT 架构中的重中之重,小到故障排查、问题定位,大到业务预测、运营管理,都离不开监控系统,可以说一个稳定、健康的 IT 架构中必然会有一个可信赖的监控系统,而一个监控系统的基石则是一个稳定而健壮的数据采集系统 ****。
定义采集数据
数据结构的选择
监控数据是标准的时间序列数据,传统的监控系统中,一条监控数据一般是由监控指标、时间戳和值组成,比如有 10 台服务器的内存使用率需要监控,一个时间周期内映射到系统中可能就是 10 条 mem.userd.percent 时间 值 这种格式的数据,然后分别和对应的主机关联。
这样做的缺点是,如果某一时刻想统计某个产品线、业务系统、集群、数据中心的某些监控指标的使用情况,可能就不太好实现。所以我们需要 ** 在传统的数据结构基础上增加一个字段,用来存储我们自定义的数据标签。为此,我们调研了当前主流的时序数据库,如 RRDtool、Graphite、InfluxDB、openTSDB 等,其中 RRDtool 和 Graphite 只能支能持时间维度和值维度,Cacti 和 Zabbix 就是基于 RRDtool 来绘图展示的。而 InfluxDB 和 openTSDB 都能满足我们的需求:其中 InfluxDB 版本比较低,而且每次更新变动都比较大;而 openTSDB 则在企业中有大量的成功案例。所以在数据结构的定义上,我们借鉴了openTSDB的数据结构,每条数据由metric、timestamp、value、tags组成,用tags键值对来标识不同的属性。** 比如网卡发送数据包数目为例,其数据结构如下:
[ { “metric”: “net.PacketsRecv”, “data_type”: “COUNTER”, “value”: 15729345.00, “time”: 1471242889, “cycle”: 30, “tags”:{ “iface”=”eth0” } } ]
- Metric 是一个可测量的单位的标称。metric 不包括一个数值或一个时间,其仅仅是一个标签,包含数值和时间的叫 datapoints,metric 是用逗号连接的不允许有空格,例如:cpu.idle,app.latency 等。
- Tags:一个 metric 应该描述什么东西被测量,其不应该定义的太简单。通常,更好的做法是用 Tags 来描述具有相同维度的 metric。Tags 由 tagk 和 tagv 组成,前者表示一个分组,后者表示一个特定的项
- Timestamp。一个绝对时间,用来描述一个数值或者一个给定的 metric 是在什么时候定义的。
- Value。一个 Value 表示一个 metric 的实际数值。
这样对于相同的 metric 数据,我们可以自由的通过 tag 的组合来获取我们真正需要的数据。
三种数据类型
既然有了上面的数据结构的定义,当然就会有数据类型,不同的数据可能代表的意义都不一样,OWL 中采用了 RRDtool 中比较常用的三种数据类型,分别为 GAUGE、COUNTER、DRIVER。
GAUGE 类型是一个计量器,可以理解最终存储的数据就是采集到的数据,比如服务器上的磁盘使用率,内存使用率,cpu 使用率,硬件的温度,风扇的转速,业务系统中的访问时间等等,这种数据会随时间的变化而变化,并且没有什么规律可言。
COUNTER 类型是一个计数器,该类型一般用于记录连续增长的记录,例如操作系统中的网卡流量,磁盘的 io,交换机接口的流量,业务的吞吐量等等,COUNTER 类型会假设计数器的值永远不会减小,除非达到数据类型的最大值产生溢出,OWL 客户端会存储最近一次的值和上一次的值,每次上报的过程中会取每秒的速率发送到 repeater,当计数器溢出,agent 会自动对数据进行补值,否则可能会因为溢出产生一个巨大的错误值导致错误告警。
DRIVER 类型用于表示单位时间内的数据变化,简单来说就是用来表示当前值和上一次值之间的差值,在监控领域中的实际应用场景可能不是很多。
agent 每次采集都会判断数据类型,并应用对应的运算规则。
采集系统的整体架构
架构的变化
相比于上个版本的架构,我们的数据采集系统还是发生了很大的变化,变化主要体现在服务逻辑拆分和重新规划。
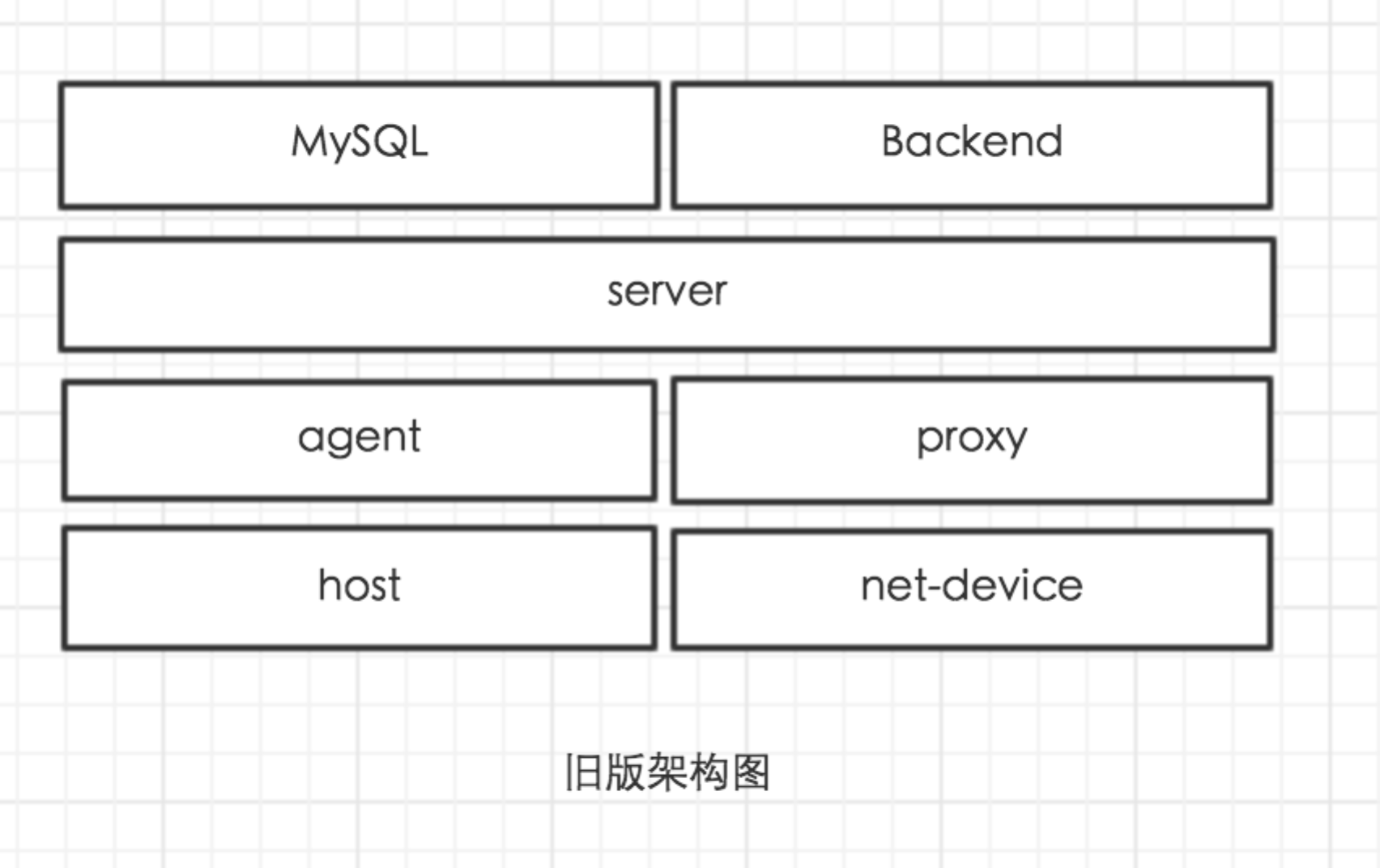
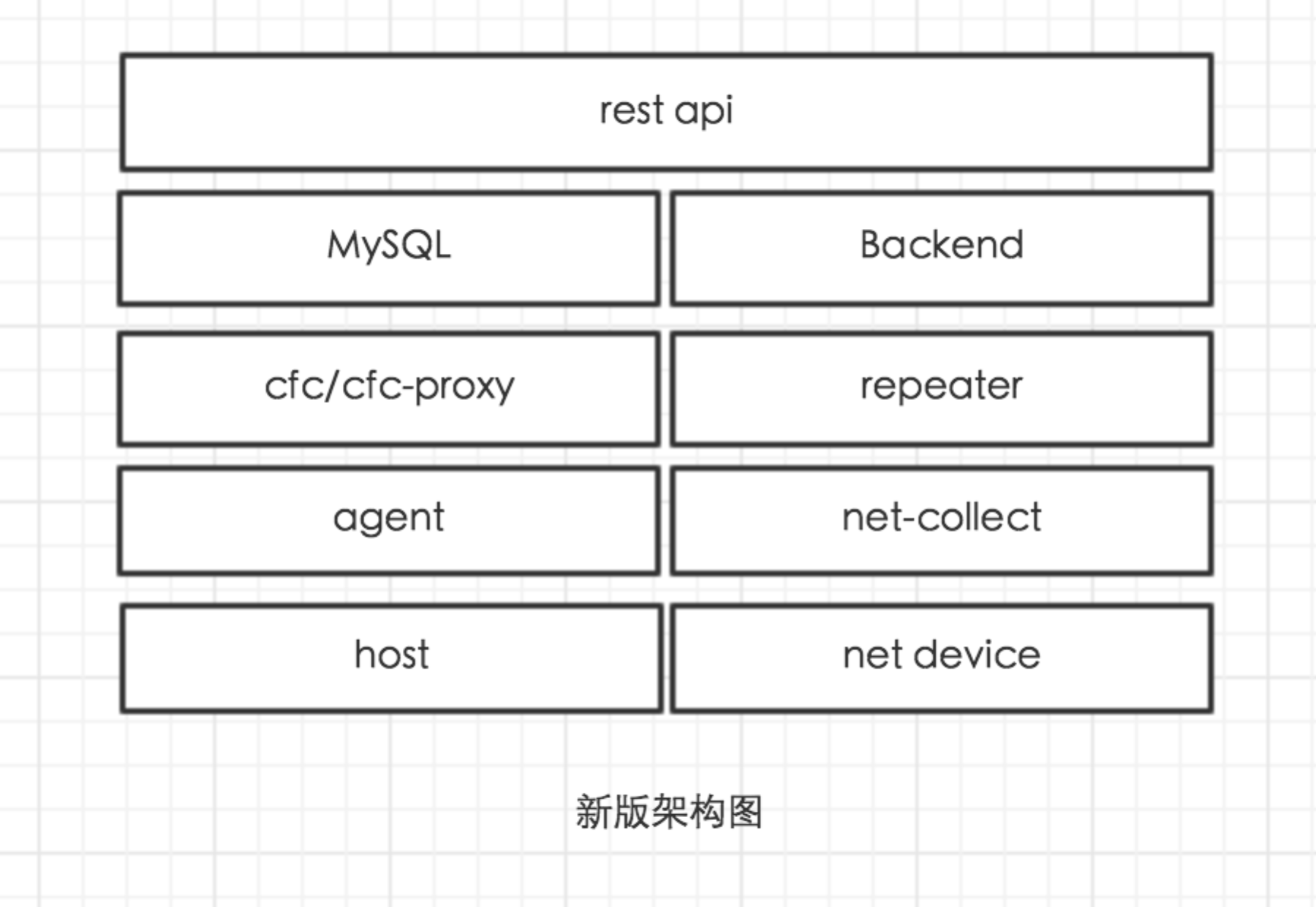
服务端在上个版本中,主要负责 agent 端配置的维护,监控数据的接收和转存,网络设备数据的采集,端口健康状态监测等功能,当服务端需要进行维护的时候,整个监控服务相当于不可用的。另外也不利于扩展。所以在该版本中对 server 进行了拆分,分别为 cfc、repeater、net-collect,其中 cfc 主要负责配置维护,repeater 负责监控数据接收和转发,net-collect 负责采集网络设备数据,任何一个组件都可用做到水平扩展,极大的降低了系统的风险。
模块的角色功能
- agent:通过内置 metric 以及自定义插件方式采集主机硬件、操作系统、中间件、业务系统等数据,并通过 tcp 长连接异步发送到 repeater。
- net-collect:负责采集网络设备各项性能指标,包含各接口接收发送字节数、数据包数、错误数等等,监控数据通过 tcp 长连接发送到 repeater 中,配置和接口信息发送到 cfc 中。
- cfc:一般部署于数据中心,直连 MySQL,负责维护 agent 或 net-collect 同步过来的 metric 信息以及插件的同步等
- cfc-proxy:一般部署于分支机构或异地机房,是 agent/net-collect 和 cfc 之间的通讯桥梁。
- repeater:可任意部署,负责接收时间序列数据并转发到指定的后端,支持 repeater->repeater、repeater->openTSDB、repeater->Redis 等。
采集系统如何与应用系统对接
比如我们现在新开发一个应用,那么我们需要梳理我们需要关心的指标,比如系统的吞吐量、延迟、接口或 url 访问量等等,由于 OWL 不支持主动 push 数据,所以我们需要将这些数据通过 Http REST API 方式暴露出来,然后使用 OWL 自带的 app_collect 插件来定时采集数据,API 暴露的数据结构大概如下:
[ { "metric": "app. latency ", "data_type": "GAUGE", "value": 1.0, "tags": { "product": "app01" } }, { "metric": "app.page_view", "data_type": "COUNTER", "value": 10324564, "tags": { "product":"app01”, “page”:”index.html”, } } ] {1}
采集系统的上层应用封装
基于该系统,我们可以在上层构建报警系统,统计分析系统,报表系统等等。大家可以自由去发挥。
其中,报警服务在上个版本中是基于 Python 的 Celery 去实现的,由于依赖众多模块,安装部署复杂,在开源过程中大部分反馈的问题都是在该模块的部署上。因此,在该版本中我们使用 go 语言对重构了报警服务,分为控制器和报警逻辑处理模块:其中控制器负责报警策略生成和报警结果处理;逻辑处理模块负责从控制器获取策略并去 OpenTSDB 读取数据进行对比,产生的结果返回给控制器处理。整体而言这是一个生产者消费者模型,理论上消费者可用无限扩展。更多报警的具体细节,会在本系列的报警文章中进行详细的介绍。
总结
数据的采集是起点而非终点,如何对采集到的数据进一步加工处理,并且能够帮助我们改善工作和生活才是最终目标,我们坚信,数据改变人们的决策方式,数据改善人类自身和环境。 TalkingData,让数据说话。
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论