

1. 绪论
etcd 作为华为云 PaaS 的核心部件,实现了 PaaS 大多数组件的数据持久化、集群选举、状态同步等功能。如此重要的一个部件,我们只有深入地理解其架构设计和内部工作机制,才能更好地学习华为云 Kubernetes 容器技术,笑傲云原生的“江湖”。本系列将从整体框架再细化到内部流程,对 etcd 的代码和设计进行全方位解读。本文是《深入浅出 etcd》系列的第三篇,重点解析 etcd 的日志同步机制,下文所用到的代码均基于 etcd v3.2.X 版本。
另,由华为云容器服务团队倾情打造的《云原生分布式存储基石:etcd 深入解析》一书已正式出版,各大平台均有发售,购书可了解更多关于分布式存储和 etcd 的相关内容!
另,由华为云容器服务团队倾情打造的《云原生分布式存储基石:etcd 深入解析》一书已正式出版,各大平台均有发售,购书可了解更多关于分布式存储和 etcd 的相关内容!
2. etcd 安全性
分布式共识算法(consensus algorithm)通常的做法就是在多个节点上复制状态机。分布在不同服务器上的状态机执行着相同的状态变化,即使其中几台机器挂掉,整个集群还能继续运作。
复制状态机正确运行的核心的同步日志,日志是保证各节点状态同步的关键,日志中保存了一系列状态机命令,共识算法的核心是保证这些不同节点上的日志以相同的顺序保存相同的命令,由于状态机是确定的,所以相同的命令以相同的顺序执行,会得到相同的结果。
raft 协议保证系统在任何时刻都保持以下特性:
选举安全:每次给定的 Term,整个集群只能选上一个 leader。
leader 只追加日志: leader 永远不会改写或者删除日志中的条目,它只会追加日志。
日志匹配: 如果两个节点的日志包含了相同的 index 和 term 的条目,则这两个节点的日志中,该条目及以后的条目都一样。
leader 日志完整性: 在一个 term 中如果 1 条日志已经 commit,那么后续的 term 中选举出来的 leader 一定存有这条日志。
状态机安全性:如果一个 server 已经 apply 了一条日志条目到状态机中,则其他的 server 不会 apply 一调相同 index 但是不同的日志。
其中 1、4、5 中我们在心跳和选举一章已经有所阐述,我们将在这一章中详细阐述 etcd 是如何保证所有这 5 条特性成立的。
3. 日志的基本形式和存储方式
日志的是以条目(Entry)的方式顺序组织在一起的,日志中包含 index、term、type 和 data 等字段。index 随日志条目的递增而递增,term 是生成该条目的 leader 当时处于的 term。type 是 etcd 定义的字段,目前有两个类型,一个是 EntryNormal 正常的日志,EntryConfChange 是 etcd 本身配置变化的日志。data 是日志的内容。

内存中的日志操作,主要是由一个 raftLog 类型的对象完成的,以下是 raftLog 的源码。可以看到,里面有两个存储位置,一个是 storage 是保存已经持久化过的日志条目。unstable 是保存的尚未持久化的日志条目。
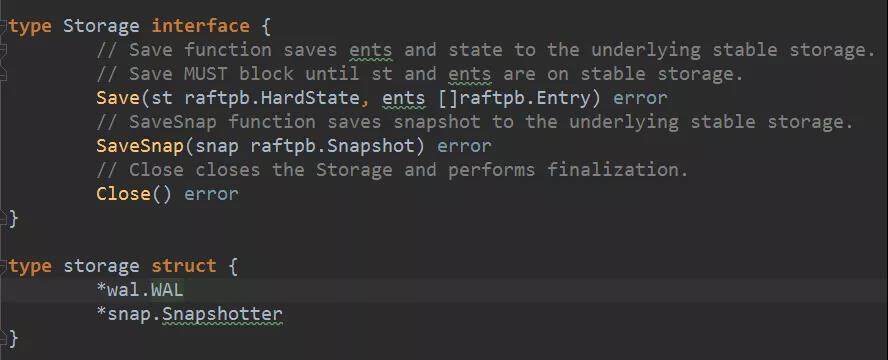
持久化日志: WAL 和 snapshot。下图显示持久化的 Storage 接口定义和 storage 结构中字段的定义。它实际上就是包含一个 WAL 来保存日志条目,一个 Snapshotter 负责保存日志快照的。
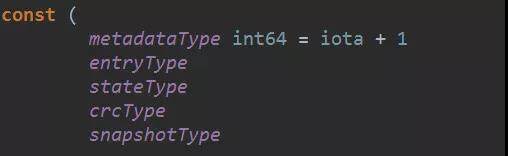
WAL 是一种追加的方式将日志条目一条一条顺序存放在文件中。存放在 WAL 的记录都是 walpb.Record 形式的结构。Type 代表数据的类型,Crc 是生成的 Crc 校验字段。Data 是真正的数据。v3 版本中,有下图显示的几种 Type:
WAL 有 read 模式和 write 模式,区别是 write 模式会使用文件锁开启独占文件模式。read 模式不会独占文件。

Snapshotter 提供保存快照的 SaveSnap 方法。在 v2 中,快照实际就是 storage 中存的那个 node 组成的树结构。它是将整个树给序列化成了 json。在 v3 中,快照是 boltdb 数据库的数据文件,通常就是一个叫 db 的文件。v3 的处理实际代码比较混乱,并没有真正走 snapshotter。
etcd 日志的保存总体流程如下:
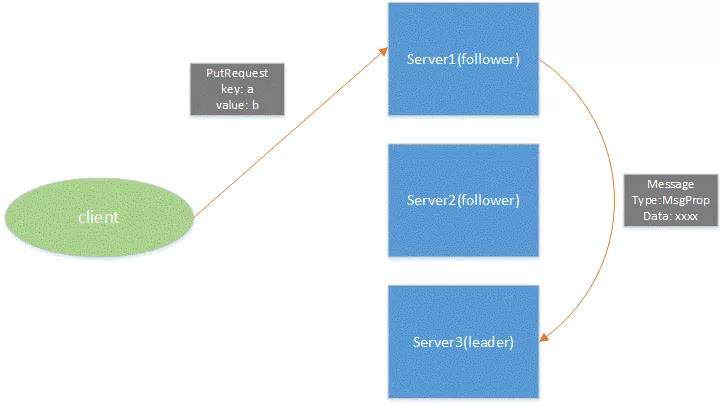
集群某个节点收到 client 的 put 请求要求修改数据。节点会生成一个 Type 为 MsgProp 的 Message,发送给 leader。
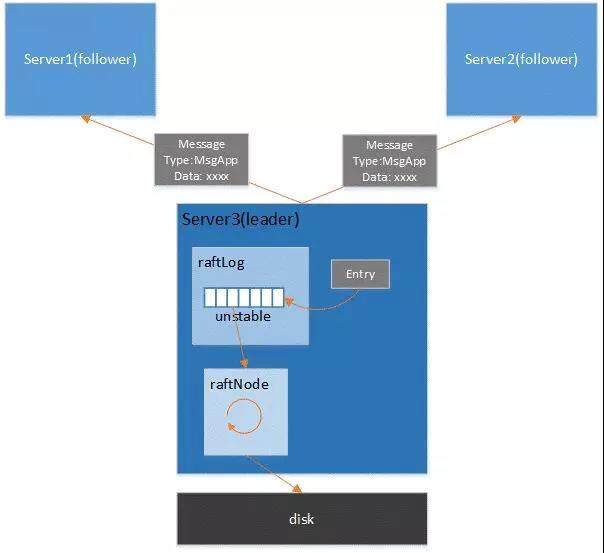
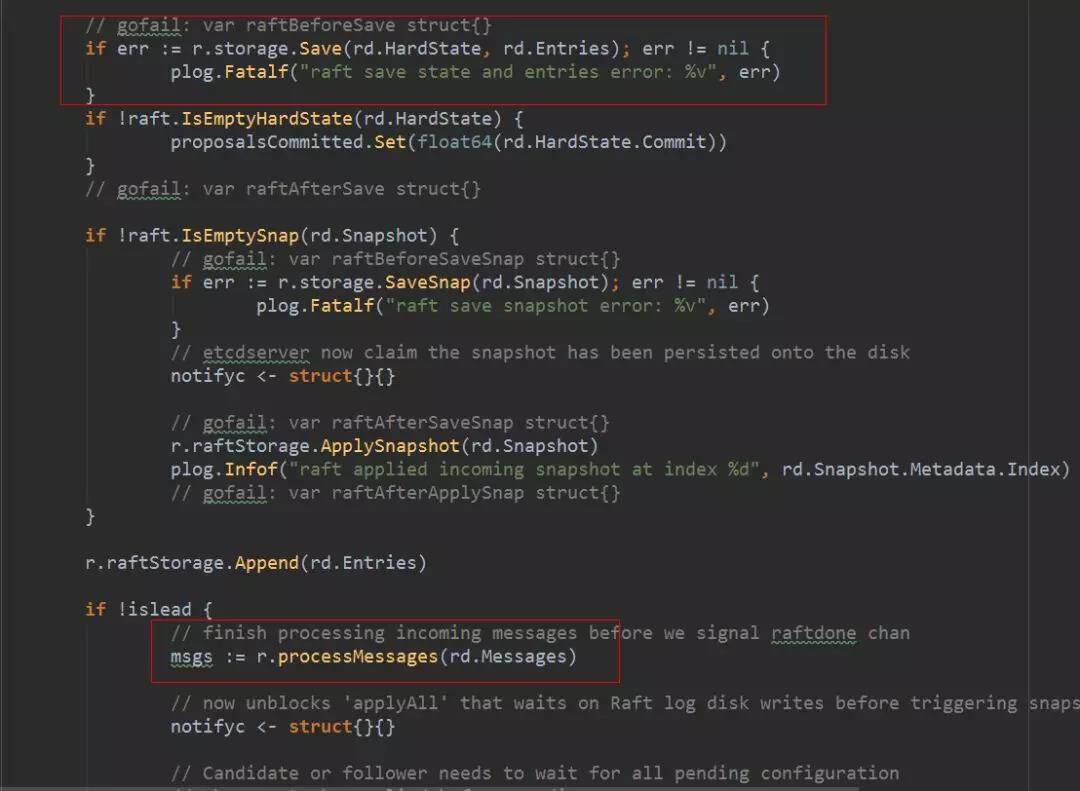
2. leader 收到 Message 以后,会处理 Message 中的日志条目,将其 append 到 raftLog 的 unstable 的日志中,并且调用 bcastAppend()广播 append 日志的消息。
3. leader 中有协程处理 unstable 日志和刚刚准备发送的消息,newReady 方法会把这些都封装到 Ready 结构中。
4. leader 的另一个协程处理这个 Ready,先发送消息,然后调用 WAL 将日志持久化到本地磁盘。
follower 收到 append 日志的消息,会调用它自己的 raftLog,将消息中的日志 append 到本地缓存中。随后 follower 也像 leader 一样,有协程将缓存中的日志条目持久化到磁盘中并将当前已经持久化的最新日志 index 返回给 leader。
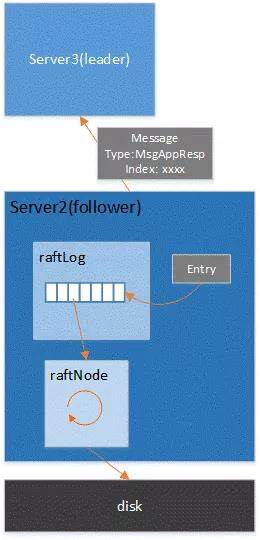
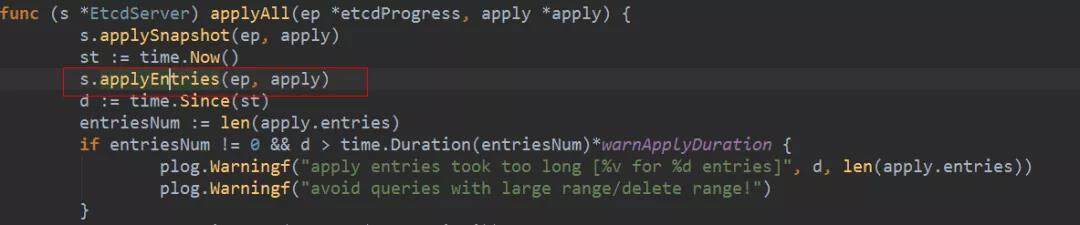
所有节点,包括 follower 和 leader 都会将已经认定为 commit 的日志 apply 到 kv 存储中。对于 v2 就是更新 store 中的树节点。对于 v3 就是调用 boltdb 的接口更新数据。
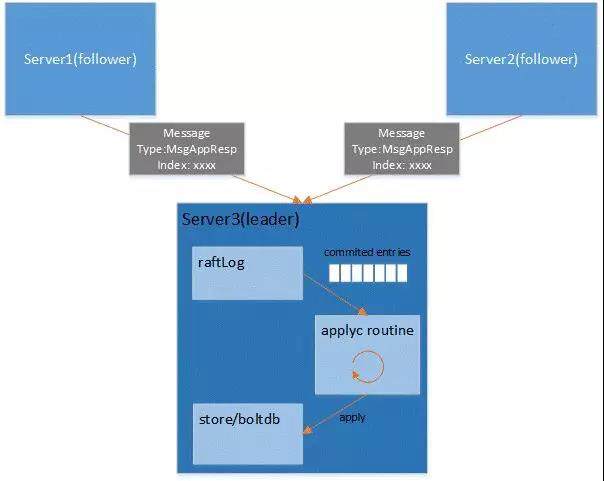
7. 日志条目到一定数目以后,会触发 snapshot,leader 会持久化保存第 6 步所说的 kv 存储的数据。然后删除内存中过期的日志条目。
8. WAL 中保存的持久化的日志条目会有一个定时任务定时删除。
以下将以 v3 代码为例,详细分析以上过程。
4. 日志的生成
v3 操作 etcd 一般是直接使用 etcd 提供的 client 库,因为 v3 的 client 和 server 也采用 grpc 通信,直接用 httpclient 会非常复杂。Client 结构中包含了一个叫 KV 的接口,里面定义了 Put、Get、Delete 等方法。Put 方法的实现实际就是向其中一个 server 发送一条 grpc 请求,请求体正是 PutRequest 结构的对象。
服务端收到 gprc 请求以后,会调用 EtcdServer 的 Put()、Range()、DeleteRange()、Txn()等方法,这些方法最终都会调用到 processInternalRaftRequestOnce(),这个方法的处理是先用 request 的 id 注册一个 channel,调用 raftNode 的 Propose()方法,将 request 对象序列化成 byte 数组,作为参数传入 Propose()方法,最后等待刚刚注册的 channel 上的数据,node 会在请求已经 apply 到状态机以后,也就是请求处理结束以后,往这个 channel 推送一个 ApplyResult 对象,触发等待它的请求处理协程继续往下走,返回请求结果。
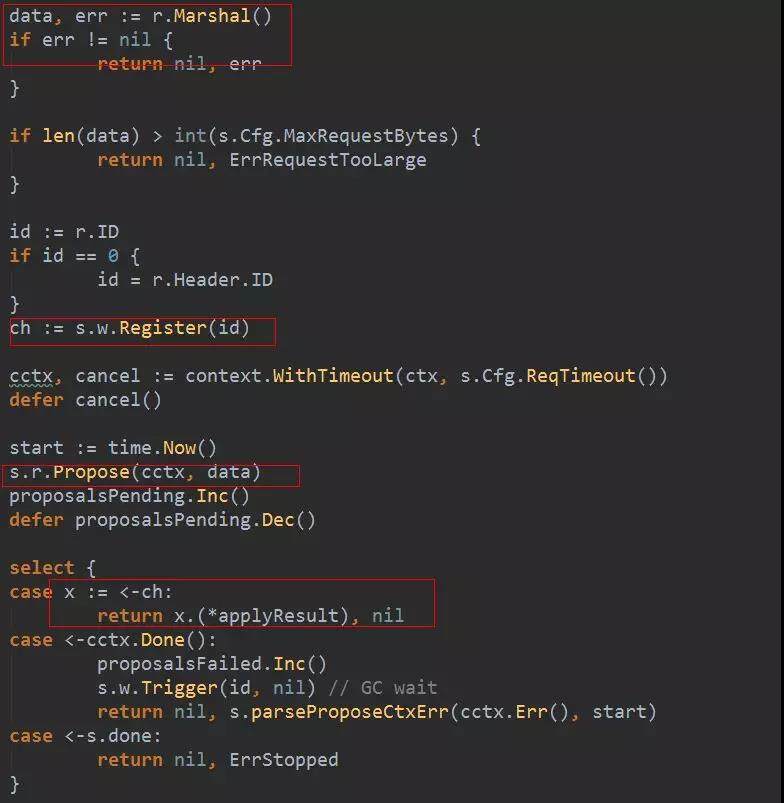
raftNode 的 Propose 方法实现在 node 结构上。它会生成一条 MsgProp 消息,消息的 Data 字段是已经序列化的 request。也就是说 v3 中,日志条目的内容就是 request。最后调用 step()方法,是把消息推到 propc channel 中。
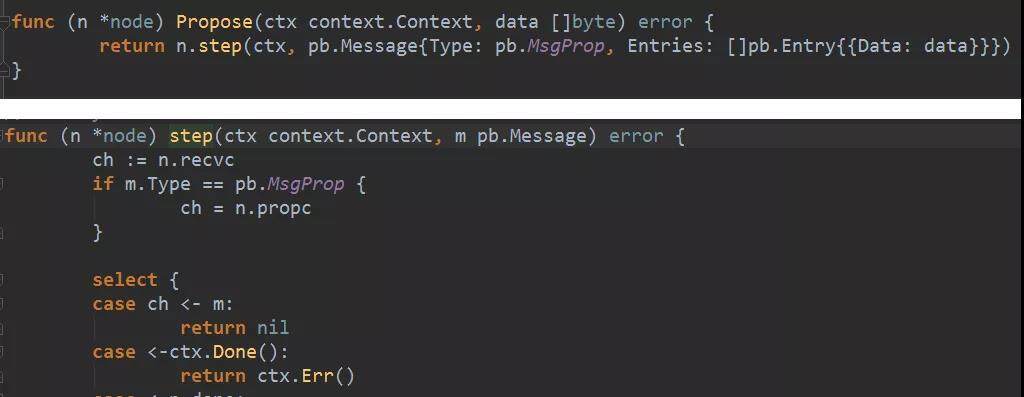
4. propc channel 由 node 启动时运行的一个协程处理,调用 raft 的 Step()方法,如果当前节点是 follower,实际就是调用 stepFollower()。而 stepFollower 对 MsgProp 消息的处理就是:直接转发给 leader。
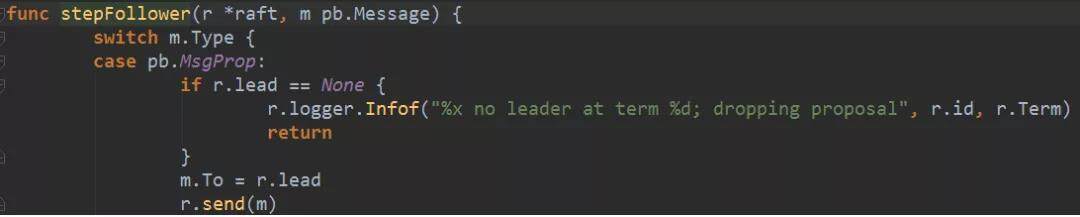
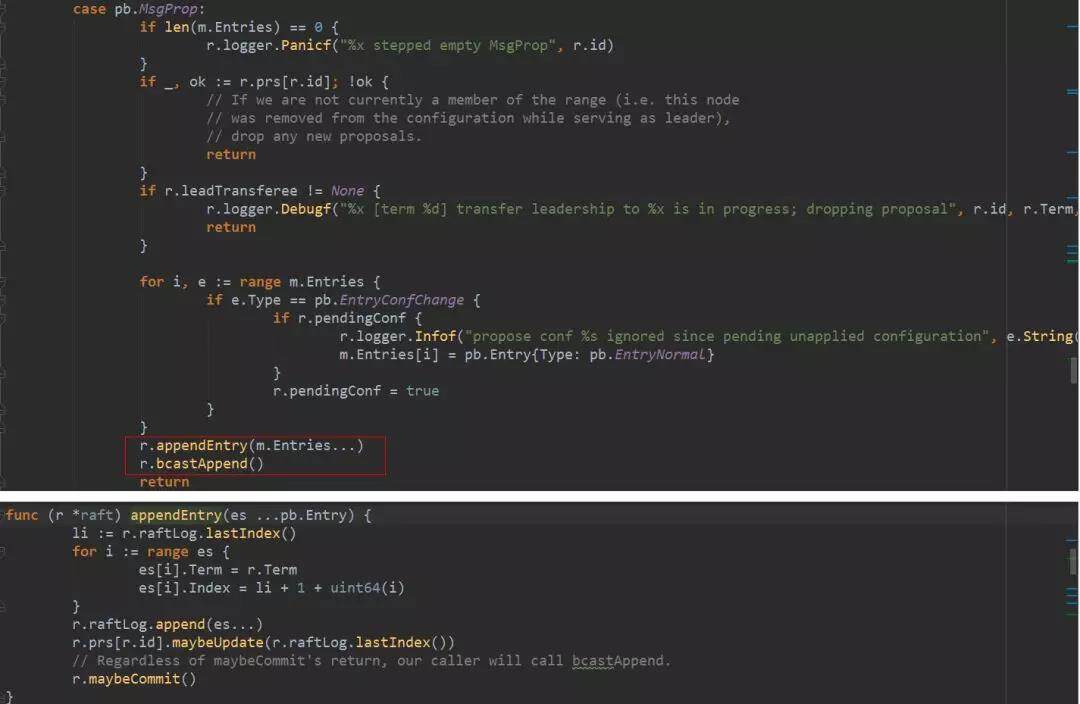
实例之间消息发送的过程在本系列文章的第二篇《心跳与选举》中已经介绍,不再赘述。消息到 leader 以后。下图是 leader 的处理,leader 在接收到 MsgProp 消息以后,会调用 appendEntries()将日志 append 到 raftLog 中。这时候日志已经保存到了 leader 的缓存中。
-
5. leader 同步日志
从上图可以看到,leader 在 append 日志以后会调用 bcastAppend()广播日志给所有其他节点。raft 结构中有一个 Progress 数组,这个数组是 leader 用来保存各个 follower 当前的同步状态的,由于不同实例运行的硬件环境、网络等条件不同,各 follower 同步日志的快慢不一样,因此 leader 会在本地记录每个 follower 当前同步到哪了,才能在每次同步日志的时候知道需要发送那些日志过去。Progress 中有一个 Match 字段,代表其中一个 follower 当前已经同步过的最新的 index。而 Next 字段是需要 leader 发送给它的下一条日志的 index。
sendAppend 先根据 Progress 中的 Next 字段获取前一条日志的 term,这个是为了给 follower 校验用的,待会我们会讲到。然后获取本地的日志条目到 ents。获取的时候是从 Next 字段开始往后取,直到达到单条消息承载的最大日志条数(如果没有达到最大日志条数,就取到最新的日志结束,细节可以看 raftLog 的 entries 方法)。
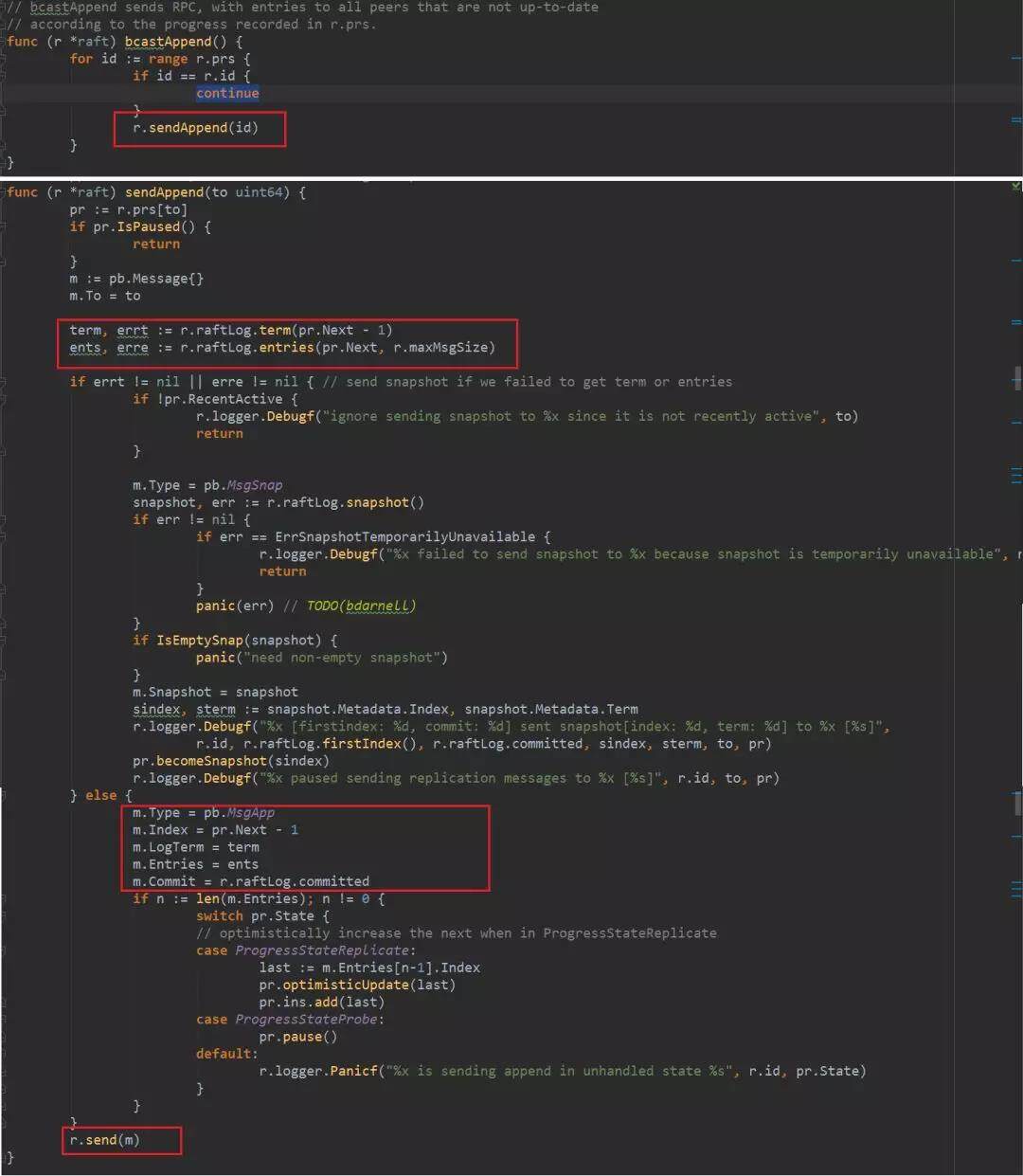
如果获取日志有问题,说明 Next 字段标示的日志可能已经过期,需要同步 snapshot,这个就是上图的 if 语句里面的内容。这部分我们等 snapshot 的时候再细讲。
正常获取到日志以后,就把日志塞到 Message 的 Entries 字段中,Message 的 Type 为 MsgApp,表示这是一条同步日志的消息。Index 设置为 Next-1,和 LogTerm 一样,都是为了给 follower 校验用的,下面会详细讲述。设置 commit 为 raftLog 的 commited 字段,这个是给 follower 设置它的本地缓存里面的 commited 用的。最后的那个"switch pr.State"是一个优化措施,它在 send 之前就将 pr 的 Next 值设置为准备发送的日志的最大 index+1。意思是我还没有发出去,就认为它发完了,后面比如 leader 接收到 heartbeat response 以后也可以直接发送 entries。
follower 接收到 MsgApp 以后会调用 handleAppendEntries()方法处理。处理逻辑是:如果 index 小于已经确认为 commited 的 index,说明这些日志已经过期了,则直接回复 commited 的 index。否则,调用 maybeAppend()把日志 append 到 raftLog 里面。maybeAppend 的处理比较重要。首先它通过判断消息中的 Index 和 LogTerm 来判断发来的这批日志的前一条日志和本地存的是不是一样,如果不一样,说明 leader 和 follower 的日志在 Index 这个地方就没有对上号了,直接返回不能 append。如果是一样的,再进去判断发来的日志里面有没有和本地有冲突(有可能有些日志前面已经发过来同步过,所以会出现 leader 发来的日志已经在 follower 这里存了)。如果有冲突,就从第一个冲突的地方开始覆盖本地的日志。
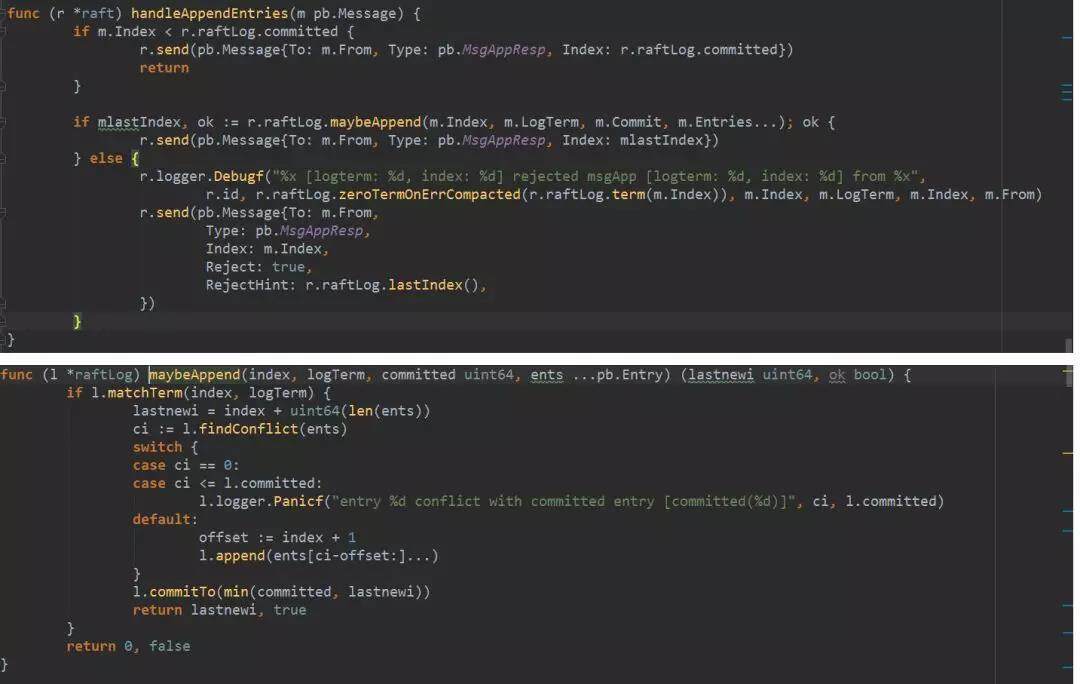
5. follower 调用完 maybeAppend 以后会调用 send 发送 MsgAppResp,把当前已经 append 的日志最新 index 告诉给 leader。如果是 maybeAppend 返回了 false 说明不能 append,会回复 Reject 消息给 leader。消息和日志最后都是在 raftNode.start()启动的协程里面处理的。它会先持久化日志,然后发送消息。
follower 调用完 maybeAppend 以后会调用 send 发送 MsgAppResp,把当前已经 append 的日志最新 index 告诉给 leader。如果是 maybeAppend 返回了 false 说明不能 append,会回复 Reject 消息给 leader。消息和日志最后都是在 raftNode.start()启动的协程里面处理的。它会先持久化日志,然后发送消息。
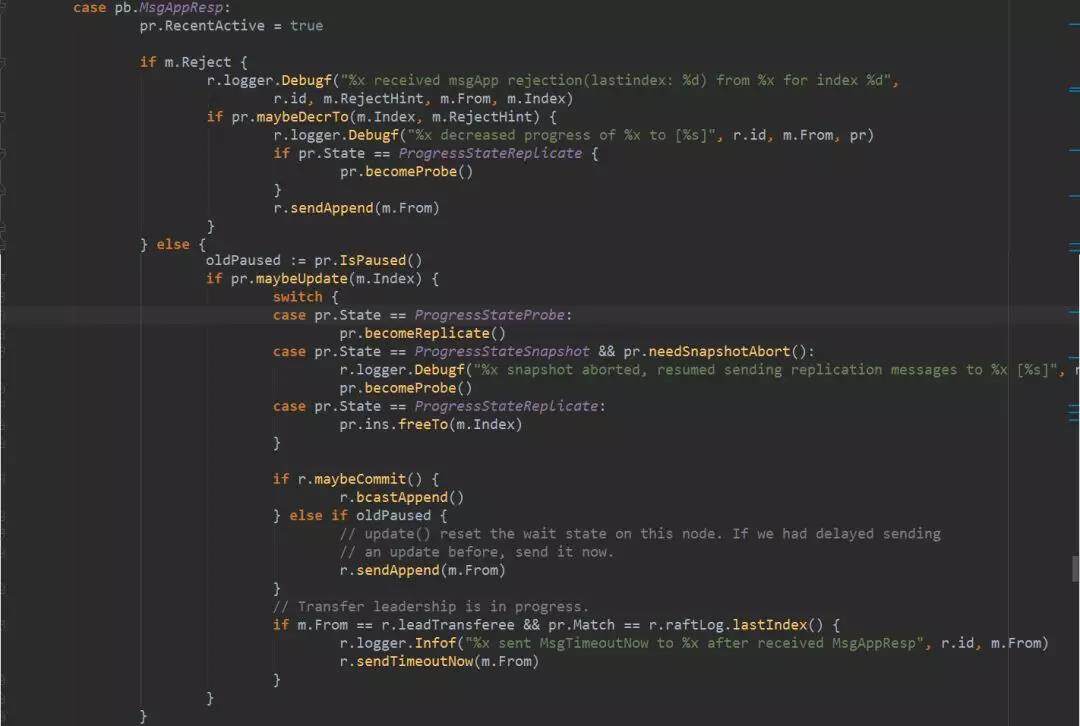
leader 收到 follower 回复的 MsgAppResp 以后,首先判断如果 follower reject 了日志,就把 Progress 的 Next 减回到 Match+1,从已经确定同步的日志开始从新发送日志。如果没有 reject 日志,就用刚刚已经发送的日志 index 更新 Progess 的 Match 和 Next,下一次发送日志就可以从新的 Next 开始了。然后调用 maybeCommit 把多数节点同步的日志设置为 commited。
commited 会随着 MsgHeartbeat 或者 MsgApp 同步给 follower。随后 leader 和 follower 都会将 commited 的日志 apply 到状态机中,也就是会更新 kv 存储。
6. 持久化
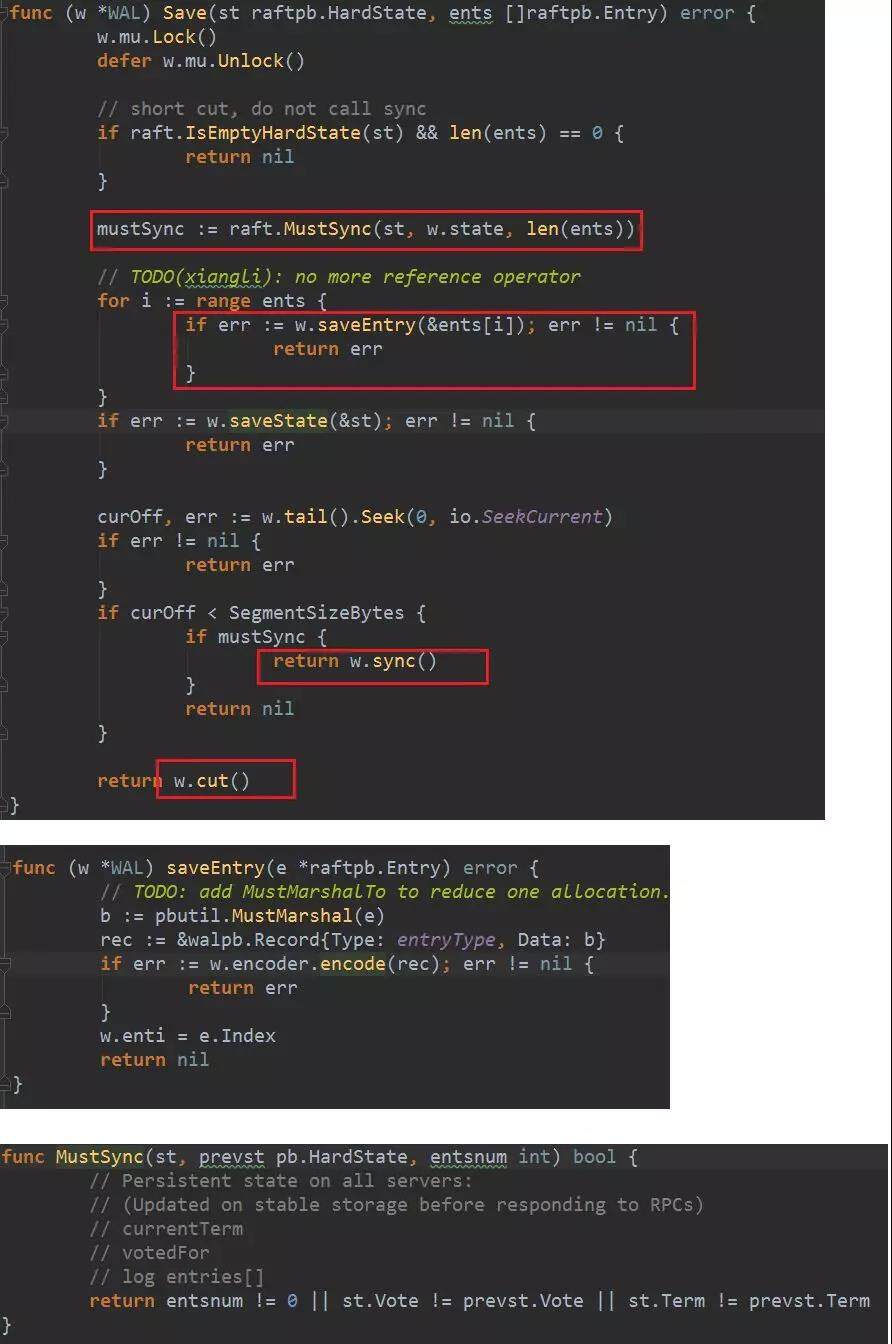
日志的持久化是调用 WAL 的 Save 完成的,同时如果有 raft 状态变更也会写到 WAL 中(作为 stateType)。日志会顺序地写入文件。同时使用 MustSync 判断是不是要调用操作系统的系统调用 fsync,fsync 是一次真正的 io 调用。从 MustSync 函数可以看到,只要有 log 条目,或者 raft 状态有变更,都会调用 fsync 持久化。最后我们看到如果写得太多超过了一个段大小的话(一个段是 64MB,就是 wal 一个文件的大小)。会调用 cut()拆分文件。
本文转载自华为云产品与解决方案公众号。
原文链接:https://mp.weixin.qq.com/s/o_g5z77VZbImgTqjNBSktA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论