
近日,AI 顶会 ICLR 2025 在新加坡举行,阿里巴巴达摩院共有 13 篇论文被大会收录,其中一篇聚焦于视觉生成模型底层框架 DiT 的改进优化。达摩院提出了创新架构 DyDiT,通过引入动态化调整机制,可精准削减视觉生成任务中 50%的推理算力,有效缓解传统扩散模型的计算冗余问题,相关工作已开源。
为什么会开源这样一款框架?
过去一年来,由 Sora 模型开始推动的 Diffusion Transformer(DiT)架构在视觉生成领域展现出了强大的能力,得到了包括 Stable Diffusion 3、Flux、Sora、WanX、Movie Gen 等众多视觉模型的应用。但 DiT 架构也面临一些重大挑战,其中最显著的就是运行效率问题。
业内提出了多种方法来解决这一问题,包括高效的 diffusion 采样器、特征缓存、注意力机制以及模型压缩剪枝等。但这些方法都是针对静态不变模型,即图像生成过程使用的模型规模完全不变,导致了潜在的冗余浪费问题。
所以达摩院研究团队提出了名为 Dynamic Diffusion Transformer 的新方法。该方法从 timestep 和空间两个级别入手,根据不同 timestep 和图像复杂度所需的计算量来调整模型计算大小,从而降低计算冗余度,同时基本保持输出效果,实现较好的性能提升。
论文链接:https://arxiv.org/abs/2410.03456
代码仓库:https://github.com/alibaba-damo-academy/DyDiT
DiT 架构作为当前主流的生成模型框架,有效实现了图像与视频的可控生成,推动生成式 AI 走向应用爆发。然而,DiT 架构的多步生成策略存在推理效率低、算力冗余等问题,在执行视觉生成任务容易造成极高的算力消耗,限制其往更广泛的场景落地。业内提出高效采样、特征缓存、模型压缩剪枝等方法尝试解决这一问题,但这些方法均针对静态不变模型,又衍生出潜在的冗余浪费问题。
像在其他视觉和语言领域中的 Transformer 模型一样,Diffusion Transformer 也面临显著的生成效率问题。然而,与 ViT 或 LLMs 不同,Diffusion Transformer 中的多时间步生成范式本质上引入了额外的计算复杂性。此外,生成任务通常在空间区域上呈现出不平衡的难度,从而进一步加剧了效率问题。
为了提升 Diffusion Transformer 的推理效率。许多高效采样器和免训练加速技术在过去几年被提出,可以无缝地加入 Diffusion Transformer 来提升效率。同时,与这些技术相正交方案是结合传统的模型压缩技术,例如结构化剪枝,来降低 Diffusion Transformer 的推理开销。然而,剪枝方法通常在整个扩散过程中的时间步和空间维度上保留一个静态的架构。
如下图所示,原始 Diffusion Transformer 和剪枝后的 Diffusion Transformer 都在所有扩散时间步中使用固定的模型宽度,并对每个图像块分配相同的计算成本。这种静态推理范式忽略了不同时间步和空间区域所具有的不同复杂性,导致了显著的效率问题。
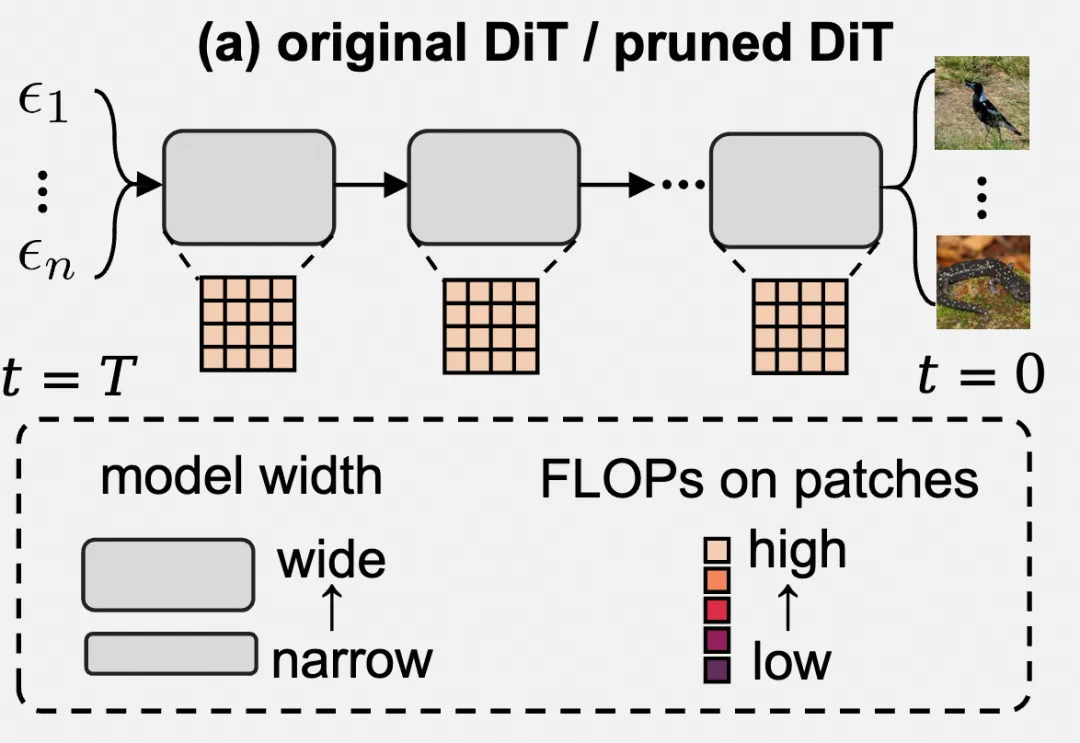
探索 Diffusion Transformer 的冗余问题
在研究新的 Diffusion Transformer 方法之前,首先要研究 Diffusion Transformer 架构中的冗余问题有多大。这里分别从两方面来研究:
第一个实验从 timestep 角度入手,对比经过预训练的一个小模型(DiT-S)与大模型(DiT-XL)在 ImageNet 上不同 timestep 上的损失差异,将它们的差值画成曲线:
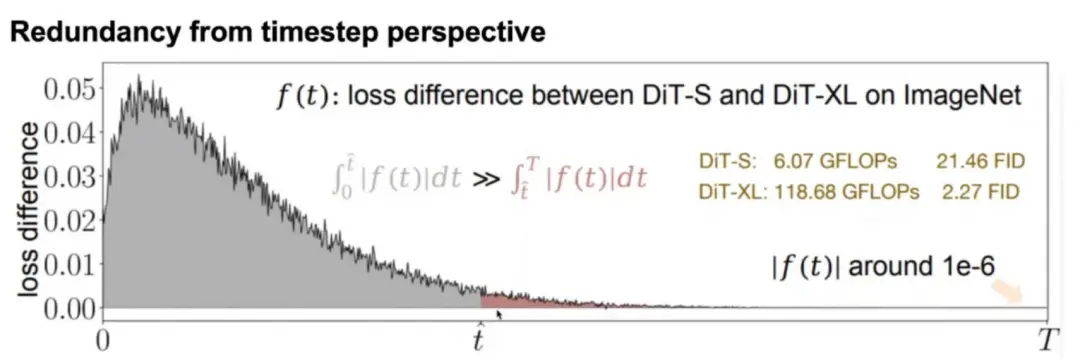
结果发现,T 较大(生成过程中趋于噪声)时差值较小,而 T 较小(生成过程中接近真实图像)时差值较大。这说明不同的 timestep 对应的任务预测难度是不同的,趋于噪声时小模型就能很好地处理,接近真实图像时就需要大模型。但如果一直使用大模型,就会在 T 较大时造成计算冗余。
第二个实验从空间角度入手。这里可视化了模型在不同 timestep 上的损失 map:
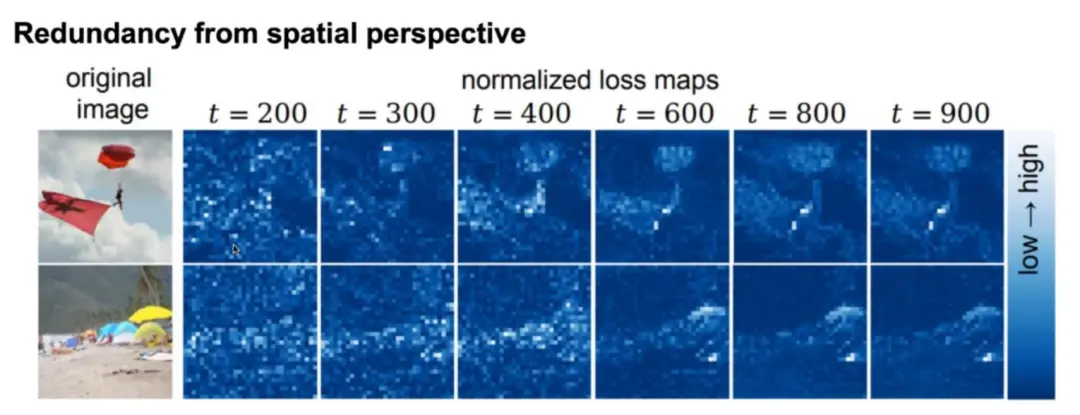
如图所示,白色区域的损失较高,蓝色区域损失较低。可以看到图像不同区域的预测难度是不同的,诸如沙滩、天空等特征接近的区域预测难度较低,而人物、物体等区域预测难度较高。显然,如果对所有区域都使用较大的模型预测,在低难度区域就会带来计算冗余。
在最近的工作中,研究团队还将 Dynamic Diffusion Transformer 进行了进一步的升级。主要包括三个部分:
1、验证对于 flow-matching(流匹配)的支持。flow-matching 的生成机制目前也应用在主流的生成模型中,研究团队验证了我们方法可以无缝衔接到其中。
2、扩展对模型的支持。目前视频生成模型和文本到图像生成模型在实际应用中十分广泛。研究团队将方法进行针对性的升级,实现对主流生成模型,例如 FLUX 的兼容,使其达到了更好的性能效率平衡。
3、提出了为 Dynamic Diffusion Transformer 专门设计的高效微调机制。降低了 Dynamic Diffusion Transformer 的训练参数量,显著降低显存占用。
团队基于上述研究提出了 Dynamic Diffusion Transformer 动态 diffusion transformer 模型架构。该架构的动态性表现在 timestep 和空间两个层面:
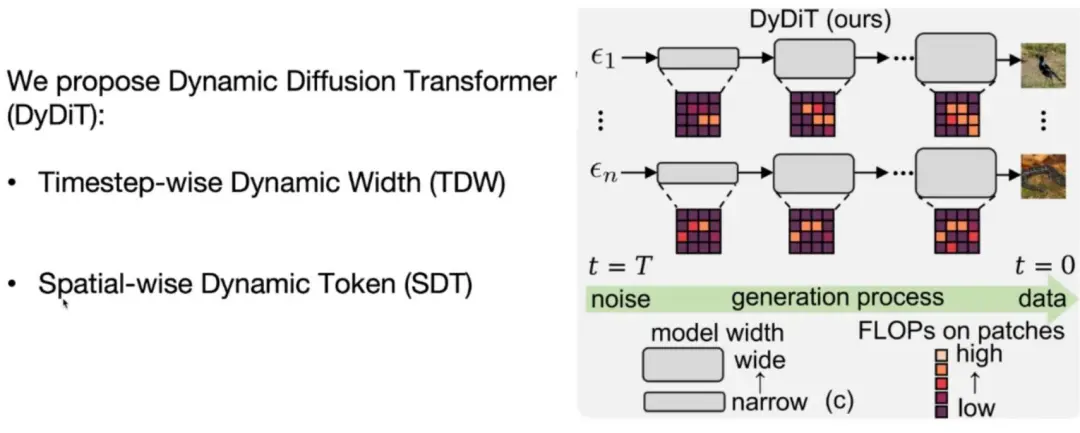
如图所示,该模型在生成过程中的不同步骤和不同图像复杂度上的模型大小是不一样的,从而尽可能降低计算冗余度。
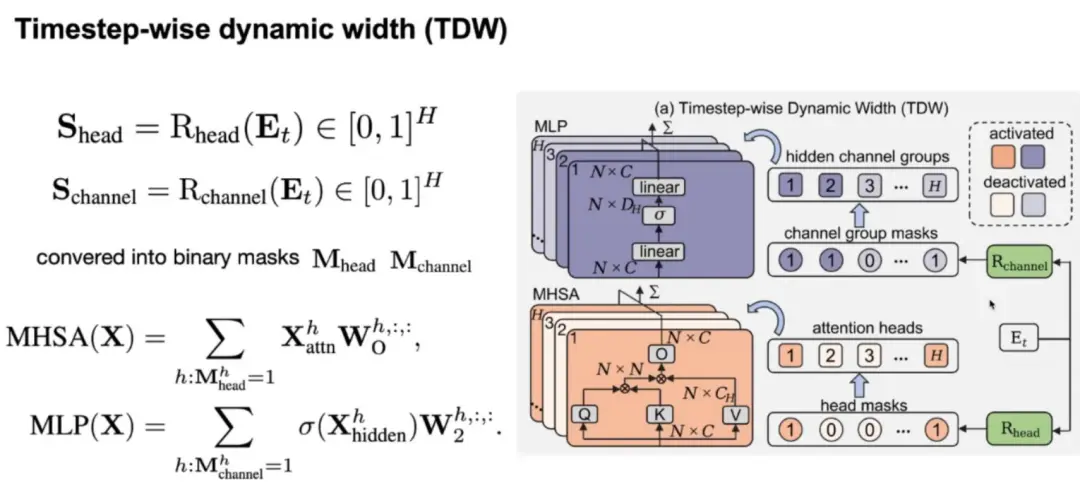
Timestep 级别的动态性(TDW)
在 Diffusion Transformer 工作期间,timestep 信息 Et 是嵌入生成流程的,从而让模型知道自己当前处于哪一步。为实现 TDW,可以将 Et 输入两个 Rooter 中,分别是 Rchannel 和 Rhead。它们分别会学习每一步骤需要激活哪些 channel 或 head。根据 Rooter 的计算结果,模型就可以在每一步舍弃不需要计算的 head 和 channel 了。这里的 MHSA 为多头自注意力机制,MLP 为多层感知机。每一个 Router 可以通过一层线性层来实现。
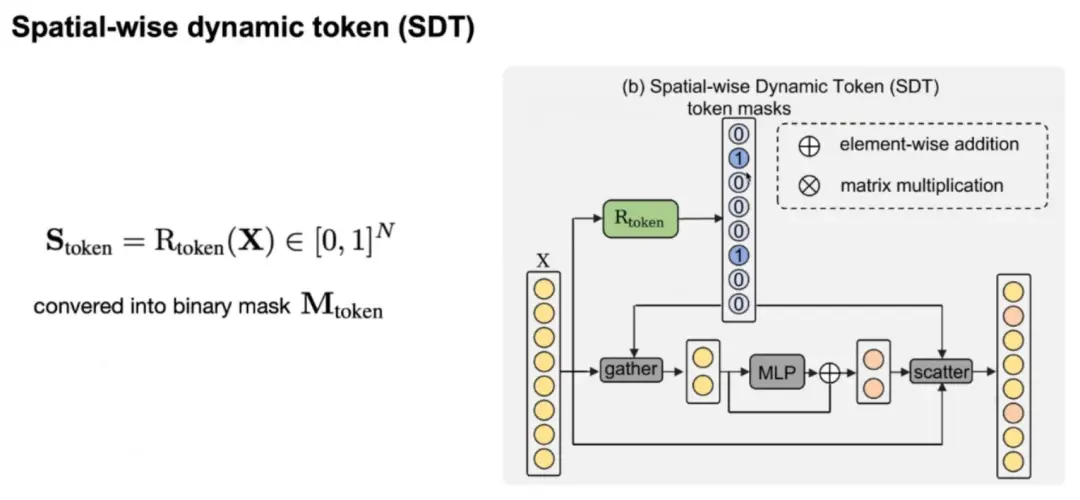
空间级别的动态性(SDT)
在空间级别,同样需要引入一个 Rooter(Rtoken)来预测每帧图片输入 token 中需要计算的部分,得到一个 token mask,mask 的值为 0 代表该 token 不需要计算,而 mask 的值为 1 代表该 token 需要计算。随后我们可以根据 mask 使用 gather 操作将那些需要计算的 token 取出输入到 MLP 中计算,随后再使用 scatter 操作将计算结果与原始输入合并。 这里研究团队只针对 MLP 使用 SDT 而不针对 MHSA 的原因是,研究团队发现对 MHSA 进行这个操作会对性能影响较大,另外 MHSA 有很多基于稀疏注意力的改进方案,可以即插即用,所以这里不对 MHSA 做这个操作。
根据计算量节约目标调整训练过程
上述两个方法都存在一个 Mask,可以利用这些 Mask 计算网络当前的整体计算量,再计算原始 Diffusion Transformer 的计算量,对比两个计算量的比值就可以得到动态模型计算量的节约程度:

通过调节上述公式中的 λ 为我们预期的计算量比值,例如 0.5,与原始的 DiT loss 进行训练,模型就可以学习到如何在保证性能的前提下,让计算量符合预期。
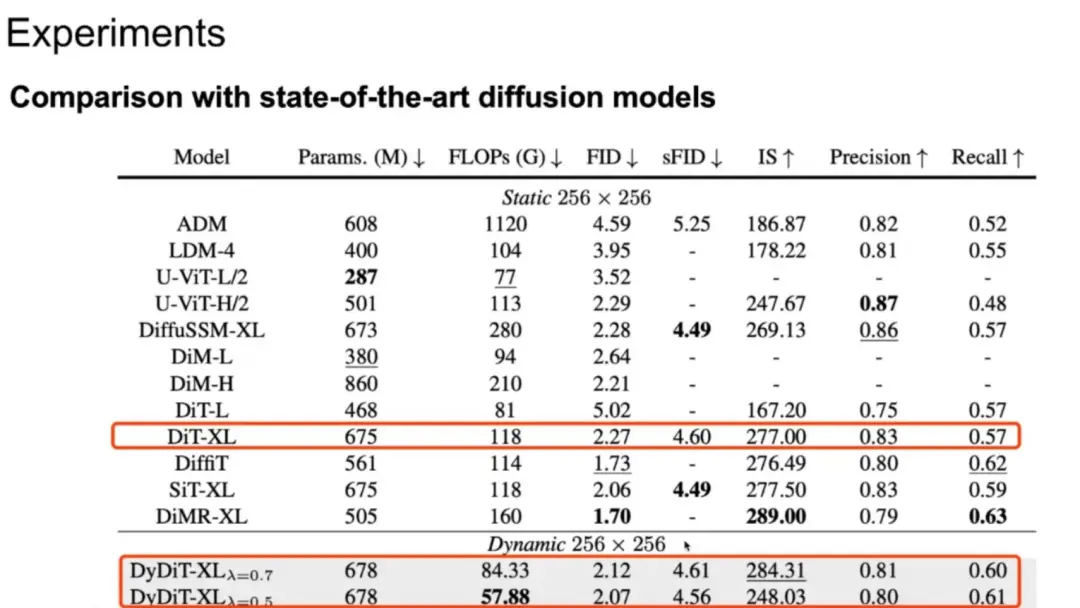
性能表现
对比发现,将 DiT-XL 模型改进为 DyDiT-XL 动态架构后,模型计算量有了明显下降,同时 FID 得分与原模型基本相当。与其他生成模型对比,动态模型的计算量是最低的,各类指标都有一些优势。
团队也探索了动态架构在不同模型大小上的 Scaling up 能力:
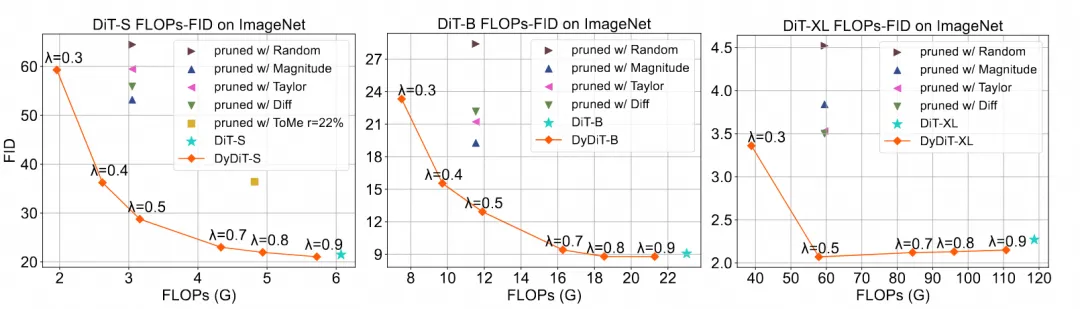
可以看到在较小模型(DiT-S)上,在基本维持输出效果的前提下可以节约的模型计算量是较小的(λ 需设置为 0.9);而在中等模型(DiT-B)上 λ 可以设置为 0.7,较大模型(DiT-XL)上 λ 可以设置为 0.5,节约的计算量较多。这也表明随着模型增大,计算量的冗余度也随之提升。
团队还可视化了不同 timestep 时动态模型激活 head 和 channel 的情况,当接近噪声端时,任务预测难度较小,需要激活的模型资源较少:
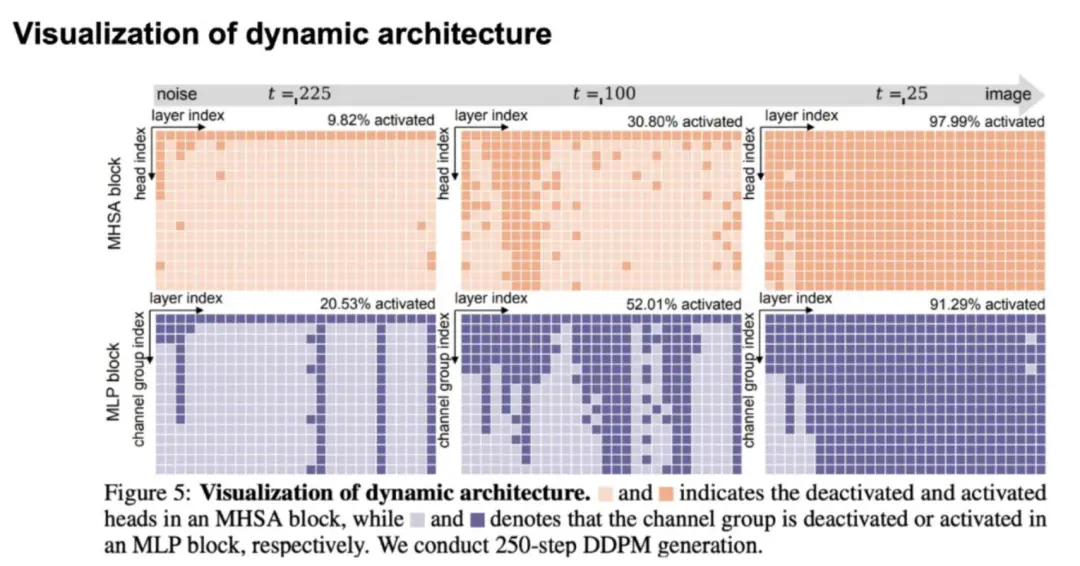
团队也可视化了不同图像区域需要的计算量差异,可以看到简单背景/物体所需的计算量较少:

动态方法也可以同其他加速方法,如高效采样器、DeepCache 等方案结合进一步提升性能:
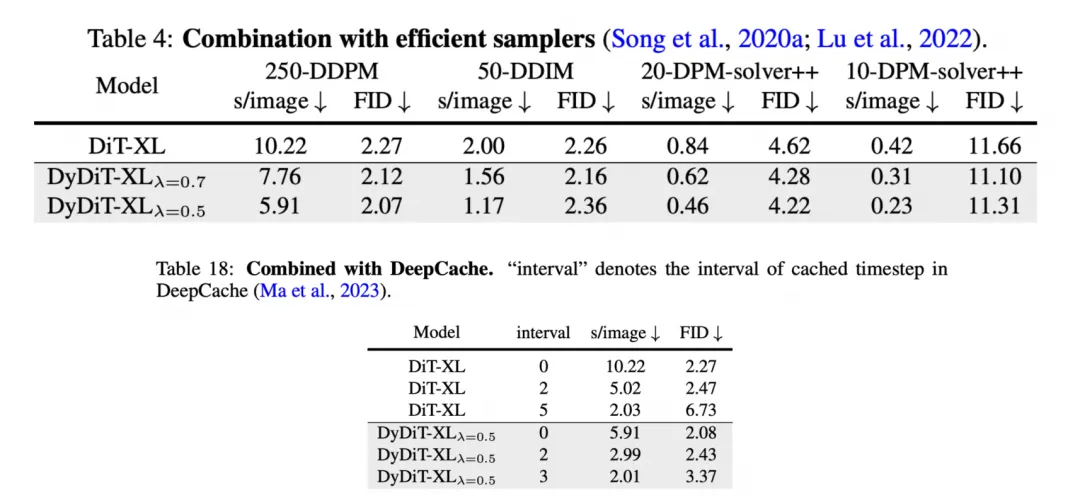
实验结果表明,DyDiT 在多个数据集和生成模型下均表现出高稳定性。仅用不到 3%的微调成本,将 DiT-XL 的浮点运算次数(FLOPs)减少了 51%,生成速度提高了 1.73 倍,在 ImageNet 测得的 FID 得分与原模型几乎相当(2.27 vs 2.07)。据透露,DyDiT 相关训练与推理代码已开源,并计划适配到更多的文生图、文生视频模型上,目前基于知名文生图模型 FLUX 调试的 Dy-FLUX 也在开源项目上架。
ICLR 是由图灵奖得主杨立昆、约书亚·本吉奥发起的 AI 顶级会议。据悉,达摩院今年共有 13 篇论文被 ICLR 2025 录用,涵盖了视频生成、自然语言处理、医疗 AI、基因智能等领域,其中 3 篇被选为 Spotlight。




