
1. 概述
H.266/VVC 的帧内预测 ( Intra Prediction ) 技术主要包括以下几个方面的改进和新工具 [1][2] :
67 个帧内预测模式,包含了广角 ( Wide Angle ) 模式扩展
块大小和模式相关的 4 头内插滤波器
位置相关的组合帧内预测技术( Position Dependent intra Prediction Combination PDPC )
跨亮度色度的线性模型帧内预测技术( Cross Component Linear Model intra prediction CCLM )
多参考行帧内预测技术( Multiple Reference Line intra prediction MRL )
帧内预测子块划分技术( Intra Sub-Partition ISP )
矩阵加权平均的帧内预测技术( Matrix weighted Intra Prediction MIP )
在 VVC 标准中,各个新加的编码工具的详细的 tool-off 测试编码增益性能汇总在 AHG 13 每次JVET 会议的报告中 [3] 。这里按各编码工具在编码过程中的大致技术类别做了一个简单的归类。(最新 VTM 10 的测试数据和这里提供的 VTM 9 的数据基本相同 [3] 。)
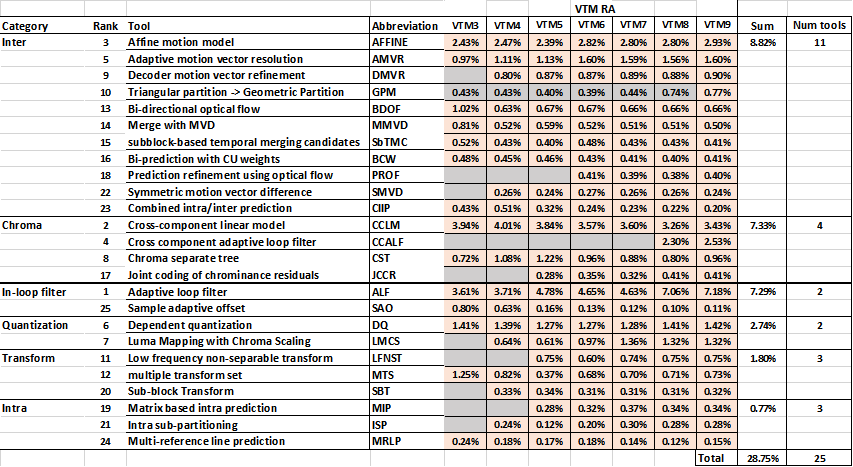
上表整理自 [3]
下面我们来逐一看下这些新的 VVC 帧内预测的技术改进和工具。
2. 67 个帧内预测模式
VVC 中将基于角度的方向性帧内预测模式,由 HEVC 中的 33 个增加扩展到了 65 个。再加上原有的 DC (直流平均), Planar (平面加权平均)模式,一共就是 67 个预测模式。
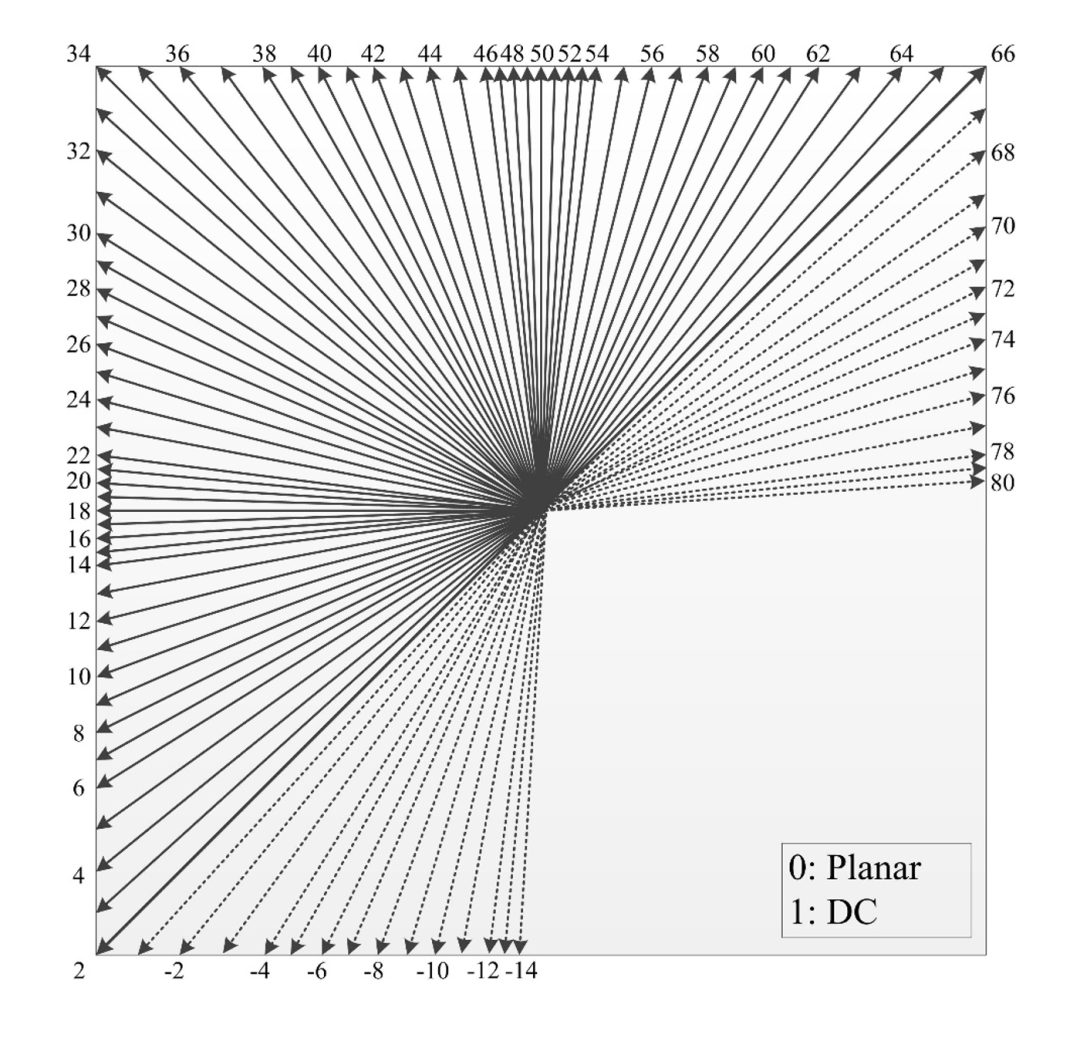
上图、表来自 [1]
除此之外,模式 -14~-1 , 67~80 则代表了针对长方形 CU ( Coding Unit ) 块的大角度(即广角)帧内预测模式。
2.1 传令语法
VVC 帧内预测模式的传令 ( signalling ) 语法如下:

上表来自 [1]
基本上是先判断所传帧内预测模式是否是 MIP 模式,再依次判断是否 MRL, ISP 模式,然后是传 MPM ( Most Probable Modes ) 的 5 个候选模式之一的 Index ,最后如果所传模式不在这 5 个候选 MPM 中,则继续传 MPM Remainder 来表征最一般性的 Intra Prediction Mode 。
色度的 Intra Prediction Mode 传令语法是:
先判断,如果是 MipChromaDirect 模式:即 Single-Tree , 4:4:4 , 且 intra_chroma_pred_mode = 4 , 这种情况下的 MIP 模式就会使用 Collocated Luma Intra Mode (同位置对应的亮度块的 Intra Mode )作为 lumaIntraPredMode 。
否则,就将块中心点对应的同位置 Luma 块的 Intra Mode 作为 lumaIntraPredMode,除非:如果是 MIP 模式,则 lumaIntraPredMode 设为 Planar 模式。如果是 IBC ( Intra Block Copy ) 或 Palette (调色板)模式,则将 lumaIntraPredMode 设为 DC 模式。
然后,根据 lumaIntraPredMode ,按下表的对应关系推导出当前块的 Chroma Intra Pred Mode :
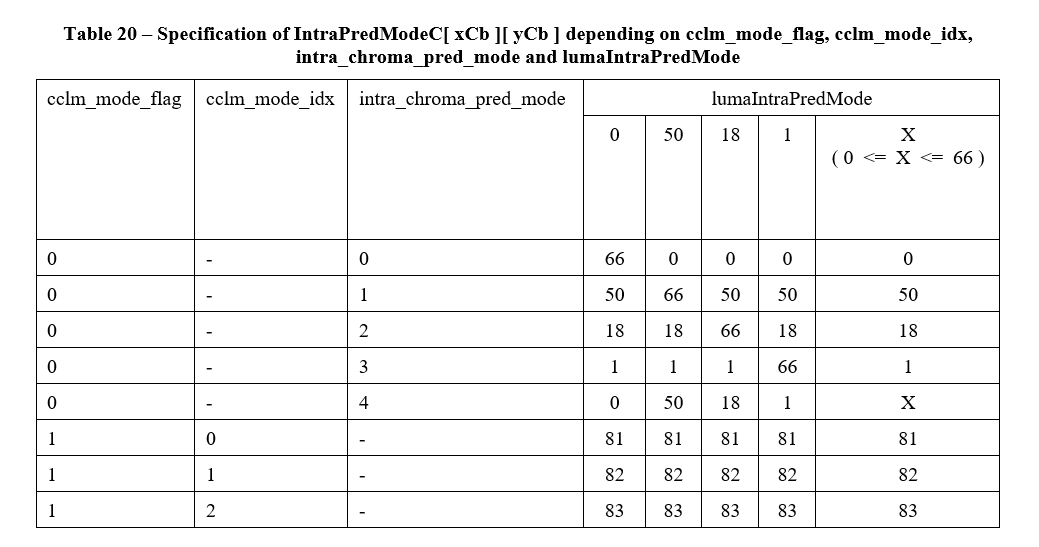
上表来自 [1]
2.2 针对长方形块的广角模式
通常的 Mode 2 ( 45° 预测) 到 Mode 67 ( ﹣135° 预测) 范围主要针对的是正方形的 CU 块。对于长方形的块,如果还是按照同样的 45°~﹣135° 的预测范围,那么对 45° 或 ﹣135° 附近的一些预测角度,其对应的参考样本会超过通常的 ( 2W + 1 ) 或( 2H + 1 ) ( W, H 为块的宽和长的样本数)参考样本范围,同时这些超出范围的参考样本到当前样本的预测距离也会比较长,从而降低了预测性能。
为了保持同样的长宽方向 ( 2W + 1 ) 或( 2H + 1 )的参考样本,同时减少超范围参考样本导致的较长预测距离,从而提高预测性能, VVC 里针对长方形块引入了广角预测模式:对那些对应正方形块 45° 或 ﹣135° 附近的预测角度,用在当前长方形快上会导致超出原有 ( 2W + 1 ) 或( 2H + 1 ) 的参考样本范围的,会把这个模式重新映射成同一预测角度延长线上利用另一侧(或宽边或长边)的参考样本的反向预测角度。即 predModeIntra 的传令方式不变,如果发现当前 CU 是符合上述条件的长方形块,会自适应地将 predModeIntra 转换一下,变成模式 -14~-1 , 67~80 之中的一个代表了针对长方形 CU 块的大角度帧内预测模式。如下图所示。
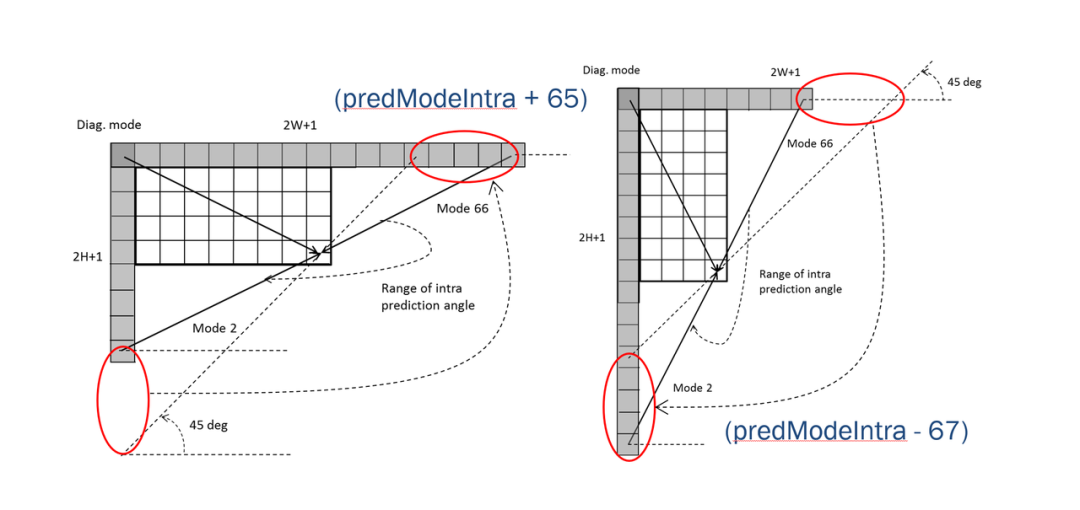
上图来自 [2]
3. 模式相关的帧内预测平滑 ( Mode Dependent Intra Smoothing MDIS )
在一些情况下,对帧内预测利用的重建参考样本做一定程度的滤波,会提升预测性能。这一技术在 HEVC 中已有应用, VVC 中则将这一技术进行了进一步的优化和细化。
针对亮度参考样本的平滑滤波:
对 Mode 0 ( Planar ), Mode 2 , 34 , 66 ( Diagonal Bottom-Left, Top-Left, Top-Right ), 非分数参考样本位置的广角模式 ( Mode -14 , -12 , -10 , -6 , 72 , 76 , 78 , 80 ), 且如果不是 MRL 或 ISP 模式, CU 总样本数 > 32 ,那么对其亮度帧内预测参考样本会做系数为 { 1/4 , 2/4 , 1/4 } 的 3 -头滤波器平滑滤波。
针对分数参考样本的内插滤波:
否则,如果不是 MRL 或 ISP 模式:继续根据定义的 MDIS 条件来判断是否预测角度接近水平或竖直。如果判断为接近,对分数位置的参考样本就会使用 4 头的内插滤波器,主要做内插,平滑作用较小。否则如果角度偏离水平,竖直较远,对分数位置的参考样本就会使用 4 头的高斯平滑滤波器,平滑作用较大。
其中,MDIS 条件定义如下 [1] :

上表及相关内容来自 [1]
4 头内插和高斯滤波器的定义如下(部分)[1] :
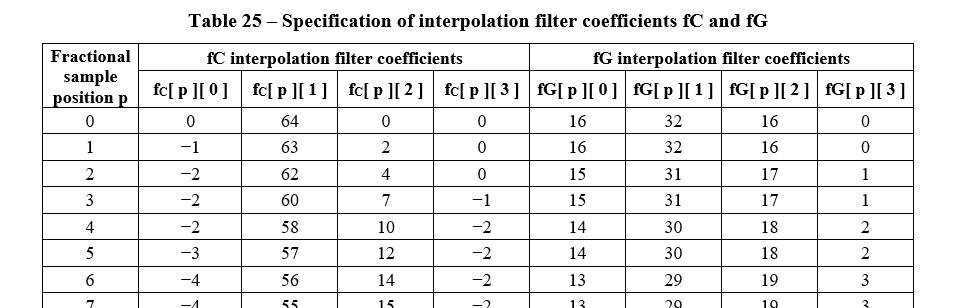
上表及相关内容来自 [1]
4. 跨亮度色度的线性模型预测 ( Cross-Component Linear Model CCLM )
VVC 中引入了通过亮度重建信息帧内预测色度信号的新的 CCLM 模式,这一模式采用了简单的线性模型进行预测。
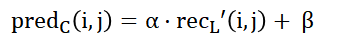
其中, recL′(i,j)rec_{L}\prime(i,j)recL′(i,j) 是下采样后的亮度重建样本 [2] 。
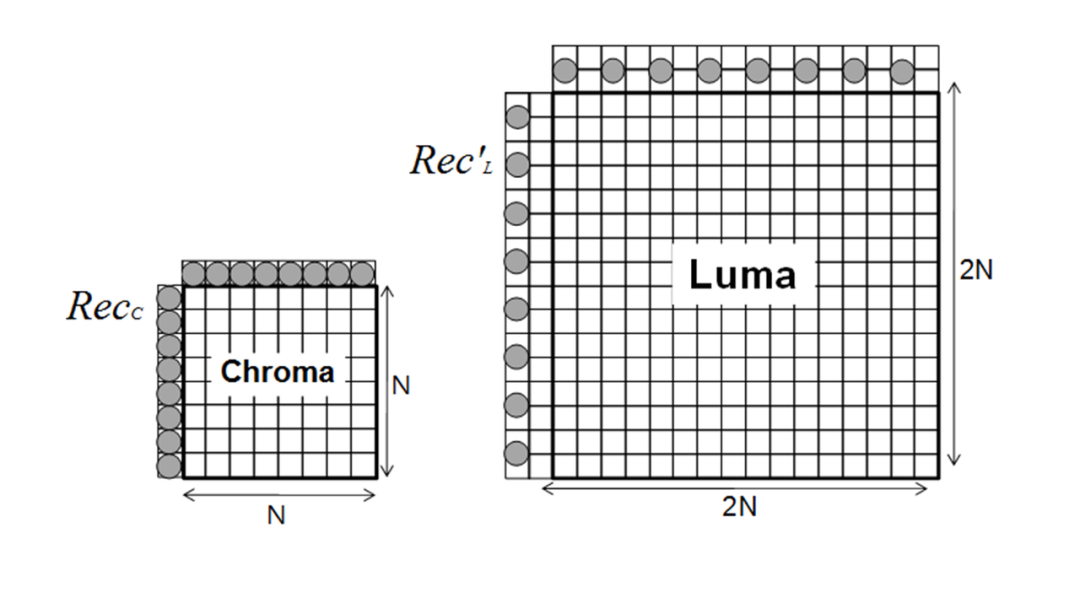
上图来自 [2]
首先,在或者上边,或者左边的下采样亮度重建样本中选取 4 个近邻样本,在该边的位置为 { 1/8 , 3/8 , 5/8, 7/8 } 处, 或者分别从上边和左边各选取两个近邻样本,在各边的位置为 { 1/4 , 3/4 } 处。
然后,将这 4 个亮度参考样本排序为两个较小值组( minY1 , minY2 ) 和两个较大值组 ( maxY1 , maxY2 ),结合其各自样本对应位置的色度重建参考样本的做同样排序后的较小,较大值组 ( minC1 , minC2 ), ( maxC1 , maxC2 ), 各组取平均得到( minY , maxY ), ( minC , maxC )。
通过以下简单线性模型的推导公式即可算出模型参数 α 和 β :
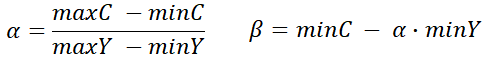
其中, 只从上边,或者左边选 4 个亮度样本,或从上边,左边各选两个亮度样本的三种方法,就是 CCLM 的三种不同模式 LM-A , LM-L , LM 。定义如下 [2] :

上图来自 [2]
5. 帧内预测子块划分 ( Intra Sub-Partitions ISP )
VVC 中的帧内预测引入了子块划分技术,即可以把做帧内预测的块做更小的子块划分,依次重建,这样后面的子块就可以利用前面重建的子块进行更准确的帧内预测。在 VVC 中,各子块要么全是是水平,要么全是垂直划分,并且各子块都必须使用相同的一个帧内预测模式。这样,ISP 模式的编码性能的提升主要就来自多个使用相同预测模式的子块模式信息传令码率的节省,因为对多个子块只需要传一次帧内预测模式信息。
VVC 中,只允许对细节较多的亮度块做 ISP 。一个做帧内预测的亮度 CU 块可以划分为 2 个(对 4x8 , 8x4 CUs ) 或 4 个 (对更大的 CU 块)子块。
各子块必须使用相同的 Intra Prediction Mode 。
Max ISP CU 大小为 64x64 :这样才能保证对应的色度块大小不违反 64x64 亮度 VPDU ( Virtual Pipeline Data Unit ) 在解码端可以并行解码的 VVC 总体设计要求。
Min PU ( Prediction Unit ) 最小预测块宽度是 4:这个限制是为了提高硬件实现解码器中内存 ( On-chip memory ) 读写最差情况下的流量带宽 ( Worst-case throughput ),从而更有效地支持实时解码。太小的预测块宽度,会导致硬件过于频繁地读取内存,从而降低了硬件解码器解码的流量效率。基于这个 PU 宽度限制, VVC ISP 中不允许 1xN , 2xN 的 PU , 但是允许 1xN , 2xN 的 TU( Transform Unit ,也即重建块)。
与其他帧内预测模式的相互影响:为了最终提升总体的编码性能, ISP 模式和其他一些帧内预测模式设定了一些相互限制的条件,比如:如果用了 MRL , 就不能再用 ISP ;如果用了 ISP ,就不能再用 PDPC , 等。
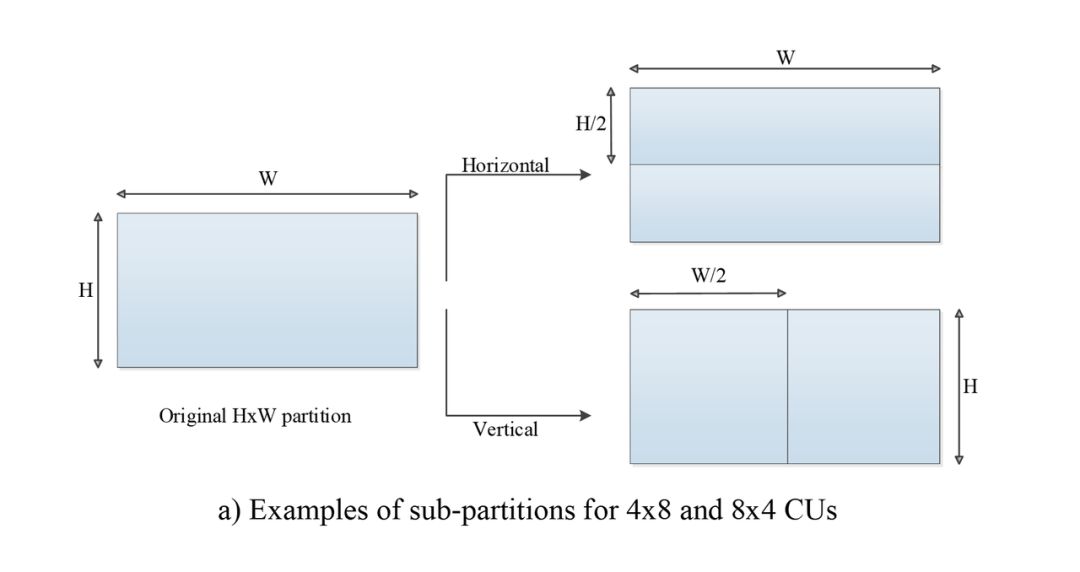
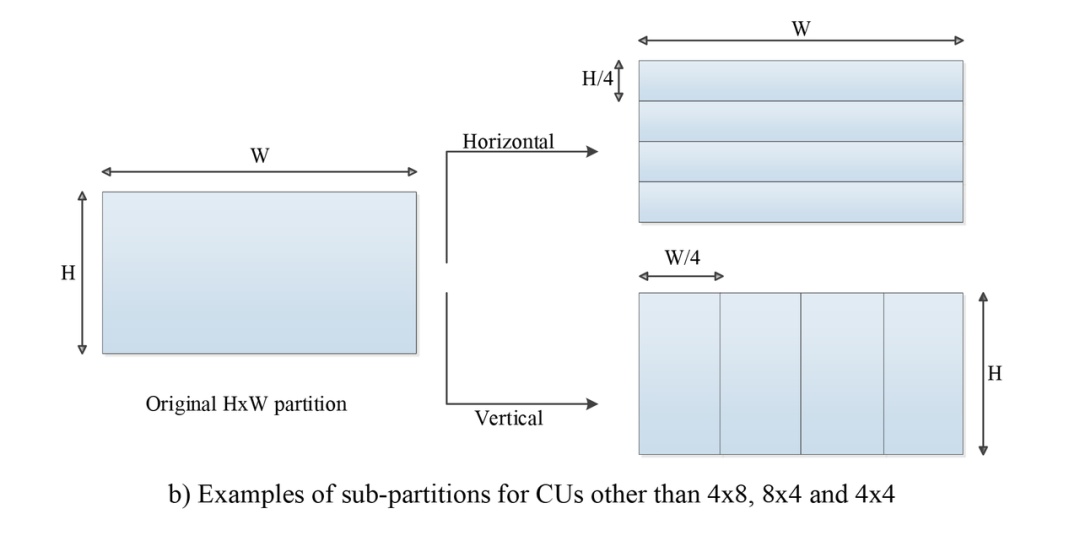
上图来自 [2]
6. 多参考行的帧内预测 ( Multiple Reference Line Intra Prediction MRL )
VVC 中将之前标准中使用的单一上边或左边的参考样本行扩展为了可以从多个上边或左边参考行选取一行做帧内预测参考行。
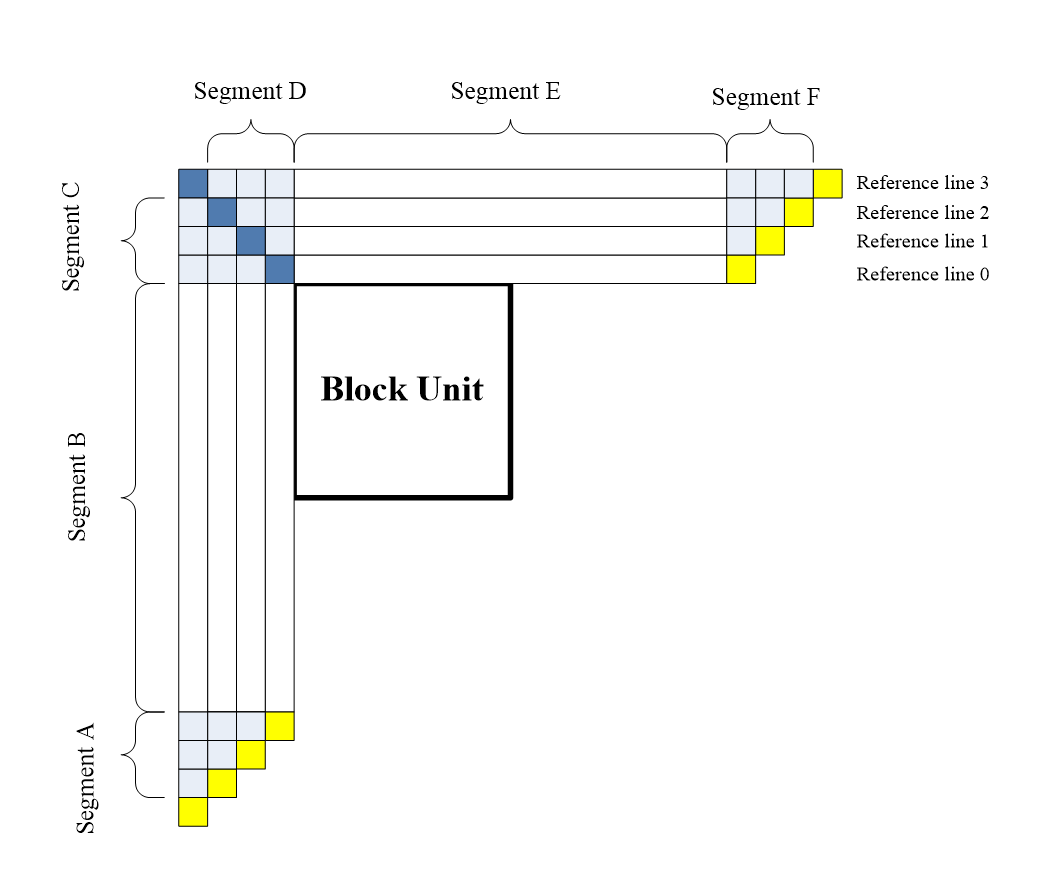
上图来自 [2]
VVC 中,最终允许对亮度块的帧内预测,可以选用两个额外的参考行 (即上图中的 Reference Line 1 和 2 )。这样可以与 CCLM 的亮度参考样本下采样需要的亮度参考样本保持同样一致的参考行存储要求,从而保证了设计的一致性和简洁。
如果使用了 MRL , 预测模式就要用 MPM 编码,同时就不能再使用 PDPC 。
对于一个 CTU ( Coding Tree Unit ) 内的第一行 CU 块,不允许使用 MRL ,因为需要存储当前 CTU 之外的重建参考样本,这在 VVC 的总体设计里是不允许的。
7.帧内预测的基本方式和原理
下面我们先从简单的 DC , Planar , Directional 这些常规的帧内预测模式入手,看一下帧内预测技术一般性的基本方式,即:基于左边和上边帧内重建参考样本的各种不同的加权平均处理。不同的帧内预测技术原理上是通过实验分析发现和利用参考样本和当前块之间不同类型的空间冗余度信息, 从而设计出不同类型的加权平均算法产生帧内预测样本。然后再继续看下 VVC 中引入的两个新的帧内预测模式方面的拓展 PDPC 和 MIP 。
7.1 直流平均和平面平均的帧内预测 ( DC and Planar Intra Prediction )
常用的最简单的 DC 模式,直接就是各个参考样本的算术平均。( VVC 中,对长方形块,即是较长的边的所有参考样本的算术平均。)
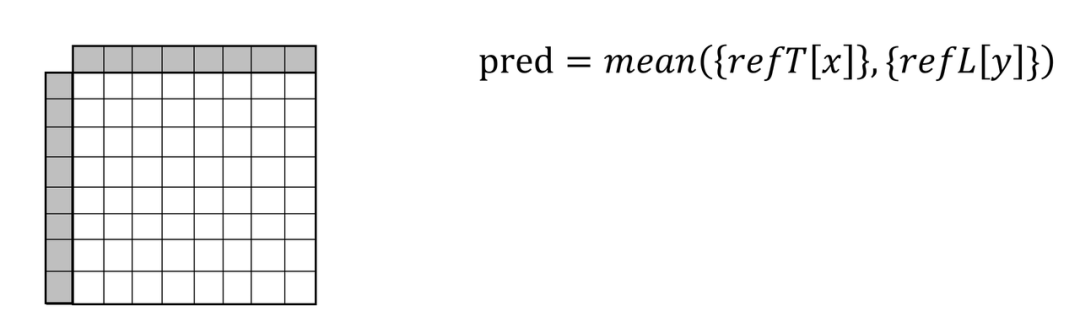
普遍比较有效的 Planar 模式,原理上是与当前样本位置对应的水平和垂直方向的参考样本的按照距离当前样本的距离大小的加权平均。(这里我们把当前块的左下角和右上角的参考样本在 Planar Mode 中的使用等效看成是将该参考样本分别延水平和竖直方向做 Padding Copy 的操作,作为对同位置未知参考样本的一种估计。这样一来, Planar Mode 的原理就比较清晰了。)
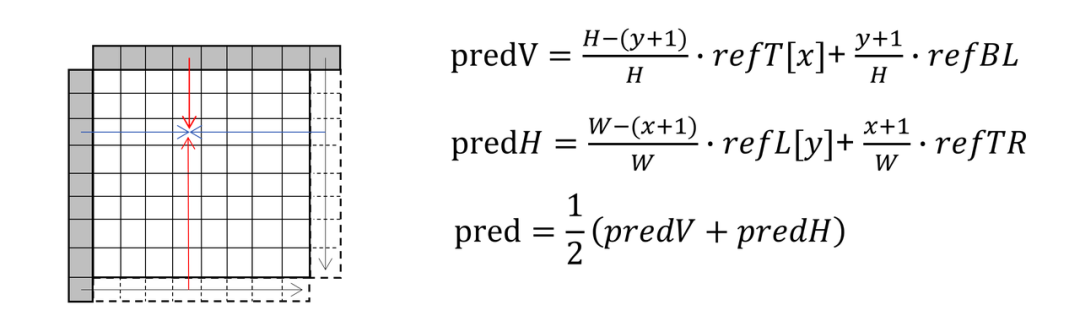
7.2 方向性的帧内预测 ( Directional Intra Prediction )
作为主体的基于预测角度的方向性帧内预测模式,是用某一预测角度上的帧内重建参考样本来直接预测当前样本。
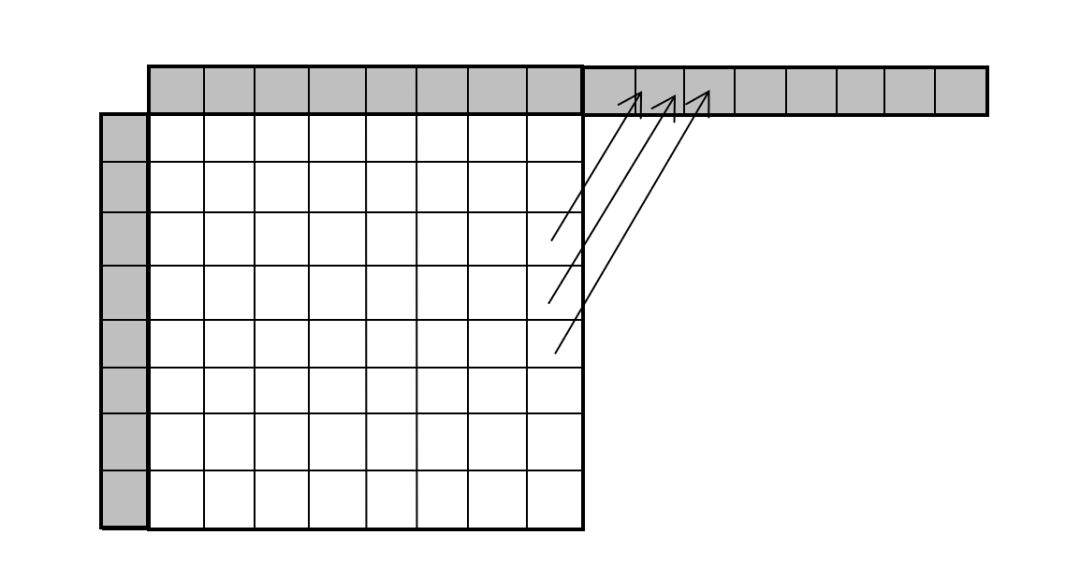
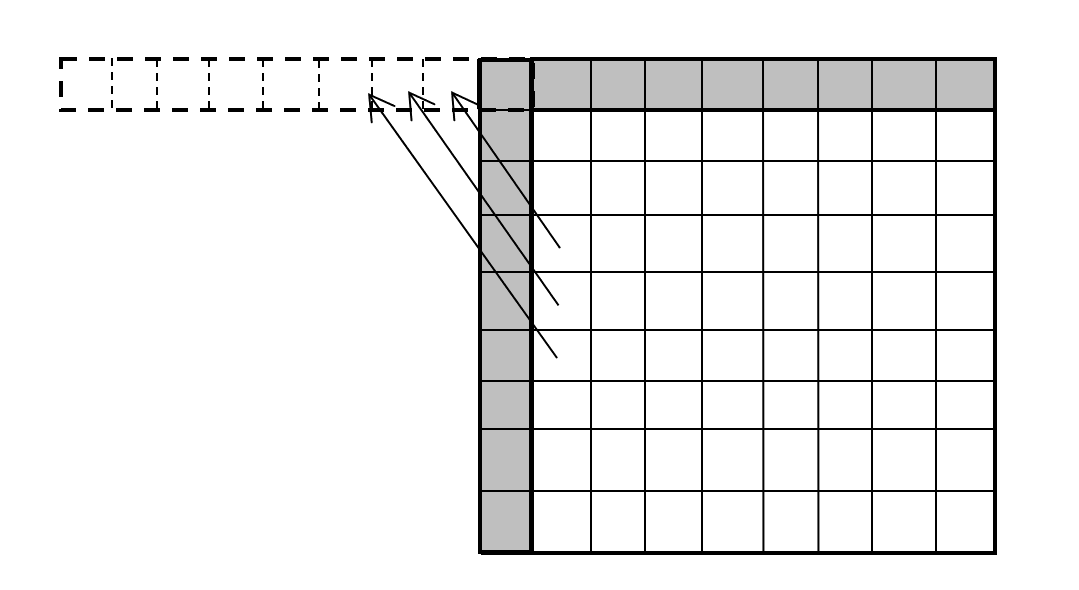
在 VVC 中,为了方便内存读取,提高效率,对于可能同时利用到左边和上边参考样本的角度模式,采取了沿着当前块主要多数参考样本的边(上边或左边),反向延长,通过另一边相应参考样本的预测角度反向投影,产生所需的反向延长边的扩展参考样本。
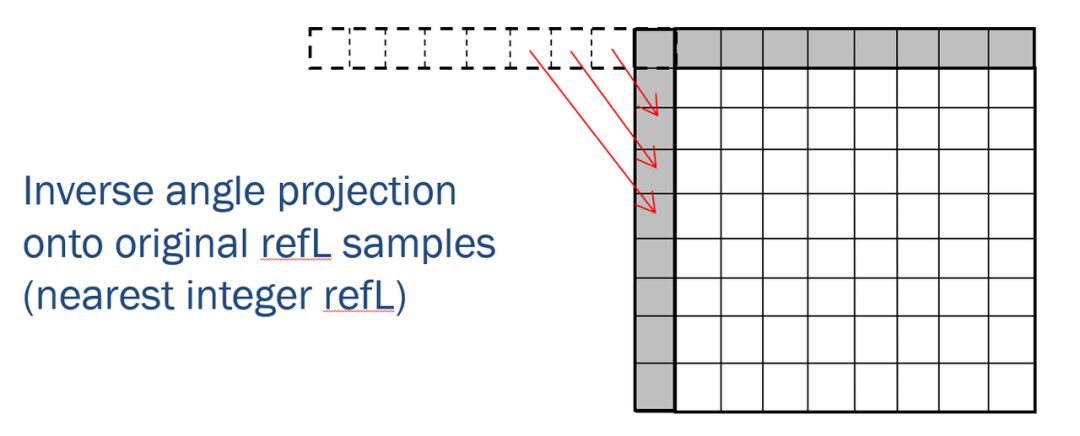
利用反向延长扩展参考样本的角度预测如下图所示。
8.位置相关的组合帧内预测 ( Position Dependent intra Prediction Combination PDPC )
为了补偿以上较简单帧内预测模式在利用空间冗余度方面的不足, VVC 中引入了一种根据当前样本的位置及帧内预测模式的角度自适应选取反方向角度上的参考样本信息作为新的一个相对互补性的帧内预测,然后将它和原有角度的帧内预测做基于样本距离的加权平均。其效果是尽量让原有的角度预测都能够充分利用该预测角度上正反两个方向对应的参考样本信息,从而提高预测性能。
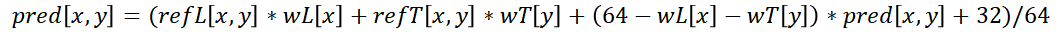
这里 refL[x,y]refL[x,y]refL[x,y] , refT[x,y]refT[x,y]refT[x,y] 是分别来自左边和上边对当前样本位置 ( x , y ) 的预测参考样本, wL[x]wL[x]wL[x] , wT[y]wT[y]wT[y] 是它们各自对应的基于水平或竖直距离的权重,等号右边的 pred[x,y]pred[x,y]pred[x,y] 是原始帧内预测样本,等号左边的 pred[x,y]pred[x,y]pred[x,y] 是最终包含了 PDPC 补偿后的预测样本值。标准中规定了 wL[x]wL[x]wL[x] , wT[y]wT[y]wT[y] 的作用范围,对超过一定距离的 ( x , y ), PDPC 的权重就会变为 0 。
VVC 中的 PDPC 只能与 DC , Planar , 低于或等于水平的预测参考角度模式,和大于或等于竖直的参考角度模式一起配合使用。
对 DC 和 Planar 模式:
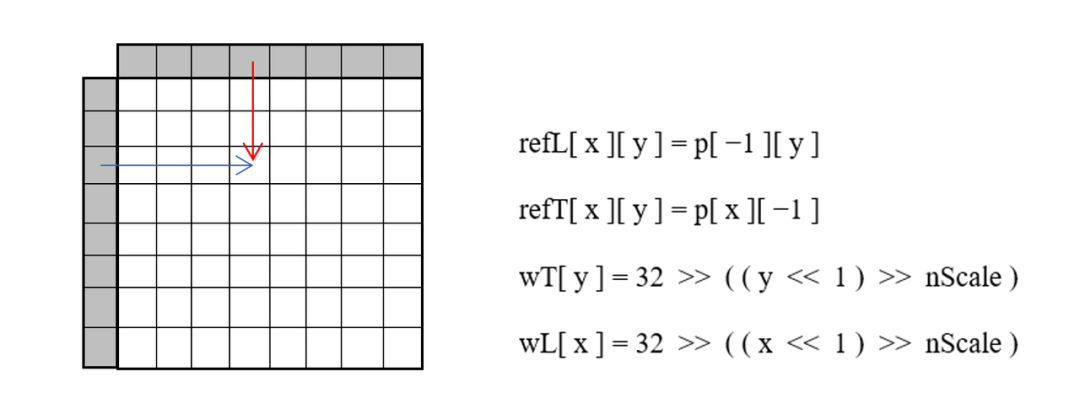
对水平或竖直的角度预测模式(以水平预测为例):
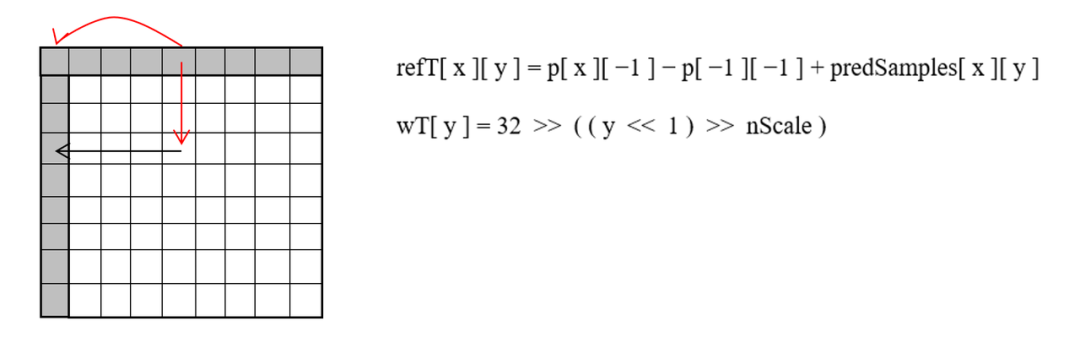
对水平以下,或竖直以外的角度预测模式(以水平以下角度预测为例):

9. 矩阵加权平均的帧内预测 ( Matrix weighted Intra Prediction MIP )
相对于常规的以角度预测为主的帧内预测模式,VVC 中新引入的 MIP 模式代表了另外一大类通过机器学习训练得到的新的帧内预测模式。对三类不同的块大小,MIP 总共包括了 60 个新的预测模式。刨去矩阵转置因素的影响(一个 MIP 模式矩阵可以通过转置,从而一共定义两个 MIP 模式), MIP 的模式定义矩阵共有 30 个,针对不同类的块大小。总体对小块定义的 MIP 矩阵较多,对大块定义的 MIP 矩阵数量较少。
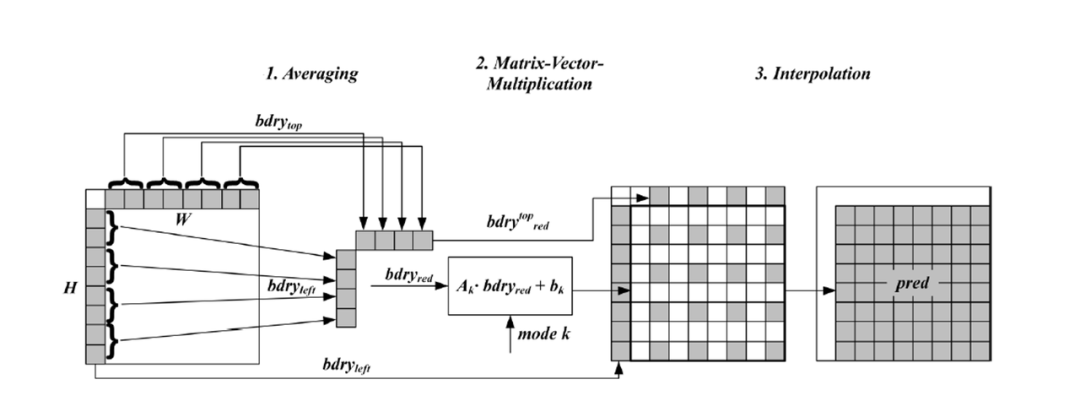
上图来自 [2]
MIP 模式先对左边和上边的参考样本做下采样平均,然后将其于训练得到的块大小相关的模式矩阵做矩阵相乘,最后加上一个模式矩阵对应的常数调整( Offset ) 矢量项。产生的预测样本再上采样到原始块大小。关于块大小的分类如下:
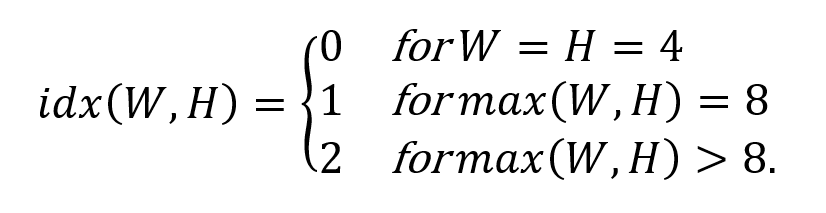
上图来自 [2]
这里 W,H 是当前块的宽和高, idx 是最终的类别 Index 。最小块的 idx 0 类定义了 16 个 MIP 矩阵, idx 1 , 2 分别定义了 8 个和 6 个 MIP 矩阵。通过转置,这 30 个矩阵就代表了 60 个 MIP 模式。
可以看到, MIP 技术实际上是通过机器学习的方法,在统计意义上对实际中高效的帧内预测模式通过矩阵定义的方式进行线性建模。这里的针对块中每个样本位置定义的加权矩阵,实际上就是对每一个块中的样本都利用全体参考样本加权平均的最一般化的帧内预测方法,图示如下。
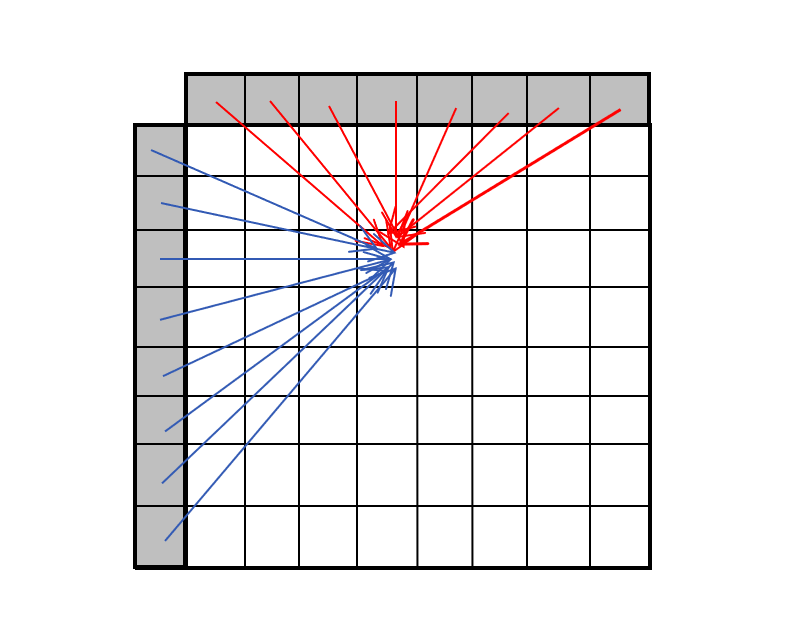
10.小结
相比于 HEVC , VVC 对已有的一些帧内预测技术在多个方向上进行了细化和优化:
加倍细化的预测角度,及针对长方形块的更有效预测的广角模式
更加高效自适应的 4 头内插及平滑滤波
多个参考行
多个子块划分另外, VVC 还引入了几个新的帧内预测技术:
利用亮度帧内参考样本信息预测色度信号的 CCLM
利用反向互补角度方向上的参考样本加权补偿原有帧内预测的 PDPC
利用机器学习进行矩阵线性建模的最一般化的帧内预测方法的 MIP
参考文献
[1] B. Bross, et al., “Versatile Video Coding Editorial Refinements on Draft 10”, JVET-T2001
[2] J. Chen, et al., “Algorithm description for Versatile Video Coding and Test Model 11 (VTM 11)”, JVET-T2002
[3] W.-J. Chien, et al., “JVET AHG report: Tool reporting procedure and testing (AHG13)”, JVET-T0013




