

本文是 InfoQ“解读 2020”年终技术盘点系列文章之一。
在移动互联网时代,数据极大丰富,但同时也导致人们获取有效信息的效率降低,即信息过载。 推荐系统能够主动地、个性化地推送用户感兴趣的信息从而极大缓解信息过载问题,也因此成为移动互联时代发展最快、应用最广泛的技术之一。
与搜索引擎相比,推荐场景下用户主动表达信息少,意图不明确,如何结合用户多维度信息,有效建模用户兴趣点是非常有挑战性和价值的问题。 在超大规模数据场景中,工业级推荐系统主要包含两个核心阶段,召回阶段(Match)和排序阶段(Rank)。 召回阶段从超大规模候选库中快速选出用户可能感兴趣的候选物品集合,要求在几十毫秒内完成从亿级别候选物品中快速选出数千兴趣候选集合。排序阶段对召回候选集进行精准打分,准确预估用户对目标物品的点击率,进而将用户最感兴趣的内容进行呈现。
下面就推荐系统的召回和排序核心环节,展开最新进展介绍。
召回阶段
召回阶段是推荐系统的核心环节,其目的是在极短的时间内将推荐物品规模从数亿级别降低到较小范围(千级别),同时尽可能保证推荐系统的效果。 因此,召回物品的质量直接决定了整个推荐系统效果上限,是工业级推荐中非常重要的一环,近些年相关研究也百花齐放。
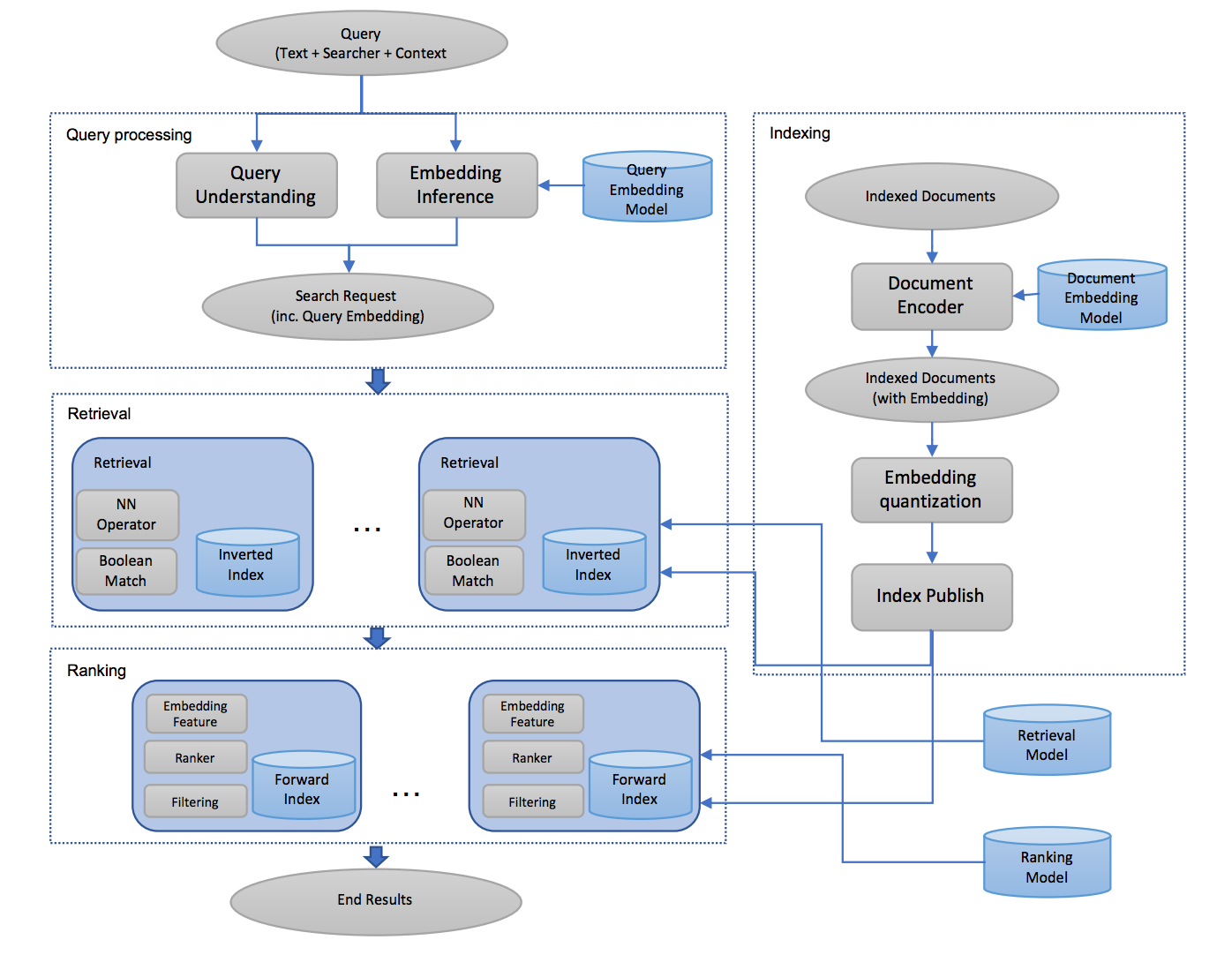
Mobius [1] 从样本着手探究如何对召回模型进行优化。论文的起点是,如果能够找到那些本身是“好”的但是却没有被系统召回的样本,那么这些样本就可以有效用于模型的训练矫正。但是如何在没有被召回的样本中判断哪些是所谓的“好”的样本却并不是一个简单的问题,为此论文提出一种“近似评估”的方案:将后续的排序模型的评分作为参考,即将 CTR 模型评分比较高但没有被召回的样本看做是一些困难样本。 离线阶段,基于原始召回方式挑选出低相关性但高预估 CTR 的样本标记为困难作为数据增强,而原始二分类模型也升级为三分类问题(正样本/负样本/困难样本),从而有效缓解了点击曝光数据稀疏、长尾训练不足的问题。这种方法直接应用到在线系统会存在计算压力大的问题,为此在在线阶段,论文引入 ANN 近似近邻检索算法进行加速,使用向量压缩方案节省线上内存需求,有效缓解了线上服务性能问题。延续对训练数据的理解,EBR [2] 模型也表示召回阶段的负样本筛选是重中之重的事情,不能照搬排序模式只使用曝光未点击数据作为负样本,而应该在未曝光和曝光未点击的数据中进行随机采样生成负样本,以点击数据作为正样本。同时借助 cv 领域的困难样本挖掘方法,将负样本区分为简单/困难分别对待,与 Mobius 的思量有异曲同工之意。EBR 如下图所示:
我们前面提到,召回系统对计算耗时要求极为苛刻,这也导致将一些优秀的模型如深度模型引入到召回系统的尝试止步不前,究其原因,是因为复杂的深度模型计算量过大,直接应用到全部候选集会带来计算量的爆炸,为此基于树模型深度匹配的召回技术 TDM 被提出,基于树组织结构可以实现复杂模型的全库检索。近年来,围绕这一框架取得了持续进展,从 TDM、JTM [3] 到 BSAT [4] ,从模型结构、树的构建、检索过程多维度展开了系列探究,如下图所示:

图片来源:https://flashgene.com/archives/145299.html
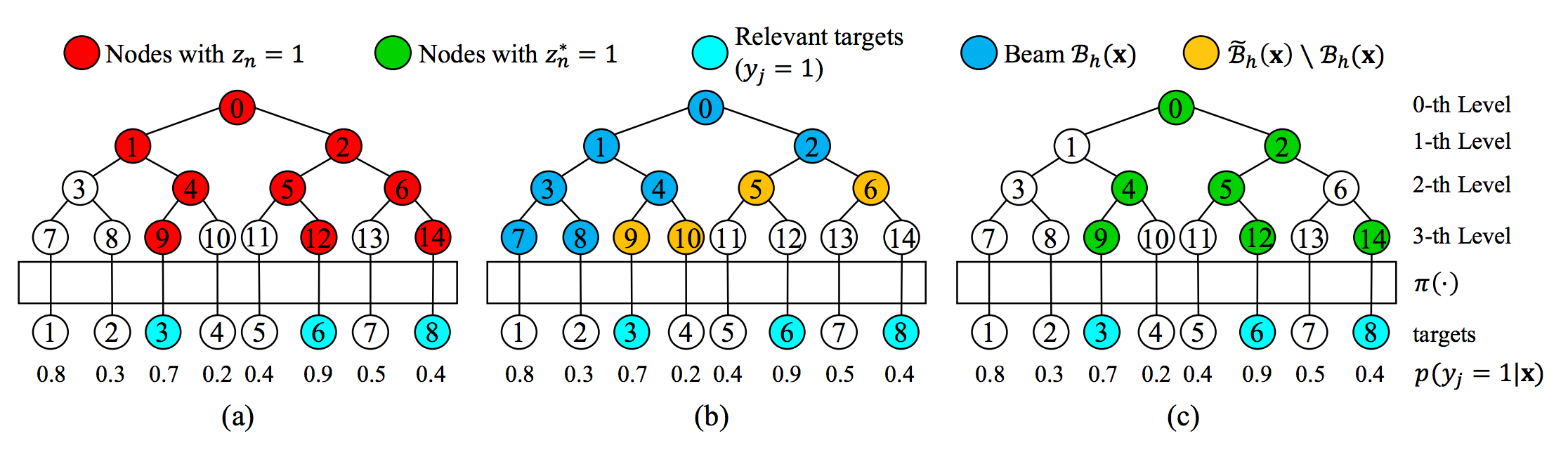
TDM 工作的核心目标是能够突破向量检索模式的限制,使得复杂的深度学习模型,都能够在有限的资源和时间范围内做到近似的全库最优检索。 TDM 基于最大兴趣堆假设来实现对全库物品进行树结构索引构建,并通过复杂的深度神经网络模型建模用户和树中节点的兴趣程度,在线服务过程中,通过 beam search 来实现快速检索。
在 TDM 工作中,模型的优化和树结构索引的学习二者的优化目标并不完全一致,这可能导致二者的优化相互牵制而导致最终整体效果次优。树结构索引的质量对整个召回效果有着至关重要的影响。因此,如何通过学习得到高质量的树索引结构,是 JTM 想要解决的主要问题。
JTM 沿用了 TDM 树结构索引+任意复杂模型的系统框架,通过联合优化和层次化特征建模来解决 TDM 的缺陷。JTM 在一个共同的损失函数下提出交替优化的联合训练框架,来学习树索引结构,避免二者优化目标不一致导致次优解的情况。同时提出了层次化用户兴趣表达的概念,借助树索引的层级结构对用户行为特征进行不同精度层次的建模,更好地表征了在检索过程中用户兴趣从粗到细的表达。 BSAT 在 JTM 基础上,对检索过程(即 beamsearch)进行了联合学习,用以缓解离线训练阶段和在线服务阶段节点分布不匹配的问题:1)训练时通过正样本上溯+同层随机负采样生成树上节点,而在线服务时通过 beamsearch 检索生成树上节点;2)树上节点的标签通过其子节点标签决定,无法避免在 beam search 过程中不出错。
BSAT 首先给出了面向 Beam Search 最优树模型的理论定义,并对其存在性进行了理论证明。为了训练最优树模型,文章给出了损失函数的定义以及训练算法。训练算法中核心不同点在于:1)用于训练的树上节点通过 beamsearch 的方式进行生成; 2)树上节点的标签等于其子树中边缘概率最高的物品标签,而不仅仅由其子节点标签决定。通过以上改进可以有效解决训练-在线服务不匹配的问题。实验结果表明,BSAT 从召回指标上比 JTM 取得了更优的效果。BSAT 如下图所示,
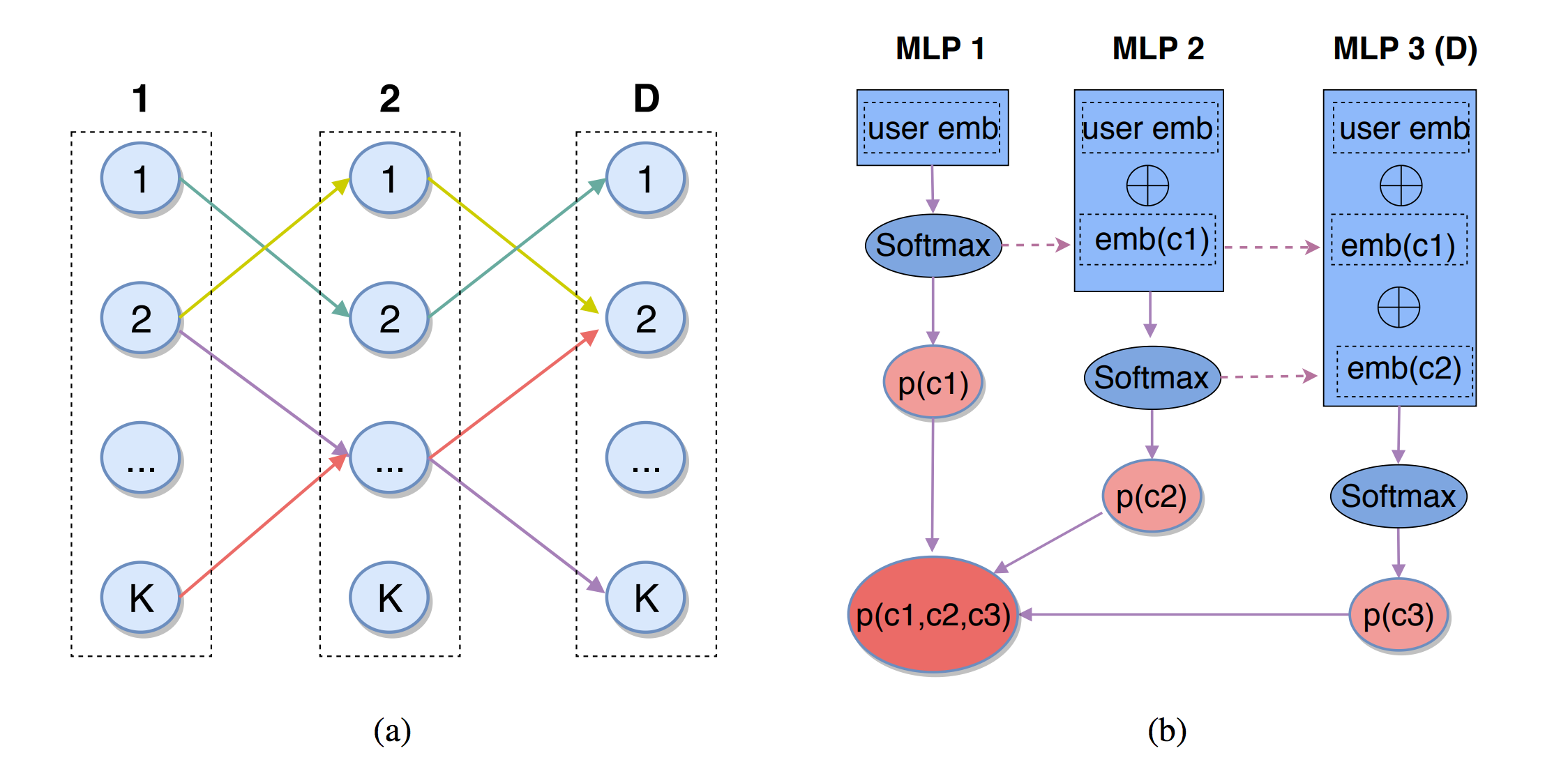
尽管基于树结构的召回取得了不错的效果,但仍存在两点不足,1)树结构本身很难学习,叶子节点数据稀疏难以在更细的层面学习到良好的树结构,制约了检索效果;2)每个候选物品只能分配到一个叶子节点上,限制了模型从多个角度来刻画候选集物品的表达。DeepRetrieval [5] 工作通过改变索引结构,使用 D x K 矩阵作为物品索引,通过 D 步预测每步 K 种选择编织出 K^D 条路径,路径编码通过 EM 算法与模型一同计算,得到路径与物品的多对多关系,进而从更复杂的角度学习用户与物品的关系,并且实验表明 DeepRetrieval 可以在接近线性的计算复杂度下取得与暴力全库匹配算法相当的效果。DeepRetrieval 如下图所示:
排序阶段
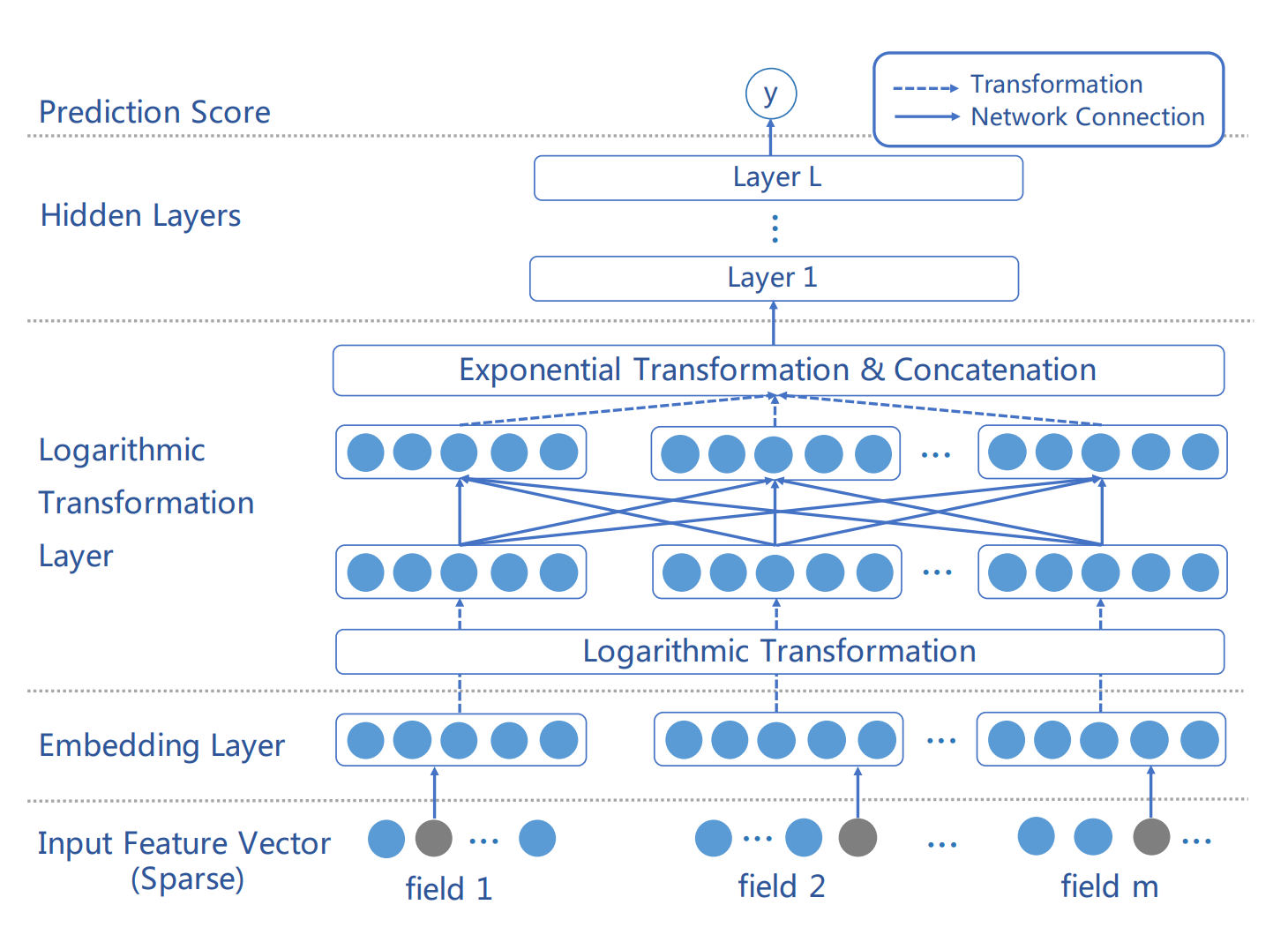
排序阶段的核心问题是点击率(CTR)预估,也就是去衡量一个物品被特定用户点击的概率,最终推荐点击率靠前的结果。早期排序算法是以逻辑回归模型(LR)+人工特征工程为主,模型简单易解释,但人工特征工程的成本比较高,不同任务间算法结论也难以复用,更重要的是对于稀疏数据很难抽取有效的人工特征。为了解决上面的问题,因子分解机(FM)提出了特征嵌入和二阶特征交叉来缓解数据稀疏和人工特征工程的问题。近些年,随着深度学习的快速发展,排序模型也不断演进,从经典 DNN 模型到结合浅层的 Wide&deep 模型再到结合二阶特征交叉的 DeepFM 模型,深度学习越来越广泛地应用在 CTR 预估问题上。其中 PNN、NFM、DCN、xdeepFM 等工作又进一步丰富了在深度 CTR 模型中进行有效高阶特征交叉的方式。进入 2020 年,特征交互依然是基于深度学习的 CTR 模型的研究热点之一,此外用户行为序列建模等也得到了极大的关注。
自从 Transformer 结构提出以来,推荐模型的特征交互开始进入 attention 时代。其中 AutoInt [6] 工作提出使用多头自注意力(Multi-headSelf-attention)机制将模型交互由低阶引向高阶,同时展示出 attention 机制在可解释性上的天然优势。而 FiBiNet [7] 工作借鉴 Squeeze-ExcitationNetwork(SENet)中通道 attention 结构来学习动态特征的重要性并利用双线性函数来更好的建模交叉特征。
2020 年关于注意力机制在 CTR 预估中应用的研究依然没有停止。例如,自适应因子网络(AdaptiveFactorization Networks [8] )认为虽然 attention 可以建模高阶交互特征,但是同一种高阶交互并不一定适合所有的原始特征,为此论文提出了一种可以自适应调整交互阶数的网络来提升模型的性能。而 InterHAt [9] 则侧重于探究通过引入分层策略来改善 self-attention 的特征建模效果。除了特征本身之间的直接交互外,DRM [10] 则从特征映射空间中基的语义相关性来建模特征交互,也就是特征维度关系建模,论文认为特征空间的维度本身包含一些“隐”的语义,并且证明通过 attention 机制建模这种语义之间的相关性对模型 CTR 的预估有明显的正面作用,特别是当特征维度比较的大的时候,这种增益效果就越明显。AFN 如下图所示:
另一方面,用户行为序列建模也是 CTR 预估中一个热门话题,早期的 YouTube 工作直接把用户观看过的视频序列做平均池化(mean pooling)作为用户历史兴趣的表达。后来的 DIN 将 attention 的思想引入到行为序列建模中,使用目标物品对用户行为序列中的物品做 attention,得到 attention score, 然后基于这些 score 对用户行为特征加权求和来表征用户的兴趣。这种方式有效提升用户行为序列建模的效果,但是无法有效区分用户行为中兴趣的起始和终止,这个问题在之后 DIEN 中被深入讨论并处理。
DIEN 基于 RNN 去建模用户行为中兴趣的演化过程,但是 RNN 方式对用户行为序列进行串行计算,耗时相对还是比较高,线上使用压力较大,为此 BST[11]提出可以使用 transformer 来建模用户的行为序列来缓解这个问题。另一方面,DSIN [12] 发现虽然用户在每个会话中的行为是相近的,但在不同会话中差别会比较大,因此论文提出要基于每个会话进行用户行为序列建模,也就是 session 建模。
对于 2020 年,序列建模的相关工作进展主要还是体现在如何建模更长的用户序列以及如何建模用户序列演进关系两部分。
建模更长的用户序列也就意味着对用户有着更全面的了解,但同时面对的噪声也就更多。对于这个问题,19 年 MIMN [13] 模型提出线上使用 UIC 模块(用户兴趣中心)专门用于更新用户最新兴趣表示,将耗时重头从实时计算部分拆分出来做异步更新,多通道用户兴趣记忆网络 MIMN 主要包括基于正则化修正的 NTU 模块和用来加强用户兴趣提取的能力的 MIU 单元,通过 UIC 的更新机制和 MIMN 的序列建模,首次将超长用户行为序列建模扩展到千级别长度。
虽然 MIMN 模型将用户序列长度处理到千,但由于借用了经典 CTR 的 Embedding+MLP 模式,导致特征规模的扩增显著,同时将所有用户历史行为编码到一个固定大小的内存矩阵上会给内存单元带来很多噪音。延续这一方向,20 年的 SIM [14] 模型通过两阶段的方式来对用户终身行为序列进行建模,一阶段采用通用搜索单元(GSU)以次线性时间复杂度从原始长期行为序列中寻找 top-K 相关的子行为序列以减少噪声,包括 hard-search 同类目搜索和 soft-search 使用内积的近似最近邻两种实现方式;二阶段使用过滤后的较短行为子序列,用精准搜索单元(ESU)捕捉更精准的用户兴趣,包括 DIN/DIEN 等复杂模型;实现请求级别建模用户超长行为序列。SIM 如下图所示:
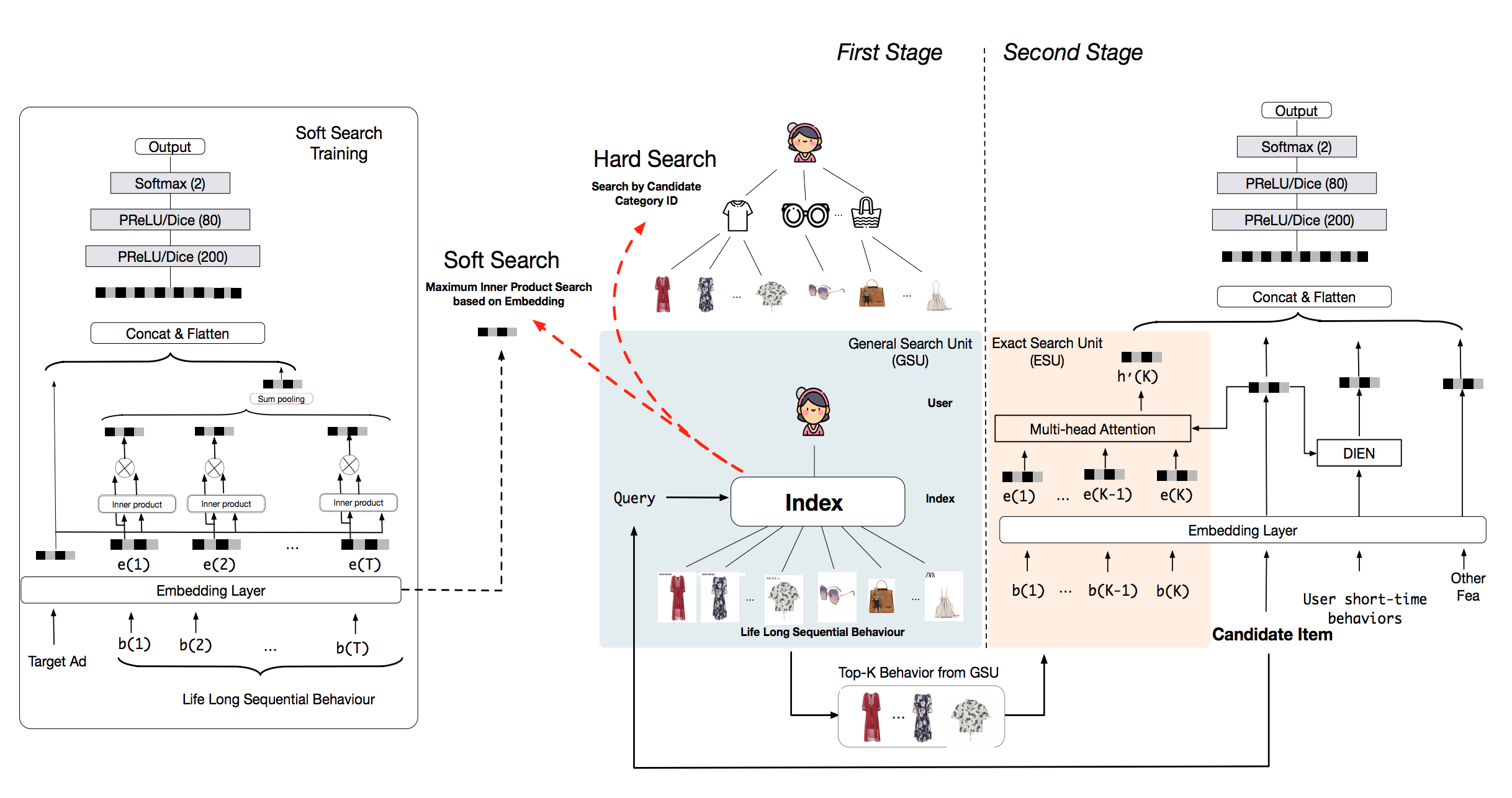
在用户序列演进关系建模方面,DTS[15]通过在一个常微分方程中引入时间信息,使用神经网络根据用户历史行为连续建模用户的兴趣演变。但在电商场景中,临时促销活动中的爆品热销物品会成为用户的短期新兴趣,仅使用用户行为序列通常无法预测用户产生的新兴趣,而预测用户新的兴趣又严重依赖于物品的演化过程,因此基于时间感知的深度物品演化网络(DTAN [16] )提出基于时间 attention 的物品演化建模网络来解决这个问题。
上面的工作都是假设用户的每一个行为都是处于其真实意图的,但是实际电商场景中,有些用户行为可能是随机的,与真实用户意图无关的,如果基于这个无关的行为进行推荐可能会产生错误的推荐,同时反映用户真实意图的行为也可能有缺失。基于此,论文 [17] 提出基于卡尔曼滤波的注意力机制来克服这种观测上的误差和缺失。他们使用 transformer 来捕捉长期行为序列的关系和动态特征,但是在 Attention 里将用户历史行为作为用户隐藏兴趣的间接测量值,为用户的隐藏兴趣给出解析解。最终模型效果提升相对显著。
未来展望
随着互联网技术的发展,云技术、实时计算服务推动信息流推荐朝着实时化边缘化的方向发展,更好的满足用户多元化需求。这就需要对用户兴趣的实时追踪建模,对已有的深度学习推荐模型进一步升级优化,及时捕获用户兴趣就可以更迅速精准的为用户推荐感兴趣物品,提升用户体验。
随着智能产品的增多以及 5G 及物联网的发展,未来新场景下的交互方式的变化,能够让我们获得更多维度的用户信息,提升推荐模型的效果。 信息流场景的爆发式增长,推荐系统的商业价值越来越重要,个性化推荐成为了标配,如何满足用户的使用体验以及如何提高商业价值,是工业、学术界专家学者在推荐系统上的深入探索的重要方向。
参考文献:
[1] Fan M, Guo J, Zhu S, et al. MOBIUS: Towards the Next Generation ofQuery-Ad Matching in Baidu’s Sponsored Search[C]//Proceedings of the 25th ACMSIGKDD International Conference on Knowledge Discovery & Data Mining. 2019:2509-2517.
[2] Huang J T, Sharma A, Sun S, et al. Embedding-based retrieval in facebooksearch[C]//Proceedings of the 26th ACM SIGKDD International Conference onKnowledge Discovery & Data Mining. 2020: 2553-2561.
[3] Zhu H, Chang D, Xu Z, et al. Joint optimization of tree-based index anddeep model for recommender systems[C]//Advances in Neural InformationProcessing Systems. 2019: 3971-3980.
[4] Zhuo J, Xu Z, Dai W, et al. Learning Optimal Tree Models under BeamSearch[C]//International Conference on Machine Learning. PMLR, 2020:11650-11659.
[5] Gao W, Fan X, Sun J, et al. Deep Retrieval: An End-to-End LearnableStructure Model for Large-Scale Recommendations[J]. arXiv preprintarXiv:2007.07203, 2020.
[6] Song W, Shi C, Xiao Z, et al. Autoint: Automatic feature interactionlearning via self-attentive neural networks[C]//Proceedings of the 28th ACMInternational Conference on Information and Knowledge Management. 2019:1161-1170.
[7] Huang T, Zhang Z, Zhang J. FiBiNET: combining feature importance and bilinearfeature interaction for click-through rate prediction[C]//Proceedings of the13th ACM Conference on Recommender Systems. 2019: 169-177.
[8] Cheng W, Shen Y, Huang L. Adaptive factorization network: Learningadaptive-order feature interactions[C]//Proceedings of the AAAI Conference onArtificial Intelligence. 2020, 34(04): 3609-3616.
[9] Li Z, Cheng W, Chen Y, et al. Interpretable Click-Through Rate Predictionthrough Hierarchical Attention[C]//Proceedings of the 13th InternationalConference on Web Search and Data Mining. 2020: 313-321.
[10] Zhao Z, Fang Z, Li Y, et al. Dimension Relation Modeling for Click-ThroughRate Prediction[C]//Proceedings of the 29th ACM International Conference onInformation & Knowledge Management. 2020: 2333-2336.
[11] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commercerecommendation in alibaba[C]//Proceedings of the 1st International Workshop onDeep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[12] Feng Y, Lv F, Shen W, et al. Deep session interest network forclick-through rate prediction[J]. arXiv preprint arXiv:1905.06482, 2019.
[13] Pi Q , Bian W , Zhou G , et al. Practice on Long Sequential User BehaviorModeling for Click-Through Rate Prediction[J]. 2019.
[14] Qi P, Zhu X, Zhou G, et al. Search-based User Interest Modeling withLifelong Sequential Behavior Data for Click-Through Rate Prediction[J]. arXivpreprint arXiv:2006.05639, 2020.
[15] Shi S T, Zheng W, Tang J, et al. Deep Time-Stream Framework forClick-through Rate Prediction by Tracking Interest Evolution[C]//AAAI. 2020:5726-5733.
[16] Deep Time-Aware Item Evolution Network for Click-Through Rate Prediction
[17] Liu H, Lu J, Zhao X, et al. Kalman Filtering Attention for User BehaviorModeling in CTR Prediction[J]. arXiv preprint arXiv:2010.00985, 2020.

加V:busulishang4668

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论