
整理|华卫、核子可乐
昨晚,DeepSeek 在 Hugging Face 上开源了一个新模型。这次他们发布的,是名为 DeepSeek-Prover-V2 的数学推理模型,提供 7B 和 671B 两种参数规模。
_开源项目链接:_https://github.com/deepseek-ai/DeepSeek-Prover-V2/tree/main
该模型专为在数学验证工具 Lean 4 中进行形式化定理证明而设计。Lean 是一种函数式编程语言,可以作为定理证明时的辅助证明工具,在数学界应用甚广,目前已发展到第四代,即 Lean 4。此前,陶哲轩曾借助 Lean 4 成功完成 PFR 猜想的证明。
在多个标准基准测试中,DeepSeek-Prover-V2-671B 都取得了神经定理证明领域的最先进性能水平。并且,面对从著名的 AIME 竞赛(2024 - 2025 年)中挑选的 15 个问题,该模型成功解出了其中的 6 个。相比之下,DeepSeek-V3 通过多数投票解决了其中 8 个问题。DeepSeek 团队表示,这一对比突出表明大语言模型中形式化和非形式化数学推理之间的差距正在大幅缩小。
并且,相比 Numina 和 Kimi 团队前段时间联合推出的数学定理证明模型 Kimina-Prover ,DeepSeek-Prover-V2-7B 在 MiniF2F 测试中的通过率更高。在 pass@8192 的采样预算下,Kimina-Prover 的通过率为 80.7%,而 DeepSeek-Prover-V2-7B 达到了 82.0%。
该模型一发布,就有数学奥赛学生迫不及待地去试用了。据称,DeepSeek-Prover-V2 的效果让他印象深刻,“我甚至还尝试了一道题,结果它完全搞定了。它真的太棒了。”海外的网友大呼:“人工智能的更新速度比光速还要快!”“中国正在崛起。”
还有网友直接给出这样的高评价:“DeepSeek-Prover-V2-671B 旨在实现所有数学运算的自动化。”“DeepSeek 这篇在 reasoning 的追求上,到了一个让普通老百姓不能理解的程度。”

据介绍,DeepSeek-Prover-V2 通过强化学习推进子目标分解的形式数学推理,其初始化数据通过由 DeepSeek-V3 驱动的递归定理证明流程收集得到。冷启动训练过程首先会促使 DeepSeek-V3 将复杂问题分解为一系列子目标,已解决子目标的证明被合成为一个思维链过程,并结合 DeepSeek-V3 的逐步推理,为强化学习创建初始冷启动条件,这一过程能够将非正式和形式化的数学推理整合到一个统一的模型中。
从随后放出的技术报告里,我们看到了有关 DeepSeek-Prover-V2 的完整训练方案及更多技术细节。
两步走的训练方案
将复杂定理的证明分解为一系列较小的引理,作为证明的垫脚石,这是人类数学家常用的有效策略。DeepSeek-Prover-V2 本质上就是一种用于子目标分解的推理模型,利用一系列合成冷启动数据和大规模强化学习来提高其性能。
递归证明搜索合成形式化推理数据
为构建冷启动数据集,DeepSeek 团队开发了一个简单而有效的递归定理证明流程,利用 DeepSeek-V3 作为子目标分解和形式化的统一工具,最终的思维链以一个由一系列 have 语句组成的 Lean 定理结束,每个 have 语句都以 sorry 占位符结尾,表示有待解决的子目标。
过程中,DeepSeek-V3 首先用自然语言分析数学问题,然后将证明分解为更小的步骤,并将每个步骤转换为相应的 Lean 形式化陈述;由于通用模型在生成完整的 Lean 证明方面存在困难,仅指示 DeepSeek-V3 生成省略细节的高级证明草图。这种方法模仿了人类构建证明的方式,即将复杂定理逐步简化为一系列更易于处理的引理。
利用 DeepSeek-V3 生成的子目标,DeepSeek-Prover-V2 采用递归求解策略来系统地解决每个中间证明步骤:从 have 语句中提取子目标表达式,用它们替换给定问题中的原始目标,然后将前面的子目标作为前提条件。这种构建方式使得后续子目标可以利用前面步骤的中间结果来解决,从而促进更局部化的依赖结构,并有助于开发更简单的引理。
接下来,为了减少广泛证明搜索的计算开销,DeepSeek 团队使用一个专门优化用于处理分解后引理的较小的 70 亿参数证明模型,可以在所有分解步骤都成功解决后,自动推导出原始定理的完整证明。
证明模型的训练需要大量的形式语言问题集,这些问题集通常通过对现有的自然语言数学语料库进行形式化得到。为此,该团队在 DeepSeek-Prover-V2 中引入了一个课程学习框架,利用分解后的子目标生成推测性定理,逐步增加训练任务的难度,以更好地指导模型的学习过程。一旦具有挑战性的问题的分解步骤得到解决,就将完整的逐步形式化证明与 DeepSeek-V3 相应的思维链配对,创建冷启动推理数据。
上述算法框架分两个阶段运行,利用两个互补的模型:DeepSeek-V3 用于引理分解,70 亿参数证明模型用于完成相应的形式化证明细节。这个流程提供了一种自然且可扩展的机制,将大语言模型的高级推理与精确的形式验证相结合,合成形式化推理数据。通过这种方式,DeepSeek 团队在单个模型中统一了非形式化数学推理和证明形式化的能力。
执行强化学习阶段
在冷启动的基础上,DeepSeek 团队应用后续的强化学习阶段,进一步加强非形式化数学推理与形式化证明构建之间的联系。实验表明,从任务分解中的非形式化推理冷启动开始的强化学习,显著提高了模型在形式化定理证明方面的能力。
据介绍,他们整理了一组 70 亿参数证明模型无法端到端解决,但所有分解后的子目标都已成功解决的具有挑战性问题子集。通过组合所有子目标的证明,为原始问题构建了一个完整的形式化证明,然后将该证明附加到 DeepSeek-V3 的思路链中。这一思路链概述了相应的引理分解,从而将非形式化推理与后续形式化过程紧密结合。
在对证明模型进行合成冷启动数据的微调后,该团队开始执行强化学习阶段,以进一步提高其将非形式化推理与形式化证明构建联系起来的能力。遵循推理模型的标准训练目标,它们使用二元正确或错误反馈作为主要的奖励监督形式。
由于在训练过程中观察到生成的证明结构经常与思维链指导提供的引理分解不同,他们在训练的早期步骤中纳入了一致性奖励,对结构不一致进行惩罚,明确要求最终证明中包含所有分解的 have 结构引理。在实践中,强制执行这种一致性提高了证明的准确性,特别是在需要多步推理的复杂定理上。
提供两种推理证明模式
简单来说,DeepSeek-Prover-V2 通过两阶段训练流程开发,建立了两种互补的证明生成模式:
高效非思维链(non-CoT)模式:此模式针对快速生成形式化 Lean 证明代码进行了优化,专注于在不显示中间推理步骤的情况下生成简洁的证明。
高精度思维链(CoT)模式:此模式在构建最终形式化证明之前,系统地阐述中间推理步骤,强调透明度和逻辑进展。
与 DeepSeek-Prover-V1.5 一致,DeepSeek-Prover-V2 的两种生成模式由两个不同的引导提示控制。在第一阶段,DeepSeek 团队在课程学习框架内使用专家迭代范式来训练非思维链证明模型,同时通过基于子目标的递归证明为难题合成证明。选择非思维链生成模式是为了加速迭代训练和数据收集过程,因为它提供了明显更快的推理和验证周期。
在此基础上,第二阶段利用了通过将 DeepSeek-V3 复杂的数学推理模式与合成形式证明相结合而生成的冷启动链式思维链数据。CoT 模式通过进一步的强化学习阶段得到增强,遵循推理模型常用的标准训练流程。
据介绍,该团队使用恒定的学习率 5e-6,在 16384 个 token 的上下文窗口内,对 DeepSeek-V3-Base-671B 进行监督微调。训练语料库由两个互补来源组成:(1)通过专家迭代收集的非思维链数据,这些数据生成的 Lean 代码没有中间推理步骤;(2)冷启动思维链数据,这些数据将 DeepSeek-V3 先进的数学推理过程提炼为结构化的证明路径。非思维链组件强调 Lean 定理证明生态系统中的形式验证技能,而思维链示例则明确模拟了将数学直觉转化为形式化证明结构的认知过程。
DeepSeek-Prover-V2 所采用的强化学习算法是组相对策略优化(GRPO),该算法在推理任务中已证明具有卓越的有效性和效率。与近端策略优化(PPO)不同,GRPO 通过为每个定理提示采样一组候选证明,并根据它们的相对奖励优化策略,消除了对单独批评模型的需求。训练使用二元奖励,即每个生成的 Lean 证明如果被验证正确则获得 1 的奖励,否则为 0。
为确保有效学习,DeepSeek 团队精心挑选了训练提示,仅包括那些具有足够挑战性但可由监督微调模型解决的问题。在每次迭代中,DeepSeek-Prover-V2 会采样 256 个不同的问题,为每个定理生成 32 个候选证明,最大序列长度为 32768 个 token。
此外,该团队将 DeepSeek-Prover-V1.5-Base-7B 的最大上下文长度从 4096 个 token 扩展到 32768 个,并使用在 DeepSeek-Prover-V2-671B 强化学习阶段收集的滚动数据对这个扩展上下文模型进行微调。除了 CoT 模式,他们还纳入了在专家迭代期间收集的非思维链证明数据,以实现一种成本效益高的证明选项,使用小型模型生成简洁的形式化输出。并且,7B 模型亦执行与 671B 模型相同的强化学习阶段。
高中、本科、奥赛题“一网打尽”
在最后的性能评测环节,DeepSeek 团队用各种形式定理证明的基准数据集对 DeepSeek-Prover-V2 进行了系统的评估,涵盖高中竞赛题目和本科阶段数学知识。
结果表明,尽管训练数据主要来自高中水平的数学问题,该模型仍能很好地泛化到更高级的大学水平问题,展现出其强大的形式化推理能力。
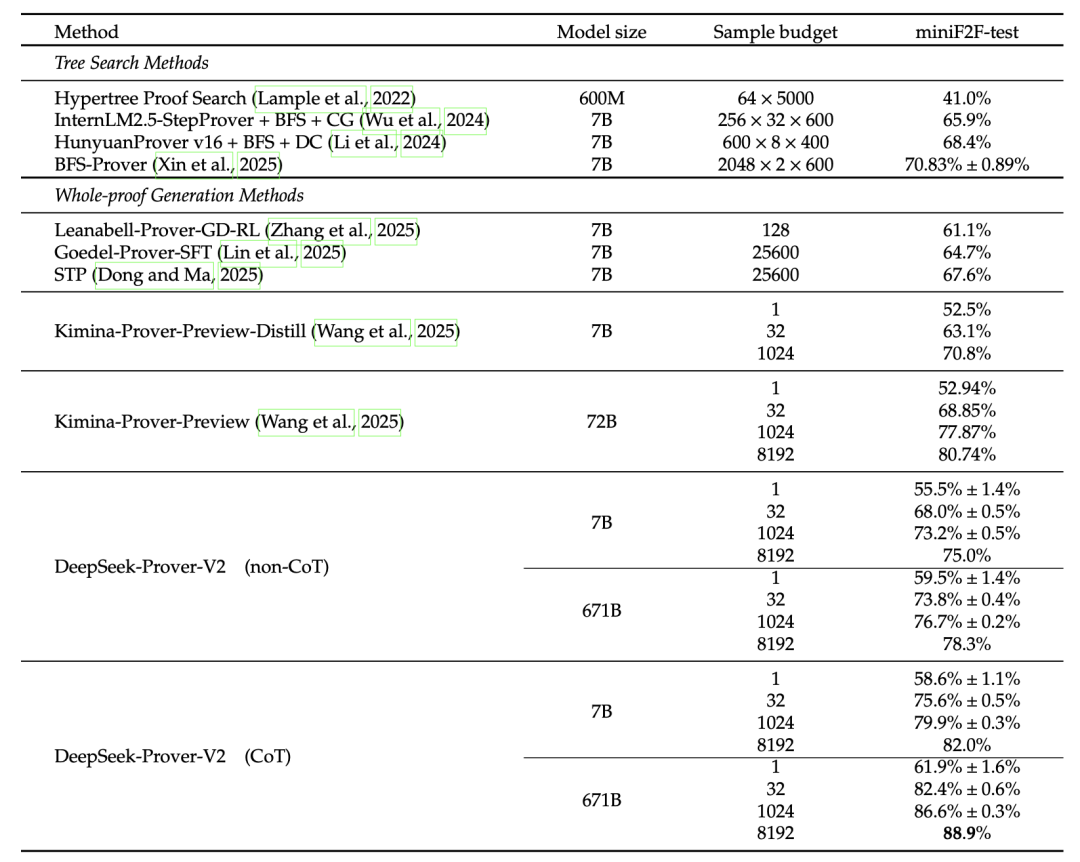
在 MiniF2F 测试中,DeepSeek-Prover-V2-671B 在使用 CoT 生成策略的情况下,仅需 32 次采样即可达到前所未有的 82.4% 准确率,刷新了该基准测试的最新记录,到 8192 次采样时提高到 88.9%。值得注意的是,参数更少但效率更高的 DeepSeek-Prover-V2-7B 模型同样表现出色,超越了所有现有的开源定理证明模型。
据了解,MiniF2F 基准测试包含 488 道形式数学问题陈述,这些问题来源于 AIME、AMC 和 IMO 等竞赛以及 MATH 数据集,涵盖代数、数论和归纳法等领域。
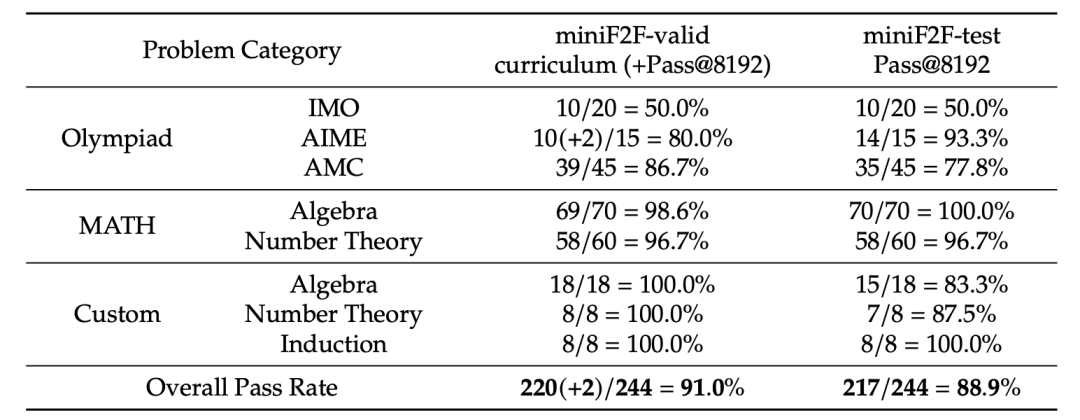
令人印象深刻的是,其子目标引导课程学习框架,结合通用模型 DeepSeek-V3 和轻量级专业 7B 定理证明器,DeepSeek-Prover-V2 在 miniF2F-valid 上取得了 90.2% 的成功率,几乎与体量更大的 DeepSeek-Prover-V2-671B 持平。这一发现表明,最先进的通用 LLM 不仅可以扩展自然语言理解能力,还能有效支持复杂的形式推理任务。通过战略性子目标分解,模型能够将复杂问题拆解为一系列可处理的步骤,从而在非形式推理和形式证明之间建立起有效的桥梁。
在 ProofNet 和 PutnamBench 基准测试上,DeepSeek-Prover-V2-671B 也展示了超强的解题推理能力,且 CoT 模式下效果更优。这些结果进一步强调,CoT 推理方法在处理有挑战性的大学水平数学问题方面更具有效性。
ProofNet 包含 371 道用 Lean 3 编写的数学问题,这些问题来源于多部流行的本科纯数学教材,涵盖实分析、复分析、线性代数、抽象代数和拓扑学等领域。PutnamBench 是一项持续更新的基准测试,包含自 1962 年至 2023 年的普特南数学竞赛题目。该竞赛面向美国和加拿大的本科生,涵盖分析、线性代数、抽象代数、组合数学、概率和集合论等多个领域。
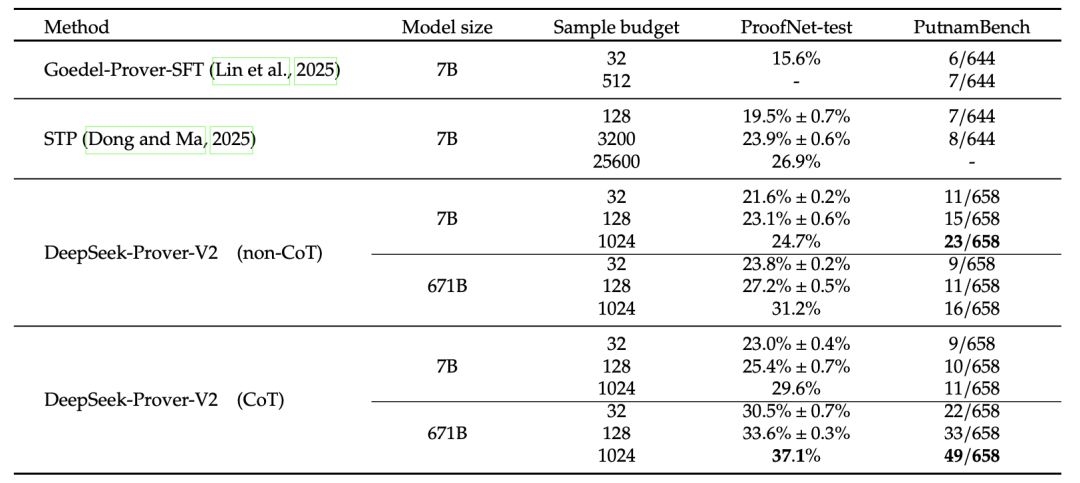
一个意外发现是,DeepSeek-Prover-V2-7B 在非 CoT 生成模式下对 PutnamBench 数据集的表现更为出色,成功解决了 DeepSeek-Prover-V2-671B 无法解决的 13 道问题。通过对模型输出的进一步分析,DeepSeek 团队发现,其推理方法中存在一种显著的模式:7B 模型经常使用 Cardinal.toNat 和 Cardinal.natCast_inj 来处理涉及有限基数的问题,这些手段似乎使模型能够有效地解决需要精细操作基数值的一类问题,
而这样的思路在 671B 版本的输出中明显缺失。
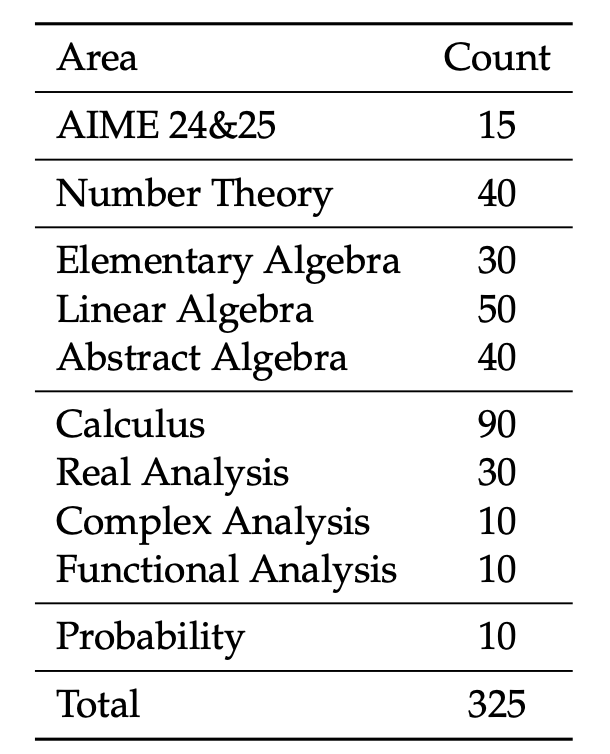
除了标准基准测试,DeepSeek 团队还引入了在 ProverBench,这是一个包含 325 个形式化问题的集合,其中 15 道问题是基于近期 AIME 竞赛中的数论和代数问题形式化而成,反映出真实的高中竞赛水平挑战,剩余的 310 道问题则来自精心挑选的高中竞赛和大学课程教材示例,为形式化数学问题提供了多样且以教材为基础的集合。此基准测试旨在对高中竞赛问题和大学数学问题解答能力做出更为全面评估。
参考链接:
https://github.com/deepseek-ai/DeepSeek-Prover-V2/blob/main/DeepSeek_Prover_V2.pdf
声明:本文为 InfoQ 翻译整理,不代表平台观点,未经许可禁止转载。




