

一、症状
一天,金融分析团队的同事报告了一个问题,他们发现在两个生产环境中(为了区分,命名为环境 A 和 B), Spark 大版本均为 2.3。但是,当运行同样的 SQL 语句,对结果进行对比后,却发现两个环境中有一列数据并不一致。此处对数据进行脱敏,仅显示发生数据丢失那一列的数据,如下:
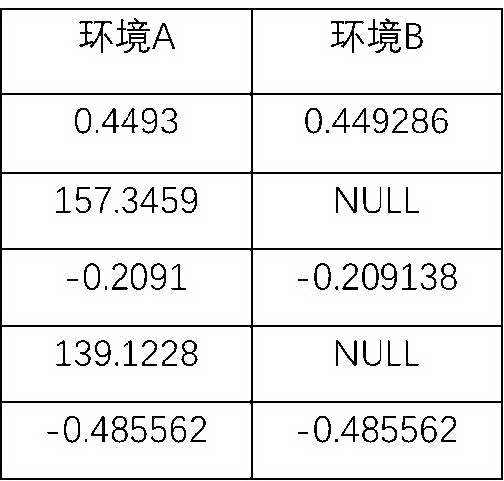
由此可见,在环境 A 中可以查询到该列数据,但是在环境 B 中却出现了部分数据缺失。
二、排查
上述两个查询中用的 Spark 大版本是一致的,团队的同事通过对比两个环境中的配置,发现有一个参数在最近进行了变更。该参数为:spark.sql.decimalOperations.allowPrecisionLoss, 默认为 true。
在环境 A 中未设置此参数,所以为 true,而在环境 B 下 Spark client 的 spark-defaults.conf 中,该参数设置为 false。
该参数为 PR SPARK-22036 引入,是为了控制在两个 Decimal 类型操作数做计算的时候,是否允许丢失精度。在本文中,我们就针对乘法这种计算类型做具体分析。
关于 Decimal 类型
在详细介绍该参数之前,先介绍一下 Decimal。
Decimal 是数据库中的一种数据类型,不属于浮点数类型,可以在定义时划定整数部分以及小数部分的位数。对于一个 Decimal 类型,scale 表示其小数部分的位数,precision 表示整数部分位数和小数部分位数之和。
一个 Decimal 类型表示为 Decimal(precision, scale),在 Spark 中,precision 和 scale 的上限都是 38。
一个 double 类型可以精确地表示小数点后 15 位,有效位数为 16 位。
可见,Decimal 类型则可以更加精确地表示,保证数据计算的精度。
例如一个 Decimal(38, 24)类型可以精确表示小数点后 23 位,小数点后有效位数为 24 位。而其整数部分还剩下 14 位可以用来表示数据,所以整数部分可以表示的范围是-10^14+1~10^14-1。
关于精度和 Overflow
关于精度的问题其实我们小学时候就涉及到了,比如求两个小数加减乘除的结果,然后保留小数点后若干有效位,这就是保留精度。
乘法操作我们都很清楚,如果一个 n 位小数乘以一个 m 位小数,那么结果一定是一个**(n+m)位**小数。
举个例子, 1.11 * 1.11 精确的结果是 1.2321,如果我们只能保留小数点后两位有效位,那么结果就是 1.23。
上面我们提到过,对于 Decimal 类型,由于其整数部分位数是(precision-scale),因此该类型能表示的范围是有限的,一旦超出这个范围,就会发生 Overflow。而在 Spark 中,如果 Decimal 计算发生了 Overflow,就会默认返回 Null 值。
举个例子,一个 Decimal(3,2)类型代表小数点后用两位表示,整数部分用一位表示,因此该类型可表示的整数部分范围为-9~9。如果我们 CAST(12.32 as Decimal(3,2)),那么将会发生 Overflow。
下面介绍 spark.sql.decimalOperations. allowPrecisionLoss 参数。
当该参数为 true(默认)时,表示允许 Decimal 计算丢失精度,并根据 Hive 行为和 SQL ANSI 2011 规范来决定结果的类型,即如果无法精确地表示,则舍入结果的小数部分。
当该参数为 false 时,代表不允许丢失精度,这样数据就会表示得更加精确。eBay 的 ETL 部门在进行数据校验的时候,对数据精度有较高要求,因此我们引入了这个参数,并将其设置为 false 以满足 ETL 部门的生产需求。
设置这个参数的初衷是美好的,但是为什么会引发数据损坏呢?
用户的 SQL 数据非常长,通过查看相关 SQL 的执行计划,然后进行简化,得到一个可以复现的 SQL 语句,如下:

上面的 select 语句将会返回一个 NULL。
我们将上述语句的执行计划打印出来。

执行计划很简单,里面有一个二元操作(乘法),左边的 case when 是一个 Decimal(34, 24)类型,右边是一个 Literal(1)。
程序员都知道,在编程中,如果两个不同类型的操作数做计算,就会将低级别的类型向高级别的类型进行类型转换,Spark 中也是如此。
一条 SQL 语句进入 Spark-sql 引擎之后,要经历 Analysis->optimization->生成可执行物理计划的过程。而这个过程就是不同的 Rule 不断作用在 Plan 上面,然后 Plan 随之转化的过程。
在 Spark-sql 中有一系列关于类型转换的 Rule,这些 Rule 作用在 Analysis 阶段的 Resolution 子阶段。
其中就有一个 Rule 叫做 ImplicitTypeCasts,会对二元操作(加减乘除)的数据类型进行转换,如下图所示:
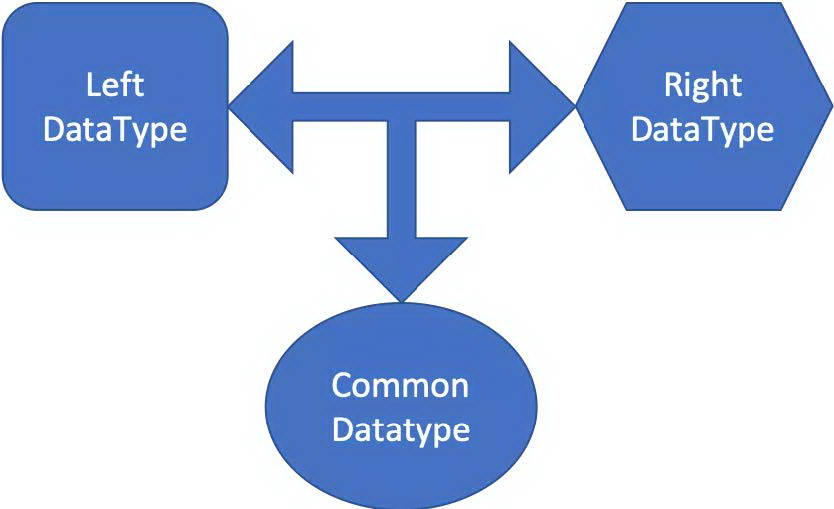
用文字解释一下,针对一个二元操作(加减乘除), 如果左边的数据类型和右边不一致,那么会寻找一个左右操作数的通用类型(common type), 然后将左右操作数都转换为通用类型。针对我们此案例中的 Decimal(34, 24) 和 Literal(1), 它们的通用类型就是 Decimal(34, 24),所以这里的 Literal(1)将被转换为 Decimal(34, 24)。
这样该二元操作的两边就都是 Decimal 类型。接下来这个二元操作会被 Rule DecimalPrecision 中的 decimalAndDecimal 方法处理。
在不允许精度丢失时,Spark 会为该二元操作计算一个用来表达计算结果的 Decimal 类型,其 precision 和 scale 的计算公式如下表所示,这是参考了 SQLServer 的实现。
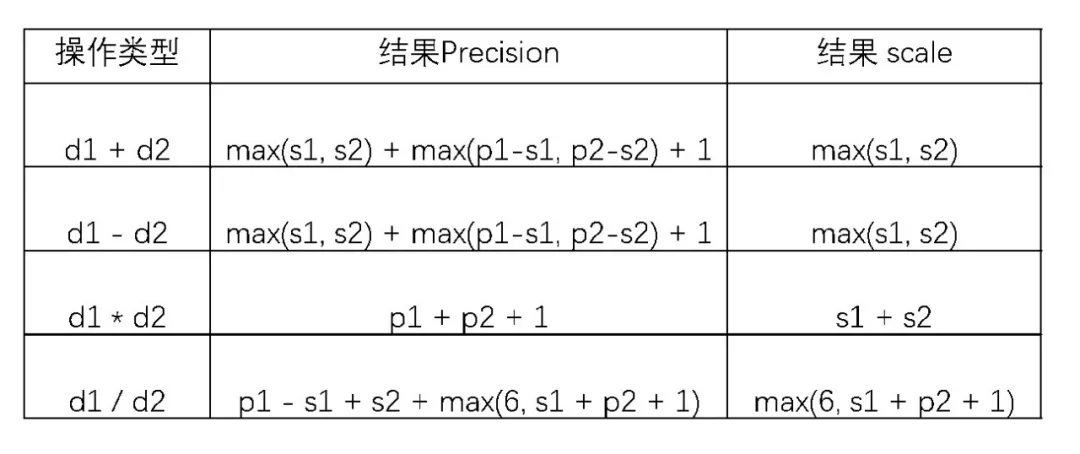
此处我们的操作数都已经是 Decimal(34, 24)类型了,所以 p1=p2=34, s1=s2=24。
如果不允许精度丢失,那么其结果类型就是 Decimal(p1+p2+1, s1+s2)。由于 precision 和 scale 都不能超过上限 38,所以这里的结果类型是 Decimal(38, 38), 也就是小数部分为 38 位。于是整数部分就只剩下 0 位来表示,也就是说如果整数部分非 0,那么这个结果就会 Overflow。在当前版本中,如果 Decimal Operation 计算发生了 Overflow,就会返回一个 Null 的结果。
这也解释了在前面的场景中,为什么使用环境 B 中 Spark 客户端跑的结果,非 Null 的结果中整数部分都是 0,而小数部分精度更高(因为不允许精度丢失)。
好了,问题定位到这里结束,下面讲解决方案。
三、解决方案
01 合理处理操作数类型
通过观察 Spark-sql 中 Decimal 相关的 Rule,发现了 Rule DecimalPrecision 中的 nondecimalAndDecimal 方法,这个方法是用来处理非 Decimal 类型和 Decimal 类型操作数的二元操作。
此方法代码不多,作用就是前面提到的左右操作数类型转换,将两个操作数转换为一样的类型,如下图所示:

文字描述如下:
如果其中非 Decimal 类型的操作数是 Literal 类型, 那么使用 DecimalType.fromLiteral 方法将该 Literal 转换为 Decimal。例如,如果是 Literal(1),则转化为 Decimal(1, 0);如果是 Literal(100),则转化为 Decimal(3, 0)。
如果其中非 Decimal 类型操作数是 Integer 类型,那么使用 DecimalType.forType 方法将 Integer 转换为 Decimal 类型。由于 Integer.MAX_VALUE 为 2147483647,小于 3*10^9,所以将 Integer 转换为 Decimal(10, 0)。当然此处省略了其他整数类型,例如,如果是 Byte 类型,则转换为 Decimal(3,0);Short 类型转换为 Decimal(5,0);Long 类型转换为 Decimal(20,0)等等。
如果其中非 Decimal 类型的操作是 float/double 类型,则将 Decimal 类型转换为 double 类型(此为 DB 通用做法)。
因此,这里用 DecimalPrecision Rule 的 nonDecimalAndDecimal 方法处理一个 Decimal 类型和另一个非 Decimal 类型操作数的二元操作的做法要比前面提到的 ImplicitTypeCasts 规则处理更加合适。ImplicitTypeCasts 会将 Literal(1) 转换为 Decimal(34, 24), 而 DecimalPrecision 将 Literal(1)转换为 Decimal(1, 0) 。
经过 DecimalPrecision Rule 的 nonDecimalAndDecimal 处理之后的两个 Decimal 类型操作数会被 DecimalPrecision 中的 decimalAndDecimal 方法(上文提及过)继续处理。
上述提到的案例是一个乘法操作,其中,p1=34, s1=24, p2 =1, s2=0。
其结果类型为 Decimal(36,24),也就是说 24 位表示小数部分, 12 位表示整数部分,不容易发生 Overflow。
前面提到过,Spark-sql 中关于类型转换的 Rule 作用在 Analysis 阶段的 Resolution 子阶段。而 Resolution 子阶段会有一批 Rule 一直作用在一个 Plan 上,直到这个 Plan 到达一个不动点(Fixpoint),即 Plan 不再随 Rule 作用而改变。
因此,我们可以在 ImplicitTypeCasts 规则中对操作数类型进行判断。如果在一个二元操作中有 Decimal 类型的操作数,则此处跳过处理,这个二元操作后续会被 DecimalPrecision 规则中的 nonDecimalAndDecimal 方法和 decimalAndDecimal 方法继续处理,最终到达不动点。
我们向 Spark 社区提了一个 PR SPARK-29000, 目前已经合入 master 分支。
02 用户可感知的 Overflow
除此之外,默认的 DecimalOperation 如果发生了 Overflow,那么其结果将返回为 NULL 值,这样的计算结果异常并不容易被用户感知到(此处非常感谢金融分析团队的同事帮我们检查到了这个问题)。
在 SQL ANSI 2011 标准中,当算术操作发生 Overflow 时,会抛出一个异常。这也是大多数数据库的做法(例如 SQLService, DB2, TeraData)。
PR SPARK-23179 引入了参数 spark.sql. decimalOperations.nullOnOverflow 用来控制在 Decimal Operation 发生 Overflow 时候的处理方式。
默认是 true,代表在 Decimal Operation 发生 Overflow 时返回 NULL 的结果。
如果设置为 false,则会在 Decimal Operation 发生 Overflow 时候抛出一个异常。
因此,我们在上面的基础上合入该 PR,引入 spark.sql.decimalOperations.nullOnOverflow 参数,设置为 false, 以保证线上计算任务的数据质量。
四、总结
本文分析了一个 Decimal 操作计算时发生的数据质量问题。我们不仅修复了其不合适的类型转换问题,减小了其结果 Overflow 的几率,还引入了一个参数,以便在计算发生 Overflow 时抛出异常,让用户感知到计算中存在的问题,保证线上计算的数据质量。
在大数据计算场景中,我们不仅关心数据计算得快不快,更关心结果数据的质量高不高。这需要各个团队的密切配合,平台开发人员需要提供可靠稳定的计算平台,业务团队需要写出高质量的 SQL,数据服务团队则要提供良好的调度和校验服务。相信在各个团队的共同努力下,eBay 在大数据这条路上能走得更远、更宽阔。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
https://mp.weixin.qq.com/s/yKFzO41l-2n617xICN2ObQ

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论