

5 月 25 日,互联网架构技术沙龙圆满落幕。本期沙龙特邀请腾讯的技术专家分享关于技术架构、落地实践案例、无服务器云函数架构、海量存储系统架构等话题,从技术角度看架构发展,为开发者们带来丰富的实践经验内容,深度揭秘技术架构。下面是朱建平老师关于如何架构海量存储系统的分享。
接下来我给大家分享的是海量存储系统,有人说存储是“后台开发领域中的明珠”,是后台技术挑战最大的,今天那么多人趁着周末的时间来学习,我们一起来剖析下这个“明珠”。
整个分享分为四块:一是讲讲什么是存储,虽然大家都接触过,今天我稍微系统点地给大家梳理下;二是怎么去从零构建一个海量存储的系统,在座各位亲自构建海量分布式存储系统的机会可能并不是很多,但是可以从中学习下怎么去架构后台系统,实现运营可控的目标;三是存储关键技术,希望这方面的知识帮助大家正确地选型公有云上的存储产品,节约运营成本;最后给大家分享我们存储研发和运营十多年来碰到很多的坑,从中挑了两个曾经摔得最痛的坑给大家分享下。
认识存储
在存储领域我们内部喜欢用“面粉”跟“面包”这两个词,什么意思?我们知道面粉是原材料,面包是产品,而存储的常见的面粉是这么几类:一是内存,二是非易失性内存,三是固态硬盘,四是机械硬盘,五是磁带,六是蓝光盘;磁带和蓝光盘,大家以前听歌,看电影会接触到,现在在企业存储中,它们也被用来存储一些很冷的备份数据。

内存这个大家已经很熟悉了,而非易失性内存,是最近几年出来的新鲜事物,前几年业界一直翘首以盼,去年开始有产品出来了,英特尔的奥腾。它是介于内存跟固态硬盘的形态,可以低成本地扩展内存容量,如果未来服务器普及几百 G 的大内存配置,相信咱们技术方案设计上会有明显地改变。固态硬盘用在企业存储里面,一开始听说固态硬盘擦写五千次就报废,很担心把它用作持久化存储,因为天天写数据,不知道啥时候擦写完五千次后数据就丢了。慢慢这个固态硬盘技术越来越成熟,现在在高性能数据存储场景中,固态硬盘已经成为的广泛使用的一种存储介质。机械硬盘,也称为“HDD”,要读取一个数据,首先移动磁头到指定磁道,等盘片转到指定位置,再把数据读出来。我进腾讯的时候,机械硬盘一块盘是 750G,随后这些年 1T,2T,4T,8T,12T 单盘容量逐步演变,但受限于它的机械原理,机械硬盘的性能在过往 20 年来基本上没有太多的变化,IO 读带宽也就维持 100MB/s 左右,IO 延时在 5 毫秒左右。机械硬盘也是目前价格相对最低的存储介质。
那么怎么去看不同的存储介质?主要从三个纬度:一是性能,二是成本,三是 IO 约束。先看成本,我在京东上查了一下数据,如果是用内存的,“DDR4”1GB 大概 87 元,就是面粉价,固态硬盘 1GB 的成本大概是 1.5 元,机械硬盘 1GB 的的成本是 0.3 元,所以它的成本差别很大,内存跟 HDD 的差距肯定是上百倍的级别。然后看 IO 性能,内存最快,大概十纳秒的级别,机械硬盘是几毫秒级别,固态硬盘大概是微妙级的,NVM 比固态盘贵,比内存要便宜,性能也是介于两者之间。不仅仅是性能能和成本,IO 约束也是有差别,比如固态盘,一个 Block 只能顺序写,写完以后整个 Block 擦掉再从头开始写;蓝光盘/磁带,写上数据后就只读了,这些都是 IO 约束,NVM 也有类似的约束。我们在做任何一个产品的时候,首先要认识好底层的东西有什么特点,各种的存储技术方案也是围绕介质展开的,如果所有的存储介质都跟内存一样高性能,跟机械盘一样能持久化和低成本,我想技术也就不会做得那么复杂。
再跟大家讲一下面包,大家看到的公有云平台上的存储产品,主要是两大类:一是对象存储,不同的产品形态接口不一样,最上面的是 AWS S3 接口,是亚马逊公司定义出来,他们做得最早,目前各个公有云的厂商都提供了 S3 接口存储访问的产品;另外常见的是 Block Device 接口,在虚拟机下加了一块盘,但实际上它并不是一块物理磁盘在那里,访问这块虚拟盘时,转向访问后端的分布式存储系统;第三个接口叫做 Posix—Compliant Filesystem 接口,需要的时候我们直接挂靠(mount)一个目录到本地,这个目录同样也是虚拟的,由后端分布式存储支撑对该目录的访问。

在数据库范畴,大家平常用得最多是 SQL 接口,接下来是 Redis/Memcached 接口,MogoDB 接口,还有图存储、时序数据库等等。数据库中 NoSQL 存储产品,未能像对象存储那样,各家公有云厂商统一起来,而是非常的分散。简单介绍一:Redis/Memcached 比较常用,简单的键值对存储并做了一些扩展;图存储,一般用于知识图谱类场景,包括社交关系链的推导;时序数据库,物联网以及一些监控类场景使用较多;ElasticSearch 这个增加了倒排索引,主要用在搜索场景;最后两个是大数据的人比较熟悉,它支持列存储,在做大数据计算的时候,按列存储数据,再进行压缩,能更好节省存储空间,提升检索效率,所以在大数据中较多采用列存储。
从零构建海量存储系统
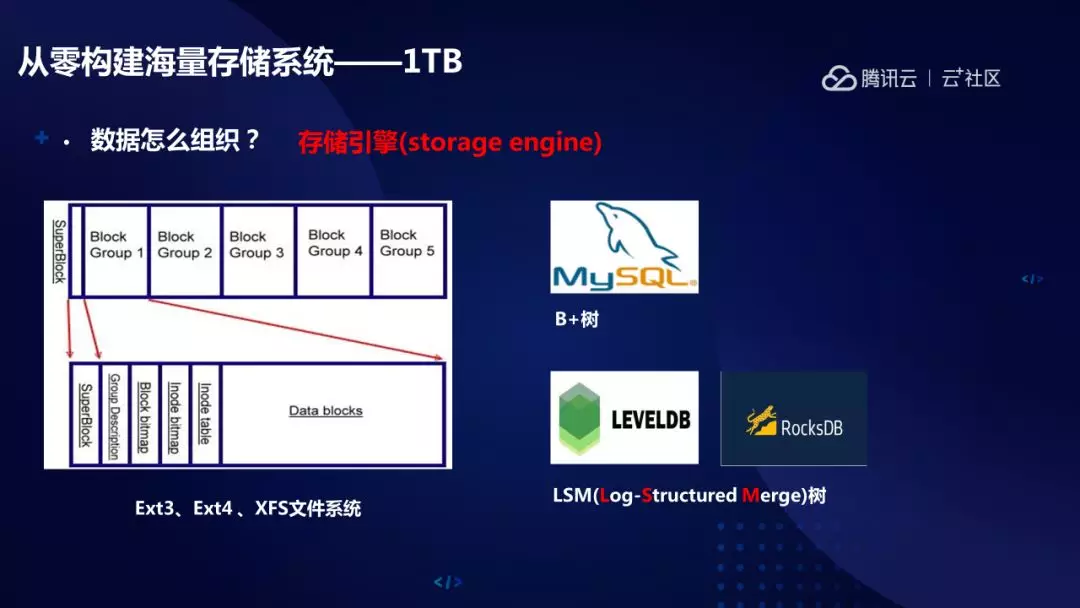
接下来跟讲一下海量分布式存储怎么一步步构建出来。做存储面临的第一个问题是怎么在存储介质上组织数据。先看下文件系统,比如常见的 Ext3、Ext4 这些文件系统,文件系统帮助我们解决了大文件的问题,把大文件数据拆分存放在磁盘的多个位置,这是第一。第二,借助于 inode,一级二级索引,组织出一个数据的层次结构。直到现在,如果大家有时间,我还是推荐大家多看下这写文件系统的实现,做存储这里面很多思想是一脉相承的。
B+树是我们数据库里面最常用的数据组织结构,之前学数据结构时我们比较熟悉的是二叉树,B+树通过更多的分杈加快数据检索。另外就是 LSM 树,开源数据引擎中比较有影响力的 LevelDB 和 RocksDB 都是这类,现在很多开源存储系统直接基于 RocksDB 构建,时间太短,不展开介绍了。希望大家有时间网上找相关材料去看看。
1T 涨到 10T 我们会关注什么?根据访问场景和要求,看看该选用什么介质存储数据,但如果到 100T,一台服务器就存不下了? 这时候,我们要解决数据分布,和多副本数据存储。比较常用的是 DHT,这是一种完全去中心化的数据分布方式,这个也是历史很久,但是实际运用中,存在数据复制不太可控的问题;二是 CRUSH,这也是中心化的数据分布方式,是 Ceph 底层的数据分布方式,它按照 OSD-Shelf-Cabinet-Room 来层次化组织存储介质,提供 uniform/list/tree/straw 等散列目标数据单元 PG 。三是数据分布表,这是在业界用得最多的地方,维护和存储每个存储单元到磁盘,存储单元到多个副本的动态映射,运营可控性强,也是常见的数据分布方案。

到 1PB 的时候,我们面临着怎么管理好这么大的盘子。此时,我们需要构建一个海量存储的运营支撑系统,做海量存储平台肯定写完程序只占 30% ,70%是研发和运营好这个东西。这里面最主要的几个方面:一是容量管理,我们要知道什么时候该扩容了,需要实时统计数据的存储量,根据过往的增长情况,预测未来一段时候的存储容量;二是故障管理,盘坏了,机器死了怎么去探测,怎么去剔除/置换,怎么去恢复;接下来是数据流动,安全地将数据从一台机器调度到另外一台机器,从一个机房调度到另外一个机房等等。

涨到 10PB 级,你要考虑数据的数据热度变化对成本的影响了,可能当初合理的存储方案不再合理了怎么办?纠删存储,它可以做到数据小于两份(冷数据 1.x 份),但是它的数据可靠性比简单两份/三份副本数据的可靠性还要高;纠删存储以后还有自动分层调度,怎么从业务数据中,识别并剥离出冷数据, 借助于数据调度和搬迁,降低存储份数。
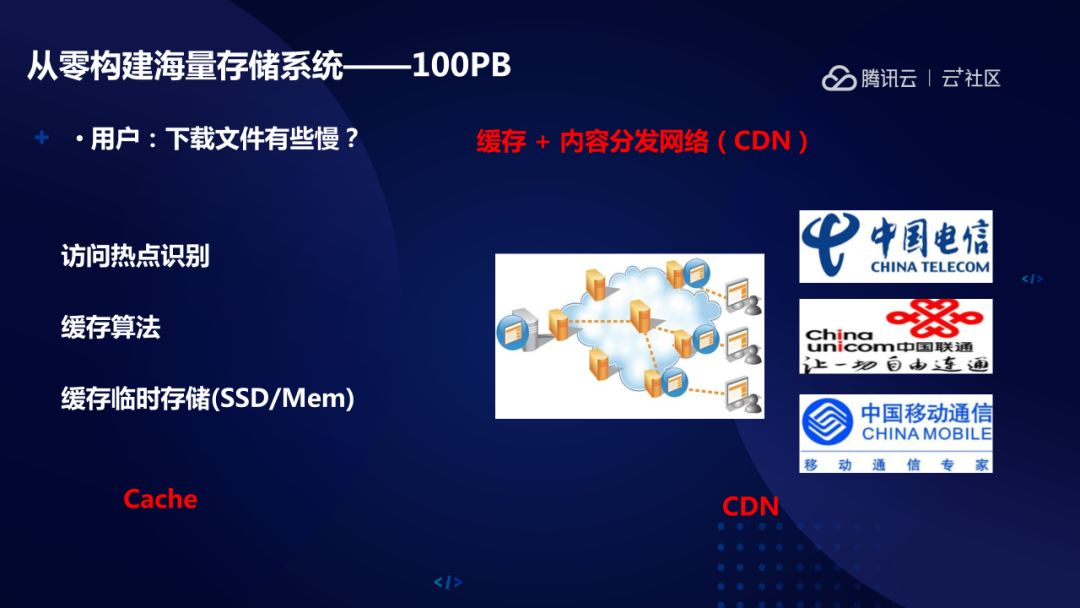
如果涨到 100PB,可能会面临用户投诉下载文件慢的问题,一般可以通过缓存+数据预分发去应对:一是缓存,识别出访问热点对象,借助于多数据多副本或固态硬盘等手段把数据缓存起来,另外就是数据预分发 CDN,我们访问数据的时候, 比如说在武汉联通访问一个 QQ 存储在天津数据,如果你能提前将要访问的数据在武汉联通的机房准备好,就近访问,延时体验就会好很多。
数据涨到 1EB 的时候,如何充分利用海量的存储设备可能就是一个问题,比如你会发现存储特别是晚上的时候,服务器 CPU 很空闲,这个时候我们可以借助虚拟化/容器化等技术调度部分计算的任务来做。

关键技术
总结一下海量存储的关键技术:一是数据分布算法,二是存储引擎,三是数据一致性协议,四是数据建议,五是磁盘管理,六是数据容灾、恢复。这些对于海量存储系统都是非常关键的一些技术,大家如果要了解的话,可以从这几个方面展开看看,拓展来看,还有异地分布方面的一些技术。

经验分享
分享一个例子:这是我们当年在做社交游戏数据存储时的一个技术方案,当时我们最前端有一个接入层,最下面有存储层,是用机械硬盘去存的,但是我们发现做社交游戏的数据访问频次很高,比如每秒上万次读写请求,而磁盘每秒的访问能力只有 100—200 IOPS 的访问能力,肯定支撑不了上万的请求,所以我们当时增加了一个内存存储夹层。这个架构为什么很坑?这个架构看起来不复杂,其实挺复杂的,位于中间的这个内存存储夹层,虽然是临时中转存储下,但是它还必须要保证数据的可靠性,一方面要业务要快速更新写入,一方面要同步给多副本的另外一些内存存储节点,同时还要做本地的磁盘持久化以及往底层硬盘转存数据。四路并行,当时在这里吃了很多的亏。
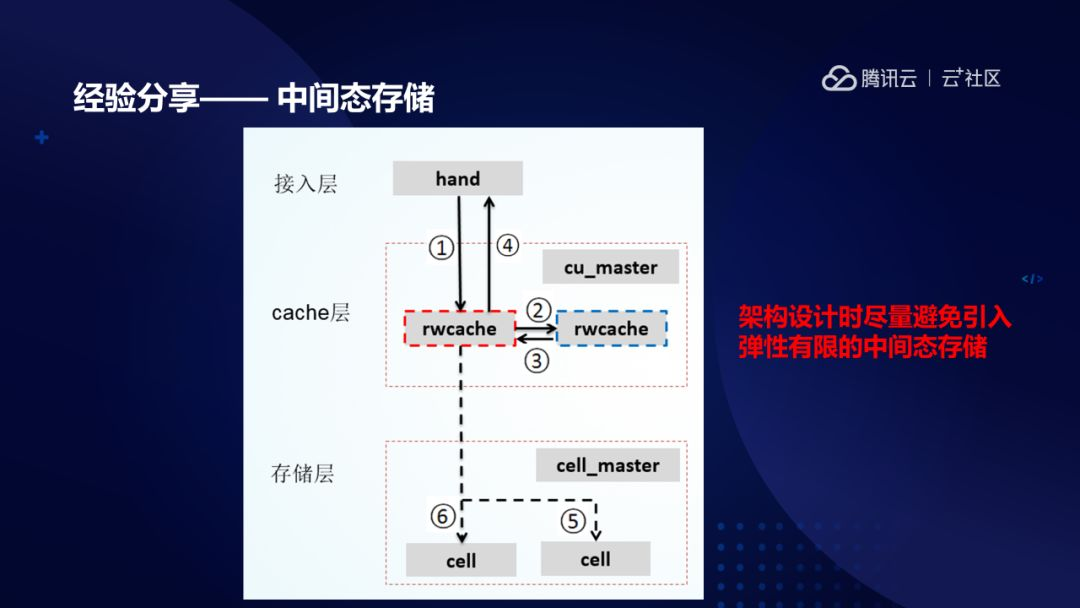
我举上面这个例子是想告诉大家我们在做架构设计的时候避免类似的临时态的夹层设计,让系统的能力直接取决于你最终的存储介质,以获取更好的运营可控性。以上就是今天我给大家分享的主要内容,谢谢大家。

Q:您好,我想问一下基于微服务架构底层的存储,更推荐于哪种类型的存储?
A:微服务跟存储没有太大的关联,存储本身就是一个服务,微服务也是一个服务。存储服务基于协议接口访问,都是适合供微服务使用的。
Q:我们有一个数据库就一个 T,从存储的角度来讲,怎么样去解决一个 T 的数据库访问的数据比较慢的问题,我也不希望通过增加成本的形式,能不能通过文件或者数据存放去降低成本提高效率?
A:如果是我的话,我首先看一下数据库的结构怎么设计,这个很重要,我曾经跟一朋友交流,他在一些请求场景下,数据库访问面临严重的吞吐和时延问题。后来,我们一起分析发现它的一个接口,在上述请求场景下可能最多要访问一千次数据库,才能完成请求的处理。所以,最最关键的地方还是我们自己要用好数据库,数据库再强没有办法替代你的设计,所以说我们要看看数据库的表结构设计,哪些是变的,哪些是不变的,在频繁变的地方尽量缩减其存储量。
作者介绍:
朱建平,毕业于武汉大学计算数学系。现任腾讯云架构平台部技术总监,负责对象存储,NoSQL 存储等相关平台的研发,在分布式存储平台建设,视频处理,异构计算,数据传输等方向拥有多年的实践经验。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/DJYCFI5mtEf4xBmLvcsTlw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论