

8 月 26 日,星环邀请来自华东师范大学软件工程学院的博士生导师宫学庆教授带来《数据库前沿技术系列讲座》,分享数据库业内前沿发展和研究热点。现将宫学庆教授的培训第一讲内容:内存数据库的技术发展分享给大家。
基于磁盘的数据库管理系统
传统的数据库管理系统(DBMS)通常是采用基于磁盘的设计,原因在于早期数据库管理系统设计时受到了硬件资源如单 CPU、单核、可用内存小等条件的限制,把整个数据库放到内存里是不现实的,只能放在磁盘上。由于磁盘是一个非常慢的存储设备(相对于 CPU 的速度),因此学术界和工业界发展出的数据库管理系统在架构上都必须适应当时的硬件条件,沿用至今的 Oracle 和 MySQL 等数据库管理系统仍然采用的是这种架构设计。伴随着技术的发展,内存已经越来越便宜,容量也越来越大。单台计算机的内存可以配置到几百 GB 甚至 TB 级别。对于一个数据库应用来说,这样的内存配置已经足够将所有的业务数据加载到内存中进行使用。虽然大数据处理的数据量可能是 PB 级别的,但那些数据一般是非结构化的数据。通常来讲,结构化数据的规模并不会特别大,例如一个银行 10 年到 20 年的交易数据加在一起可能只有几十 TB。这样规模的结构化数据如果放在基于磁盘的 DBMS 中,在面对大规模 SQL 查询和交易处理时,受限于磁盘的 I/O 性能,很多时候数据库系统会成为整个应用系统的性能瓶颈。
如果我们为数据库服务器配置足够大的内存,是否可以仍然采用原来的架构,通过把所有的结构化数据加载到内存缓冲区中,就可以解决数据库系统的性能问题呢?这种方式虽然能够在一定程度上提高数据库系统的性能,但在日志机制和更新数据落盘等方面仍然受限于磁盘的读写速度,远没有发挥出大内存系统的优势。内存数据库管理系统和传统基于磁盘的数据库管理系统在架构设计和内存使用方式上还是有着明显的区别。
缓冲区管理方式
在传统的数据库管理系统中,数据的主存储介质是磁盘。例如,逻辑上的一张表通常会被映射到磁盘上的一个文件,文件是以数据块(Data Block,也称作 Page)的形式存储在磁盘上。对于结构化数据来说,一条记录会被保存在磁盘上的某个数据块中,可以用数据块 ID 和 Offset/偏移量来表示该条记录的具体位置。这种形式的数据块也被称作 Slotted Page,顾名思义是把数据块划分成很多槽位,然后一个 Record 放在某一个槽位上。在对某条记录进行处理时,可以通过代表该记录地址的 Page ID + Offset 从磁盘上获取该记录;随后系统会把存储有该条记录的数据块从磁盘读到缓冲区(Buffer Pool 分为多个 Frame,每个 Frame 可以保存一个磁盘块),再从缓冲区将该条记录读到线程或事务的工作区进行处理;处理结束后将更新的记录写回缓冲区中的数据块,再由数据库管理系统将修改过的数据块写回到磁盘上。
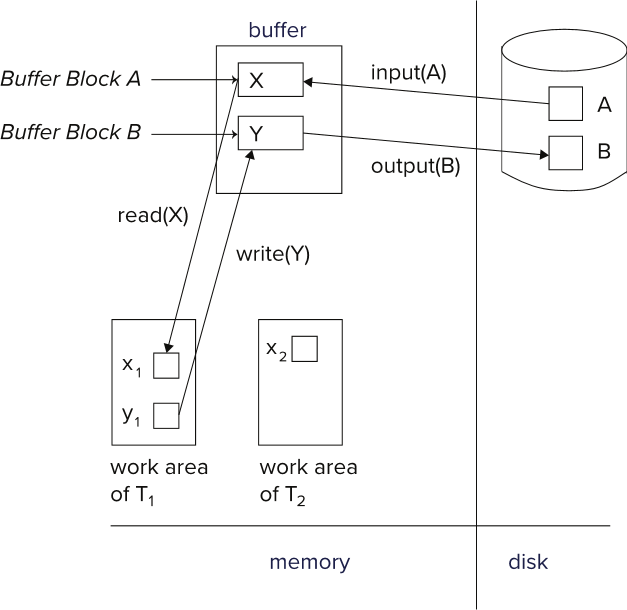
基于磁盘的数据库管理系统中的数据访问示例
在基于磁盘的数据库管理系统中,处理查询时通常会把整个索引加载到内存,而 B+树索引中一个索引节点的大小通常是一个数据块。每个被索引的 key 值在索引叶子节点中都有对应的索引项,索引项中包含该 key 值所对应记录的存储位置(Page ID + Offset);当一个数据块被加载到内存中的缓冲区时,DBMS 通过 Page Table 结构来维护 Page ID + Offset 的地址与内存缓冲区地址的转换。在访问数据时,先在 Page Table 中查找是否存在对应的 Page ID + Offset,如果没有则说明这条记录仍然在磁盘上,需要先把磁盘上数据块的读进缓冲区,然后再在 Page Table 中维护好地址映射关系。具体的实现过程是,DBMS 首先会在缓冲区中寻找可用的 Frame,如果没有就根据缓冲区替换算法选取脏页(Dirty Page)替换出去;假如选中了某个脏页进行替换,则需要对该位置加 Latch 锁来保证在替换过程中该位置不会被其他事务访问(Latch 后面会介绍)。在脏页写回磁盘后,系统就可以把目标数据块读入到缓冲区中的该位置,再将其在缓冲区中的地址写到 Page Table,维护好地址映射关系;在这些操作完成后再将 Frame 上的 Latch 锁释放。
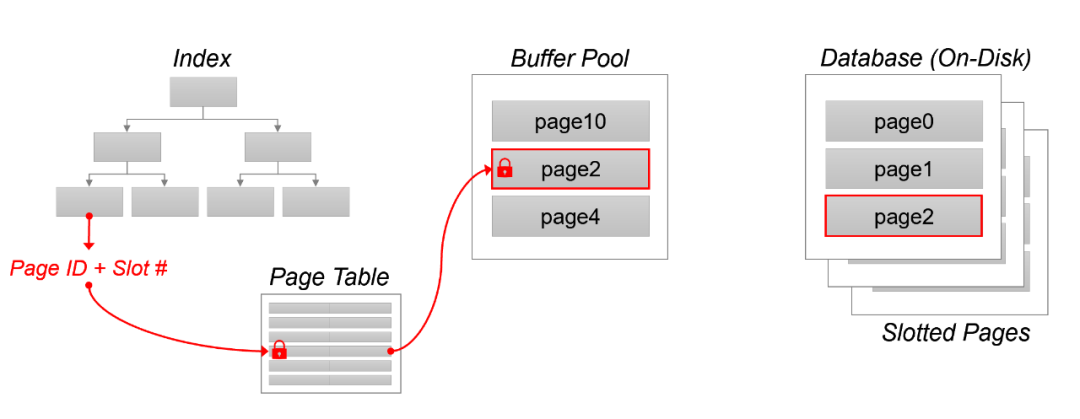
传统 DBMS 中的内存地址映射
对于传统基于磁盘的 DBMS 而言,即使内存缓冲区足够大,可以将所有数据加载到内存中,但访问数据过程中的地址映射和转换依然存在,只是省掉了将数据块从磁盘加载到内存的开销。即使数据已经全部被加载到内存,基于磁盘的 DBMS 性能上与内存数据库相比还是有很大差距,这是其中一个重要的原因。
总结来看,基于磁盘的 DBMS 和内存数据库在实现技术上一个重要区别是:在访问数据时,基于磁盘的 DBMS 需要通过地址映射将数据在磁盘上的地址转换成在内存中地址,而内存数据库在设计上则是直接使用数据在内存中的地址。
事务 AC ID 属性保证
在数据库管理系统中,需要保证并发访问场景下事务的 ACID 属性,即事务的原子性、一致性、隔离性和持久性。事务的 ACID 属性主要靠数据库管理系统中的两个机制实现,一个是并发控制,另一个是 Logging/Recovery 机制。
并发控制
传统基于磁盘的 DBMS 大部分是采用基于锁(Lock)的悲观并发控制,即事务在访问数据时先加锁,用完后再进行解锁,其他事务在访问数据时如果存在冲突则需要等待拥有锁的事务释放锁。传统 DBMS 一般会在内存中维护一个单独数据结构——Lock Table 来存放所有的锁,由 Lock Manager 模块进行统一管理,这样在内存中锁和缓冲区中的数据是分开存放和管理的。事务在访问数据时先向 Lock Manager 申请数据所对应的锁,然后再访问数据;执行结束后通过 Lock Manager 把锁释放,Lock Manager 能够保证所有事务申请和释放锁都是遵循严格的两阶段封锁协议(strict 2 phase locking protocol)。同时,并发控制机制所带来的开销与用户的实际业务处理没有直接关系,是用于保证事务一致性和隔离性的额外开销。内存数据库在访问数据时也需要加锁,但和基于磁盘的 DBMS 不同,锁和数据在内存中是存放在一起的,通常是将锁信息保存在数据记录 Header 中。为什么基于磁盘的 DBMS 要单独将锁信息放在 Lock Table 中,而内存数据库就可以把锁信息和数据存放在一起呢?因为在基于磁盘的 DBMS 中,数据块是有可能被系统从内存缓冲区中替换到磁盘上,如果锁信息和数据放在一起,一旦数据块被替换出去,Lock Manager 和所有事务都无法获得关于数据的锁信息。所以说对于传统基于磁盘的 DBMS 来讲,锁要单独维护在内存中,且需要始终保持在内存中,不能被替换出去。而对于内存数据库来说,不存在这样的场景。
实际上,数据库管理系统中有两种锁机制,分别被称为 Lock 和 Latch,目的都是为了保护数据的一致性不被并发访问所破坏。Lock 机制是对数据库逻辑内容的保护,一般来说拥有持续时间长,通常是事务执行的整个过程;并且 Lock 机制要支持事务的回滚以撤销事务对数据修改。而 Latch 机制是为了保证内存中特定的数据结构不会因为并发访问而导致错误,比如在多线程编程时有一个共享队列发生插入、删除等操作时,需要 Latch 保证操作过程中的队列不受其他线程的干扰。Latch 的保持时长与操作有关,本次操作做完就结束,同时也不需要支持对数据修改的回滚。
所以传统 DBMS 如果要对缓冲区中的一个 Page 做操作则需要加 Latch;如果是修改数据库的内容则需要加 Lock,单独放在 Lock Table 维护和管理。下图是对 Lock 和 Latch 的一个简单对比。
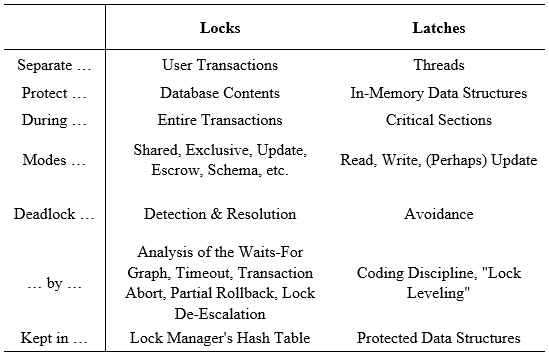
Lock 和 Latch 特征对比
Logging 和 Recovery
数据库管理系统中,Logging 和 Recovery 机制是日志来保证事务的原子性和持久性的方式。原子性意味着一个事务中的所有操作必须同时成功或者撤销,在执行一半做不下去时,可以按照日志进行回滚;持久性意味着数据如果丢失,可以根据日志来进行恢复。
在传统 DBMS 的 Logging 和 Recovery 中,最重要的概念是 WAL(Write-Ahead Log)——预写式日志。WAL 是指系统中所有更新操作都有对应的日志,而在日志没有落盘前,对数据的修改不允许落盘。系统中每条日志都有一个 LSN 号(Log Sequence Number),所有的 LSN 号单调递增,日志落盘的过程是向磁盘的连续写(顺序写)。但如果系统严格按照一条日志对应一条操作,日志落盘后马上将操作对数据的更新结果落盘,那么系统性能会受到很大影响。所以,大多数的 DBMS 会采用 Steal + No Force 的缓冲区管理策略。Steal 是指 DBMS 可以将未提交事务的更新刷到磁盘,不必等事务提交时再把更新刷到磁盘,提高了系统刷盘的灵活性和性能;如果在事务未提交时发生 crash,由于更新可能已经写到磁盘,这时就需要通过对日志的 undo 操作进行回滚。No Force 是指在事务已经提交后,对数据的更新可以依然存放在内存缓冲区中不写入磁盘,在合并其他事务的更新后再一次性写入磁盘,为系统提供优化空间。但 No Force 可能带来的风险是:如果事务已经成功提交但更新没有写到磁盘,此时出现 crash,则仍然在内存中的数据更新就会丢失,需要根据已经写到磁盘的日志(事务成功提交的前提是其所有日志都必须已经落盘)进行 redo 操作。
有了 WAL 和 Steal + No Force 机制后,就可以给基于磁盘的 DBMS 提供最大的灵活性,来优化磁盘 I/O。但对于内存数据库而言,所有的数据放在内存里,是否还需要这个机制呢?可以明确的一点是,内存数据库还是需要 Logging 的,但和基于磁盘的 DBMS 有所区别,在日志中只记载 redo 操作所需的信息,不记载 undo 所需的信息。大家可以想一下这是为什么?另一方面,内存数据库在 Logging 过程中不记录关于索引的更新,只记录对于基础表的更新,那 Logging 过程中所需写盘的内容就少了很多。而在内存数据库出现故障需要恢复时,首先从磁盘上保存的检查点(Check Point)数据和日志中恢复基础表,然后在内存中重新构造索引。
面向磁盘的 DBMS 性能开销
2008 年,SIGMOD 的一篇论文对面向磁盘的数据库性能开销做了分析,把整个数据库系统的开销做了划分。分析发现:假设一次业务处理的总开销是 100%,实际上只有 7%不到的资源是在真正处理业务逻辑;34%用于缓冲区管理如缓冲区的加载替换、地址转化等;14%处理 Latching;16%处理 Locking;然后 12%处理 Logging;最后 16%用于对 B 树索引的处理。也就是说,机器资源跑满负荷以后,真正用于处理业务逻辑的只有 7%。
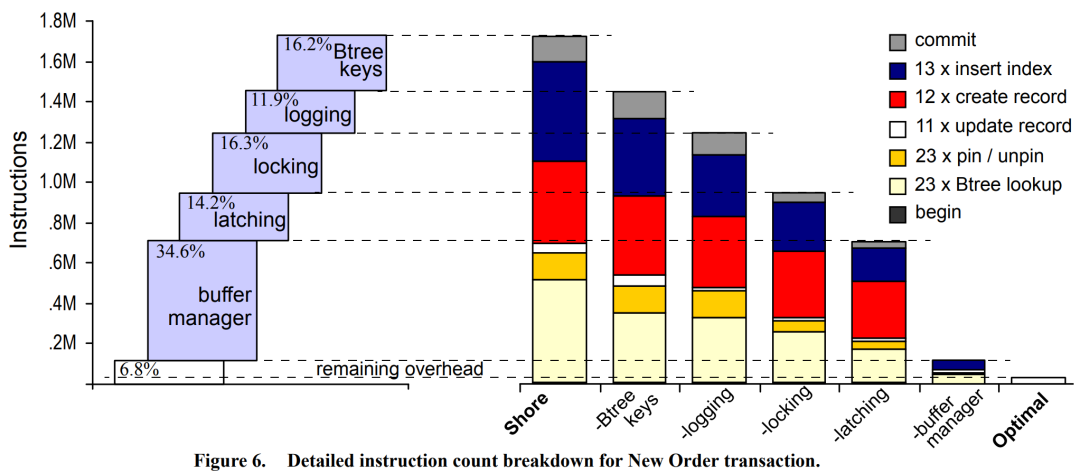
磁盘数据库系统性能开销
那么是否可以将开销大的部分去掉,来提高业务逻辑的资源占比呢?如果数据库是单用户的,没有并发竞争冲突,那么可以省去 Locking 和 Latching 等方面的开销。历史上也有一些单线程的解决方案,例如将数据库分成多个 Partition,每个 Partition 由一个线程处理等。但这样的方案具有明显缺点:每个 Partition 是串行处理,假如有一个长的事务在执行,串行处理将导致后续事务全部被阻塞,直到该事务结束。而且面向磁盘的系统在进行大规模事务处理时瓶颈是磁盘 I/O,如果单线程执行,在从磁盘读取数据时 CPU 将处于空闲状态。但对于内存数据库来说,所有数据存储在内存,磁盘 I/O 不是系统主要瓶颈,因此使用的技术与之前有了很大的差别。当然技术在发展过程中也经历了各种各样的尝试,某些技术的发展不适合于现实背景,慢慢就被人忘记了。可以看到,基于磁盘的数据库管理系统做了很多额外的管理工作,这些工作虽然不处理业务逻辑,但在保证业务逻辑正确性上不可或缺。对于内存数据库而言,面临的问题是应该做哪些优化来得到最优的性能。和基于磁盘的系统相比,内存数据库主存储是内存,但依然需要磁盘来做 Check Point 和 Logging,故障时要靠磁盘上的检查点数据和日志来恢复整个内存数据库。
内存数据库技术历史发展
内存数据库的发展大致可以分成三个阶段:1984 年到 1994 年的 10 年;1994 年到 2005 年的 10 年;2005 年以后到现在。第一个阶段出现了内存相关的处理技术;第二阶段出现了一些内存数据库系统;第三个阶段就是我们现在面临的场景。
1984 年 - 1994 年
在 1984 年到 1994 年间,学术界针对内存数据管理提出了很多假设,比如内存缓冲区可以放进全部数据,可以采用组提交和快速提交优化技术等。同时也提出了面向内存的数据访问方法,不再像基于磁盘的 DBMS 一样采用 Page ID + Offset 方式进行访问,而是在所有数据结构中都直接采用内存地址。还有面向内存的 T-tree 索引结构以及对系统按功能分成多个处理引擎,有的专门做事务处理,有的专门做恢复,相当于有两个核,一个专门负责事务处理,另一个负责日志处理。此外还有和 Partition 相关的主存数据库,把数据库分成很多个 Partition,每个 Partition 对应一个核(或节点),进程间没有竞争。可以看到,这个期间的数据库技术发展已经在考虑如果数据全部放在内存,可以采用哪些技术。但受限于当时的硬件条件,这些技术并没有得到大规模应用。

1994 年 - 2005 年
1994 年到 2005 年间出现了一些商业内存数据库系统,比如贝尔实验室研发的 Dali、Oracle Times Ten 的前身 Smallbase 等。同时,也出现了一些面向多核的优化系统如 P*-Time(现在是 SAP-HANA 事务处理引擎)。当时也有一些 Lock-free 的实现技术被应用于内存数据库系统,即无锁的编程技术和数据结构。

前两阶段小结
前两个阶段的技术大致可以分成这样几类:1、解决 Buffer Pool 的 In-Direction 访问:把间接访问替换掉,换成直接的内存地址访问;索引的叶子节点不再放 Page ID 和 Offset,而直接是内存地址。2、Data Partition:切分数据,不做并发访问控制的一类技术。3、Lock-free 和 Cache-Conscious:相较于面向磁盘的数据库管理系统把一个索引节点存储在一个数据块中,内存数据库中一个索引节点是一个或几个 Cache Line 的长度。4、粗粒度的锁:一次锁一张表或一个 Partition,而不是一条记录,但这种技术现在使用较少,因为多核场景访问竞争激烈,粗粒度锁可能导致并发程度降低。(目前使用较少)5、Functional Partition:把系统按照功能进行切分,每一个线程负责特定的功能等。(目前使用较少)

DBMS 历史技术总结
数据库系统的现代化发展
在现在的环境中,硬件条件基本有三个特点:1. 内存大而便宜;2. 多核 CPU(从主频提升转变到内核数的提升);3. Multi-Socket 即多核多 CPU,意味着处理的并发程度可以越来越高。这些都是数据库系统研发在当下所面临的情况。

现代硬件环境对于内存数据库而言,CPU 和磁盘 I/O 不再是主要瓶颈,因此优化技术目前主要从以下角度来考虑:- 去掉传统的缓冲区机制:传统的缓冲区机制在内存数据库中并不适用,锁和数据不需要再分两个地方存储,但仍然需要并发控制,需要采用与传统基于锁的悲观并发控制不同的并发控制策略。
尽量减少运行时开销:磁盘 I/O 不再是瓶颈,新的瓶颈在于计算性能和功能调用等方面,需要提高运行时性能。
采用编译执行方式:传统数据库多采用火山模型执行引擎,每一个 Operator 都被实现为一个迭代器,提供三个接口:Initial、Get-Next、Closed,从上往下依次调用。这种执行引擎的调用开销在基于磁盘的数据库管理系统中不占主要比重(磁盘 I/O 是最主要瓶颈),但在内存数据库里可能会构成瓶颈。假设要读取 100 万条记录,就需要调用 100 万次,性能会变得难以忍受,这就是内存数据库中大量采用编译执行方式的原因。直接调用编译后的机器代码,不再需要运行时的解释和指针调用,性能会有效提升。
可扩展的高性能索引构建:虽然内存数据库不从磁盘读数据,但日志依然要写进磁盘,需要考虑日志写速度跟不上的问题。可以减少写日志的内容,例如把 undo 信息去掉,只写 redo 信息;只写数据但不写索引更新。如果数据库系统崩溃,从磁盘上加载数据后,可以采用并发的方式重新建立索引。只要基础表在,索引就可以重建,在内存中重建索引的速度也比较快。
本文小结
本篇主要介绍了基于磁盘的数据库管理系统与内存数据库管理系统在几个实现方面存在的主要异同,以及内存数据库从 1984 年开始到现在的技术发展。后面会继续分享关于内存数据库技术的发展,从数据组织、索引、并发控制、编译查询和持久化角度出发,介绍并对比几款主流内存数据库产品的实现技术。
注:本文部分材料来自于:
1. VLDB 2016 会议上的现代主存数据库系统教程(Modern Main-Memory Database Systems Tutorial)
2. CMU(卡耐基梅隆大学)Andy Pavlo 教授的高级数据库系统(Advanced Database Systems)课程
作者介绍:
本文转载自大数据开放实验室,已经过对方授权。大数据开放实验室由星环信息科技(上海)有限公司运营,致力于大数据技术的研究和传播。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 1 条评论