
一、背景
目前,越来越多的 AI 场景将 AI 能力直接部署在移动端,其优势主要在于实时、省流、以及安全性等方面,也称为端侧 AI。端侧 AI 给移动端产品带来巨大的想象空间,促进了移动互联网下半场的繁荣。
然而在移动端直接部署 AI,成本相对较高。首先需要选择开源的移动端预测引擎,并将模型转换为该引擎所支持的格式,如百度支持多平台的高性能预测引擎——Paddle-Lite。虽然预测引擎已经尽量设计的简单易用,并且对移动端开发者友好,但还是有一定的学习成本;预测引擎集成完毕,业务开发中还需要考虑模型资源的下发及加载,输入的前处理,输出的后处理,资源释放,模型升级,模型加解密等诸多环节。
另外,有些特殊业务场景可能还会用到不同的预测引擎,此时若面向不同预测引擎的 API 进行开发,将会增加业务开发和维护成本。在此背景下,也是在百度 App 多次移动 AI 部署的经验总结中,MML 应运而生。
二、MML 架构设计
MML(Mobile Machine Learning)作为移动端 AI 统一接入方案, 其架构设计如下图:
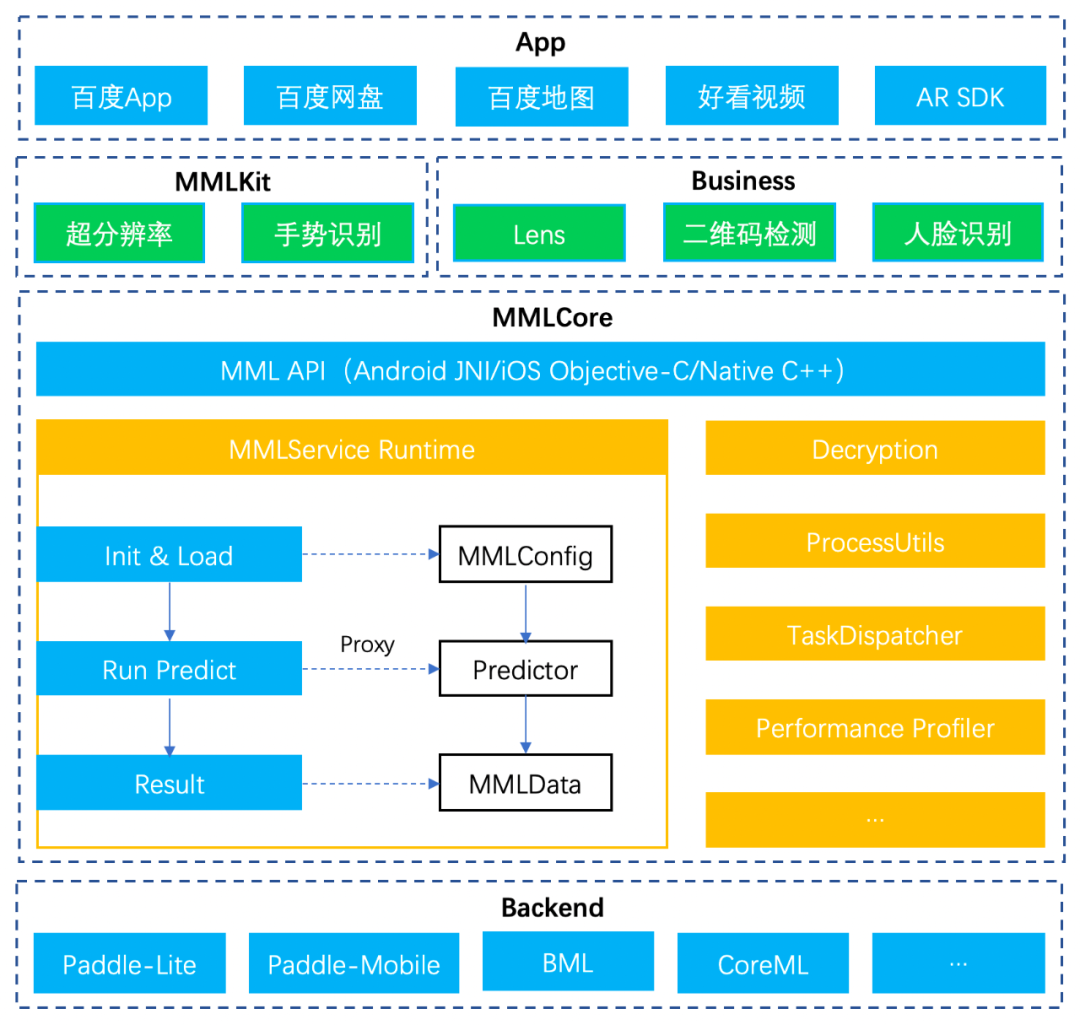
最底层是移动端预测引擎,这里也称为 Backend,例如百度的深度学习引擎 Paddle-Lite,Paddle-Mobile(Paddle-Lite 的前身),百度的机器学习引擎 BML,以及苹果的 CoreML 等。
往上则是 MML,是处于底层预测引擎与上层业务之间的隔离层。对于上层业务,其屏蔽了底层不同预测引擎的细节,使上层业务面向统一的接口开发,并提供多种基础能力来提高开发效率。例如百度 App 目前正在将预测引擎从 Paddle-Mobile 升级到 Paddle-Lite,如果每项 AI 业务之前都是通过 MML 接入的 Paddle-Mobile,那么升级到 Paddle-Lite 将非常容易,接口调用上几乎没有差别,只要指明所使用的预测引擎即可,后面我们可以看到 MML 是如何抽象这些细节。
再往上则是业务层,如百度 App 中的 Lens,图片/视频超分辨率等 AI 能力。另外,MML 也会逐步对一些通用 AI 能力进行封装,如超分辨率,手势检测等,在未来随 MML 一起开源,进一步帮助开发者降低移动端 AI 部署成本。所以 MML 本身可以分为两层,包括基础层 MML Core,以及通用 AI 能力层 MML Kit。最上层则是宿主 App。
三、MML Core
MML Core 作为基础层,对所支持的多款预测引擎的 Api 进行了抽象封装,使得开发者可以面向统一接口编程,业务代码与预测引擎的细节隔离开来。目前,预测引擎的推理过程基本都可以抽象为初始化,前处理,推理,后处理,释放资源五个步骤。因此,不管开发者使用何种预测引擎,只要是 MML 所支持的,都可以通过 MML 的抽象接口进行开发,只要指定所用 Backend 即可,添加或切换新的 Backend 将会非常方便。同时,MML 不仅提供 Java 和 OC 接口给移动端开发者使用,还提供了 C++接口,这样不仅降低性能损耗,还可以双端共用一套代码。
MML Core 除了对预测 API 的抽象封装,还提供了多种基础能力和工具集,包括模型解密,前后处理工具集,以及任务调度,profiler 统计等。
1. 工具集
1.1 模型解密
模型的安全是移动端 AI 部署的一个重要问题,MML 集成了百度自研的模型加解密算法,可以在内存中对加密模型进行解密。另外,业务方也可以选择自己解密,或者交给 Backend 解密。
1.2 前后处理工具集
深度学习模型,对输入数据有各种各样的要求,如数据类型,数据排布,以及尺寸等等,输出数据同样也需要进行相应处理才能交给上层使用。这些操作如果都使用 OpenCV 来实现,性能可能达不到上线要求,MML 前后处理工具集对多类 OpenCV 函数进行了汇编级优化,避免前后处理成为性能瓶颈。
1.3 任务调度
任务调度是 MML 目前仍在完善的功能。一个模型在某款移动设备上运行,在 CPU 上更快,还是在 GPU 上更快,目前采用的动态测速方式会进一步升级,根据模型计算量以及设备硬件信息来推断和决定运行在哪里,以及更进一步地对模型进行混合调度,使部分算子运行在 CPU,部分算子运行在 GPU。
2. 接下来,我们看一下使用 MML 进行预测的各个步骤:
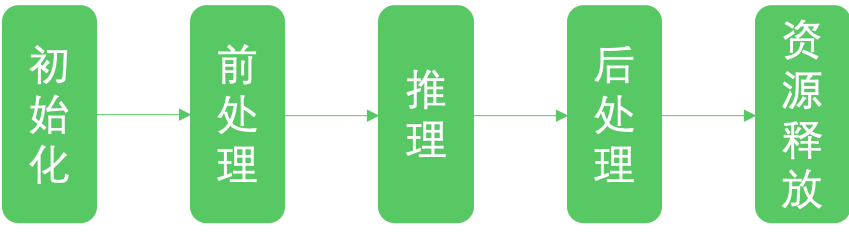
2.1 初始化
首先需要初始化 MML 预测实例,一个示例对应一个模型,同时需要设置预测精度,模型路径,Backend 类型,以及 Backend 专用的一些配置信息。最后 load 方法将会使用指定的 Backend 加载模型。
MMLMachineService *predictor = new mml_framework::MMLMachineService();MMLConfig config;config.precision = MMLConfig::FP32; // 预测精度config.modelUrl = modelDir; // 模型路径config.machine_type = MMLConfig::MachineType::PaddleLite; // Backend类型MMLConfig::PaddleLiteConfig paddle_config; // Backend专用configconfig.machine_config.paddle_lite_config = paddle_config;predictor ->load(config);2.2 前处理
前处理主要是对用户的输入数据进行操作,例如对图片数据进行类型转换,缩放等,MML 提供了前后处理工具集,这些方法是经过 ARM 汇编或 GPU 优化的,如果是 MML 还未支持的操作,则可以使用 OpenCV 完成。对数据完成前处理后,可以通过 predictor 的 getInputData 方法创建 MMLData 数据容器,传入的 index 参数表示模型的第几个输入,因为有的模型需要多个输入数据。然后通过 resize 设置输入的维度信息,通过 mutable_data 申请所需内存,最后将用户前处理后的数据拷贝到该内存即可。
std::unique_ptr<const MMLData> input = predictor->getInputData(0);input->mmlTensor->Resize({1, 3, 224, 224});auto *data = input->mmlTensor->mutable_data<float>();2.3 推理/预测
设置好输入之后,就可以进行预测了,非常简单又令人激动的一步。
predictor ->predict();2.4 后处理
获取模型推理的结果,方式和前处理类似,通过 predictor 的 getOutputData 方法获取 MMLData 类型的输出,同样可以传入 index 表示获取模型的第几个输出,然后通过 shape 获取输出的纬度信息,通过 data 获取数据的指针,最后再通过 MML 的前后处理工具集进行相应操作。
std::unique_ptr<const MMLData> output = predictor->getOutputData(0);auto shape = output ->mmlTensor->shape();auto *data = output ->mmlTensor->data<float>();2.5 释放资源
delete predictor;四、MML Kit
MML 除了提供基础的预测 API 以及工具集,还会提供多种通用 AI 能力 SDK,包括超分辨率、手势识别等,这些 SDK 组成了 MML Kit。最初这些能力首先是在百度 App 部署上线,然而在迁移到其他 App 时,又有很多重复开发的工作,因此我们将这些通用 AI 能力进行封装,使用方甚至不用关心任何模型相关的问题,不用关心预测 Api 的细节,只需集成相应的 SDK 即可,极大地降低了重复部署的成本。后续的文章中,我们会详细介绍这部分的工作。
五、未来展望
未来,MML Core 会持续完善和优化目前的功能和工具集,MML Kit 也会提供更多的通用 AI 能力,并逐步在 Github 开源,为业界提供易用、稳定、安全的移动端 AI 统一解决方案,全流程帮助移动端开发者部署 AI 能力。
头图:Unsplash
作者:zhaojiaying
来源:百度 App 技术 - 微信公众号 [ID:gh_59f5931152fe]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




