

随着深度学习技术的快速发展,人工智能应用逐渐落地到各个生产生活场景,大大提升了生产效率,降低了生产成本。携程旅游的度假 AI 部门根据业务特征需求,已将计算机视觉,自然语言处理,机器翻译,语音识别和处理等多种主流 AI 技术逐步应用到旅游业务的多个场景,包括智能客服平台,搜索排序等。另外值得一提的是度假 AI 自主研发的机器翻译技术为全集团公司提供翻译服务,将为携程推进国际化进程发挥重要作用。
为了保证服务质量,模型复杂度逐渐提升,计算量不断增加,由此带来的问题也日益明显:一是计算资源需求增加所带来的成本上升;二是推理过程计算量过大导致响应时间延长,极大影响了用户体验,而训练速度太慢则降低了生产效率。因此优化训练和推理性能的需求尤为迫切。
本文将着重介绍 AI 应用的推理性能优化方法,从系统以及模型等层面阐述推理性能优化的一般方法,并从实际应用出发,给出了具体优化的实践案例和取得的部分成果以及对未来发展方向的一些展望和思考。
一、推理性能优化的背景和发展现状
当前绝大多数人工智能应用都是基于深度学习技术,在数据驱动下建立算法模型,再经过训练测试、工程部署和推理实现完成。某个具体的算法模型能否最终成功落地为产品,满足场景需求,推理性能是关键变量之一。影响这个关键变量的因素非常多,包括硬件配置,工程部署方式,算法和模型复杂度以及深度学习框架等。
1.1 推理服务的性能评价指标
深度学习推理服务根据应用需求和特征不同,对性能需求也有所不同。比如计算机视觉和自然语言处理,机器翻译等服务主要是计算密集型应用,对计算资源需求较高;搜索推荐类的应用的输入数据特征维度高,更偏向于 I/O 密集型。
无论是哪种应用,都用延迟和吞吐作为常用的服务性能指标。在线类的应用延迟敏感,对响应时间要求高,而离线类的应用则侧重于批量处理的高吞吐需求。
具体来说,延迟(latency)可以细分为平均延迟,90 线,95 线和 99 线(99%的请求所达到响应时间)等,吞吐(throughput)则表示每单位时间处理的请求数(QPS/TPS),或者字符数(CPS)等,整体服务的并发度取决于两者的共同表现。
除此之外,还有一系列用来反映服务处理质量的指标,跟深度学习模型和算法关系密切,主要有精确率,召回率等,或者针对具体应用的特定指标,比如机器翻译常用的 BLEU 等。推理服务的终极目标就是满足服务质量的指标需求,实现低延迟和高吞吐。
1.2 主流的深度学习框架
工业界将深度学习技术快速落地的便捷有效的方式就是借助深度学习框架,部分框架兼顾训练和推理,将二者合二为一,比如 TensorFlow,PyTorch 和 MXNet 等主流框架,另外一些为了实现推理的高性能,将训练和推理进行分离,专门实现推理框架,比如 ONNX Runtime,TensorRT 等。
表 1 当前主流框架
针对推理的性能优化,除了开发新的推理框架,另一个方法是即时编译技术(Just-In-Time)。即时编译技术对于传统的计算机编程已经不算是新名词了,但是在 AI 领域的应用也是近两年才发展起来。比较常用的编译优化技术 TVM 目前已应用于深度学习的各个场景。
随着 tvm 功能的逐步完善,业界也将 tvm 称为一种特殊的推理框架。TVM 的设计初衷就是解决兼容性和推理性能问题,因为硬件平台越来越多样化,深度学习框架也层出不穷,经过 tvm 编译优化后可以方便地部署到不同硬件平台,并且获取满意的推理性能。图 1 是 tvm 的基本框架总览图,来自 tvm 主页(https://tvm.apache.org/)。
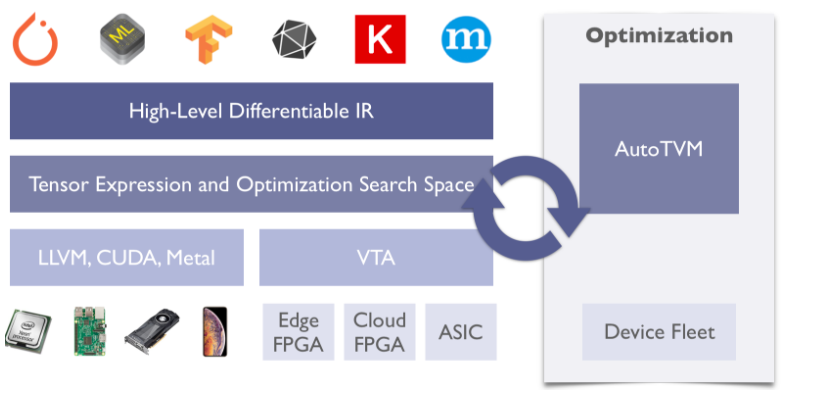
图 1 tvm 框架和主要功能总览
Tvm 主要优化包括:
high level 的计算图优化,包括算子融合,内存复用,数据布局转换等,主要跟模型和框架相关;
low level 的算子优化,数据局部性优化,并行优化以及硬件原语优化等。结合传统编译优化技术,充分利用硬件平台所提供的高性能数学库,从而实现高性能。
另外值得一提的是,AutoTVM 是它的突出特征之一,在给定的搜索空间进行自动优化搜索,这一优化思想可以延伸到很多优化场景。
深度学习推理服务的性能跟其他传统应用一样受很多因素影响,包括模型本身的算法复杂度,硬件平台,操作系统,部署方式,请求处理方式,是否缓存等等。深度学习框架的选择和优化只是其中一个影响因子。
综合来看,为了实现深度学习的高性能推理服务,我们需要一套科学系统的推理优化方法论,基于该方法论,充分考虑各种影响因素并逐个击破,才能达到最理想的符合应用场景需求的性能结果。
二、性能优化的一般方法论
无论是传统应用还是深度学习应用,提升性能都有相应的方法论,使用正确的方法能够事半功倍,大大提升效率。这一节内容我们重点探讨深度学习的推理优化应该如何来展开。
2.1 优化流程
深度学习应用的优化流程如下图所示。分为以下几步:
优化目标的确定取决于实际应用需求,主要体现在延迟目标和吞吐目标以及模型服务质量;
性能分析方法取决于所使用的深度学习框架,不同硬件平台也会提供相应的分析工具;
性能瓶颈定位,确定最耗时的模块和性能问题根源;
根据所定位的性能瓶颈,结合实际问题和已有优化经验制定优化策略,评估优化方案;
执行优化策略,这一步是最耗费时间和人力成本的;
进行优化方案的性能测试,判断是否达到目标,确保结果准确性和服务质量;
若不满足要求,再进入下一轮性能分析、优化和测试;如此循环往复,直到达成目标,完成最终的优化方案。
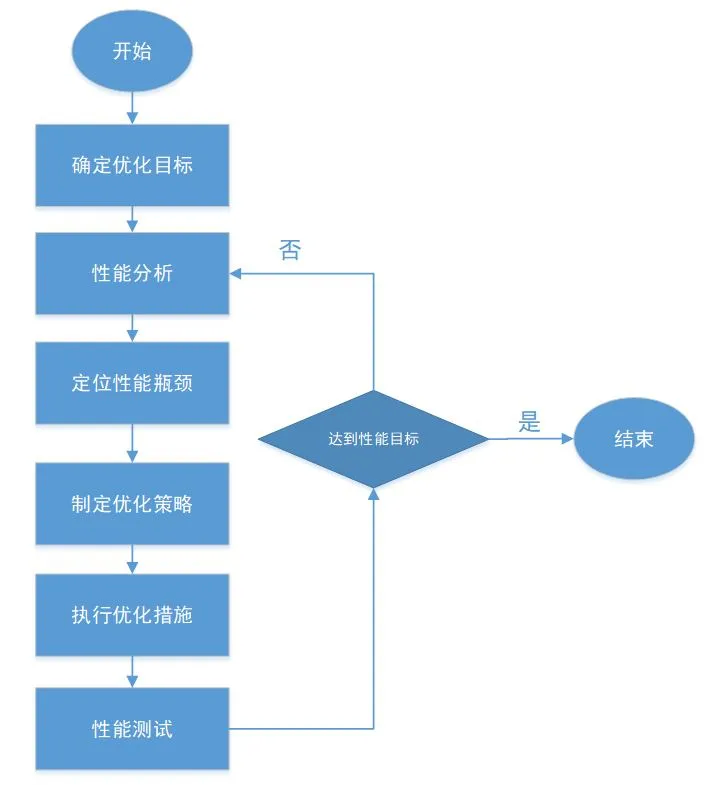
图 2 优化的一般流程
2.2 优化方法
针对深度学习推理服务,很多优化方法跟传统应用既有共性又有其特殊之处。从整体服务性能来看,可以简单的将其分为模型外的优化和针对模型的优化。其中模型外的优化跟传统应用的优化类似,使用的方法也基本相同,比如添加多级缓存,异步处理,考虑负载均衡等。针对模型本身的优化是本节的重点,下图是普通的深度学习推理服务的系统结构图。基于该系统结构图,本文将所有的优化分为两大类,分别是系统级优化和模型优化。
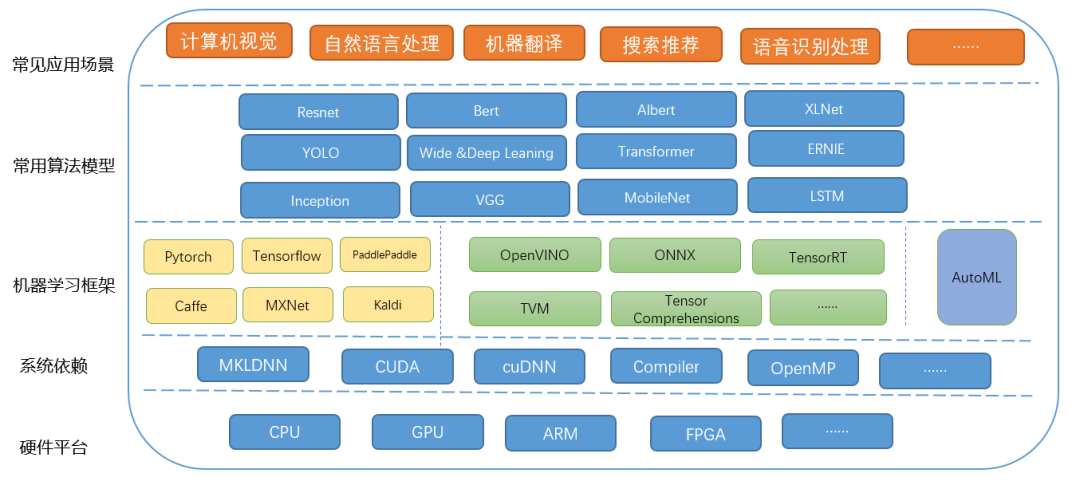
图 3 深度学习推理的主要技术架构图
2.2.1 系统级优化
对于一个已训练好的模型,模型复杂度和计算量都不变的前提下,通过优化代码和运行时优化等手段提升软件的执行效率,充分压榨硬件平台的性能和利用率,这样的优化方式称为系统级优化。
系统级优化可以分为多个层次,分别对应于深度学习推理服务的系统结构层,针对每一层都有相应的优化方法,根据不同硬件平台有不同的实现。例如 CPU 平台基于 SIMD 指令集加速和数学库 MKL-DNN 加速,GPU 平台使用 cuDNN 加速等。下图描述了系统级优化的不同层级和实现方法。
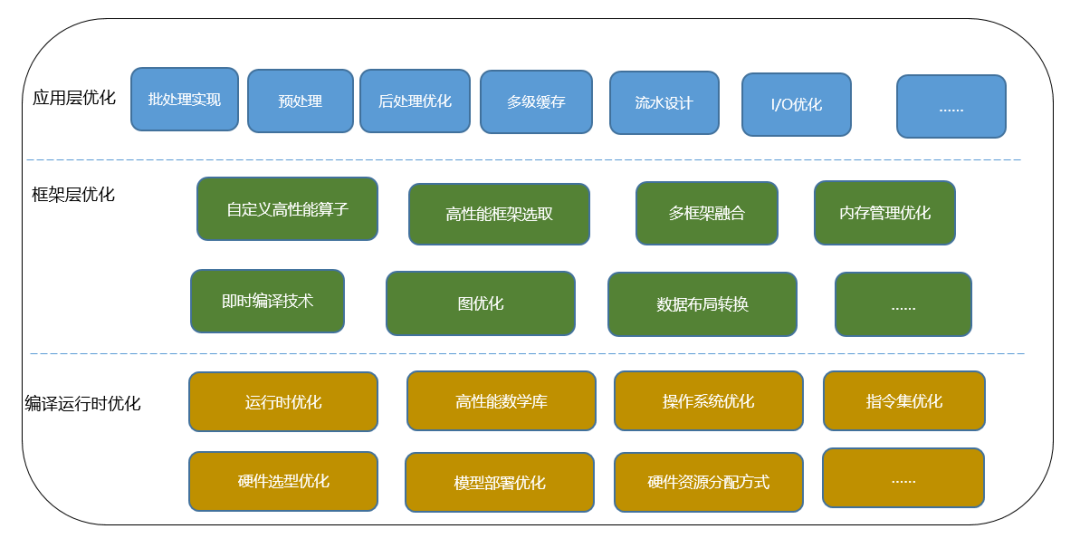
图 4 深度学习推理的系统级优化
深度学习模型大多数是计算密集型应用,在优化的过程中,同样需要遵循几大原则,一是尽量提升代码并行效率,充分发挥 cpu 或者 gpu 的核心利用率;二是提升计算访存比,同时想办法隐藏内存访问延迟;三是尽量提升访存命中率,降低访存带宽需求;四是充分发挥硬件的特殊性能,例如特定的硬件指令集等。
2.2.2 模型优化
实际 AI 应用部署时,充分提升硬件利用率的优化往往不足以达到推理目标需求,尤其对于计算复杂度较高的模型。因此需要保证模型质量的前提下,降低模型计算量,从而实现更好的优化效果,这种方式称为模型优化。模型优化的方式很多,如下图所示。
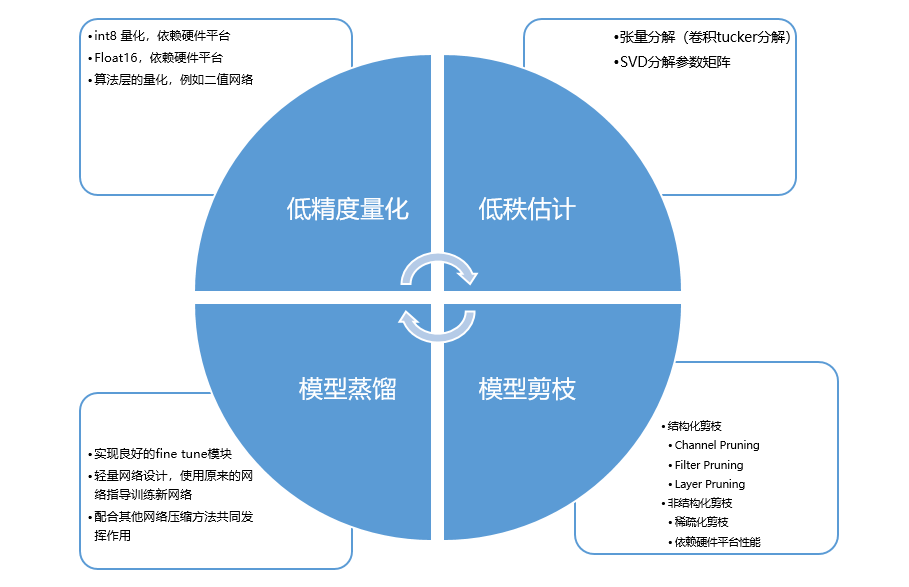
图 5 深度学习推理的模型优化
这些方法可以同时使用,但是具体效果和对推理质量的影响取决于实际模型和应用。总结而言,低精度量化和模型剪枝广泛应用于计算机视觉模型的压缩优化,尤其是分类模型,但是优化效果依赖于硬件平台的实现,例如 CPU 的 VNNI 指令集,GPU 的 Tensor core 等。低秩估计更多是针对耗时较多的算子从数学角度进行优化,提升效果和压缩效果比较有限。模型蒸馏概念比较广泛,不依赖任何框架和硬件平台,配合其他压缩方法使用往往能收获不错的效果。模型优化除了提升性能,还可以减少参数量,从而减小了模型尺寸,降低内存占用量,使得移动端部署更加可行。
将模型压缩优化和系统级优化结合使用,能更好地提升总体推理性能。
三、优化实践案例
本节内容将基于上述优化方法论提供一些优化案例。这些模型都已成功应用到携程旅游的实际业务中,包括图形图像,自然语言处理和机器翻译等多个场景。
下面重点以 Transformer 翻译模型为例阐述优化实践过程。Transformer 翻译模型基于 Encoder-decoder 结构,其中 encoder 主要包含 self-attention, FFN(Feed Forward)和 residual connection 等结构,decoder 包含 self-attention,交叉 attention,FFN 和 residual connection 等。图 6 给出的具体的图结构。
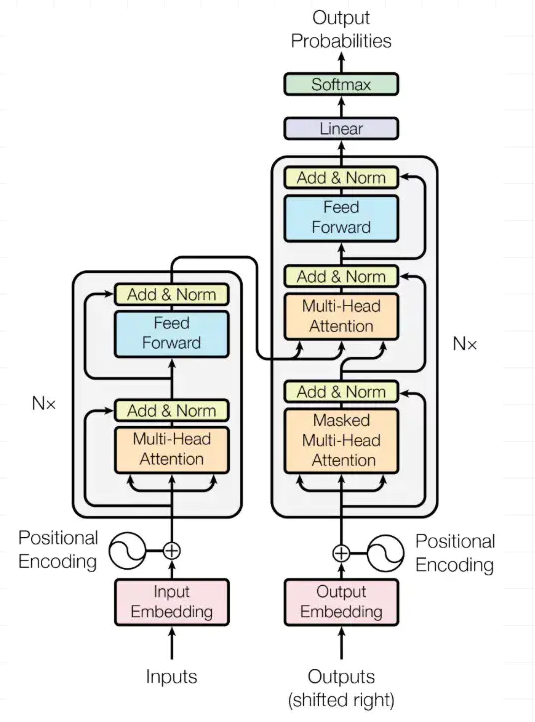
图 6 Transformer 模型结构
无论是 cpu 还是 gpu 平台,我们使用 tensorflow 的 timeline 进行性能分析发现:
典型的计算密集型应用,主要耗时集中在矩阵乘法,尤其是 self-attention,交叉 attention 和 ffn 等;
对 CPU 和 GPU 的核心利用率都不高,cpu 利用率只有 40%左右;
self-attention 由大量零散的算子构成,同时还存在一些可避免的 transpose 操作;
由此可以确定优化方向:
优化矩阵乘法的性能,例如充分利用硬件平台的高性能数学库 mkl 和 cuDNN
优化内存布局,避免冗余的访存操作,尤其是 transpose;因为核心利用率低的原因之一很可能是内存访问开销过大,导致计算核心没有充分利用,transpose 操作和过多的数据存取操作或者内存布局不合理都可能引起该问题;
针对硬件平台进行微架构优化,提升多个核心的并行计算效率;
大量零散的 python 算子势必带来大量的 op kernel 启动和存储开销,进行算子融合是最有效的解决方法。
因此,我们实现对 transformer 的算子融合和算子重写,合理设计内存布局,降低访存开销,再结合硬件平台进行微架构和编译运行优化,在 cpu 和 gpu 平台都取得了明显的提升。在实际线上业务部署时,同时采用批处理等模型外的优化措施,大大提升了翻译服务的性能。
图 7 是 Transformer 翻译模型基于 T4 GPU 平台使用系统级优化和 float16 低精度优化后的结果,图中给出的是 token 长度为 32 不同 batch 大小时的响应时间。
实际测试中,我们发现 token 越大,float16 的优势越明显。图 8 是 batch=1 时,使用不同 token 长度进行测试的结果,纵坐标表示优化前后的吞吐,每秒处理的 token 数。由于翻译在 GPU 平台耗时主要在于解码,这里的 token 指的都是解码长度。
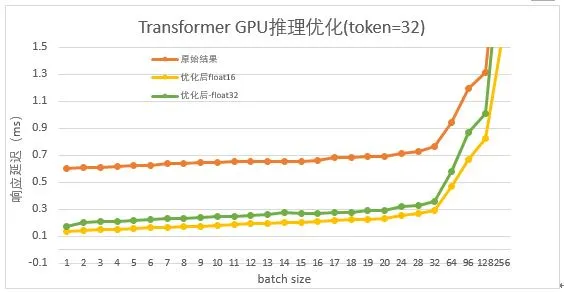
图 7 Transformer 翻译模型 GPU 延迟优化结果
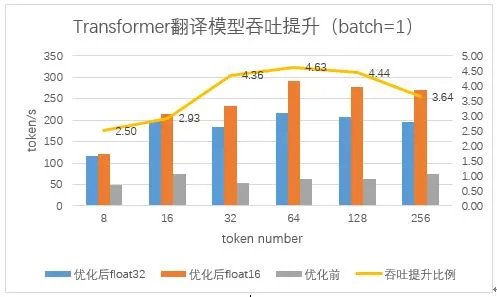
图 8 Transformer 翻译模型 GPU 吞吐优化结果
同样的,对于其他模型,我们也是用类似的分析和优化措施,取得一定的优化成果,如图 9 所示。所测试平台为 CPU: Intel® Xeon® Silver 4210CPU @ 2.20GHz,CPU 平台使用 8 个逻辑核进行测试,以固定算例的平均响应延迟为测试数据,优化后和优化前的加速比。其中,原始性能基于 tensorflow1.14 为测试基准,Bert 和 Albert 的 batch_size=1, seq_len=128. Transformer 翻译模型的 cpu 结果展示的是 token=16 的算例结果。
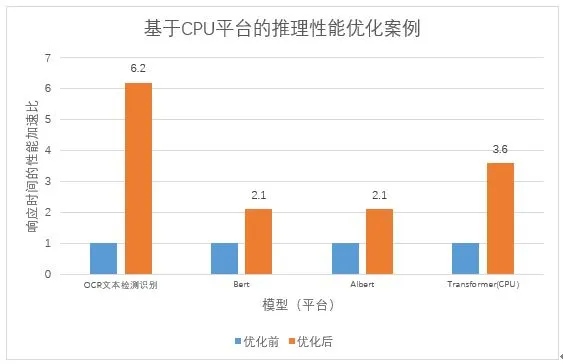
图 9 推理性能 CPU 优化加速比
目前展现的主要是系统级优化所取得的成果,经验证,推理服务的质量指标也完全符合旅游业务需求。对于推理服务的性能优化还在持续进行中,尤其是模型压缩的优化,需充分权衡模型质量指标,值得更多尝试,相信未来会有更大的提升。
四、未来发展与展望
AI 理论和模型日益完善,应用场景对模型精度等推理服务质量有更高的要求,模型深度和宽度都可能变大,对推理服务的性能需求只会有增无减。业界各种优化方法也已广泛使用并取得不错的成效,但突出的问题是,如果每增加一个模型都需要手动一点点优化,对技术人员要求较高,而且需耗费大量时间和精力,长久来看通过自动优化提升效率是未来推理模型的发展趋势。
尤其是编译优化技术的推广,tvm 的出现便是一个先行者,就像当初各种语言编译器的出现可以自动解决大部分传统应用的性能问题一样,深度学习的编译优化技术也会在未来发挥更重要的作用。同时,自动优化的普及能极大提升优化效率,完成 80%的优化工作,而对于性能的极致追求仍然依赖技术经验由工程师手动优化来实现剩下的 20%。
推理性能优化技术的逐步完善和提高将极大地降低人工智能应用的部署成本,提升生产效率,同时加快 AI 应用的落地,扩充应用场景,推动人工智能行业的整体发展。携程度假 AI 也将持续结合实际业务需求,进一步提升模型性能,降低成本,推动 AI 技术在旅游行业的全面落地,提供高质量的旅游服务,更好地服务客户。
作者介绍:
Shan Zhou,携程算法专家,主要负责携程度假 AI 应用在 CPU 和 GPU 平台的性能优化,涉及计算机视觉,自然语言处理,机器翻译和语音处理等多个领域。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论