

导读:今天分享一下 facebook 新发的深度学习推荐系统的论文:
Deep Learning Recommendation Model for Personalization and Recommendation Systems
https://arxiv.org/pdf/1906.00091.pdf
这篇文章概述了当前推荐系统实现的主要思路,提出了一种通用的模型结构 DLRM,与其他常见的 paper 不同,该篇有着浓浓的工业界风格,不仅和其他模型进行效果对比,还讲述了常见的特征如何处理,内在思维逻辑如何,在大规模的现实场景中会面临哪些问题。像大规模稀疏特征如何解决,比如用数据并行与模型并行相结合。以及 CPU 和 GPU 在实践中的性能如何,等等。
有在真实线上实践的同学应该都有过各自的思考,其实我觉得这里边的思路相关同学都是了解的,模型结构也不是壁垒,许多推荐系统问题在实践中更偏向于工程问题。像现今的开源框架都无法支持大规模推荐系统,所以各家其实都有自研的框架和配套设施,去解决海量用户 & 产品等对应的 embeddings,合适的 online training 等等问题
简介
目前个性化推荐有两个主要的方向,现在基本都投奔了深度学习的怀抱中。
1. the view of recommendation systems
早期系统雇佣专家们来对产品进行分类,用户选择他们喜好的类别并基于他们的偏好进行匹配。此领域后来演变成了协同过滤,推荐基于用户过去的行为,比如对产品的打分。Neighborhood methods 将用户和产品分组并用矩阵分解来描述用户和产品的 latent factors,获得了成功。
2. the view of predictive analytics
用统计学模型去分类或预测给定数据的事件概率。预测模型从原来的用简单的 linear and logistic regression 建模转向了用 deep networks。为了处理类别特征,一般采用 embeddings,将 one-hot 或 multi-hot vectors 转换到抽象空间的 dense respresentations。这里的抽象空间其实也就是推荐系统中的 latent factors 空间。
本文结合了上边的两种角度,模型使用 embeddings 处理稀疏特征,MLP 处理稠密特征,然后用统计技术进行显示的特征交叉。最后用另一个 MLP 来处理交差后的特征,得到事件的概率。我们将这个模型称为 RLRM,见图 1。
Pytorch & Caffe2 开源实现地址:
https://github.com/facebookresearch/dlrm
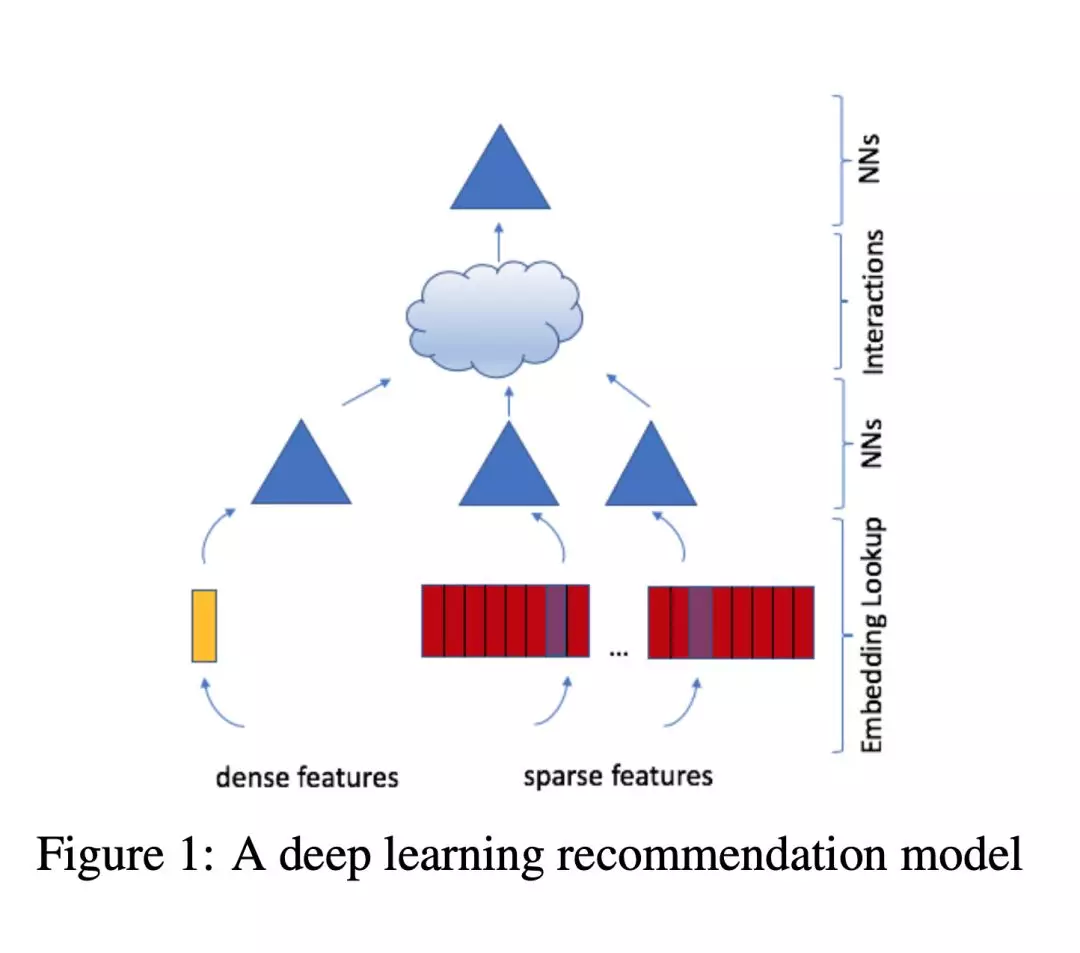
模型设计 &结构
1. Components of DLRM
① Embeddings
处理类别特征时,一般使用 embedding,实现的时候其实是搞了个 lookup table,然后去查对应类别的 embedding,所以 one-hot vector ei 就相当于是 embedding lookup ( 对位 i 是 1,其他为 0 ),embedding table
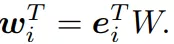
embedding 也可以被理解为是多个 items 的带权组合,mulit-hot vector
,,index ik 对应 items。一个大小为 t 的 mini-batch embedding lookups 可以写为:
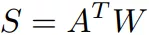
DLRMs 利用 embedding tables 将类别特征映射到稠密表示。但即使 embeddings 是有意义的,但我们要如何利用它们进行准确的预测呢?latent factor methods。
② Matrix Factorization
回顾推荐问题的典型场景,有一组用户 S 已经给一些产品进行了评价。我们将产品表示为 vector wi 将用户表示为 vector vj,共 n 个产品,m 个用户。( i,j ) S
The matrix factorization approach solves this problem by minimizing:
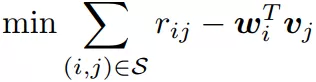
,R 其实就是 Reward matrix,W,V 是两个 embedding tables,每一行分别表示着 laten factor space 里的 user/product。
vectors 的点积代表对 rating 的预测。
③ Factoriation Machine
在分类问题中,我们会定一个预测函数:输入 x 预测 label y。我们定义 T={+1, -1},+1 代表有点击,-1 代表每点击,去预测 click-through rate。FM 在线性模型上引入了二阶交叉。 输入 x 预测 label y。我们定义 T={+1, -1},+1 代表有点击,-1 代表每点击,去预测 click-through rate。FM 在线性模型上引入了二阶交叉。
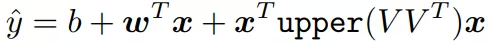
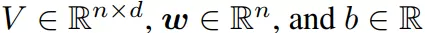
FM 明显不同于多项式核函数 SVM 的是,它将分解二阶交叉矩阵到 latent factors ( or embedding vectors ) 就像矩阵分解似的,更高效的处理了稀疏数据。通过仅用不同 embedding vectors 交叉显著减少了二阶交叉的复杂度。转为了线性计算复杂度。
④ Multilayer Perceptrons
当然,当前许多在机器学习上的成功是源于深度学习的兴起。这里边最基础的模型就是 MLP 了,一个由 FC layers 和激活函数组成的预测函数。
weight matrix ,bias for layer
这些方法被用来捕获更复杂的 interactions。比如在有足够的参数下,MLPs 有足够的深度和广度来适应数据到任意精度。各种方法的变种被广泛应用到了各种场景下,包括 cv 和 nlp。有一个特别的 case,NCF 被用来做 MLPerf benchmark 的一部分,它使用 MLP 来计算矩阵分解中 embeddings 直接的 interaction,而非 dot product。
2. DLRM Architecture
上边描述了推荐系统和预测分析使用的不同模型,现在我们将其组合起来,构建一个 state-of-the-art 的个性化模型:
users 和 products 可以用许多的连续特征和类别特征来描述。
类别特征,用同一尺寸的 embedding vector 表示。
连续特征用 MLP( bottom or dense MLP ) 转换为同样长度的稠密向量。
我们按照 FM 的方式处理稀疏特征,显示地计算不同特征的二阶交叉,可选的将其传给 MLPs。将这些 dot products 与原始的 dense features 拼接起来,传给另一个 MLP ( the top or output MLP ),最后套个 sigmoid 函数输出概率。
3. Comparison with Prior Models
许多基于深度学习的推荐模型使用类似的想法去处理稀疏特征,生成高阶项。
Wide and Deep,Deep and Cross,DeepFm,xDeepFM 都设计了特别的网络去系统性地构建 higher-order interactions。这些网络将他们特别的结构和 MLP 相加,然后传到一个 linear layer 使用 sigmoid 函数去输出一个最终概率。DLRM 模仿因子分解机,以结构化的方式 interacts embeddings,通过仅在最终 MLP 中对 embeddings 进行 dot product 产生交叉项来显着降低模型的维数。 我们认为其他网络中发现的二阶以上的高阶交互可能不值得额外的计算/内存消耗。
DLRM 与其他网络之间的关键区别在于这些网络如何处理 embedded feature vectors 及其交叉项。 特别是,DLRM ( 和 xDeepFM ) 将每个特征向量解释为表示单个类别的单个 unit,而像 Deep and Cross 这样的网络将特征向量中的每个元素视为一个新的 unit 来产生不同交叉项。因此,Deep and Cross 不仅会像 DLRM 中通过点积产生来自不同特征向量的元素之间的交叉项,还会在相同特征向量内的元素之间产生交叉项,从而产生更高的维度。
Parallelism
现在的个性化推荐系统需要大且复杂的模型去充分利用巨大的数据。DLRMs 尤其包含了非常多的参数,比其他常见的深度学习模型如 CNN,RNN,GAN 还要大几个数量级。
这导致训练过程可能要到几周甚至更多。为此,要想在实际场景中解决这些问题,就必须有效的并行化这些模型。
如上描述,DLRMs 用耦合的方式处理离散特征和连续特征。其中 Embeddings 贡献了主要的参数,每个表都要需要很多 GB 的内存,所以 DLRM 是内存容量和带宽密集型。Embeddings 的规模让数据并行变得不可行,因为他需要在每个设备上都复制 Embeddings。在很多场景下,内存的约束强制让模型的分布必须跨多个设备来满足内存容量的需求。
另一方面,MLP 的参数占用内存比较小,但是在计算量上占大头。因此,数据并行适合 MLPs,支持对不同设备上的样本进行并发处理,并且仅在累积更新时需要通信。并行 RLRM 对 embeddings 用模型并行,对 MLP 用数据并行,在缓解 embeddings 的内存瓶颈的同时让 MLPs 进行前向和反向传播。模型 & 数据并行的结合是 DLRM 这样结构和大模型尺寸的一个特别需要。这样组合的并行 Caffe2 和 Pytorch 都不支持,其他流行的深度学习框架也如此,因此我们需要设计一个定制的应用。会在未来的工作中提供详细的性能研究。
在我们的设置里,top MLP 和 interaction op 需要能连接到 bottom MLP 和所有 embeddings。因为模型并行已经将 embeddings 分散到各个 device 上,这就需要个性化的 all-to-all 的通信。在 embedding lookup 最后这块,每个设备都驻留着一个 embedding tables 的向量,用于 mini-batch 中的所有样本,需要沿着 min-batch 的维度进行拆分并于对应设备通信,如图 2 所示。
Pytorch 和 Caffe2 都没有提供原生的模型并行,因此我们通过显示的去不同设备上 mapping the embedding op 来实现。然后使用 butterfly shuffle operator 实现个性化的全对所有通信,适当地对所得到的 embedding vectors 进行切片并将它们传送到目标设备。在当前版本中,这些传输是显式复制,但我们打算使用可用的通信原语 ( 例如 all-gather 和 send-recv ) 进一步优化它。我们注意到,对于数据并行的 MLP,反向传播中的参数更新是用 allreduce 一起累积的,并以同步方式将参数复制到每个设备上,确保每次迭代前每个设备上的更新参数一致。在 PyTorch 中,数据并行性通过 nn.DistributedDataParallel 和 nn.DataParallel 模块在每个设备上复制模型并插入 allreduce 与必要性依赖。在 Caffe2 中,我们在梯度更新之前手动插入 allreduce。
Data
搞了三个数据集,随机集、人造集和公开数据集。前两个可用于从系统角度试验模型,它允许我们通过动态生成数据,消除对数据存储系统的依赖性来测试不同的硬件属性和瓶颈。后者让我们对实际数据进行实验并测量模型的准确性。
1. Random
连续特征用 numpy 根据均匀分布或者高斯分布来生成。
离散特征我们直接生成 embedding matrix 以及对应的 index。
2. Synthetic
有很多理由让我们定制化的生成类别特征的 indices,比如我们用了个特别的数据集,并因为隐私问题不想共享它。那么我们可以通过分布来表达类别特征。这可能有助于替代应用中使用的隐私保护技术,比如 federated learning。同样,如果我们想要研究内存行为,我们 synthetic trace 中原始 trace 的基本访问位置。
假设我们有所有特征的 embedding lookups indices 的 trace。我们可以记录轨迹中的去重后的访问和重复访问的距离频率(算法 1),生成 [14] 提到的 synthetic trace ( 算法 2 )。

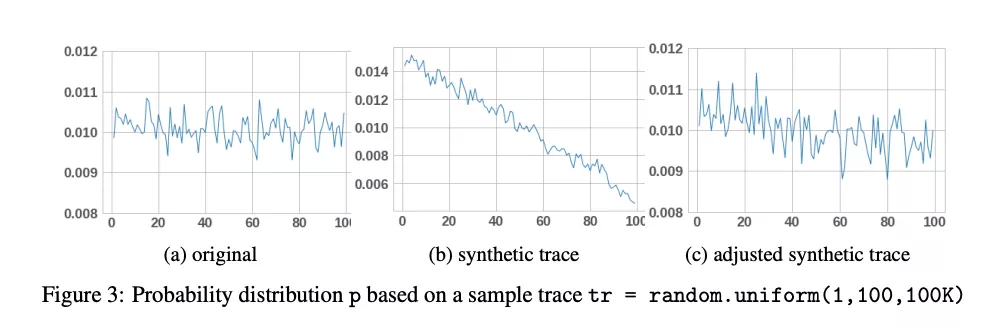
请注意,我们只能生成到目前为止看到的 s 次唯一访问,因此 s 是控制算法 2 中分布 p 的支撑集。给定固定数量的唯一访问,input trace 越长将导致在算法 1 中分配给它们的概率越低,这将导致算法 2 要更长的时间取得完整分布支撑集。为了解决这个问题,我们将唯一访问的概率提高到最小阈值,并调整支撑集以便在看到所有访问后从中删除唯一访问。基于 original and synthetic traces 的概率分布 p 的可视化比较如图 3 所示。在我们的实验中,original and adjusted synthetic traces 产生了类似的缓存命中/未命中率。
算法 1 和算法 2 设计过去用于更精确的缓存模拟,但是它们表明一般概念,那就是概率分布可以怎样用来生成具有期望属性的 synthetic traces。
3. Public
个性化推荐系统的公开数据比较少,The Criteo AI Labs Ad Kaggle 和 Terabyte 数据集为了做点击率预估包含了点击日志。每个数据有 13 个连续特征,26 个离散特征。连续特征用 log(1+x) 处理。离散特征映射到对应 embedding 的 index,无标注的离散特征被映射到 0 或 NULL。
Experiments
DLRM 实现地址 ( Pytorch and Caffe2 ) :
https://github.com/facebookresearch/dlrm
The experiments are performed on
the Big Basin platform with Dual Socket Intel Xeon 6138 CPU
@ 2.00GHz and eight Nvidia Tesla V100 16GB GPUs
1. Model Accuracy on Public Data Sets
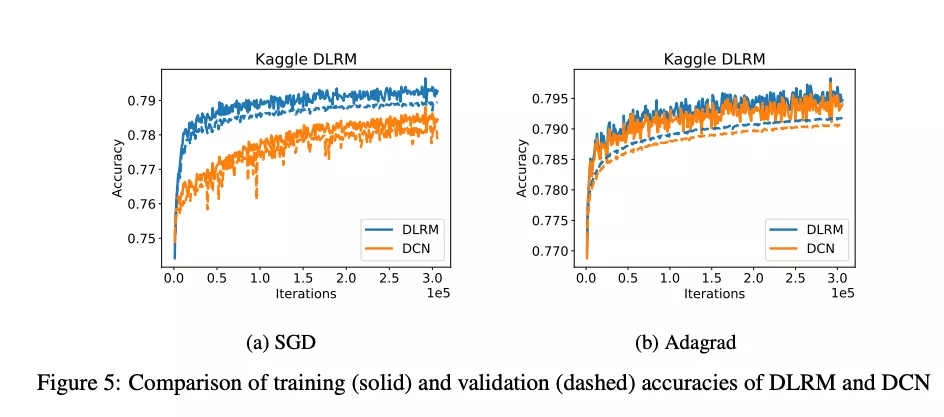
我们在 Criteo Ad Kaggle 数据集上和 Deep and Cross(DCN) 比较模型的准确率和性能,因为这个模型在同样数据集上有比较综合的结果。值得注意的是,模型的大小可以根据数据集中的特征数去调整。特别地,DLRM 包括用于处理稠密特征的 bottom MLP,其包括 512,256 和 64 个节点的三个隐层,以及由 512 和 256 个节点的两个隐层组成的 top MLP。而 DCN 由六个 cross layer 和一个 512 和 256 个节点的深度网络组成,embedding dimension 是 16,所以 DLRM 和 DCN 都大概有 540M 的参数。
我们画出了训练集和验证集在单 epoch 的准确率,每个模型都使用了 SGD 和 Adagrad 优化器,没有使用正则化。实验中 DLRM 在训练集和验证集的准确率都略高一些,如图 5。值得注意的是,这里边没有进行额外的调参。
2. Model Performance on a Single Socket/Device
这里使用 8 个离散特征+512 个连续特征的模型去测我们模型在单 socket device 上的性能。每个离散特征被处理为有 1M vectors 的 embedding table,vector dimension 是 64,这些连续特征等价一个有 512 维的 vector。让 bottom MLP 有两层,top MLP 有四层。我们在一个 2048K 的随机生成样本数据集即 1K 个 mini-batches 上评估模型。
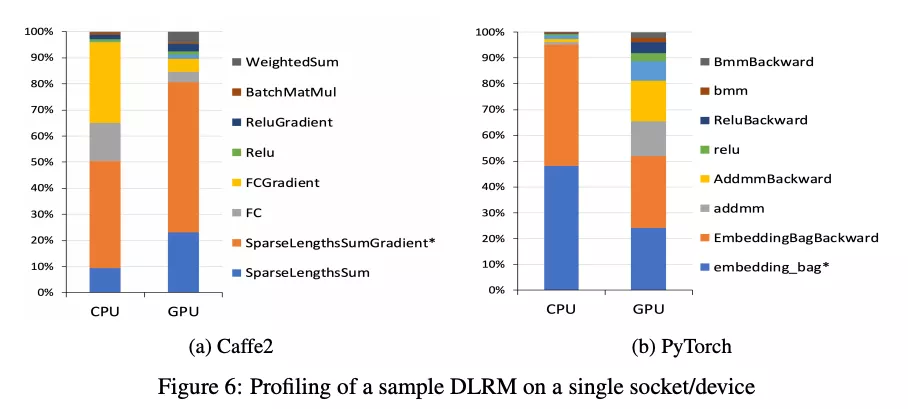
这个模型用 Caffe2 实现,在 CPU 上要跑 256s,GPU 上跑 62s,具体见图 6。如所预期,主要的时间花费在 embedding lookups 和全连接层。在 CPU 上全连接层的计算消耗显著,而 GPU 上几乎可以忽略。
Conclusion
在本文中,我们利用分类数据提出并开源了一种新的基于深度学习的推荐模型。尽管推荐和个性化系统已在当今工业界中通过深度学习获得了实用的成功,但这些网络在学术界仍然很少受到关注。通过详细描述先进的推荐系统并开源其实现,我们希望人们能关注到这类特别的网络,以便进一步进行算法实验、建模、系统协同设计和基准测试。
本文来自 DataFun 社区
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论