

自动语音识别(ASR)是一种将音频输入转换成文本的技术,目前基于深度学习的 ASR 系统往往面临数据量不足的挑战。Google Brain 团队最新推出的 SpecAugment,是一种简单的 ASR 数据增强方法。该方法从视觉角度出发,对音频频谱图进行数据增强。该方法简单、计算量小,且不需要额外的数据,并且能有效提高 ASR 网络的表现性能,在 LibriSpeech 960h 测试集上达到了 5.8%的字错误率(结合语言模型),Switchboard 300h 测试集上达到了 6.8%的字错误率(结合语言模型),均达到了目前最先进的表现水平。本文是 AI 前线第 77 篇论文导读。
介绍
自动语音识别(ASR)是一种将音频输入转换成文本的技术,深度神经网络的发展推动了 ASR 的进步。ASR 在许多现代设备和产品中都有应用,如谷歌助手、谷歌主页和 YouTube。目前 ASR 的主流研究方向依然是设计更好的 ASR 网络结构。然而传统的 ASR 模型包含许多参数,当训练集的数量不足或不够全面时,模型往往会过度拟合训练数据,从而难以泛化到新数据上。
在图像分类领域,缺乏足够数量的训练数据时,可以通过数据增强来增加数据的有效数量,能够显著提高深度神经网络的性能。在语音识别中,数据增强方法通常指以某种方式对训练的音频波形进行变形(例如加速或减速),或添加背景噪声。这种方法能够有效地扩大数据集,因为在训练过程中,单个输入的多个增强版本也被输入到网络中。并且驱使网络学习相关特征,让网络变得更鲁棒。然而,现有的传统方法在增强音频数据的同时也带来了额外的计算成本,有时甚至还需要额外的数据。
在 Google Brain 团队最新的论文《SpecAugment:一种简单的语音自动识别数据增强方法》中,作者采用一种新的方法来增强音频数据,即将其视为视觉问题而不是音频问题。与传统的方法中增加输入音频波形不同的是,SpecAugment 直接将增强策略应用于音频频谱图(即波形的图像表示)。该方法简单、计算量小,且不需要额外的数据。并且该方法能有效提高 ASR 网络的性能,在 ASR 任务LibriSpeech 960h和Switchboard 300h数据集上达到了目前最先进的表现性能。
SpecAugment
在传统的 ASR 中,音频波形通常被编码为视觉表示,例如频谱图(spectrogram),然后作为网络的输入训练数据。训练数据的增强通常在波形音频转换成频谱图之前,因此在每次迭代之后,都需要生成新的频谱图。在新方法中,作者研究了增强频谱图本身的方法,而不是增强波形数据。由于该增强直接应用于网络的输入特征,因此可以在训练期间在线运行,而不会对训练速度造成严重影响。
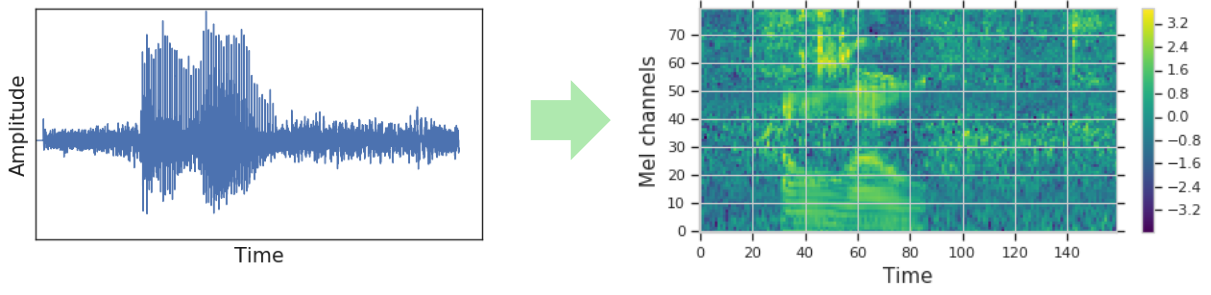
图 1 在输入网络之前,音频波形往往先转化成视觉表示(log 梅尔谱图)。
作者的目标是设计一种能直接作用于 log 梅尔谱图的数据增强策略,帮助网络学习到有用的特征。这些特征需要对时间方向上的变形、频率信息的部分损失以及语音片段的部分损失鲁棒,因此我们选择以下三种变形来组成 SpecAugment:
1. 时间变形,通过 tensorflow 的 sparse_image_warp 函数实现。给定一个时间步长为τ的对数梅尔谱图,我们将其视为一张图像,时间轴为水平维度,频率轴为垂直维度。对于时间步长为(W,τ-W)的图像,穿过图像中心水平线的某个随机点经变形后,处在其左或其右距离为 w 的位置,w 是从[0,W]的均匀分布中选择的数字。W 为时间变形参数。
2. 频率掩膜(Frequency masking),对 f 个连续的梅尔频率通道[f,f0+f) 应用掩膜,f 是从[0, F]均匀分布中选择得到,F 为频率掩膜参数,f0 从[0, v-f)中选择得到,v 代表梅尔频率通道的数量。
3. 时间掩膜(Time masking),对 t 个连续的时间步长[t0, t0+t)应用掩膜,t 从[0, T]的均匀分布中选择的数字,T 为时间掩膜参数,t0 从[0, τ-f)中选择。
图 2 给出了增强策略的示意图:
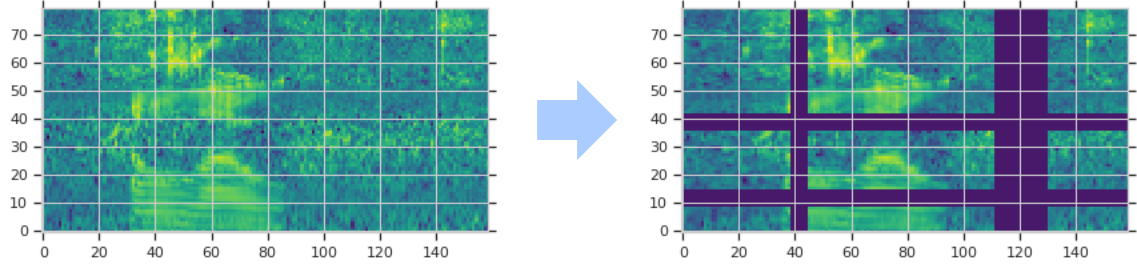
图 2 通过时间方向上的变形、连续时间步长(垂直方向)和梅尔频率通道(水平方向)的 mask 分块,对 log 梅尔频谱进行增强。频谱中被 mask 的部分显示为紫色。
图 3 给出了对单独输入进行单独增强的示意图:

图 3 从上到下分别为未经增强的基本输入的对数梅尔频谱图,以及经过时间变形、频率掩膜和时间掩膜增强后的对数梅尔频谱图。
当增强策略包含多个频率和时间 mask 时,多个 mask 可能会互相覆盖。因此,作者考虑了一些手动增强的策略:LibriSpeech basic (LB),LibriSpeech double (LD),Switchboard mild (SM)和 Switchboard strong (SS),参数总结如表 1:
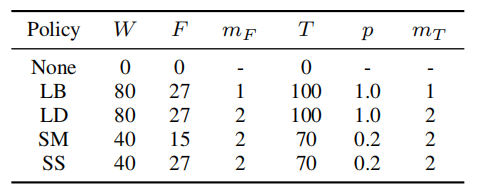
表 1 增强策略的参数。mF 和 mT 表示频率 mask 和时间 mask 的数量。
图 4 给出了一个使用 LB 和 LD 增强的对数梅尔谱图示例:
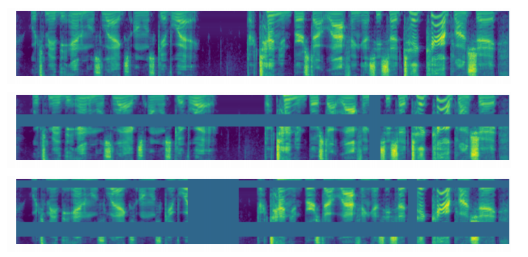
图 4 从上到下分别为:基础输入、LB 增强和 LD 增强的对数梅尔谱图。
测试模型
1. LAS 网络模型
作者使用Listen, Attend and Spell (LAS)网络作为 ASR 任务的模型,记为 LAS-d-w。输入的对数梅尔谱图经过 2 层卷积网络,得到的输出经过有 d 个堆栈的双向 LSTM 编码器,LSTM 单元大小为 w,产生注意力矢量(attention vector)。随后,注意力矢量输入 2 层 RNN 解码器,单元维度为 w,生成文本的词块(token)。通过单词量为 16k 的 LibriSpeech 和 1k 的 Switchboard 数据集,采用 Word Piece Model(WPM)对文本进行词块化。LibriSpeech 960h 的 WPM 用训练集的文本构建,Switchboard 300h 的 WPM 由训练文本和 Fisher 语料库中的文本构建。最终的文本通过束搜索得到。
2. 学习率策略
学习率是决定 ASR 网络表现的一个重要因素。论文中研究学习率策略有两个目标,一是验证较长的策略有助于提升网络最终的表现,二是引入非常长的学习率策略,能够最大化网络的表现性能。
在实验中,学习率策略包括提升、保持和指数衰减三个阶段。这三个阶段由三个时间节点定义(sr,si,sf)。除此之外,实验中还有另外两个参数控制时间尺度。第一个是在节点 snoise 处打开变分加权噪声,第二个是均匀标签平滑。标签平滑在学习率较小时会影响网络的稳定性,因此只在训练开始时加入标签平滑,在学习率开始衰减时取消该操作。
文中使用的两个基本策略如下:
1. B(asic): (sr, snoise, si, sf)=(0.5k, 10k, 20k, 80k)
2. D(ouble): (sr, snoise, si, sf)=(1k, 20k, 40k, 160k)
可以通过使用更长的训练策略提升训练网络的表现:
3. L(ong): (sr, snoise, si, sf)=(1k, 20k, 140k, 320k)
3. 与语言模型的浅聚合
尽管通过数据增强,网络可以取得最好的表现性能,但是可以利用语言模型进一步提升网络的表现。作者通过浅聚合将一个 RNN 语言模型整合入两个任务中。在浅聚合中,解码过程中的“下一词块(token)” y*由下式得到:
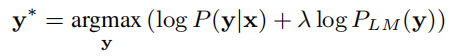
即使用基础 ASR 模型和语言模型对词块进行联合打分。
实验结果
1. LibriSpeech 960h
为了测试 SpecAugment 的增强效果,作者在 LibriSpeech 数据集上进行了实验。作者采用了三种 Listen, Attend and Spell (LAS)网络作为 ASR 任务的模型:LAS-4-1024、LAS-6-1024 和 LAS-6-1280,利用增强策略(无、LB、LD)和训练策略(B/D)的组合在 LibriSpeech 960h 数据集上训练。
ASR 网络的表现由网络生成的文本和目标文本之间的字错误率(Word Error Rate,WER)衡量。网络的所有参数都保持一致,只有输入网络的数据有所改变。表 2 给出了在 test-clean 和 test-other(含噪声)测试集上的测试结果。实验表明,SpecAugment 持续提升了网络表现性能,并且数据增强的程度越高时,较大的模型和较长的学习率策略的好处越明显。

表 2 不同网络、训练策略、增强策略在 LibriSpeech 测试集上的字错误率

图 5 网络在 LibriSpeech 测试集的表现性能对比图,蓝色为经过增强的数据输入,黄色为未经过增强的数据输入。LibriSpeech 测试集包含两部分,test-clean 和 test-other,后者的音频数据包含更多的噪声。
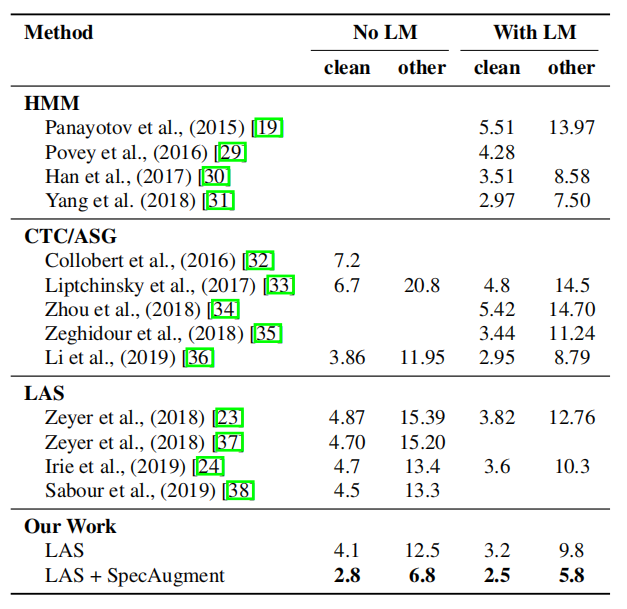
表 3 LibriSpeech 960h 字错误率
2. Switchboard 300h
在该数据集上,作者采用 LAS-4-1024 网络结构,增强策略分别为无、SM、SS 和学习率策略 B。表 4 给出了采用不同的数据增强策略、有无标签平滑的网络在 Switchboard 300h 数据集上的实验结果。从表 4 中可以看出标签平滑和数据增强在该语料库上具有额外的效果。
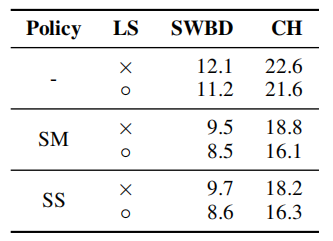
表 4 Switchboard 300h 字错误率,不使用语言模型。
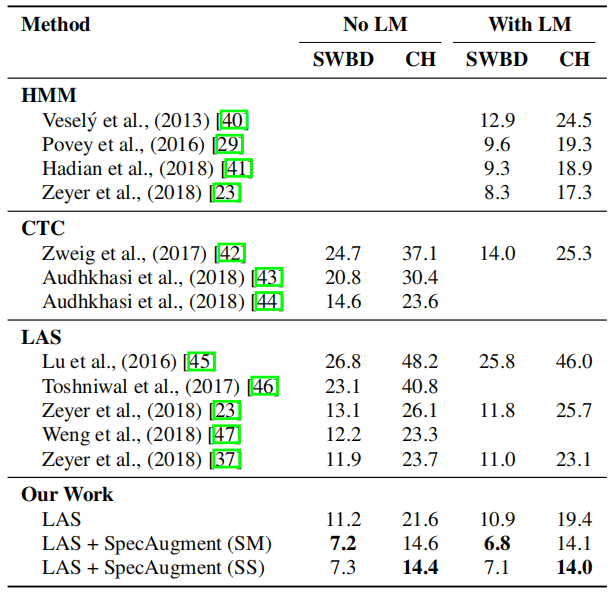
表 5 Switchboard 300h 字错误率
3.最优结果
通过增加网络大小、训练时间,该数据增强方法可以在 LibriSpeech 960h 和 Switchboard 300h 上取得目前最好的效果:

表 6 LibriSpeech 960h 和 Switchboard 300h 任务上之前 SOTA(state-of-the-art)的字错误率对比
该数据增强方案虽然方法简单,但是效果很强大,能够提高端到端 LAS 网络的性能,让它超越经典的 ASR 模型。
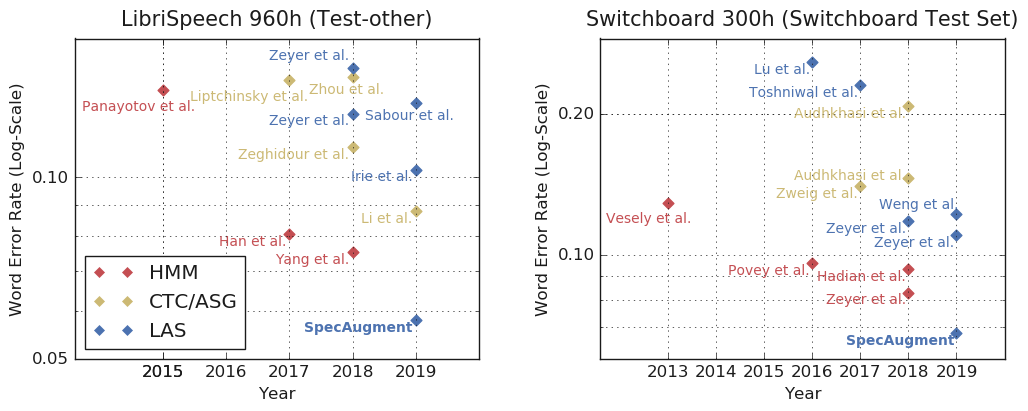
图 6 不同类型的网络在 LibriSpeech 960h 和 Switchboard 300h 任务上的表现。
讨论
1.时间变形有用,但不是提升表现的主要原因
表 7 给出了分别去除时间变形、时间掩膜和频率掩膜情况下的训练结果。时间变形的效果虽然小,但还是有的。因此在计算成本受限的情况下,时间变形作为影响最小,但成本最高的策略,应该首先被丢弃。
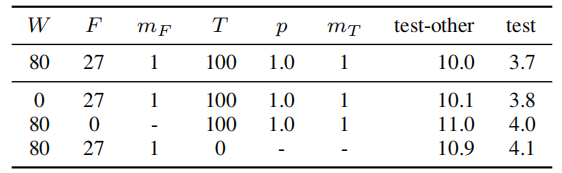
表 7 不同增强策略在测试集上的字错误率对比
2.数据增强使过拟合问题转化为欠拟合问题
SpecAugment 通过故意提供损坏的数据来防止网络过拟合。下图展示了网络在训练集和测试集的 WER 是如何随训练过程变化的。
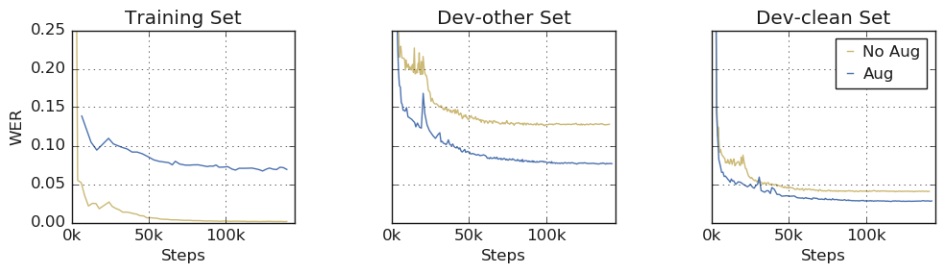
图 7 网络经过数据增强和未经数据增强在训练、test-clean、test-other 数据集上的表现对比
可以看出,如果不进行数据增强,网络在训练集上的性能近乎完美,而在 test-clean 和 test-other 的测试集上的性能则会大打折扣。另一方面,经过数据扩充,网络很难在训练集上取得完美表现,但是在 test-clean 数据集上表现得更好,并且在 test-other 数据集上取得了与之相当的表现。这表明网络不再过度拟合训练数据,提高训练性能将带来更好的测试性能。
3.常用的欠拟合问题解决方法可以提升网络性能
解决欠拟合有两个标准方法:更大的网络和更长的训练时间,从而在表现性能上取得显著的进步。当前给出的实验结果是通过不断应用增强策略获得的,然后可以建立更宽、更深的网络,并用更长的学习率策略对其进行训练,以解决欠拟合的问题。
4.语言模型
语言模型(Language Model,LM)通过利用从文本中学习到的信息,对提升 ASR 网络的表现性能起到重要作用。然而语言模型往往需要独立训练,并且占用内存很大,因此难以将其应用到小的设备上,如智能手机。但在研究中,作者发现了一项意料之外的结果:使用 SpecAugment 增强数据训练的模型在没有语言模型的帮助下,也能超越其他模型的表现。因此,尽管 LM 对网络有所助益,该研究结果预示了在实际应用中去掉语言模型,独立训练 ASR 网络的可能性。
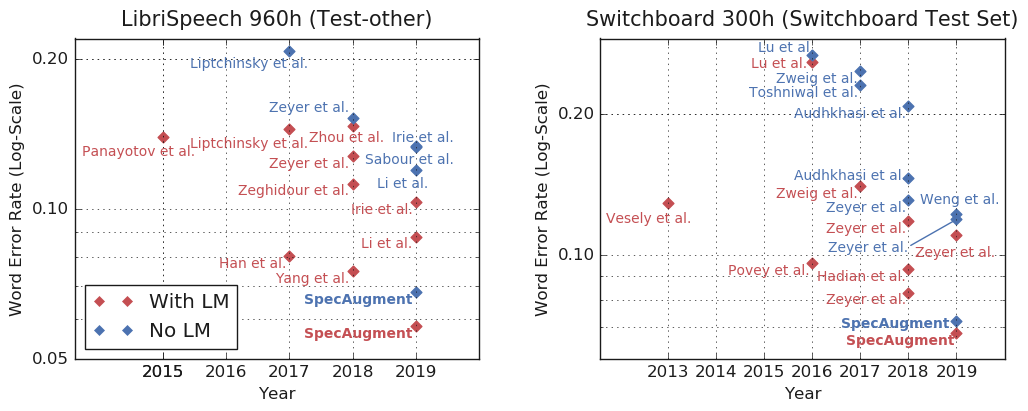
图 8 包含语言模型和不包含语言模型的字错误率对比。即使没有语言模型,SpecAugment 的表现也达到了最佳水平。
结论
本文介绍了 SpecAugment,一种简单的用于语音识别(ASR)的数据增强方法。SpecAugment 大大提高了 ASR 网络的性能。通过使用简单的手工策略增加训练集,即使没有语言模型的帮助,也能够让端到端的 LAS 网络在 LibriSpeech 960h 和 SwitchBoard 300h 任务上获得最佳表现性能。SpecAugment 将 ASR 从过拟合转换为欠拟合问题,可以通过使用更大的网络和更长的学习率策略来提升性能。过去,ASR 的大部分研究都集中在寻找更好的网络结构。但该的研究结果表明,寻找更好的训练网络的方法不失为一个有前景的研究方向。
查看 Google AI Blog:SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition
查看论文原文:SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
更多内容,请关注 AI 前线公众号


暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论