

导读: 视频是爱奇艺的核心内容,视频内容的精彩度分析,不仅关系着视频的分发,也关系着视频相关广告的投放等,比如能否将广告放在非常吸引人的点位上。所以我们非常关注能否分析出有吸引力的内容,甚至根据分析的结果,二次创造出有吸引力的内容。对于吸引力,我们在思考什么是非常重要的。这里列出三点:
第一个是视频质量,比如是否清晰、镜头是否晃动、是否有无意义的内容,这是基础的质量问题。
第二个是视频美学,比如色彩是否优美,构图是否好,光线明暗对比度是否好。
当然,有了质量和美学还不足以说明视频是否有吸引力,大部分的视频是靠情节取胜,也就是靠视频的内容去吸引人,不管是长视频的电视剧、电影、动漫,还是横版短视频和竖版小视频,都包含着当前视频是何人何地发生何事,由这样的内容反映精彩度。精彩度是视频吸引力的第三点,也是最重要的一点。
01 方法及整体框架
1. 如何识别精彩

这就促使我们去思考,如何分析内容的精彩度,这里有几个维度:第一,内容标签,比如打斗等偏感官层面的信息或者是浪漫等偏高层语义方面的信息,这需要理解视频内容。第二方面是程度等级,比如说打斗,如果是武林高手之间的对决,相比于我们普通人之间打斗会更精彩,所以需要一个分级打分机制。还有一些信息影响到用户对视频的喜好,比如对明星、IP、剧集等的喜爱,都会影响用户对其精彩度的判断。前面这 3 点是人们对于视频精彩度的一个理性分析,但实际上精彩度还是较主观的看法,同一个视频,有些人觉得精彩,有些人则不觉得。一些上映之后成为收视率“黑马”的作品,在上映之前,人们没有预期到其足够精彩,上线之后,却成为爆款,这体现了对精彩度主观判断的局限性,因此我们也要考虑视频上线后的用户反馈。比如用户的播放、弹幕等行为,有些视频片段用户会反复播放,另一些则会被跳过。我们希望通过以上几个方面,构建对于精彩度的认知。
2. 精彩度分析整体技术框架
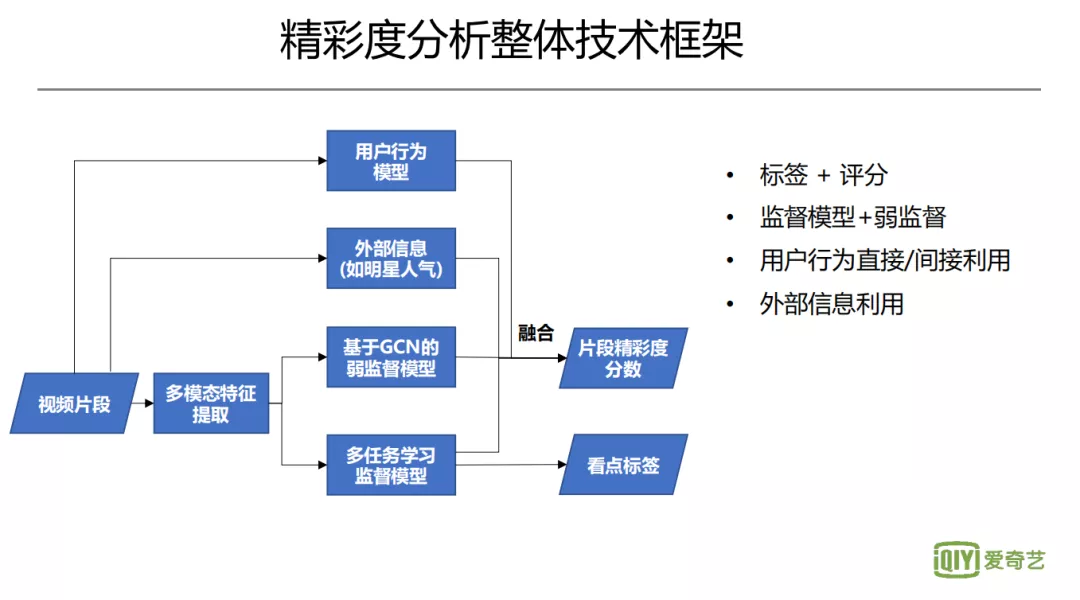
由此,我们形成如图的精彩度分析方案,该方案的适用对象较广泛,不管是对完整的剧集,还是简短的花絮,都可以适用,我们这里聚焦于对电影电视剧的片段做分析。影视剧的整体精彩度比较宏观,受参演明星,改编的小说等已知因素的影响,所以通过算法对整体做精彩度分析收益相对较小。当下我们更关注,对长视频局部剪辑片段的打分。精彩的局部片段的识别,有助于启发创作者对于局部精彩视频的思考,有利于后续创作的提升。同时,精彩片段的识别,有助于二次传播、碎片化时间的消费,以及广告的投放等。如框图所示,我们输入的是视频片段,然后进行多模态的视频特征提取,接下来分两步,一个是基于 GCN 的弱监督模型,另一个是基于多任务学习的监督模型。
02 视频精彩度分析算法
1. 精彩度监督模型
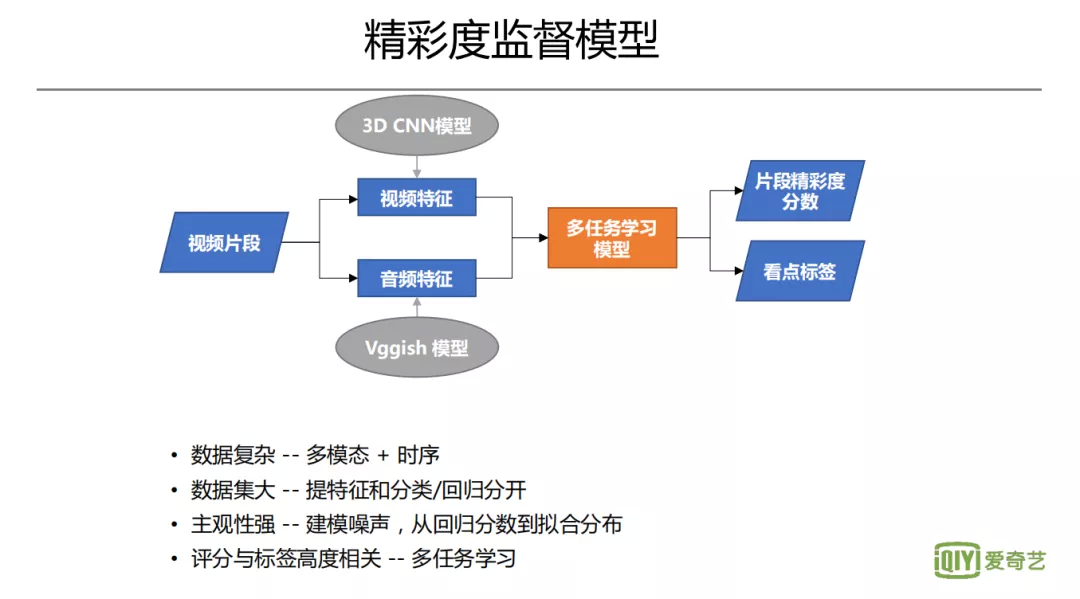
对于精彩度的监督模型,首先需要标注人员对视频精彩度进行打分。考虑到数据的复杂性,会充分利用多模态和时序关系去提取信息。操作中会有一些具体技巧,比如由于其标注主观性比较强,会进行噪声建模,从回归分数变成一个拟合分布。另外,评分和标签是高度相关性的,因此可以通过多模型、多任务学习的方式来进行。
2. 不同模型提取特征性能对比
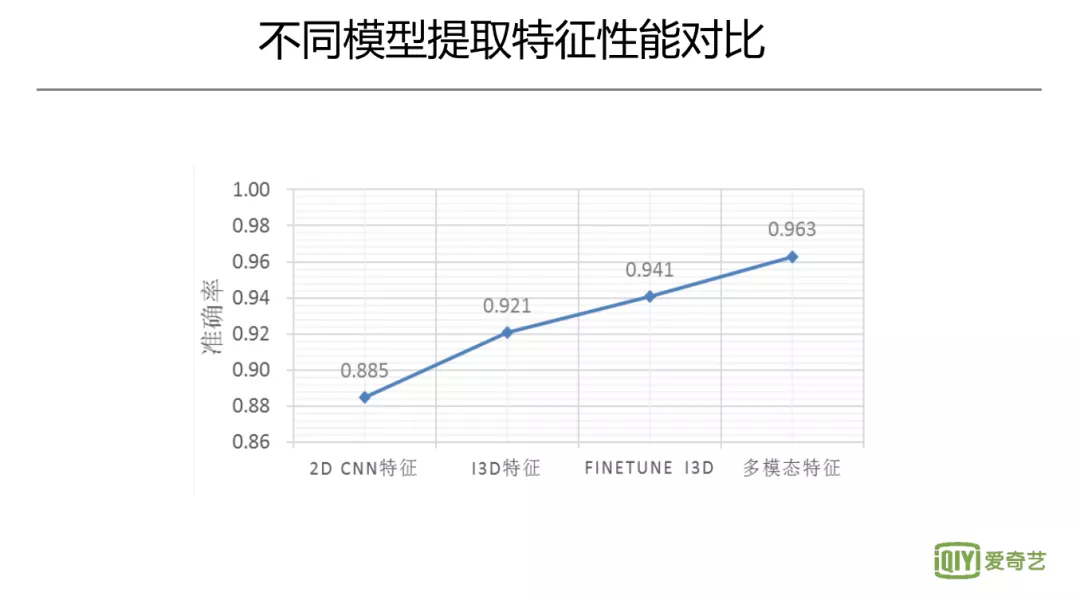
这张图显示了采用不同的模型提取特征,对最终精彩度输出的影响。最初的方法是针对图片信息采取 2D 的 CNN,再去对帧级别 feature 进行融合;接着考虑由时序上的 3D 卷积模型来提特征;然后尝试根据预训练模型来进行微调;再利用视觉+音频的多模态的信息进一步提升。
3. 精彩度分数预测
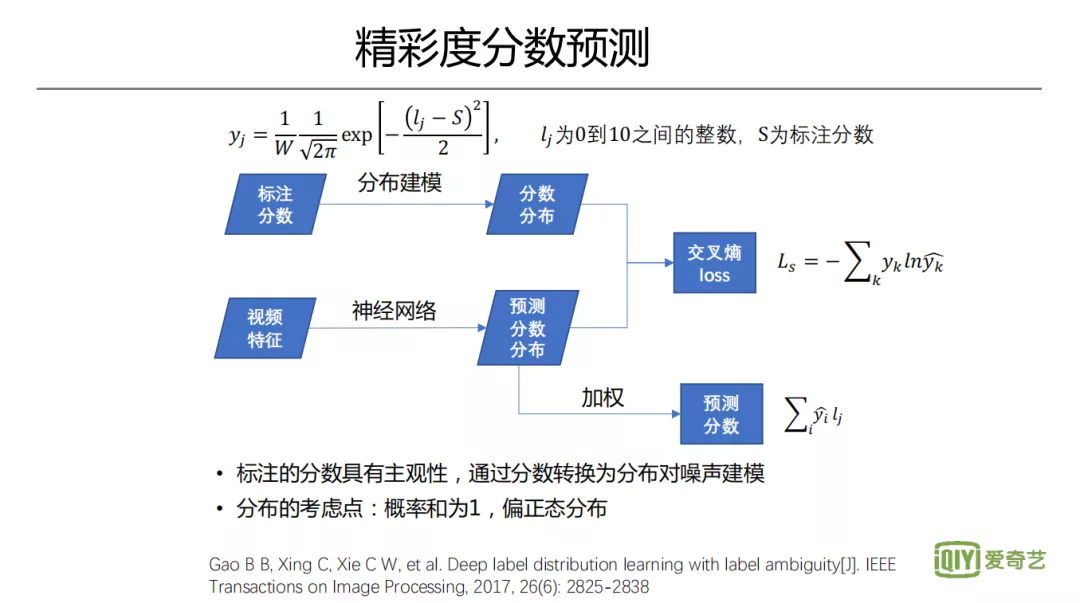
监督模型的一个分支是精彩度分数预测。对于精彩度分数,会先做人工标注,但是因为主观性偏向非常强,所以噪声较大,可信度并不高。当标注为某一个分数,那它很大概率会是以这个分数为均值的正态或偏正态分布。比如标注分数是六分,那该视频可能很大的概率是六分,但也可能会小一些的概率是五分或七分。为减少噪声影响,会对噪声做一个建模,直观的假设,将标注的分数看做一个正态分布的均值。为了满足概率积分的要求,实际上设计了一个偏正态分布。分布的方差通过理论分析+实验,来确定一个比较合适的值。有了这个分布,对于分数的回归,可以变成一个类似分类的任务,对于每一个离散值给出一个概率,这样得到对分布的预测,从而加权得到最终预测的分数。采取该策略后,我们发现对于噪声比较大的主观性标注任务还是有意义的,其它一些图片回归任务我们也用了类似方法,取得了不错的效果。
4. 看点多标签模型
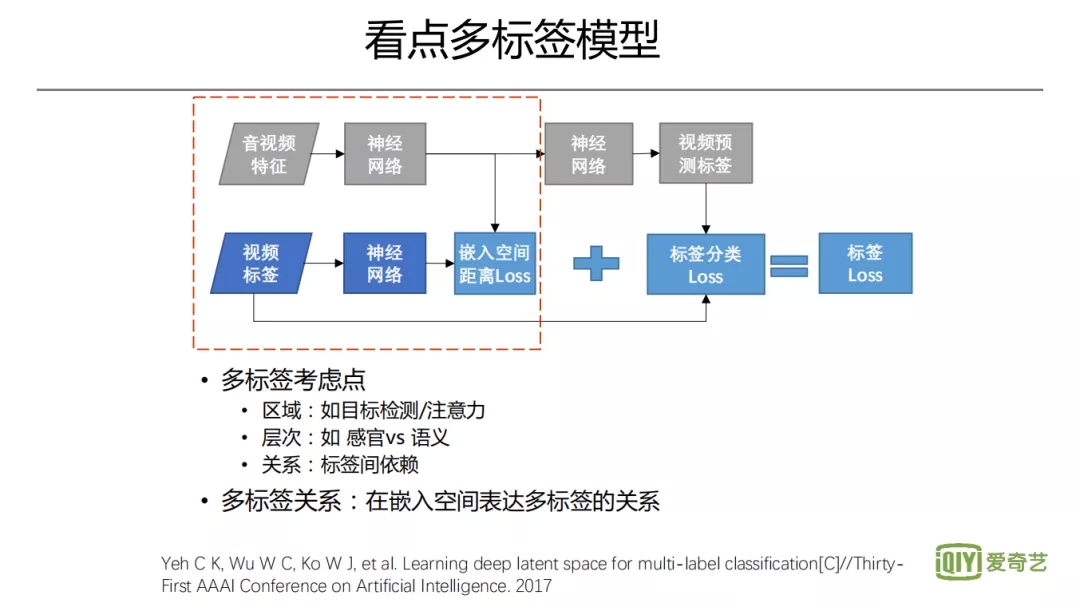
接下来看第二点,关于视频内容的看点多标签。比如像打斗、爆炸,都是比较有意思的标签,可能是会吸引人的。对于不同类型的视频,看点的标签是不一样的。比如说对于偶像片来说,浪漫的标签可能非常有吸引力;对于动作片来说,可能飙车、打斗、枪战等很有吸引力。多标签模型,在近几年各领域都广泛关注,包括短视频标签、图片多标签、文本多标签等。多标签的难点,是如何对同样的信息去生成不同的标签,针对这个问题会有三个方案。第一种是利用信息不同区域对应不同的标签,可以类比目标检测。即划分图像的不同区域,用其本身及周边的信息,去预测该区域的一个标签。那第二个是层次的关系,比如从画面视觉内容来说,一男一女在西餐厅吃烛光晚餐,则需要进行性别识别、场景识别、目标检测等,同时它是一个浪漫的约会场景,所以还可以推理出上层的标签。第三个要考虑的点,是标签之间的依赖关系,有一些标签很可能经常共同出现,比如说有海滩和阳光。有一些标签之间不太容易共现,比如手机跟古装片,可能是互斥关系。当然如果能识别这是一个穿越片,就可认为这两个标签共现是比较和谐的。在很多看点多标签之间,有这种互相依赖的关系,如何去表达标签的关系有很多方式,比如说 CNN 和 RNN 结合,通过 RNN 去显示地表达标签之间的依赖。那其它一些方式,比如通过标签 embedding,希望其去影响分类器,而对于这个 embedding,可能会通过图的拓扑结构,根据相似的邻域标签信息来修改 embedding,从而让这个 embedding 包含标签之间的关系,再将这个 embedding 以某种方式去影响分类器。还有一种方式,就是训练时找到一个嵌入的空间,把 ground truth 的多标签投射到嵌入空间,利用多标签去生成一个 feature,同时对于待处理的数据也生成一个 feature,要求这两个 feature 要尽可能接近,之间的某种距离可以作为 loss 之一。这样,嵌入空间的音视频 feature,即表达了多标签的关系,可以认为是对多标签的编码,而后续的分类过程,就是对多标签的解码。
5. 多任务学习模型
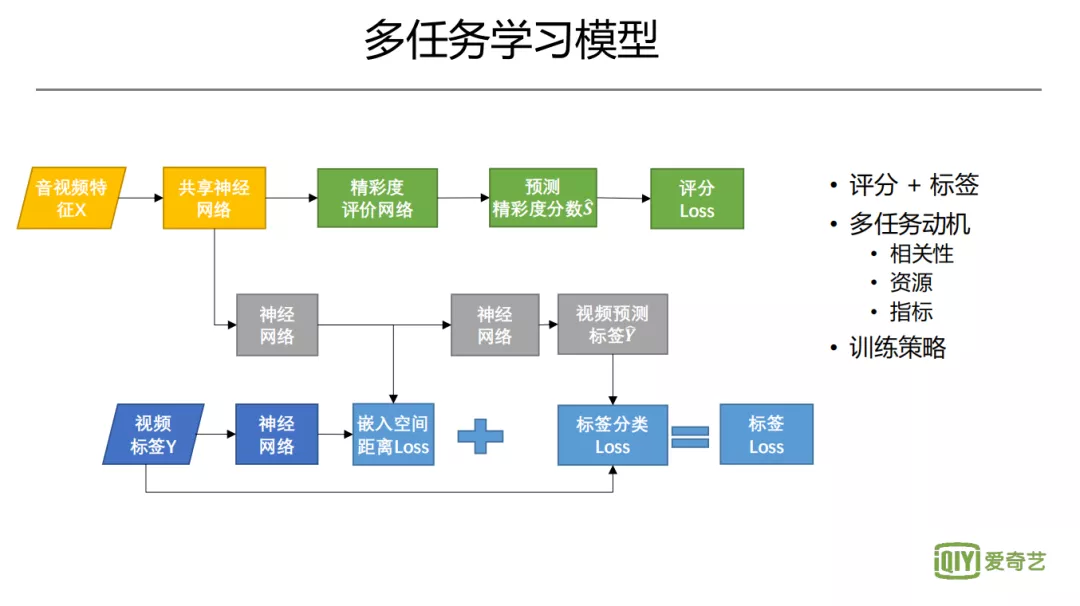
评分和看点标签这两个模型高度相关,所以用了多任务学习。因为业务有非常多的需求,各需求之间往往有相关性,经常存在多任务学习的可能性。另外,海量数据下如何节省资源,也是非常现实的需求。如果我们通过多任务学习能够降低资源消耗,更好的体现相关性,甚至还有可能提升指标,那会非常有动力去做多任务学习。我们现在的架构,底层共享网络,上层建立评分和标签网络。训练策略方面没有标准化方式,采取一些经验性的方式,动态调节权重,比如根据每一路分支 loss 下降的情况进行调整,或是动态分析每路分支的运行情况,修改训练频次,保持一致的收敛速度。
6. 弱监督模型
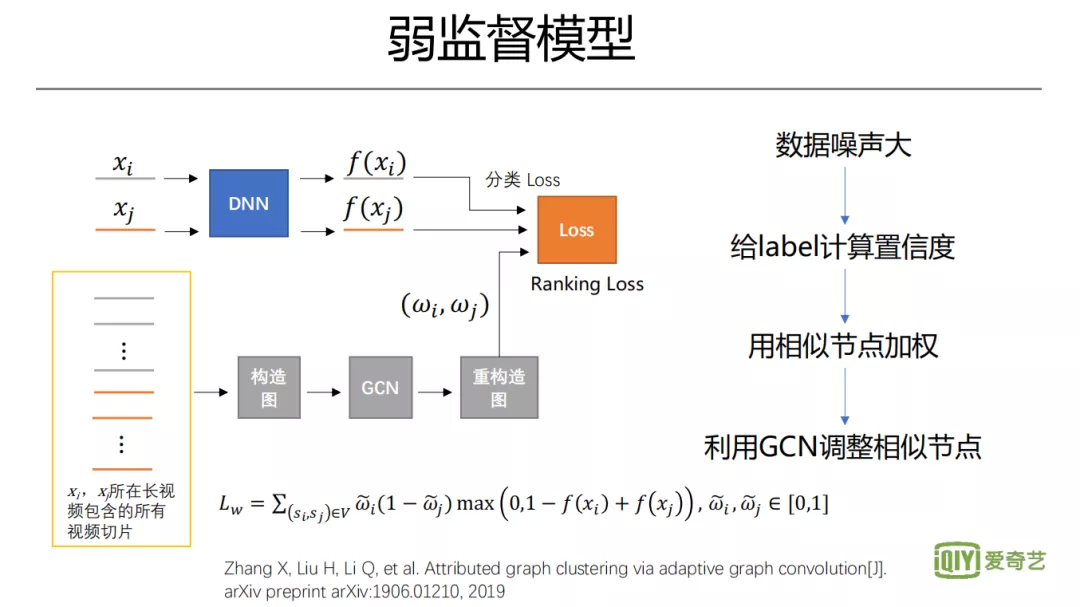
接下来我们再看一下,弱监督模型这一块。我们有很多用户观影行为数据,是否可用于拟合对分数的标注。比如观看行为,观看次数越高,一般也越精彩。但是不同视频本身热度不一样,同一个视频的不同部分,单纯看播放量也不公平,因为很多用户不会看完整个视频,一般前面的片段播放量会更高。所以,直接将用户行为作为精彩度的度量,虽然相对于人工标注的分数更能体现用户的实际偏好,但还是存在非常多的噪声。为了减少噪声影响,要做很多数据预处理,比如尽量避免用区分度不大的数据。除了关心绝对精彩度,也关心相对大小,即一个视频中,哪些内容相对其余部分更有吸引力。我们往往会从一个视频当中,筛选相对精彩的内容,去做二次创作、投放广告等。在这样的诉求下,可以采用 Ranking 思想去设计 Loss。因为噪声较大,会给 label 计算置信度,比如可以用相似的样本来做平滑。这里我们还可以利用图,设计图卷积过滤高频信息更新样本 feature,实现更好的聚类,并利用更新后的相近节点来修改样本置信度,最终有效提升弱监督模型效果。
03 应用
1. 前情提要
前情提要是精彩度相关的一个应用,运用算法对每一集识别出精彩片段,通过一定策略剪辑。虽然前景提要本身是一个用户产品,但可以在上面投放广告,并且处于片头这个黄金位置,实现了很好的商业价值。
2. 拆条

第二个应用是长视频拆条。做一个比较好的拆条,要从长视频当中选出比较精彩的部分,同时满足切分方式的合理性。可以方便投放在站内或者是站外的各种渠道上,这样可利用用户的碎片化时间,一方面形成对短内容的消费,一方面也能够起到短带长的作用。所以要做拆条的话,不仅仅需要对内容本身的理解,也需要对精彩度做分析。
3. 自动生成封面
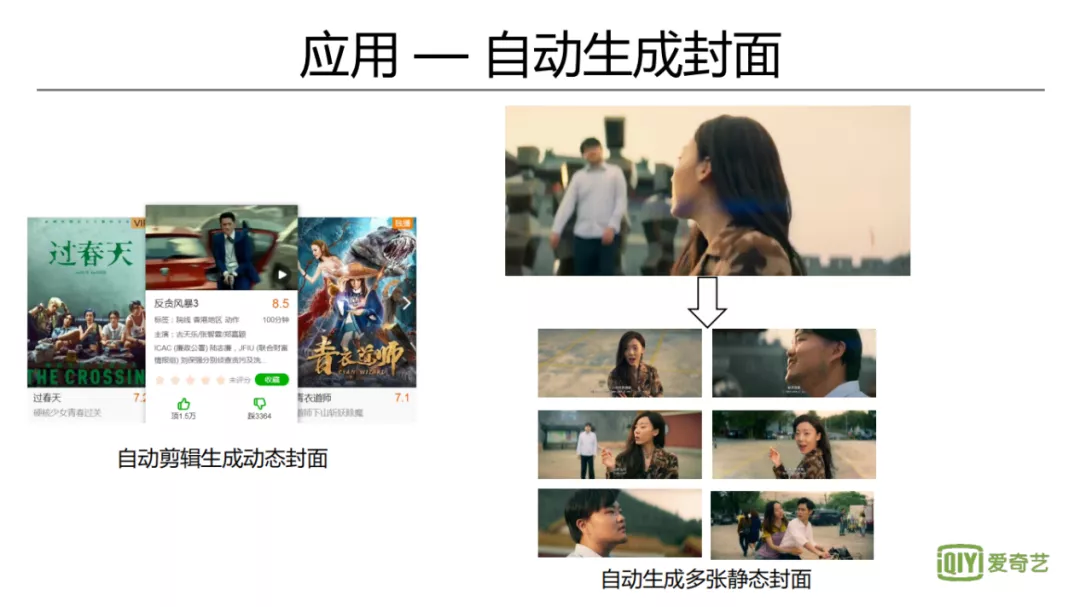
智能封面图生成,目前线上的影视剧封面,采用自动生成动态图的方式。对视频中精彩片段进行打分,并需要保证片段的多样性和代表性。对于图片也会有精彩度、美学等分析。不管是静态封面图还是动态封面图,都可以生成多个,然后去做个性化的分发,并通过线上的反馈来调整生成封面图的策略。
4. 片段打分
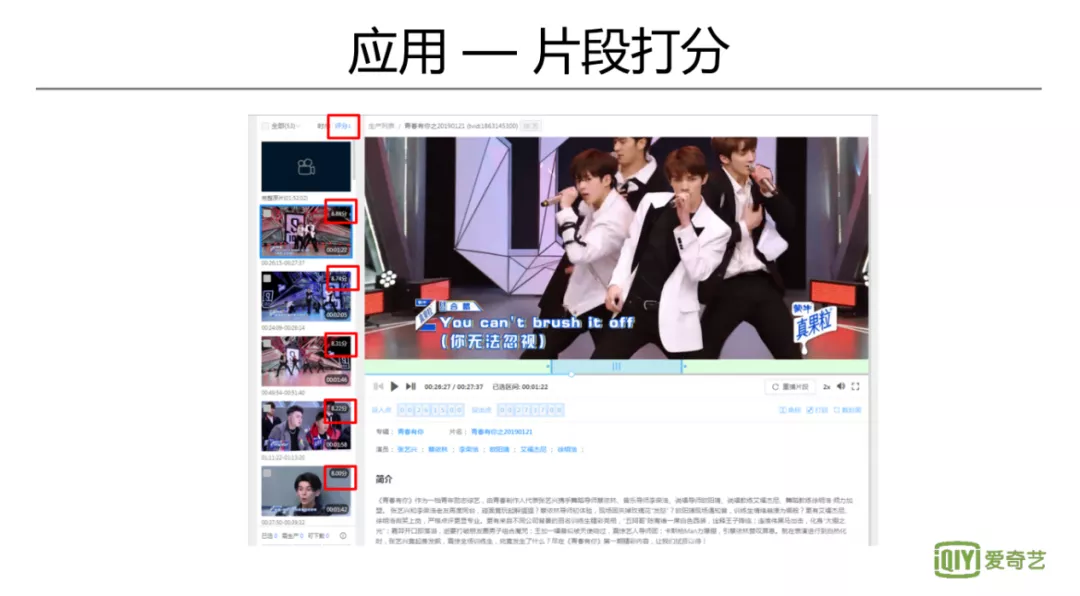
还有一个应用,是直接对片段的精彩度打分,有利于冷启动阶段的分发;也能给创作者提供参考。
04 总结和展望

总结一下,当大家思考内容平台的时候,会非常关注内容是否精彩。针对精彩度分析,不只是一个单一的技术,更是一个综合性的解决策略。可能会利用各种各样的垂直算法、产品策略,工程策略等,最终形成可行方案。精彩度方案已被广泛应用,并会从质量和效率两个方面的提升来做评价。由于精彩度分析任务的特点,如需要用到海量数据、具有较强主观性、有很多用户行为数据等,会牵涉到很多技术方向,像弱监督、多任务、多标签、图等等。此类偏主观的分析,用户标准、用户行为以及先验的外部信息,这三个维度都非常重要。
后续的展望,第一方面是在特征提取上,尽量去融合更多的信息,包括文本的信息,比如台词、弹幕等。第二个是在模型上,比如怎么通过半监督的方式,把有标注和无标注的数据,放到一个统一框架中来。第三点是如何利用各种垂直识别,不管是底层的识别,还是偏上层的推理形成高层语义,需要能把这些信息利用起来,从而知道为什么精彩,作出可解释的精彩度评价。
今天的分享就到这里,谢谢大家。
作者介绍:
刘祁跃,爱奇艺科学家
刘祁跃,爱奇艺科学家,智能平台部视频分析组负责人。负责对视频内容的理解和生成,并应用到广告、创作、分发等业务。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论