

半年前,vivo 研究院开始建设 AI 计算平台,以期解决在统一和高性能训练环境、大规模分布式训练、计算资源的高效利用和调度方面的痛点。在这个过程中,整个团队发现 K8s 的原生调度器存在诸多问题,最后决定采用社区提供的批调度器 kube-batch,本文讲解了 vivo 基础计算小组的 kube-batch 实践历程和解决的问题。
vivo AI 研究院的基础计算平台小组从半年前开始建设 AI 计算平台,以解决如下痛点:
统一和高性能的训练环境
痛点:
以前,算法工程师直接在物理机上进行训练。当使用一台新机器时,算法工程师需要重新安装训练所需要的依赖,这需要花费不少时间,不同机器的环境一致性也很难保证。不同项目的依赖可能存在冲突,导致物理机不能被共享,降低资源使用率。其次,物理机只提供 CentOS 操作系统,而有些训练场景在 Ubuntu 系统上性能更好。最后,同一台机器上可能会有多个训练任务在跑,任务之间互相争抢资源,降低训练效率。
方案:
计算平台通过利用这几年流行的容器技术,解决了上述痛点,将训练环境打包成容器镜像后,可以将镜像跑在任何安装了容器的机器上,而同一台机器也可以运行不同的镜像。平台通过对镜像的优化,比如安装编译优化过的 tensorflow,提高训练性能,并迅速推广到各个项目。容器的隔离和资源限制特性可以保证任务互不影响。
大规模算法分布式训练
痛点:
对于某些场景,训练的数据量十分庞大,在单机上训练的时间十分长。提高算法训练效率,从而缩短算法迭代周期,对算法优化而言至关重要。对于一些场景,必须在一定时间内完成增量训练,把新模型应用在线上,才能保证线上效果。
方案:
平台提供了一套基于 MPI 实现的训练框架。单机训练的代码只需要做简单调整,就可以分布式的方式运行。并且随着训练节点的增加,训练样本数保持了接近线性的增长。
计算资源的高效利用和调度
痛点:
之前,每个团队都分配一定数量的物理机,有些团队的资源使用率不高,有些团队资源十分紧张。分布式训练任务需要同时在多台机器上将任务拉起,并且满足不同任务的资源需求,这需要一个成熟的调度系统。
方案:
平台使用了这几年炙手可热的 Kubernetes(简称 k8s),将训练机器加入 k8s 集群。作为统一资源池,各任务都通过平台向 k8s 申请资源,由 k8s 将任务的各个 worker 调度到各个机器上并启动容器。为了进一步提高资源利用率,我们采用了批调度器 kube-batch。
为什么使用 kube-batch
K8s的原生调度器会将需要启动的容器,放到优先队列(Priority Queue)里面,每次从队列里面取出容器,将其调度到一个节点上。 分布式训练需要所有 worker 都启动后,训练才能够开始进行。使用原生调度器,可能会出现以下问题:
一个任务包含 10 个 worker, 但是集群资源只满足 9 个 worker。原生调度器会将任务的 9 个 worker 调度并启动,而最后一个 worker 一直无法启动。这样训练一直无法开始,9 个已经启动的 worker 资源就会被浪费。
两个任务,各包含 10 个 worker, 集群资源只能启动 10 个 worker。两个任务分别有 5 个 worker 被启动,但两个任务都无法开始训练。10 个 worker 的资源被浪费了。
由此可见,原生调度器对于分布式训练的调度存在问题,影响了资源的利用率。而 k8s 社区提供了一个批调度器 kube-batch, 它能够将一个训练任务的多个 worker 当做整体进行调度,只有当任务所有 worker 的资源都满足,才会将容器在节点上启动。这解决了上述问题,避免了任务间的资源死锁,提高了资源利用率。
kube-batch 还提供了队列机制,同个队列的任务会依次运行。不同队列直接可以设置优先级,优先级高的队列中的任务会优先得到调度。队列还可以设置权重,权重高的队列分配到的资源会更多。
kube-batch 的原理与实现
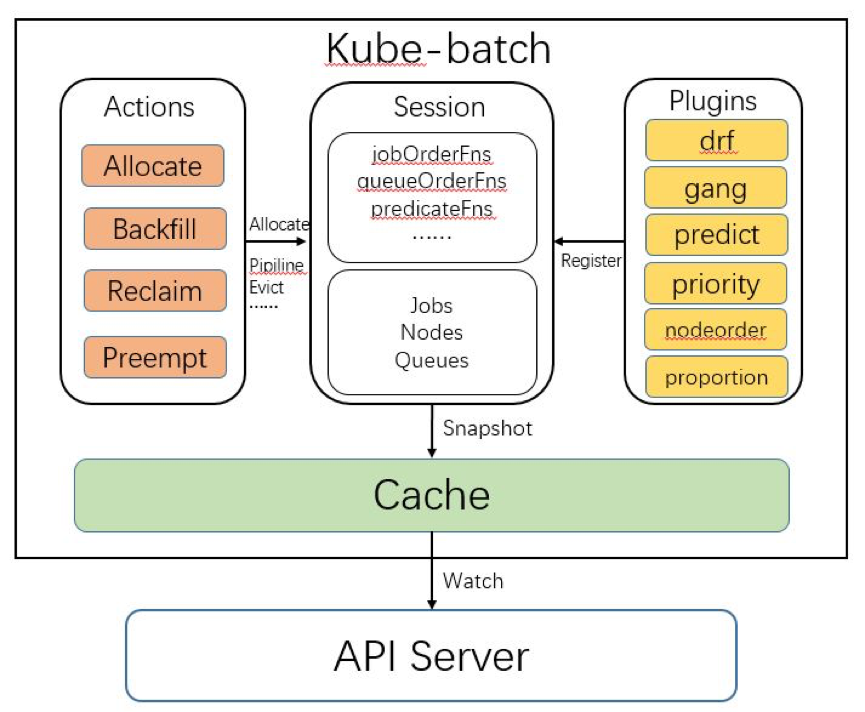
如上图所示,kube-batch 中有四个模块,分别是 Cache, Session, Plugin 和 Action。
Cache 模块
Cache 模块封装了对 API Server 节点、容器等对象的数据同步逻辑。K8s 的数据保存在分布式存储 etcd 中,所有对数据的查询和操作都通过调用 API Server 接口,而非直接操作 etcd。在调度时,需要集群中节点和容器的使用资源和状态等信息。Cache 模块通过调用 K8s 的 sdk,通过 watch 机制监听集群中节点、容器的状态变化,将信息同步到自己的数据结构中。
Cache 模块还封装了对 API server 接口的调用。比如 Cache.Bind 接口,会调用 API Server 的 Bind 接口,将容器绑定到指定节点上。在 kube-batch 中,只有 cache 模块需要和 API Server 交互,其他模块只需要调用 Cache 模块接口。
Session 模块
如图所示,Session 模块是将其他三个模块串联起来的模块。Kube-batch 在每个调度周期开始时,都会新建一个 Session 对象,这个 Session 初始化时会做以下操作:
调用 Cache.Snapshot 接口,将 Cache 中节点、任务和队列信息拷贝一份副本,之后在这个调度周期中使用这份副本进行调度。因为 Cache 的数据会不断变化,为了保持同个调度周期中的数据一致性,在一开始就拷贝一份副本。
将配置中的各个 plugin 初始化,然后调用 plugin 的 OnSessionOpen 接口。plugin 在 OnSessionOpen 中,会初始化自己需要的数据,并将一些回调函数注册到 session 中。Plugin 可以向 Session 中注册的函数是:
jobOrderFns: 决定哪个训练任务优先被处理(调度、回收、抢占)。
queueOrderFns:决定哪个训练队列优先被处理。
taskOrderFns:决定任务中哪个容器优先被处理。
predicateFns: 判断某个节点是否满足容器的基本调度要求。比如容器中指定的节点的标签。
nodeOrderFns: 当多个节点满足容器的调度要求时,优先选择哪个节点。
preemptableFns: 决定某个容器是否可以被抢占。
reclaimableFns :决定某个容器是否可以被回收。
overusedFns: 决定某个队列使用的资源是否超过限额,是的话不再调度对队列中的任务。
jobReadyFns:判断某个任务是否已经准备好,可以调用 API Server 的接口将任务的容器调度到节点。
jobPipelinedFns : 判断某个任务是否处于 Pipelined 状态。
jobValidFns: 判断某个任务是否有效。
注意:plugin 不需要注册上面所有的函数,而是可以根据自己的需要,注册某几个函数。比如 Predict plugin 就只注册了 predicateFns 这个函数到 session 中。
初始化成功后,Kube-batch 会依次调用不同的 Action 的 Execute 方法,并将 Session 对象作为参数传入。在 Execute 中,会调用 session 的各种方法。这些方法,有些最终会调用到 Cache 的方法, 有些是调用 Plugin 注册的方法。
Action 模块
Action 模块实现了具体的调度流程。现在有 4 个不同的 Action:
Allocate: 这个 Action 负责将还未调度的设置了资源限制(request、Limit)的容器调度到节点上。
Backfill: 这个 Action 负责将还未调度的的没设置资源限制的容器调度到节点上。
Reclaim: 这个 Action 负责将任务中满足回收条件的容器删除。
Preempt: 这个 Action 负责将任务中满足条件的容器抢占。
Action 实现了调度机制(mechanism),Plugin 实现了调度的不同策略(policy)。举个例子,在 Allocate 中,每次会从优先队列中找到一个容器进行调度,这是机制,是由 Action 决定的。而在优先队列中容器排序的策略,是调用了 session 的 TaskOrderFn 方法,这个方法会调用 Plugin 注册的方法,因此策略是由 Plugin 实现。这种机制和策略分离的软件设计,带来了很好的扩展性和灵活性。
Plugin 模块
Plugin 模块提供了一种可插拔的方式,向调度提供不同的策略的实现。
如图所示,目前最新版本有 6 个 plugin,它们分别是:
drf: :实现了 Dominant Resouce Fairenss 算法,这个算法能够有效对多种资源(cpu、memory、gpu)进行调度。
gang:实现了 gang scheduling 的逻辑,即保证任务所需 worker 同时被启动。
predict:判断某个节点是否满足容器的基本要求。
priority: 根据容器和队列设置的 PriorityClass 决定容器和队列的优先级。
node order:决定满足调度要求的节点中,哪个节点优先被选择。
proportion: 根据队列设置的权重决定每个队列分配到的资源。
kube-batch 在平台的应用
首先,按照 kube-batch 项目的文档,将其以 deployment 的方式部署到 k8s 集群中。k8s 支持多种调度器并存。每个调度器按照约定,只处理指定了自己的容器。容器可以在 scheduleName 这个字段指定调度器名字。默认是”default-scheduler“, 即 k8s 原生的调度器。平台将训练任务的容器的 scheduleName 都设置成”kube-batch“, 这样这些容器就会被 kube-batch 所调度。
在使用 kube-batch 的过程中,我们遇到了一些问题。我们首先在自己使用的版本上将问题修复,保证平台的可用性。然后我们会将问题反馈到社区中,并提供最新版本上的补丁。这样能够反馈社区,和社区共同推进 kube-batch 项目的发展。
问题一:调度器偶尔会 crash
经过排查日志,我们发现导致调度器 crash 的逻辑在 proportion 这个 plugin 中。在给多个队列分配资源时,会有一个变量 remaining 记录集群剩余的资源容量。这个变量的计算有误,导致程序抛出 Panic 后 Crash 了。
给社区的 issue: https://github.com/kubernetes-sigs/kube-batch/issues/665
给社区的 PR:https://github.com/kubernetes-sigs/kube-batch/pull/666
问题二:当集群资源足够时,任务没有被成功调度
经过日志的排查和代码分析,我们发现这个问题是 proportion 的 plugin 中,给队列分配资源的计算有误。每个队列有两个属性,一个是 allocated,表示实际上已经分配了的资源,一个是 deserved, 表示应该分配的资源。 当 allocated 大于 deserved 的时候,就会停止对队列里的任务进行调度。由于对 deserved 的计算有误,比正确的要少,导致 allocated 大于 deserved,队列中的任务不再被调度。
给社区的 issue:https://github.com/kubernetes-sigs/kube-batch/issues/729
给社区的 PR:https://github.com/kubernetes-sigs/kube-batch/pull/730
问题三: 大任务阻塞了后续任务的调度
当有一个大任务,即使用了很多资源的任务,因为集群资源不够而处于等待状态时,后面提交的小任务,哪怕集群有足够资源,也无法得到调到。只有把大任务删掉后,才能被成功调度。这是因为在调度周期中,大任务总是优先被处理。在调度大任务时,Session 中记录的空闲资源已经分配给这个大任务了,最后发现资源不够无法启动,也不会释放这些资源。所以后续的任务也不会被调度成功。如果修改这个逻辑,就可能导致大的任务永远都无法启动,因为后面一直有小任务提交并被调度。具体的改动方案社区还在讨论中。这个问题的影响可控,改动成本大,因此我们也没自己修复,而是等待社区的方案。
给社区的 issue:https://github.com/kubernetes-sigs/kube-batch/issues/561
作者介绍:
吴梓洋,曾就职于 Oracle, Rancher 等公司,目前是 vivo AI 研究院计算平台组的资深工程师。也是 kube-batch, tf-operator 等项目的 contributor。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论