

互联网的高速发展使得对数据实效性的要求越来越高,基于数据流的流计算越来越重要。以 Flink 为代表的新一代流计算引擎以其高吞吐、低延迟、checkpoint、state、time、window 等特性方便了我们对数据流的高效处理。
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink 起源于德国柏林工业大学的一个研究项目 Stratosphere,Flink 从 Stratosphere 的分布式执行引擎开始,并于 2014 年 3 月成为 Apache Incubator 项目。2014 年 12 月,Flink 成为 Apache 顶级项目。
Why flink
high throughput & low latency。流计算任务对吞吐和延迟有着很高要求,Spark Streaming 通过微批去实现流处理,而 Flink 是纯流式计算的思路,可以满足高吞吐和低延迟。
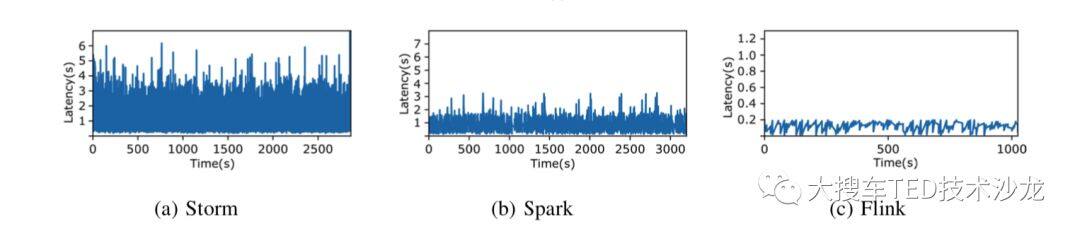
图 1 latency 对比
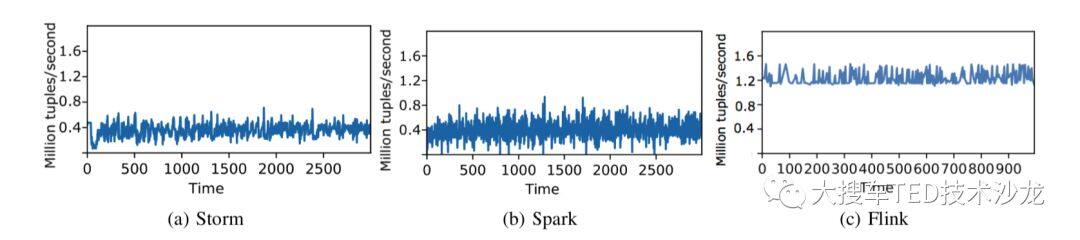
图 2 throughput 对比
state & checkpoint。流计算任务中 state 管理是非常重要的一部分,在 Storm 等框架中需要开发人员自己去管理 state,同时 Storm 不支持批计算,而 Flink 能够支持批流统一。Flink 通过内置的 state 使得我们可以像使用集合类一样方便进行状态操作,同时得益于 checkpoint 机制,通过 Chandy-Lamport 算法产生一个分布式快照,保证了 exactly-once 并可以进行快速的故障恢复。
time & window。现在流处理中,对 time 的支持必不可少,Flink 中,processing time 表示处理消息的时间、event time 表示流数据中包含的业务时间时间、ingestion time 表示进入到系统的时间。watermark 也是一个很关键的概念。基于 event time 必须指定如何生成事件 watermark,这是表示事件时间进度的机制。通过 watermark 声明不会再有任何小于该 watermark 的时间戳的数据元素到来,即使一些事件延迟到达,也不至于过于影响窗口计算的正确性。watermark 很好的解决了 event time 乱序的问题。此外,Flink 还提供了一套便捷的窗口操作包括滚动窗口、滑动窗口、会话窗口。
流计算开发平台
大搜车旗下包括车易拍、车行 168、运车管家、布雷克索等公司,以及深度战略合作的长城汽车、长安汽车、英菲尼迪等主机厂商,以及与中石油昆仑好客等产业链上下游的合作伙伴。
Flink 在大搜车各个业务域有着广泛的应用,如日志分析、物联网、实时数仓等。大搜车基于 Flink 的流计算的开发平台,经历了从小到大的历程。
整体架构
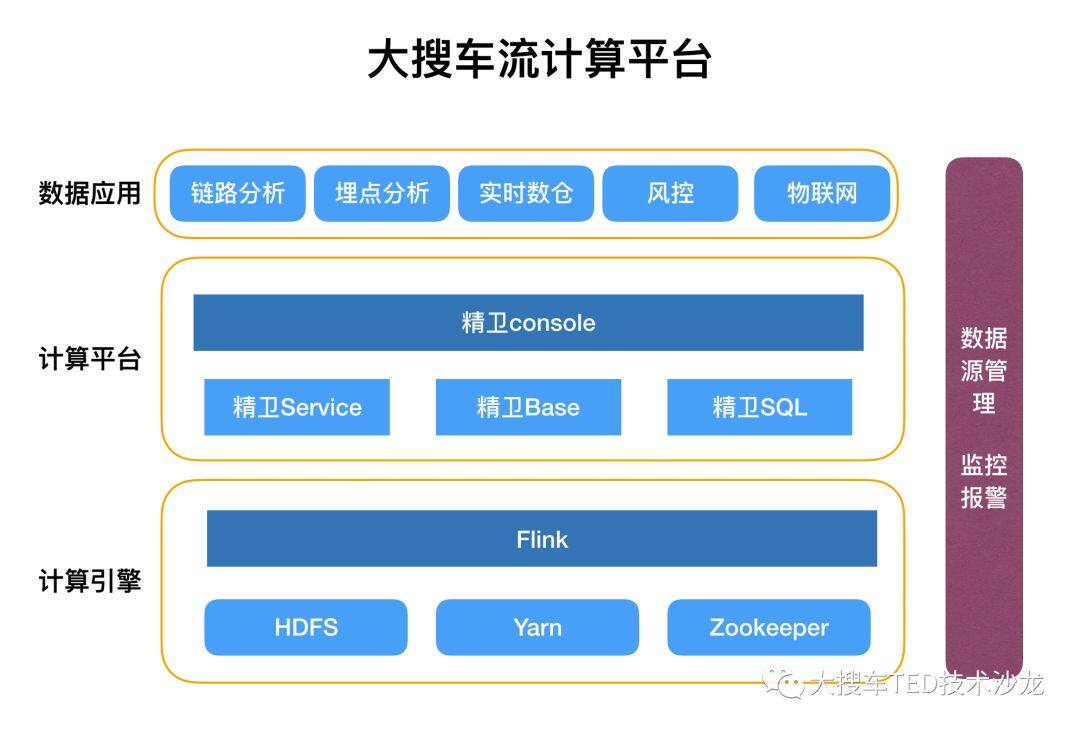
图 3 大搜车流计算平台架构
统一脚手架
最初各个任务是自己创建 maven 工程,过程中发现开发人员需要花大量时间去结果依赖冲突的问题,同时线上会出现由于版本带来的各种问题。为了解决这个问题,我们提供 maven 提供的脚手架创建一个任务模板。生成的作业模板 pom.xml 已经将 Flink 相关的依赖进行了处理。
开发人员无需再花时间处理依赖冲突,也方便后续 Flink 版本的升级。同时我们对 Flink 中的常见 source 及 sink,如 kafka、mysql,进行了封装,开发人员通过简单配置即可接入数据源,对于 kakfa 还可以通过统一参数管理进行 offset 重置进行任务重跑,此外在任务 Dispatcher 中配置任务重启策略等。
统一工作台
最初我们依赖 Flink Web 工作台进行,随着业务量的增加,我们发现诸多不便,对于权限管理、任务版本、执行 savepoint 等功能不能很好支持,因此我们开发了一个统一的流计算工作台(精卫)。包含如下功能:
任务运行/恢复
版本管理
任务暂停(savepoint)
权限管理
日志查询
运行监控
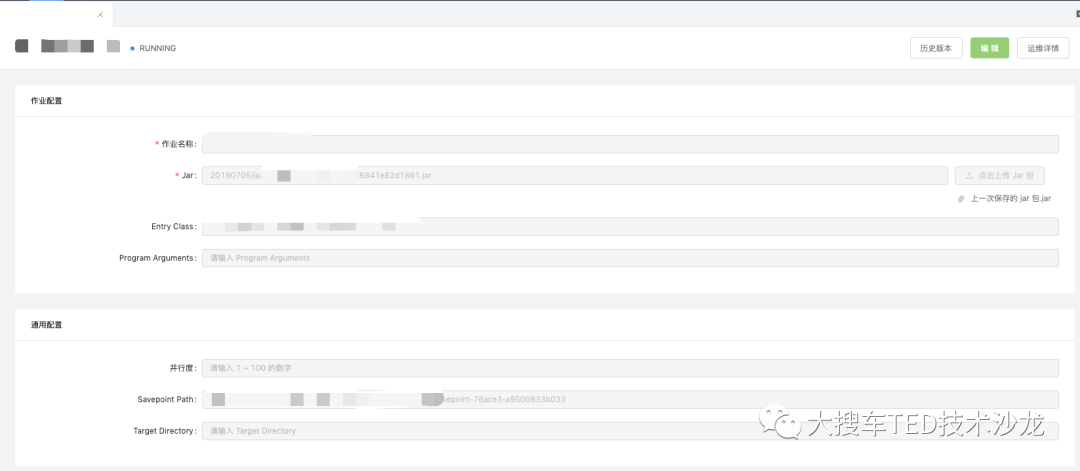
图 4 任务开发
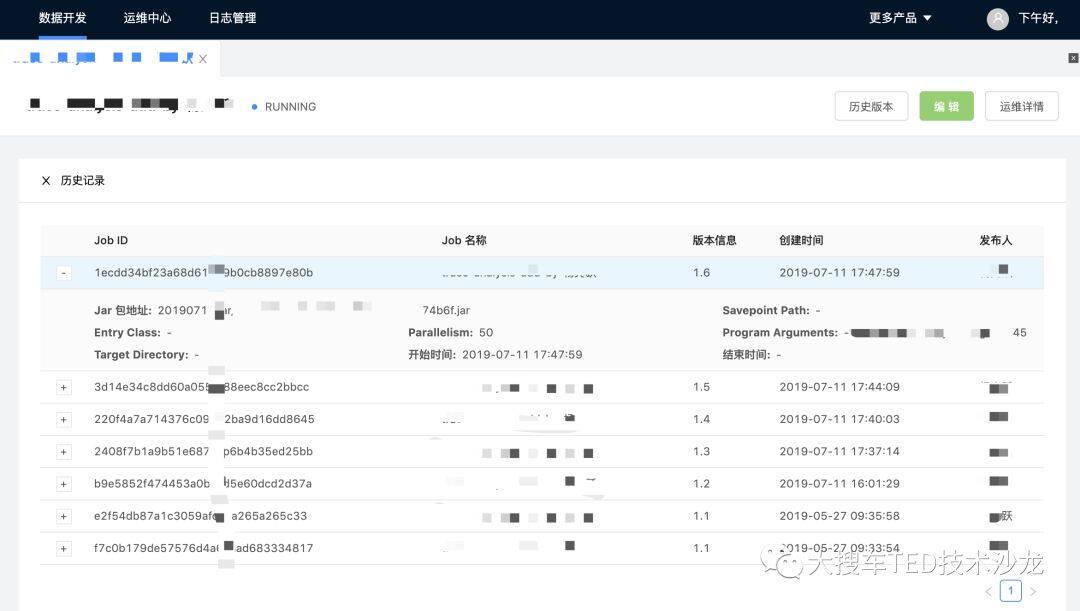
图 5 版本管理
SQL 开发
Java API 的问题
开发效率及成本
通过 Java API 基于 DataStream 开发流计算任务,通过脚手架解决了依赖冲突的问题,但是开发人员还是要通过 flatmap、filter、keyby、window 等 Operator 去开发流计算任务,同时要经过打包,上传及发布等流程,调试过程中出现问题需要重新执行上述流程,这便造成了流计算任务开发缓慢、效率低下的问题。开发周期长,一个开发人员很难同时维护多个任务。
维护成本
同时任务一旦出现问题,平台开发运维人员不了解具体业务,不能快速处理问题,往往需要查看业务源代码来进行问题定位和处理。
SQL 的重要性
如何解决这些问题,能提升开发人员的效率,并减少平台方的运维成本?SQL 是一个很好的解决方案。SQL 语言是一个高级的非过程化语言,1974 诞生至今,经久不衰,语言简洁,在开发人员、DBA、数据分析师中都有着良好的基础。同时我们看到在大数据离线处理领域,也经历了 MapReduce 到 Hive 的发展过程,当下 Hive 以其快速、高效、易于维护的特性已经成为数据仓库的重要组成部分。因此支持 Flink SQL 开发流计算任务变得尤为重要。
我们知道 SQL 是作用于关系表的,流计算是对流数据的处理,为什么可以用 SQL 开发流计算任务?回答这个问题,就要提到流与表的等价性。以 Mysql 和 Binlog 为例,Mysql 的对表的操作会通过 Binlog 形成携带时间的数据流,主从同步中会通过对 Binlog 数据流的处理形成一张表。因此,流与表是等价的,流跟表可以进行互转,因此作用于关系表的 SQL 可以适用于流计算中。
SQL 实践
Flink 当前版本(1.8)对 DDL、维表 join 等功能尚不完善,同时内置 UDF 少、connector 少,开发 SQL 任务繁琐,没法做到百分百 SQL 开发流计算任务。阿里巴巴开源的 BLink 对 DDL、维表 join、UDF 等功能有了很大的增强,对于 connector 和 SQL 任务提交等功能开源版本尚不完善。为了解决能够实现完全 SQL 开发流计算任务,我们对 SQL 任务提交接口和 connector 进行了扩展。通过实现 sql-client 中的 Executor 实现了 SQL 任务的 Rest 接口,并提供参数配置、Savepoint 等功能。通过实现 StreamTableSink 、 StreamTableSourceFactory
、 LookupableTableSource 等接口实现了自定义 connector 及维表 join 功能。
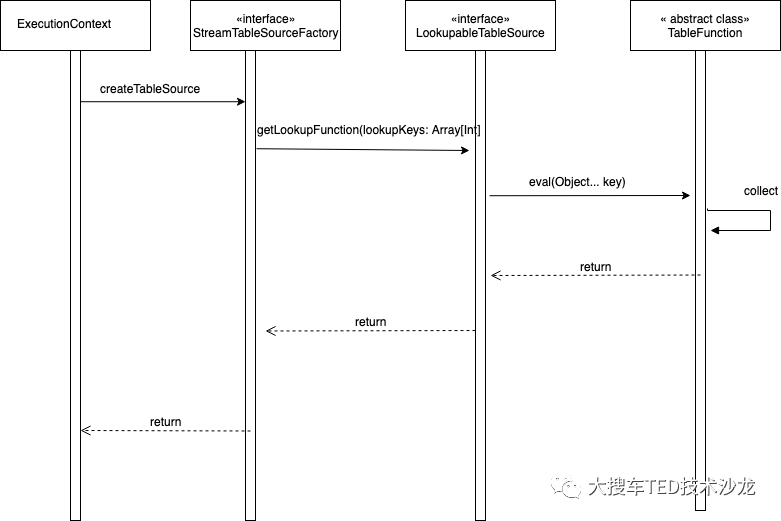
图 6 维表时序图
以此,实现了以 Flink SQL 方式提供平台化服务。通过 SQL 语言优势降低了业务开发成本,提升了开发效率,减少运维成本。原来需要两周的任务,三天既可以上线,上百行的 Java 代码,可以缩减到几十行 SQL 脚本。出现问题后,平台开发人员可以快速定位和解决问题。
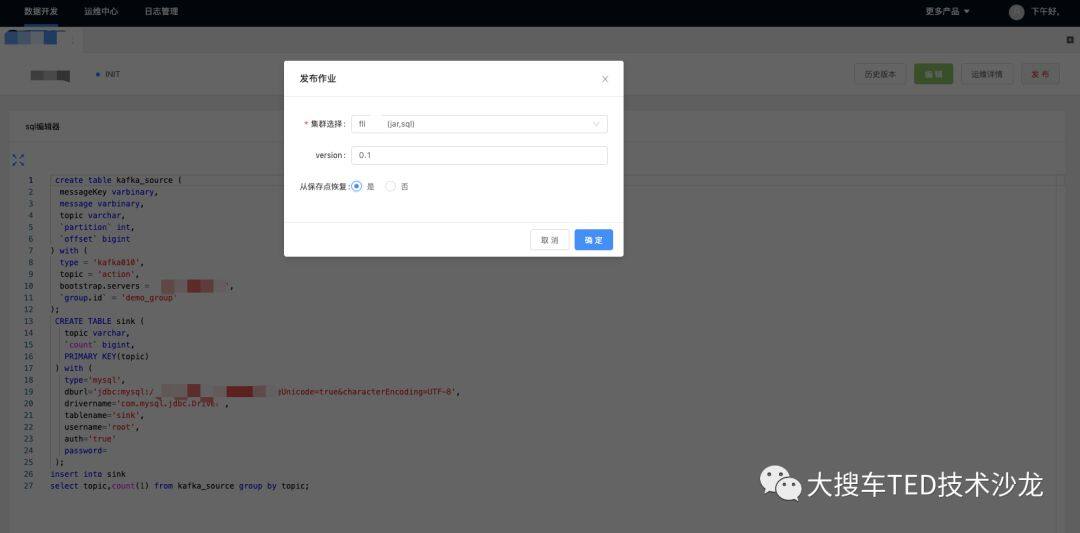
图 7 SQL 任务开发与运行
运维监控
监控报警
流计算任务不同于离线任务,对数据的实时性要求很高,一旦任务出现异常,出现数据堆积将直接影响下游应用,因此流计算任务的监控报警极为重要。大搜车基于 Flink Metrics 并在关键节点(source、sink)开发了自定义监控指标,通过 Prometheus+Grafana 实现了对 Flink 集群的监控及 Flink Job 的监控 Dashboard。同时对任务状态、集群资源等关键指标进行了报警规则的配置,确保平台开发人员可以第一时间获取集群异常信息。
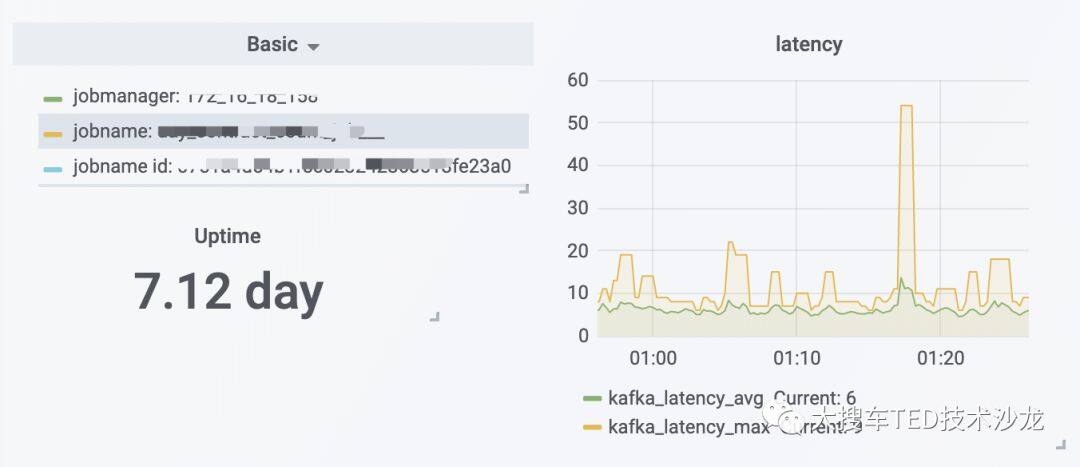
图 8 Flink job 监控
Flink on yarn
Flink 支持 standalone 和 yarn/k8s 等模式,大搜车包括多个工作域,出于业务的需求要进行资源隔离,yarn 模式可以实现对资源的隔离,同时资源按需使用提升资源率。
日志采集
通过 Flink Web 工作台可以方便的查看日志,但是如果日志过多则会出现加载缓慢甚至页面 Crash。可以通过修改 conf 下日志配置进行按日滚动和日志拆分,大搜车在实践过程中,会将 Flink 应用日志通过 Flume 进行采集对接日志平台,方便开发人员定位问题。
远程调试
Flink 是运行在 JVM 上的,因此可以通过配置相关参数进行 remote debug。
再通过 IDE 新建 remote
图 9 远程调试
Checkpoint
checkpoint 的时间间隔不要太小,分钟级别即可。
后期规划
SQL 任务可视化调试
任务血缘关系分析
作者简介:
张迪,大搜车基础架构部资深数据研发工程师,现负责大搜车流计算平台的建设与研发。
本文转载自公众号 大搜车 TED 技术沙龙 (ID: souchedata)。
原文链接:https://mp.weixin.qq.com/s/KVmS0ZToSxlrpdTtclOj4A

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论