

一、业务背景
运满满创立于 2013 年,致力于为公路运输行业提供高效管理配货的 app。在 5 年时间内从初创型公司发展到独角兽企业,我们经历了很多次的技术架构调整。
今天给大家分享下不同时期,在运维监控方面做的多次架构升级。希望给大家在技术选型阶段,提供一些参考和借鉴。
二、架构演进
运满满监控整体可以分为三个阶段:全家桶套餐时代、DevOps 时代、定制 AIOps 时代
创业期:全家桶套餐
在 2015 年以前,公司业务发展的不确定性,服务器数量规模较少。大部分都是靠运维人工监控、每日脚本巡检。
和大部分创业公司一样,当时的运维人员控制在 3 人以下,每天都在处理各类开发需求,完全没有空闲去开发系统,做整体的监控告警。这个阶段,我们急需一款开源的、功能齐全的、入门成本低的监控系统。
Zabbix 是我们当时的选择,简单的配置页面,丰富的 agent 数据采集,支持短信、邮件及微信告警,在一个星期内,我们就完成了全站的基础监控。
Zabbix 开箱即用的使用方式,适合初创型公司。即使是现在,Zabbix 还在线上运行,监控网络设备的运行状态。

发展期:DevOps 时代
到了 2016 年,随着业务高速发展,研发的需求越来越复杂,同时也暴露出 Zabbix 的很多缺点。
Zabbix 性能瓶颈,监控数据存储在 Mysql 中,随着监控数据越来越多,Zabbix 响应时间变慢。
Zabbix 只支持 metric 类型监控,对于日志类监控,支持并不友好。
Zabbix 监控大盘页面不美观,无法满足业务方定制的需求。
基于以上问题,我们开始寻求专业领域内的各类监控。
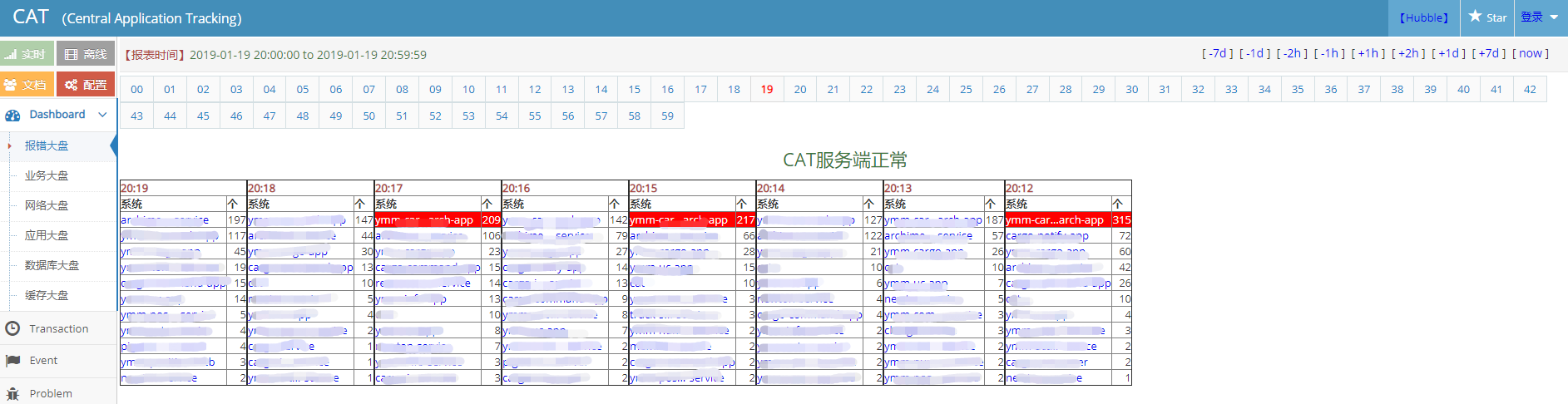
CAT
CAT(Central Application Tracking)是基于 Java 开发的实时监控平台,主要包括移动端监控,应用侧监控,核心网络层监控,系统层监控等。
CAT 的优点是功能丰富,支持钉钉告警,95 线 99 线计算,可展示代码级别监控,在代码层故障定位提供了强有力的工具。
LEPUS
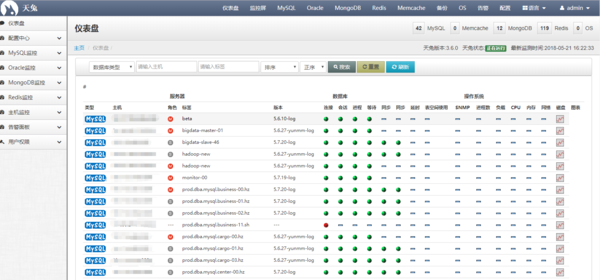
Lepus(天兔)数据库企业监控系统是一套由专业 DBA 针对互联网企业开发的一款强大的企业数据库监控管理系统。Lepus 后端采用 Python 语言开发,对于运维非常友好,可以很方便地作出一些个性化的修改。
Lepus 的优点是无需安装 agent,账号集中管理,适合作为数据库的 CMDB 使用。
ELK 监控生态
ELK(Elasticsearch,Logstash,Kibana)是 Elastic 公司提供的三个开源组件。在日常工作中,我们需要进行日志分析场景:直接对日志文件进行 grep、awk 等正则操作,获取我们想要的信息。在大规模的场景中,日志文件分布在不同的服务器上,且文件非常大,逐台操作性能非常低。比如 Nginx 日志,Mysql 慢查询日志,应用 log 日志等。ELK 提供一整套的解决方案,可以帮助我们快速全站查询。
下图是 Mysql 慢查询的截图,通过 python 脚本,可以实时读取 Mysql 慢查询日志,并写入 ES,方便查看线上问题。
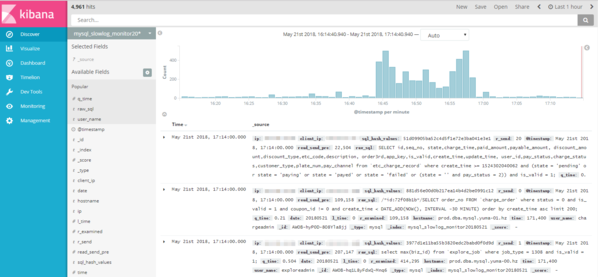
下图是服务器的 dashboard,通过模糊匹配,可以快速查询相关服务器组的性能指标。

Open-Falcon
Open-Falcon 是小米开源的监控系统,灵活的数据采集,水平扩展能力以及高效的告警策略帮助我们快速监控 servers 的信息。在实际的环境中,我们仅采用了 falcon-agent、falcon-transfer 组件,帮助我们采集数据,具体的存储及展示由更专业的组件处理。
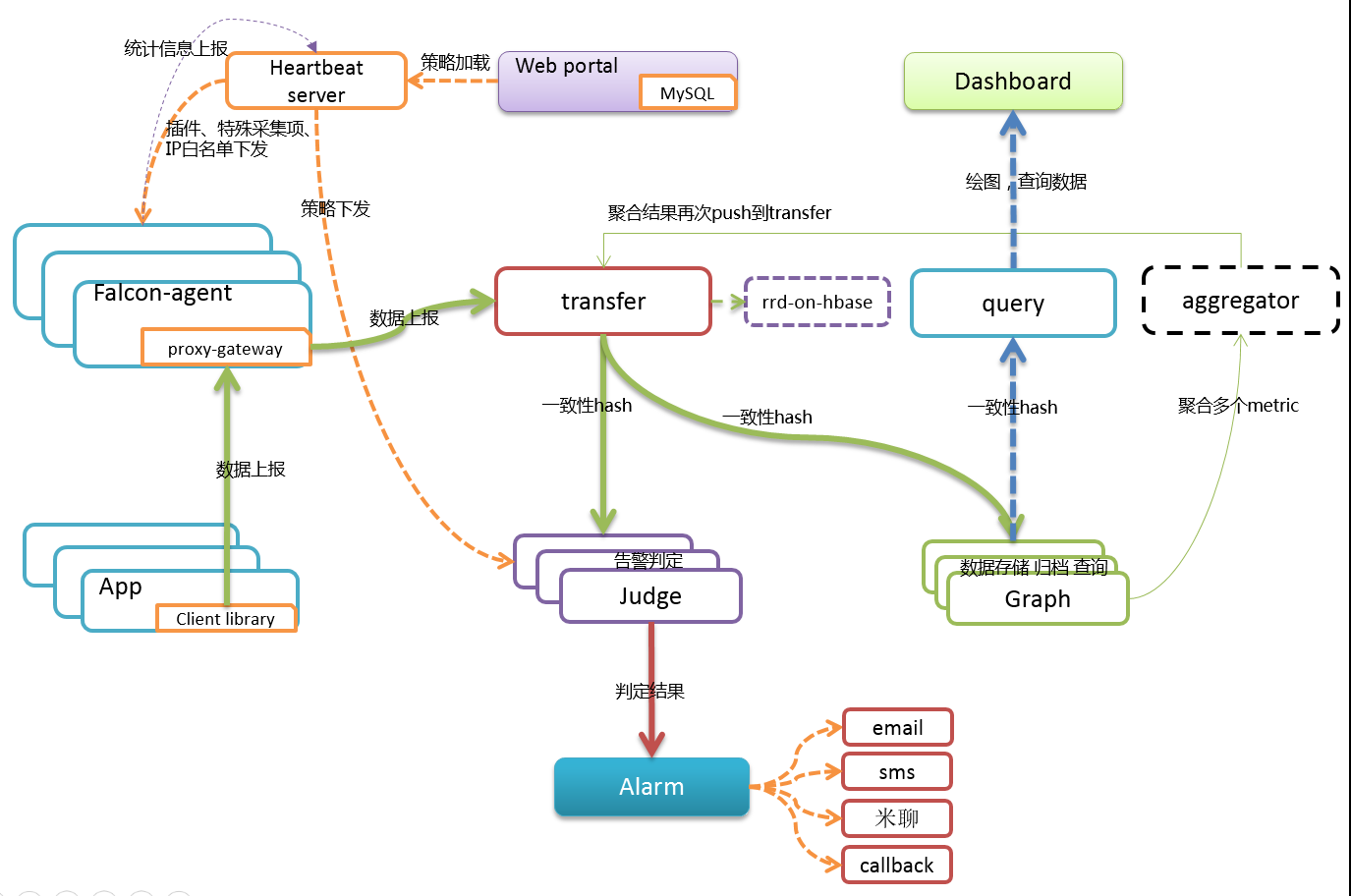
数据存储及展示
随着业务的发展,数据量越来越大,需要一款通用的时序数据库提供数据存储,当时有 Prometheus、OpenTSDB、InfluxDB 三大选择。
Prometheus 提供了丰富的数据模型和查询语句,容易上手,很容易集成到现有的环境中,但是 Prometheus 的集群和 HA 架构并不成熟,需要额外的开发,并不适合。
InfluxDB 是在 Prometheus 之后才提出的,并且提供商业的伸缩和集群化服务,相比 Prometheus 的 metrics 存储,InfluxDB 还能处理事件类型的数据,对于大部分公司而言,商业化基本不会考虑。
OpenTSDB 是一个基于 Hadoop 和 Hbase 的分布式事件序列数据库,相比 Prometheus 和 InfluxDB,OpenTSDB 的横向扩缩容很容易(需要有丰富的 Hadoop/HBase 维护经验),同时官方 Open-falcon 支持 OpenTSDB,结合公司现有的技术栈,综合考虑后最终选择了 OpenTSDB 作为我们的存储。
关于数据展示的选型,在没有自研能力的情况下,Grafana 是不二选择。Grafana 的告警功能强大方便,同时支持钉钉,Webhook 等,满足公司所有的需求。与此同时,我们将 Grafana 和 Docker 技术结合,实现了 Grafana 高可用、自愈和无限扩展能力。
数据库监控

Nginx 监控
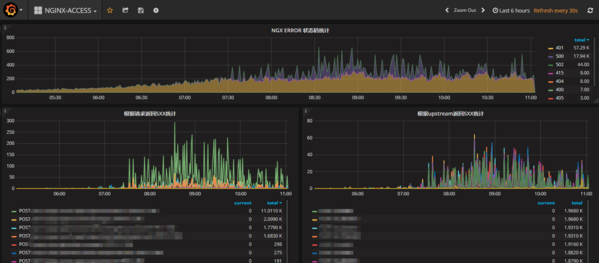
专线监控
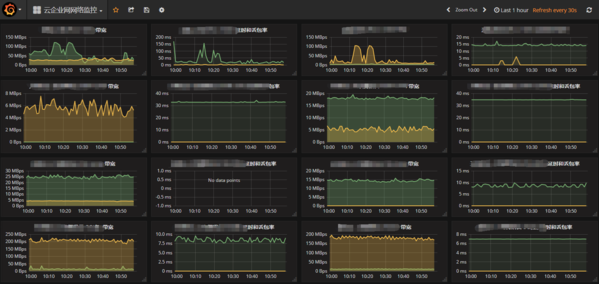
Kubernetes 监控
独角兽期:定制 AIOps 时代
在 2017 年底,运满满与货车帮合并,底层数据量翻倍,人员翻倍。我们碰到了以下几个问题:
问题排查,需要打开多套监控系统,效率低。
每套监控都有学习成本,对研发不友好。
一个故障,多套监控工具同时告警形成短信风暴,扰乱视听。
基于以上问题,我们提出了建设一套大而全的监控理念,主要包括以下几个要素:
同时支持基础监控与业务监控;
事件日志与 metric 指标关联:
告警接口统一;
支持多种语言接入。
监控架构图如下:
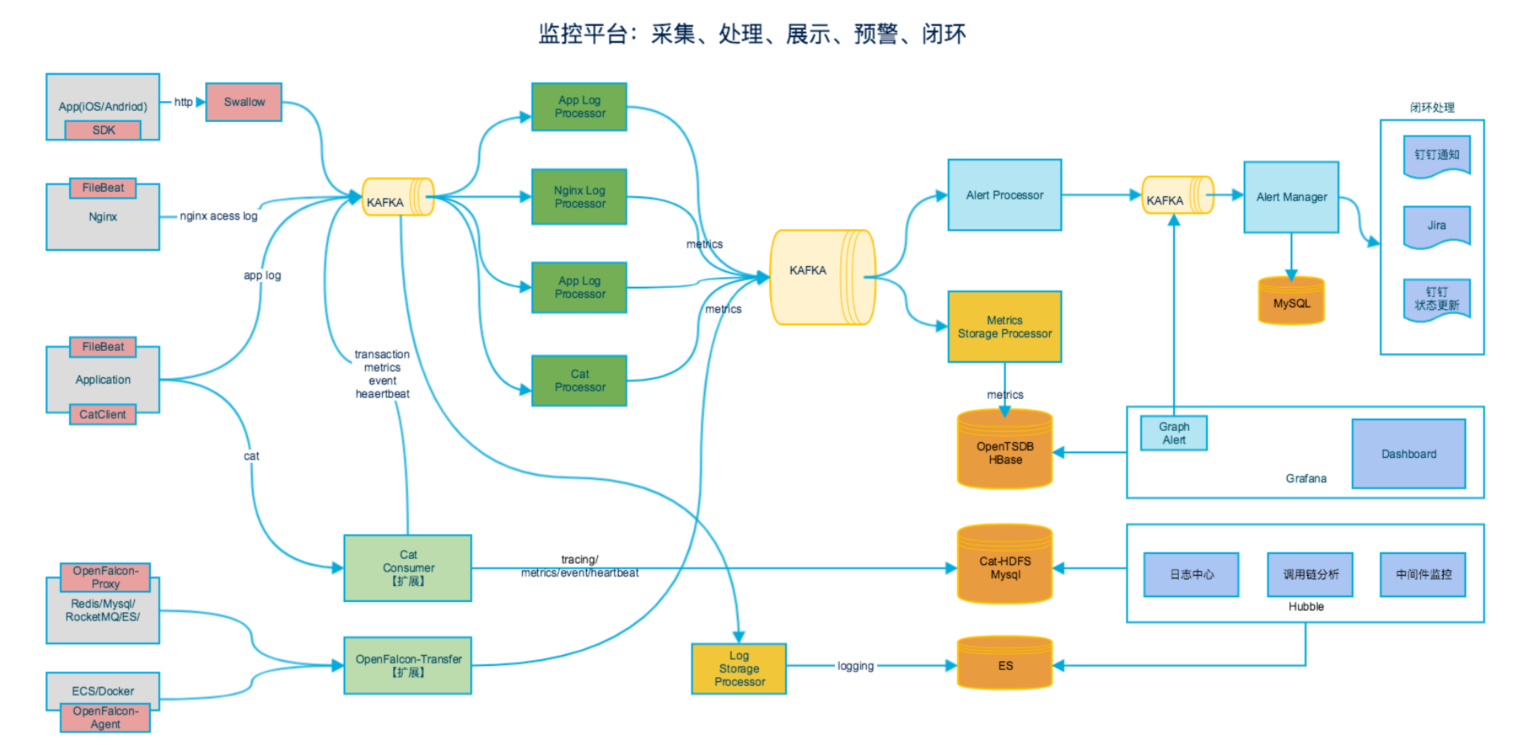
在数据采集阶段,保留了 Open-Faclon、CAT、 客户端 SDK、Logstash 等入口,通过 Kafka 进行汇聚,引入大数据实时计算平台 Flink,提炼 metric 指标,并最终入库。
在告警方面,开发了 Alert Manager 组件,对接多种告警渠道:钉钉、短信、微信等,并且自动创建 Jira,告警闭环。
我们的最终目标是实现 AI 自愈的功能,比如自动降级、限流、流量切换等,目前该部分的功能还在探索中。
作者简介
叶圣贤,满帮集团运满满公司技术保障部负责人。长期关注运维、DB、容器等领域,推崇 DevOps 理念,善于开发工具解决日常运维工作,提高运维效率。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论