

本文由 InfoQ 整理自小红书基础技术部后端开发 孙晓飞 在 QCon 全球软件开发大会(北京站)2022 上的演讲《小红书的降本增效之路》。
大家好,我是孙晓飞,目前就职于小红书容器架构组,负责团队内调度系统整体工作,拥有 6 年云原生相关开发设计经验,是 Kubernetes 和 Volcano member。本文将分享过去一年中,容器架构团队为小红书和整体容器服务在降本增效方面所采用的方案措施。
小红书与云原生
小红书早在 2013 年成立之初便坚定了云原生的方向,主要原因也是出于成本方面的考量,对小型厂商而言,将服务全部上云意味着无需自行搭建 IDC 机房、构建运维体系,便于成本节约。依托云厂商所提供的云服务,小红书可以将主要精力投入到业务研发,快速地迭代升级。经过九年多的发展,小红书的容器化率已经达到 80%有余。
然而,云厂商所提供的便捷云交付方式是一把双刃剑。短短几分钟便可完成的 Kubernetes 集群构建和交付也带来了不少问题:
集群碎片化。早期小红书对集群申请方面缺乏相对专业的评估,内部业务线轻松申请到的小规模集群数量众多,导致了资源的滥用。
版本碎片化。集群申请后缺乏专业团队维护导致版本停滞不前,而 Kubernetes 在过去九年间已有大规模版本迭代,内部集群跨越 1.8~1.22 版本,特性差异极大。
资源碎片化。为处理不同业务场景(如 Redis 的 I/O 问题),容器团队会申请 8 核 16G 之类小型机型作为 node 节点,其机型过小导致后续资源优化难度极大。
容器架构
容器团队的主要工作可按架构分为不同层级,如下图所示:
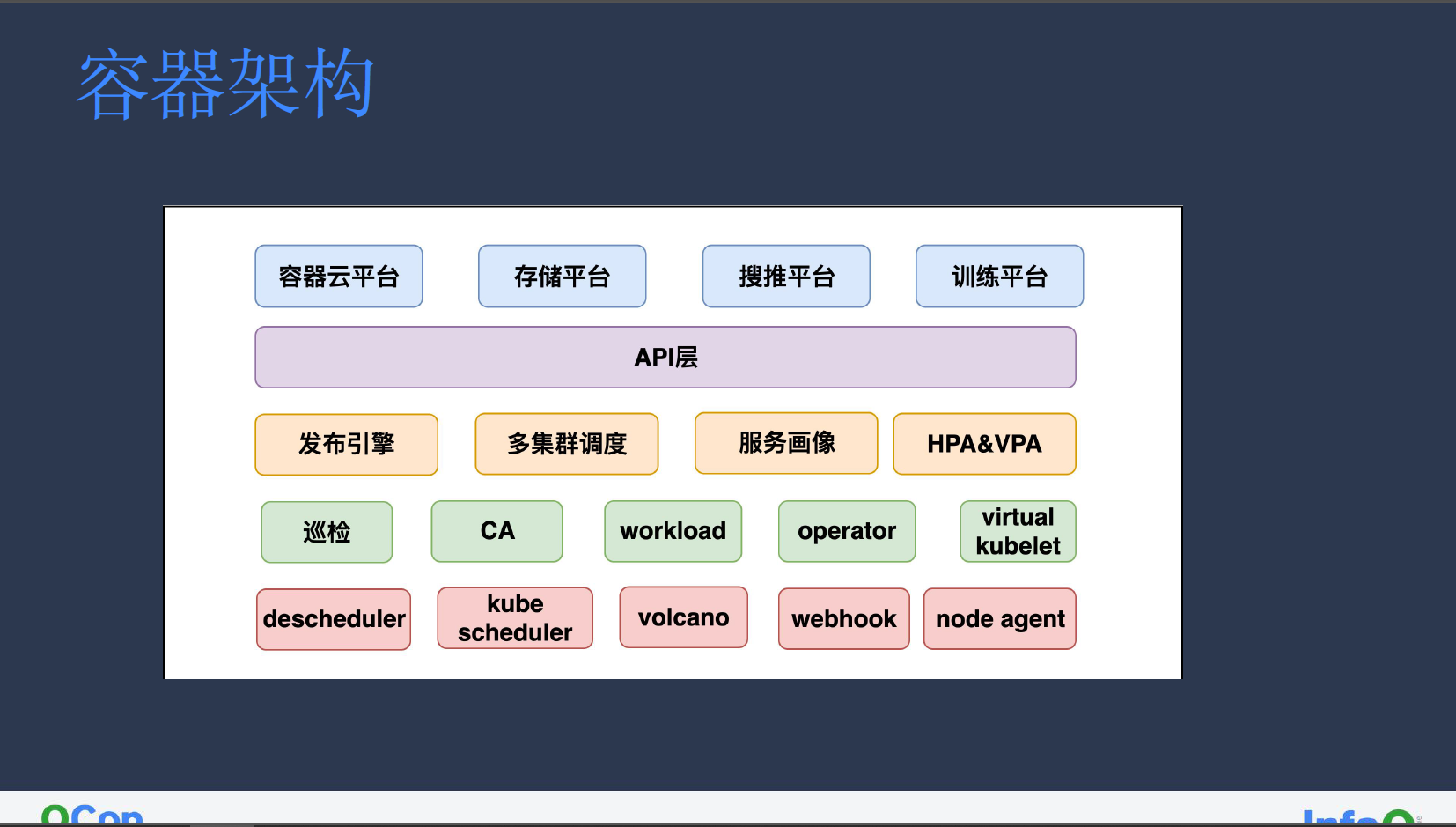
在小红书内部,许多业务最初都是由工程师在集群中提交 YAML 任务申请才能实现服务搭建,为降低业务成本,我们内部构建了容器云平台便于常规业务构建使用。其他平台还包括存储平台(Redis 等)、搜推平台和训练平台。为便于管控,我们搭建了统一的 API 层用于对接所有平台。
在架构下层,我们构建了发布引擎以控制业务的灰度升级、多集群调度模块以筛选出适合业务的集群、服务画像以处理分析历史数据中业务特性、常规 HPA 和 VPA 以处理服务弹性。其次,因为机器涉及多个集群,存在许多机器长期闲置的情况,因此采用巡检模块以便于精细管理;CA(Cluster Autoscaler)模块用于集群自动扩缩节点;定制 workload 面向分片服务;有状态服务定制的 operator;联通小集群的 virtual kubelet。
最后,我们还构建了用于闲置机器治理的 descheduler,其中 descheduler 模块的默认周期性轮巡无法满足部分业务需求,因此我们也通过事件触发的方式对其进行了重构改造;自定义 kube scheduler 集群调度器用于抢占云厂商的默认锁;用于离线训练服务的批调度 Volcano;用于安全防护的 webhook;主要用于混部和故障检测的 node agent。
容器云平台
早期小红书内部业务均是通过 YAML 模式进行部署,这对许多研发而言门槛非常高;新服务往往需要查询许多文档才能完成搭建。
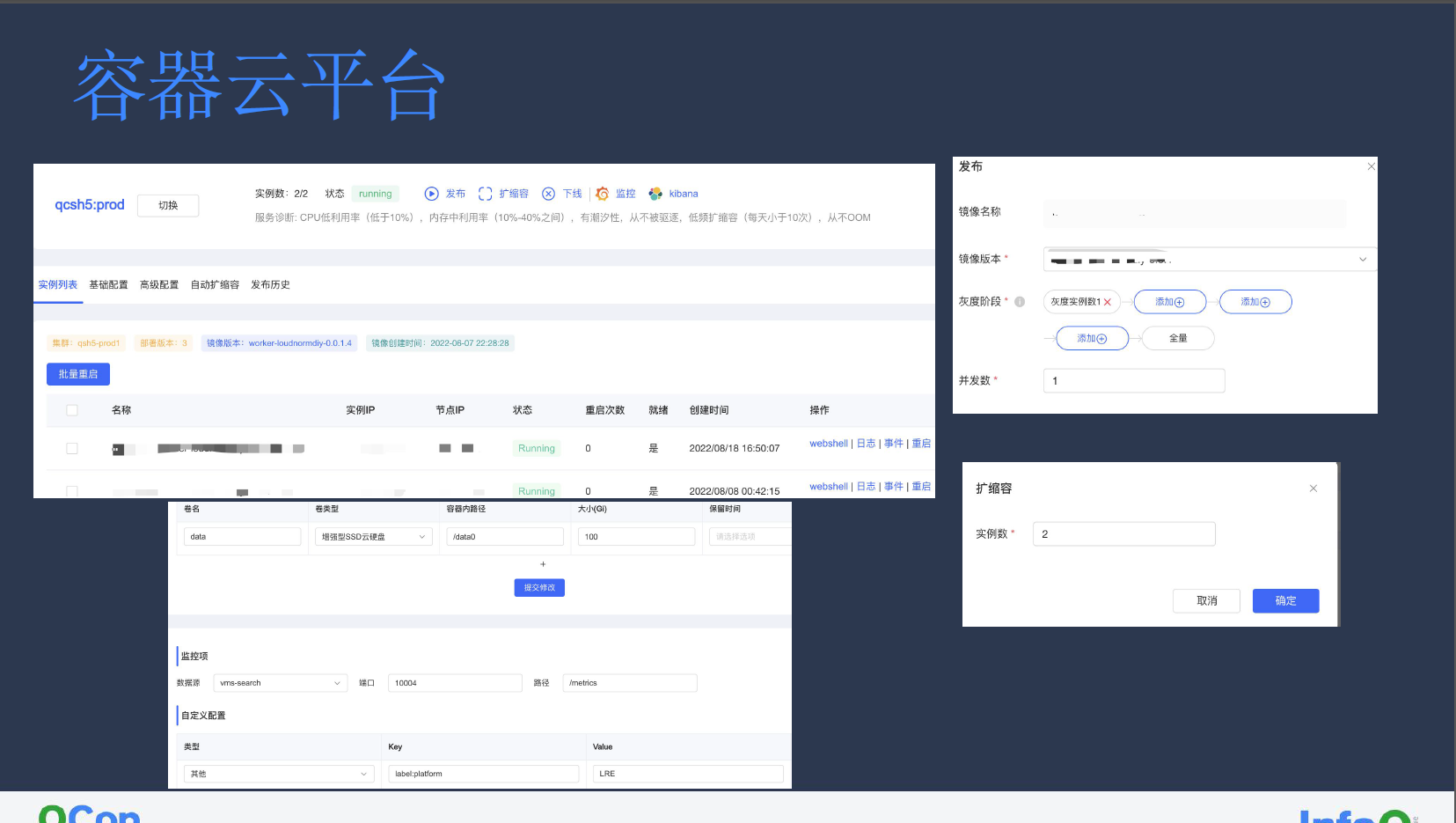
对此,我们希望能将容器云平台的设计尽量简化,让用户只需提供镜像、灰度部署步长、目标实例数等配置,即可实现完整的发布。容器扩缩容也可以通过简单指定实例数实现。当然,我们也提供根据具体业务自定制的高级特性。除了效率的提升,容器云平台的构建还屏蔽了多云多版本的差异,通过封禁发版的行为规范用户行为,以平台侧规范注入的方式,降低了先前业务通过 YAML 模式进行的资源申请的治理成本。
多集群调度
涉及多个集群的业务在发布过程中,无从得知集群资源情况,此时就需要多集群调度模块将具体集群资源情况返回业务服务,之后再通过规则发布引擎将其下发至具体集群进行管控。
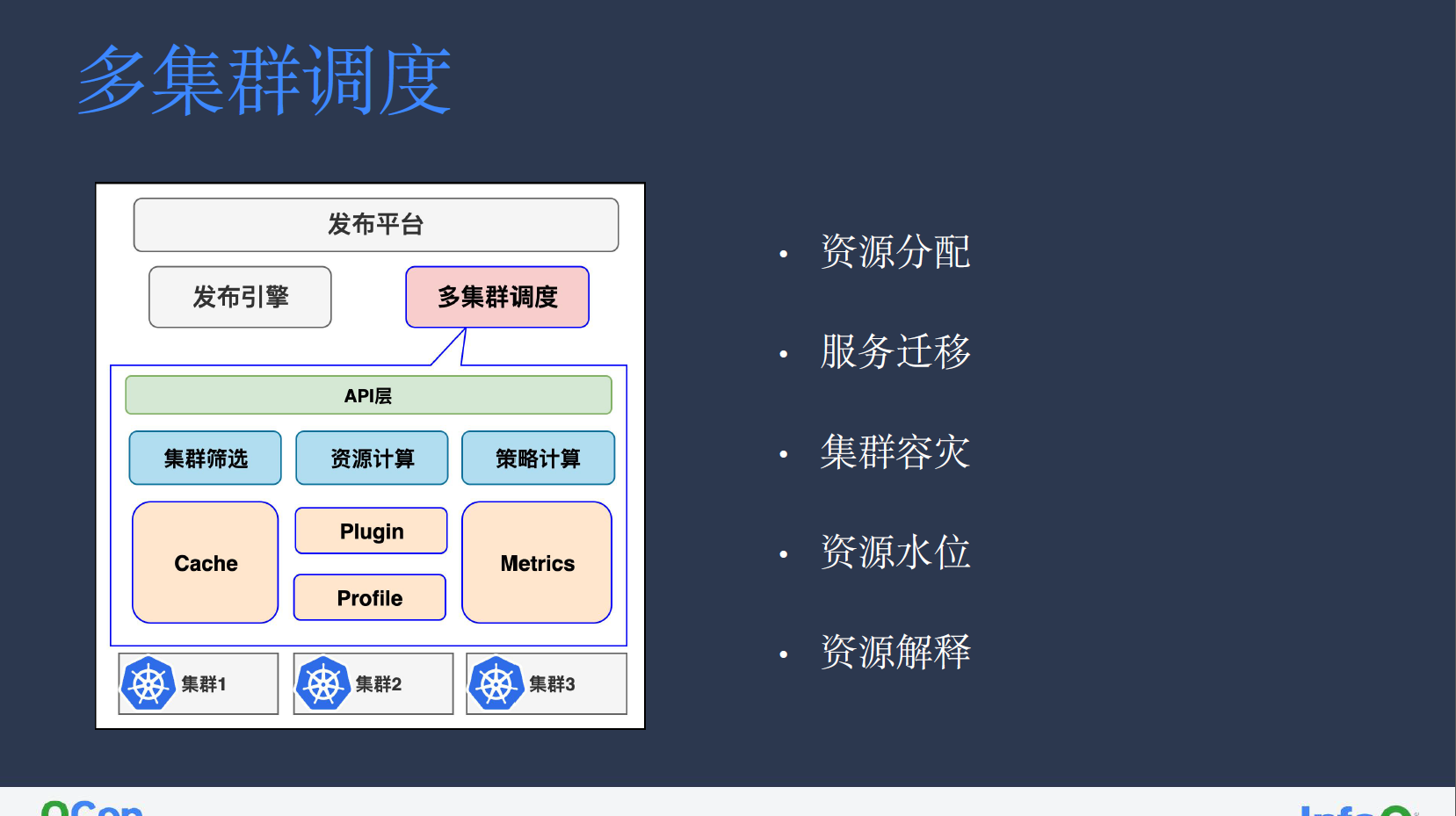
多集群调度模块会同时监听多个集群,其中 Cache 负责缓存 node、pod 等相关资源信息。PlugIn 模块则类似于定制化的 Kube Scheduler 插件,主要负责节点过滤;配置插件启用的 Profile 模块则是负责同步集群中调度策略,不同调度策略都有可能影响集群最终的调度。
在接收到业务请求后,我们首先会筛选出满足业务所需集群特性的 Zone 下的集群列表,根据业务对 pod 等相关信息的请求,计算集群可创建资源,并最终根据其策略筛选出合适集群。如选择剩余资源最多的集群,或根据服务容灾情况返回按一定比例分布的多个集群。
我们在集群调度模块中,主要实现了以下几个方面:
资源分配。根据集群剩余资源情况进行资源最优分配,保障实例调度完成后不出现 pending 情况。
服务迁移。在调度器层屏蔽底层集群场景,做到业务新旧集群迁移时的无感知。
集群容灾。单个集群故障不影响其余集群正常运行。
资源水位。通过 metrics 监听所有集群剩余资源情况,根据资源水位管控结果腾挪资源或机器退机。
资源解释。调度器涉及插件策略众多,为简化排查机器不可调度原因,我们在多集群调度中新增了对应接口,用户只需提供实例和机器信息便能查到节点调度失败原因,如内存不足、PVC 或 Label Selector 亲和性等问题。
容器侧的降本增效改造
分片管理
分片管理的特性主要面对搜索、数据库等有状态服务,主要用于将无法被服务独立承载业务请求拆分,最终将每个分片单独计算的结果汇总返回用户。
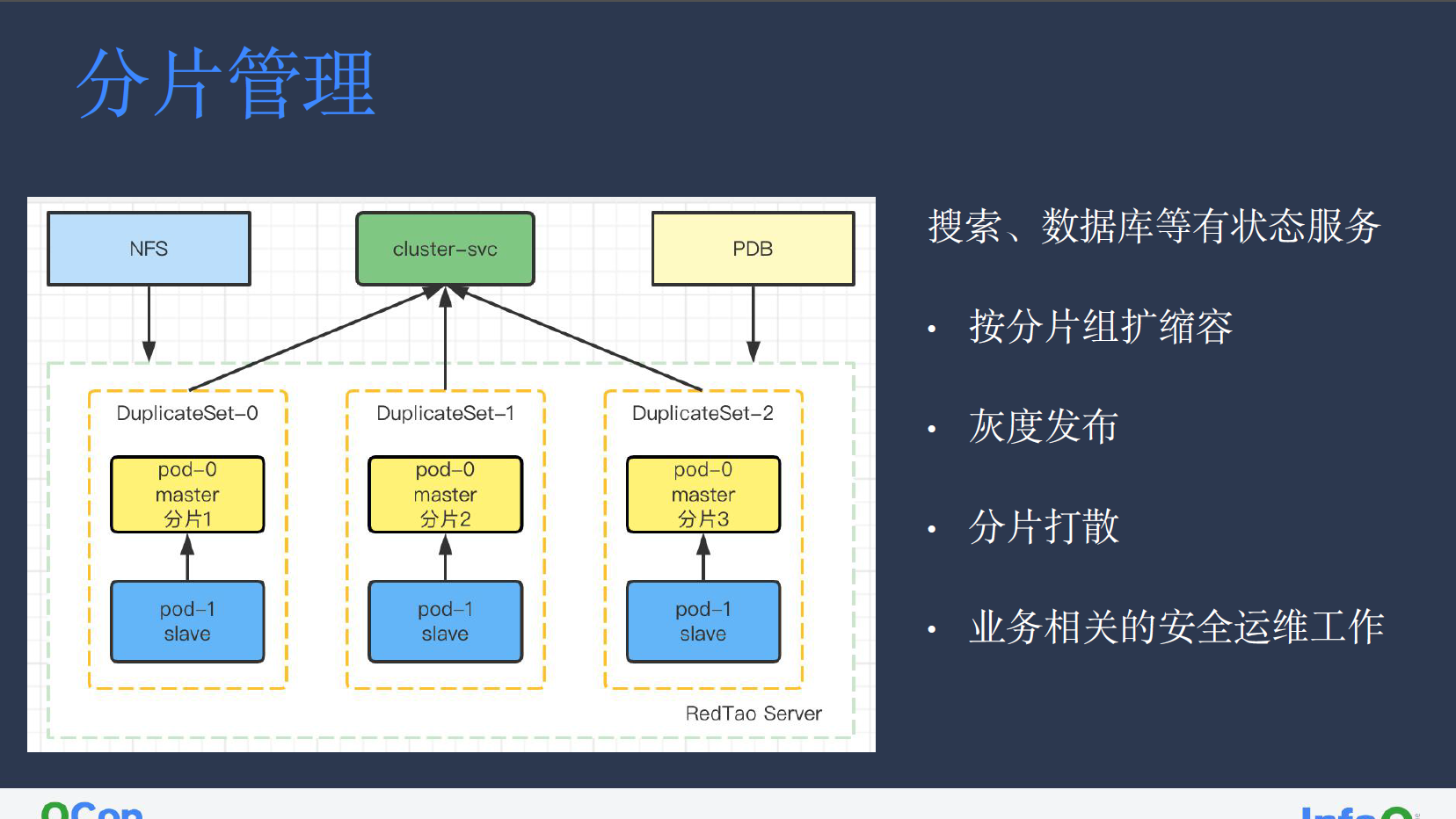
在分片管理中,每组分片是一组独立的有状态服务,由一个分片组 workerload 控制所有分片,用于控制分片扩缩容,确保每一组分片都可同步进行扩缩容和灰度发布。此外,在调度器侧,我们也将分片的多个副本强制打散,确保其不会出现在同一台机器之上。业务侧的安全运维工作则是由相关 operator 实现,如创建 NFS、cluster-svc、PDB 等主要用于防止有状态服务的业务误操作情况发生。
Webhook 扩展
我们也在 Webhook 层进行了扩展,其中包含 PVC 动态 bind、动态超售、删除保护、资源转换、变量注入、规范校验,以下进行展开:
PVC 动态绑定
Kubernetes Deployment 之类无状态服务因为其随机的命名方式,导致无法动态创建 PVC,为此,我们在 Webhook 层进行了相应注入。业务只需在 pod annotation 中添加指定字段,便能在 Webhook 层自动创建 PVC,并将其更新至 pod 的 YAML 模板中。该功能只能在 Webhook 层实现,因为提交至集群的 pod YAML 模板将无法变更。
动态超售
许多业务套餐申请不合理,而容器平台无法单独为业务进行变更,因此我们通过服务画像获取监控数据,计算 node 节点当前利用率信息,从而得出超售系数。如下图所示,我们在 Webhook 层拦截 Kubelet 上报的 node allocatable 信息请求(64 核 256G),如果我们通过计算得出其超售系数为 2,则会将该 node 的节点资源信息视作 128 核 256G。通过这种方式,我们可以在集群中部署更多服务,而超售系数的动态调整也允许我们根据资源超发或节点利用率提升等情况,进行热点驱逐。
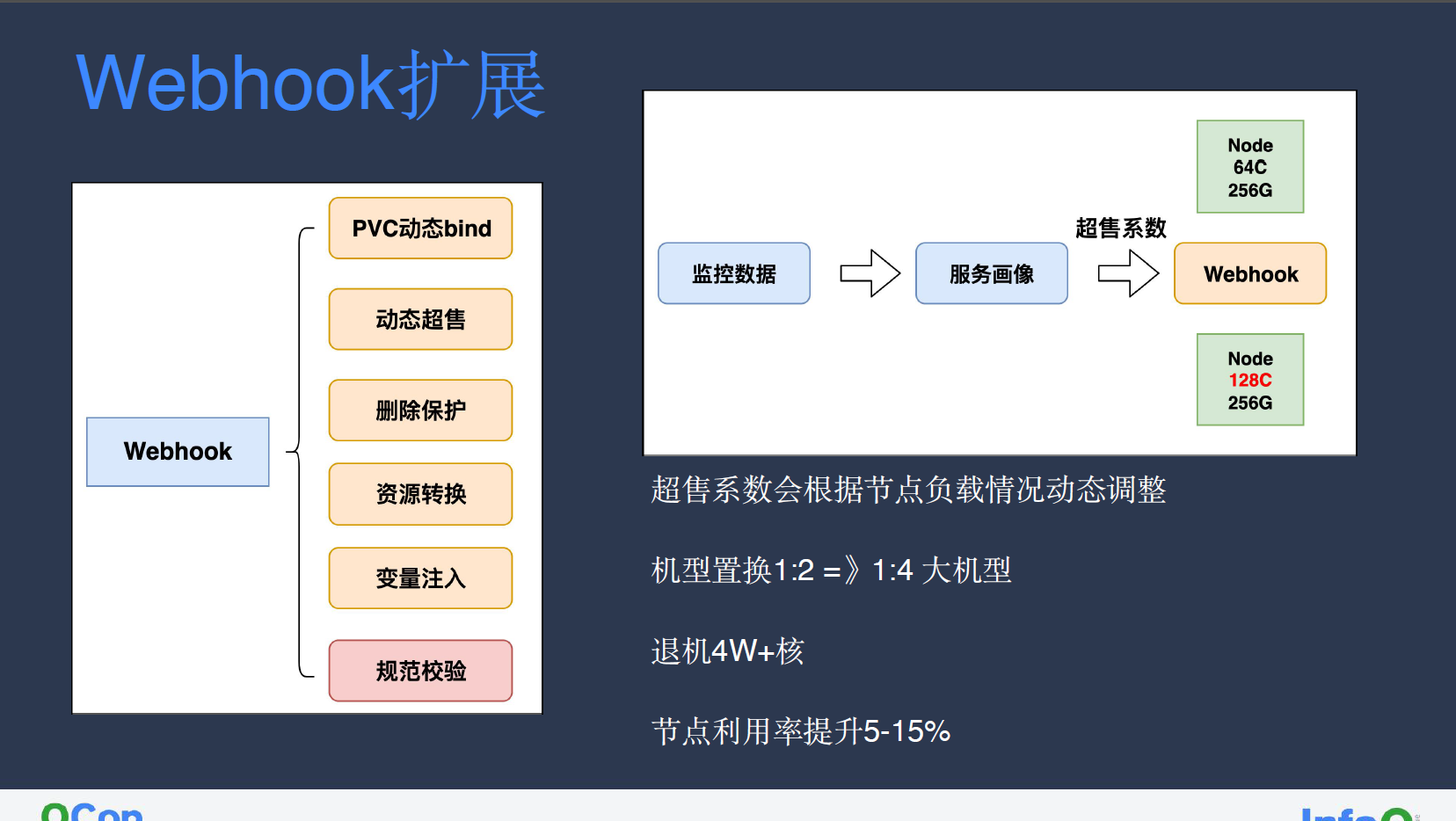
小红书大部分服务在前期仍使用 1:2 机型,在这种情况下单纯的 CPU 超售无法解决节点不可用的问题,为此我们通过将其置换为 1:4 大机型,充分利用超售资源,从而实现了整体退机 4 万余核、单节点利用率提升 5%~15%的目标。
删除保护
这一功能与小红书先前遭遇的几起故障相关。通过在 Webhook 层拦截请求,限制 Ingress Service 等对象的随意删除,仅允许添加特定 Label 的请求才允许进行全部服务对象的删除操作。
资源转换
Webhook 层的资源转换功能主要为实现独立扩展资源(如离线资源)的业务无感知。
变量注入
环境变量如 Region、Zone 等业务相关信息,以及 Sidecar 等变量注入均在 Webhook 层实现。
规范校验
业务必须遵守小红书内部制定的规范,如业务套餐 Request 大小限制,出于内部机型限制问题,过大的 Request 会导致服务调度失败。
资源弹性
云厂商提供资源的一大优势是资源弹性,我们可以按需申请机器。直接从云厂商处获取的机器可能会因为资源不足或者网络限制导致失败,需要人工介入。从云厂商开新机器大约耗时五分钟,一些高优服务扩容是无法容忍这个开机时间。
我们在集群部署了 CA(Cluster Autoscaler)在集群内维护的一定 Buffer 池,提前储备部分机器,减少业务扩容等待时间。
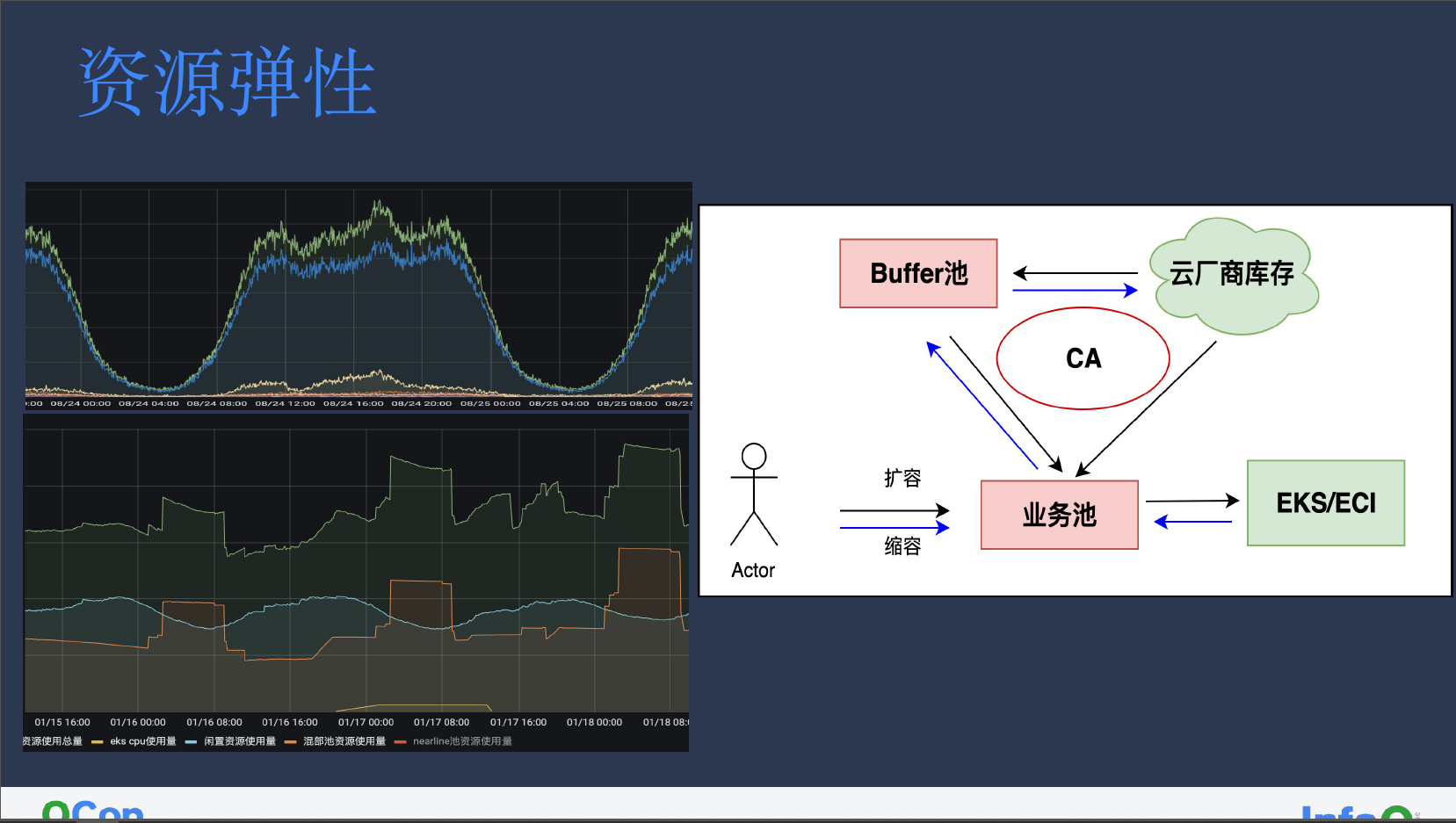
CA 会在检测到业务扩容失败时,直接从 Buffer 池中添加机器至业务池,但如果 Buffer 池资源不足我们也会直接从云厂商库存中获取机器。缩容同理,在业务池进行缩容时,CA 会对机器进行碎片整理,将大机器清理完成后放入 Buffer 池中,如果 Buffer 池中机器存在超过 24 小时则会自动退回云厂商库存,从而实现资源的弹性管理。
因为小红书中部分业务对 daemonset 部署的基础组件有强依赖,只能通过 CA 管控常规机器的方式进行扩缩容。至于其他对公司内部基础组件没有依赖度的业务,则可直接使用云厂商的 EKS 或 ECI。对弹性服务而言,白天高峰期短暂使用(低于 16 小时)EKS 或 ECI 资源往往会比常规机器价格便宜,但这也取决于各家的不同报价折扣。
服务弹性
我们的服务弹性功能是基于常规 HPA&VPA 进行了定制开发的改造。小红书内部 Kubernetes 集群版本碎片化严重,各个集群的 HPA&VPA 行为不一致,很难为其提供行为保障。因此,我们在集群之上开发了统一 HPA&VPA 功能,通过采集服务画像和 Prometheus 信息,从而实现了定时扩缩容、按利用率扩缩容,以及业务自定义指标扩缩容能力。
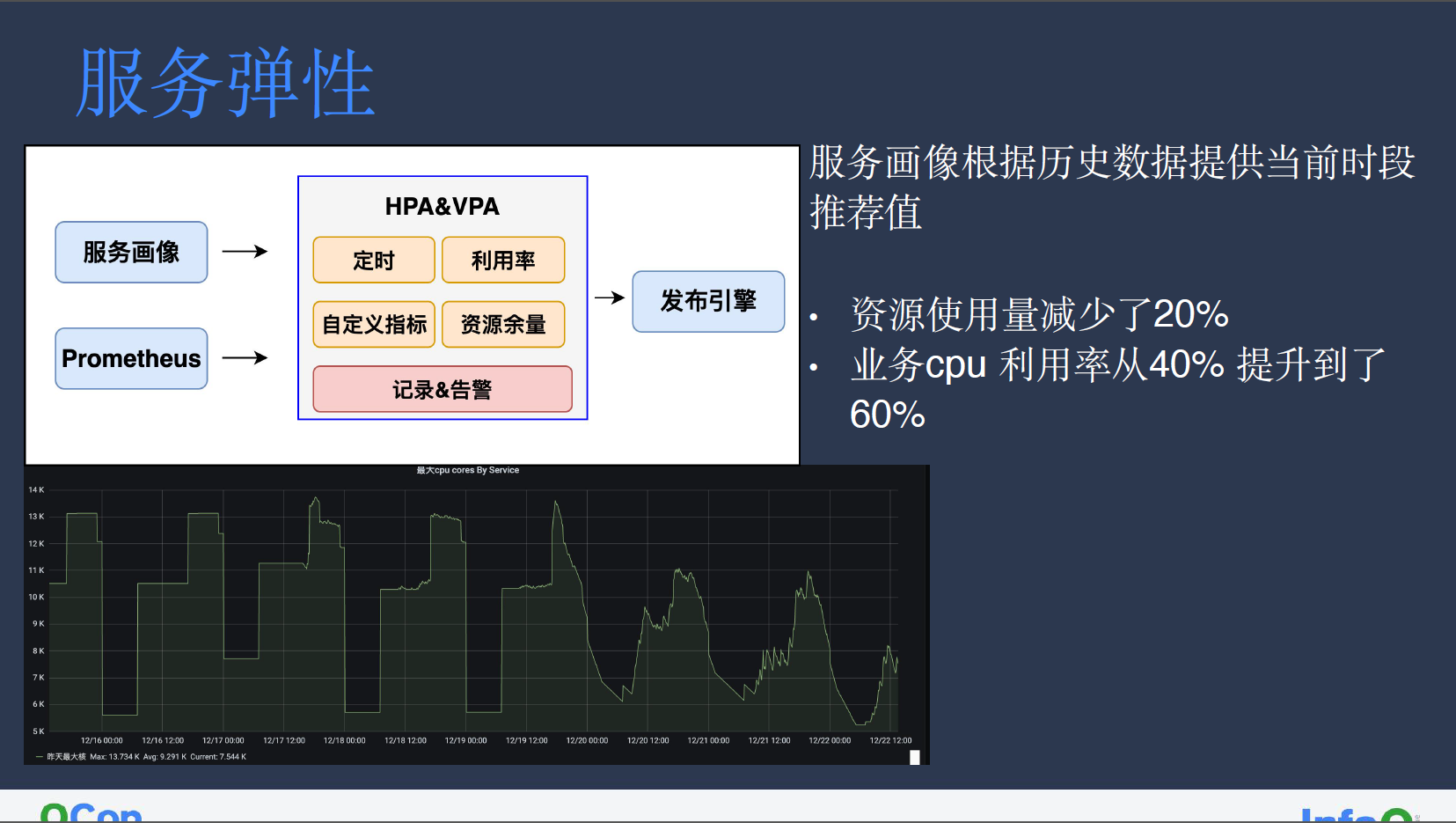
此外,我们也新增了按资源余量扩缩容的能力,主要面向转码等离线资源使用。我们希望能让转码等离线服务充分利用夜间时段的空闲资源,夜间资源扩容较多可能导致正常在线业务扩容失败,而夜间扩容较少则可能导致资源浪费,按资源余量扩缩容可以更充分地利用资源。
以转码服务为例,我们在根据服务画像获取到业务平均利用率的推荐值后,首先对其进行定时扩缩容的改造,后续再根据业务指标进行改造,在我们所提供的推荐 CPU 利用率下,整体的业务资源使用量减少 20%左右,服务利用率则从 40%提升至 60%。
统一 Kube-scheduler
小红书 Kubernetes 集群版本众多,集群版本横跨 1.12 至 1.20。为了统一集群调度行为满足未来调度需求,我们选择基于目前较为稳定且版本最新的 1.22 进行改造开发。
由于 Kubernetes 集群均是托管至云厂商,master 组件对我们而言并不可见,我们首先修改了 1.22 版本 Kube-scheduler 调度器抢锁逻辑,将我们自己调度器的锁优先级调整至最高,云厂商调度器变为 standby 模式,从而接管整体集群的调度。
1.18~1.20 版本:Kubernetes 集群没有太多变化,主要为 PVC、volume 相关版本从 alpha 升级 至 GA 等等,故而版本兼容只需简单通过 feature-gates=CSIStorageCapacity=false,PodDisruptionBudget=false 命令关闭没用到的 CSI、PDB 等功能。
1.14~1.16 版:将 NodeVolumeLimits、VolumeBinding 关闭,前者是为限制每个 node 中 PVC 数量,其中插件多半为国外云厂商所提供,故而我们进行了单独的改造。VolumeBinding 延迟挂载在我们大部分场景,尤其是低版本,因此我们也将该插件注销。
1.12-1.13 版本:因为 1.22 版本默认抢锁模式是通过 Lease 实现,因此我们只需在部署时抢锁模式指定为 endpoint。
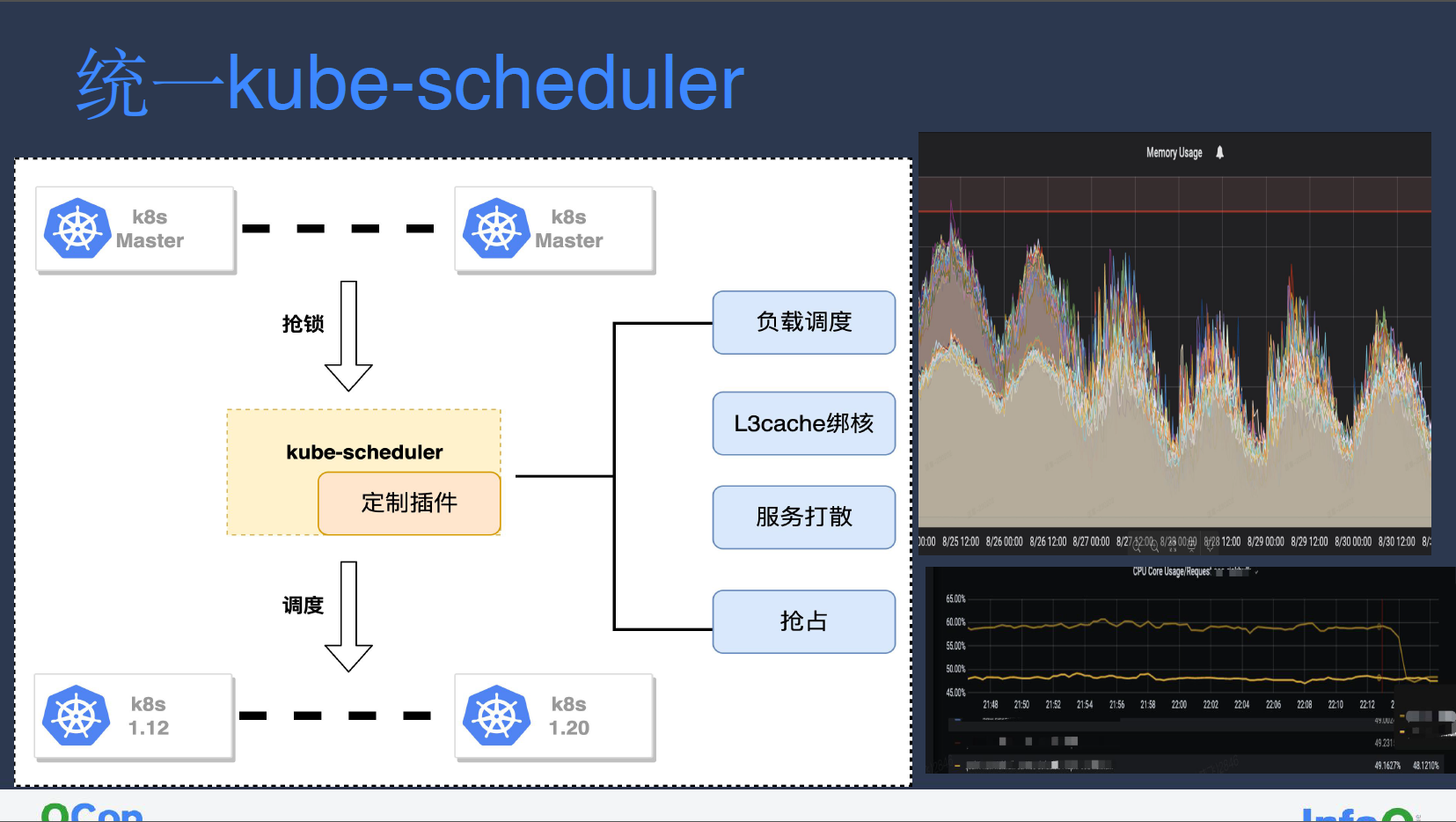
通过调度器版本统一,我们可以统一所有集群的所有调度器行为。此外,我们也开发了插件定制化,其中包括:
负载调度。如图中右上所示,开启负载调度后内存利用率基本趋于均衡。
L3cache 绑核。小红书所使用的主要为相对较为廉价的 AMD 机器,其架构主要为 Zen,使用 CCX 的 CPU 堆叠模式,即 AMD 每四个物理核(即八个逻辑核)共享一个 L3cache。因此我们在进行调度时需要尽量将 8 核或 16 核机器绑定至同一个 L3cache 上,从而提高 cache 命中率,进而提升服务利用率。如右下所示,部分服务在开启 L3cache 后利用率有显著下降。
服务打散策略。默认调度器的服务打散仅针对 deployment、statefulSet 等原生 workload,因此我们需要针对定制 CRD 进行扩展,使其具备打散能力。此外,我们也定义了强制打散、尽量打散等策略。
抢占。根据服务特性,我们对抢占功能进行定制开发。
Volcano 调度与抢占
我们在训练集群的服务主要用 Volcano 调度器。小红书的训练服务高峰期主要在夜间,为应对夜间资源量不够的情况,我们将部分峰值流量卸载至云厂商的 EKS,从而减少机器成本。
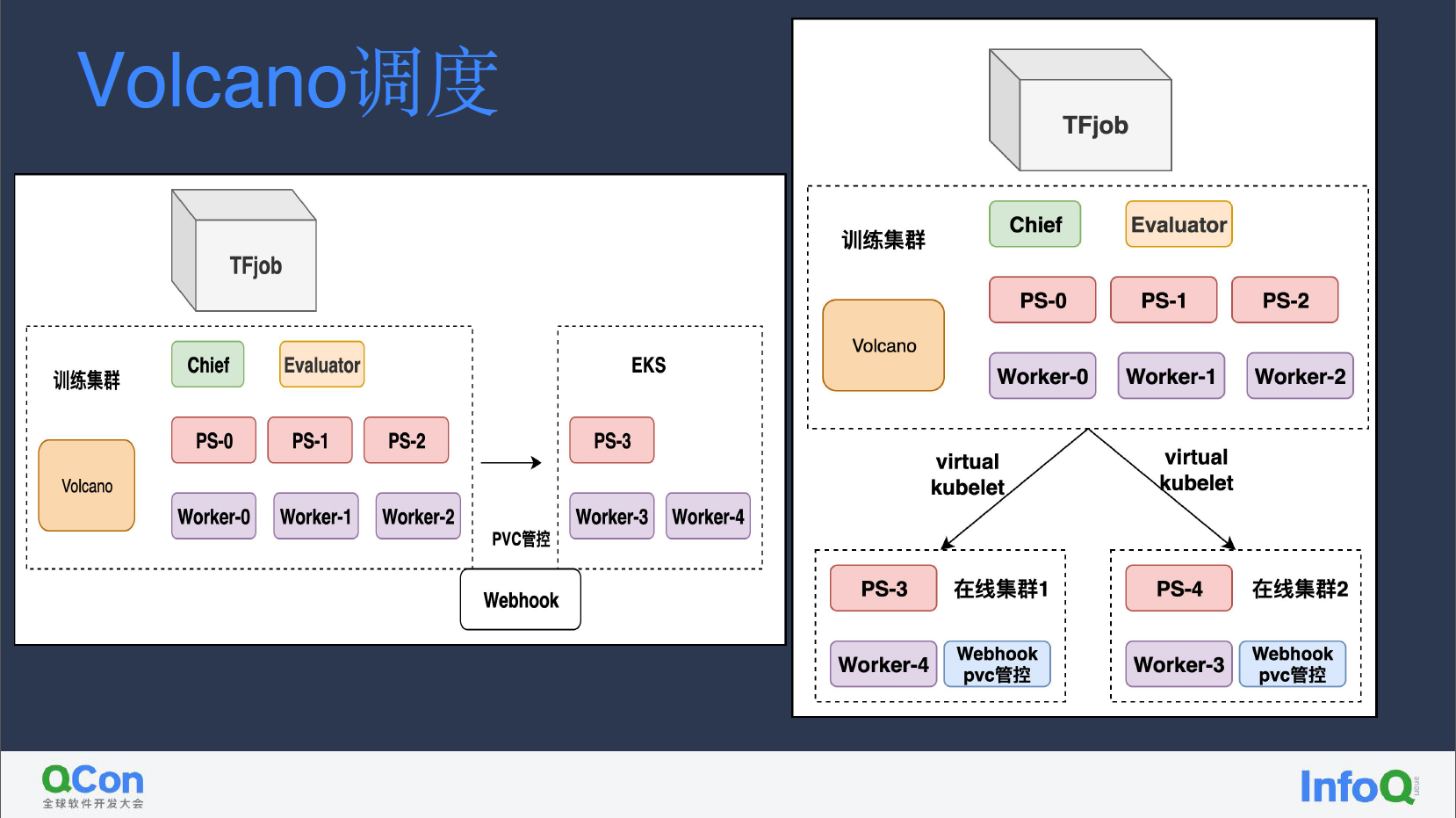
由于很多在线集群的服务开启了 HPA,在线集群在夜间时段也有很多剩余资源。我们通过 virtual kubelet 打通在线集群与训练集群,让夜间的部分训练任务能够在在线集群中运行。
我们的训练任务使用的是 Kubeflow 计算框架 ,TFjob 训练任务套餐大、数量多,再加上按照 queue、资源池划分机器资源,整体集群资源碎片较多。为此我们会用部分低优先级、可随时中断的离线任务填充资源碎片空间。此外,因为 TFjob 往往根据业务触发时间提交,时间不固定所带来的碎片时间也可以用低优先级的离线任务填充。
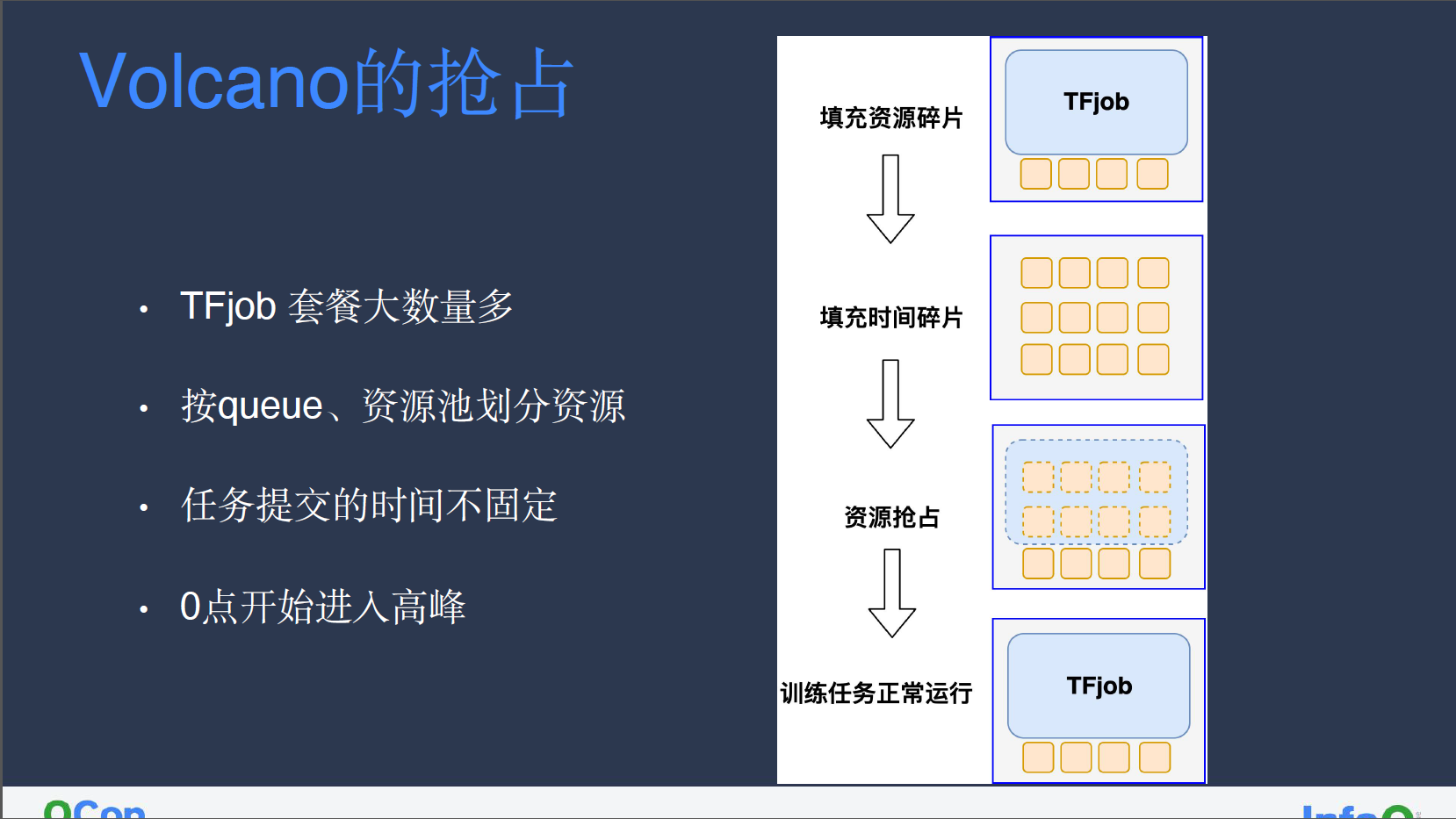
我们增强了 volcano 的抢占功能,批调度的抢占和普通的抢占不同,因为训练集群大部分时间有大量 pending 的训练任务在等待调度,不能以 pod 维度进行抢占,必须以 podgroup 批调度维度进行抢占。volcano 在抢占之前,会进行预调度,在预调度阶段计算出驱逐哪些离线转码服务,能让整个训练任务整体可以运行,才会执行抢占动作。
训练集群只损失了 30s+的启动时间(需要等待离线转码服务 30s 退出),但整个训练集群的利用率提升了约 10%。
闲置资源
我们通过巡检模块,从服务画像中获取机器过去三天的资源使用情况,再结合机器当前资源信息生成报表,从而发现业务闲置机器。机器闲置原因有很多,可能是业务在申请后遗忘了机器,业务在先扩后缩,灰度发布时所申请的 buffer 资源,为防止业务紧急扩容而提前储备的 buffer 机器等等。
我们会根据巡检模块生成的闲置机器报表,如果是业务遗忘的机器,会进入退机流程;其他情况则会将机器添加指定 label,加入到闲置池中,这一过程主要是通过 Descheduler 二次调度器实现。
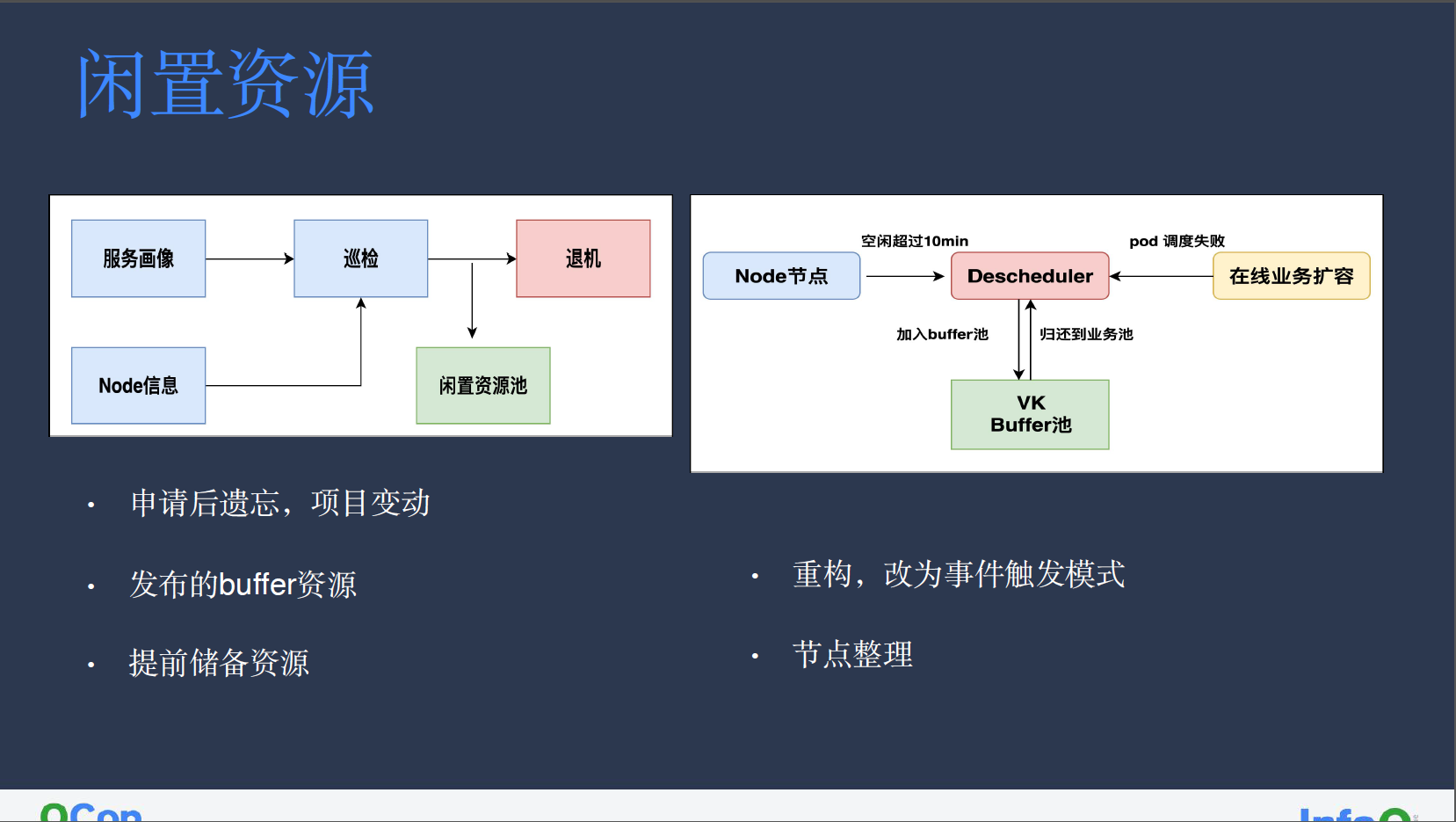
Descheduler 会定期检测 node 节点的闲置情况,连续超过 10 分钟的闲置机器会被标记为 VK Buffer,并放入 VK Buffer 池中。如果在线业务在扩容时因为资源被占用而调度失败,我们会通过 Descheduler watch 到调度失败信息,并将 VK Buffer 池中机器上的离线服务驱逐,将机器并归还给业务。
对业务而言,日常更新升级不受影响,只是服务扩容时间略有增加,但整体集群的资源利用率得到有效提升。
混部资源
混部资源的主要组成部分是业务申请与实际使用的差,再加上集群的碎片化资源,整体架构有参考阿里的 Koordinator。
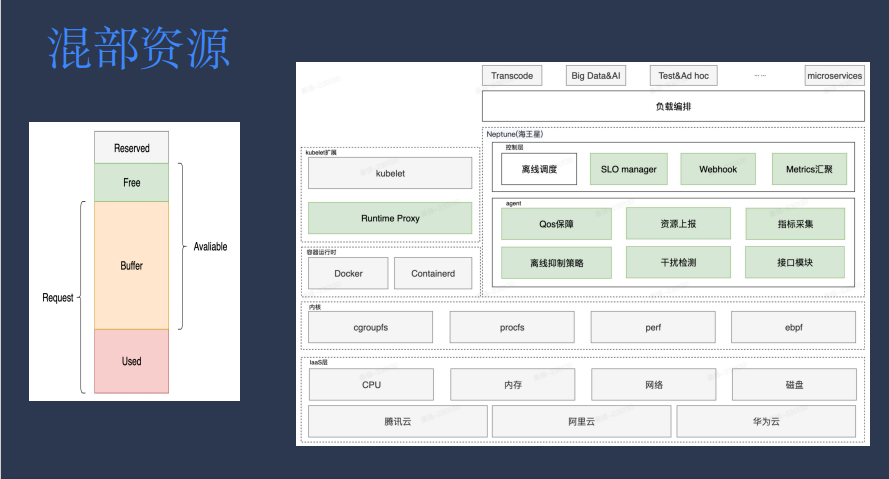
架构上层的 SLO manager 主要负责全局计算,综合计算 node 节点资源使用、剩余情况,如网络带宽等方面,从而得出机器节点可用资源情况。
Agent 侧的 QoS 保障模块总管离线服务,根据离线抑制策略和资源使用情况判断是否需要执行驱逐。该模块同时也负责干扰检测,将干扰在线业务的离线服务进行驱逐。其余模块还包括指标采集、接口模块。
闲置资源治理
由于小红书集群多且比较分散,每个集群闲置机器或者混部资源并不多,我们通过 VK 将各个小块资源聚合起来,统一接入到元数据集群,进行统一调度分配。
VK 下层则接入了在线集群、训练集群,以及混部集群资源:
在线集群:通过 descheduler 巡检找出闲置机器
训练任务:volcano 通过抢占提供的碎片资源
混部集群:混部资源
我们将离线服务大致分为近线和离线两类:
近线服务 pod 可以被驱逐,资源供给可以有几分钟的延迟。这类业务优先使用常规 node、闲置资源、混部资源,高峰时段还可以使用 EKS 资源。
离线服务则可以容忍长时间 pending,对于这类服务,会使用近线资源剩余的部分,不会用 EKS 资源。
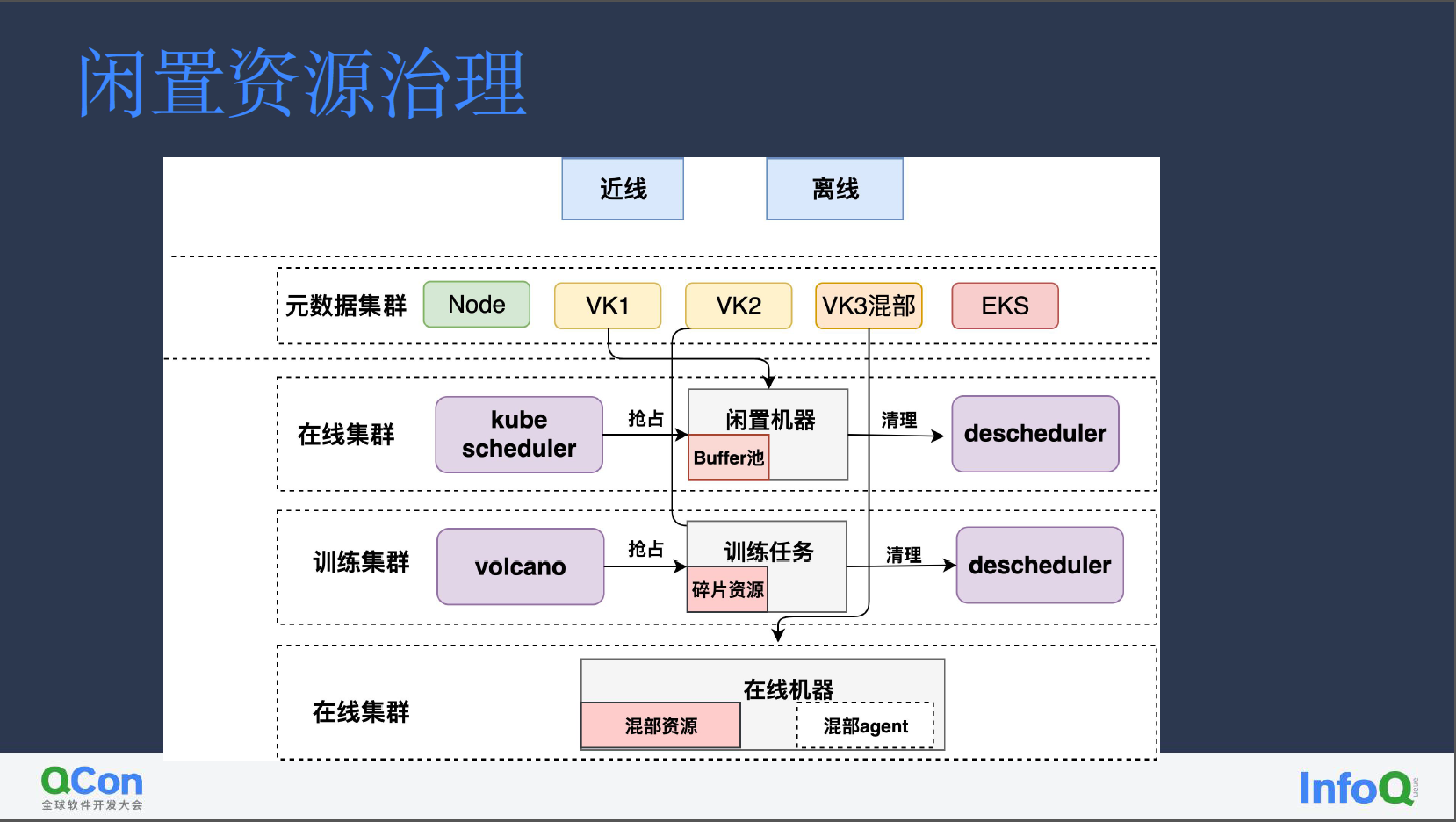
通过闲置资源治理,在线闲置池能为我们提供约五万核算力,训练集群能提供约一万核算力、在线集群混部资源则也有五万核算力,整体为我们带来了 11 万核的算力。
成果
总体来说,我们的成果如下:
通过超售及机型置换,实现了退机四万核的目标
闲置池资源治理,提供了五万核算力
资源混部,提供了五万核算力
整体集群利用率提升了约 7%
探索
因为集群划分较为分线,因此我们借助 VK 将 kubeflow、airflow、flink、存储等独立集群相连接。
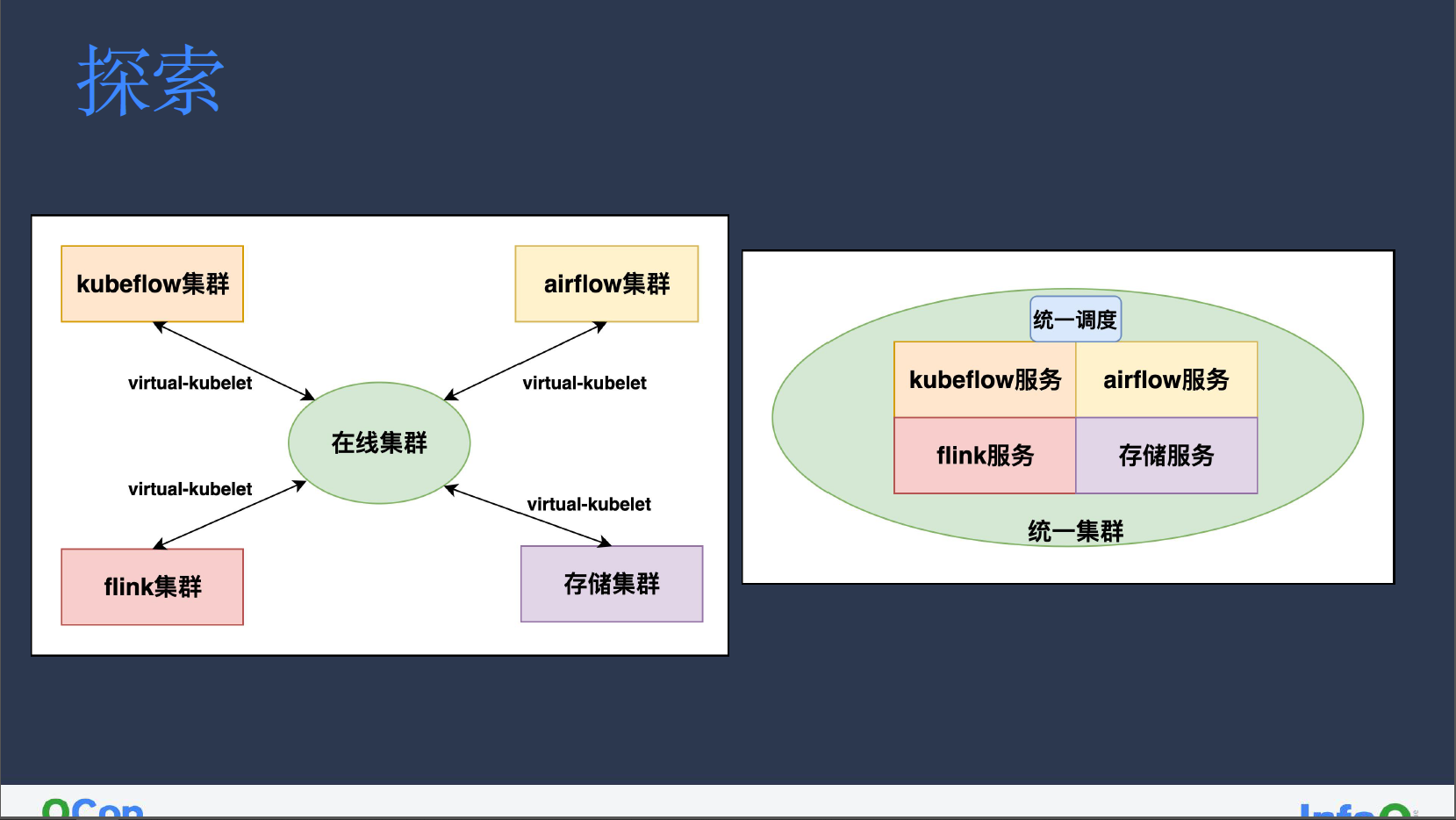
由于 VK 本身架构设计模式所限,部分问题无法得到解决,其中就包括:
VK 社区的不稳定性,其中存在许多潜在问题,我们是在使用一年左右才基本达到稳定。
VK 无法准确测量资源情况。调度至 VK 的服务可能存在不同套餐,这些套餐都会影响对资源的计算,套餐的随意变化则会影响服务对底层实际集群的调度,导致 pending 情况出现。为此,我们通过提高 VK 的预留从而避免这类情况发生。
PVC 无法进行跨集群迁移。这种问题主要针对 pod 共享的 PVC 上有相关业务数据的场景。但如果只是动态 PVC,那么为减少对机器 I/O 的限制,先前提到的 Webhook 注入也可以用于管理这类 PVC。
我们后期的主要目标,是将小集群集中放置到统一集群中,以基于 kube-scheduler 的方式进行统一调度,希望能减少先前在 volcano 中遇到的诸多问题。
主要改造方向基本可以分为三点:
在离线统一调度。增强批调度能力,加强离线服务目前所匮乏的资源管控能力。
推动混部业务大规模上量。让混部业务不再受限于集群和机器规模、特殊有状态服务等情况,实现大规模上量。
训练任务的弹性伸缩。TFjob 对失败容忍度很低,单独 worker 失败即会造成整体训练精度降低,三个 worker 训练失败则会导致任务失败。我们需要通过夜间弹性方式,将在线业务的夜间时段空闲资源供给离线业务使用,同时也要增强 TFjob 对 worker 调度失败的容忍。
作者简介
孙晓飞,小红书基础技术部后端开发,毕业于北京邮电大学,曾在美团、快手负责 Kubernetes 系统和多集群调度相关工作,目前就职于小红书容器架构组,负责团队内调度系统整体工作。拥有 6 年云原生相关开发设计经验,是 Kubernetes 和 Volcano member。
相关阅读:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论