

我们在 Apache Flink 零基础入门系列文章的前几篇已经为大家介绍了 Flink 开发环境的搭建和应用的部署以及运行,今天这篇文章主要介绍 Flink 的客户端操作。本文以实际操作为主,基于社区的 Flink 1.7.2 版本,使用的操作系统是 Mac 系统,浏览器是 Google Chrome 浏览器。有关开发环境的准备和集群的部署,请参考「开发环境搭建和应用的配置、部署及运行」的内容。
1.概要
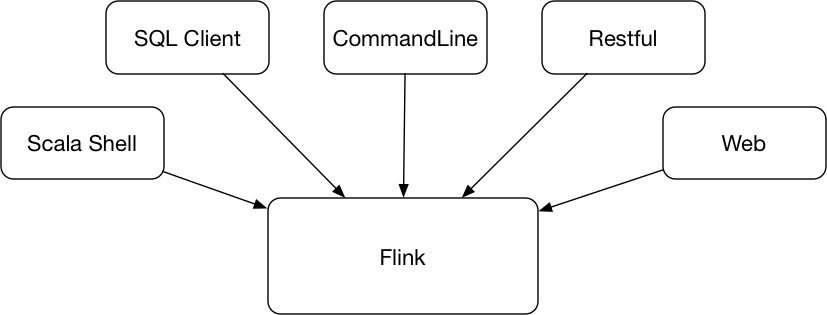
如下图所示,Flink 提供了丰富的客户端操作来提交任务和与任务进行交互,包括 Flink 命令行,Scala Shell,SQL Client,Restful API 和 Web。Flink 首先提供的最重要的是命令行,其次是 SQL Client 用于提交 SQL 任务的运行,还有就是 Scala Shell 提交 Table API 的任务。同时,Flink 也提供了 Restful 服务,用户可以通过 http 方式进行调用。此外,还有 Web 的方式可以提交任务。
在 Flink 安装目录的 bin 目录下面可以看到有 flink, start-scala-shell.sh 和 sql-client.sh 等文件,这些都是客户端操作的入口。
2.Flink 客户端操作
2.1 Flink 命令行
Flink 的命令行参数很多,输入 flink - h 能看到完整的说明:
➜ flink-1.7.2 bin/flink -h
如果想看某一个命令的参数,比如 Run 命令,输入:
➜ flink-1.7.2 bin/flink run -h
本文主要讲解常见的一些操作,更详细的文档请参考: Flink 命令行官方文档。
2.1.1 Standalone
首先启动一个 Standalone 的集群:
➜ flink-1.7.2 bin/start-cluster.shStarting cluster.Starting standalonesession daemon on host zkb-MBP.local.Starting taskexecutor daemon on host zkb-MBP.local.
打开 http://127.0.0.1:8081 能看到 Web 界面。
Run
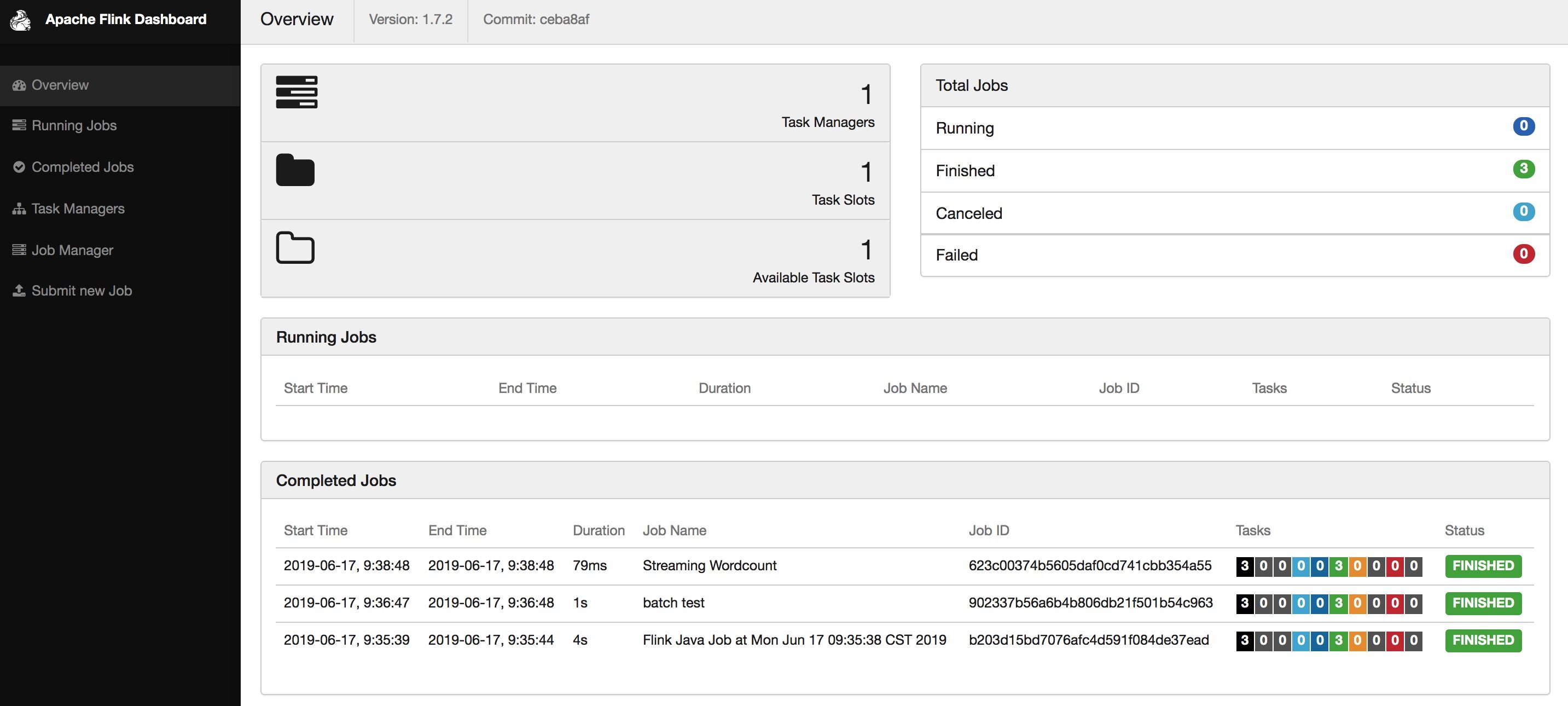
运行任务,以 Flink 自带的例子 TopSpeedWindowing 为例:
➜ flink-1.7.2 bin/flink run -d examples/streaming/TopSpeedWindowing.jarStarting execution of programExecuting TopSpeedWindowing example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.Job has been submitted with JobID 5e20cb6b0f357591171dfcca2eea09de
运行起来后默认是 1 个并发:
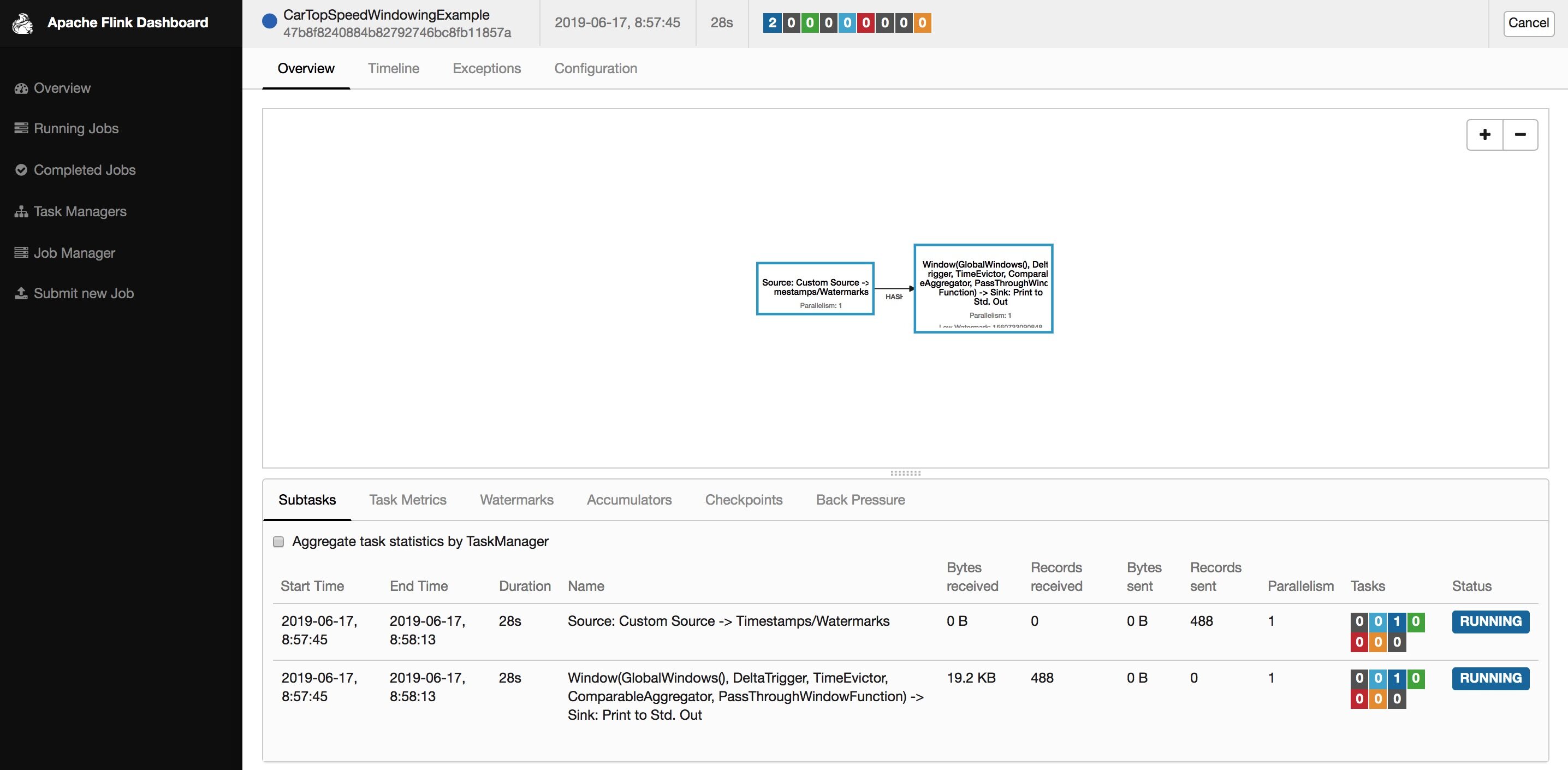
点左侧「Task Manager」,然后点「Stdout」能看到输出日志:
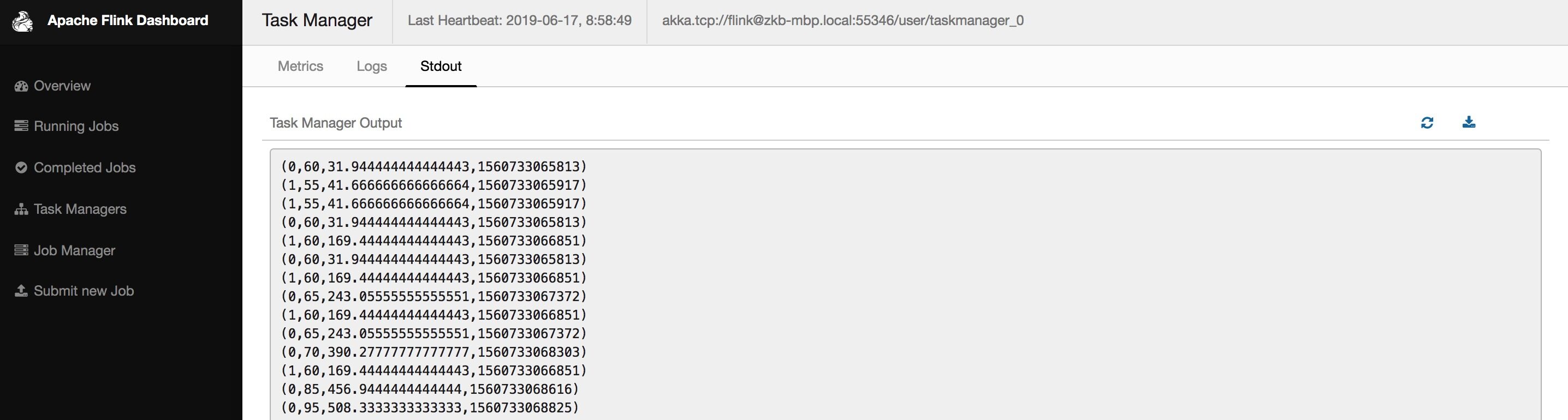
或者查看本地 Log 目录下的 *.out 文件:
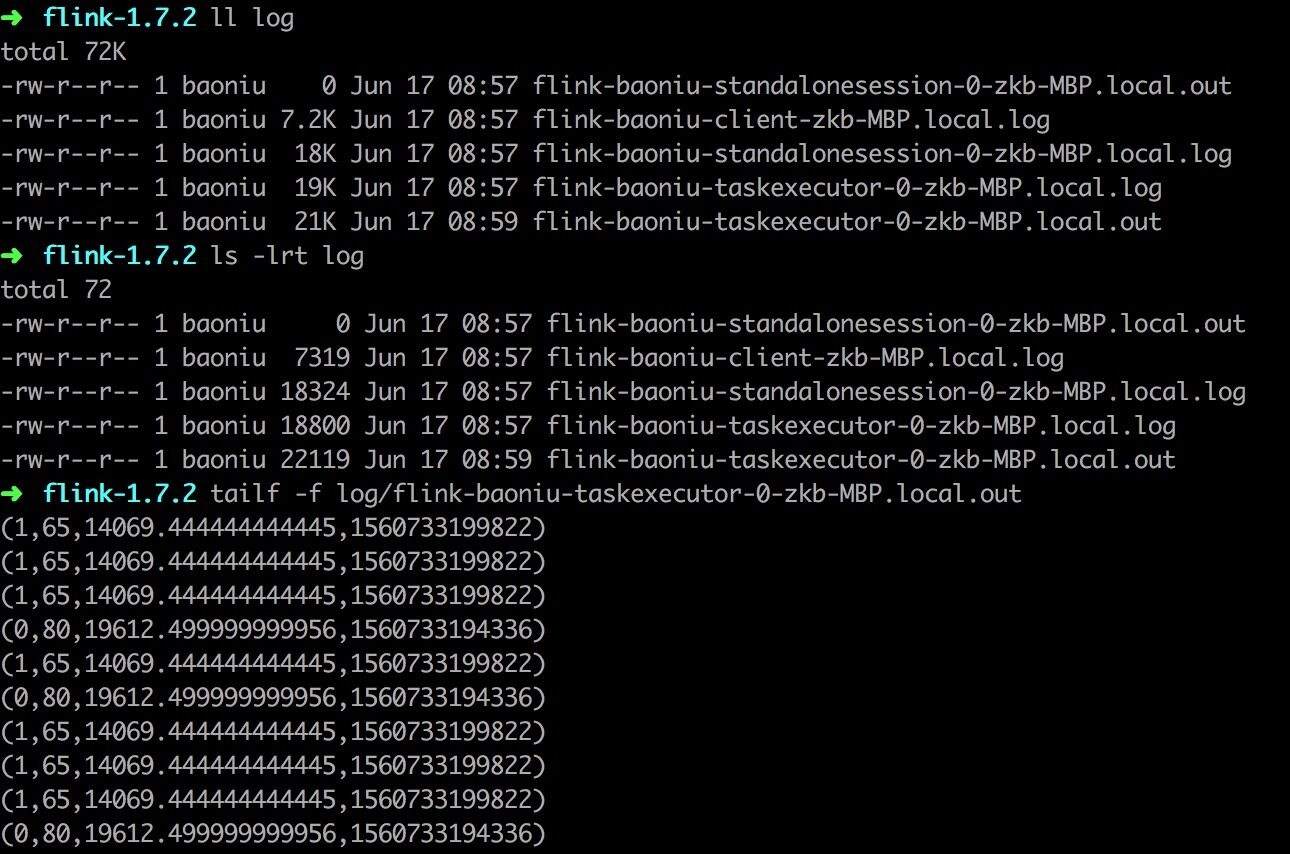
List
查看任务列表:
➜ flink-1.7.2 bin/flink list -m 127.0.0.1:8081Waiting for response...------------------ Running/Restarting Jobs -------------------24.03.2019 10:14:06 : 5e20cb6b0f357591171dfcca2eea09de : CarTopSpeedWindowingExample (RUNNING)--------------------------------------------------------------No scheduled jobs.
Stop
停止任务。通过 -m 来指定要停止的 JobManager 的主机地址和端口。
➜ flink-1.7.2 bin/flink stop -m 127.0.0.1:8081 d67420e52bd051fae2fddbaa79e046bbStopping job d67420e52bd051fae2fddbaa79e046bb.------------------------------------------------------------The program finished with the following exception: org.apache.flink.util.FlinkException: Could not stop the job d67420e52bd051fae2fddbaa79e046bb. at org.apache.flink.client.cli.CliFrontend.lambda$stop$5(CliFrontend.java:554) at org.apache.flink.client.cli.CliFrontend.runClusterAction(CliFrontend.java:985) at org.apache.flink.client.cli.CliFrontend.stop(CliFrontend.java:547) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1062) at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)Caused by: java.util.concurrent.ExecutionException: org.apache.flink.runtime.rest.util.RestClientException: [Job termination (STOP) failed: This job is not stoppable.] at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1915) at org.apache.flink.client.program.rest.RestClusterClient.stop(RestClusterClient.java:392) at org.apache.flink.client.cli.CliFrontend.lambda$stop$5(CliFrontend.java:552)... 9 moreCaused by: org.apache.flink.runtime.rest.util.RestClientException: [Job termination (STOP) failed: This job is not stoppable.] at org.apache.flink.runtime.rest.RestClient.parseResponse(RestClient.java:380) at org.apache.flink.runtime.rest.RestClient.lambda$submitRequest$3(RestClient.java:364) at java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:952) at java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:926) at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:442) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
从日志里面能看出 Stop 命令执行失败了。一个 Job 能够被 Stop 要求所有的 Source 都是可以 Stoppable 的,即实现了 StoppableFunction 接口。
/** * 需要能 stoppable 的函数必须实现这个接口,例如流式任务的 source。 * stop() 方法在任务收到 STOP 信号的时候调用。 * source 在接收到这个信号后,必须停止发送新的数据且优雅的停止。 */@PublicEvolvingpublic interface StoppableFunction { /** * 停止 source。与 cancel() 不同的是,这是一个让 source 优雅停止的请求。 * 等待中的数据可以继续发送出去,不需要立即停止。 */ void stop();}
Cancel
取消任务。如果在 conf/flink-conf.yaml 里面配置了 state.savepoints.dir,会保存 Savepoint,否则不会保存 Savepoint。
➜ flink-1.7.2 bin/flink cancel -m 127.0.0.1:8081 5e20cb6b0f357591171dfcca2eea09de Cancelling job 5e20cb6b0f357591171dfcca2eea09de.Cancelled job 5e20cb6b0f357591171dfcca2eea09de.
也可以在停止的时候显示指定 Savepoint 目录。
➜ flink-1.7.2 bin/flink cancel -m 127.0.0.1:8081 -s /tmp/savepoint 29da945b99dea6547c3fbafd57ed8759 Cancelling job 29da945b99dea6547c3fbafd57ed8759 with savepoint to /tmp/savepoint.Cancelled job 29da945b99dea6547c3fbafd57ed8759. Savepoint stored in file:/tmp/savepoint/savepoint-29da94-88299bacafb7. ➜ flink-1.7.2 ll /tmp/savepoint/savepoint-29da94-88299bacafb7total 32K-rw-r--r-- 1 baoniu 29K Mar 24 10:33 _metadata
取消和停止(流作业)的区别如下:
cancel() 调用,立即调用作业算子的 cancel() 方法,以尽快取消它们。如果算子在接到 cancel() 调用后没有停止,Flink 将开始定期中断算子线程的执行,直到所有算子停止为止。
stop() 调用,是更优雅的停止正在运行流作业的方式。stop() 仅适用于 Source 实现了 StoppableFunction 接口的作业。当用户请求停止作业时,作业的所有 Source 都将接收 stop() 方法调用。直到所有 Source 正常关闭时,作业才会正常结束。这种方式,使作业正常处理完所有作业。
Savepoint
触发 Savepoint。
➜ flink-1.7.2 bin/flink savepoint -m 127.0.0.1:8081 ec53edcfaeb96b2a5dadbfbe5ff62bbb /tmp/savepointTriggering savepoint for job ec53edcfaeb96b2a5dadbfbe5ff62bbb.Waiting for response...Savepoint completed. Path: file:/tmp/savepoint/savepoint-ec53ed-84b00ce500eeYou can resume your program from this savepoint with the run command.
说明:Savepoint 和 Checkpoint 的区别(详见文档):
Checkpoint 是增量做的,每次的时间较短,数据量较小,只要在程序里面启用后会自动触发,用户无须感知;Checkpoint 是作业 failover 的时候自动使用,不需要用户指定。
Savepoint 是全量做的,每次的时间较长,数据量较大,需要用户主动去触发。Savepoint 一般用于程序的版本更新(详见文档),Bug 修复,A/B Test 等场景,需要用户指定。
通过 -s 参数从指定的 Savepoint 启动:
➜ flink-1.7.2 bin/flink run -d -s /tmp/savepoint/savepoint-f049ff-24ec0d3e0dc7 ./examples/streaming/TopSpeedWindowing.jarStarting execution of programExecuting TopSpeedWindowing example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.
查看 JobManager 的日志,能够看到类似这样的 Log:
2019-03-28 10:30:53,957 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Starting job 790d7b98db6f6af55d04aec1d773852d from savepoint /tmp/savepoint/savepoint-f049ff-24ec0d3e0dc7 ()2019-03-28 10:30:53,959 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Reset the checkpoint ID of job 790d7b98db6f6af55d04aec1d773852d to 2.2019-03-28 10:30:53,959 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Restoring job 790d7b98db6f6af55d04aec1d773852d from latest valid checkpoint: Checkpoint 1 @ 0 for 790d7b98db6f6af55d04aec1d773852d.
Modify
修改任务并行度。
为了方便演示,我们修改 conf/flink-conf.yaml 将 Task Slot 数从默认的 1 改为 4,并配置 Savepoint 目录。(Modify 参数后面接 -s 指定 Savepoint 路径当前版本可能有 Bug,提示无法识别)
taskmanager.numberOfTaskSlots: 4state.savepoints.dir: file:///tmp/savepoint
修改参数后需要重启集群生效,然后再启动任务:
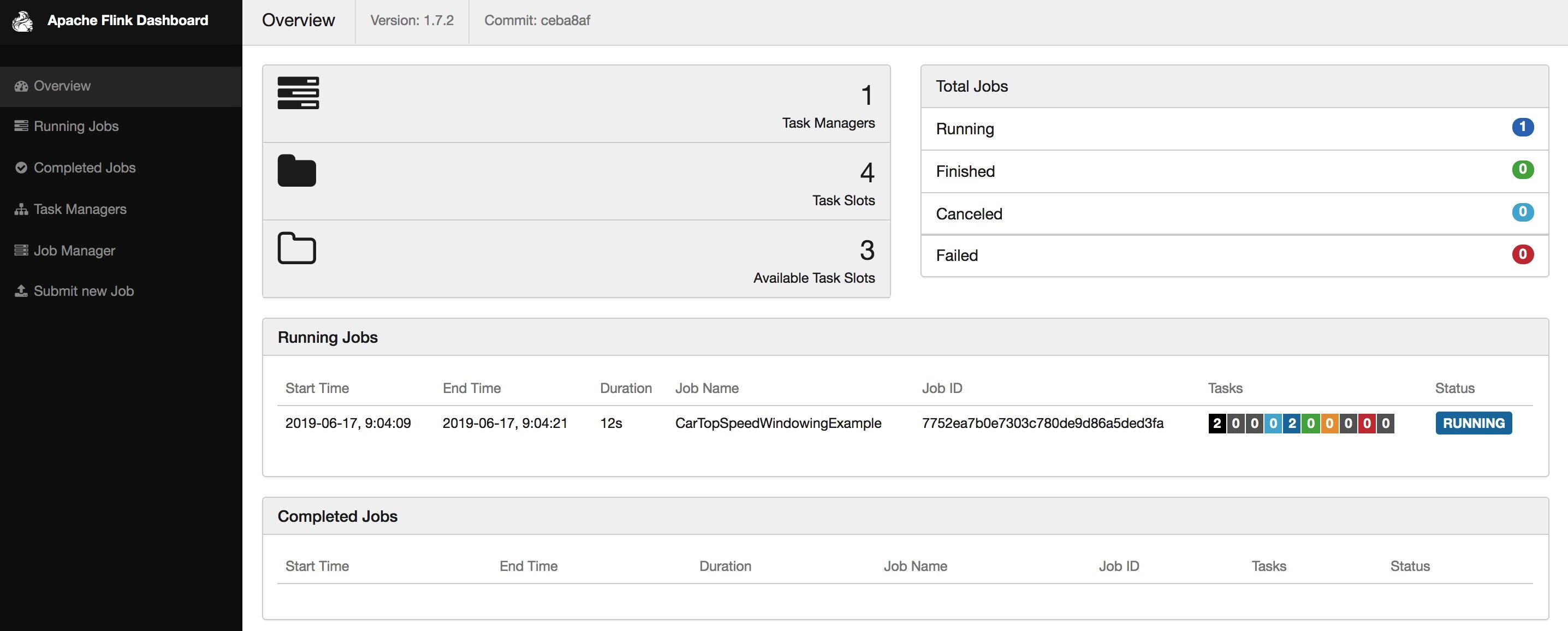
➜ flink-1.7.2 bin/stop-cluster.sh && bin/start-cluster.shStopping taskexecutor daemon (pid: 53139) on host zkb-MBP.local.Stopping standalonesession daemon (pid: 52723) on host zkb-MBP.local.Starting cluster.Starting standalonesession daemon on host zkb-MBP.local.Starting taskexecutor daemon on host zkb-MBP.local. ➜ flink-1.7.2 bin/flink run -d examples/streaming/TopSpeedWindowing.jarStarting execution of programExecuting TopSpeedWindowing example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.Job has been submitted with JobID 7752ea7b0e7303c780de9d86a5ded3fa
从页面上能看到 Task Slot 变为了 4,这时候任务的默认并发度是 1。
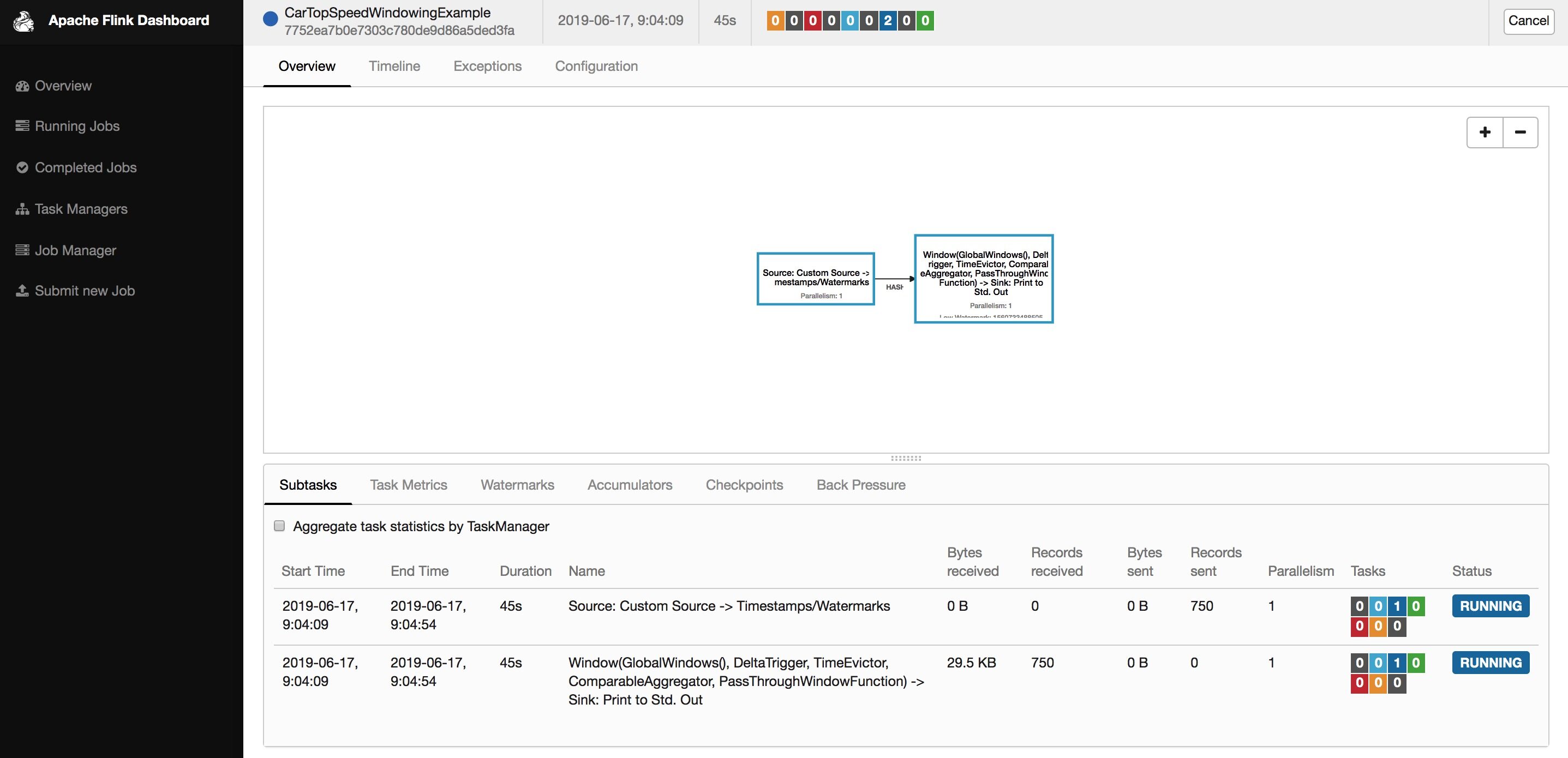
通过 Modify 命令依次将并发度修改为 4 和 3,可以看到每次 Modify 命令都会触发一次 Savepoint。
➜ flink-1.7.2 bin/flink modify -p 4 7752ea7b0e7303c780de9d86a5ded3faModify job 7752ea7b0e7303c780de9d86a5ded3fa.Rescaled job 7752ea7b0e7303c780de9d86a5ded3fa. Its new parallelism is 4. ➜ flink-1.7.2 ll /tmp/savepointtotal 0drwxr-xr-x 3 baoniu 96 Jun 17 09:05 savepoint-7752ea-00c05b015836/ ➜ flink-1.7.2 bin/flink modify -p 3 7752ea7b0e7303c780de9d86a5ded3faModify job 7752ea7b0e7303c780de9d86a5ded3fa.Rescaled job 7752ea7b0e7303c780de9d86a5ded3fa. Its new parallelism is 3. ➜ flink-1.7.2 ll /tmp/savepointtotal 0drwxr-xr-x 3 baoniu 96 Jun 17 09:08 savepoint-7752ea-449b131b2bd4/
查看 JobManager 的日志,可以看到:
2019-06-17 09:05:11,179 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Starting job 7752ea7b0e7303c780de9d86a5ded3fa from savepoint file:/tmp/savepoint/savepoint-790d7b-3581698f007e ()2019-06-17 09:05:11,182 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Reset the checkpoint ID of job 7752ea7b0e7303c780de9d86a5ded3fa to 3.2019-06-17 09:05:11,182 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Restoring job 790d7b98db6f6af55d04aec1d773852d from latest valid checkpoint: Checkpoint 2 @ 0 for 7752ea7b0e7303c780de9d86a5ded3fa.2019-06-17 09:05:11,184 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - No master state to restore2019-06-17 09:05:11,184 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Job CarTopSpeedWindowingExample (7752ea7b0e7303c780de9d86a5ded3fa) switched from state RUNNING to SUSPENDING.org.apache.flink.util.FlinkException: Job is being rescaled.
Info
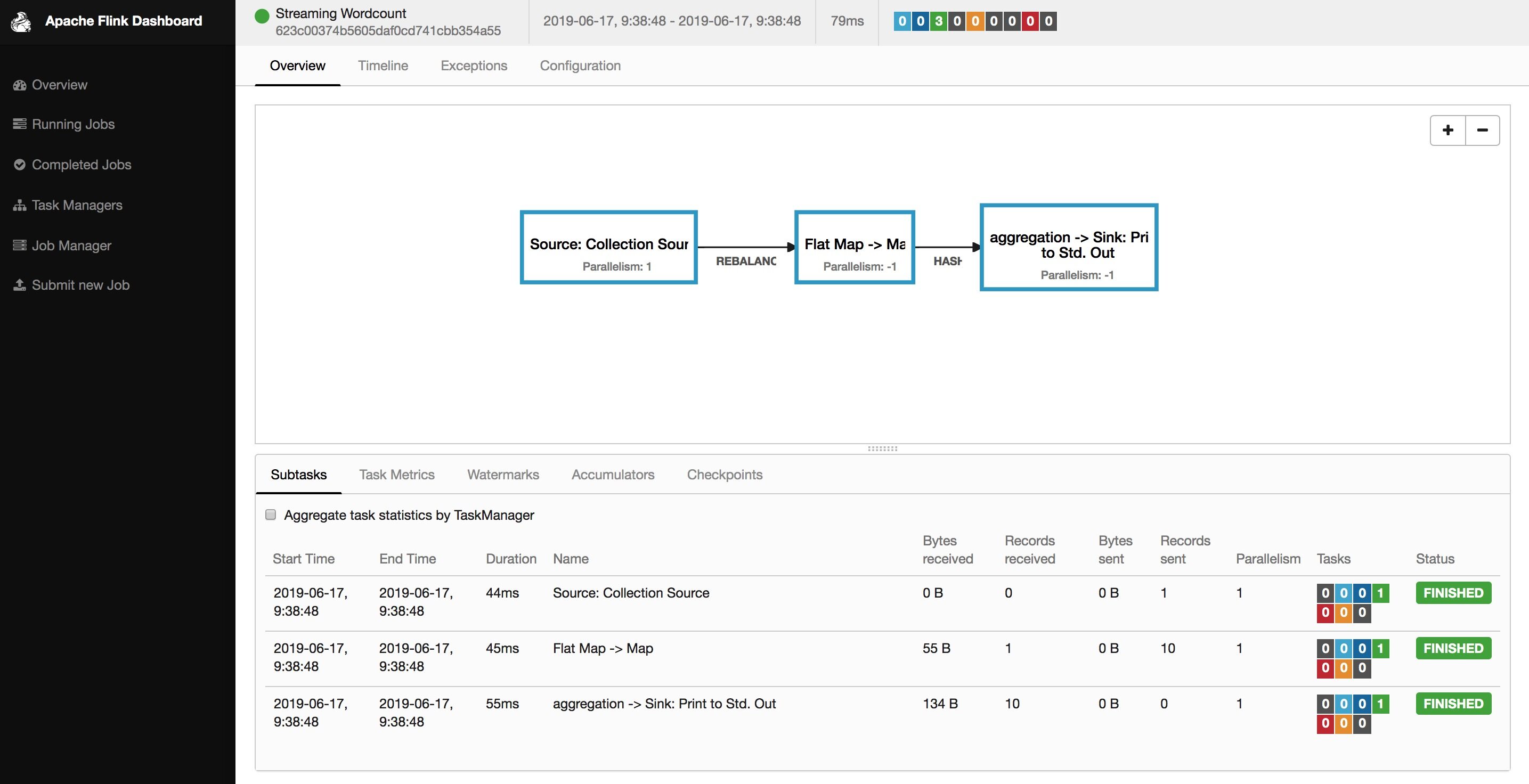
Info 命令是用来查看 Flink 任务的执行计划(StreamGraph)的。
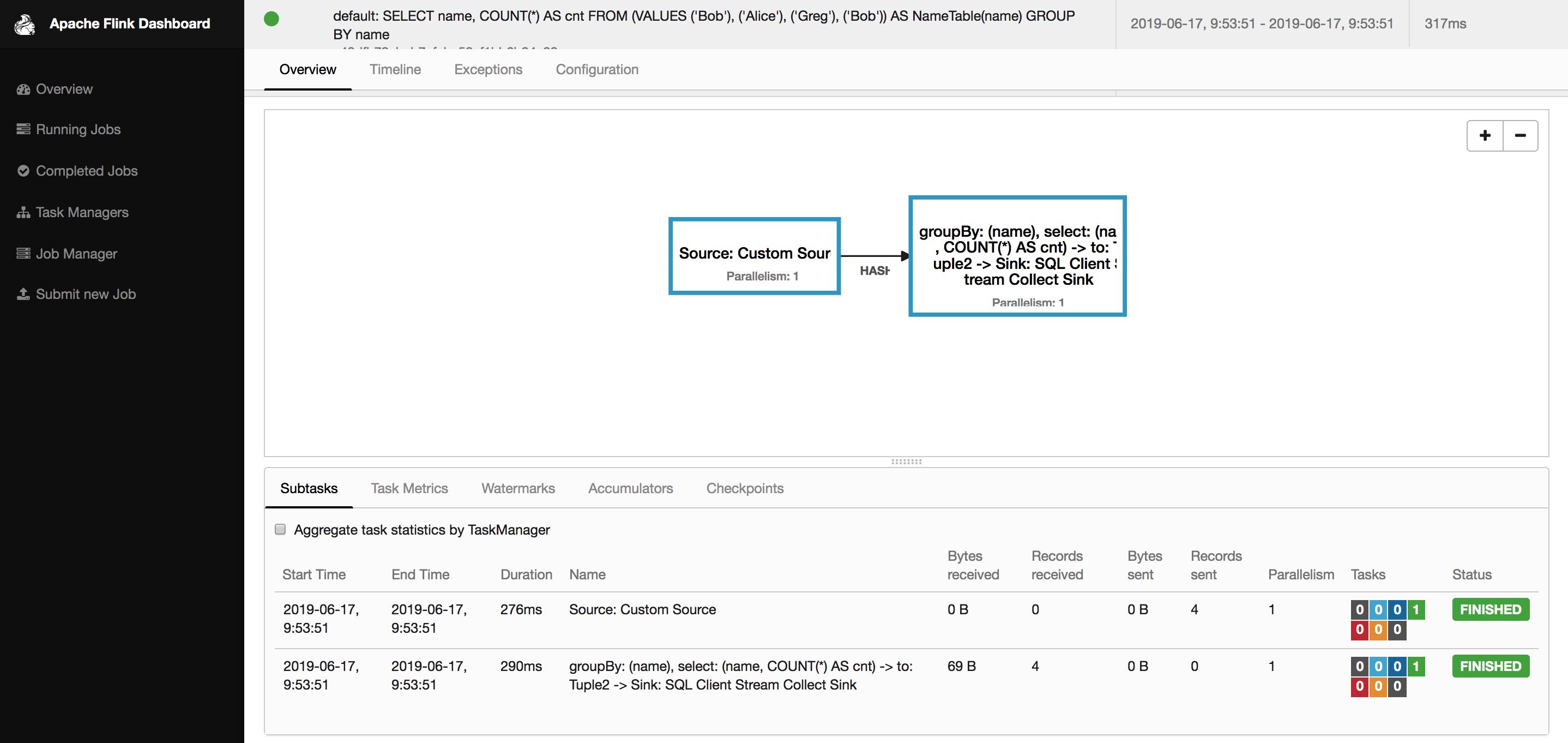
➜ flink-1.7.2 bin/flink info examples/streaming/TopSpeedWindowing.jar----------------------- Execution Plan -----------------------{"nodes":[{"id":1,"type":"Source: Custom Source","pact":"Data Source","contents":"Source: Custom Source","parallelism":1},{"id":2,"type":"Timestamps/Watermarks","pact":"Operator","contents":"Timestamps/Watermarks","parallelism":1,"predecessors":[{"id":1,"ship_strategy":"FORWARD","side":"second"}]},{"id":4,"type":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)","pact":"Operator","contents":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)","parallelism":1,"predecessors":[{"id":2,"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":1,"predecessors":[{"id":4,"ship_strategy":"FORWARD","side":"second"}]}]}--------------------------------------------------------------
拷贝输出的 Json 内容,粘贴到这个网站:http://flink.apache.org/visualizer/
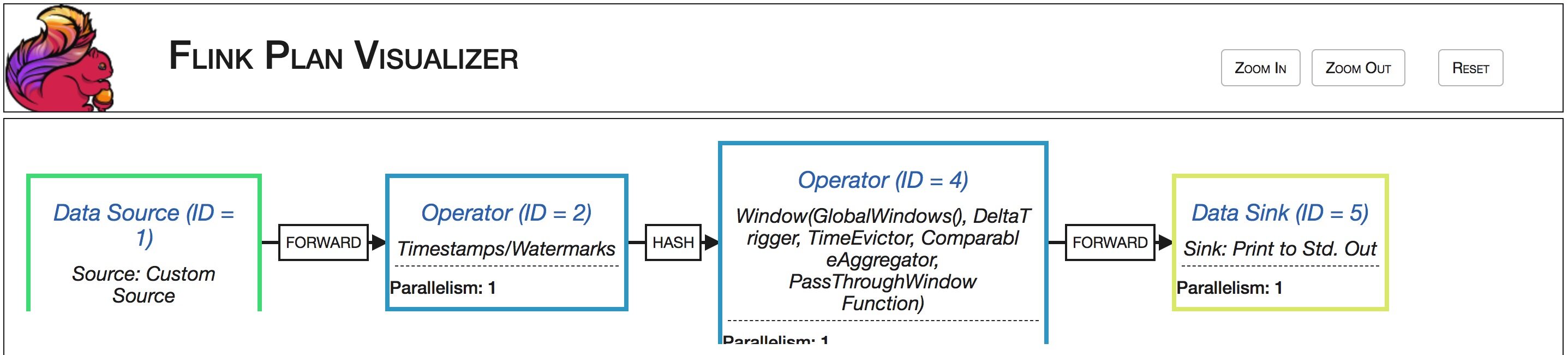
可以和实际运行的物理执行计划对比:
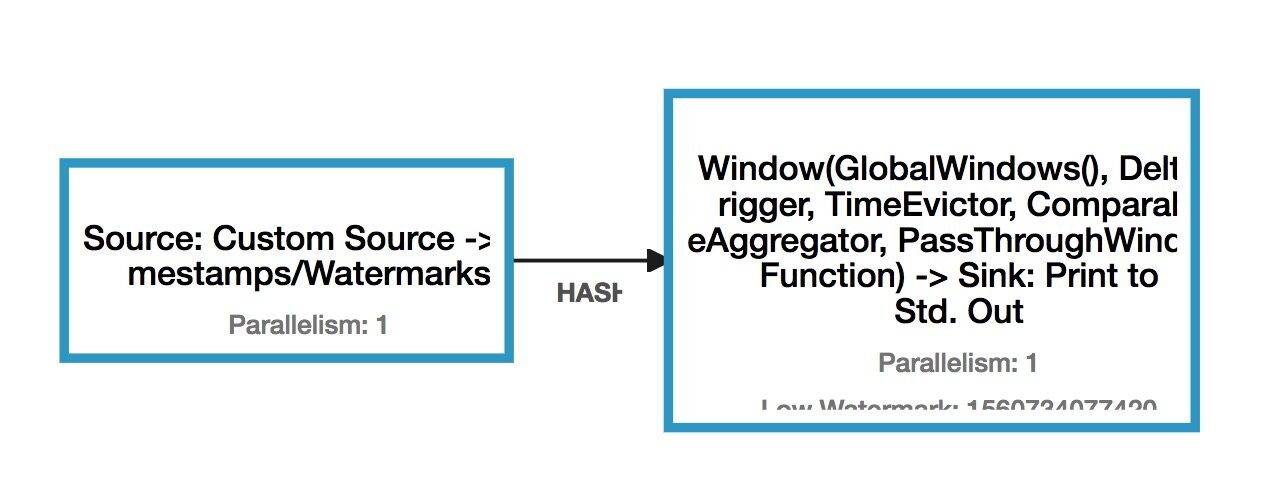
2.1.2 Yarn per-job
单任务 Attach 模式
默认是 Attach 模式,即客户端会一直等待直到程序结束才会退出。
通过 -m yarn-cluster 指定 Yarn 模式
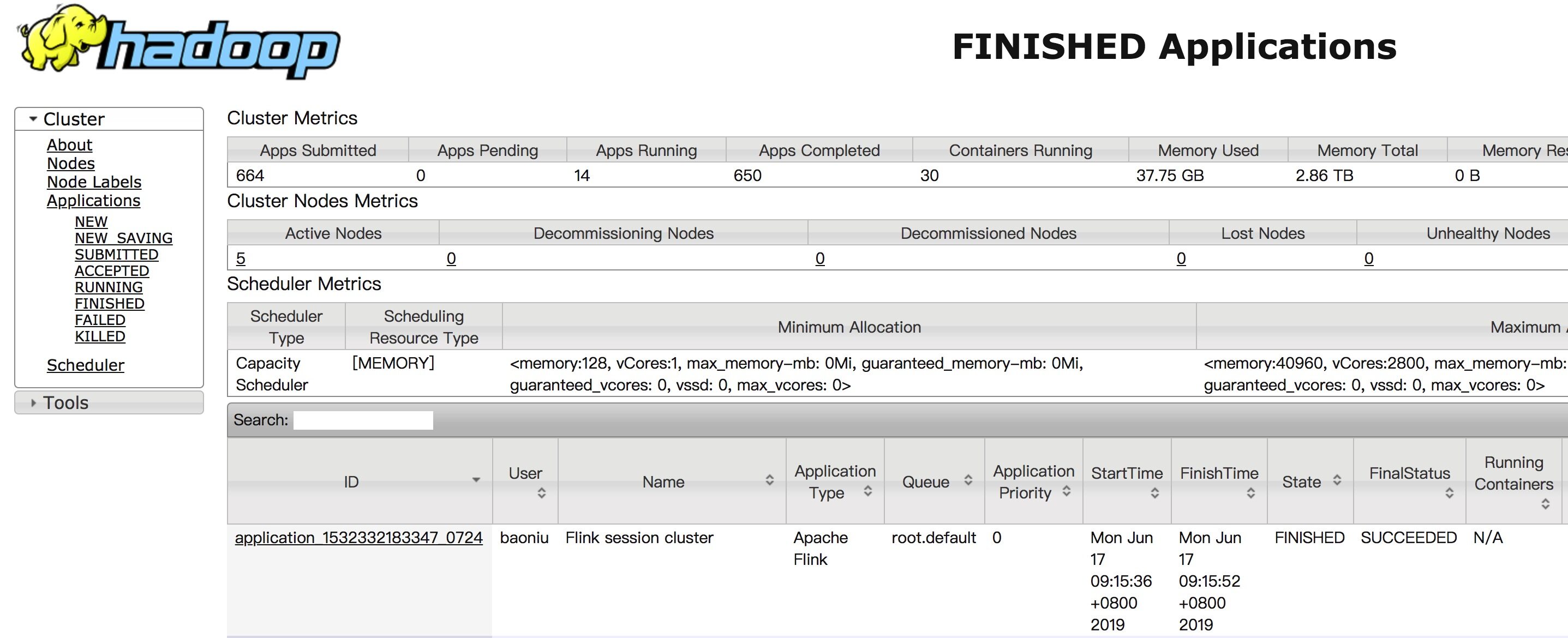
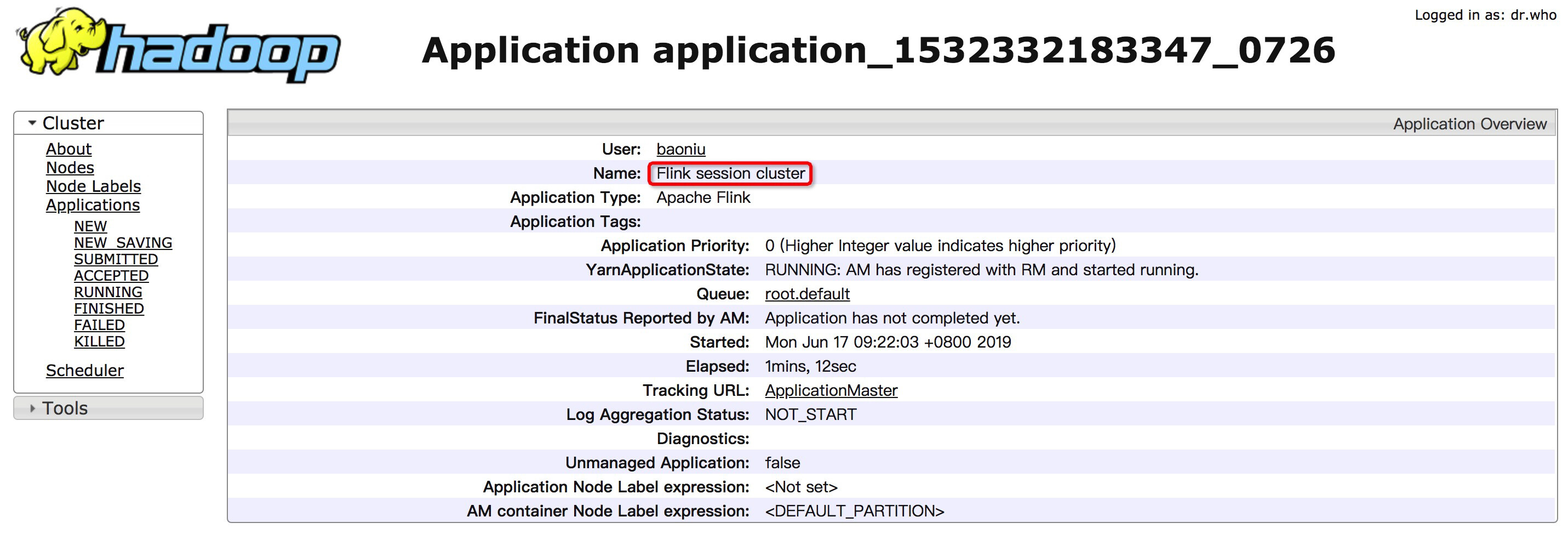
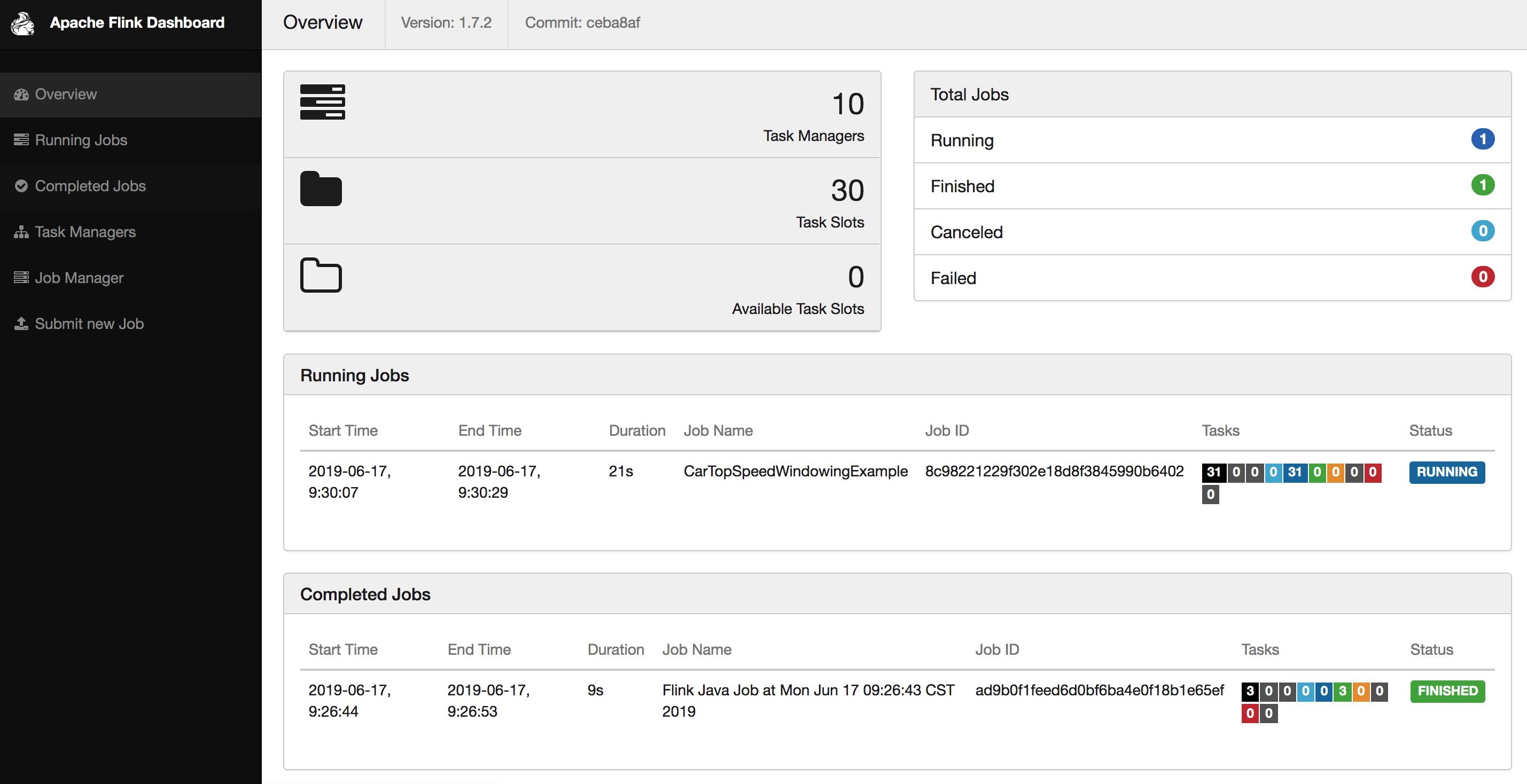
Yarn 上显示名字为 Flink session cluster,这个 Batch 的 Wordcount 任务运行完会 FINISHED。
客户端能看到结果输出
[admin@z17.sqa.zth /home/admin/flink/flink-1.7.2]$echo $HADOOP_CONF_DIR/etc/hadoop/conf/ [admin@z17.sqa.zth /home/admin/flink/flink-1.7.2]$./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar 2019-06-17 09:15:24,511 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at z05c05217.sqa.zth.tbsite.net/11.163.188.29:80502019-06-17 09:15:24,690 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-06-17 09:15:24,690 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-06-17 09:15:24,907 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=4}2019-06-17 09:15:25,430 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.2019-06-17 09:15:25,438 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.2019-06-17 09:15:36,239 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1532332183347_07242019-06-17 09:15:36,276 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1532332183347_07242019-06-17 09:15:36,276 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated2019-06-17 09:15:36,281 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED2019-06-17 09:15:40,426 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.Starting execution of programExecuting WordCount example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.(a,5)(action,1)(after,1)(against,1)(all,2)... ...(would,2)(wrong,1)(you,1)Program execution finishedJob with JobID 8bfe7568cb5c3254af30cbbd9cd5971e has finished.Job Runtime: 9371 msAccumulator Results:- 2bed2c5506e9237fb85625416a1bc508 (java.util.ArrayList) [170 elements]
如果我们以 Attach 模式运行 Streaming 的任务,客户端会一直等待不退出,可以运行以下的例子试验下:
./bin/flink run -m yarn-cluster ./examples/streaming/TopSpeedWindowing.jar
单任务 Detached 模式
由于是 Detached 模式,客户端提交完任务就退出了
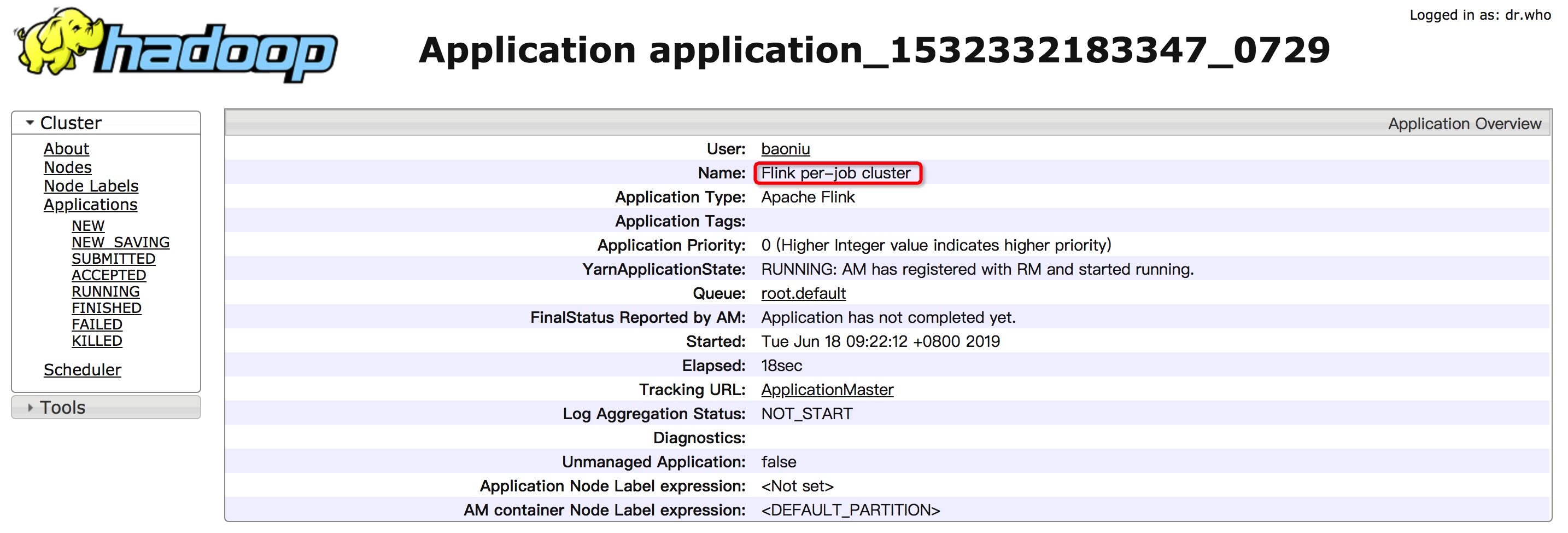
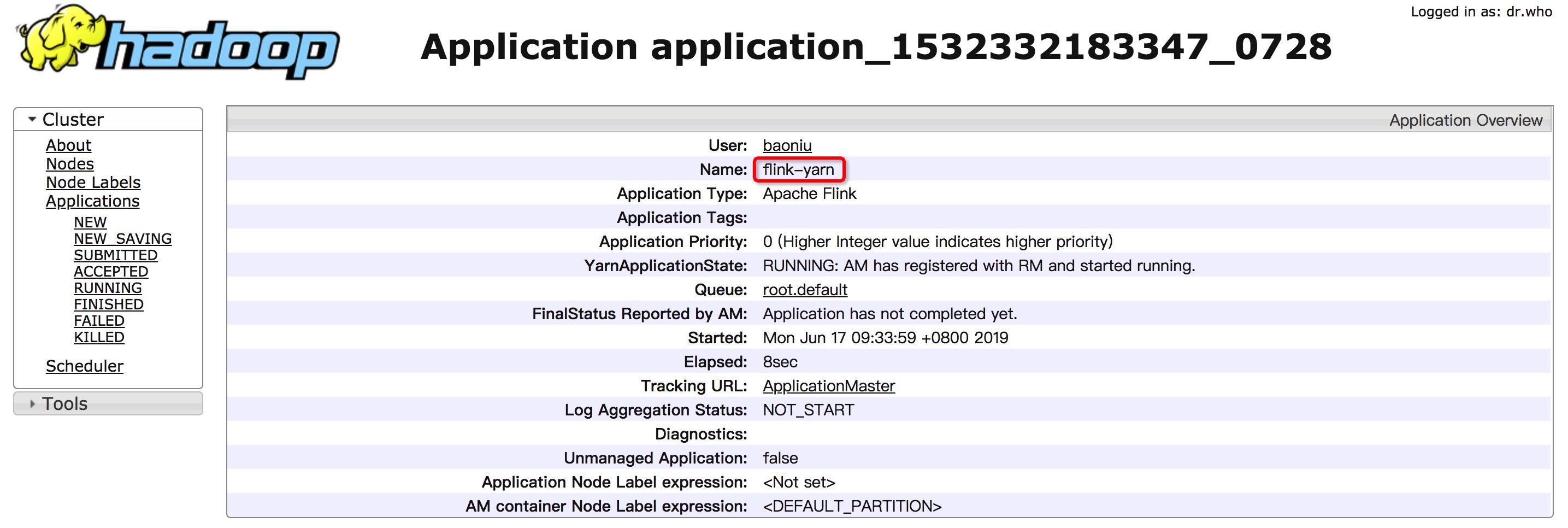
Yarn 上显示为 Flink per-job cluster
$./bin/flink run -yd -m yarn-cluster ./examples/streaming/TopSpeedWindowing.jar 2019-06-18 09:21:59,247 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at z05c05217.sqa.zth.tbsite.net/11.163.188.29:80502019-06-18 09:21:59,428 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-06-18 09:21:59,428 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-06-18 09:21:59,940 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=4}2019-06-18 09:22:00,427 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.2019-06-18 09:22:00,436 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.^@2019-06-18 09:22:12,113 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1532332183347_07292019-06-18 09:22:12,151 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1532332183347_07292019-06-18 09:22:12,151 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated2019-06-18 09:22:12,155 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED2019-06-18 09:22:16,275 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.2019-06-18 09:22:16,275 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - The Flink YARN client has been started in detached mode. In order to stop Flink on YARN, use the following command or a YARN web interface to stop it:yarn application -kill application_1532332183347_0729Please also note that the temporary files of the YARN session in the home directory will not be removed.Job has been submitted with JobID e61b9945c33c300906ad50a9a11f36df
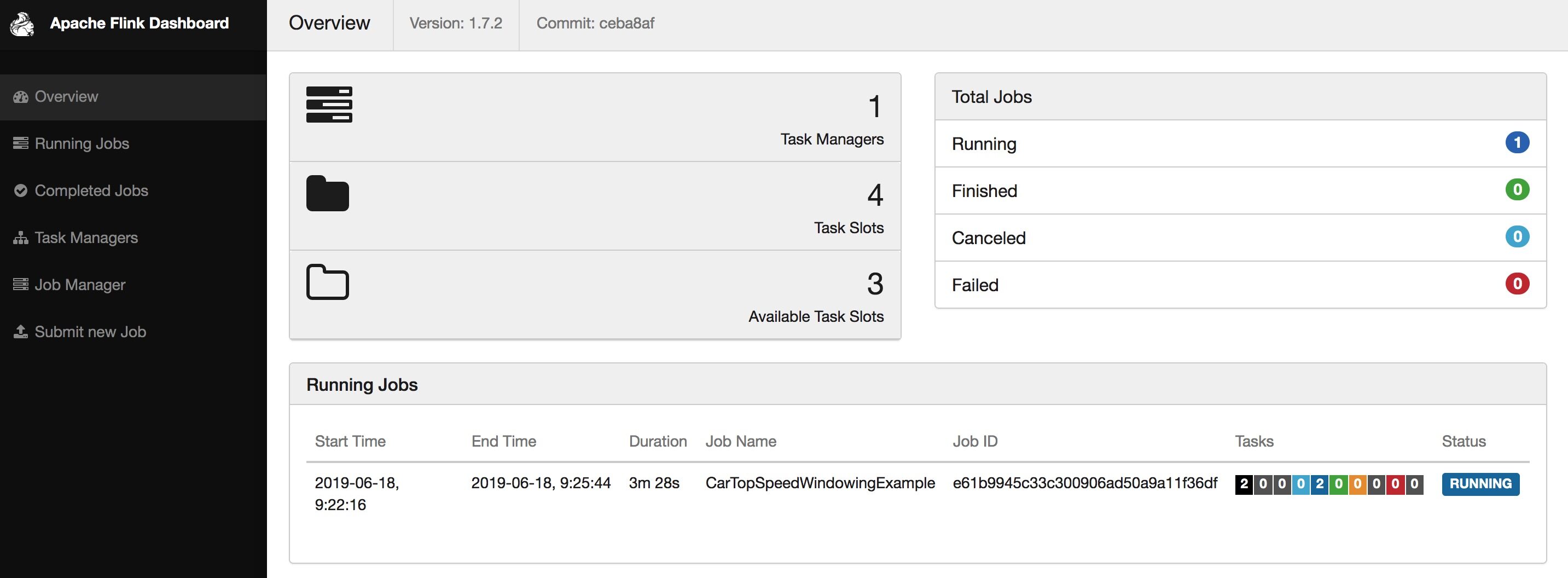
2.1.3 Yarn session
启动 Session
./bin/yarn-session.sh -tm 2048 -s 3
表示启动一个 Yarn session 集群,每个 TM 的内存是 2 G,每个 TM 有 3 个 Slot。(注意:-n 参数不生效)
➜ flink-1.7.2 ./bin/yarn-session.sh -tm 2048 -s 32019-06-17 09:21:50,177 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, localhost2019-06-17 09:21:50,179 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 61232019-06-17 09:21:50,179 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m2019-06-17 09:21:50,179 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m2019-06-17 09:21:50,179 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 42019-06-17 09:21:50,179 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: state.savepoints.dir, file:///tmp/savepoint2019-06-17 09:21:50,180 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 12019-06-17 09:21:50,180 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: rest.port, 80812019-06-17 09:21:50,644 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2019-06-17 09:21:50,746 INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to baoniu (auth:SIMPLE)2019-06-17 09:21:50,848 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at z05c05217.sqa.zth.tbsite.net/11.163.188.29:80502019-06-17 09:21:51,148 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=2048, numberTaskManagers=1, slotsPerTaskManager=3}2019-06-17 09:21:51,588 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.2019-06-17 09:21:51,596 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.^@2019-06-17 09:22:03,304 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1532332183347_07262019-06-17 09:22:03,336 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1532332183347_07262019-06-17 09:22:03,336 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated2019-06-17 09:22:03,340 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED2019-06-17 09:22:07,722 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.2019-06-17 09:22:08,050 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.Flink JobManager is now running on z07.sqa.net:37109 with leader id 00000000-0000-0000-0000-000000000000.JobManager Web Interface: http://z07.sqa.net:37109
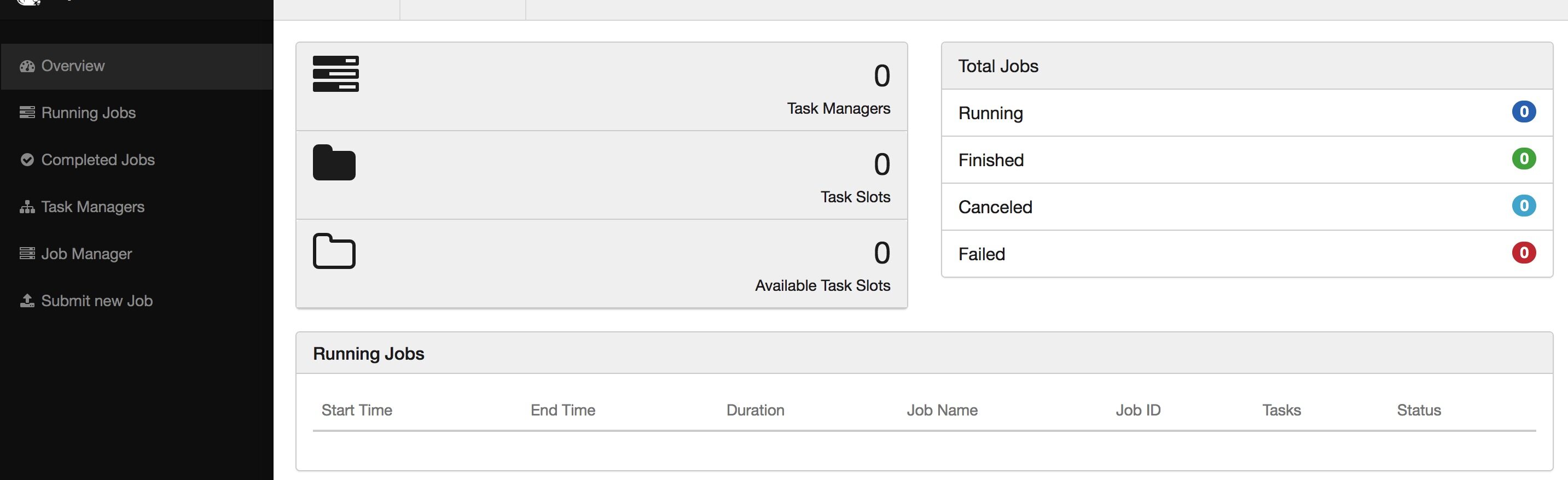
客户端默认是 Attach 模式,不会退出:
可以 ctrl + c 退出,然后再通过 ./bin/yarn-session.sh -id application_1532332183347_0726 连上来;
或者启动的时候用 -d 则为 detached 模式
Yarn 上显示为 Flink session cluster;
在本机的临时目录(有些机器是 /tmp 目录)下会生成一个文件:
➜ flink-1.7.2 cat /var/folders/2b/r6d49pcs23z43b8fqsyz885c0000gn/T/.yarn-properties-baoniu#Generated YARN properties file#Mon Jun 17 09:22:08 CST 2019parallelism=3dynamicPropertiesString=applicationID=application_1532332183347_0726
提交任务
./bin/flink run ./examples/batch/WordCount.jar
将会根据 /tmp/.yarn-properties-admin 文件内容提交到了刚启动的 Session。
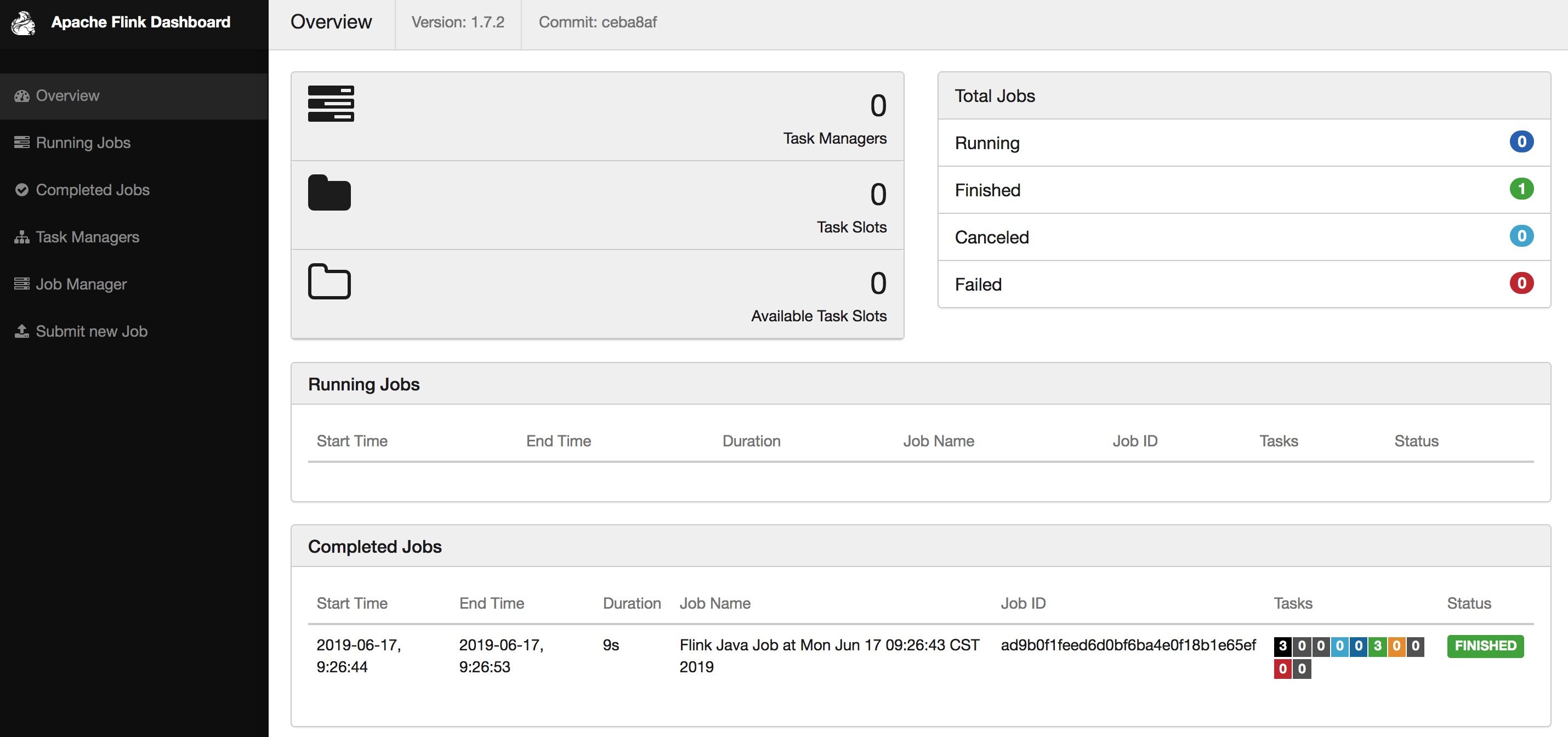
➜ flink-1.7.2 ./bin/flink run ./examples/batch/WordCount.jar2019-06-17 09:26:42,767 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /var/folders/2b/r6d49pcs23z43b8fqsyz885c0000gn/T/.yarn-properties-baoniu.2019-06-17 09:26:42,767 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /var/folders/2b/r6d49pcs23z43b8fqsyz885c0000gn/T/.yarn-properties-baoniu.2019-06-17 09:26:43,058 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 32019-06-17 09:26:43,058 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 3YARN properties set default parallelism to 32019-06-17 09:26:43,097 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at z05c05217.sqa.zth.tbsite.net/11.163.188.29:80502019-06-17 09:26:43,229 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-06-17 09:26:43,229 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-06-17 09:26:43,327 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'z05c07216.sqa.zth.tbsite.net' and port '37109' from supplied application id 'application_1532332183347_0726'Starting execution of programExecuting WordCount example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.^@(a,5)(action,1)(after,1)(against,1)(all,2)(and,12)... ...(wrong,1)(you,1)Program execution finishedJob with JobID ad9b0f1feed6d0bf6ba4e0f18b1e65ef has finished.Job Runtime: 9152 msAccumulator Results:- fd07c75d503d0d9a99e4f27dd153114c (java.util.ArrayList) [170 elements]
运行结束后 TM 的资源会释放。
提交到指定的 Session
通过 -yid 参数来提交到指定的 Session。
$./bin/flink run -d -p 30 -m yarn-cluster -yid application_1532332183347_0708 ./examples/streaming/TopSpeedWindowing.jar 2019-03-24 12:36:33,668 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at z05c05217.sqa.zth.tbsite.net/11.163.188.29:80502019-03-24 12:36:33,773 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-03-24 12:36:33,773 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-03-24 12:36:33,837 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'z05c05218.sqa.zth.tbsite.net' and port '60783' from supplied application id 'application_1532332183347_0708'Starting execution of programExecuting TopSpeedWindowing example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.Job has been submitted with JobID 58d5049ebbf28d515159f2f88563f5fd
注:Blink版本 的 Session 与 Flink 的 Session 的区别:
Flink 的 session -n 参数不生效,而且不会提前启动 TM;
Blink 的 session 可以通过 -n 指定启动多少个 TM,而且 TM 会提前起来;
2.2 Scala Shell
官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/scala_shell.html
2.2.1 Deploy
Local
$bin/start-scala-shell.sh localStarting Flink Shell:Starting local Flink cluster (host: localhost, port: 8081).Connecting to Flink cluster (host: localhost, port: 8081).... ...scala>
任务运行说明:
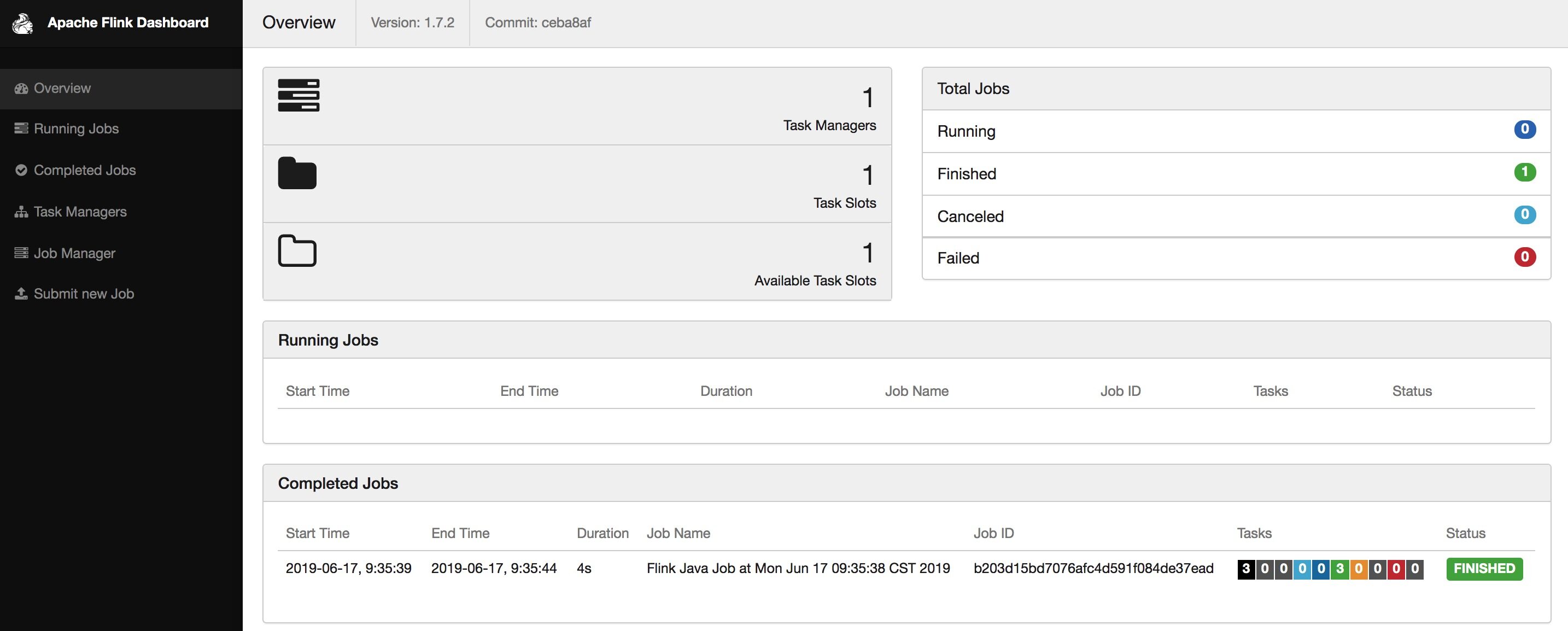
Batch 任务内置了 benv 变量,通过 print() 将结果输出到控制台;
Streaming 任务内置了 senv 变量,通过 senv.execute(“job name”) 来提交任务,且 Datastream 的输出只有在 Local 模式下打印到控制台;
Remote
先启动一个 yarn session cluster:
$./bin/yarn-session.sh -tm 2048 -s 3
2019-03-25 09:52:16,341 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, localhost2019-03-25 09:52:16,342 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 61232019-03-25 09:52:16,342 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m2019-03-25 09:52:16,343 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m2019-03-25 09:52:16,343 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 42019-03-25 09:52:16,343 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 12019-03-25 09:52:16,343 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: state.savepoints.dir, file:///tmp/savepoint2019-03-25 09:52:16,343 INFO org.apache.flink.configuration.GlobalConfiguration … ...Flink JobManager is now running on z054.sqa.net:28665 with leader id 00000000-0000-0000-0000-000000000000.JobManager Web Interface: http://z054.sqa.net:28665
启动 scala shell,连到 jm:
$bin/start-scala-shell.sh remote z054.sqa.net 28665Starting Flink Shell:Connecting to Flink cluster (host: z054.sqa.net, port: 28665).... ...scala>
Yarn
$./bin/start-scala-shell.sh yarn -n 2 -jm 1024 -s 2 -tm 1024 -nm flink-yarn
Starting Flink Shell:2019-03-25 09:47:44,695 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, localhost2019-03-25 09:47:44,697 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 61232019-03-25 09:47:44,697 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m2019-03-25 09:47:44,697 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m2019-03-25 09:47:44,697 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 42019-03-25 09:47:44,698 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 12019-03-25 09:47:44,698 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: state.savepoints.dir, file:///tmp/savepoint2019-03-25 09:47:44,698 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: rest.port, 80812019-03-25 09:47:44,717 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-admin.2019-03-25 09:47:45,041 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at z05c05217.sqa.zth.tbsite.net/11.163.188.29:80502019-03-25 09:47:45,098 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2019-03-25 09:47:45,266 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar2019-03-25 09:47:45,275 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The argument yn is deprecated in will be ignored.2019-03-25 09:47:45,357 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=2, slotsPerTaskManager=2}2019-03-25 09:47:45,711 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.2019-03-25 09:47:45,718 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/home/admin/flink/flink-1.7.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.2019-03-25 09:47:46,514 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1532332183347_07102019-03-25 09:47:46,534 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1532332183347_07102019-03-25 09:47:46,534 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated2019-03-25 09:47:46,535 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED2019-03-25 09:47:51,051 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.2019-03-25 09:47:51,222 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Connecting to Flink cluster (host: 10.10.10.10, port: 56942).
按 CTRL + C 退出 Shell 后,这个 Flink cluster 还会继续运行,不会退出。
2.2.2 Execute
DataSet
➜ flink-1.7.2 bin/stop-cluster.shNo taskexecutor daemon to stop on host zkb-MBP.local.No standalonesession daemon to stop on host zkb-MBP.local.➜ flink-1.7.2 bin/start-scala-shell.sh localStarting Flink Shell:Starting local Flink cluster (host: localhost, port: 8081).Connecting to Flink cluster (host: localhost, port: 8081).
scala> val text = benv.fromElements("To be, or not to be,--that is the question:--")text: org.apache.flink.api.scala.DataSet[String] = org.apache.flink.api.scala.DataSet@5b407336
scala> val counts = text.flatMap { _.toLowerCase.split("\\W+") }.map { (_, 1) }.groupBy(0).sum(1)counts: org.apache.flink.api.scala.AggregateDataSet[(String, Int)] = org.apache.flink.api.scala.AggregateDataSet@6ee34fe4
scala> counts.print()(be,2)(is,1)(not,1)(or,1)(question,1)(that,1)(the,1)(to,2)
对 DataSet 任务来说,print() 会触发任务的执行。
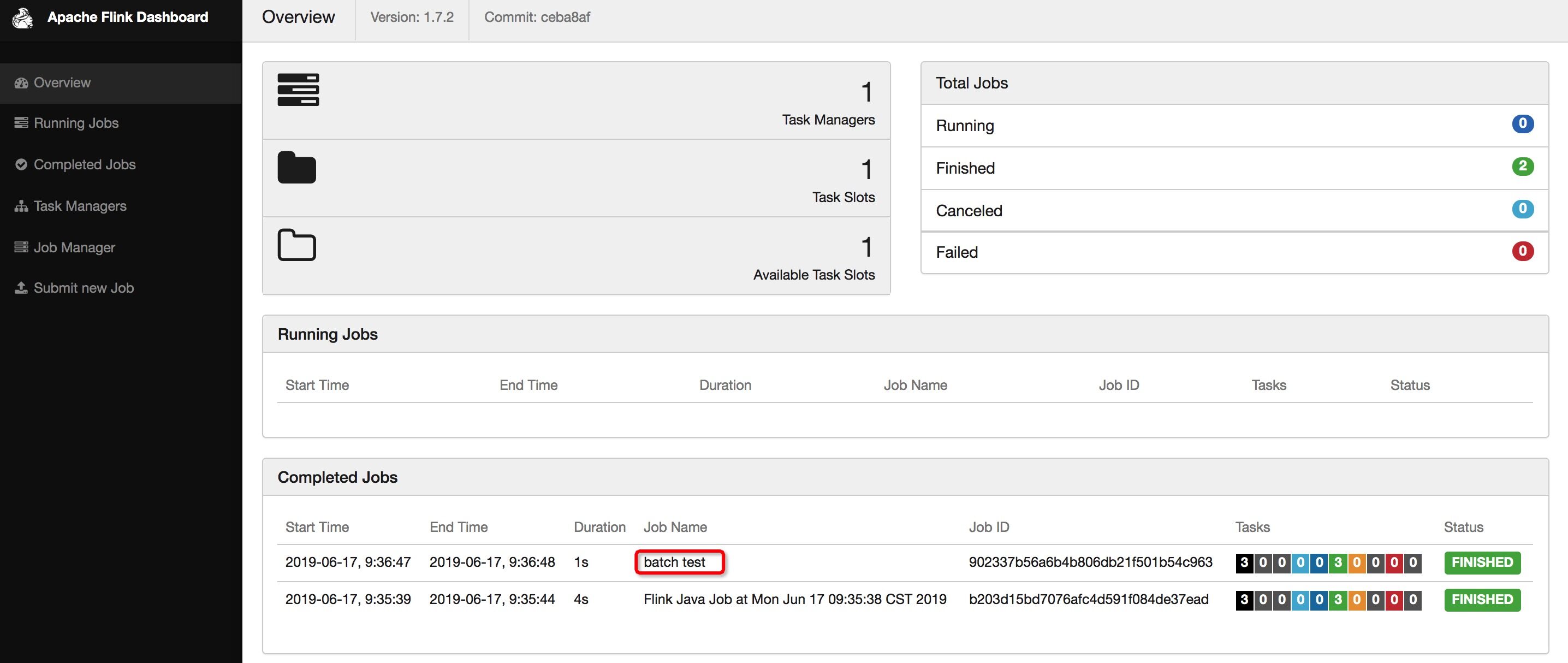
也可以将结果输出到文件(先删除 /tmp/out1,不然会报错同名文件已经存在),继续执行以下命令:
scala> counts.writeAsText("/tmp/out1")res1: org.apache.flink.api.java.operators.DataSink[(String, Int)] = DataSink '<unnamed>' (TextOutputFormat (/tmp/out1) - UTF-8)
scala> benv.execute("batch test")res2: org.apache.flink.api.common.JobExecutionResult = org.apache.flink.api.common.JobExecutionResult@737652a9
查看 /tmp/out1 文件就能看到输出结果。
➜ flink-1.7.2 cat /tmp/out1(be,2)(is,1)(not,1)(or,1)(question,1)(that,1)(the,1)(to,2)
DataStream
scala> val textStreaming = senv.fromElements("To be, or not to be,--that is the question:--")textStreaming: org.apache.flink.streaming.api.scala.DataStream[String] = org.apache.flink.streaming.api.scala.DataStream@4970b93d
scala> val countsStreaming = textStreaming.flatMap { _.toLowerCase.split("\\W+") }.map { (_, 1) }.keyBy(0).sum(1)countsStreaming: org.apache.flink.streaming.api.scala.DataStream[(String, Int)] = org.apache.flink.streaming.api.scala.DataStream@6a478680
scala> countsStreaming.print()res3: org.apache.flink.streaming.api.datastream.DataStreamSink[(String, Int)] = org.apache.flink.streaming.api.datastream.DataStreamSink@42bfc11f
scala> senv.execute("Streaming Wordcount")(to,1)(be,1)(or,1)(not,1)(to,2)(be,2)(that,1)(is,1)(the,1)(question,1)res4: org.apache.flink.api.common.JobExecutionResult = org.apache.flink.api.common.JobExecutionResult@1878815a
对 DataStream 任务,print() 并不会触发任务的执行,需要显示调用 execute(“job name”) 才会执行任务。
TableAPI
在 Blink 开源版本里面,支持了 TableAPI 方式提交任务(可以用 btenv.sqlQuery 提交 SQL 查询),社区版本 Flink 1.8 会支持 TableAPI: https://issues.apache.org/jira/browse/FLINK-9555
2.3 SQL Client Beta
SQL Client 目前还只是测试版,处于开发阶段,只能用于 SQL 的原型验证,不推荐在生产环境使用。
2.3.1 基本用法
➜ flink-1.7.2 bin/start-cluster.shStarting cluster.Starting standalonesession daemon on host zkb-MBP.local.Starting taskexecutor daemon on host zkb-MBP.local.
➜ flink-1.7.2 ./bin/sql-client.sh embeddedNo default environment specified.Searching for '/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf/sql-client-defaults.yaml'...found.Reading default environment from: file:/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf/sql-client-defaults.yamlNo session environment specified.Validating current environment...done.… …
Flink SQL> help;The following commands are available:
QUIT Quits the SQL CLI client.CLEAR Clears the current terminal.HELP Prints the available commands.SHOW TABLES Shows all registered tables.SHOW FUNCTIONS Shows all registered user-defined functions.DESCRIBE Describes the schema of a table with the given name.EXPLAIN Describes the execution plan of a query or table with the given name.SELECT Executes a SQL SELECT query on the Flink cluster.INSERT INTO Inserts the results of a SQL SELECT query into a declared table sink.CREATE VIEW Creates a virtual table from a SQL query. Syntax: 'CREATE VIEW <name> AS <query>;'DROP VIEW Deletes a previously created virtual table. Syntax: 'DROP VIEW <name>;'SOURCE Reads a SQL SELECT query from a file and executes it on the Flink cluster.SET Sets a session configuration property. Syntax: 'SET <key>=<value>;'. Use 'SET;' for listing all properties.RESET Resets all session configuration properties.
Hint: Make sure that a statement ends with ';' for finalizing (multi-line) statements.
Select 查询
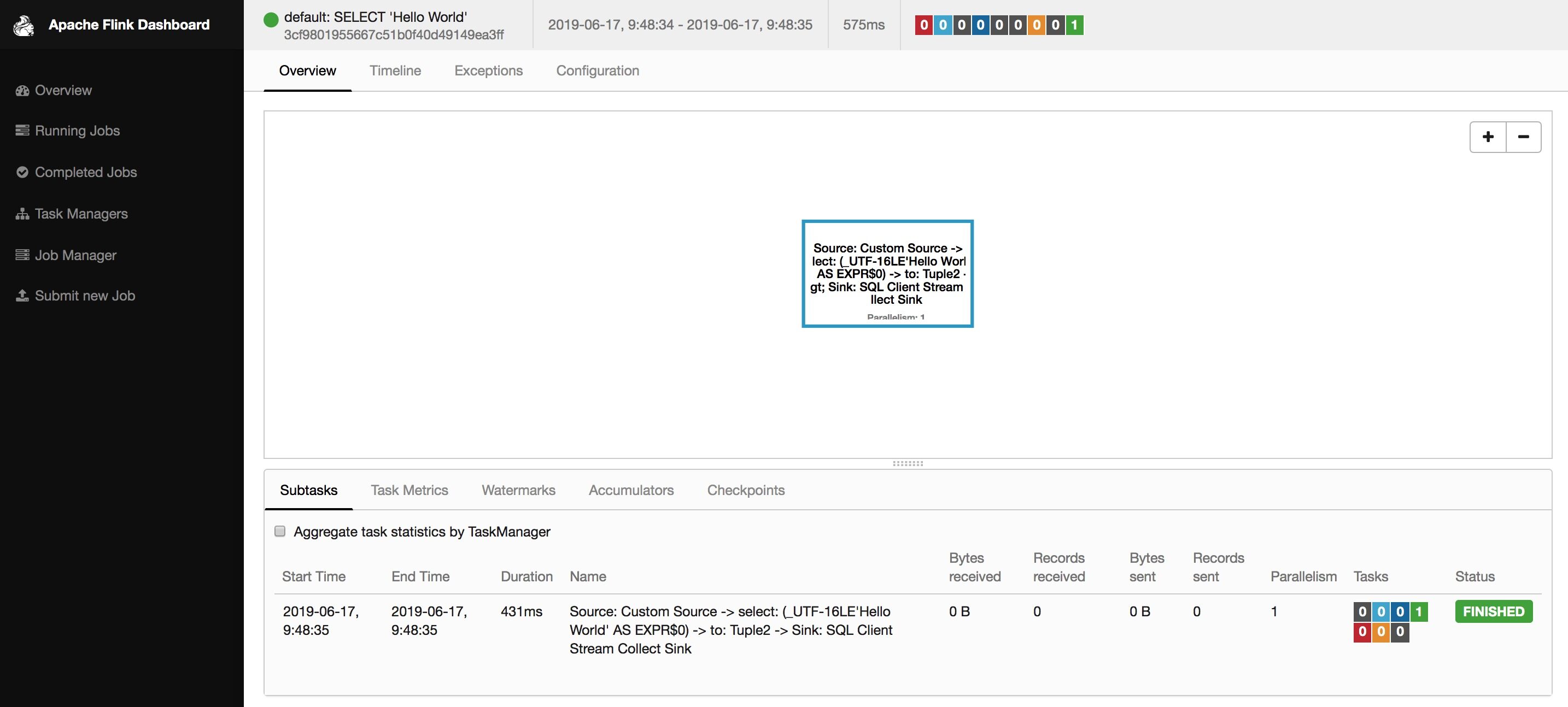
Flink SQL> SELECT 'Hello World';
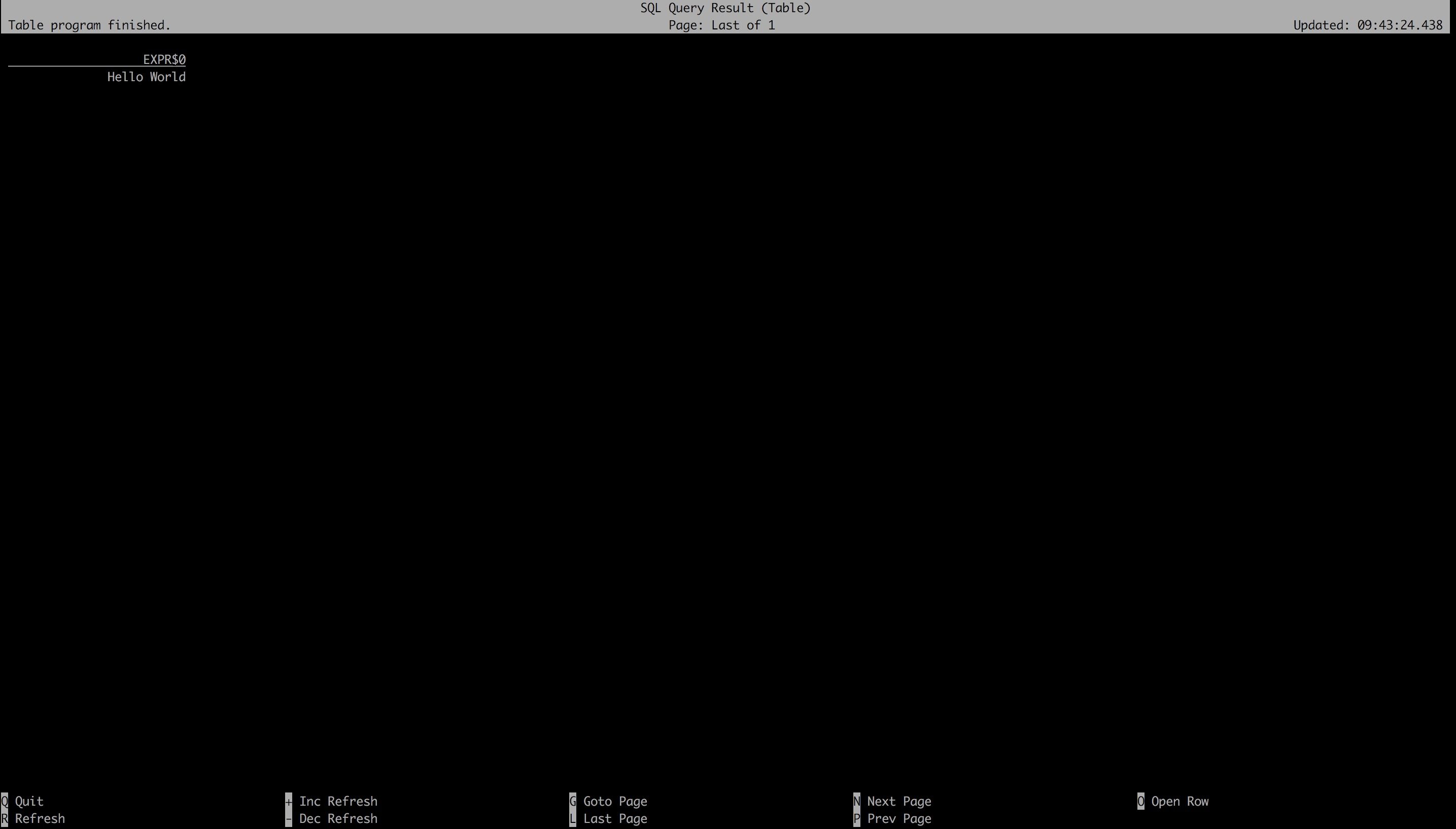
按 “Q” 退出这个界面
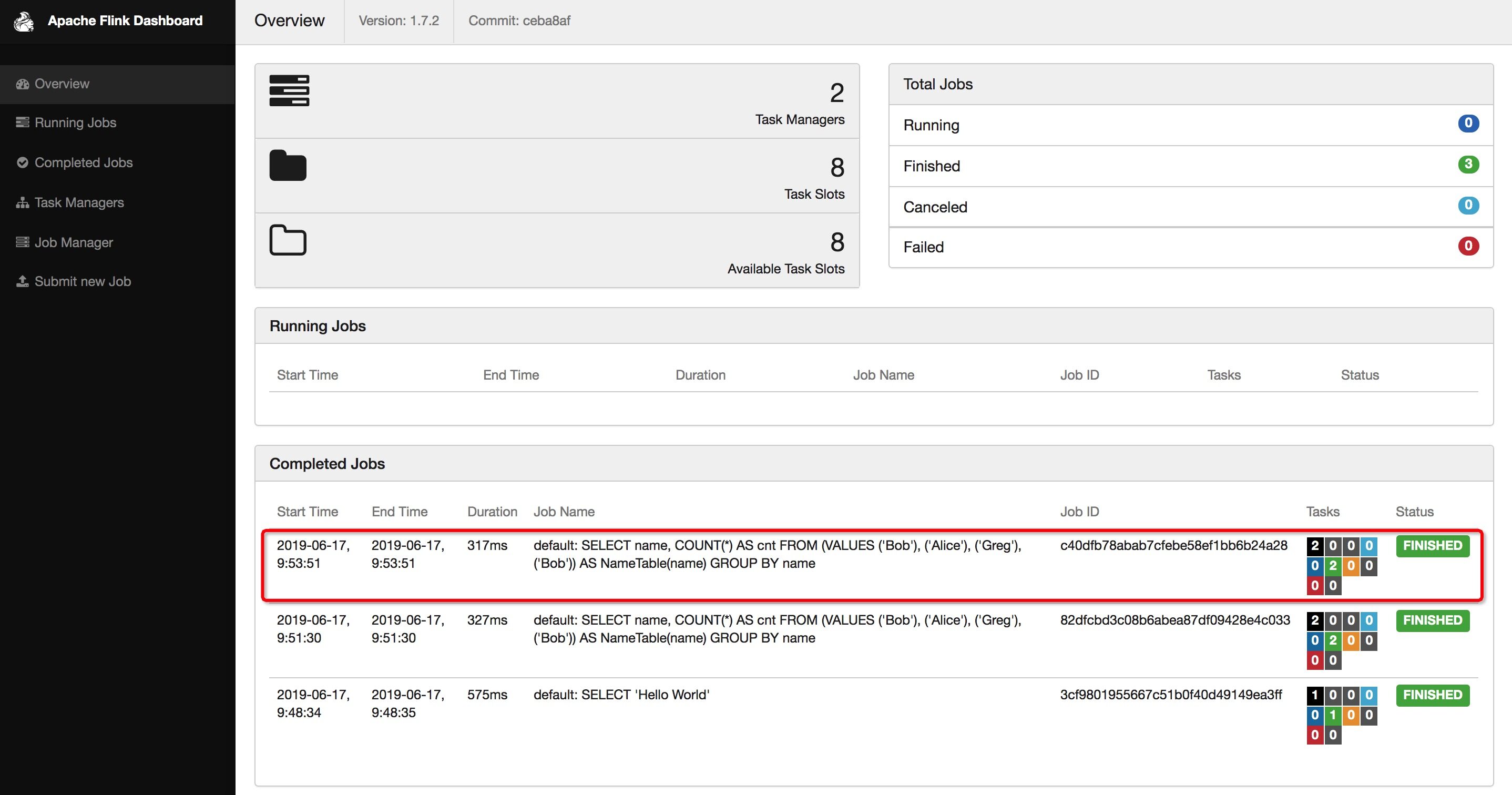
打开 http://127.0.0.1:8081 能看到这条 Select 语句产生的查询任务已经结束了。这个查询采用的是读取固定数据集的 Custom Source,输出用的是 Stream Collect Sink,且只输出一条结果。
注意:如果本机的临时目录存在类似 .yarn-properties-baoniu 的文件,任务会提交到 Yarn 上。
Explain
Explain 命令可以查看 SQL 的执行计划。
Flink SQL> explain SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
== Abstract Syntax Tree == // 抽象语法树LogicalAggregate(group=[{0}], cnt=[COUNT()]) LogicalValues(tuples=[[{ _UTF-16LE'Bob ' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg ' }, { _UTF-16LE'Bob ' }]])
== Optimized Logical Plan == // 优化后的逻辑执行计划DataStreamGroupAggregate(groupBy=[name], select=[name, COUNT(*) AS cnt]) DataStreamValues(tuples=[[{ _UTF-16LE'Bob ' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg ' }, { _UTF-16LE'Bob ' }]])
== Physical Execution Plan == // 物理执行计划Stage 3 : Data Source content : collect elements with CollectionInputFormat
Stage 5 : Operator content : groupBy: (name), select: (name, COUNT(*) AS cnt) ship_strategy : HASH
2.3.2 结果展示
SQL Client 支持两种模式来维护并展示查询结果:
table mode: 在内存中物化查询结果,并以分页 table 形式展示。用户可以通过以下命令启用 table mode;
SET execution.result-mode=table
changlog mode: 不会物化查询结果,而是直接对 continuous query 产生的添加和撤回(retractions)结果进行展示。
SET execution.result-mode=changelog
接下来通过实际的例子进行演示。
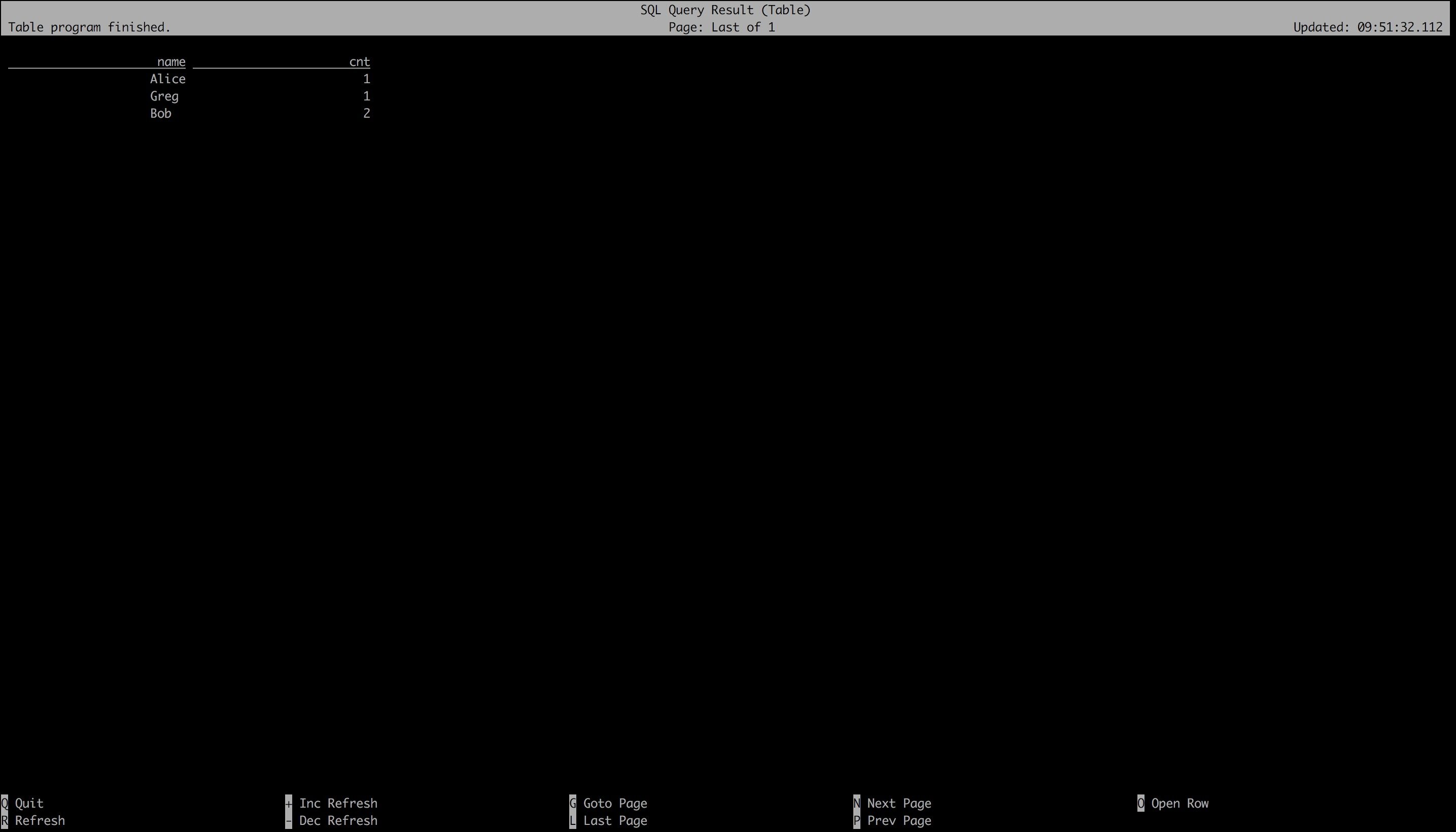
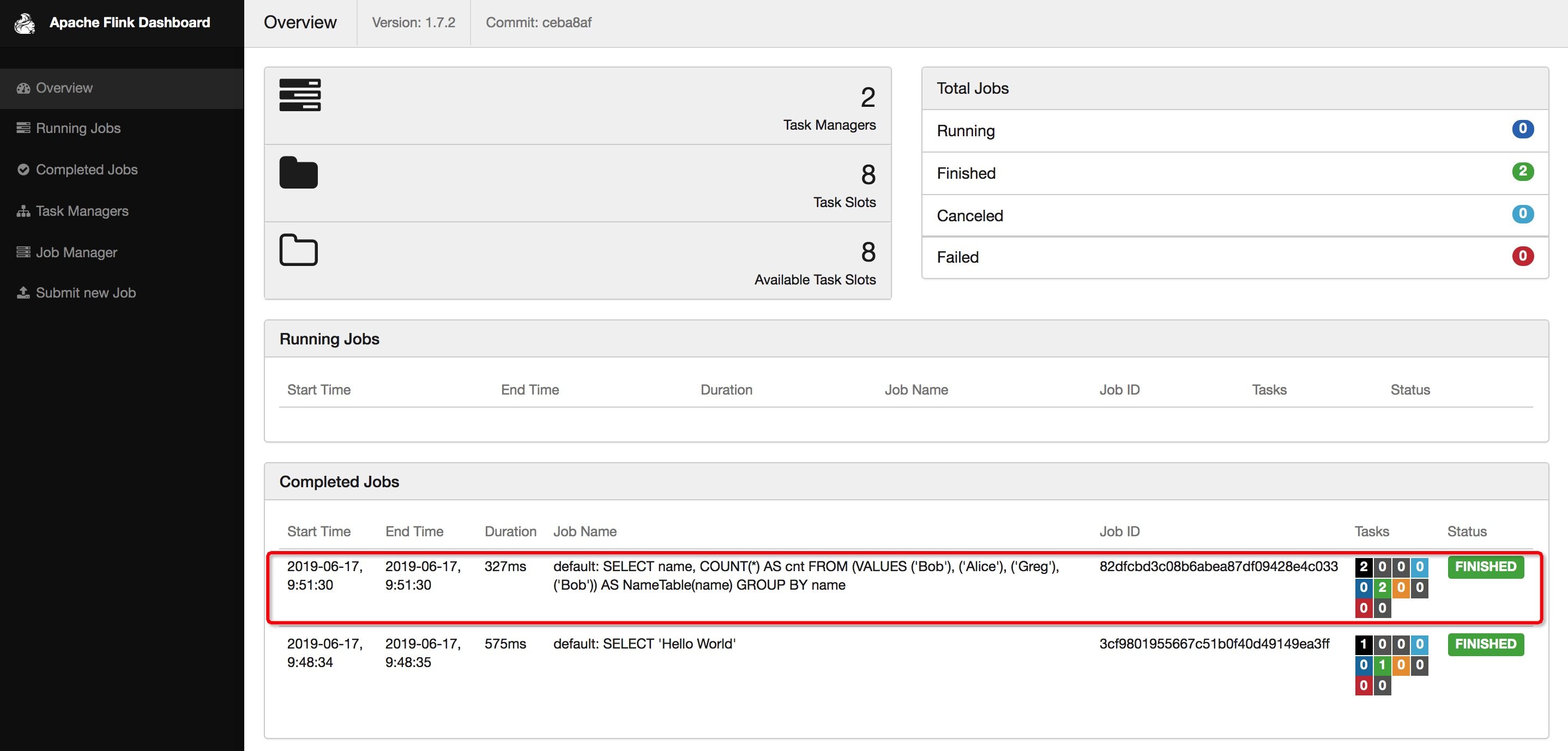
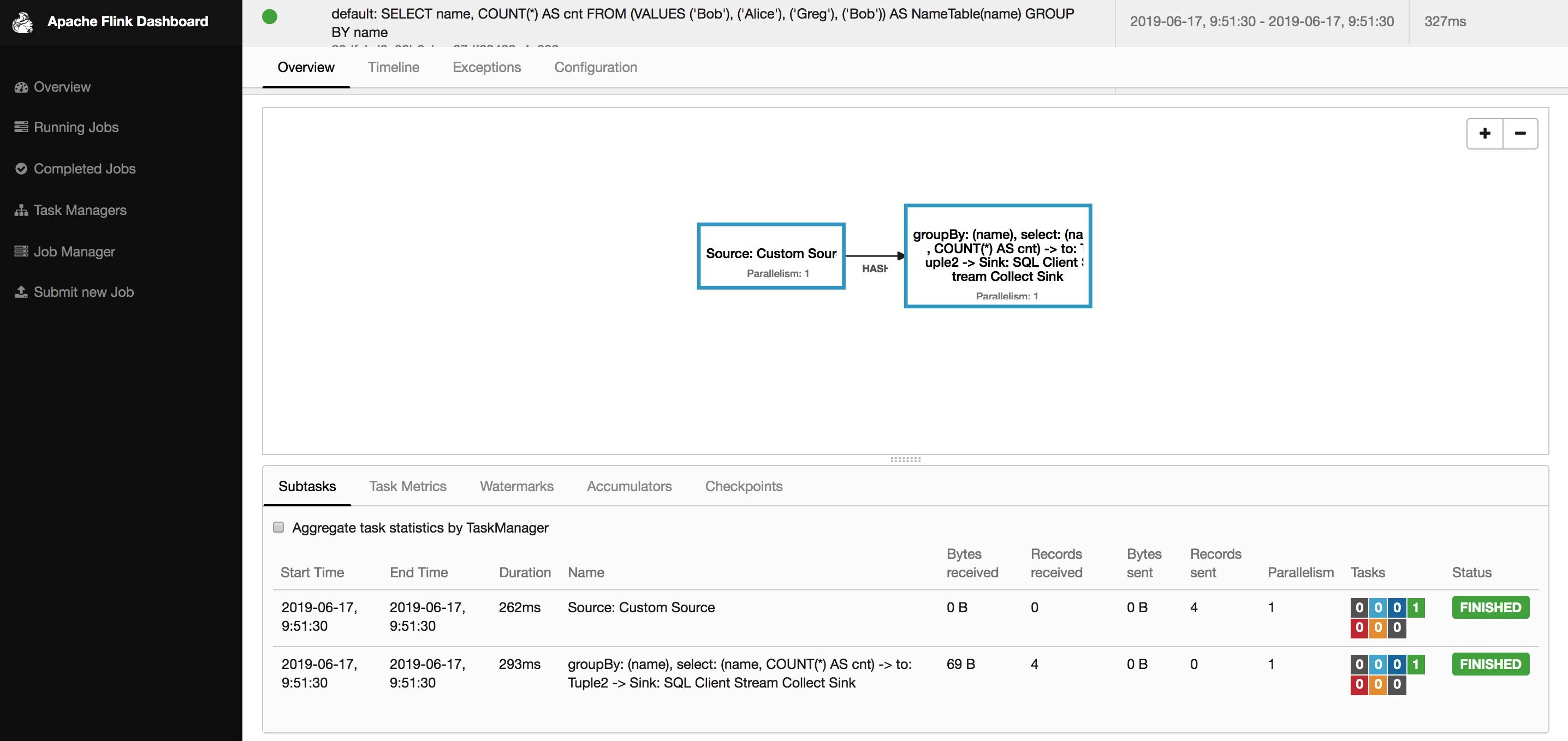
Table mode
Flink SQL> SET execution.result-mode=table;[INFO] Session property has been set.
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
运行结果如下图所示:
Changlog mode
Flink SQL> SET execution.result-mode=changelog;[INFO] Session property has been set.
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
运行结果如下图所示:

其中 ‘-’ 代表的就是撤回消息。
2.3.3 Environment Files
目前的 SQL Client 还不支持 DDL 语句,只能通过 yaml 文件的方式来定义 SQL 查询需要的表,UDF 和运行参数等信息。
首先,准备 env.yaml 和 input.csv 两个文件。
➜ flink-1.7.2 cat /tmp/env.yamltables: - name: MyTableSource type: source-table update-mode: append connector: type: filesystem path: "/tmp/input.csv" format: type: csv fields: - name: MyField1 type: INT - name: MyField2 type: VARCHAR line-delimiter: "\n" comment-prefix: "#" schema: - name: MyField1 type: INT - name: MyField2 type: VARCHAR - name: MyCustomView type: view query: "SELECT MyField2 FROM MyTableSource" - name: MyTableSink type: sink-table update-mode: append connector: type: filesystem path: "/tmp/output.csv" format: type: csv fields: - name: MyField1 type: INT - name: MyField2 type: VARCHAR schema: - name: MyField1 type: INT - name: MyField2 type: VARCHAR # Execution properties allow for changing the behavior of a table program.
execution: type: streaming # required: execution mode either 'batch' or 'streaming' result-mode: table # required: either 'table' or 'changelog' max-table-result-rows: 1000000 # optional: maximum number of maintained rows in # 'table' mode (1000000 by default, smaller 1 means unlimited) time-characteristic: event-time # optional: 'processing-time' or 'event-time' (default) parallelism: 1 # optional: Flink's parallelism (1 by default) periodic-watermarks-interval: 200 # optional: interval for periodic watermarks (200 ms by default) max-parallelism: 16 # optional: Flink's maximum parallelism (128 by default) min-idle-state-retention: 0 # optional: table program's minimum idle state time max-idle-state-retention: 0 # optional: table program's maximum idle state time restart-strategy: # optional: restart strategy type: fallback # "fallback" to global restart strategy by default
# Deployment properties allow for describing the cluster to which table programs are submitted to.
deployment: response-timeout: 5000
➜ flink-1.7.2 cat /tmp/input.csv1,hello2,world3,hello world1,ok3,bye bye4,yes
启动 SQL Client:
➜ flink-1.7.2 ./bin/sql-client.sh embedded -e /tmp/env.yamlNo default environment specified.Searching for '/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf/sql-client-defaults.yaml'...found.Reading default environment from: file:/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/conf/sql-client-defaults.yamlReading session environment from: file:/tmp/env.yamlValidating current environment...done.
Flink SQL> show tables;MyCustomViewMyTableSinkMyTableSource
Flink SQL> describe MyTableSource;root |-- MyField1: Integer |-- MyField2: String
Flink SQL> describe MyCustomView;root |-- MyField2: String
Flink SQL> create view MyView1 as select MyField1 from MyTableSource;[INFO] View has been created.
Flink SQL> show tables;MyCustomViewMyTableSourceMyView1
Flink SQL> describe MyView1;root |-- MyField1: Integer
Flink SQL> select * from MyTableSource;
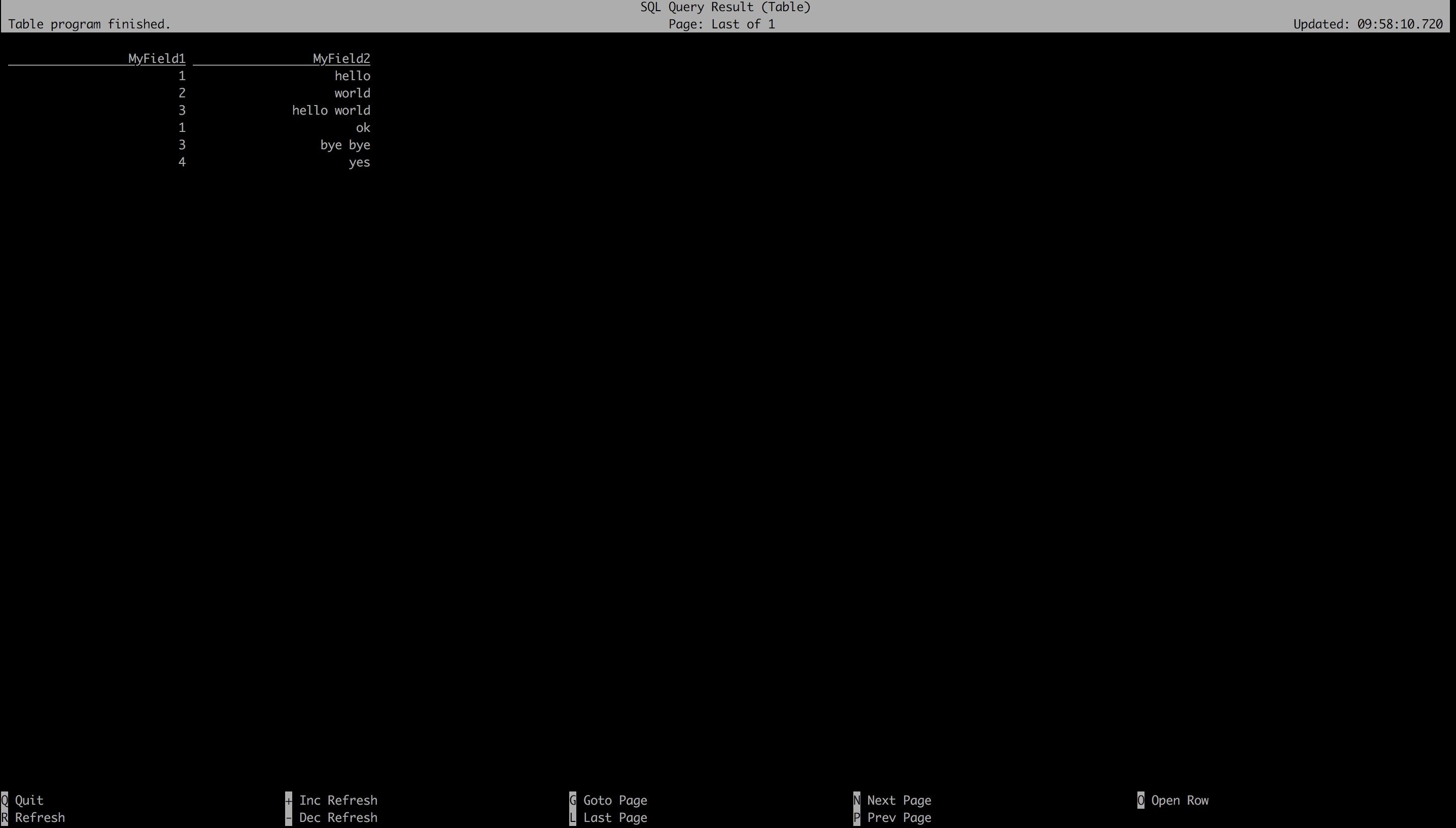
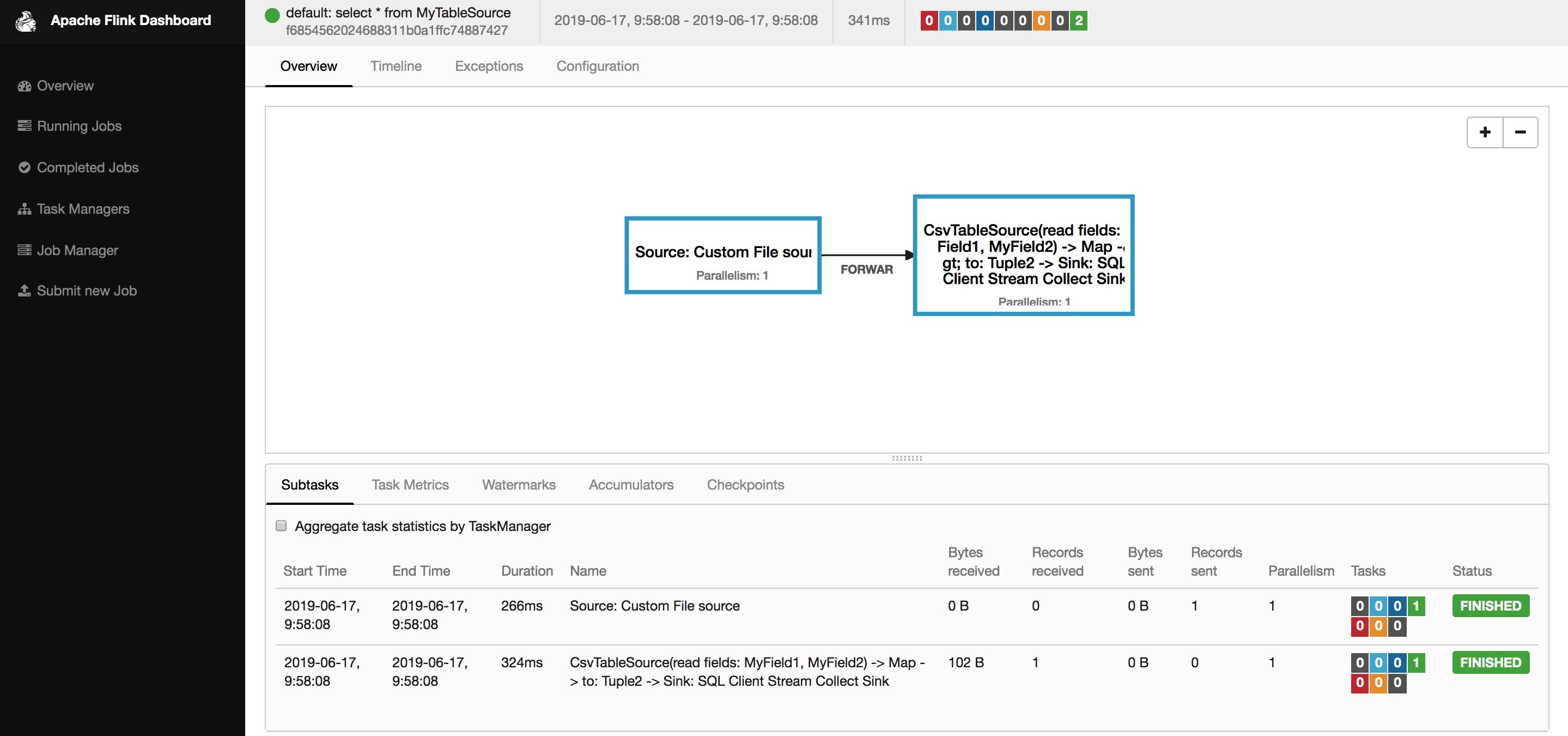
使用 insert into 写入结果表:
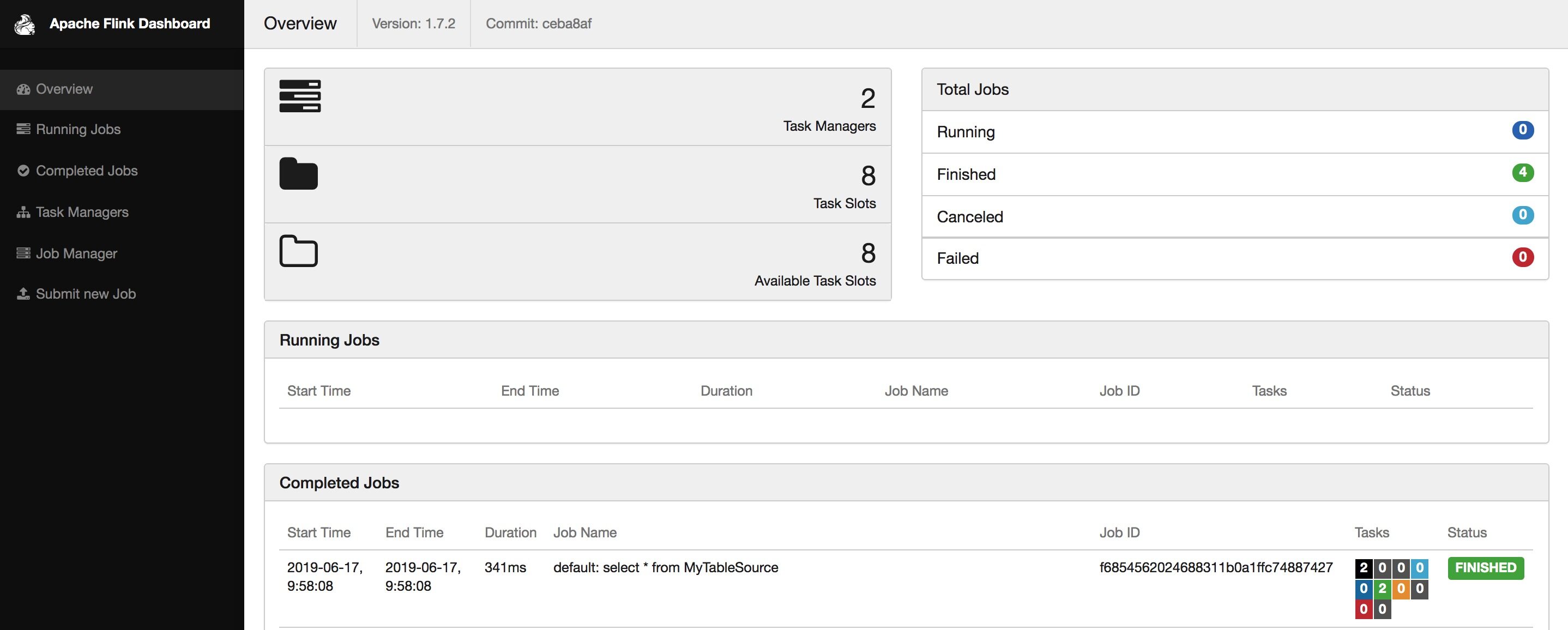
Flink SQL> insert into MyTableSink select * from MyTableSource;[INFO] Submitting SQL update statement to the cluster...[INFO] Table update statement has been successfully submitted to the cluster:Cluster ID: StandaloneClusterIdJob ID: 3fac2be1fd891e3e07595c684bb7b7a0Web interface: http://localhost:8081
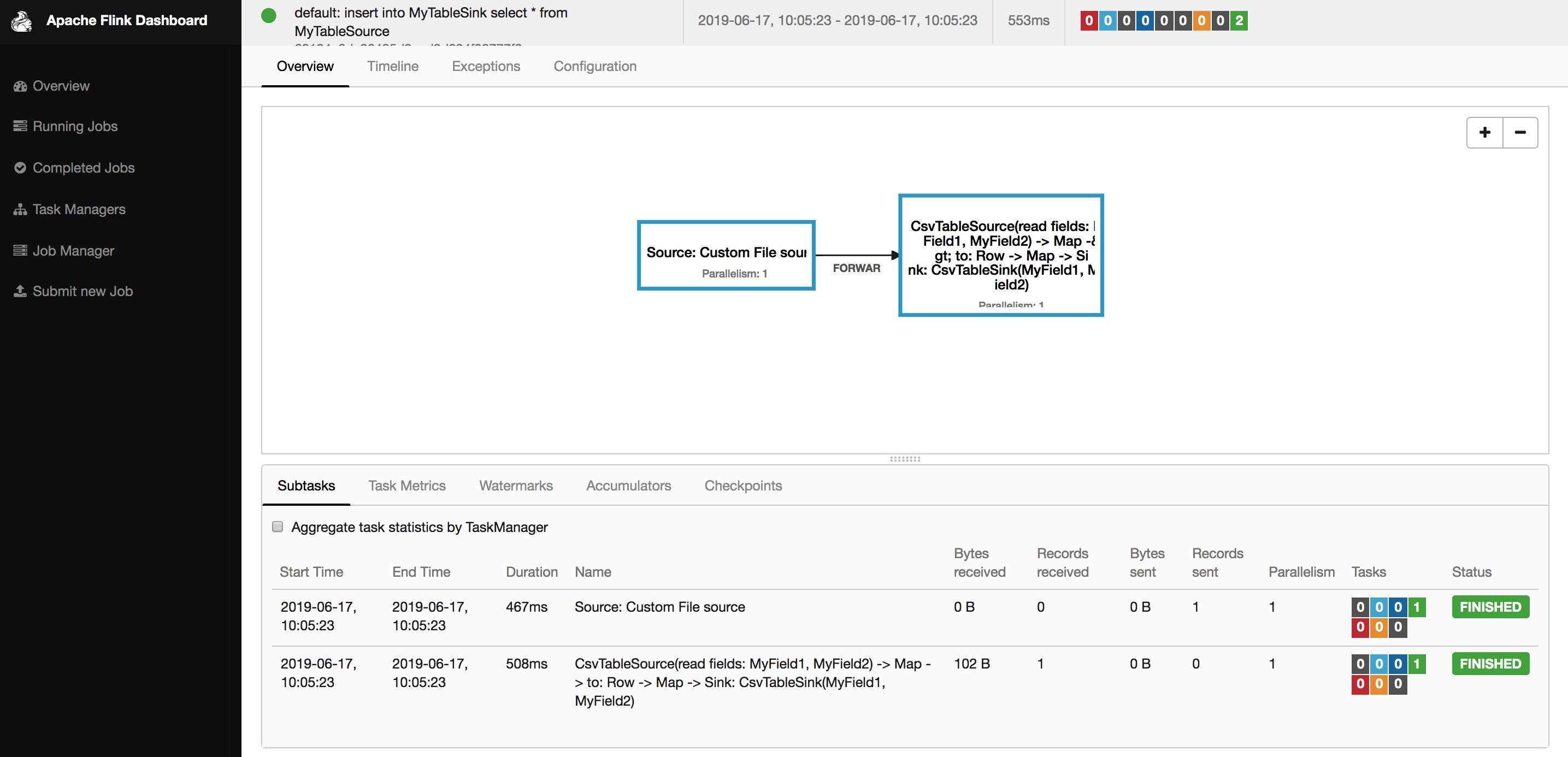
查询生成的结果数据文件:
➜ flink-1.7.2 cat /tmp/output.csv1,hello2,world3,hello world1,ok3,bye bye4,yes
也可以在 Environment 文件里面定义 UDF,在 SQL Client 里面通过 「HOW FUNCTIONS」查询和使用,这里就不再说明了。
SQL Client 功能社区还在开发中,详见 FLIP-24。
2.4 Restful API
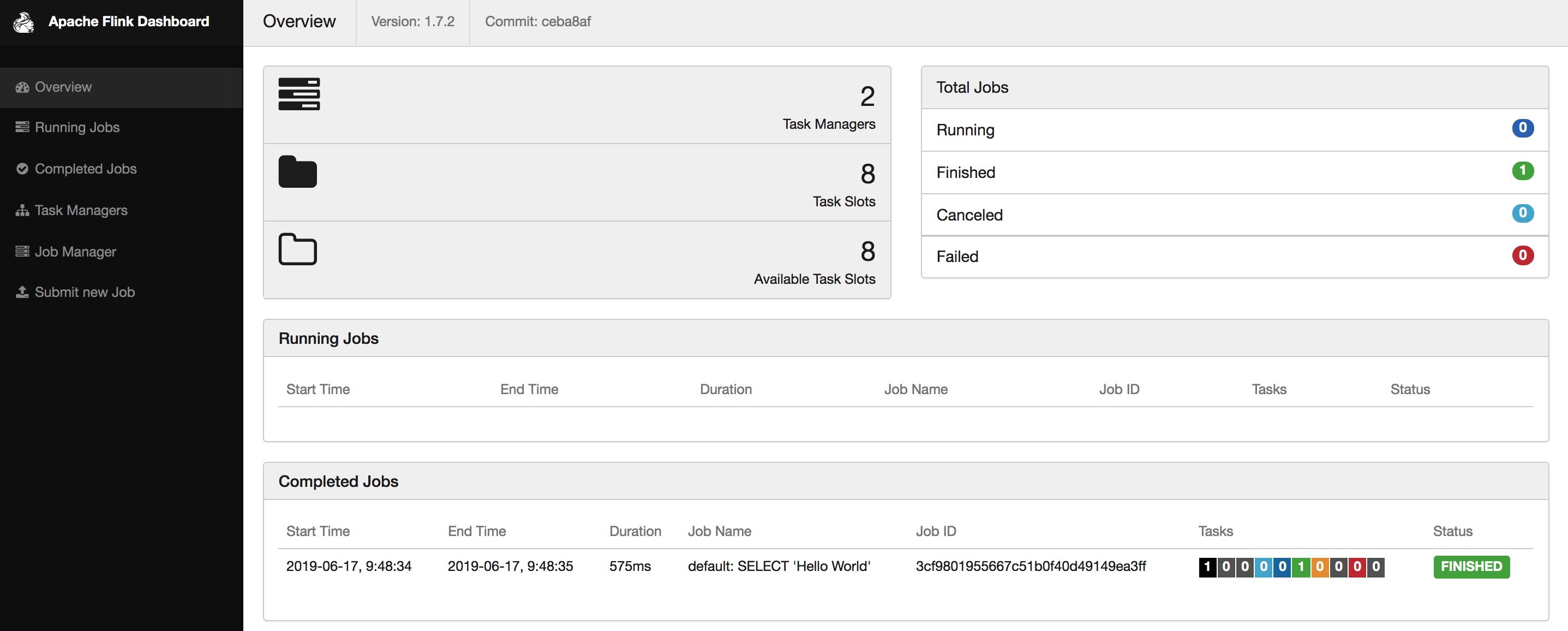
接下来我们演示如何通过 Rest API 来提交 Jar 包和执行任务。
更详细的操作请参考 Flink 的 Restful API 文档:https://ci.apache.org/projects/flink/flink-docs-stable/monitoring/rest_api.html
➜ flink-1.7.2 curl http://127.0.0.1:8081/overview{"taskmanagers":1,"slots-total":4,"slots-available":0,"jobs-running":3,"jobs-finished":0,"jobs-cancelled":0,"jobs-failed":0,"flink-version":"1.7.2","flink-commit":"ceba8af"}%
➜ flink-1.7.2 curl -X POST -H "Expect:" -F "jarfile=@/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/examples/streaming/TopSpeedWindowing.jar" http://127.0.0.1:8081/jars/upload{"filename":"/var/folders/2b/r6d49pcs23z43b8fqsyz885c0000gn/T/flink-web-124c4895-cf08-4eec-8e15-8263d347efc2/flink-web-upload/6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar","status":"success"}% ➜ flink-1.7.2 curl http://127.0.0.1:8081/jars{"address":"http://localhost:8081","files":[{"id":"6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar","name":"TopSpeedWindowing.jar","uploaded":1553743438000,"entry":[{"name":"org.apache.flink.streaming.examples.windowing.TopSpeedWindowing","description":null}]}]}% ➜ flink-1.7.2 curl http://127.0.0.1:8081/jars/6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar/plan{"plan":{"jid":"41029eb3feb9132619e454ec9b2a89fb","name":"CarTopSpeedWindowingExample","nodes":[{"id":"90bea66de1c231edf33913ecd54406c1","parallelism":1,"operator":"","operator_strategy":"","description":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction) -> Sink: Print to Std. Out","inputs":[{"num":0,"id":"cbc357ccb763df2852fee8c4fc7d55f2","ship_strategy":"HASH","exchange":"pipelined_bounded"}],"optimizer_properties":{}},{"id":"cbc357ccb763df2852fee8c4fc7d55f2","parallelism":1,"operator":"","operator_strategy":"","description":"Source: Custom Source -> Timestamps/Watermarks","optimizer_properties":{}}]}}% ➜ flink-1.7.2 curl -X POST http://127.0.0.1:8081/jars/6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar/run{"jobid":"04d80a24b076523d3dc5fbaa0ad5e1ad"}%
Restful API 还提供了很多监控和 Metrics 相关的功能,对于任务提交的操作也支持的比较全面。
2.5 Web
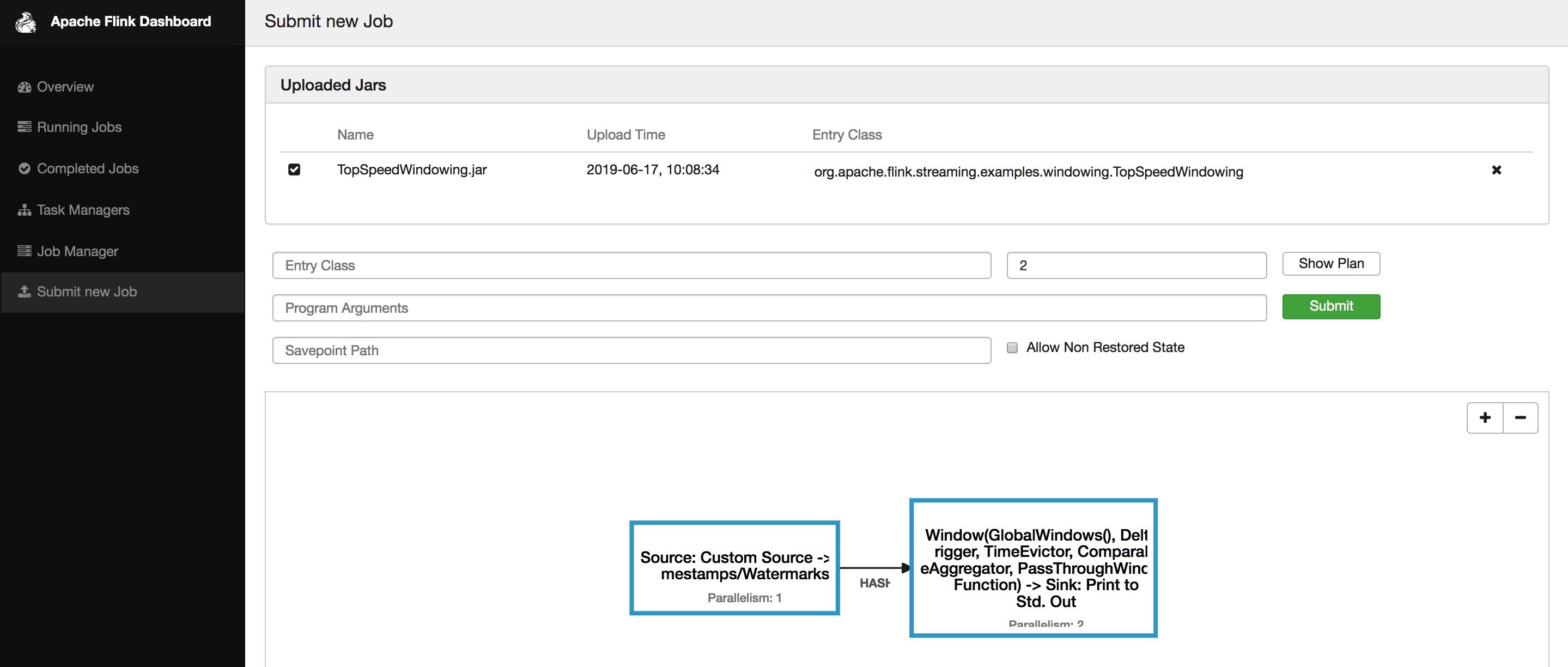
在 Flink Dashboard 页面左侧可以看到有个「Submit new Job」的地方,用户可以上传 Jar 包和显示执行计划和提交任务。Web 提交功能主要用于新手入门和演示用。
3.结语
本文主要讲解了 Flink 的 5 种任务提交的方式。熟练掌握各种任务提交方式,有利于提高我们日常的开发和运维效率。
视频回顾:https://www.bilibili.com/video/av47600600/?spm_id_from=333.788.videocard.5
更多干货内容参见Apache Flink 零基础入门专题。
更多内容推荐
Flink1.11+Hive 批流一体数仓
本文主要分享在Flink 1.11中对接Hive的新特性,以及如何利用Flink对Hive数仓进行实时化改造,从而实现批流一体的目标。
Apache Flink 零基础入门(二):开发环境搭建和应用的配置、部署及运行
本文主要面向于初次接触 Flink或者对 Flink 有了解但是没有实际操作过的同学。希望帮助大家更顺利地上手使用 Flink,并着手相关开发调试工作。
常见工具脚本大汇总
今天,我们一起梳理一下Kafka 2.2版本自带的所有脚本,学习一些常见的运维操作的工具行命令。
2019 年 8 月 13 日
腾讯基于 Flink 的实时流计算平台演进之路
腾讯实时计算团队为业务部门提供高效、稳定和易用的实时数据服务。其每秒接入的数据峰值达到了 2.1 亿条,每天接入的数据量达到了 17 万亿条,每天的数据增长量达到了 3PB,每天需要进行的实时计算量达到了 20 万亿次。腾讯选择用 Flink 作为新一代的实时流计算引擎,并对社区版的 Flink 进行了深度的优化,在此之上构建了一个集开发、测试、部署和运维于一体的一站式可视化实时计算平台——Oceanus。本文整理自腾讯大数据高级工程师杨华在 QCon 全球软件开发大会(北京站)2019 上的演讲,他介绍了腾讯流计算技术的演进过程,产品化及云端对外服务进展。
Custom Metrics: 让 Auto Scaling 不再“食之无味”
今天,我为你详细讲解了 Kubernetes 里对自定义监控指标,即 Custom Metrics 的设计与实现机制。
2018 年 12 月 14 日
微博基于 Flink 的机器学习实践
本文介绍微博基于Flink的机器学习实践。
从 0 到 1:你的第一个 GUI 自动化测试
我基于Selenium 2.0,带你从0到1建立了一个GUI自动化测试用例。这个用例的实现很简单,但是只有真正理解了这个工具的原理,你才能真正用好它。
2018 年 7 月 25 日
Flink Checkpoint 原理流程以及常见失败原因分析
本文是对Flink Checkpoint 原理流程的介绍以及常见失败原因分析。
让时间倒流的保存点:用 Apache Flink 的保存点技术重新处理数据流
这篇文章是系列文章的第一篇,数据工匠团队会在这里为大家展示一些Apache Flink的核心功能。
MLPipLine:如何通过 Spark ML PipLine 模式实现模型训练?
2021 年 1 月 28 日
新的 Dataproc 可选组件支持 Apache Flink 和 Docker
集群。Flink。是一种广泛使用的容器技术。集群的每个节点。集群交互。中创建容器化的服务。集群。可移植性的更多信息。
Spark 任务等待与运行策略
前面我们提到了Spark的资源分配策略,资源配置有静态和动态两种模式,不同模式在任务提交后会有不同的内存占用行为,但是由于队列资源是有限的,因此会出现任务因为资源不够导致等待的情况。本节来详细分析一下任务提交后在的等待与运行影响因素。
2021 年 4 月 19 日
Apache Flink 1.9 重磅发布:正式合并阿里内部版本 Blink 重要功能
拥有阿里内部版本重要功能的Flink版本终于来啦!
Word Count:从零开始运行你的第一个 Spark 应用
纸上谈兵不可取,今天用一个小练习为你示范怎样解决统计词频的问题。
2019 年 5 月 29 日
Flink 中的应用部署:当前状态与新应用模式
平台开发人员和维护人员经常提到的障碍之一是,Deployer 可能是一个很难配置的大量资源消耗者。
Apache Beam 实战冲刺:Beam 如何 run everywhere?
在实践中,你可以动态地选择数据处理流水线在何处运行。
2019 年 7 月 1 日
揭秘华为云 DLI 背后的核心计算引擎
本文主要给大家介绍隐藏在华为云数据湖探索服务(后文简称DLI)背后的核心计算引擎——Spark。
Flink 如何取代 JStorm,成为字节跳动流处理唯一标准?
本文将为大家展示字节跳动公司将 Jstorm 任务迁移到Apache Flink 上的整个过程以及后续计划。你可以借此了解到字节跳动公司引入Apache Flink 的背景,Apache Flink 集群的构建过程,如何兼容以前的 Jstorm 作业以及基于Apache Flink 构建一个流式任务管理平台,本文将一一为你揭开这些神秘的面纱。
推荐阅读
重磅!阿里巴巴 Blink 正式开源,重要优化点解读
Apache Flink 进阶(六):Flink 作业执行深度解析
经典 PaaS 的记忆:作业副本与水平扩展
2018 年 10 月 1 日
Apache Flink 零基础入门(八):Flink SQL 编程实践
用 Apache Spark 进行大数据处理——第一部分:入门介绍
跨集群备份解决方案 MirrorMaker
2019 年 8 月 22 日
ZooKeeper API:Watch 示例
2019 年 8 月 19 日
电子书

大厂实战PPT下载
换一换 
薛秋实 | 快手 客户端团队稳定性负责人
阮铭 | 西门子Mendix 高级架构师
贾岩涛 | 华为 中央软件院知识图谱首席技术专家










评论