
本文作者|Yuan Zhu
ByConity 0.3.0 版本本周发布,其中「基于共享存储的选主方式」作为 0.3.0 版本的主要功能将在此次更新中实现。本文将介绍其在 ByConity 中的设计思考与实践。
背景
在传统常见的分布式 share-nothing 微服务架构中,我们通常使用 DNS 这类成熟方案来进行节点之间的服务发现,使用 Zookeeper、Etcd、Consul 这类成熟组件在副本节点之间进行 leader-follower 选举以实现集群的高可用,在配置、使用、运维管理都有一定的复杂度。
在越来越多的分布式系统中使用一份高可用存储来实现 share-everything 存算分离架构的今天,我们可以利用这块高可用存储来模拟单机系统里的共享内存,将不同的计算节点看成是单机系统里的进(线)程,模仿单机系统的方案来实现他们之间的发现、同步。
本文即介绍以上思想是如何在开源云原生数仓 ByConity 中设计和实践的。
ByConity 的基本架构
《谈谈 ByConity 存储计算分离架构和优势》介绍了基于 ClickHouse 的开源云原生数仓 ByConity 的存算分离架构。
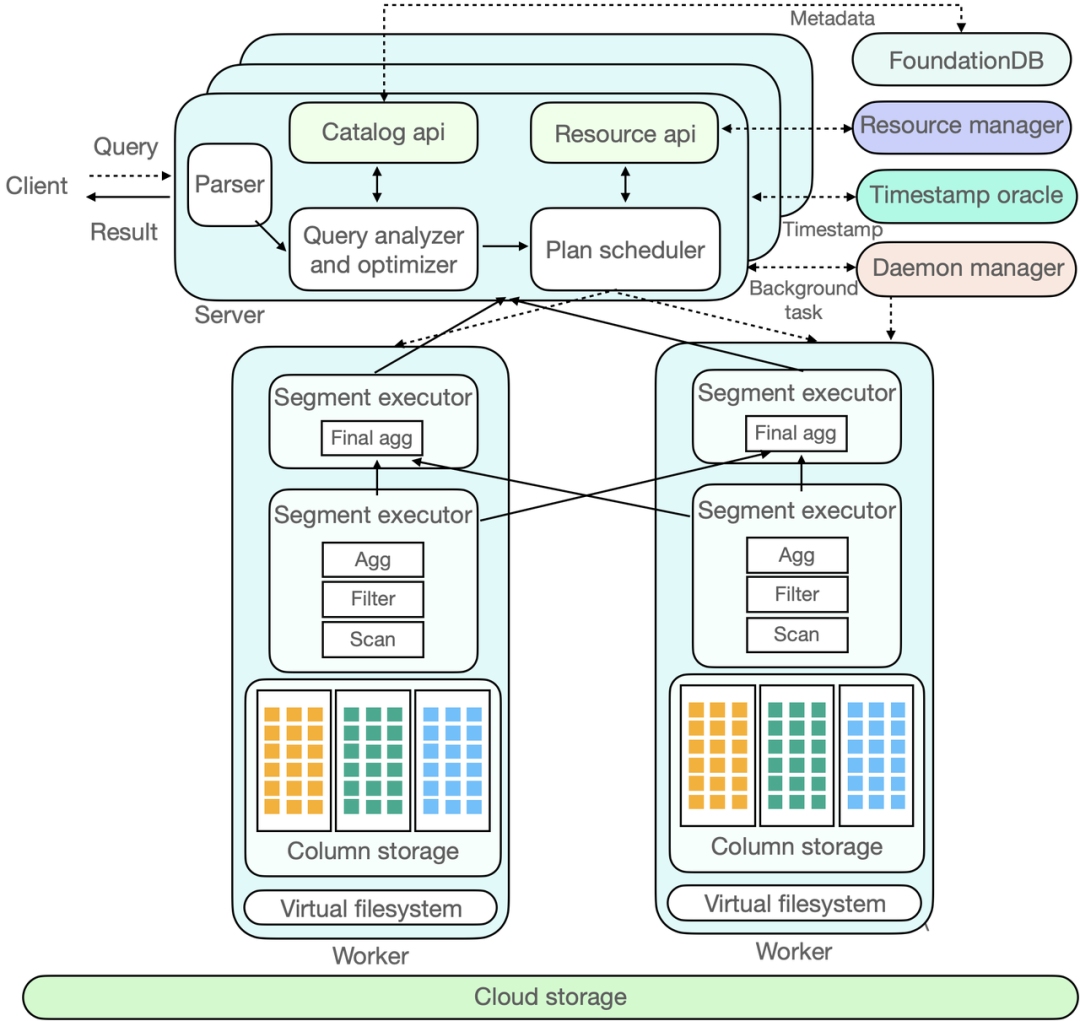
可以看到,在计算一侧,存在多种控制节点,它们需要各自通过多副本 + 选主来提供高可用的服务能力,例如上图中的 Resource manager/Timestamp oracle 等。实际中的多个计算 server,也需要在选出一个单节点来执行特定的读写任务。
最早 ByConity 使用了 ClickHouse-keeper(以下简称"keeper")组件来进行选主,该组件基于 Raft 实现,提供兼容 zookeeper 的选主接口,在实际使用中遇到了以下运维问题:
至少需要部署 3 个 keeper 节点,才能提供单个节点故障的容灾。这是因为 Raft 协议需要过半节点正常运行,才能维护主节点的正常工作和选举。
节点增删和服务发现流程复杂。需要修改所有 keeper 节点的配置文件才能生效,且所有的调用者也需要修改配置才能发现这个结果。ByConity 实现过一个使用固定的共享域名来代替给每个 keeper 节点配置地址的方案,但又进一步带来了处理 域名解析的可访问节点数量和 keeper 中配置数量不一致时的复杂性。
容器重启后如果服务变换 ip 和服务端口,ClickHouse-keeper 难以快速恢复。这不仅是因为 2,也是因为 keeper 实现中 raft 的 server_id 和监听地址进行了强绑定。

我们可以把以上问题分类为:
故障时的容灾性能。
高可用的运维、部署成本。
考虑到 ByConity 作为一个新的云原生服务,并不需要兼容 ClickHouse 对 zookeeper 的访问,我们选择了基于存算分离的云原生架构实现一种新的选主方式来优化以上问题。
基于共享存储的 leader 选举
术语定义
副本:地位相互平等的某个服务多个部署实例进程。
业务:除了选举之外的服务逻辑。
Follower:副本中不可提供业务服务的节点。
Leader:副本中可提供业务服务的节点,本文也常把 leader 选举简称为“选主”。
客户端:需要访问 leader 提供业务服务的节点。
设计思想
我们注意到如果一台计算机在试图同步多个线程对一个临界资源的访问竞争时,常见的 pthread_mutex 内存锁实现方案是非常简单的,依赖了以下基础:
锁被分配在一份所有线程可见的内存中;
内存支持通过 CAS(Compare And Swap)指令实现小对象的原子写入;
内存支持确保原子写入的结果,读者看到的写入顺序和写者的写入顺序一样;
操作系统内核通过 futex 等系统调用指令,支持原子的等待 / 通知线程某个值的变化,使得线程知道某个资源又可以被竞争了。

如果我们把 ByConity 多个试图选主的节点看成不同的线程,把支持事务提交、可见性顺序等于事务提交顺序的 Foudation DB(用于存储 ByConity 元数据的高可用 KV 存储,以下简称为“FDB”)看成支持 CAS 写入、保证可见性顺序的本地内存,用节点的定期 Get 轮询去模拟 Linux 内核的线程唤醒通知机制,我们就可以用 ByConity 所使用的高可用 Foudation DB KV 存储,通过模拟 CAS 操作去同步多个节点之间对“谁是 leader”这个问题答案的竞争:谁 CAS 成功谁就是 leader。
解决了相互竞争的写者之间的同步,我们还需要把写者竞争的结果发布给读者。Linux 的锁的数据结构会记录谁是 mutex owner,这里也可以把 leader 的监听地址写入竞争的结果:CAS 的 key 写入内容 value 需要包括自己的监听地址。所以读者访问这个 key 就可以完成服务发现(读者不需要知道非 leader 的地址)。
设计目标
我们预期实现以下目标:
选举组件以一个库的形式嵌入业务服务进行使用。类似 linux mutex 使用的 pthread 库。
支持任意多副本节点。
增删节点无需额外操作。
节点变更监听地址无需额外操作。
只要有一个副本节点可用,即可选主成功。这是因为存算分离场景,节点本地无状态,任何一个节点都可以成为主节点,无需从其他副本同步状态到本地。
副本节点之间无需相互通信和服务发现,包括无需进行物理时钟同步。
接下来,我们使用若干个分布式共识的达成来介绍如何具体去实现这些目标:
follower 之间对“谁是新 leader”达成共识。
新旧 2 任 leader 对“如何让卸任和上任的时间不重叠”达成共识。
服务端节点在配置变更时,对“选举的时间参数”在每一轮选举中达成共识。
客户端如何感知“谁是新 leader”这个服务端产生的共识。
follower 节点的角色共识:leader 选举的实现
数据结构
分布式系统具有许多单机系统所不涉及的复杂性,其中最主要的一个复杂性来源就是有限操作时间限制和非全连通拓扑带来的不可访问:单机系统的任何读写内存操作都没有“超时”或者失败的概念,而分布式系统必须考虑这个点才能保证可用性。

所以如上图,对于 leader CAS 写入的数据结构 LeaderInfo,除了包括自己的监听地址 address,也需要包括关于绑定了时间相关的状态信息 lease:例如 leader 上任时间点 elected_time,最近一次刷新时间 last_refresh_time(有变化就证明自己还活着),刷新的时间间隔要求 refresh_interval_ms,多长时间不刷新就认为 leader 已经任期结束(其它节点可以开始重新竞争 leader 了)expired_interval_ms,以及 leader 的状态 status。
选举基本规则
每个节点要么是 follower,要么是 leader。预期系统内任何一个时间点,只有一个节点认为自己是 leader。
任何节点都可以读 KV 存储中的一个 key (以下皆简称 “key”),从中得知 “谁是 leader”这个结果。如果这个 key 不存在,说明 leader 从未被成功选举。
leader 定期 CAS 更新 key 中存储 value(以下皆简称 “value”)的 lease.last_refresh_time 字段,延长自己的任期到 lease.last_refresh_time + lease.refresh_interval_ms。
leader 遇到进程结束等服务可控停止时,可以 CAS 更新 value 的 lease.status 字段为 Yield,主动让出 leader 身份。
每个 follower 定期 GET 读取 value,确认 leader 是否被成功选举、是否已经任期过期、是否已经让出 leader。如果是,那么 follower CAS 尝试更新 key 的 value 来竞选 leader,修改 address 为自己的地址。
接下来我们展开这个规则,介绍如何实际完成全流程的选举。
备选
前置条件
当前节点是 follower。
前置条件说明
每个节点启动后,都认为自己是 follower。
每个 leader 在 lease 任期结束之前没有成功更新 lease,被认为任期过期(即 now()
任期过期是一个节点基于本地时钟的判断,如何确保这个判断在 leader 和 follower 之间在不进行时钟同步的情况下避免判断冲突,本文会在后面介绍。 每个 leader 在更新 lease 时 CAS 失败,发现别人已经成为了 leader,也自动认为自己是 follower。
leader 遇到进程结束等服务可控停止时,可以 CAS 更新 value 的 lease.status 字段为 Yield,无论结果是否成功,也自动认为自己是 follower。
动作
follower 每隔 lease.refresh_interval_ms 就去轮询读取 key 的结果,检测 key 是否存在,或者 value 中的任期是否已经过期。
竞选
前置条件
当前节点是 follower。对于存算分离服务,我们认为每一个无状态副本都可以参与竞选,不存在状态机同步进度差异。
key 不存在,或者 value 中的任期已经过期,或者 value 中的 lease.status 是 Yield,或者 value 中的 address 是自己的监听地址。
动作
如果 key 不存在, 那么 Put if not exist 写入自己的地址信息。
如果 value 中的任期已经过期或者 value 中的 address 是自己的监听地址,那么 Put CAS 写入自己的地址信息。
写入的 lease 信息为:lease.status=Ready, lease.last_refresh_time=lease.elected_time=now(), lease.refresh_interval_ms 和 lease.expired_interval_ms 为配置文件中的信息。
胜选
前置条件
当前节点是 follower。
当前节点写入 value 成功;或者虽然 CAS 失败,但是发现 value 的 address 是自己的监听地址。
动作
检查是否任期已过期,即当前时间 now() 是否满足 now()
就职
前置条件
当前节点胜选,且任期没有过期。
动作
调用业务侧注册的 onLeader() 回调,提醒业务可以以 leader 方式提供服务了。对于有状态的服务,可能在这个过程需要同步一些状态才能以 leader 方式提供服务;对于无状态服务(例如 ByConity 的存算分离计算节点),胜选即可立即就职服务。
提供 isLeader() 接口供业务调用检查,仅在 now()
提供 yield() 接口供业务调用,可触发主动离职流程。
续任
前置条件
当前节点是 leader,且任期没有过期。可无限期连任。
距离竞选或最近一次续任时间已经超过或等于 lease.refresh_interval_ms,即 now()>=lease.last_refresh_time + lease.refresh_interval_ms 。
动作
CAS 设置 value 的 lease.last_refresh_time = now()。
主动离职
前置条件
当前节点是 leader。
被业务侧调用 yield() 接口。常见于服务退出等场景。
动作
调用业务侧注册的 onFollower() 回调,提醒业务不可以以 leader 方式提供服务了。
CAS 更新 value 的 lease.status=Yield,lease.last_refresh_time=now()。
当前节点变为 follower,即使 CAS 失败。
被动离职
前置条件
当前节点是 leader。
now()>=lease.last_refresh_time + lease.expired_interval_ms 或者在 CAS 更新 lease 发现被别的节点提前更新了。
动作
调用业务侧注册的 onFollower() 回调,提醒业务不可以以 leader 方式提供服务了。
当前节点变为 follower。
总结
我们回顾一下预期的目标,可以看到都实现了。
支持任意多副本节点。它们只需要和共享存储 FDB 进行通信。
增删节点无需额外操作。这是因为节点之间彼此都不互相服务发现和通信。
节点变更监听地址无需额外操作。这是因为节点主动通过 CAS 写入自己的监听地址,无需类似 Raft 需要显式的节点减少再增加动作。
只要有一个副本节点可用,即可选主成功。这是因为对于存算分离的无状态节点,任何副本都可以成为 leader。
副本节点之间无需相互通信同步和服务发现,包括物理时钟同步。
但是不进行物理时钟同步,会不会产生 2 个 leader 的任期相互交叠,而给集群服务带来风险?我们在下一节分析这个问题。
新旧 2 任 leader 的时间共识:对任期过期的判断
问题描述
我们可以看到一个旧的 follower 节点胜选之后,可以立即就职提供 leader 服务。此时有没可能整个集群中有 2 个 leader,都在提供 leader 服务呢?
先定义需求:
新 leader 上任开始 leader 服务后,旧 leader 不再以 leader 身份响应新的请求。
新 leader 上任开始 leader 服务后,旧 leader 在之前已经开始以 leader 身份处理的请求可以继续处理。
满足上面的需求需要以下保证:
任何 2 个节点的 leader 任期没有交叠。即不会发生节点 a 的 leader 任期还未结束,节点 b 的 leader 任期就已经开始。
业务服务在响应请求时,总是先调用选主组件提供的 isLeader() 接口检查任期是否过期。
第二个点我们需要业务服务进行改造即可满足。第一个点我们需要基于对任期的设计和实现说明安全性。
问题分析
如果要让 2 个 leader 之间任期在全局时钟下没有交叠,我们只需要保证:
假设 1:任何 follower 认为某 leader 的任期结束时间点 A 大于 leader 认为的自己的任期结束时间点 B。
因为 A 一定小于该 follower 竞选 leader 成功后的任期开始时间点。这样任何 2 个 leader 的任期就不会
有交叠了。而任期的结束时间点通常是由任期开始时间点来确定,为了方便工程实践,我们可以把假设 1 进行一个转换:
假设 1a: follower 认为的 leader 的任期开始时间点 大于 leader 认为的自己的任期开始时间点。
如果我们认为 leader 和 follower 的时钟,在任期内的计时误差,小于 2 者认为的任期开始时间点的差,那么显然假设 1a 成立时假设 1 也成立。我们接下来尝试找出能够实现假设 1a 的实际方案。
问题方案:任期区间的定义
如果我们怀疑 2 任 leader 的任期有交叠,那旧 leader 一定有一次对自己任期的续期成功 CAS 写入,第一个和他任期有交叠的新 leader 的成功上任时一定有对这个旧 leader 这个续期租约的成功读取,和对这个任期过期的判断,以及自己竞选时任期的成功 CAS 写入。
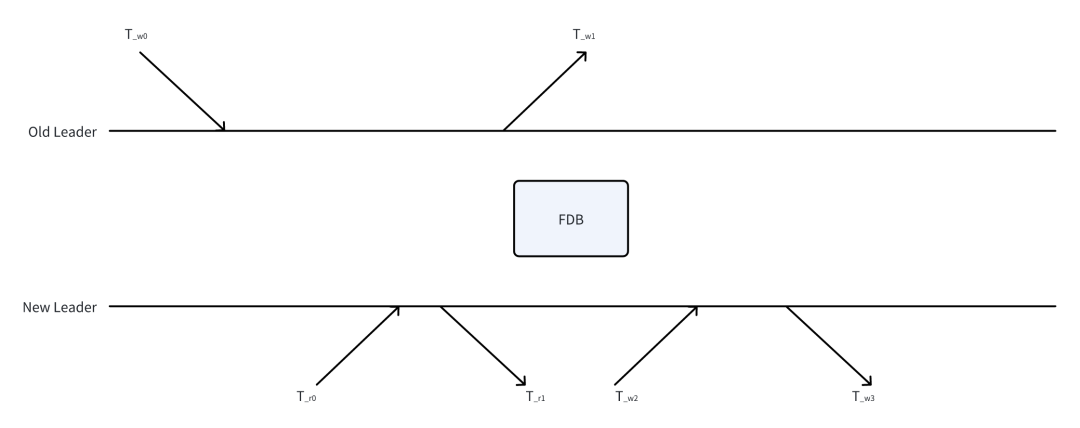
如上图:上一任旧 leader 最后一次对自己任期的续期写入的开始时间是 T_w0, 收到回包的是 T_w1;下一任新 leader 对旧 leader 最后一个任期 lease 的第一次读取的开始时间是 T_r0, 收到回包的是 T_r1, 竞选写入的开始时间是 T_w2, 收到回包的是 T_w3。假设这些数值是由一个虚拟但精确的全局时钟给出的时间戳。
从单机的视角来看,必然有大小关系顺序:
T_w0 < T_w1T_r0 < T_r1 < T_w2 < T_w3由于下一任新 leader 对旧 leader 写入最后一个任期的租约成功读取,这说明一定写、读之间有"happened-before"的关系,所以也有多机视角下的大小关系顺序:
T_w0 < T_r1我们将使用这个关系来给出符合假设 1a 的任期区间定义。设任期时间固定为 expired_interval_ms:
旧 leader 认为自己的任期是 [T_w0, T_w0+expired_interval_ms)
follower(未来的新 leader)认为旧 leader 的任期是 [T_r1, T_r1+expired_interval_ms)
新 leader 认为自己的任期是 [T_w2, T_w2+expired_interval_ms)
即 leader 总是认为自己的任期开始时间是从自己最近一次写入 FDB 成功的写入开始时间(竞选或续任发起开始时间),而其他 follower 认为这个 leader 的这一任任期开始时间是自己第一次读到这个任期 lease 的读取结束时间(得知 leader 胜选或续任成功时间)。
由于 T_w0 < T_r1,所以 T_w0+expired_interval_ms 即:两任 leader 的任期在 2 个 leader 的视角下都没有交叠。 方案安全性分析 现在我们考虑在包含时钟走时误差(不是时刻误差)情况下,在最极端的场景下上述方案的安全性。 我们假设 follower 在认为上一任 leader 任期结束之后立即开始竞选,则有 T_r1+expired_interval_ms==T_w2,此时新的任期开始时间为 T_w2,旧的任期结束时间为 T_w0+expired_interval_ms。在没有时钟误差的情况下 现在分析时钟误差是否会超过这个差值,以及安全门限: 即如果 follower 和 leader 的时钟在 expired_interval_ms 时间内的走时差异小于 T_r1-T_w0,那么不会发生上一任 leader 认为自己还在任的时候,follower 就已经开始尝试竞选的问题; 如果 follower 和 leader 的时钟在 expired_interval_ms 时间内的走时差异小于 (T_r1-T_w0)+(T_w3-T_w2),那么不会发生 2 任 leader 所在的业务各自认定自己的服务任期 实际有相互交叠的问题:这是因为业务感知到的任期开始需要等待 FDB 写入完成,新 leader 的实际上任时间需要从 T_w3 而不是 T_w2 开始计算(T_w2 仅用于计算超时时刻)。 通常我们配置的任期<10s,而 2 次读和 CAS 写 fdb 带来的读写保守估计耗时>1ms。而按极端场景的估计,现代电子计算机晶振在高温情况下工作 1s 内时钟漂变<50us,预期 10s 内连续偏差<500us。考虑到写入就差不多同时发生了读取也是很罕见的情况,我们的参数配置属于比较安全的范畴,但不建议设置大于 10s 的任期。 实际实现 在上面的流程中,可以看到是不需要在节点之间同步实际的绝对物理时刻的,那为什么选择在数据结构中存储 lease.last_refresh_time 这个任期开始的本地物理时刻,而不是如同 Raft 那样只需写入一个自增的逻辑时间戳? 这是因为 leader 有可能发生重启,我们希望它重启之后,能够基于这个物理时间判定自己还在 leader 任期之内,快速恢复工作。 follower 竞选时写入的内容可能返回超时,但实际最终写入成功了。如果该 follower 在定期查看 key 的备选过程中能够看到自己已经竞选成功了,并且这个物理时间判定自己还在 leader 任期之内,那也能快速切换为 leader 工作。 所以写入的这个物理时间不是为了分布式同步,而是 leader 自己为了提升 recovery 速度,而持久化自己的状态。 和 Raft 等分布式同步方案相比,本文介绍的方案有一个细微但重要的区别:不仅可以随意的增删节点,而且还可以随意的修改和配置任期!换而言之,集群的配置、管理类的元信息可以安全和简易的变更。 传统的 Raft 之所以不能随意的直接修改心跳周期、leader 任期等时间参数,是因为升级修改这些参数的时候,集群内不同节点会持有不一致的参数值,而 leader 选举等共识构建流程的安全性是和这些参数的一致性有关系的(考虑到一些工程实现的取舍,那更是如此)。所以安全的工程实践往往不支持热升级修改这些参数,而需要停止所有节点来更新这些参数。 而在本文的方案中,当 leader 把心跳周期 lease.refresh_interval_ms,任期 lease.expired_interval_ms 写入共享存储 key 之后,下一任 leader 尝试竞选时必须按照这个参数来进行竞选,即使它本地的配置参数和共享存储不一样;下一任 leader 胜选之后,它自然也就把自己的配置参数覆盖写入共享存储,它自己和其他 follower 都按照新发布的配置参数来决定自己的任期和未来的重新选主时间点。 简而言之:每一任 leader 胜选后都自动发布自己配置中的新选举参数到共享存储中,下一任 leader 的选举一定所有节点都能看见并遵守(否则 CAS 会失败)。所以滚动升级过程中,即使不同节点的有不同的本地配置并参与竞选,也不会带来不一致问题。 上面我们已经介绍完了服务副本之间的分布式共识建立,涵盖 follower 之间竞选的冲突、新任和上任 leader 交接的冲突、选举参数变更等共识问题的解决。我们最后介绍客户端如何感知服务端的 leader 选举结果变更。 客户端访问 leader 的逻辑很简单: 读取 K 中 address 的结果,如果 key 存在且 address.status==Ready, 无限期缓存并访问其中的地址。 如果 leader 的响应返回自己不是 leader,那么删除缓存后重试 1。 我们可以看到客户端无需访问 lease 中的时间信息,从而无需感知副本之间的时间共识,也不需要本地时钟和服务端进行任何同步。 介绍到这里,我们可以看到一个新 leader 的产生,是如何是如何在 follower 之间竞争产生分布式共识,并和旧任 leader 以及未来可能出现的新 leader 对这个共识的有效期的安全性产生共识,再让客户端感知到这个共识的全过程。 ByConity 可以把上面的选主方案使用在使用 leader 节点工作的服务,例如 Resource manager/Timestamp oracle 等。这套方案允许启动后的节点副本无需配置客户端对服务端的服务发现地址,也无需配置 ClickHouse-keeper 中副本之间的相互服务发现以及设置静态的副本数量:增加的副本只要能启动即能被客户端发现,并自动参与选主竞争。 如果使用 K8s 部署 ByConity 集群,只需要调整 replicas 属性就能简单的增减服务 Pod 副本。 本文介绍了一套基于共享存储和 CAS 操作进行 leader 选举的通用方案,充分利用了高可用共享存储的能力,使得 leader 选举运维和配置简单,让 ByConity 开源用户能更轻松的用上高可用服务能力。该方案可以简单的推广到任意的无状态服务的选主场景。 ByConity 也借此去除了对 ClickHouse-keeper 的依赖,在支持多副本高可用的同时大大简化了配置,也提升了在 2 节点等低成本场景的容灾能力,并且使得服务无论单节点和多节点副本部署 在运行逻辑上进行了统一,降低代码复杂度。T_w0+expired_interval_ms<T_w2
T_w2-(T_w0+expired_interval_ms)==T_r1-T_w0>0服务端节点的选举参数共识:发布选举参数改变
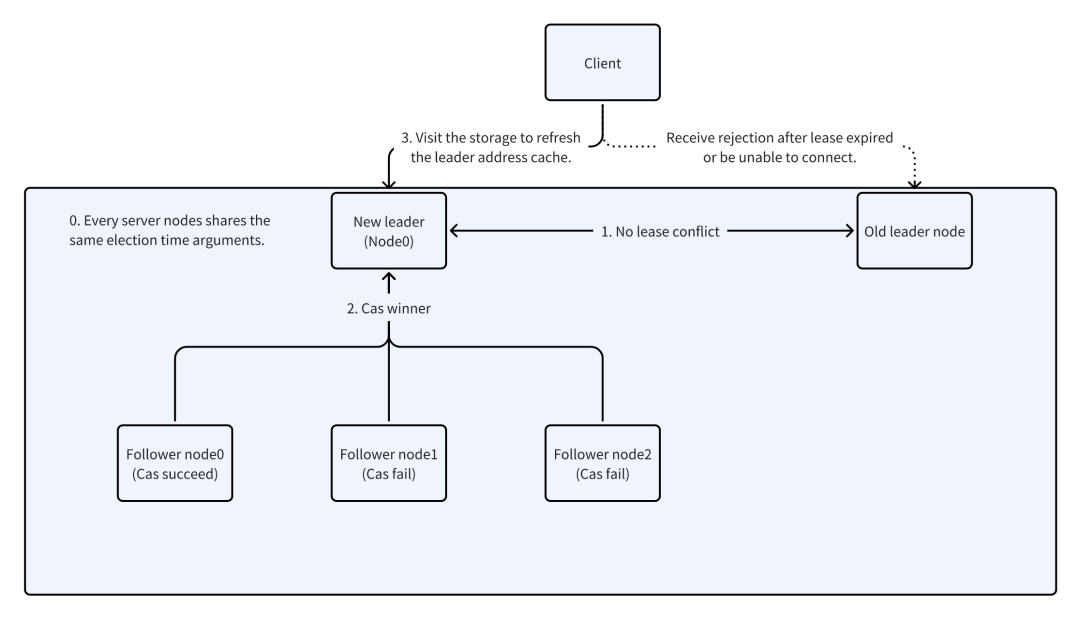
客户端和服务端的共识:“谁是 leader”的服务发现
总结
ByConity 的使用
总结




