

首先讲一下爱奇艺大数据平台业务背景,目前日均 DAU 接近三亿,爱奇艺在业务初期主要关注于长视频,随后发展业务有 PPC、UPC,同时还发展了游戏、直播、小说等业务。目前业务线达到 20 多条,存量的设备信息达到 30 亿,每天处理的用户行为日志超过 300T。这种业务数据量对数据运维、开发人员提出了很高的要求。
1. 起始时代
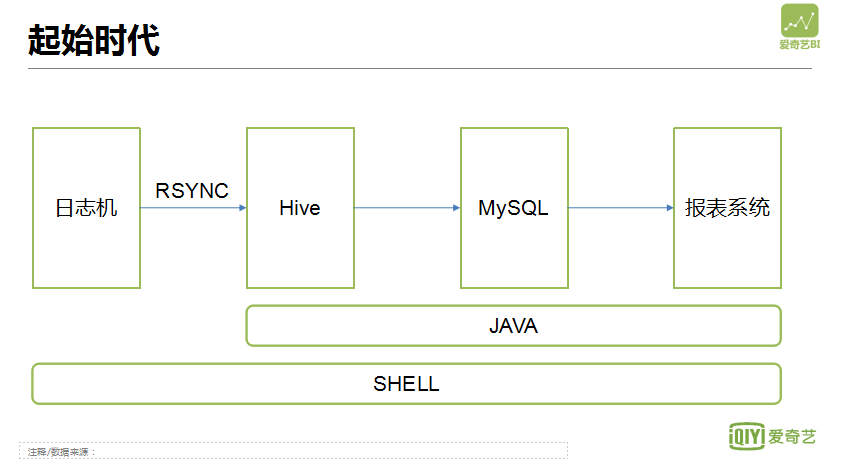
爱奇艺刚刚起步时平台架构很简单,数据流从日志通过 RSYNC 流入到 Hive,然后通过脚驱动 Hive SQL 语句统计分析,结果导入到 MySQL,最后形成报表展示。整个流程的驱动基于 Shell 脚本完成,报表系统和数据处理是利用 Java 实现。然后进入第二阶段,原先所有业务需求都是手工处理,所有报表都要写 Java 代码开发,这个给开发人员造成了很大的工作量,并且用户获取数据周期长,速度慢。
2. 魔镜时代
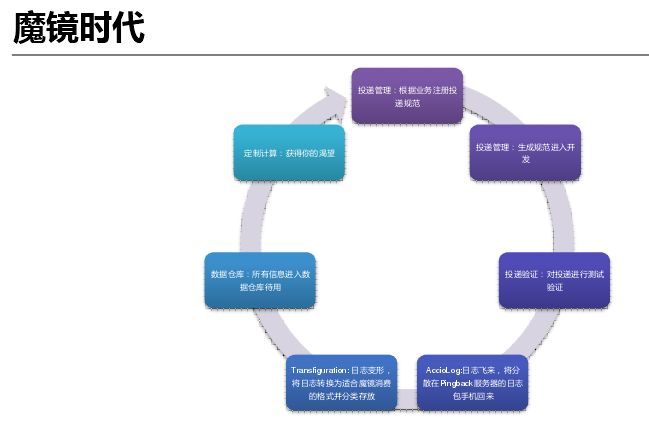
因此开发了一个魔镜系统。在魔镜系统中进行投递管理、投递验证,通过自研的日志收集器 Accio Log 将日志从 Pingback 服务器上传到 HDFS;再通过 Transfiguration 解析框架做日志格式转化和分拆入库。然后分析人员可以再魔镜系统上通过配置进行自助取数,不再需要等待开发排期
但是随着业务不断发展,数据需求不断增多,很快遇到了新的问题。开发魔镜系统是由于需求较多开发人员处理不过来,现在是取数计算太多,Hadoop 集群处理不过来。因为在魔镜系统中消费的大多都是日志数据,数据量非常大,任务又多,导致集群计算压力非常大。而且数据开发人员仍然是主要进行脚本开发,调度方式也不成体系。所以我们基于魔镜系统的思路进行进一步设计,研发了大数据平台“通天塔”系统。
3. 通天塔时代
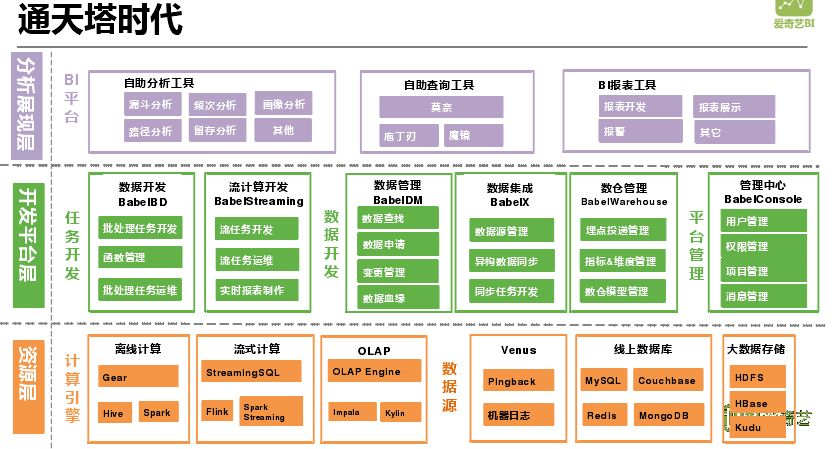
通天塔集合了整个爱奇艺技术部门所有数据、所有计算资源和服务框架,重新构建形成一个大数据平台框架。底层是大数据平台所用的计算资源,离线计算主要是 Hive、Spark,流式计算主要是 Spark Streaming 和 Flink;OLAP 主要是 Impala 和 Kylin。数据方面 Pingback 是用户行为日志,机器日志就是程序产生的相关日志。线上数据库主要是 MySQL、MongoDB 等,大数据存储主要是 HDFS、HBase、Kudu,Kudu 主要是支持实时,分布式存储主要是 HBase、HDFS。再往上层是开发平台层,主要负责工作流开发。流计算通过专门的开发工具进行管理,就是将任务开发进行重新构建。数据开发针对于系统数据进行血缘管理,提供数据集成管理,实现数据在不同集群、引擎间的同步。如机房中有很多机器分成 3-4 个集群,相互之间要进行数据同步,先前主要是手写程序完成,现在可以通过数据集成来进行跨 DC 的数据同步。数仓管理主要是埋点投递管理、指标维度管理、数仓模型管理。最上层就是直接面向用户的分析报表平台,自助分析工具有漏斗分析、画像分析、路径分析,还有自助查询工具、BI 报表工具,接下来会详细讲解。
4. 工作流管理与开发方式的演变
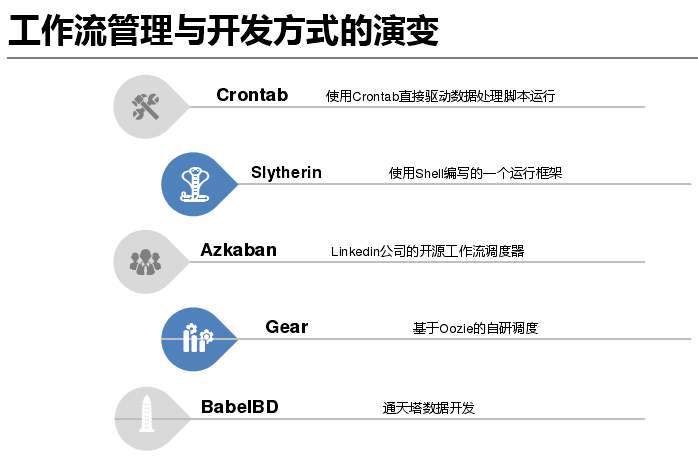
接下来讲一下工作流管理与开发方式的演变,刚开始的时候在这方面投入量不是很大,使用 Crontab 直接驱动数据处理脚本运行。随着任务量逐渐增多,crontab 会变得不可维护,就利用 Shell 写了一个框架,可以自动批量维护很多计算。随着业务发展又无法满足需求,引入 Linkedin 公司的开源工作流调度器 Azkaban。由于当时 Azkaban 只能单机,可维护性也不是很高,自研发了一个工作流管理系统 Gear,但是 Gear 的管理基于配置文件,开发调试起来麻烦又自研了通天塔数据开发 Babel BD。
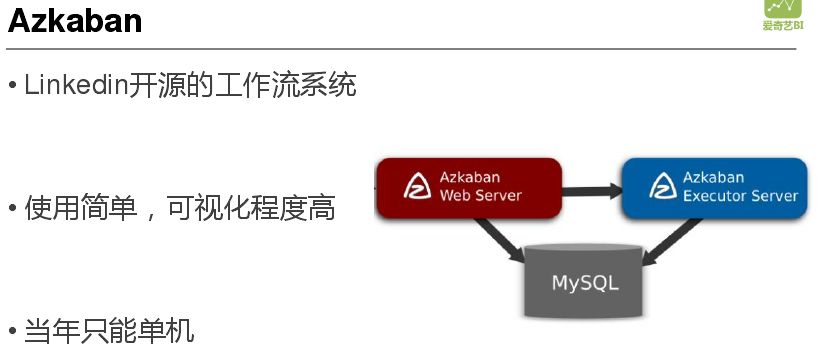
Slytherin 完全是一个 Shell 脚本,有一个驱动脚本和一个执行脚本。驱动脚本主要是调动执行脚本运行,并关注其运行生命周期,感知整个并发量,避免对集群造成过大的压力。执行脚本保证自己的唯一性,处理完成后打好标志文件,保证唯一性的方式就是记录自己的 process ID 作为 ID 锁,如果检测自己有 ID 锁存在,就不再重复执行。随着后续发展发现其可视化程度不高,维护成本大,于是引入了 Azkaban,其优点是使用简单、开源、可视化程度很高,缺点是当年只能单机,在使用 Azkaban 时爱奇艺集群有 3-4 个,涉及的集群机器有上百台,每个集群都会有很多台入口 Client 机器,只能一台机器一台机器去维护,整体大局性控制不高。

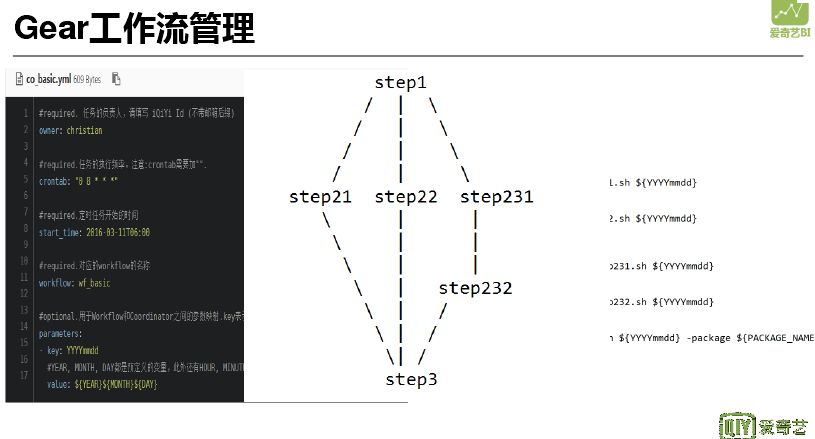
基于上述缺点,云服务部门的同事着手开发 Gear 工作流管理。 这是一个基于 appache 的 Oozie 在上层进行二次开发的工具,没有直接使用 Oozie 是由于其配置过于繁琐,可视化不是很好。因此在 Oozie 基础上进行配置简化,并且提供更友好的界面和开发方式,主要是使用 GitLab-CI 和 SDK 的方式提交。上图是一个并行的工作流,配置文件通过 GitLab 提交,Gitlab-CI 会自动提交发布,然后实例化,同时会调用相应的 API 将计算过程进行监控。
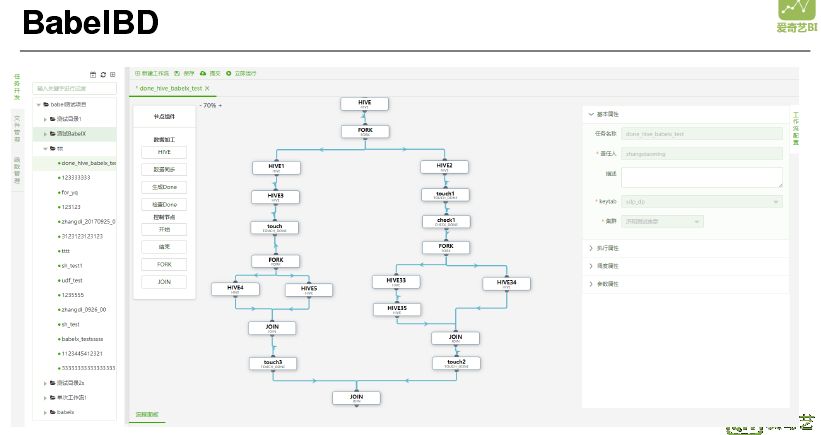
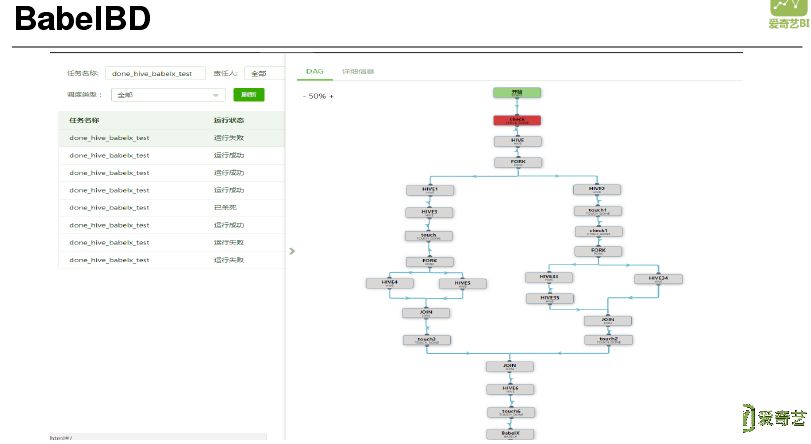
在开发过程中还是感觉配置 Gear 过程比较复杂,配置文件编写容易出错,平均需要提交三次调试三次才能成功执行。因此在通天塔系统中进行进一步封装,形成 BabelBD 开发 IDE。BabelBD 可以直接拖拽节点的方式开发工作流,这样开发人员只需要关注核心 SQL 语句编写和整个基础流程,其他都交给 IDE 完成,上图是实际开发效果和执行效果。
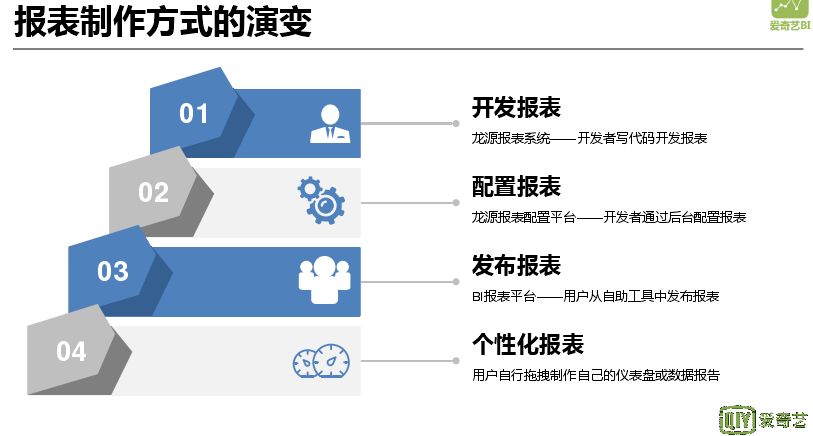
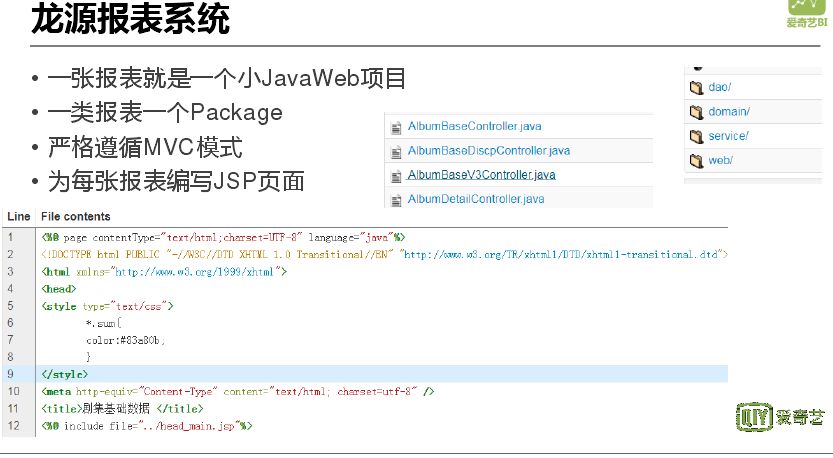
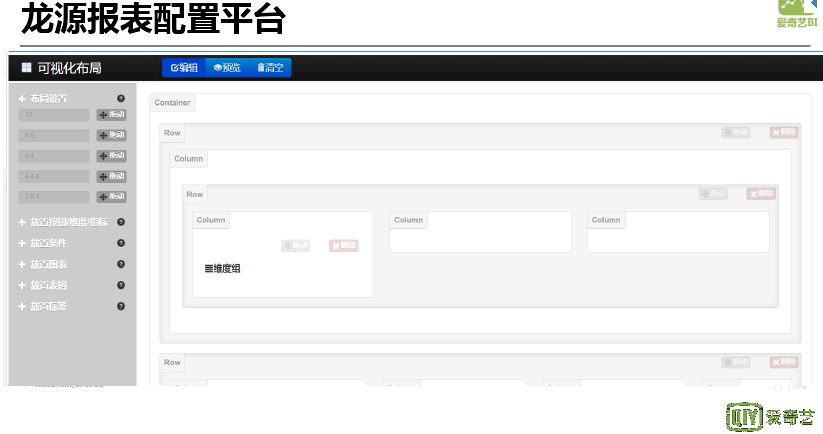
报表制作最开始是开发人员写代码开发报表,后来是配置系统去配置报表,然后是让用户从自助系统和工具去自助发布报表,最后是生成一些个性化报告。最开始的报表系统是龙源报表系统,就是一个报表系统,几乎没有管理后台,仅有用户权限管理。其架构是最基础的 MVC 模式,开发的每一张报表都是一个小的 JavaWeb 项目。需要为每一张报表编写 JSP 页面,随着业务量增加,开发人员任务加重,因此将报表配置抽象化。形成一个报表配置平台-龙源 2.0,配置流程最核心的就是写 SQL,定义相关图表信息、条件信息,将其配置成一张报表。最后利用 bootstrap 的一个可视化配置管理工具,通过拖拽方式搭建报表。由于业务线发展,爱奇艺发展成为一个多元平台,各种业务层出不穷,先前一体化的报表模式不能满足需求,大 BI 系统应运而生。
5. 爱奇艺 BI
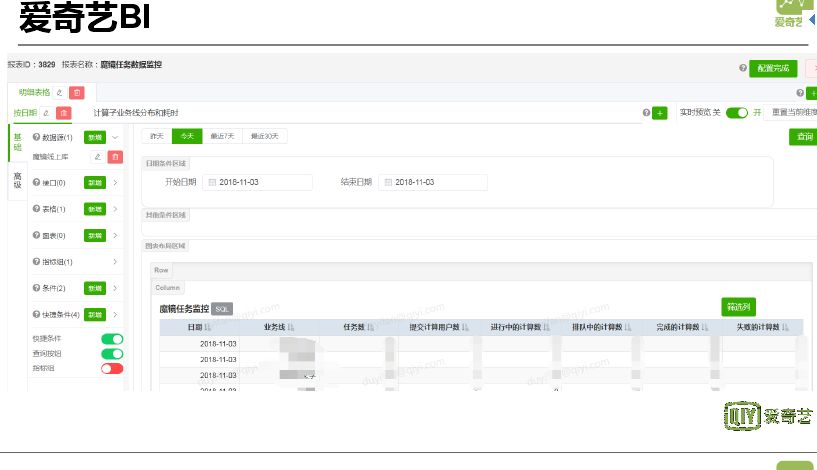
爱奇艺 BI 平台是一个很大的平台系统,报表只是其中的一部分,最核心的部分就是对不同业务线进行拆分。在前期的基础上,配置方式进一步抽象,思路也进行了变更。之前从 SQL 语句开始配置是基于开发的思路,现在是从报表构建的思路去配置,先配置报表的雏形,然后详细配置报表的各个组件,这种方式更加符合数据分析者的思路。
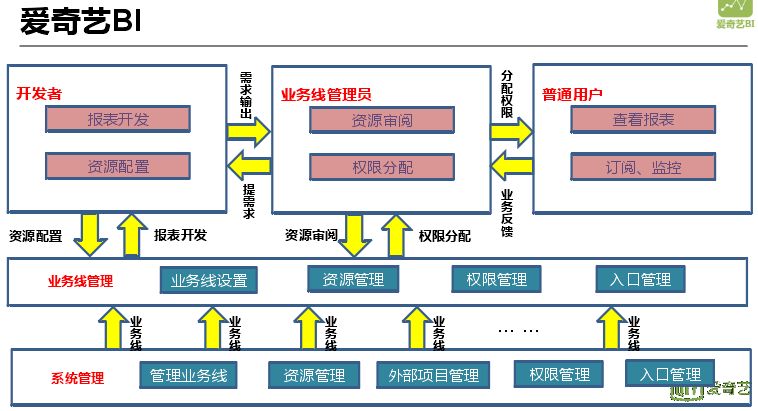
爱奇艺 BI 核心不在报表开发,核心在于业务线划分以及权限的划分。数据安全越来越重要,在业务线和权限方面做了很多工作。除了开发人员开发报表外,还可以让用户通过一些自助分析的系统发布自己的报表到 BI 进行展示。
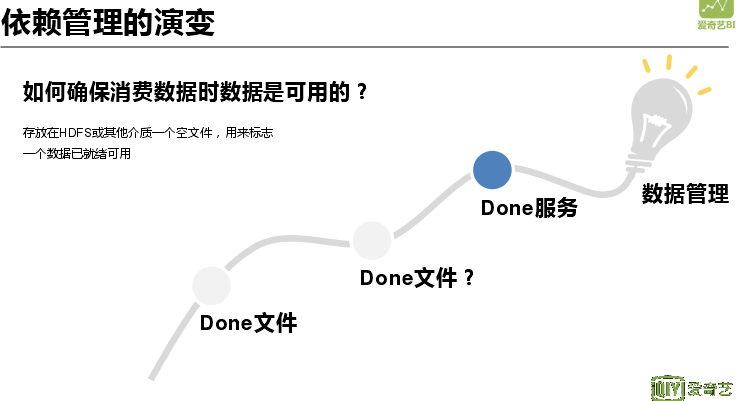
在消费数据时有个很重要的一点就是要保证数据是可用的,有时我们会去猜测数据在某一时刻是完整的,但是如果某一集群发生延迟,就会消费掉一个空数据。因此设置了 Done 文件机制。将 Done 文件放到 HDFS 上,每生成一个表都有相应的 Done 文件,每当消费某张数据表都会先检测其 Done 文件是否存在。HDFS 很怕小文件,但是每个表每天都会有若干 done 文件产生,而且表非常多,就会有海量空文件产生。所以为了避免 HDFS 压力过大,我们就制作了 Done 服务,这样直接在做依赖判断的时候,直接使用 Done 服务,不再在 HDFS 上查找,依赖管理最终采用的方案是数据管理。
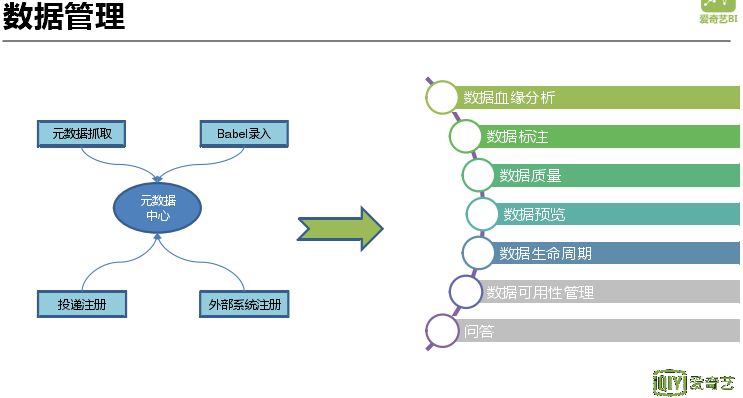
数据管理会将数据的整个生命周期管理起来,对数据进行可用性管理并提供服务给其他业务调用,用来替代 Done 服务。它通过元数据抓取、手动录入、投递注册管理、外部系统注册管理,通过数据血缘分析、数据标注、数据生命周期分析等对各种元数据进行系统性管理。
接下来讲一下我们的数据仓库演变,最开始的时候我们的分析统计都是直接消费日志表,所有报表结果都是从日志表中计算产生,产生的结果是造成资源浪费,并且定义不清楚,缺乏周知性。接着就针对视频播放设计了播放数仓模型,制作了中间大宽表,方便使用。但是对于有些简单表或者其他一些条件不适用,目前采用分层建模的方式。

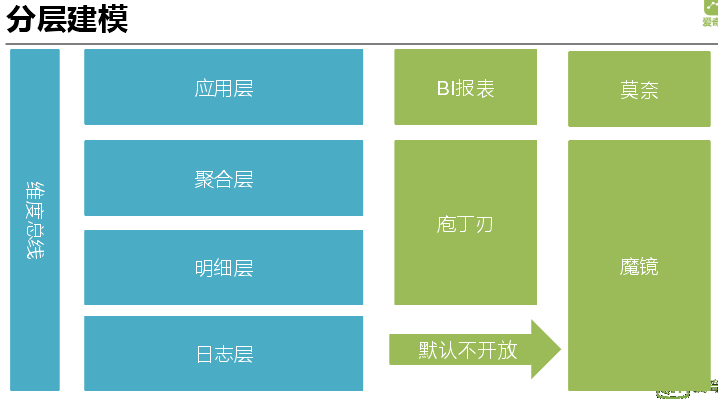
直接消费日志表优点是最底层、简单,数据原始,无任何聚合处理,可以探查细节,缺点就是数据量大,消耗计算资源大,未进行反刷量。中间大宽表就是按照一定的主题进行聚合,尽量使用最全面的字段尽量方便使用;同时也进行了反刷量过滤,只有少量数据会用到日志,大宽表有个缺点就是数据量不适合在 Impala 等 OLAP 引擎使用。分层建模有日志层、明细层、聚合层、应用层,不同主题都在聚合层,根据不同的应用场景会上升到应用层构建。明细层和日志层利用魔镜和 SQL 语句进行管理查询,应用层针对 BI 报表和莫奈系统,日志层默认不开放,业务简单时会开放查询。
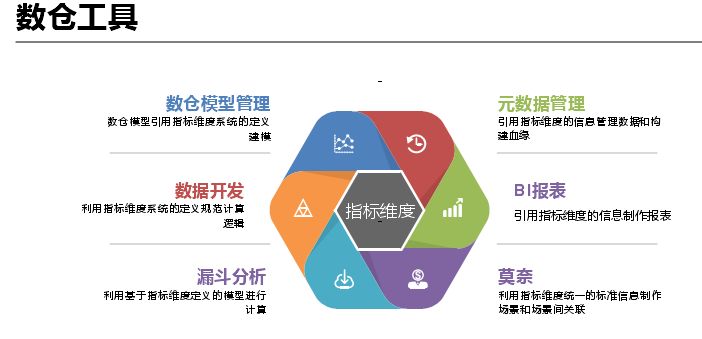
基于上述需求使用了一些数仓工具,主要负责数仓模型管理,其核心是指标维度管理,基于指标维度进行数据开发,然后进行一些分析,尤其是莫奈系统中利用指标维度统一的标准信息制作场景和场景间关联,在 BI 报表直接引用指标维度信息制作报表。
OLAP 在数仓的上一层,最开始只使用 MySQL,通过分库分表来解决大数据量问题;之后就借助 MySQL+HBase,将一部分数据提前计算好存入 HBase,根据不同的查询进行提取。接着就引入 Kylin/Impala 作为查询引擎,目前考虑的是不同框架综合使用,不局限于一个查询,根据分析目标数据源不同,智能选择不同的引擎。

一个典型的例子就是剧集统计,爱奇艺有海量视频数据,刚开始是几十万,现在是一亿+的视频资源。原先按可加项不可加项分表,分表维度也有很多(来源、提供商),随着视频量增加这种方式无法满足需求,查询速度很慢。接着采用冷热数据分表,保证日常最常用数据的查询速度,数据按天、月、年进行分表。后来考虑将一部分数据存入 HBase 中,每天会进行播放数据排行计算,最难的也是计算排行,将不同组合的排行数据预先组合计算存入 HBase 中。接着将所有数据都存入 HBase 中,这种思想就是 Kylin 思想,将不同维度组合提前算好存入 HBase,这样就可以提供给自助查询系统使用。
6. 魔镜与庖丁刃

前面主要讲报表,接下来讲一下分析人员和运维人员取数分析方式的变化。最开始是运营人员提出数据需求,首先看报表是否满足,满足直接查报表,不满足作为临时报表让开发人员完成报表取数。这种方式工作量大、周期长,后来用户通过魔镜看结果或者运行 SQL,如果魔镜不满足再去看报表或者开发。目前和未来思想就是先看报表是不是满足,不满足提供专门的分析工具,如漏斗分析、画像分析去定制化分析需求,再不满足通过 OLAP 分析进行拖拽式分析,或者通过魔镜去写 SQL,生成结果后看是否满足,是否需要进一步分析,如果需要就回到 OLAP 系统进行分析。
整体的思路是最开始靠人工,分析师通过人工导数、Excel 分析等工具进行分析。后来发展为主要依据魔镜进行报表导数,后续分析主要还是 Excel 等其他分析工具。现在是将用户往莫奈分析系统上引导,后续是希望去掉像 Excel 等其他分析工具,所有分析都在莫奈系统中完成。魔镜是通过勾选配置的方式写 SQL 达到取数的目的,通过定义指标、选取维度、定义详细的条件、排序方式,通过勾选方式生成 SQL,最后落在 SQL 执行的引擎上。庖丁刃就是提供给用户一个 SQL 编辑的工具,同时还提供一些数据源的管理。魔镜和庖丁刃是一个相相成的工具,庖丁刃的 SQL 不一定能转化为魔镜的定制计算,但是魔镜的定制计算一定能转化为庖丁刃的 SQL。
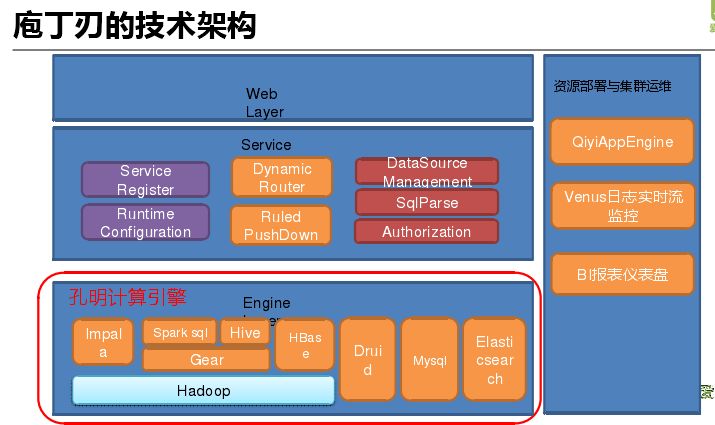
庖丁刃的技术架构,上层网页层是 SQL 编辑器以及魔镜定制计算的界面。服务器会根据不同的数据源路由到不同的执行引擎上执行,同时会进行权限的验证。最下层是实际 SQL 执行引擎,可以依据不同数据特点智能选择不同的引擎,并且根据执行情况进行智能下沉。如 Impala 满足不了会直接下沉到 Spark,分为两种一种是 Impala 没有数据,另一种是 Impala 执行失败。整个架构构建在企业云计算架构上,全部微服务化,这样易于监控和维护不容易挂掉。
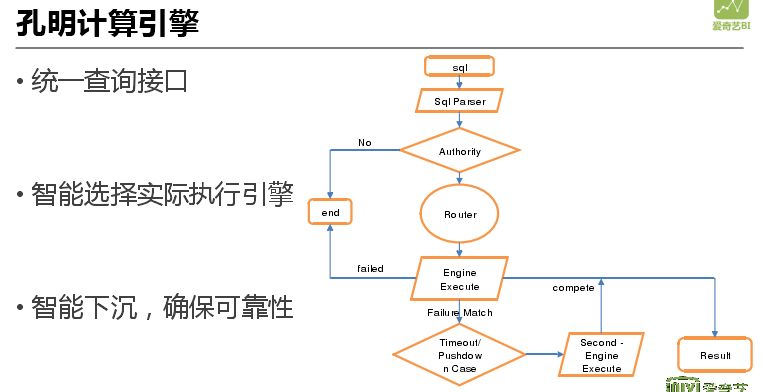
孔明计算引擎是提供数据查询的统一接口,实施智能选择执行引擎的一个工具。在执行的时候实现智能下沉,确保计算的可靠性。在 SQL 解析开始后进行权限验证,依据 SQL 解析后数据源的结果进行引擎路由。目前如果不同数据源数据存在关联会出现报错,未来会开发底层触发自动同步维护。
7. 莫奈系统
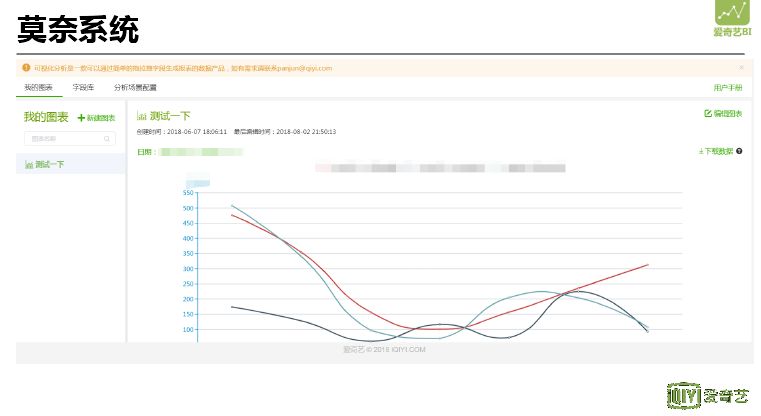
莫奈系统目标是只需鼠标如作画般划过屏幕,即可进行大数据分析,将抽象数据变成画作。上图是莫奈系统界面,给出的是事先制作好的报表进行的展示,可以直接将其发布到 BI 系统。将相应维度拖到工作区,支持不同行列的维度;同时还支持不同的图形可视化方式;支持下载 Excel 数据,后续将其去掉采用生成报告的方式。后台是场景分析配置,每一个场景是根据数仓应用层进行的进一步抽象,将维度和指标全部抽象成场景配置到系统中去。
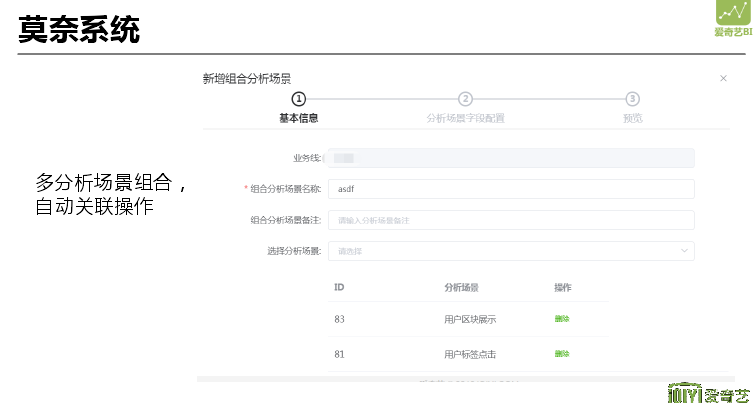
在普通场景基础上支持多分析场景的自动组合,将已经定义好的场景合并到一起,同样的字段进行合并形成一个新的大场景。组合场景会根据用户的勾选和当前场景维护情况自动生成查询,并判断当前条件维度选择是否满足需求。
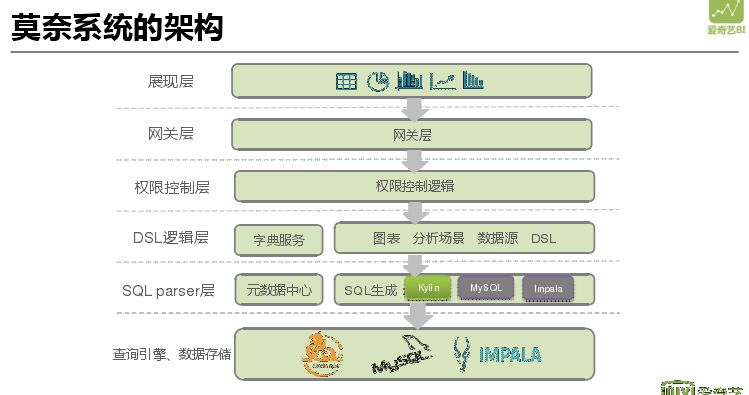
莫奈系统架构,最上层的展现层是基于定义去开发的前后端系统,网关层网关相关配置,接下来的权限控制、DSL 逻辑、SQL 层等都是微服务。最底层的查询引擎用的最多就是 Kylin,MySQL 和 IMPALA 在系统中也可用,实现 MySQL 和 Kylin 并行使用。如果用户需要对 BI 报表进行进一步分析,可以将报表数据直接拉到莫奈系统中进行进一步分析,当数据量过大时可以将 MySQL 下沉到 IMPALA 中执行。
8. 爱奇艺大数据分析体系
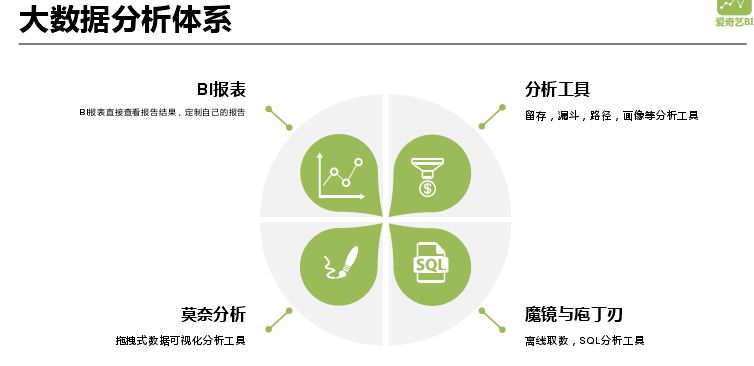
上图中的任务构成爱奇艺大数据分析体系,上层是 BI 报表、莫奈分析、魔镜与庖丁刃、分析工具。
BI 报表:BI 报表直接查看报告结果,定制自己的报告;
莫奈分析:拖拽式数据可视化分析工具;
魔镜与庖丁刃:离线取数,SQL 分析工具;
分析工具:留存,漏斗,路径,画像等分析工具。
作者介绍
杜益凡,爱奇艺****商业智能部高级技术经理,毕业于南京大学,2010 年加入爱奇艺,专注于大数据相关技术,负责爱奇艺大数据处理平台和大数据分析产品方面的研发,对 Hadoop 及其相关生态工具有深入的研究和丰富的应用实践经验。
本文来自杜益凡在 DataFun 社区的演讲,由 DataFun 编辑整理。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论