

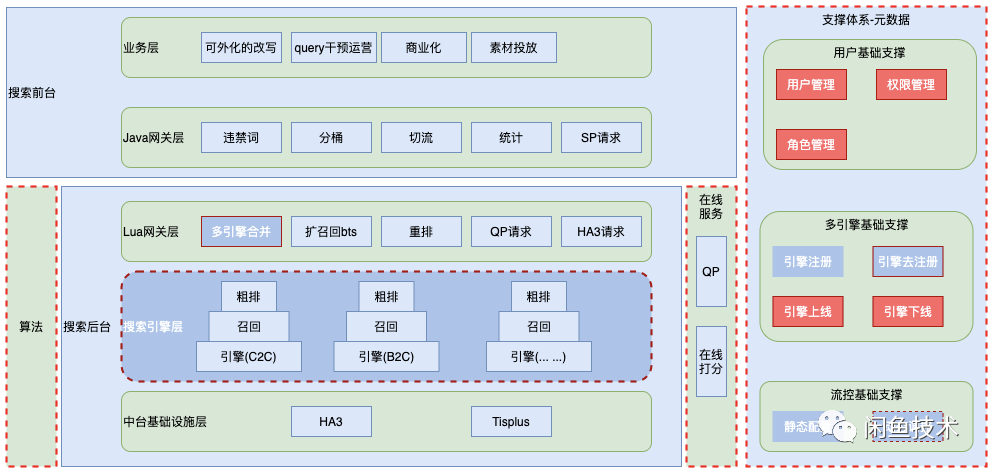
问题及现状
闲鱼搜索很多场景基于集团搜索中台能力,纵观闲鱼搜索链路,存在多角色(工程、算法工程、算法等)、多业务(闲鱼无忧购、租房、帖子等)、多节点(离线数据源聚合、在线召回、URF Rank 等),具有明显的复杂性。并且闲鱼主搜仅存在一条链路支持搜索多业务发展,各角色、各业务、各节点处于高耦合串行迭代模式。在大数据量、多业务、多角色并行场景下,以下问题日益明显:
1、迭代效率低、排期长,无法满足新业务快速迭代诉求:主要体现在数据量大,单次迭代周期长,以及多业务、多角色串行操作,耦合严重;
2、风险高:不同业务、不同特性均在主引擎召回链路执行修改,侵入大,风险高;
3、干预能力弱,业务间混排能力不足:缺少干预扶持能力,无法有效为创新业务提供定制化孵化能力。
闲鱼一次请求完整流程如下:
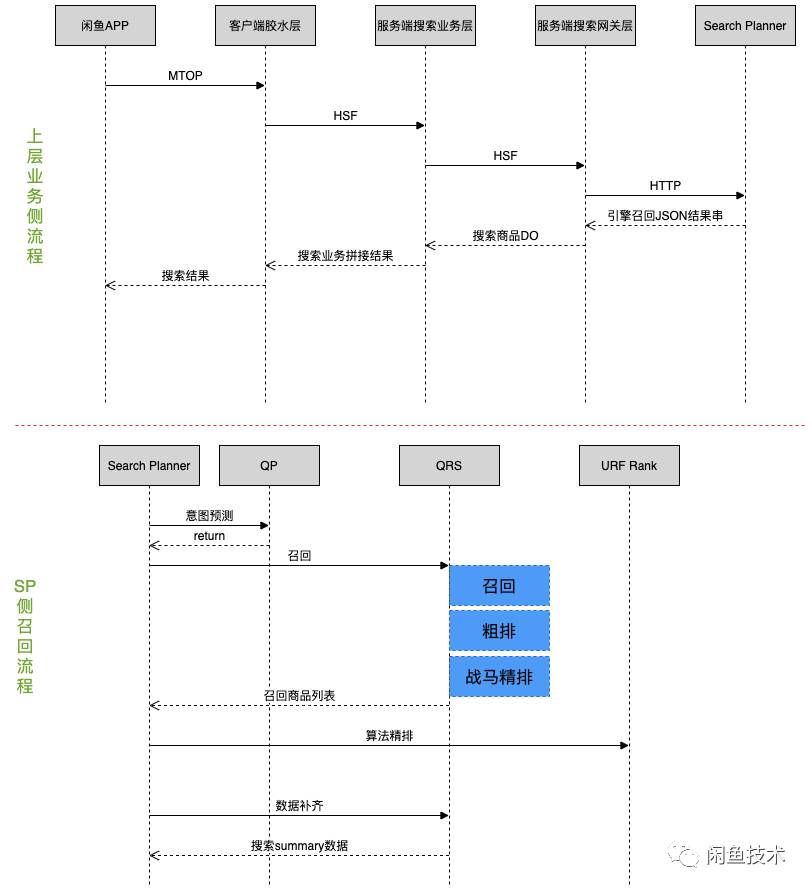
注:QP,即 Query Planner,主要用于预测用户 query 搜索意图。
SP 在测试环节下调用拓扑示例如下:
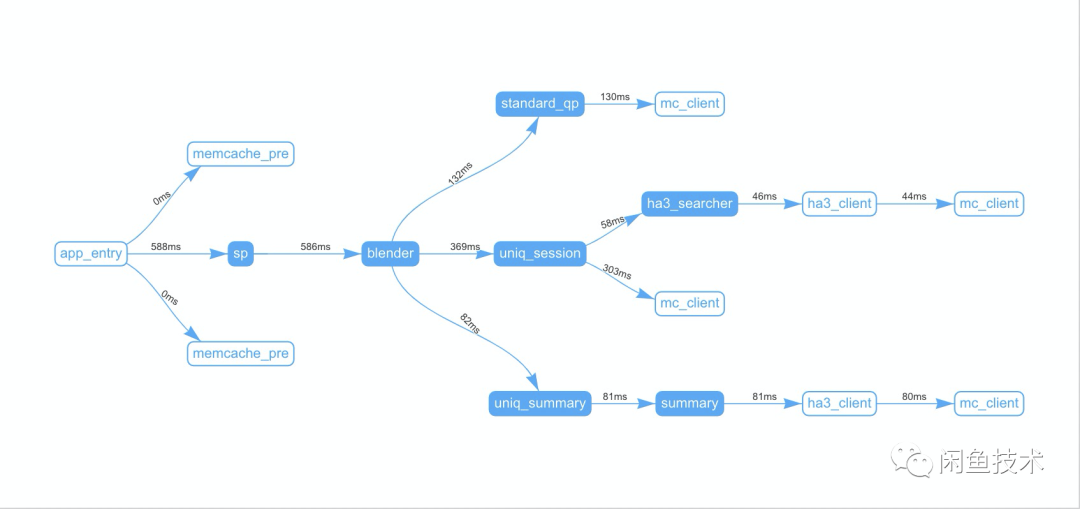
关键节点:
blender 是 SP 服务核心入口,主要职责包括解析用户 query 意图、引擎分页召回、搜索数据补齐等功能。
uniq_session 是召回核心入口,通过引擎召回、分页处理、URF Rank 等操作,获取最终商品列表
ha3_searcher 是引擎召回入口,翻译用户 query 为 HA3 引擎查询 query,请求引擎在线服务,召回满足条件商品信息 。
uniq_summary 是商品信息补充入口,依据商品 id 列表,补齐商品详细信息并返回,最终在搜索结果页呈现给用户。
背景概述
闲鱼搜索很多场景基于集团搜索中台能力,搜索引擎分为数据源聚合(离线 dump)、全量/增量/实时索引构建及在线服务等部分,通过集团内部一系列处理阶段,对客户提供高可用高性能的搜索服务。服务架构如下:
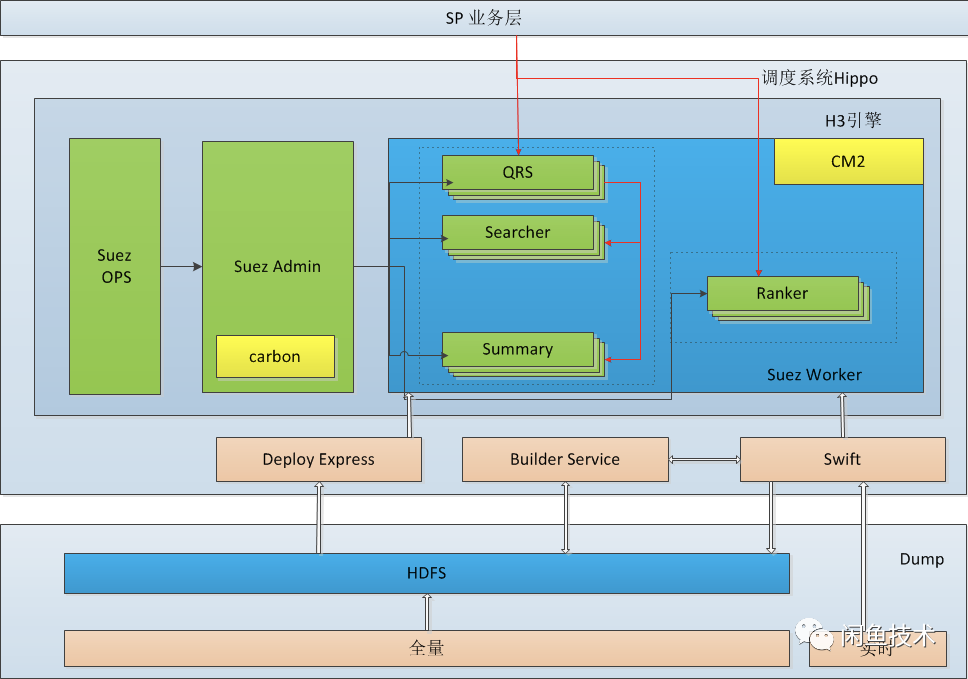
其中:
SP/SPL 是集团内一套构建于 Wunder 上的开发工具,提供开发测试打包上线的视图界面以及一套业务函数库。HA3 是一套基于 suez 框架的全文检索引擎,提供丰富的在线查询子句,过滤子句,排序子句,聚合子句且支持用户自定义开发排序插件。
Qrs 用于接收用户查询,将用户查询分发给 Searcher,收集 Searcher 返回的结果作整合,最终返回给用户。Searcher 是搜索查询的执行者,主要包括倒排索引召回、统计、条件过滤、文档打分及排序及摘要生成。在实际的部署中,Qrs 和 Searcher 都是采用多行部署的方式,可以根据业务的流量变化作调整。Searcher 还可以根据业务的数据量调整列数,解决单机内存或磁盘放不下所有数据的问题。
剖开 HA3 引擎,我们可以粗略看下引擎侧索引的构建以及在线召回链路:
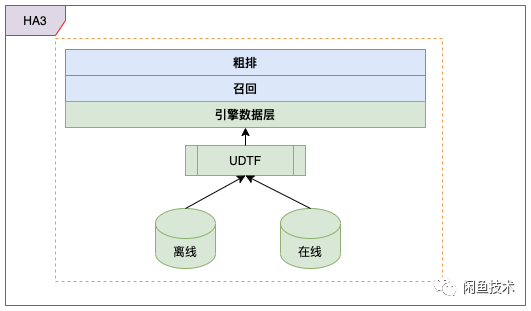
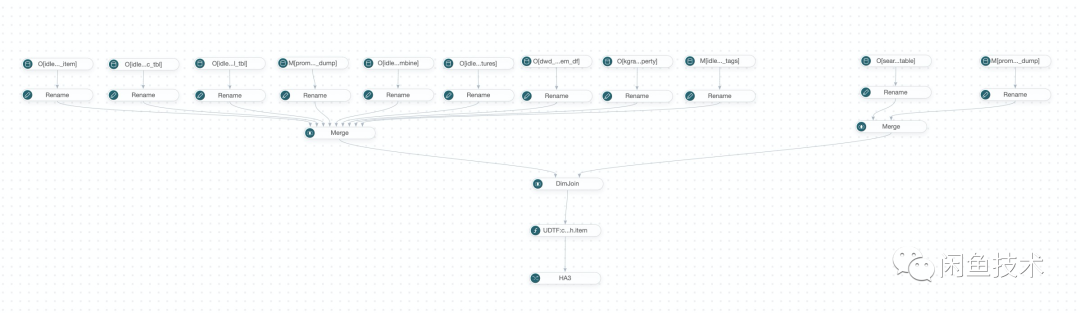
蓝色部分表示 HA3 在线服务,提供在线召回商品服务;绿色部分表示引擎数据源聚合(离线 dump)逻辑,将商品信息构建成对应的引擎数据源。下图为一个离线引擎 dump 的数据源图示例:
设计思路
由于我们要解决的问题是如何安全、灵活、高效地支撑多业务接入闲鱼搜索,并提供不同业务间混排能力,我们的设计想法如下:
1、支持业务间互相隔离,从引擎侧深层次隔离,提高整体迭代效率
2、支持多引擎并发召回能力,解决搜索 RT 恶化问题
3、支持多引擎召回结果合并能力,并统一传递给 URF Rank 执行混排
4、支持实时干预能力,满足不同业务孵化诉求
调研集团内部已有实现模式,并结合闲鱼搜索业务发展诉求,我们重新设计并执行闲鱼底层引擎召回逻辑升级流程,从单引擎单路召回架构升级为多引擎多路并发召回架构。
Search Planner 及搜索引擎层升级如下图所示:
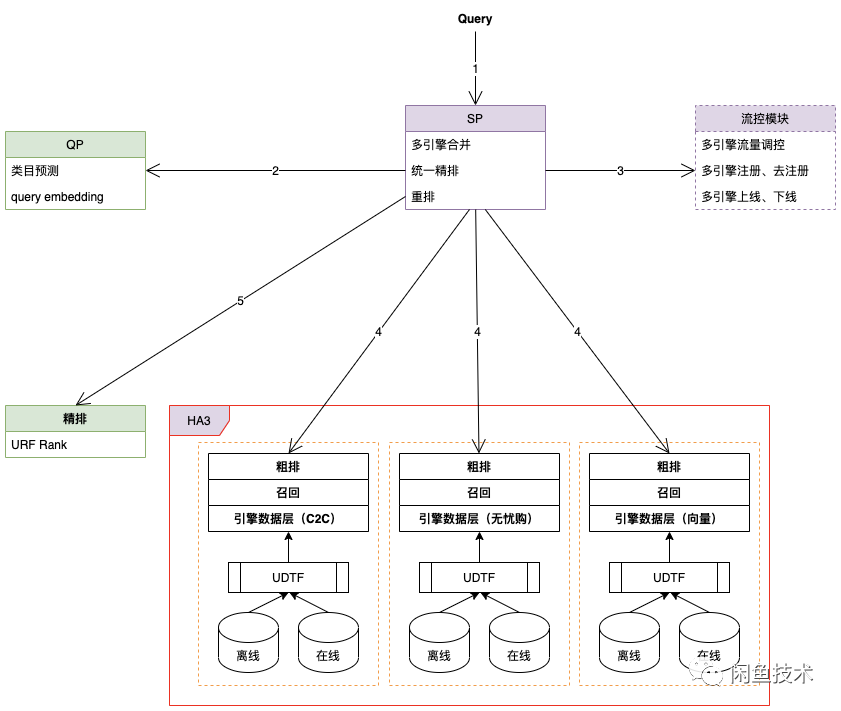
主要升级节点如下:
1、步骤 1 中解析用户 query,获取多引擎标识,解析并缓存引擎配置信息
2、步骤 3 流控模块从配置中心获取引擎定制化配置,并执行 query 改写逻辑,生成对应的 HA3 请求串
3、步骤 4 依据 query 中携带的多引擎标识,并发请求不同引擎在线服务召回商品,并合并召回结果,统一调用步骤 5 的精排服务能力
4、步骤 5 算法侧升级支持多引擎结果,支持多业务混排能力
实现方案
依照上节的设计思路,实现方案核心主要关注以下几点:
1、如何解析用户 query,并缓存用户 query 相关引擎配置信息
每一个引擎均存在唯一的标识 id(便于说明:主搜引擎标识为 0,闲鱼无忧购引擎标识为 1,向量引擎标识为 2),上层搜索业务层依据不同业务场景组装引擎查询 query,包括组装引擎标识列表(比如 bizType=0,1,2,表示同时从主搜引擎、闲鱼无忧购引擎、向量引擎召回商品)。
Search Planner 核心解析逻辑如下:
2、流控模块如何获取引擎定制化配置,执行 query 改写逻辑
目前流控模块通过阿里巴巴集团内部广泛使用的 diamond 配置中心获取详细配置参数,并与引擎唯一标识绑定映射关系。Diamond 是淘宝内部广泛使用的配置中心,提供持久化管理和动态配置推送服务。采用推送服务,每次请求不再需要实时从远端获取配置,降低搜索 RT,提高搜索体验。同一环境下,Diamond 中通过唯一的 GroupId + DataId 标识参数配置。
query 改写逻辑封装在不同的函数组中,通过前置分支判断,调用函数组中不同改写入口,生成定制化 query。
3、如何并发执行多引擎召回、合并流程,预防搜索 RT 恶化
借助于 SPL 异步协程能力,通过一条 lambda 函数,实现并行调用,以解决搜索 RT 恶化问题。如:value = search_http("/qp?xxx"):value(),即表示一次异步并发调用操作。
通过多引擎隔离、query 改写手段,各业务间能有效地解耦,满足各业务定制化诉求,并且对闲鱼主搜服务能力干扰最小,将问题集中于单业务内;
通过集成 dianmond 配置中心的流控模块,达到实时干预 query 搜索能力,并有效孵化创新业务,如当前闲鱼无忧购创新业务;
通过多引擎并发召回及合并能力,一是解决搜索 RT 恶化问题,二是结合 URF Rank,有效控制不同业务间混排效果,并最终呈现给用户,以达到更好的用户体验。
以一个精简版用户 query 为例,传递给 sp 的 query 如下(查询关键字为“Zimmermann 裙”,从三个引擎(0、1、2)中召回结果):
对应可视化调用拓扑如下:
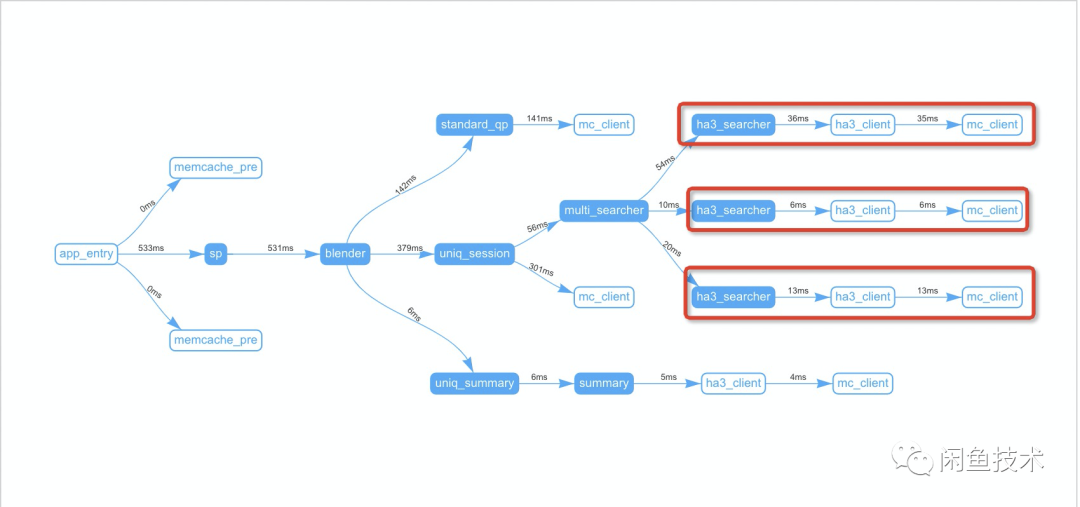
multi_searcher 是多路召回入口,包括并发多引擎召回、多引擎结果解析、合并等逻辑。
红框中每一个 ha3_searcher 表示一条独立引擎召回链路,图中三条链路可得出当前召回是多路并发召回(56ms < 54ms + 10ms +20ms)。
效果
目前多引擎多路召回能力已经在闲鱼无忧购引擎、向量引擎场景下落地,整体取得了不错的效果:
1、构建快
主引擎中闲鱼无忧购商品引擎 dump 大全量单次构建平均时长约为 14h,迁移独立引擎后平均构建时长约为 5h
2、接入快
主搜场景接入向量召回能力,采用当前多路召回能力,召回链路打通原先 1 周缩短到 2 天
3、体验好
主搜场景开启主搜引擎、闲鱼无忧购引擎、向量引擎三路并发召回能力,整体 RT 上涨约 15ms
4、资源省
主引擎占用内存(21.6T),无忧购引擎(210M),向量引擎(20G)
5、维护成本低
无忧购引擎整体 12 个 schema 字段,向量引擎目前只需要 2 个字段
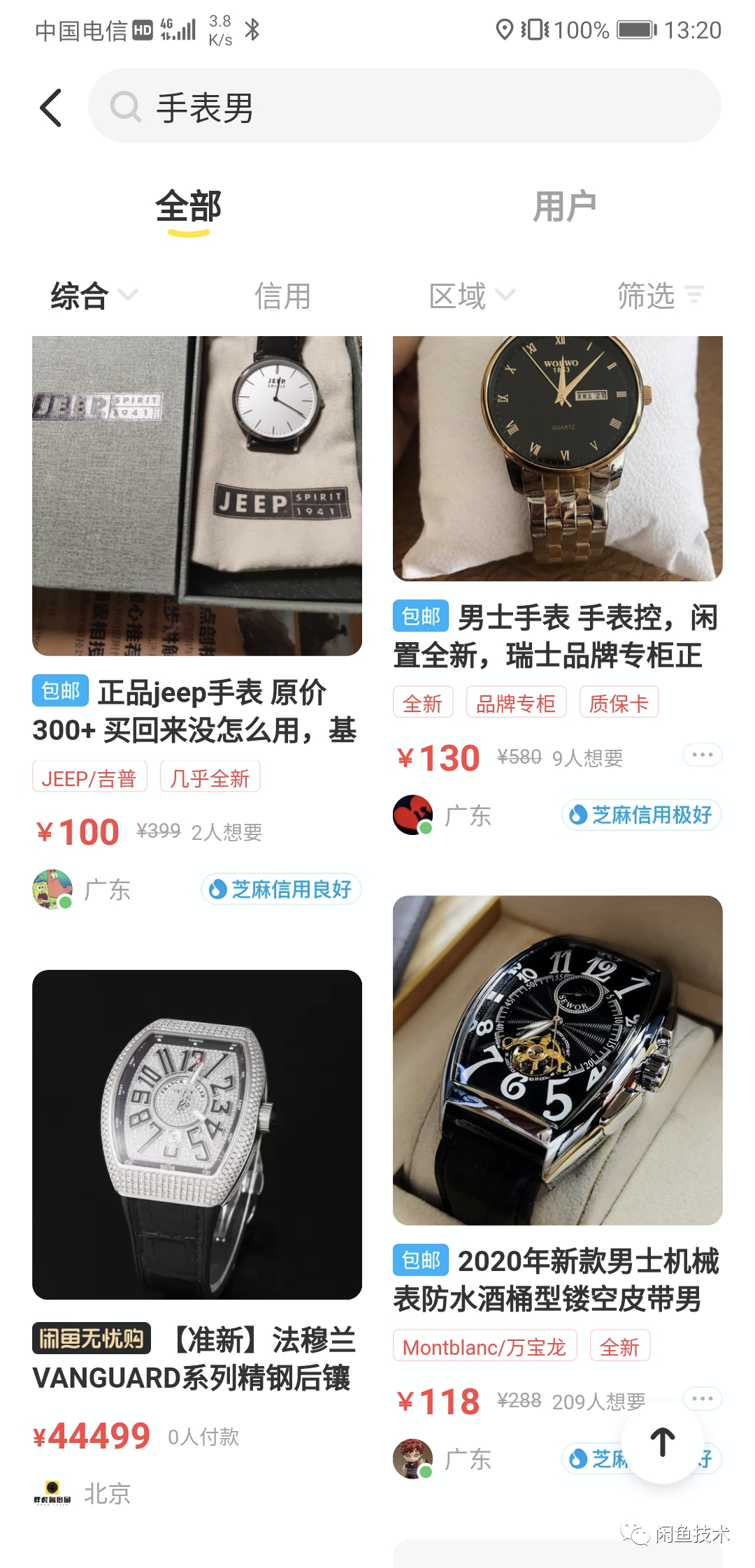
闲鱼无忧购迁移独立引擎,整体曝光 PV 提升近 50%,支付订单整体提升近 33%。
闲鱼无忧购商品与主引擎 C2C 商品混排效果如下:
展望
前期主要集中于搜索架构升级快速落地,快速支撑业务发展诉求,当前实现上存在不优雅、用户使用门槛高等问题,后续我们将围绕多路召回能力及用户体验继续优化:
1、隔离 query 改写及多引擎合并能力,将职责从平台侧迁移到业务侧,提高主链路稳定性,以及业务迭代效率
当前各个引擎 query 改写能力及合并能力,和主链路流程揉合在一起,未做到垂直业务间、垂直业务与主链路间隔离,对主链路的稳定性存在一定的影响
2、精细化流控及干预能力,并提供可视化配置能力
当前流控及干预手段,统一使用集团 diamond 配置,缺少一个便于操作使用的可视化能力
3、SP 功能核心代码逻辑从 lua 迁移 java,降低用户学习、开发成本
新的一年,闲鱼侧将有更多的垂直业务接入搜索,多路召回能力将极大的帮助更多垂直业务快速接入,并提供更优雅、灵活、高效的业务混排能力,为各业务的持续发展提供强有力的支撑。
本文转载自:闲鱼技术(ID:XYtech_Alibaba)

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论