
核心要点
对于处理用户文档查询的 RAG 管道而言,结合向量搜索和基于术语搜索的混合策略最为有效。向量数据库和基于 Lucene 的搜索引擎均支持此类混合方案,但要获得最佳效果,关键在于对底层算法进行精细调优。
当领域足够复杂,问题足够精细且含义微妙时,相似度(文档检索所呈现的结果)与相关性(大型语言模型回答问题所需的要素)并非同一个概念。
分块指的是在为数据库索引文档时将内容拆解为更小单元。若分块过大或过小,数据库检索可能会忽略相似性。分块标准应根据知识领域及内容载体类型灵活调整。
不同的内容类型不应采用统一的索引策略。图表、图形、示例代码、表格数据及各类文档的索引方案均需差异化处理。
尽管随着新版本发布而不断扩容,但是上下文窗口仍是关键考量因素。仅将最相关的搜索结果纳入 RAG 提示符,这样才能确保生成最高质量的响应。
我刚刚完成了一个为软件架构师构建 RAG 管道的开发工作,因此决定收集一些我的经验,并在这里进行分享。我希望你们能从我所学到的东西中受益。
项目的解决方案架构
我们首先简要描述一下这些经验教训来源于一个什么样的项目。这是一个基于云的 B2B 解决方案,为维护自己软件的技术公司提供软件架构的支持服务。你需要为它提供访问源代码和文档的权限。
然后,可以询问当前架构的信息或如何增强它。你可以要求一个高层次的概述或一个详细的计划,也可以询问一般情况下如何减少偶然的复杂性。下面的图 1 是这个项目的完整 RAG 管道的组件图,但本文将重点放在文档分块、索引和搜索部分学到的经验教训上。
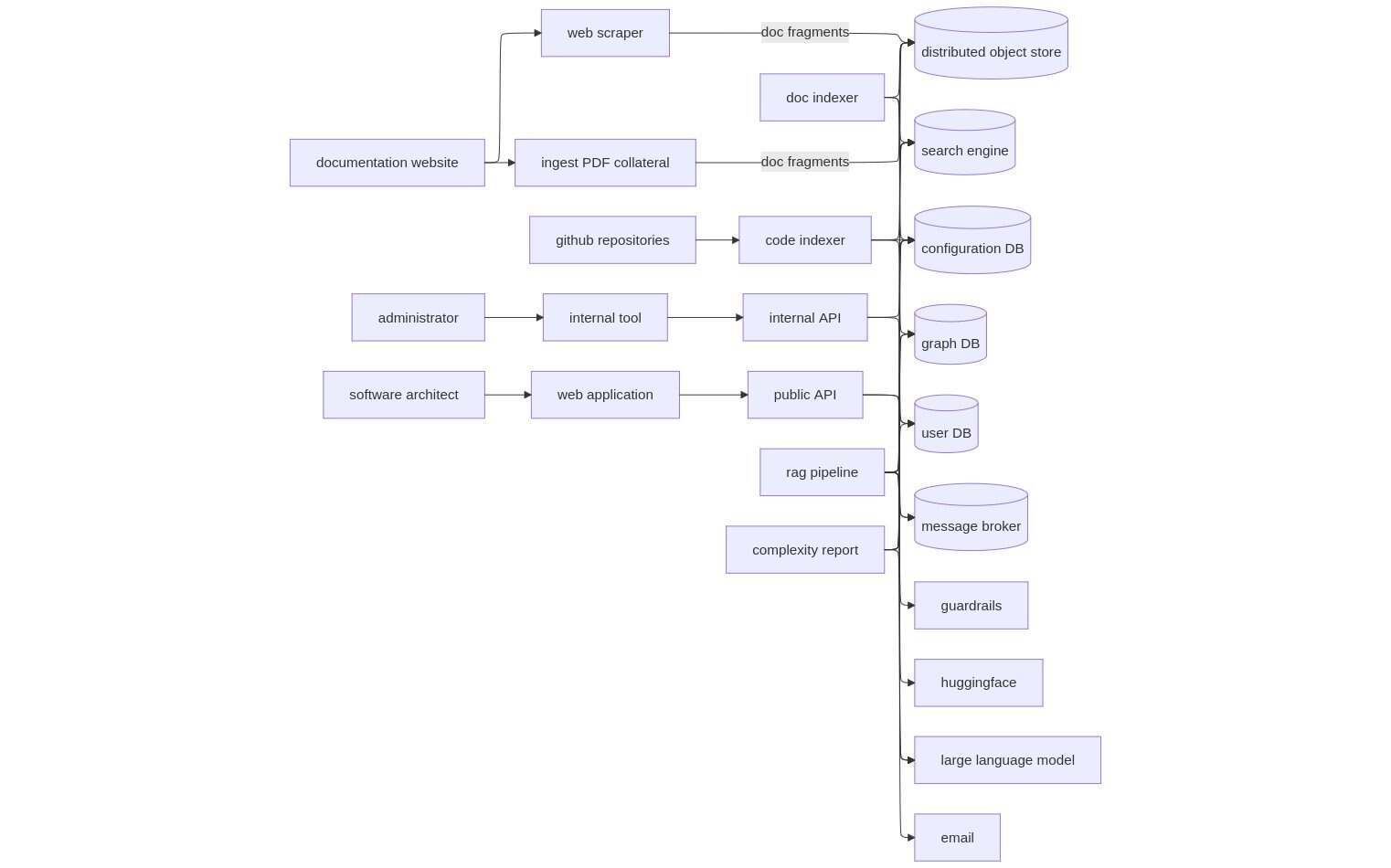
图 1. 用于软件架构支持项目的组件图,我们的经验就是从该项目中学到的
[点击放大图片]
重新审视 RAG
为了为文章的剩余内容奠定适当的上下文,我们从 RAG 的基础知识开始。我在这里会进行简要介绍,邀请你阅读 2025 年 5 月 InfoQ 的文章Beyond the Gang of Four: Practical Design Patterns for Modern AI Systems,以获取更多关于该主题的详细信息。
图 2 展示了以文档为中心的 RAG 管道的基本数据流。在用户可以提出任何问题之前,文档会被分块成片段,然后保存到数据库中。用户的问题会被收集并进行一些预处理,然后与系统指令和数据库搜索结果结合在一个模板中,从而构建最终的提示词。然后 RAG 管道将提示词提交给 LLM(大型语言模型)。响应会被收集并进行一些后处理,然后作为对用户问题的答案呈现给最终用户。
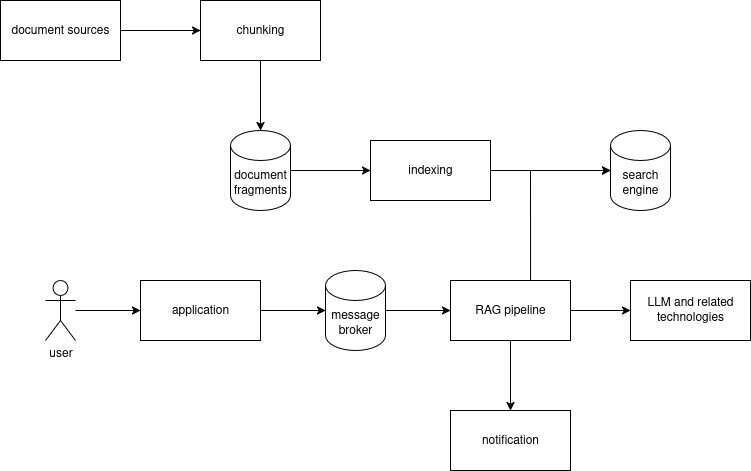
图 2. 以文档为中心的 RAG 管道中典型的数据流
我们回顾一下上下文窗口(context window),这是 LLM 在任何一个单一会话中可以考虑或记住的最大文本量(以 token 为单位)。如果你的提示词超过了上下文窗口,LLM 将不会记住系统指令或问题,它们通常位于提示词的开头位置。LLM 的后续版本会拥有越来越大的上下文窗口,但这仍然是一个需要注意的考虑因素。
为什么要费力地使用 RAG 管道呢?为什么不让用户直接向 LLM 提问,从而无需使用任何额外的提示词工程,同时也能避免支持数据库搜索呢?如果我们考虑上述项目中的一个用例,即用户询问如何增强现有的软件系统,LLM 的几个局限性就变得很明显了。也许供应商在文档发布之前训练了 LLM,或者文档不是训练数据的一部分。即使文档已被用来训练 LLM,也可能需要额外上下文的冲突信息。专有软件的内部细节几乎从未公开以供公众使用。当 LLM 知道得太少或太多时,AI 幻觉的可能性就会增加,我们必须通过策划好的过程来缓解它。
LLM 和 RAG 目前是一个非常热门的话题,这方面的支撑工具非常活跃。这类工具大致的内部结构通常是支持插件架构的开源框架。一般来讲,会有一个与之相关的 hub,可以共享资产,包括模型、训练数据和提示词。不仅工具供应商可以为这个 hub 做出贡献,社区成员也可以提供贡献。此外,还会有一个企业升级版,你可能觉得有必要购买,也可能会觉得完全没有必要。
经验教训
我们已经讲了很多的基础知识,接下来我们继续讨论遇到的问题以及是如何处理它们的。
在这个领域有很多供应商的工具,它们太多了,无法在这里完整地评估或介绍。最古老和最著名的工具是langchain,这是一个通用框架,专注于标准化组件接口、编排和可观测性。我决定放弃 langchain,原因如下:他们的向后破坏性更改让我在以前的项目中吃尽了苦头。每个 LLM 都提供了自己的 API,它们都非常相似,所以很容易互相替换。通过模板将一个步骤的输出连接到另一个步骤的输入,使用标准 Python 很容易做到。
除了 LLM 本身,我们还使用了两个专注于 LLM 的工具。还记得上述 RAG 管道描述中的问题预处理和答案后处理吗?Hub 处理主要是以安全审查的形式进行的,guardrails产品是这方面的一个优秀工具。他们的 hub 有很多检查器可供选择。有些需要 API 密钥,但很多则不需要。在本文的其余部分,你将看到对语句转换器(sentence transformer)、POS(Parts of Speech)标注、摘要和情感分析的引用。在这方面,Huggingface是一个优秀的资源。
文档摄取
在我们从数据库中搜索文档摘录以回答问题之前,必须先将这些摘录保存到数据库中。将整体文档分解成单独的文档片段,并将它们作为单独的行存储在数据库中,这个过程被称为分块。
分块粒度指的是每个单独保存的文档片段的大小。一个块可以从一个语句到多页不等。如果块太大,那么块的一小部分与问题的相似性可能会在结果中被冲淡。大块还有另一个问题,那就是最终输入到大型语言模型(LLM)的内容将包含大量的不相关内容。我们稍后将看到这会如何影响答案的质量。如果把块做得太小,我们可能会在搜索中忽略相关数据,因此,不会在提示中包含这些数据。
我希望能有一个适用于所有情况的分块粒度,但事实并非如此。虽然每个文档片段的字符长度应该在一个预定的范围内,但这不应该成为指导标准。分块粒度取决于多个因素,包括知识领域、内容类型和媒体类型。例如,为专家服务的关于详细领域的描述性文档可能需要比针对更广泛受众的简化领域的概述性文档具有更大的分块粒度。在许多类型的文档中,每个段落都想提供一个独立的想法。这可能是分块的一个合理基础。那么剧本呢?每个段落都是下一个角色要说的台词。如果在这个级别上进行分块,那么可能会错过关于两个角色之间互动的问题的相关结果。其他类型的内容,逐段落分块可能不太适用,包括示例代码、诗歌和表格数据。
原始文档交付媒介的选择也可能会对分块策略产生深远的影响。这里有一个例子,以 PDF(Portable Document Format)编写的文件会按页面组织内容。如果一个段落跨越两页怎么办?看上去,这与两个段落分别位于第一页的底部和第二页的顶部没有什么差异。我们该如何以编程的方式确定位于两页上的两个段落是否应该属于同一个段落呢?
对于我们的项目来讲,我们决定忽略这个问题,只是接受由此带来的后果。一些 PDF 内部的组织方式是每页只包含文本、图表、表格等的图像。有一些提取内容的策略,但实现起来并不容易,这方面的样例包括请求 LLM 和使用 OCR。幸运的是,对于我们的项目来说,这种类型的 PDF 更可能是面向公众的营销资料,而不是面向内部的软件架构。对于我们的项目来说,我们使用 pypdf 编写了一个自定义的 PDF 导入器,因为我们需要更精细地控制分块。如果你想选择现成的东西,那么我听说pymupdf4llm + tesseract是一个很好的选择。
那么长段落呢?根据Grammarly的说法,平均段落大小在 100 到 200 个单词之间。这是一个合理的分块大小,但并非所有作者都遵循这个规则。对于我们的项目,我们决定忽略这个问题,因为这个问题在软件架构文档的领域里并不常见。
索引网页是针对特定媒体选择分块策略的另一个样例。你需要从每个页面中过滤掉所有的导航和样板内容,这方面的样例包括标题、页脚、导航菜单和面包屑。我们可能会想要跟随链接到另一个文档区域,以便进行索引,但是不能超出限定的区域,比如其他领域、关于我们、网站地图和购物车。对于我们的项目来说,我们编写了一个自定义的网络爬虫,因为我们需要更精细地控制分块。这个自定义网络爬虫使用了Beautiful Soup库。
不同的知识领域对图形内容的依赖程度有所不同。在某些类型的内容中,图形是多余的。在其他类型的内容中,图像中相关部分的叙述性描述可能已经在文本中存在了,尽管并非所有类型都如此。我们如何为文档搜索收集这些内容呢?我们可以将图像嵌入数据库进行向量搜索(稍后会有更多内容),但嵌入的内容可能与提出的问题类型无关。比如,一个男孩和他的狗的卡通画很可能会被准确地嵌入。但是,一个政治选举结果的图表可能会被表示为不同大小的红色和蓝色圆圈,这可能就不会特别有用。你可能需要生成并保存自定义的、特定领域的文本摘要,用于特定类型的内容,包括图表、示例代码和表格数据。
对于我正在参与的项目,我们会定期抓取包含文档的网站。这主要是架构文档,但也包括用户和管理员指南,因为它们可能包含有用的信息,它们通常位于同一个网站上。我们还导入了包含教育资料的 PDF 文件。HTML 和 PDF 资产通常托管在内部 CMS 上。我们会使用启发式方法将每个页面分解成文本、示例代码、图表和配置组成的块。我们会在文本的段落级别进行分块,并要求 LLM 为其他类型的内容生成摘要。
文档搜索
现在我们已经将所有文档片段索引到数据库中了,那么在原始问题的上下文中,最好的搜索方式是什么呢?在我参与的项目中,我发现混合搜索方法最有效。混合搜索覆盖面更广,因此更有可能收集到足够的相关结果。混合搜索涉及多次搜索,通常包括一到两个向量搜索和一个术语搜索。对它们进行结果合并并重新排名,这通常会使用倒数排序融合(Reciprocal Rank Fusion,RRF)算法。向量搜索的查询可以是问题本身,或者是它的规范化版本。目前,我们还没有这样做,但应该考虑纠正语法错误,如果问题太长或离题,应该进行总结。
术语搜索的查询可以是问题,或者也可以从问题中提取最相关的术语。对于许多领域来说,这将是专有名词,你可以使用词性标注来识别它们。我们的方法是使用 huggingface 插件的flair来完成词性标注。这种方法不适用于“它能做什么?”风格的缺乏任何专有名词的问题。我们最终将这类问题视为无效,并会引导用户到一个页面上,教他们如何写出好的问题。
我们已经介绍了将文档分解成文本片段,然后将每个片段保存到数据库的过程。将文本转换为可搜索向量的过程称为嵌入,这方面存在不同的嵌入类型。使用密集向量来实现通常被称为向量搜索,我们需要使用语句转换器将文本嵌入到密集向量中。
最受欢迎的转换器源自基于 Transformers 的双向编码器(Bidirectional Encoder Representations from Transformers,BERT)算法。两个值得考虑的流行语句转换器是all-distilroberta-v1和nli-mpnet-base-v2。如果你对嵌入模型的最新发展更感兴趣,请查看这个排行榜。嵌入图像需要视觉转换器,如CLIP或Swin。向量数据库使用稀疏向量来适应基于术语的搜索。目前,有一个基于 BM25 的嵌入器,但我推荐基于 BERT 的 SParse Lexical AnD Expansion Model(SPLADE)嵌入器。你应该使用相同的嵌入算法来索引文档片段,就像在搜索时嵌入问题一样。数据库中不同的记录字段可以用不同的嵌入函数填充,但要对数据库中同一字段的所有记录使用相同的嵌入函数。
本文是在 2025 年撰写的,所以最杰出的数据库是向量数据库,如Qdrant、Pinecone和Milvus,以及基于 Lucene 的数据库,包括Elasticsearch、Solr和OpenSearch。基于 Lucene 的数据库使用倒排索引数据结构进行基于术语的搜索。它的算法是 BM25,并通过规范化的术语频率(term frequency,TF)和逆文档频率(inverse document frequency,IDF)对结果进行排名。Lucene 还支持向量搜索算法。你可以使用 Elasticsearch 的社区版来做到这一点,但必须在你的代码中使用语句转换器。
Elasticsearch 的更高级许可证使我们能够在 Elasticsearch 进程空间内配置一个 ML 管道,并自动进行嵌入。所有这些数据库都支持混合搜索,但我们最终会分别查询数据库,并在我们的代码中实现结果的合并和重新排名。我们觉得需要更精细地控制这一点,因为它对响应的质量至关重要。
向量搜索的实际算法也被称为 kNN 或 k 最近邻(k nearest neighbors)。有一个更快版本的 kNN,称为aNN或近似 k 最近邻。aNN 方法通常使用 Hierarchical Navigable Small Worlds(HNSW)算法实现。我们可以将 HNSW 视为概率跳表上的层级接近图。aNN 的另一种算法是FAISS,但大多数数据库尚未支持它。
决定邻居有多远的算法被称为距离函数。对于密集向量,最受欢迎的算法称为余弦相似度。除此之外,还有替代方案,如 Euclidean 距离和 Manhattan 距离。对于稀疏向量,使用加权点积(weighted dot product)。距离函数的选择很少会改变,但它与嵌入函数的选择松散相关。余弦相似度不考虑两个向量的幅度,而 Euclidean 距离则会进行考虑。Manhattan 距离更多是关于将一个向量转换为另一个向量所需的离散变化数量。我们使用了余弦相似度。
文档检索和重新排名
鉴于项目的性质,问题并不简单,答案的获取需要更深入的推理,我们很快学到了对 RAG 管道新手来说可能不那么显而易见的东西。数据库搜索的结果提供了与问题相似的文档片段。LLM 需要回答的问题则是相关的文档片段。相关性代表了文档片段有助于回答问题的可能性。对于大多数复杂一些的用例,相似性并不等于相关性。为什么不在提示中包含所有的搜索结果,让 LLM 确定什么是相关的内容,然后默默地忽略其余的内容呢?即使提示适合上下文窗口,随着 token 计数接近限制,响应往往也会退化。这些答案听起来更像流行词,不那么清晰,为最终用户提供的价值更少。这被称为上下文腐烂(context rot),即使输入 token 的大小超过上下文窗口的 1%,也可以发生可测量的退化。
我们必须想出一个方法来根据相关性重新排列搜索结果,并在提示中只包括最相关的结果。也许你可以找到一些特定领域的启发式方法来估计相关性。为了达到我们的目的,我们认为包含足够多来自问题中的专有名词的结果(见上述 POS 标注)被认为是相关的。如果你处于一个有争议和两极分化的领域,那么还应该包括带有专有名词的情感分析,不过这在我们的项目中并不是必需的。如果我们用这种方式没有得到足够的相关结果,我们会尝试最坏情况下的解决方案,即遍历所有搜索结果,然后提示大型语言模型(LLM)计算每个结果的相关性。系统指令可能如下所示:
研究以下问题和数据,然后返回所提供数据可以用来回答问题的相关性或可能性。这种相关性将表示为 0.0 到 1.0 之间的浮点数,其中 0.0 表示数据根本没有用,1.0 意味着数据完全确定有用,0.5 表明数据有用的可能性和没用的可能性一样,以指定模式的 JSON 格式进行输出。响应必须是有效的 JSON 对象,且不能有其他内容。
这种方法可能成本高昂且耗时,如果可扩展性和成本是你的考虑因素的话,那么它对你的场景来说可能不太匹配。
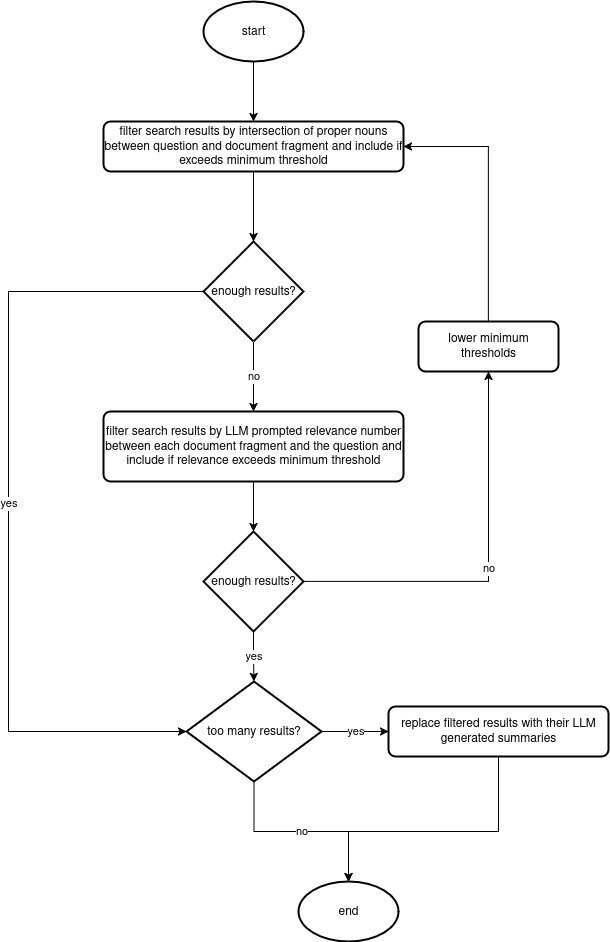
图 3. 结合 POS 标注、LLM 相关性和摘要的流程图。
[点击放大图片]
如果不能通过相关性来进行限制的话,那么可以考虑在提示中使用搜索结果的摘要。摘要可能足以缩短提示的长度,但它们需要一些时间才能生成,并且可能导致数据的相关性降低,这可能会降低答案的价值。根据结果的大小,我们最终做了相关性过滤和结果摘要的混合(见上图 3)。我们使用了在 Huggingface 上由 Meta 发布的CNN Daily Mail模型微调的大型模型BART来生成这种摘要。
基于结果来进行提示
你可能需要根据搜索结果调整系统指令。假设你有相当数量的相关搜索结果,在这种情况下,系统指令可以这样说:“你是一个专家,任务是根据提供的数据回答以下问题”。但是,如果你没有得到结果或只得到很少的相关结果,那么系统指令可能是这样的:“你是一个专家,任务是根据你对主题已有的知识回答以下问题”。
没有结果的提示听起来不太像 RAG,但我可以向你保证,根据第一手经验,当你指示 LLM 使用数据,然后未能提供任何数据时,LLM 会变得相当暴躁。
结论
从文档摄取到搜索、检索、重新排序,再到嵌入到基于模板的提示中供 LLM 使用,我希望这些关于 RAG 管道的笔记对你学习 RAG 管道构建有所帮助。阅读完这篇文章后,你应该意识到,如果你发现自己的管道中 LLM 的答案不够出色,有很多可以调整的地方和可以尝试的技术。
原文链接:





/filters:no_upscale()/articles/architecting-rag-pipeline/en/resources/140figure-1-1755593891004.jpg){kind=link}
/filters:no_upscale()/articles/architecting-rag-pipeline/en/resources/89figure-3-1755594535405.jpg){kind=link}