

在 Netflix,我们对数据基础设施进行了大量投资,这些基础设施由数十个数据平台、数百个数据生产者和消费者以及 PB 级的数据组成。
在许多其他组织中,管理数据基础设施成本的有效方法是设置预算和其他严格的约束来限制支出。但是,由于我们数据基础设施的高度分布式性质,以及我们对自由和责任的重视,这些过程是反文化的,而且效率低下。
因此,我们的效率方法是提供成本透明度,并尽可能让决策者了解效率背景。我们最大的优势是有一个定制的仪表板,它可以作为数据生产者和消费者的反馈回路:它是 Netflix 数据用户在成本和使用趋势方面唯一全面的真实来源。本文详细介绍了我们创建数据效率仪表板的方法和经验教训。
Netflix 的数据平台全景
Netflix 的数据平台大致可以分为静态数据和动态数据系统。静态存储中的数据,如 S3 数据仓库、Cassandra、Elasticsearch 等物理存储数据,基础架构成本主要来自于存储。动态数据系统,如 Keystone、Mantis、Spark、Flink 等,会带来与处理瞬态数据相关的数据基础设施计算成本。每个数据平台包含数千个不同的数据对象(即资源),这些数据对象通常由不同的团队和数据用户拥有。
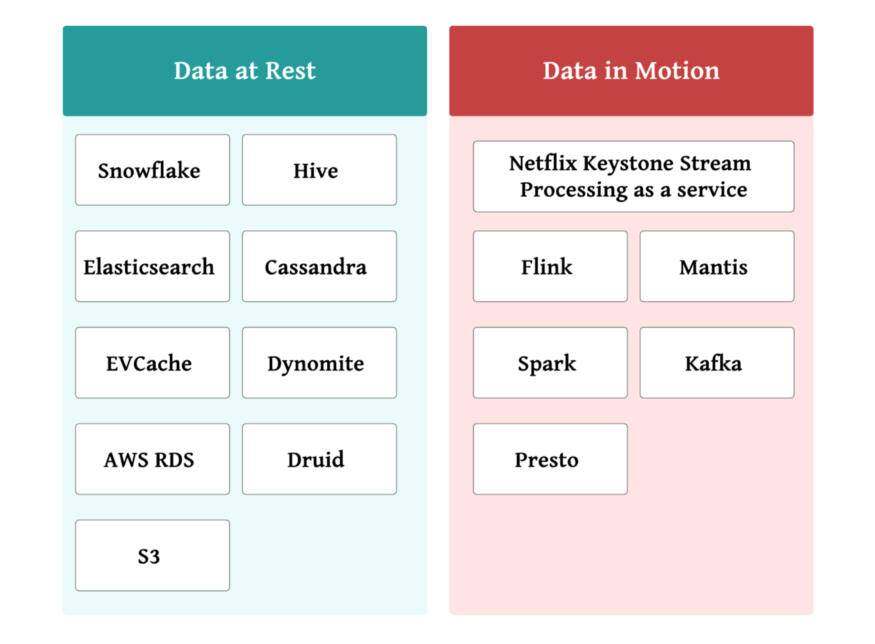
创建使用情况和成本可见性
要获得每个团队的成本的统一视图,我们需要能够汇总所有这些平台的成本,同时保留按有意义的资源单元(表、索引、列族、作业等)进行细分成本的能力。
数据流
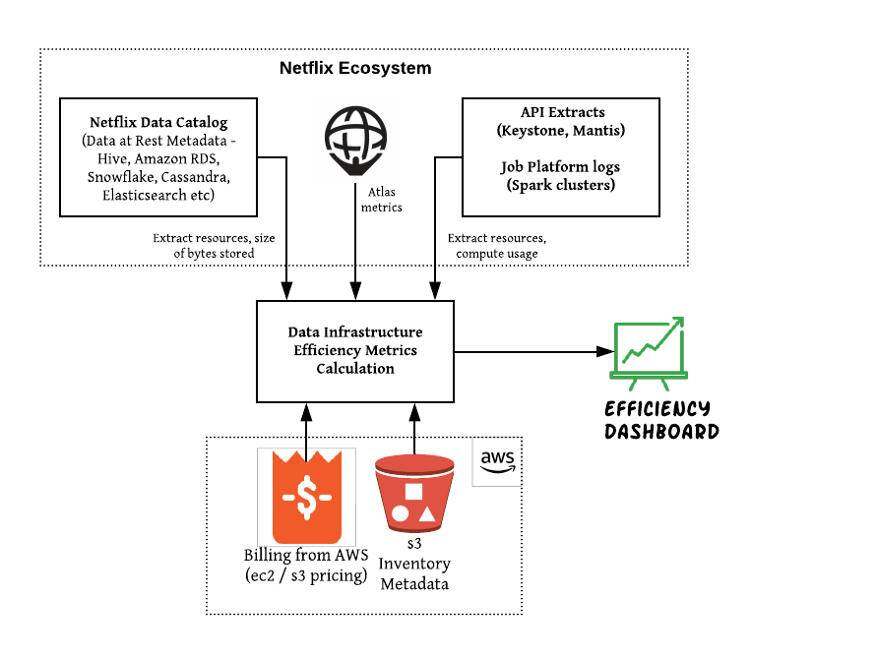
S3 Inventory:提供对象列表及其相应的元数据,如 配置为生成库存列表的 S3 存储桶的字节大小。
Netflix Data Catlog(NDC):内部联合元数据存储,代表 Netflix 所有数据资源的单一综合知识库。
Atlas:为系统生成操作指标(CPU 使用率、内存使用率、网络吞吐量等)的监控系统。
成本计算和业务逻辑
作为成本数据的真实来源,AWS 计费按服务(EC2、S3 等)分类,并可根据 AWS 标签分配到不同的平台。但是,这种粒度并不足以按数据资源和/或团队提供对基础设施成本的可见性。我们采用以下方法进一步分配这些费用:
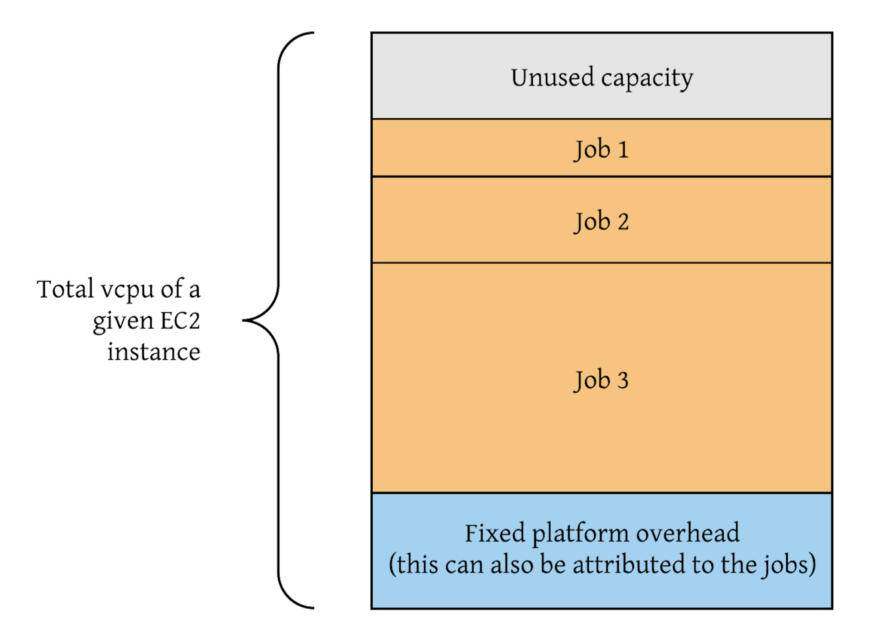
基于 EC2 的平台: 确定平台的瓶颈指标,即 CPU、内存、存储、IO、吞吐量或其组合。例如,Kafka 数据流通常受限于网络,而 Spark 作业通常受限于 CPU 和内存。接下来,我们使用 Atlas、平台日志和各种 REST API 确定每个数据资源的瓶颈指标的消耗情况。成本是根据每个资源的瓶颈指标(例如,Spark 作业的 CPU 使用率百分比)来进行分配的。平台的详细计算逻辑可能会因其架构而异。以下是在受 CPU 限制的计算平台中运行的作业的成本属性示例:
基于 S3 的平台:我们使用 AWS 的 S3 库存(具有对象级粒度)来将每个 S3 前缀映射到相应的数据资源(例如 hive 表)。然后,我们根据 AWS 计算数据中的 S3 存储价格,将每个数据资源的存储字节数转换为成本。
仪表板视图
我们使用 druid 支持的自定义仪表板将成本背景传递给团队。我们成本数据的主要目标受众是工程和数据科学团队,因为他们有根据这些信息采取行动的最佳背景。此外,我们还为工程领导者提供更高层次的成本背景。根据用例的不同,可以根据数据资源层次结构或组织层次结构对成本进行分组。快照和时间序列视图都是可用的。
注:以下片段包含的成本、可比较的业务指标和职位名称,并不代表实际数据,仅用于说明目的。

说明性摘要事实,显示年化成本和可比业务指标
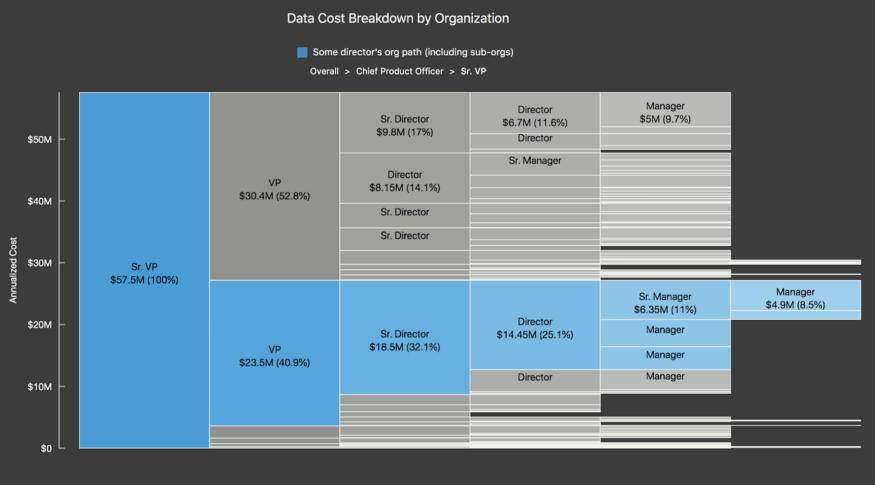
按组织层次结构划分的说明性年化数据成本
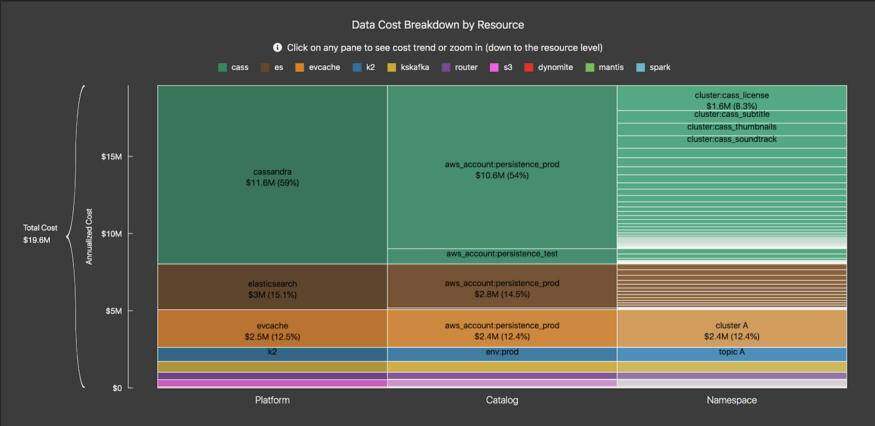
特定团队按资源层次结构划分的说明性年化数据成本
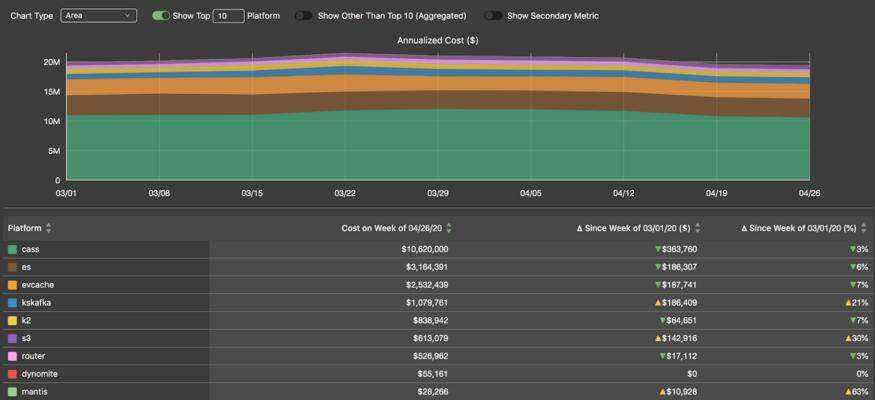
按平台显示特定团队每周成本(按年化计算)的说明性时间序列
自动化存储建议:生存时间(TTL)
在选定的值得进行工程投资的场景中,我们不仅提供透明度,还提供优化建议。由于数据存储具有很大的使用率和成本动因(即保存和遗忘的积累),因此我们根据数据使用模式自动进行分析,以确定最佳存储持续时间(TTL)。到目前为止,我们已经为 S3 大数据仓库表启用了 TTL 建议。
我们的大数据仓库允许表的个人所有者选择保留时间的长短。基于这些保留值,存储在按日起分区的 S3 表中的数据由一个数据管家(Janitor)进程清理,该进程每天删除比 TTL 值旧的分区。从历史上看,大多数数据所有者无法很好地理解使用模式以决定最佳 TTL。
数据流
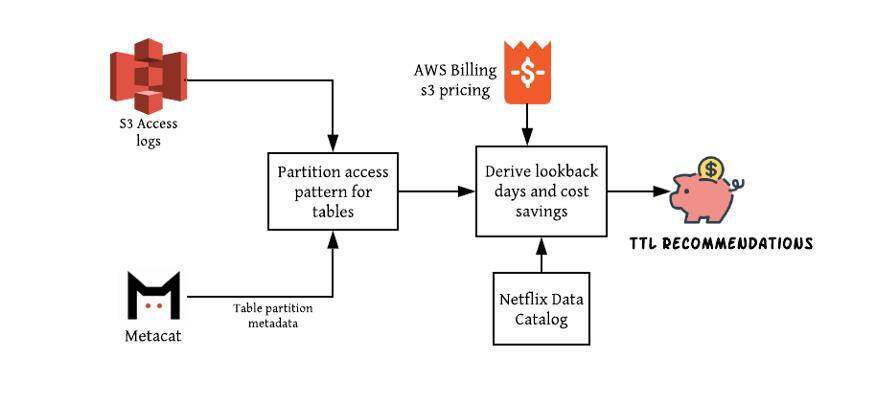
S3 Access logs:AWS 为所有 S3 请求生成日志记录,这些日志提供了关于访问了什么 S3 前缀、访问时间和其他有用信息的详细记录。
Table Partition Metadata:从内部元数据层(Metacat)生成,该元数据层将 hive 表及其分区映射到特定的底层 S3 位置,并存储此元数据。这对于将 S3 访问日志映射到请求中访问的 DW 表非常有用。
Lookback days:访问的日期分区与访问该分区的日期之间的差异。
成本计算和业务逻辑
S3 最大的存储开销来自事务表,这些事务表通常是按日期分区的。
通过使用 S3 访问日志和 S3 前缀到表分区的映射,我们可以确定在任意给定的日期访问哪些日期分区。接下来,我们查看过去 180 天内的访问(读/写)活动,并确定最大回溯天数(Lookback days)。这个回溯天数的最大值决定了给定表的理想 TTL。此外,我们还计算了基于最佳 TTL 计算可以实现的潜在年度节省(基于当前的存储水平)。
仪表板视图
从仪表板中,数据所有者可以查看详细的访问模式、建议的 TTL 与当前的 TTL 值,以及潜在的节省。

具有次优 TTL 的表的说明性例子
沟通和提醒用户
检查数据成本不应该是任何工程团队日常工作的一部分,尤其是那些数据成本微不足道的团队。同样的,我们只为具有截成材料成本潜力的表格发送自动 TTL 建议。目前,这些电子邮件是按月发送一次。
学习和挑战
识别和维护资产的元数据杜宇成本分配至关重要。
什么是资源?我们拥有的完整数据资源集是什么?
这些问题构成了成本效率和分配的主要组成部分。如前所述,我们正在为各种平台提取元数据,这写平台涵盖了动态系统和静态系统。不同的平台以不同的方式存储它们的资源元数据。为了解决这一问题,Netflix 正在建立一个名为 Netflix Data Catalog(NDC)的元数据存储。NDC 使数据访问和发现更容易,以支持现有数据和新数据的数据管理需求。我们使用 NDC 作为成本计算的起点。拥有联合元数据存储可以确保我们拥有一个普遍理解和接受的概念,即定义存在哪些资源以及哪些资源由各个团队拥有。
时间趋势充满挑战
与时间快照相比,时间趋势的维护负担要高得多。在数据不一致和接受延迟的情况下,随着时间的推移,显示一致的视图通常是很有挑战性的。具体来说,我们应对了以下两个挑战:
资源所有权的更改:对于时间点快照视图,此更改应做到自动反映。但是,对于时间序列视图,所有权的任何更改也应该反映在历史元数据中。
发生数据问题时状态丢失:资源元数据是从各种各样的源中提取的,其中许多是 API 提取,在数据提取期间,如果作业失败,可能会丢失状态。API 提取通常都有缺点,因为数据是瞬态的。重要的是要探索替代方案,比如将事件发送到 Keystone,这样,我们就可以将数据持久化更长一段时间。
结论
当面对大量具有高度分布、分散的数据用户基础的数据平台时,通过仪表板整合使用和成本背景来创建反馈循环,在解决效率问题上提供了巨大的杠杆作用。在合理的情况下,创建自动化建议以进一步减轻效率负担还是很有必要的:在我们的案例中,数据仓库表保留建议的 ROI 很高。
下一步
未来,我们计划根据使用模式对资源使用不同的存储级别,识别并积极删除未使用的数据资源的上下游依赖关系,从而进一步提高数据效率。
作者介绍
Torio Risianto,Netflix 数据分析工程师;Bhargavi Reddy Dokuru,Netflix 高级数据工程师,毕业于卡内基梅隆大学,曾在 Amazon 工作;Tanvi Sahni,供职 Netflix,负责战略规划与分析;Andrew Park,Netflix 产品平台战略、规划和分析总监。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论