

在 Twitter 上,我们每天都要实时处理大约 4000 亿个事件,生成 PB 级的数据。我们使用的数据的事件源多种多样,来自不同的平台和存储系统,例如 Hadoop、Vertica、Manhattan 分布式数据库、Kafka、Twitter Eventbus、GCS、BigQuery 和 PubSub。
为了处理这些源和平台中的这些类型的数据,Twitter 数据平台团队已经构建了内部工具,如用于批处理的 Scalding,用于流的 Heron,用于批处理和实时处理的名为 TimeSeries AggregatoR(TSAR)的集成框架,以及用于数据发现和消费的 Data Access Layer。然而,随着数据的快速增长,高规模仍然给工程师们用来运行管道的数据基础设施带来了挑战。比如,我们有一个交互和参与的管道,能够以批处理和实时的方式处理高规模数据。由于数据规模的快速增长,对流延迟、数据处理的准确性和数据的实时性提出了更高的要求。
对于交互和参与的管道,我们从各种实时流、服务器和客户端日志中采集并处理这些数据,从而提取到具有不同聚合级别、时间粒度和其他度量维度的 Tweet 和用户交互数据。这些聚合的交互数据尤其重要,并且是真正来自 Twitter 的广告收入服务和数据产品服务检索影响和参与度指标信息。此外,我们需要保证对存储系统中的交互数据进行快速查询,并在不同的数据中心之间实现低延迟和高准确性。为了构建这样一个系统,我们把整个工作流分解为几个部分,包括预处理、事件聚合和数据服务。
旧架构
旧的架构如下图所示。我们的 Lambda 架构具有批处理和实时处理管道,构建在 Summingbird 平台内,并与 TSAR 集成。如需进一步了解 Lambda 架构,请参阅《什么是 Lambda 架构?》(What is Lambda Architecture?)。批处理组件源是 Hadoop 日志,如客户端事件、时间线事件和 Tweet 事件,这些都是存储在 Hadoop 分布式文件系统(HDFS)上的。我们构建了几个 Scalding 管道,用于对原始日志进行预处理,并且将其作为离线来源摄入到 Summingbird 平台中。实时组件来源是 Kafka 主题。
实时数据存储在 Twitter Nighthawk 分布式缓存中,而批处理数据存储在 Manhattan 分布式存储系统中。我们有一个查询服务,可以在这两个存储中存取实时数据,而客户服务则会使用这些数据。
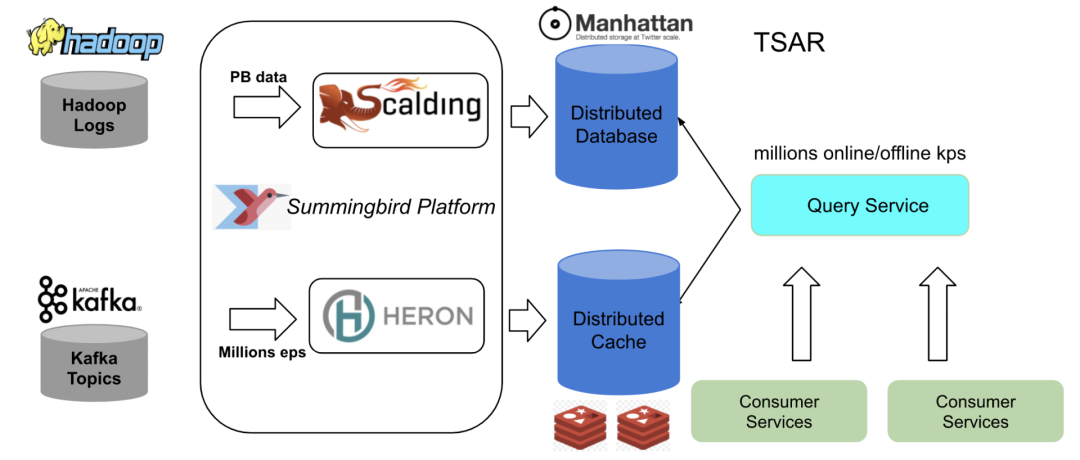
旧的 Lambda 架构
目前,我们在三个不同的数据中心都拥有实时管道和查询服务。为了降低批处理计算的开销,我们在一个数据中心运行批处理管道,然后把数据复制到其他两个数据中心。
现有挑战
由于我们实时处理的数据规模大、吞吐量高,对于实时管道来说,可能会发生数据丢失、数据不准确的问题。对于 Heron 拓扑结构,当发生更多的事件需要处理,Heron Bolt 无法不能及时处理时,拓扑结构内会产生背压。另外,由于垃圾收集成本很高,Heron Bolt 将会非常缓慢。
当系统长期处于背压状态时,Heron Bolt 会积累喷口滞后(spout lag),这表明系统延迟很高。通常当这种情况发生时,需要很长的时间才能使拓扑滞后下降。更多的时候,正如在我们的 Heron 管道中看到的那样,也有很多 Heron 流管理器的“死亡”(流管理器管理拓扑组件之间的图元路由),而滞后不断上升。
当前的操作方案是重启 Heron 容器,将流管理器唤醒,以使 Bolt 能够重新启动处理流。这会在操作过程中造成事件丢失,从而导致 Nighthawk 存储中的聚合计数不准确。
对于批处理组件,我们构建了几条重型计算管道,这些管道用于处理 PB 级数据,每小时运行一次,将数据汇入 Manhattan。集中式 TSAR 查询服务整合了 Manhattan 和 Nighthawk 的数据,为客户服务提供数据服务。由于实时数据的潜在损失,TSAR 服务可能为我们的客户提供较少的聚合指标。
为了克服这一数据损失问题,减少系统延迟,并优化架构,我们建议在 Kappa 架构中构建管道,以纯流模式处理这些事件。关于 Kappa 架构的更多信息,请参阅《什么是 Kappa 架构?》(What is Kappa Architecture?)在该解决方案中,我们去掉了批处理组件,利用实时组件实现了低延迟和高准确度的数据,从而简化了架构,减少了批处理管道中的计算成本。
Kafka 和数据流上的新架构
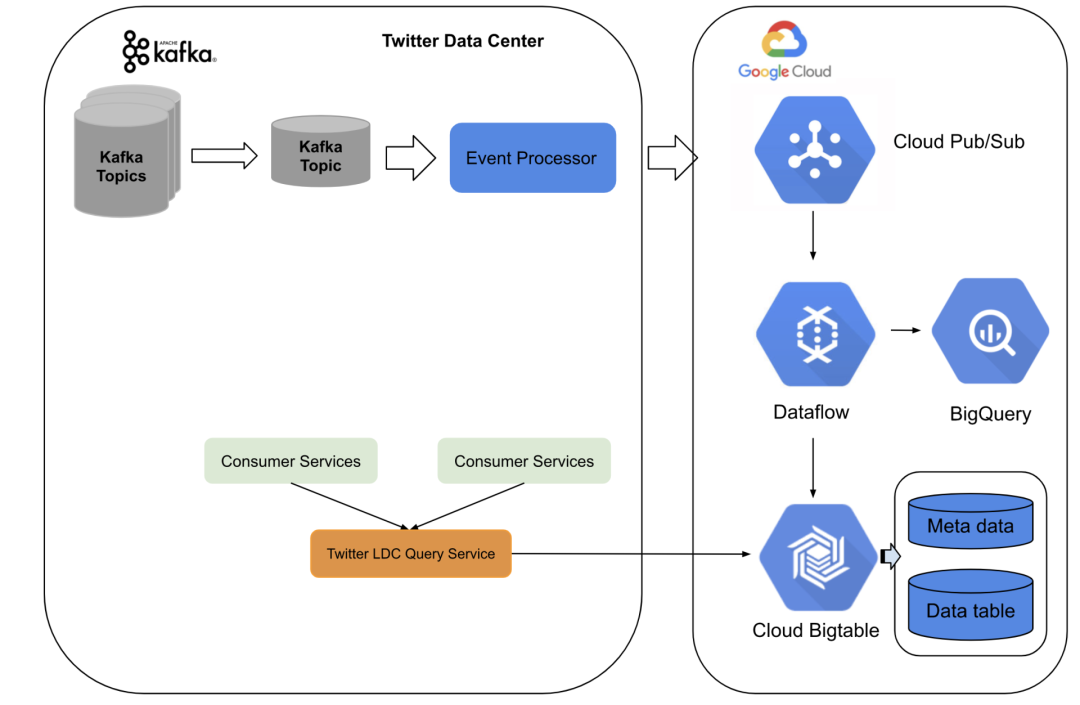
Kafka 和数据流上的新架构
新架构基于 Twitter 数据中心服务和谷歌云平台。我们在内部构建了预处理和中继事件处理,将 Kafka 主题事件转换为具有至少一个语义的 pubsub 主题事件。在谷歌云上,我们使用流数据流作业,对重复数据进行处理,然后进行实时聚合并将数据汇入 BigTable。
第一步,我们构建了几个事件迁移器作为预处理管道,它们用于字段的转换和重新映射,然后将事件发送到一个 Kafka 主题。我们使用我们内部定制的基于 Kafka 的流框架创建了这些流管道,以实现一次性语义。第二步,我们构建了事件处理器,对具有最少一次语义的事件进行流处理。事件处理器处理向 Pubsub 事件表示法的转换,并生成由 UUID 和其他与处理背景相关的元信息组成的事件背景。UUID 被下游的数据流工作器用来进行重复数据删除。我们对内部的 Pubsub 发布者采用了几乎无限次的重试设置,以实现从 Twitter 数据中心向谷歌云发送消息的至少一次。在新的 Pubsub 代表事件被创建后,事件处理器会将事件发送到谷歌 Pubsub 主题。
在谷歌云上,我们使用一个建立在谷歌 Dataflow 上的 Twitter 内部框架进行实时聚合。Dataflow 工作器实时处理删除和聚合。重复数据删除的准确性取决于定时窗口。我们对系统进行了优化,使其在重复数据删除窗口尽可能地实现重复数据删除。我们通过同时将数据写入 BigQuery 并连续查询重复的百分比,结果表明了高重复数据删除的准确性,如下所述。最后,向 Bigtable 中写入包含查询键的聚合计数。
对于服务层,我们使用 Twitter 内部的 LDC 查询服务,其前端在 Twitter 数据中心,后端则是 Bigtable 和 BigQuery。整个系统每秒可以流转数百万个事件,延迟低至约 10 秒钟,并且可以在我们的内部和云端流系统中扩展高流量。我们使用云 Pubsub 作为消息缓冲器,同时保证整个内部流系统没有数据损失。之后再进行重复数据删除处理,以达到一次近似准确的处理。
这种新的架构节省了构建批处理管道的成本,对于实时管道,我们能够实现更高的聚合精度和稳定的低延迟。在此期间,我们不必在多个数据中心维护不同的实时事件聚合。
评估
系统性能评估
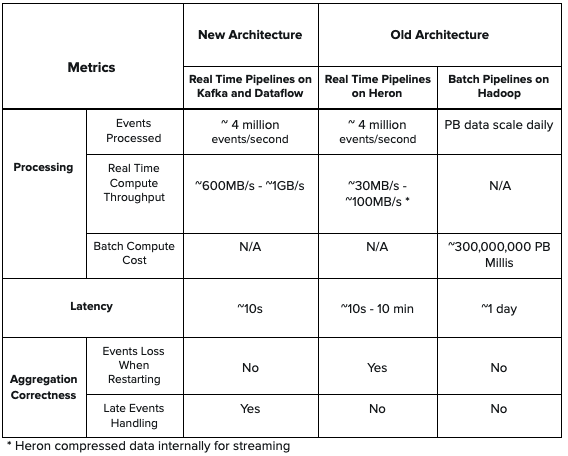
下面是两个架构之间的指标比较表。与旧架构中的 Heron 拓扑相比,新架构具有更低的延迟、更高的吞吐量。此外,新架构还能处理延迟事件计数,在进行实时聚合时不会丢失事件。此外,新架构中没有批处理组件,所以它简化了设计,降低了旧架构中存在的计算成本。
表 1:新旧架构的系统性能比较。
聚合计数验证
我们将计数验证过程分成两个步骤。首先,我们在数据流中,在重复数据删除之前和之后,对重复数据的百分比进行了评估。其次,对于所有键,我们直接比较了原始 TSAR 批处理管道的计数和重复数据删除后数据流的计数。
第一步,我们创建了一个单独的数据流管道,将重复数据删除前的原始事件直接从 Pubsub 导出到 BigQuery。然后,我们创建了用于连续时间的查询计数的预定查询。同时,我们会创建另外一条数据流管道,把被扣除的事件计数导出到 BigQuery。通过这种方式,我们就可以看出,重复事件的百分比和重复数据删除后的百分比变化。
第二步,我们创建了一个验证工作流,在这个工作流中,我们将重复数据删除的和汇总的数据导出到 BigQuery,并将原始 TSAR 批处理管道产生的数据从 Twitter 数据中心加载到谷歌云上的 BigQuery。这样我们就可以执行一个预定的查询,以便对所有键的计数进行比较。
在我们的 Tweet 交互流中,我们能够准确地和批处理数据进行超过 95% 的匹配。我们对低于 5% 的差异进行了研究,结果表明,这很大程度上是由于最初的 TSAR 批处理管道丢弃了后期事件,而这些事件被我们的新流管道捕获。这进一步证明了我们目前的系统产生了更高的准确性。
结语
通过将建立在 TSAR 上的旧架构迁移到 Twitter 数据中心和谷歌云平台上的混合架构,我们能够实时处理数十亿的事件,并实现低延迟、高准确度、稳定性、架构简单和减少工程师的运营成本。对于下一步,我们将使 Bigtable 数据集对区域故障具有弹性,并将我们的客户迁移到新的 LDC 查询服务器上。
作者介绍:
Lu Zhang,Twitter 高级软件工程师。
Chukwudiuto Malife,Twitter 高级软件工程师。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论