

Apache Hive 能在下一轮“淘汰”中幸存下来吗?
Apache Hive 在 2010 年作为 Hadoop 生态系统的一部分崭露头角,当时 Hadoop 是一种新颖而创新的大数据分析方法。Hive 的功能就是实现 Hadoop 的 SQL 接口。它的架构包括两个主要服务:一是查询引擎:负责执行 SQL 语句;二是元存储:负责在 HDFS 中将数据收集虚拟化为表。
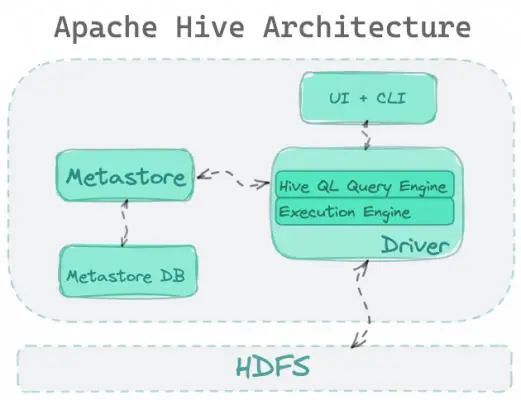
HDFS 上的 Hive 的主要组成部分,包括用户界面、驱动程序和元存储。
Hadoop 背后的概念是革命的。分布式文件系统(HDFS)中存储大量的数据集,运行于商业硬件集群之上。并行执行计算作业时使用 MapReduce 的数据。这类任务的分配由 Yarn 管理。主接口是一种编程语言,最初是 Java 或 Scala。
这些组件在 Apache 基金会下开源,可以免费使用。这套技术已经成为几年来大规模分析的标准。
但是,这个技术栈已经逐渐被一些新技术淘汰……
HDFS 被对象存储所取代,由 AWS S3 主导。MapReduce 已经被 Spark 所取代,Spark 也逐渐减少了对 Hadoop 的依赖性。Yarn 正在被像 Kubernetes 这样的技术取代。此外,Hive 的查询引擎组件在性能和采用方面已经被 Presto/Trino 超越。
虽然有这些改变,但大多数以数据湖为特色的组织仍然将活跃的 Hive Metastore 部署作为其架构的一部分。与 Hadoop 的同类产品相比,你可能会想,“Hive Metastore 有什么特别之处?”
要回答这个问题,让我们深入了解一下 Hive Metastore 目前提供了什么功能,以及正在出现什么技术来取代它。
Hive Metastore 做了什么?
在将新数据存入对象存储中时,我们会在 Hive Metastore 中注册一个元存储 API,该 API 来自于任何数据应用或编排工具。此生命性阶段将一组对象从对象存储重映射到 Hive 公开的表。部分注册包含指定文件中保存的表的模式,以及描述这些列的元数据。
以这种方式使用 Hive Metastore 有四个主要好处:虚拟化、可发现性、模式演化、性能。让我们来详细讨论一下。
虚拟化
数据分析师使用 SQL 通常不关心对象存储的细节和其访问模式。他们只是想要得到他们的表。
当其他 Hadoop 组件被取代时,Hive Metastore 将扮演不可替代的角色。每种新技术的引入都确保了对 Hive Metastore 的支持,从而避免了依赖于 Hive 中定义的表对象的关键分析工作流。
可发现性
当公开新数据并更新数据时,Hive Metastore 会变成包含在对象存储中的所有集合的目录。如果维护得当,就可以发现可供查询的数据集。
另外,补充性信息可以保存在元存储中,以便提供关于数据的有用信息,比如其更新频率,谁拥有它,等等。
模式演化
管理数据集所面临的挑战之一就是其可变性。在描述其属性的现有列时,记录可以随时间而改变。也有可能是属性集本身会随时间改变,从而导致表的模式发生改变。
上述的注册过程为每一个属于表的附加数据文件提供了模式的记录。这就是说,如果模式在某一时刻发生了变化,那么它将被记录到 Hive Metastore 中。在访问数据时,可以使用合适的模式进行访问。
这也为验证一个模式提供了一个很好的基础,如果它不应该被改变,并对它发出警报。Hive 保存着创建此类测试的信息。
性能
因为 Hive Metastore 将表映射到了底层对象上,所以它可以基于对象存储支持的主键来表示分区。当分区均衡且数量合理时,分区的粒度可以由用户设置,这种映射可以提高查询性能。
这通常被称为“分区修剪”(partition pruning),它允许查询引擎识别哪些数据文件可以被跳过。
Hive 会在下一次革命中幸存吗?
目前还没有直接取代元存储的候选者,但如果现有的一些趋势占据上风并发挥好作用,那么它可能会被淘汰。
让我们来看看领先的继任者们。
开放表格式
Iceberg、Hudi 和 Delta Lake 是这个类别中的三个参与者。每一个都是为了满足不同的需求而创建的,但是随着时间的推移,它们全部汇聚在一起,涵盖了一系列的特性。这些特性允许:
可变性(Hudi、Delta)
访问大表的效率(Iceberg)
模式实施和演化(Delta)
由于 Hive Metastore 是一个所有应用程序都支持的通用接口,因此使用开放表格式的组织仍然依赖 Hive 来进行虚拟化,以及 / 或用于格式未涵盖的其他用例。
数据目录
在过去的一年多时间里,我们目睹了由数据工程领域的领导者发布的 10 多个开源发现工具的闪电战,这表明了对组织级数据目录的需求。这些新来者加入了其他现有的商业数据目录产品,如 Allation。
目录支持对象存储与目前使用的大多数数据库的映射。如有可能,许多发现工具将利用已经在 Hive Metastore 中的数据,否则就会进入对象存储。毫不奇怪,随着时间的推移,这些工具很有可能取代 Hive Metastore 的编目功能。
可观察性工具
可观察性工具的主要目的是在运行中监控数据管道的质量和数据本身。一些工具专注于前者(如 Databand),而另一些工具侧重于后者(Great Expectations 或 Monte Carlo)。如果可观察性工具在整个数据生命周期内实施,它可以动态地更新数据目录,并将 Hive Metastore 替换为目录。
结 语
许多技术已经开始在改进 Hive 的功能方面有所突破。但是现在还没有任何一种技术足够成熟,也没有就成功去除 Hive Metastore 的组合达成共识。
这并不意味着它应该或将继续成为数据架构的一部分。实际上,它在可用性和性能方面都存在着明显的不足。值得关注的是 Hive Metastore:
难以安装和维护。
非云原生架构,使得管理服务的实施变得复杂。
因依赖关系型数据库而受到可扩展性限制。
综合这些因素,我们可以预测 Hive Metastore 不会在下一个数据架构的演进中幸存下来。这种情况不会自动发生——它需要来自社区内部的力量。愿你与我们携手共创美好未来!
作者介绍:
Einat Orr 博士,Treeverse 合伙创始人兼 CEO,lakeFS 合伙创始人。
原文链接:
https://lakefs.io/hive-metastore-why-its-still-here-and-what-can-replace-it/

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论