
概述
准确地感知人类面部表情,并能够做出合理的反应,是人机交互发展中的重要一环。表情能够帮助反映情绪,准确的表情表征方式能够促进机器对于人类情感的理解,这为建立一个友好、智能、和谐的人机交互系统提供了技术基础。合理的表情表征方式能够帮助推进多个相关下游任务的发展,包括表情图像检索、情绪识别、AU 识别、面部表情生成等。这些任务以表情表征为基础,广泛应用于虚拟人设计,游戏设计,视频制作等多个领域。
人类具有感知表情的天性,但这却是机器不擅长的,原因在于机器难以通过明确地定义特征来模拟人类抽象的感知过程。因此,如何合理地表征表情并促进自然和谐的人机交互功能的发展,为多个应用领域提供技术支持,是一个热门的研究方向。
现有的表征表情方法主要有:基于面部动作单元(Action Unit, AU)的表征方法,基于离散表情标签的表征方法以及基于相似度比较的表征方式。基于 AU 的方法将人脸面部划分成多个动作单元,每个单元描述局部区域的肌肉运动,不同的表情可以用不同的 AU 组合以及强度进行表示。基于离散表情标签的方式一般基于 7 种基本表情(高兴,伤心,生气,厌恶,中性,惊讶,害怕)的分类任务,容易忽略一种基本表情类别中存在着巨大的方差,难以表征细粒度的表情。无论是基于 AU 还是基于离散表情标签的方式都忽略了一个事实,不是所有的表情都可以从明确的语义上进行定义。基于相似性比较的方式往往能够实现比较细粒度的表征,但是这种方式需要大量的数据的比较,对数据的标注要求较高。考虑到标注者的主观判断影响,不同标注者间可能存在一定的差异性影响。另外目前该类的方法没有充分考虑到身份信息与表情信息的耦合关系。
针对这些问题,网易伏羲虚拟人团队近期发表了一篇论文,采用显式去除身份信息的建模方式,对复杂环境下的细粒度人脸表情进行精确表征,提升机器对人类表情的理解能力。本论文已被 CVPR 2021 接收。

为构建紧致、平滑的表情表征空间,本文采用基于相似度比较的方法,从人的感知标注出发,模拟真实人类对表情的抽象分析过程。通过 FEC 数据集(首个基于人类感知的表情三元组比较数据集,相关论文收录于 CVPR 2019), 实现复杂环境下精细粒度的表情表征。本文将表情特征建模为从身份特征表征向量出发偏移得到的一个差值向量,以显式的方式去掉身份特征的影响。同时,为了加强网络在深层的学习能力,本研究通过高阶多项式的方法替代一般的全连接层去完成从高维到低维的映射。另外,考虑到不同标注者存在一定标注噪音,本研究增加了众包层(Crowd layer)学习不同标注者的偏差,使学习到的表情表征更加鲁棒。最后,我们利用层级化的标注实现了数据增强。
定性和定量的实验结果表明,该方法在 FEC 数据集上达到了 SOTA 水平,并且的确去除了身份信息的影响。该模型在情绪识别、图像检索以及人脸表情生成等应用上都有不错的效果。
以下为方案的详细解读。
方案详解
相关研究论证,人脸表情特征应该位于靠近人脸身份特征的低维流型上。因此,本文将表情特征建模为从身份特征出发的一个差值特征,如图 1 所示,其中$V_{exp}=V_{face}-V_{id。}$
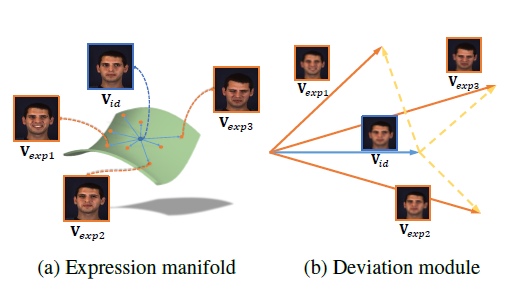
为了获得这种差值向量,我们设计了一个伪孪生结构的网络 Deviation Learning Network(DLN)去学习表情的表征,该网络的结构如图 2 所示。
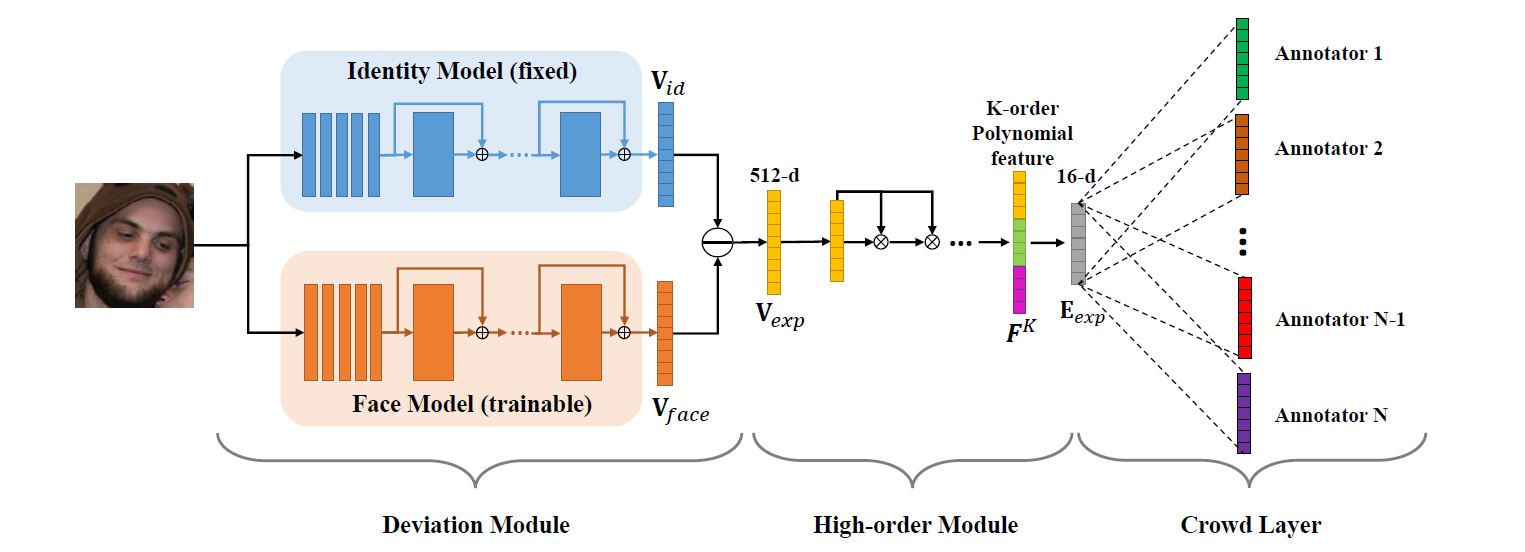
Deviation Module 包含两部分网络:Identity Model 和 Face Model。Identity Model 采用固定参数的,已预训练好的 FaceNet,用于输出稳定可靠的身份特征;Face Model 的结构和初始化参数与 Identity Model 一样,它用于学习全脸特征,两个网络之间的差值向量用于表征表情。这样的方式不仅显式地去掉了身份信息的影响,并且使得模型对表情表征的优化空间靠近 id 特征,符合表情的流型假设,收敛速度更快。
为了实现紧致的表情表征,需要将差值特征$V_{exp}$从 512 的高维空间映射到 16 维的低维流型上。常用的方式是采用几个全连接层,但是在网络越深的位置继续增加层数会导致网络收敛优化困难。而实际上全连接层的作用就是帮助拟合这种非线性的映射,因此本方法直接提供网络输入的多项式特征,帮助缓解网络的优化压力。
考虑到不同标注者存在一定的主观性差异,本方法为每个标注者构建一个全连接层(Crowd Layer)用于学习各个标注者的标注偏差,每个全连接层的输入来自于一个共同的表征编码$E_{exp}$,输出是每个标注者各自的表情表征,在训练时,每条数据的标注者将从各自的输出上计算损失函数并更新网络,而在测试和预测时仅使用 Crowd Layer 前的$E_{exp}$作为表情的表征编码。本设计采用 Triplet loss 损失函数作为模型的训练依据,使用 SGD 优化器实现梯度计算和参数更新。
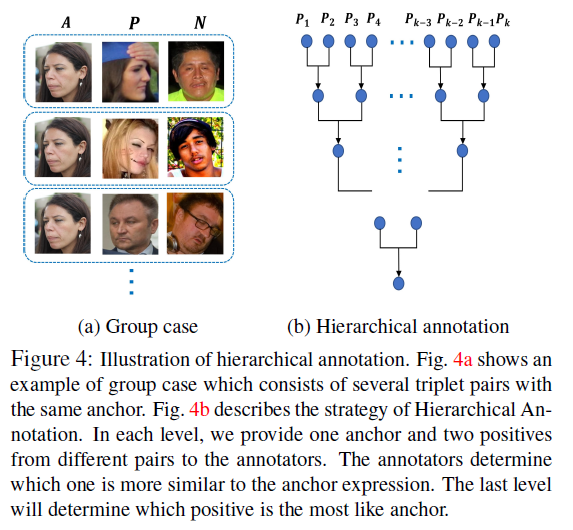
FEC 数据集中存在一张图像反复出现在不同三元组的现象,据此可以通过层次化标注的方式进行进一步的标注,实现一种数据增强,层次化标注的示意图如下所示。该方法可以帮助提供更多细粒度的数据,并且由于比较的传递性,除了标注的数据之外,我们还可额外获得一些三元组数据。
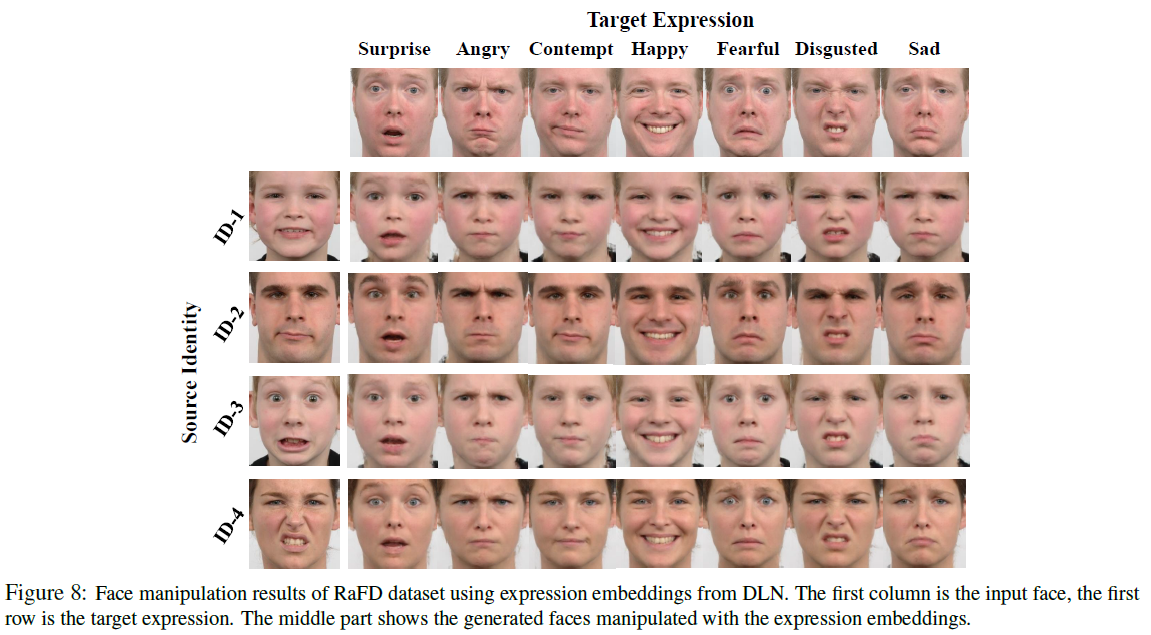
训练好的模型在 FEC 数据集的三元组预测任务上达到 85.4%的准确率,获得现有的 SOTA 水平。在不使用额外 trick 的情况下,所提出的模型在情绪识别任务上达到接近 SOTA 的效果。在表情检索以及人脸表情生成任务上都有不错的效果。

总结与展望
本文提出的去身份信息的表情表征方法,依据有效的表情特征建模方式,大幅减小了模型参数并且加快了收敛速度。实验部分论述了我们的方法在身份信息解耦合,以及表情空间紧致性方面均有提升。下一步我们的工作将在表情空间的紧致性和平滑性方面做进一步的提升,一些应用论证我们的方法具有非常巨大的潜在应用,未来这一工作可与众多与表情有关的任务相结合。




