

一、当前大数据挑战
近年来,随着大数据规模的增长,以及大数据应用的发展,大数据技术的架构也在持续演进。早期的技术架构是计算资源和存储资源高度融合,计算和存储资源一体化存在以下明显的挑战:
1. 数据孤岛
如今,企业拥有 PB 级数据已经成为常态,EB 级数据时代也将很快到来。企业需要面向结构化数据、非结构化数据、实时数据等多种类型的数据提供高扩展且统一的数据管理和数据存储能力。
2. 刚性扩容
在数据空间持续增长的背景下,大数据应用场景不断增加,对企业算力的需求也在加剧提升。而同时,新品发布、热点事件等带来的业务浪涌,也需要企业大数据系统拥有极致的弹性能力。
3. 利用率低
大数据行业技术栈迭代迅速,企业自行构建 IDC 中心和自行部署软件,一次性投资大,且折旧成本高,运营运维负担沉重。
4. 作业拥塞
随着业务的发展,在数据量巨大的背景下,单次分析作业常需要读取 TB-PB 级的数据,多任务并发下,极易出现作业拥塞。
面对以上挑战,传统的以私有数据中心为基础的存算一体大数据架构,已无法满足企业海量数据分析的需求。业界知名分析机构 IDC 在最新的报告中明确指出:企业上云已成必然趋势。因此,在公有云上部署更灵活高效的大数据分析平台,将成为企业的必然选择。
二、腾讯云弹性 MapReduce(EMR)
目前越来越多的企业开始选择使用计算和存储分离的架构,以应对更低成本的要求,和兼顾资源扩展的灵活性。
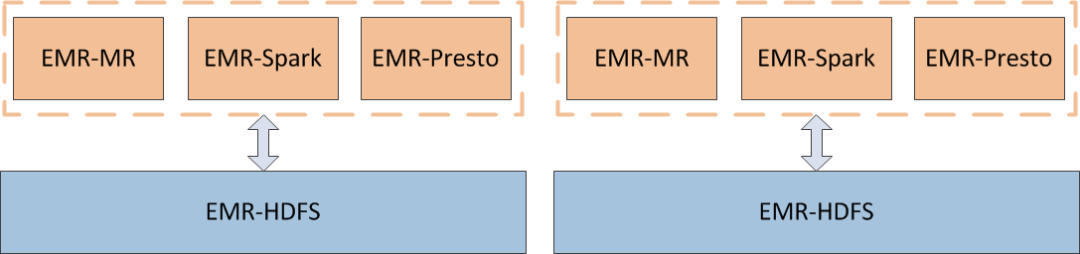
传统计算存储一体架构
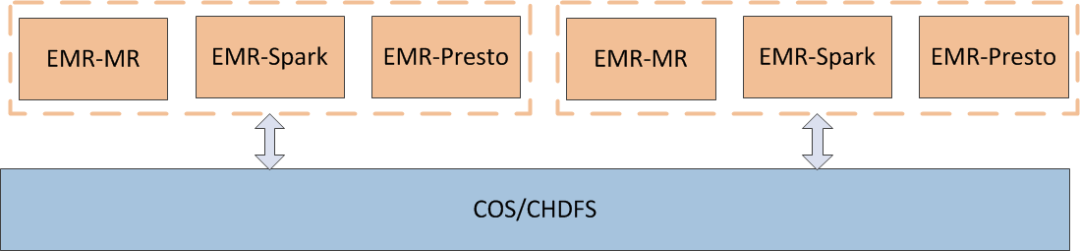
计算存储分离架构
目前腾讯云弹性 MapReduce(EMR)[1]支持了三种存储系统:EMR-HDFS、EMR-COS[2]、EMR-CHDFS[3],其中 EMR-COS 和 EMR-CHDFS 在 EMR 中都是开箱即用的原生支持计算存储分离的方案,其具体应用场景及特点如下:
元数据操作效率高,能够与 HDFS 相当,能够有效规避 COS 文件系统元数据操作耗时以及高频访问下可能引发不稳定的问题。但在实际使用场景中,因为可能存在多个数据存储源管理复杂,部分业务场景对数据源的 IO 访问密集造成网络压力大,访问不稳定等问题。所以我们基于 Alluxio 进一步优化计算和存储架构,更好的满足业务应用上的需求。
三、基于 Alluxio 优化计算存储分离架构
传统计算存储分离,解决了计算量和存储量不匹配问题, 实现了算力的按需使用,大幅节省了运维规划时间以及闲置的算力成本。但直接使用计算存储分离架构,也引入了新的问题:
在 IO 密集型的场景下,网络带宽会成为瓶颈, 可能导致计算 & 存储资源利用不充分;
数据本地化不够,导致很多 shuffle 过程的重复计算,造成部分浪费计算资源的浪费;
可能存在多种甚至异构的存储源,增加了管理难度。
为此,腾讯云 EMR 团队与 Alluxio 社区合作,引入最新 alluxio2.3.0 Release 版本进行深度优化,推出开箱即用的计算存储分离优化版本:EMR2.5.0/EMR3.1.0/EMR-TianQiong-1.0,解决上述问题。
1. 提供内存级 I/O 能力
Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio 的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
2. 提高数据本地性
利用 Alluxio 提供的分布式缓存服务,在部署 Alluxio 数据节点(Alluxio-Worker)时和计算节点部署在一起,可以直接从数据节点中以内存级 IO 速度检索读取数据,而不是从底层云存储或对象存储中检索读取,提高了数据本地性。
3. 简化云存储和对象存储接入
与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。在云存储和对象存储系统上进行常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。
4. 简化数据管理
Alluxio 提供对多数据源的单点访问。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接同一存储系统的不同版本,如多个版本的 HDFS 以及云上 COS/CHDFS,只需基于 EMR 配套的简单配置下发和管理管理功能。
在引入 Alluxio 后,EMR 基于 Alluxio 的存算分离的整体架构变成了:
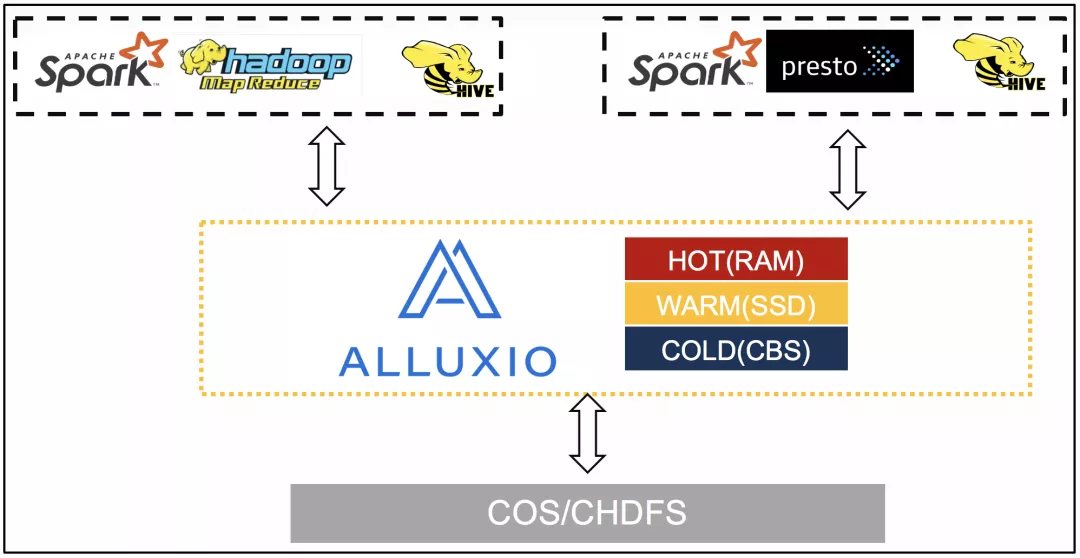
这样,EMR 的计算引擎(Spark,MapReduce,Presto 等)就可以统一通过 Alluxio 来提升性能,降低网络峰值带宽,以及简化数据管理。
四、性能评估及调优
为了分析理解使用 Alluxio 存储在主流查询引擎 Spark 性能上差异,我们使用大数据压测工具 TPC-DS 进行了一些性能压测。我们使用的环境及配置如下:
EMR 版本:EMR-2.5.0;
选择组件:zookeeper-3.6.1,hadoop-2.8.5,hive-2.3.7,spark_hadoop2.8-3.0.0,tez-0.9.2,alluxio-2.3.0,knox-1.2.0;
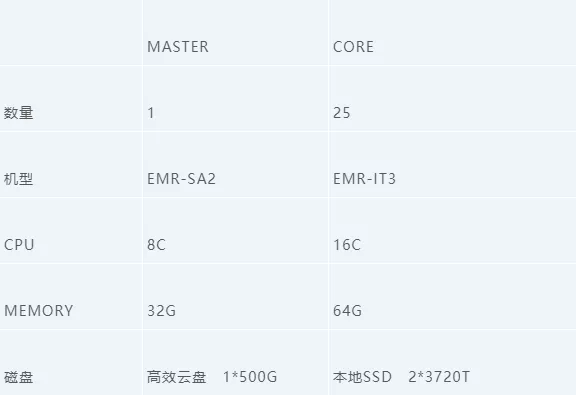
压测配置,使用了 1 个 EMR 的 Master 节点和 25 个 CORE 节点,具体如下:
1. 带宽评估
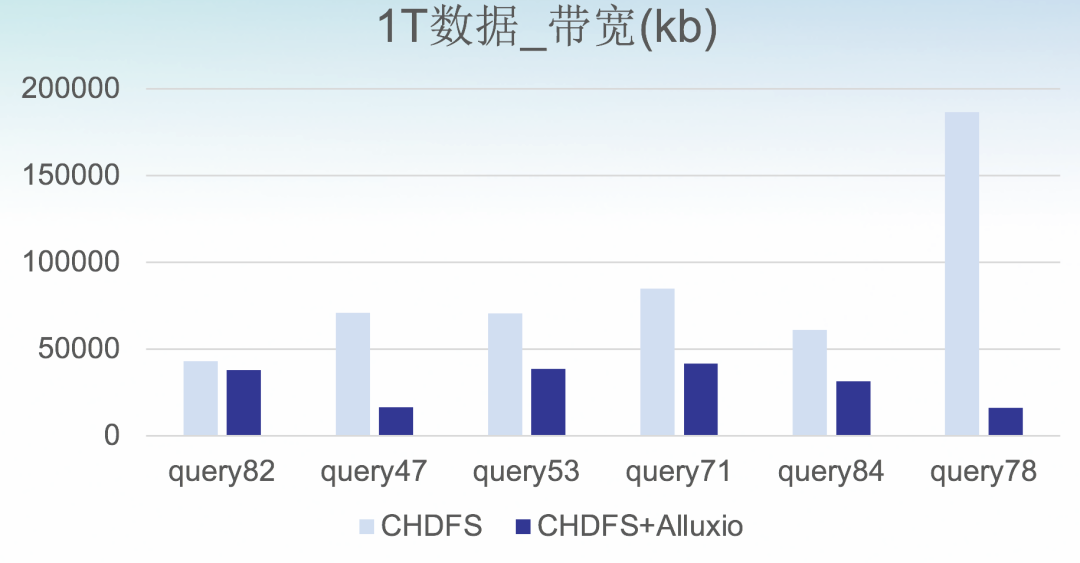
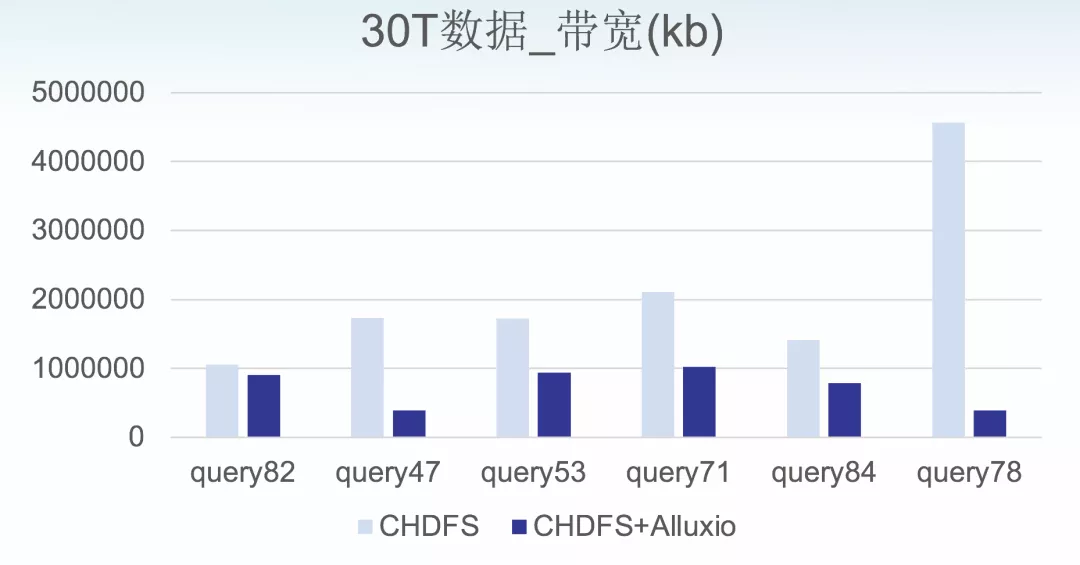
从压测结果可以看到,能大幅优化计算存储分离网络带宽,节省峰值带宽(削峰)20%-50%,节省总带宽(10%-50%)。
2. 查询性能评估
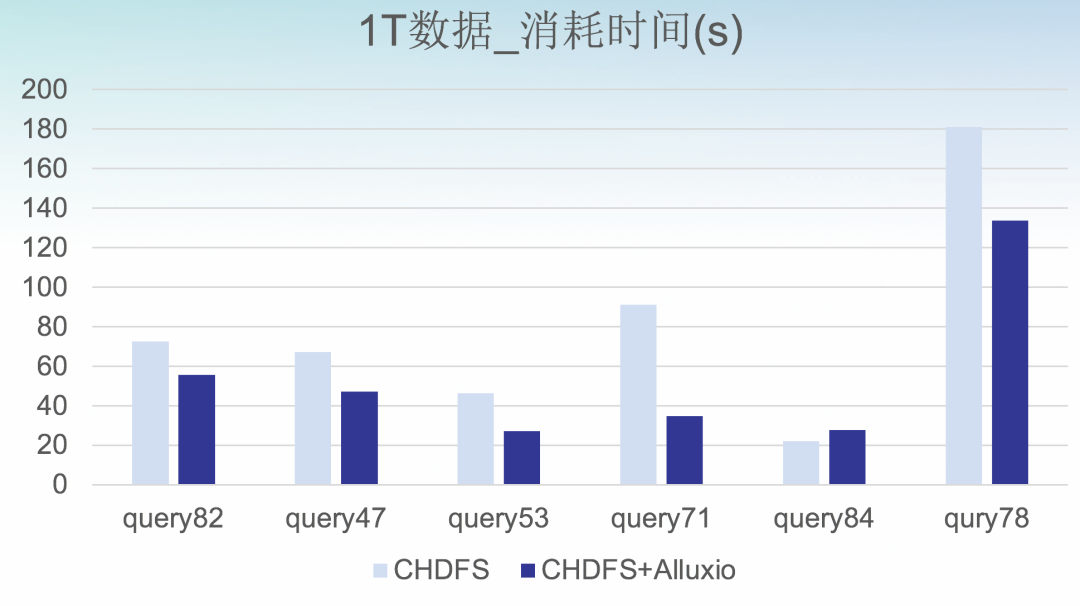
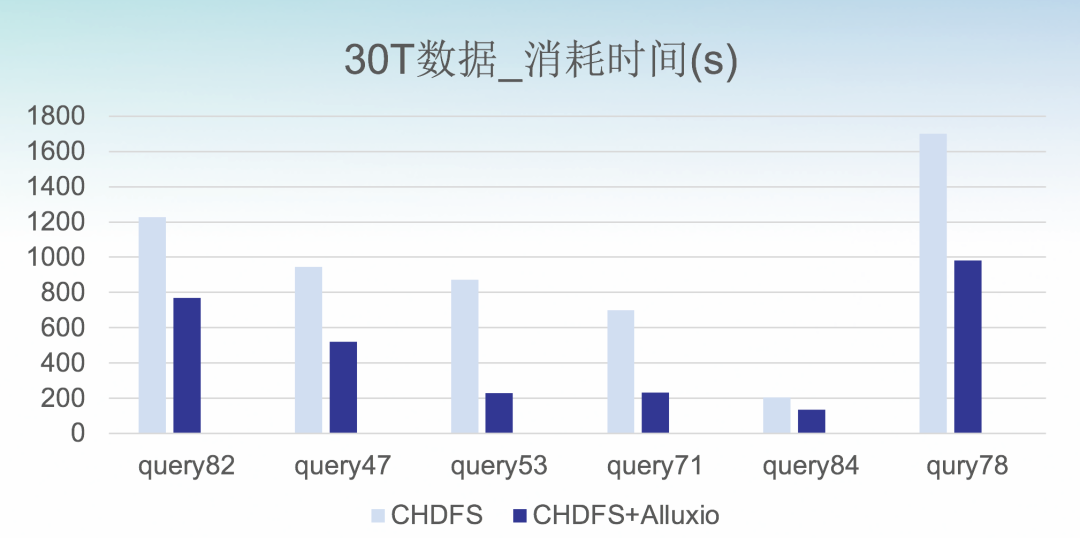
从压测结果可以看到,在大部分场景下能优化性能,特别是 IO 密集型,优化性能 5%-40%。
3. 性能调优及专项优化
为了更好满足计算存储分离场景,EMR 团队针对 Alluxio 做了专项调优,具体包括:
(1)数据本地性
为了更好满足数据本地,EMR 在部署 Alluxio 时,在 core 节点把 alluxio-worker 同计算节点部署在一起,这样 yarn 等计算服务节点可以在同一个节点中与 alluxio-worker 节点通信,大量提升了效率。
另一方面,结合 alluxio 已经提供的读写策略,结合存算分离场景优化了 block.read.location.policy,writetype.default 等策略,让 alluxio 的缓存能力更好满足本地性。
(2)元数据优化
Alluxio 基于 Presto 实现了 Catalog Service,并且实现了计算框架端的 Connector,Alluxio 可以感知并管理结构化数据的元数据,大大简化表级别的使用成本。同时,腾讯内部在大规模使用 Alluxio 时,我们发现 Alluxio 本身的 inode 元数据也面临着膨胀的风险。为此结合 Alluxio 提供的 Catalog Service 和 Path 缓存能力,优化了 path.caching.thread 和 path.cache.capacity 等策略。
更多 meta 具体优化可参考,社区 meta 优化[4]及 catalog 介绍[5]。
(3)Java GC 的影响
Alluxio 作为 Java 的进程,其 GC 的经常影响其性能表现,为此,EMR 团队引入了 Tencent Kona,经过了内部大数据和 AI 等业务场景的验证,为 JAVA 生态提供专业持续的保障。Kona 在 GC 线程调度优化,物理内存释放优化等方面有优秀表现,更多功能特性可见:Kona JDK[6]。
上述的这些能力和优化,在存算分离场景下,腾讯云 EMR 产品针对这种场景都已经直接提供了开箱即用的能力,直接在腾讯云 EMR 产品购买页创建,或者在已有支持了 alluxio 的 EMR 版本上安装,即可达到性能评估中效果。
五、总结
从上述的压测结果看到,一方面有效的降低了带宽峰值和总带宽,从而降低带宽成本,加速访问;另一方面,IO 密集型场景下的性能也有不少提升,能更好的支持 IO 密集型场景下的业务。此次基于 Alluxio 的优化,让腾讯云弹性 MapReduce(EMR)产品更好的支持存储计算分离架构,为用户更好的满足业务需求的同时,降低成本,且保持资源扩展的灵活性。
头图:Unsplash
作者:腾讯云大数据
原文:https://mp.weixin.qq.com/s/WUcuGRJwOnlfNW4XjS0JiA
原文:腾讯云基于 Alluxio 优化计算存储分离架构的最佳实践
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论