

今天为大家带来的论文导读是由布兰迪斯大学和微软亚洲研究院所提出的 RePr——专为卷积神经网络所设计的训练方法。该方法通过对滤波器的重要性进行排序,对网络进行修剪,并迭代训练完整网络和子网络,提升网络表现和泛化能力。作者设计了充分的 ablation study 和跨任务网络实验,证明了该训练方法的有效性。这篇论文已被 CVPR2019 接收为 oral。本文是 AI 前线第 73 篇论文导读。
摘 要
一个训练良好的卷积神经网络可以很容易地进行网络修剪,而不会有明显的性能损失。这是因为网络滤波器捕捉的特征之间有不必要的重叠。跳跃连接、密集连接,以及 Inception 单元等网络结构上的创新都在一定程度上减轻了这个问题,但是这些改进往往伴随着运行时计算和内存需求的增加。我们试图从另一个角度来解决这个问题——不再是通过改变网络的结构,而是通过改变训练方法。通过暂时修剪,然后恢复模型的滤波器子集,并循环重复此过程,可以减少学习特征的重叠,从而提升泛化能力。我们发现,现有的模型修剪标准并不是最佳的,因此我们引入滤波器间正交性作为排序标准,来确定表示能力较弱的滤波器。我们的方法既适用于最简单的卷积网络,也适用于当前复杂的网络结构,提高了网络在各项任务上的性能。
介 绍
卷积神经网络(ConvNet)在许多计算机视觉任务中达到了最先进的水平,其成功的主要原因是由于针对特定任务对网络结构进行了改进。尽管新的网络结构层出不穷,多种多样,但是核心的优化方法依然没有改变。目前的优化方法将网络权重看作单独的个体,然后进行独立更新。卷积神经网络的滤波器是其基础单元,但一个滤波器并不是一个单独的权重参数,而是由一组空间滤波器核组成的。
由于卷积神经网络模型往往过度参数化(over-parameterized),一个训练好的模型滤波器通常是冗余的。因此大部分修剪滤波器的方法都能去掉大量滤波器,而不损失模型的表现。但是对于小型模型,从头开始训练的表现也比不过一个大型网络修剪到和它一样大小的表现。标准的训练过程倾向于让模型有额外的和可修剪的滤波器。这也意味着卷积神经网络的训练还有提升的空间。
为此,我们提出了一种训练方案,在该方案中,在经过标准训练的迭代之后,我们选择一部分滤波器的子集暂时丢弃。在对修剪后网络进行额外训练之后,我们重新引入先前丢弃的滤波器,用新的权重初始化,并继续标准训练。我们观察发现,在重新引入丢弃的滤波器之后,该模型能够达到比修剪之前更高的性能。如图 1,重复这一过程所获得的模型,其表现超过了由标准训练产生的模型。我们发现这一提升适用于多种任务和多种卷积神经网络。
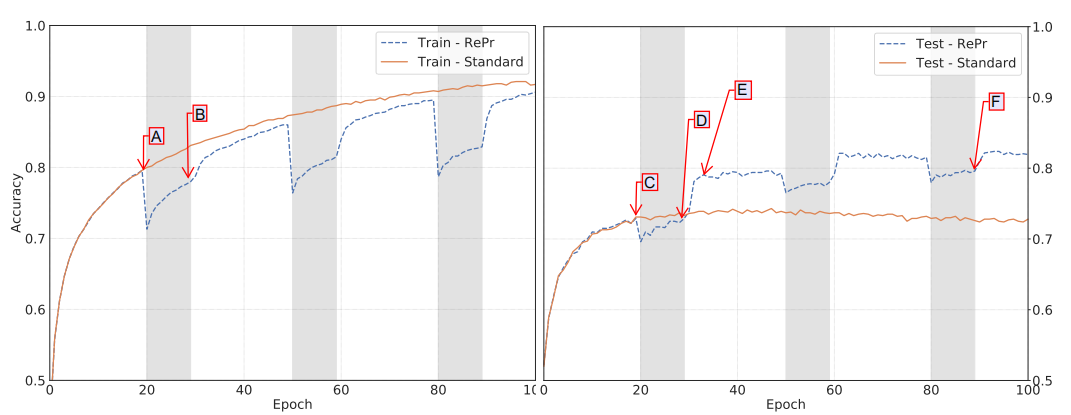
图 1 有 32 个滤波器的三层 ConvNet 使用标准训练方法和 RePr 方法,训练 100 个 epoch 后在 CIFAR-10 上的分类准确度。阴影区域表示仅有部分网络训练。左:训练准确率,右:测试准确率。(对 A-F 各点的详细介绍请参考论文原文第 4 部分)
除了所提出的新的训练方法,该论文的第二个贡献在于提出了衡量滤波器重要性的指标。我们发现即使是参数化不足(under-parameterized)的网络也会出现学习参数冗余的情况,说明滤波器冗余并不只是由于过度参数化,而是由于训练过程低效所导致的。我们的目标是减少滤波器的冗余性,增加卷积网络的表示能力,而我们通过改变训练方法而不是网络结构来实现这个目标。
实验表明,标准的滤波器修剪方法并不能达到最优的效果,我们提出了一种替代的指标,计算效率较高,并且极大的提升了网络表现。我们基于卷积层内的滤波器正交性提出了一个滤波器丢弃指标 Ortho,该指标的效果超过了目前最先进的滤波器重要性排序算法。
正交特征
如果一个特征能帮助提升模型的泛化能力,则该特征是有用的。特征之间的相关性与网络的泛化能力和稳定性都密切相关。对于一个泛化能力较差的模型,其特征在响应空间只能捕捉到有限的方向,即特征相关性较高。另一方面,如果特征之间互相正交,这说明他们分别学习到了响应空间的不同方向,则提高了模型的泛化能力。除了表现性能和泛化能力的提升,权重正交还能够提升网络训练的稳定性。为了降低特征之间的相关性,人们提出过多种方法。可以通过分析不同层特征的相关性,然后将特征进行聚类。或者在损失函数中加入正则项,最小化特征的协方差。但这些方法或计算复杂度高,或效果提升一般。在 RNN 中常采用正交初始化,但是该方法并不适用于卷积神经网络。因此,我们的动机是增强 CNN 特征正交性,并且基于此形成滤波器排序指标。
由于直接计算特征的正交性需要跨训练集,所以我们通过计算滤波器的权重来代替。我们使用 Canonica 相关性分析(CCA)来研究特征在单层内的重叠。研究人员发现大部分卷积神经网络结构学习到的都是相似的特征。增加模型深度并不一定能增加模型的维度,因为不同层学习的特征也是相关的。但我们关注的是在同一卷积层内不同滤波器特征的相关性。在过度参数化的网络中,例如 VGG16,好几层卷积层都含有多达 512 个滤波器,而这些滤波器的特征都是高度相关的。因此 VGG16 是很容易修剪的网络——超过 50%的滤波器都可以被丢弃,而不改变网络的表现性能。那么对于很小的卷积网络这一点还成立吗?
我们考虑一个简单的网络,只有两层卷积层,每层 32 个滤波器,网络最后有一个 softmax 层。我们在 CIFAR-10 数据库上训练 100 个 epoch,采用学习率衰减,测试准确率仅为 58.2%,远远低于 VGG-16 所达到的 93.5%。对于 VGG16 来说,我们可能会觉得滤波器之间的相关性只是模型过度参数化导致的假象,因为数据集的维度根本就不需要每个特征都达到相互正交。但是,小型网络明显没有捕捉到训练数据的全部特征空间,因此滤波器之间的相关性均是由于低效的训练所导致的,而不是过参数化导致的。
给定一个模型,我们可以通过移除某个滤波器,然后计算准确率的下降情况来评估该滤波器对模型的贡献,即该滤波器的重要性。我们将这种评价滤波器重要性的标准称为“greedy Oracle”。我们可视化了每个滤波器的对模型性能的影响,如图 2(右)。
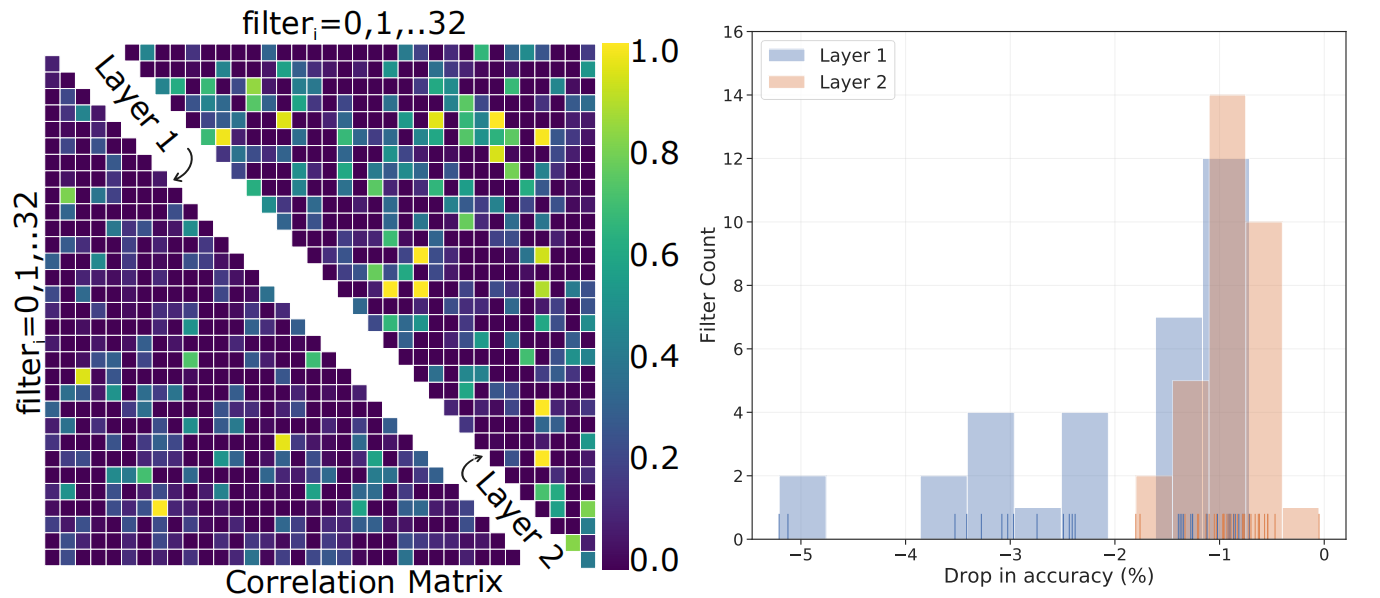
图 2:左:两层卷积网络特征的 Canonica 相关性分析。右:模型每丢弃一个滤波器时准确率的变化分布。
从图中可以看出,Layer2 的大部分滤波器对网络性能的影响不足 1%。而 Layer1 中,部分滤波器对准确率的影响达到了 4%,但是大部分依然处于 1%。这意味着即使是参数不足的网络也会出现冗余权重,也可以进行滤波器修剪而不影响模型的整体表现。说明模型没有有效的分配滤波器去捕捉必要特征的广泛表示。图 2 左给出了滤波器特征线性组合的相关性。很明显这两层滤波器之间都存在很高的相关性,有的几乎达到了完全相关(亮黄色)。第二层(右上三角)的特征重叠率比第一层(左下三角)更高。充分说明了卷积滤波器的标准训练程序不能最大化网络的表示能力。
新的训练方法:RePr
我们提出了新的训练算法 RePr:首先训练完整网络,然后移除冗余滤波器,形成子网络,再训练子网络,随后将丢弃的滤波器重新初始化,再补充回网络,重复该过程,完整网络和子网络迭代训练。算法中最重要的部分是用于对滤波器进行排序的指标:层内滤波器正交性(Ortho)。
该算法可以概括为:重新初始化(Re-initializing)和修剪(Pruning)。训练算法如下:

滤波器排序指标:滤波器间正交性(Ortho)
卷积网络一层的多个卷积核可以用一个矩阵表示。一个大小为 k x k 的滤波器核,可以视为一个形状为 k x k x c 的 3D 张量(tensor)。将这个张量平铺成一个 1D 矢量 f。Wl 为一个矩阵,其中每一行分别为网络第 l 层平铺的滤波器矢量 f。Jl 表示在第 l 层滤波器的数量。
先对矩阵进行归一化得到
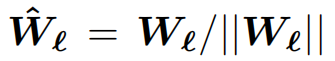
然后计算滤波器 f 在 l 层内的正交性:
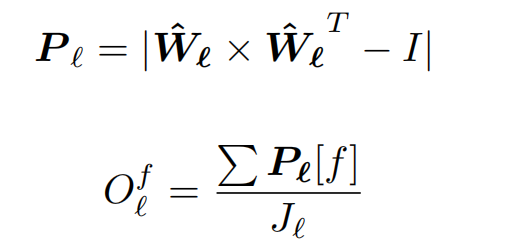
其中矩阵 Pl 是一个大小为 Jl x Jl 的矩阵,第 i 行表示 l 层内其他滤波器对第 i 个滤波器的投影。当其他滤波器与该滤波器均正交时,该行的数值之和最小。因此可以通过每行的数值之和对滤波器的重要性进行排序。这个指标的计算是在一层内完成的,但是排序是对所有层的滤波器进行的。目的是不引入过多的超参数,并且避免层与层之间的差异性。我们的方法在较深的层修剪的滤波器要多于较浅层的滤波器。这与滤波器的重要性在网络中的分布也相符(图 2)。
消融研究(Ablation study)
修剪标准
我们提出的滤波器重要性排序指标 Ortho 能否替代 greedy Oracle 呢?我们通过衡量不同指标与 greedy Oracle 之间的相关性来回答这个问题。

图 3:左:不同指标与 greedy Oracle 的 Pearson 相关系数,右:不同评价指标在 CIFAR-10 上的测试准确率。
不同指标值的相关性表示了该指标能否替代 greedy Oracle,除此之外,更重要的是衡量滤波器排序结果的相关性。图 3 给出了不同指标与 greedy Oracle 的相关性图。图 3 右边的表格给出了不同评价指标在 CIFAR-10 上的测试准确率。
修剪滤波器比例
训练方法中很重要的一个参数是每个阶段修剪滤波器的比例。它与 Dropout 参数类似,影响模型的训练时间和泛化能力。总的来说修剪比例越高,模型表现越好,然而超过 30%之后,效果提升不明显。到 50%,模型就需要从丢弃滤波器中进行恢复。超过该数值后,训练不稳定,有时会出现无法收敛的情况。
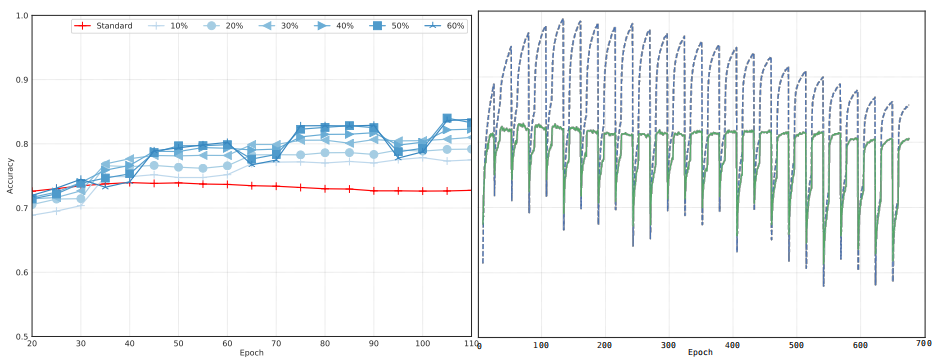
图 4 左:RePr 训练方法,不同修剪比例对比图。右:RePr 边缘收益——CIFAR-10 的训练和测试准确率。
RePr 迭代次数
实验发现,每重复一次 RePr 过程收益都会缩减,因此应该将迭代次数限制在个位数(如图 4 右)。
优化器和 S1/S2
图 5 左给出了使用不同优化器模型准确率的方差。大部分常用的优化器都适用于我们的模型。
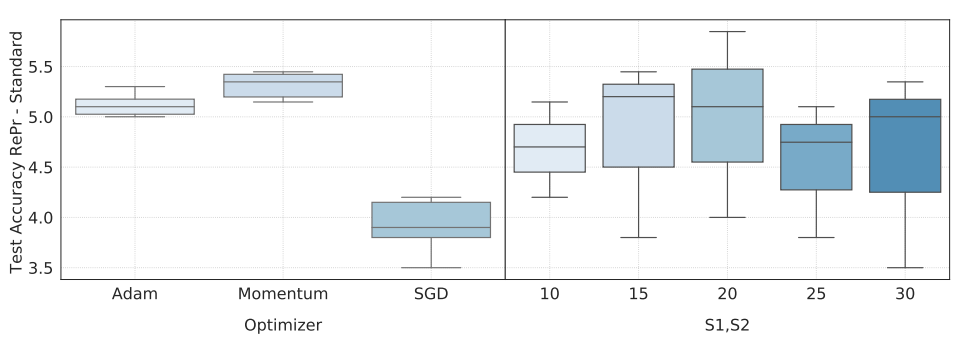
图 5:左:不同的优化器+RePr 训练方法的模型准确率方差。右:不同 S1/S2 比值的结果。
S1 和 S2 分别表示训练完整网络和子网络的迭代次数。
学习率
由于 SGD 使用固定的学习率,通常不能使模型达到最佳表现。而学习率逐渐衰减是目前常用的方法,能够让模型的准确率更高。周期性学习率(Cyclical learning rate)给出了更好的效果。图 6 对比了我们的训练方法分别与固定学习率优化器和周期变化学习率结合的效果。我们的训练方法不会受到学习率变化的影响,与标准训练方法相比提升依然很明显。
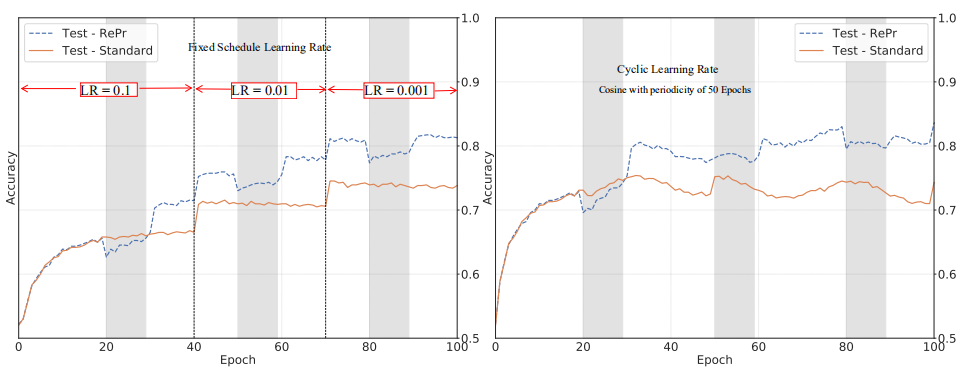
图 6:使用标准训练方法和 RePr 训练的网络在 CIFAR-10 数据库上的测试识别率。左:固定学习率 0.1,0.01,0.001。右:周期学习率,周期为 50 个 epoch,幅度变化为 0.005,起始学习率为 0.001。
Dropout 的影响
我们的方法可以视为一种非随机的 Dropout,专门适用于卷积网络。Dropout 通过鼓励权重的共适应性来防止过拟合。这对于过度参数化的模型是有效的,但是对于紧凑的或浅层模型,Dropout 或许会降低模型本就有限的表示能力。
图 7 给出了三层 ConvNet 在标准训练和 RePr 训练方法中,有 Dropout 和没有 Dropout 的情况对比。我们发现有 Dropout 和没有 Dropout,我们的方法都提升了模型的表现,说明了我们算法的效果和 Dropout 是不同的。
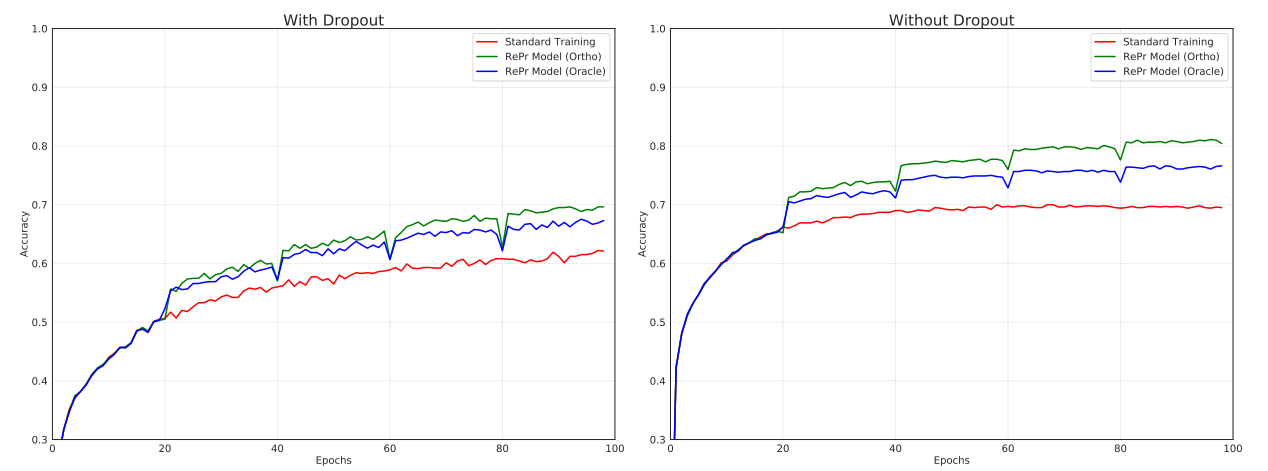
图 7:网络测试准确率对比图。红色为标准训练模式,蓝色为 RePr 和 Oracle 评价标准,绿色为 RePr 和 Ortho 评价标准。左:Dropout 为 0.5,右:无 Dropout。
正交性损失——OL
增加滤波器的正交性作为损失函数的一部分不会影响模型的表现。损失函数可以表示为:
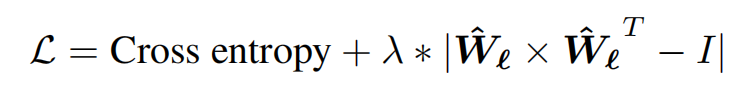
其中λ是平衡损失项的超参数。我们对λ不同值进行了实验,λ=0.01 时验证准确率最高,表 1 给出了λ=0.01 的实验结果。OL 指的是增加正交性损失项。
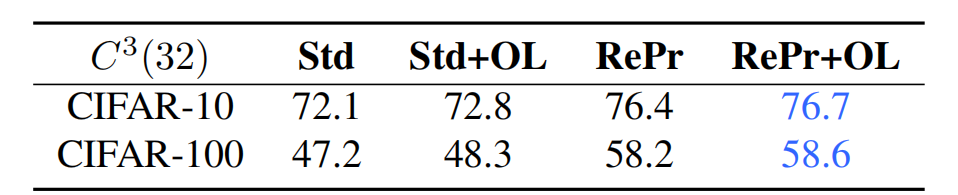
表 1:标准训练过程和 RePr 分别增加正交性损失的模型识别率。
正交性和知识蒸馏
RePr 和知识蒸馏(Knowledge Distillation,KD)都是提升模型表现的方法。RePr 减少滤波器表示之间的重叠,而 KD 从更大的网络中提取信息。我们对比了这两种方法,并发现二者可以结合,得到更好的效果。
RePr 不断的修剪权重方向重叠最多的滤波器,因此我们希望修剪滤波器的数量随训练时间逐渐减少。图 8(左)显示了三种不同训练方法下该数值的变化曲线。可以看出 RePr 训练方法+Ortho 指标的模型滤波器正交性和最低。
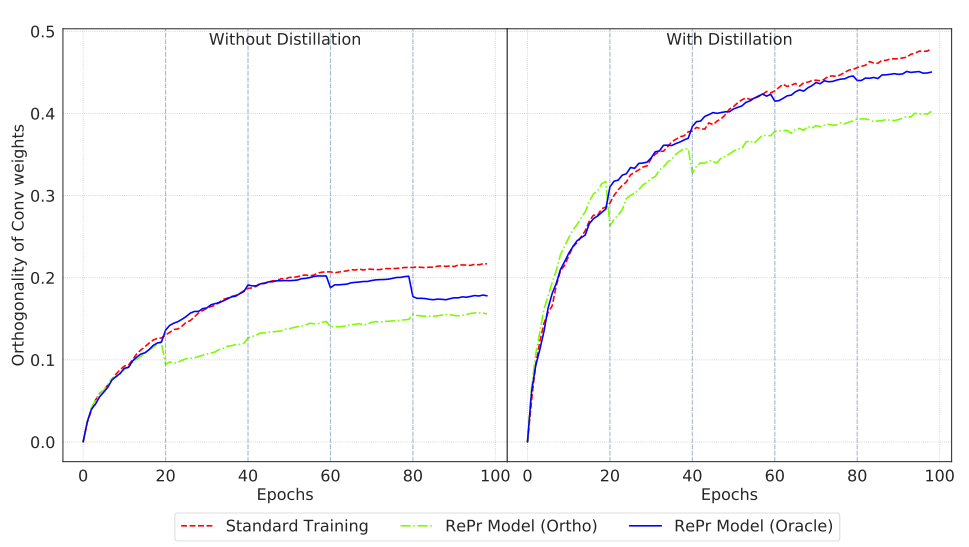
图 8:滤波器正交性对比,标准训练、RePr 训练,以及有知识蒸馏和无知识蒸馏。数值越低,说明重叠的滤波器越少。
图 8(右)对比了加入 KD 之后三种训练方法的情况,我们发现所有模型的正交性和都增加了。但是 RePr+Ortho 方法依然在努力降低模型的正交性和,说明 KD 对模型的提升并不是由于减少了滤波器重叠。因此,使用这两种方法的模型泛化性更强。如表 2 所示。

表 2:知识蒸馏与 RePr 对比
实验结果
我们对训练方法 RePr,以及滤波器重要性排序标准 Ortho 进行了实验。表 3 对比了 BAN 和 DSD 两种方法。DSD 和 RePr(Weights)的作用相似:模型稀疏化,区别在于 DSD 作用于单独的权重,而 RePr(Weights)作用于整体滤波器。而 RePr(Ortho)的表现超过了其他方法,并且训练更简单。
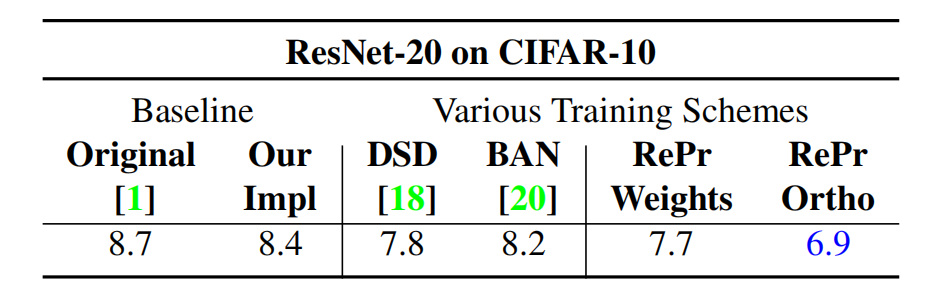
表 3:不同方法的测试误差对比
与目前的网络相比,最简单的卷积网络在特征表示的分配上效率更低,因此我们发现 RePr+Ortho 在简单卷积网络上的提升比在更复杂网络上的提升更大。表 4 给出了在 CIFAR-10 和 CIFAR-100 数据集上的测试误差。

表 4:使用标准训练方法和 RePr 训练方法的不同卷积神经网络在 Cifar-10 和 Cifar-100 数据集上的测试误差。
RePr 训练方法将简单神经网络在 CIFAR-10 数据集上的表现提高了 8%,在 CIFAR-100 数据集上的表现提高了 25%。
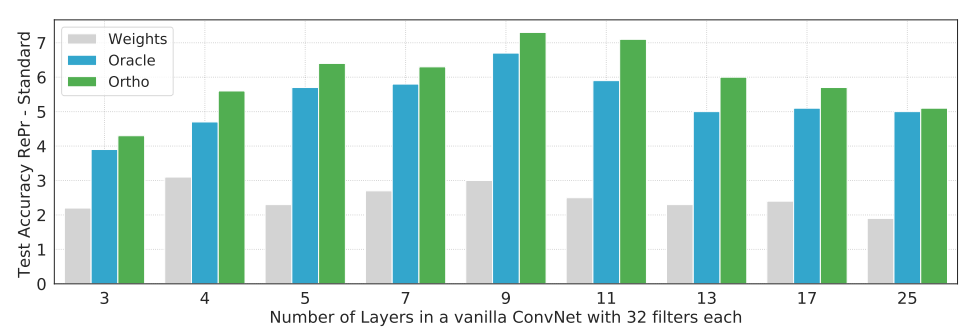
图 9:随网络层数变化,使用 RePr 训练方法与标准训练方法准确率提升程度柱状图。
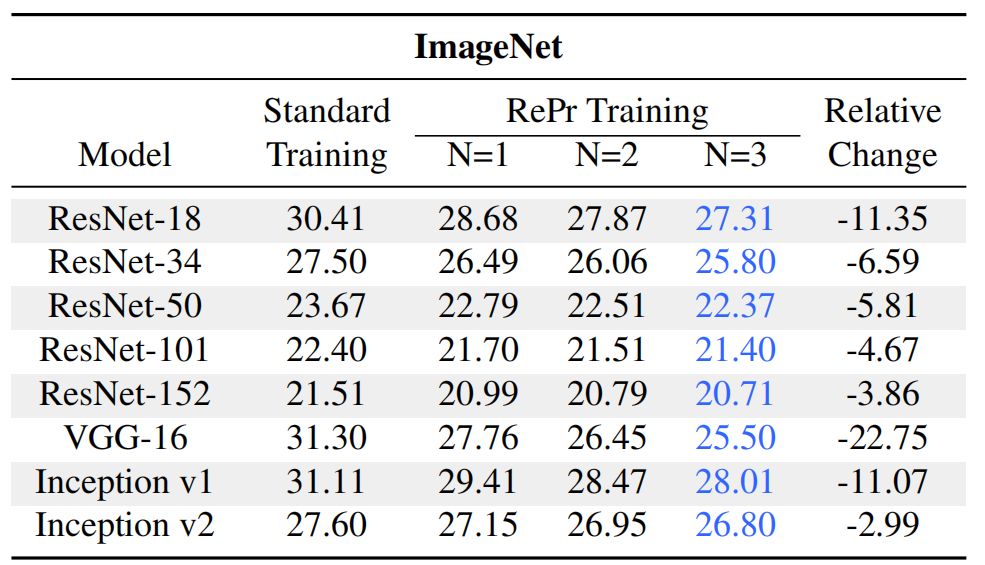
表 5:ImageNet 数据集上不同模型 Top-1 测试误差。
对于其他使用类似卷积神经网络的计算机视觉任务,我们的方法也提升了模型的表现。我们以视觉问题回答和目标检测任务为例,这两个任务都需要使用卷积网络提取特征,而 RePr 算法提升了他们的基线结果。
视觉问题回答
视觉问题回答(VQA)是指给模型一张图片和一个关于图片的问题,然后模型需要回答该问题。解决这个问题所采用的模型大部分是采用标准 ConvNet 来提取图像特征,然后用 LSTM 网络提取文本特征。实验中提取图像特征的 Inception-v1 网络分别采用标准训练方法和 RePr 训练方法。
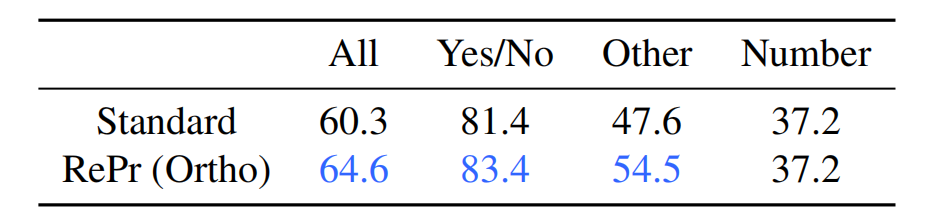
表 6:VQA-LSTM-CNN 模型在 VQAv1 数据集上的准确率。
目标检测
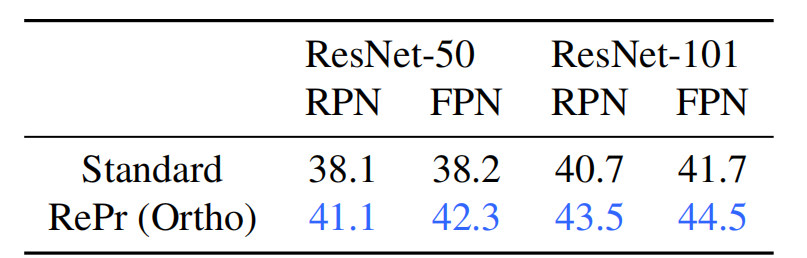
表 7:分别采用标准训练方法和 RePr(Ortho)方法训练的 ResNet-50 和 ResNet-100 在 COCO 数据集上的 mAP 分数。
总 结
这篇论文提出了 RePr 训练方法,通过将表达力较差的滤波器进行修剪和再学习,提升模型的表现。由于卷积神经网络学习到的特征表示通常是低效的,作者进一步提出了滤波器间正交性标准,对滤波器的重要性进行排序,并应用在 RePr 的修剪步骤中。实验结果表明该训练方法能大幅提升参数不足(under-parameterized)的网络的表现,确保模型能力的有效分配。对于过参数化(over-parameterized)的网络结构,所提出的方法也能提升卷积网络在多个任务上的表现。
查看论文原文:https://arxiv.org/pdf/1811.07275.pdf


暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论